Intel OpenVINO निर्यातित माल
इस गाइड में, हम निर्यात को कवर करते हैं YOLOv8 करने के लिए मॉडल OpenVINO प्रारूप, जो 3x तक प्रदान कर सकता है CPU स्पीडअप, साथ ही तेज करना YOLO पर अनुमान Intel GPU और एनपीयू हार्डवेयर।
OpenVINO, ओपन विजुअल इनफेरेंस एंड न्यूरल नेटवर्क ऑप्टिमाइज़ेशन टूलकिट के लिए संक्षिप्त, एआई अनुमान मॉडल के अनुकूलन और तैनाती के लिए एक व्यापक टूलकिट है। भले ही नाम में दृश्य हो, OpenVINO भाषा, ऑडियो, समय श्रृंखला आदि सहित विभिन्न अतिरिक्त कार्यों का भी समर्थन करता है।
सतर्कता: कैसे निर्यात और अनुकूलन करने के लिए Ultralytics YOLOv8 के साथ अनुमान के लिए मॉडल OpenVINO.
उपयोग के उदाहरण
निर्यात a YOLOv8n मॉडल को OpenVINO निर्यात किए गए मॉडल के साथ अनुमान को प्रारूपित और चलाएं।
उदाहरण
from ultralytics import YOLO
# Load a YOLOv8n PyTorch model
model = YOLO("yolov8n.pt")
# Export the model
model.export(format="openvino") # creates 'yolov8n_openvino_model/'
# Load the exported OpenVINO model
ov_model = YOLO("yolov8n_openvino_model/")
# Run inference
results = ov_model("https://ultralytics.com/images/bus.jpg")
तर्क
| अत्यंत महत्वपूर्ण | मूल्य | या क़िस्म |
|---|---|---|
format |
'openvino' |
निर्यात करने के लिए प्रारूप |
imgsz |
640 |
स्केलर या (एच, डब्ल्यू) सूची के रूप में छवि का आकार, यानी (640, 480) |
half |
False |
FP16 परिमाणीकरण |
के लाभ OpenVINO
- प्रदर्शन: OpenVINO की शक्ति का उपयोग करके उच्च प्रदर्शन अनुमान प्रदान करता है Intel सीपीयू, एकीकृत और असतत जीपीयू, और एफपीजीए।
- विषम निष्पादन के लिये समर्थन: OpenVINO एक बार लिखने और किसी भी समर्थित पर तैनात करने के लिए एक एपीआई प्रदान करता है Intel हार्डवेयर (CPU, GPU, एफपीजीए, वीपीयू, आदि)।
- मॉडल अनुकूलक: OpenVINO एक मॉडल ऑप्टिमाइज़र प्रदान करता है जो लोकप्रिय गहन शिक्षण ढांचे से मॉडल आयात, परिवर्तित और अनुकूलित करता है जैसे कि PyTorch, TensorFlow, TensorFlow लाइट, केरास, ONNX, PaddlePaddle, और कैफे।
- उपयोग में आसानी: टूलकिट 80 से अधिक ट्यूटोरियल नोटबुक (सहित YOLOv8 अनुकूलन) टूलकिट के विभिन्न पहलुओं को पढ़ाना।
OpenVINO निर्यात संरचना
जब आप किसी मॉडल को निर्यात करते हैं OpenVINO प्रारूप, इसका परिणाम एक निर्देशिका में होता है जिसमें निम्नलिखित होते हैं:
- XML फ़ाइल: नेटवर्क टोपोलॉजी का वर्णन करता है.
- बिन फ़ाइल: इसमें weights and biases बाइनरी डेटा।
- मैपिंग फ़ाइल: मूल मॉडल आउटपुट टेंसर की मैपिंग को पकड़ता है OpenVINO tensor नाम।
आप इन फ़ाइलों का उपयोग अनुमान के साथ चलाने के लिए कर सकते हैं OpenVINO अनुमान इंजन।
का उपयोग करके OpenVINO परिनियोजन में निर्यात
एक बार आपके पास OpenVINO फ़ाइलें, आप OpenVINO मॉडल को चलाने के लिए रनटाइम। रनटाइम सभी समर्थित में अनुमान लगाने के लिए एक एकीकृत एपीआई प्रदान करता है Intel हार्डवेयर। यह लोड बैलेंसिंग जैसी उन्नत क्षमताएं भी प्रदान करता है Intel हार्डवेयर और अतुल्यकालिक निष्पादन। अनुमान चलाने के बारे में अधिक जानकारी के लिए, देखें के साथ अनुमान OpenVINO रनटाइम गाइड।
याद रखें, आपको रनटाइम के साथ मॉडल को सही ढंग से सेट अप करने और उपयोग करने के लिए XML और BIN फ़ाइलों के साथ-साथ किसी भी एप्लिकेशन-विशिष्ट सेटिंग्स जैसे इनपुट आकार, सामान्यीकरण के लिए स्केल फैक्टर आदि की आवश्यकता होगी।
आपके परिनियोजन अनुप्रयोग में, आप आमतौर पर निम्न चरणों का पालन करेंगे:
- प्रारंभ OpenVINO बनाकर
core = Core(). - का उपयोग करके मॉडल को लोड करें
core.read_model()विधि। - का उपयोग करके मॉडल संकलित करें
core.compile_model()फलन। - इनपुट (छवि, पाठ, ऑडियो, आदि) तैयार करें।
- का उपयोग करके अनुमान चलाएं
compiled_model(input_data).
अधिक विस्तृत चरणों और कोड स्निपेट के लिए, OpenVINO प्रलेखन या एपीआई ट्यूटोरियल।
OpenVINO YOLOv8 मानक
YOLOv8 नीचे दिए गए बेंचमार्क द्वारा चलाए गए थे Ultralytics गति और सटीकता को मापने वाले 4 अलग-अलग मॉडल प्रारूपों पर टीम: PyTorch, TorchScript, ONNX और OpenVINO. बेंचमार्क पर चलाए गए थे Intel फ्लेक्स और आर्क जीपीयू, और चालू Intel FP32 परिशुद्धता पर Xeon CPU (के साथ half=False तर्क)।
नोट
नीचे दिए गए बेंचमार्किंग परिणाम संदर्भ के लिए हैं और सिस्टम के सटीक हार्डवेयर और सॉफ़्टवेयर कॉन्फ़िगरेशन के आधार पर भिन्न हो सकते हैं, साथ ही बेंचमार्क चलाए जाने के समय सिस्टम के वर्तमान कार्यभार के आधार पर भी भिन्न हो सकते हैं।
सभी बेंचमार्क के साथ चलते हैं openvino Python पैकेज संस्करण 2023.0.1.
Intel झुकाना GPU
इंटेल® डाटा सेंटर GPU फ्लेक्स सीरीज एक बहुमुखी और मजबूत समाधान है जिसे बुद्धिमान दृश्य क्लाउड के लिए डिज़ाइन किया गया है। यहन GPU मीडिया स्ट्रीमिंग, क्लाउड गेमिंग, एआई विजुअल अनुमान और वर्चुअल डेस्कटॉप इन्फ्रास्ट्रक्चर वर्कलोड सहित वर्कलोड की एक विस्तृत श्रृंखला का समर्थन करता है। यह AV1 एन्कोड के लिए अपने खुले आर्किटेक्चर और अंतर्निहित समर्थन के लिए खड़ा है, जो उच्च-प्रदर्शन, क्रॉस-आर्किटेक्चर अनुप्रयोगों के लिए मानक-आधारित सॉफ़्टवेयर स्टैक प्रदान करता है। फ्लेक्स श्रृंखला GPU घनत्व और गुणवत्ता के लिए अनुकूलित है, उच्च विश्वसनीयता, उपलब्धता और मापनीयता प्रदान करता है।
नीचे दिए गए बेंचमार्क इंटेल® डेटा सेंटर पर चलते हैं GPU FP170 परिशुद्धता पर फ्लेक्स 32।
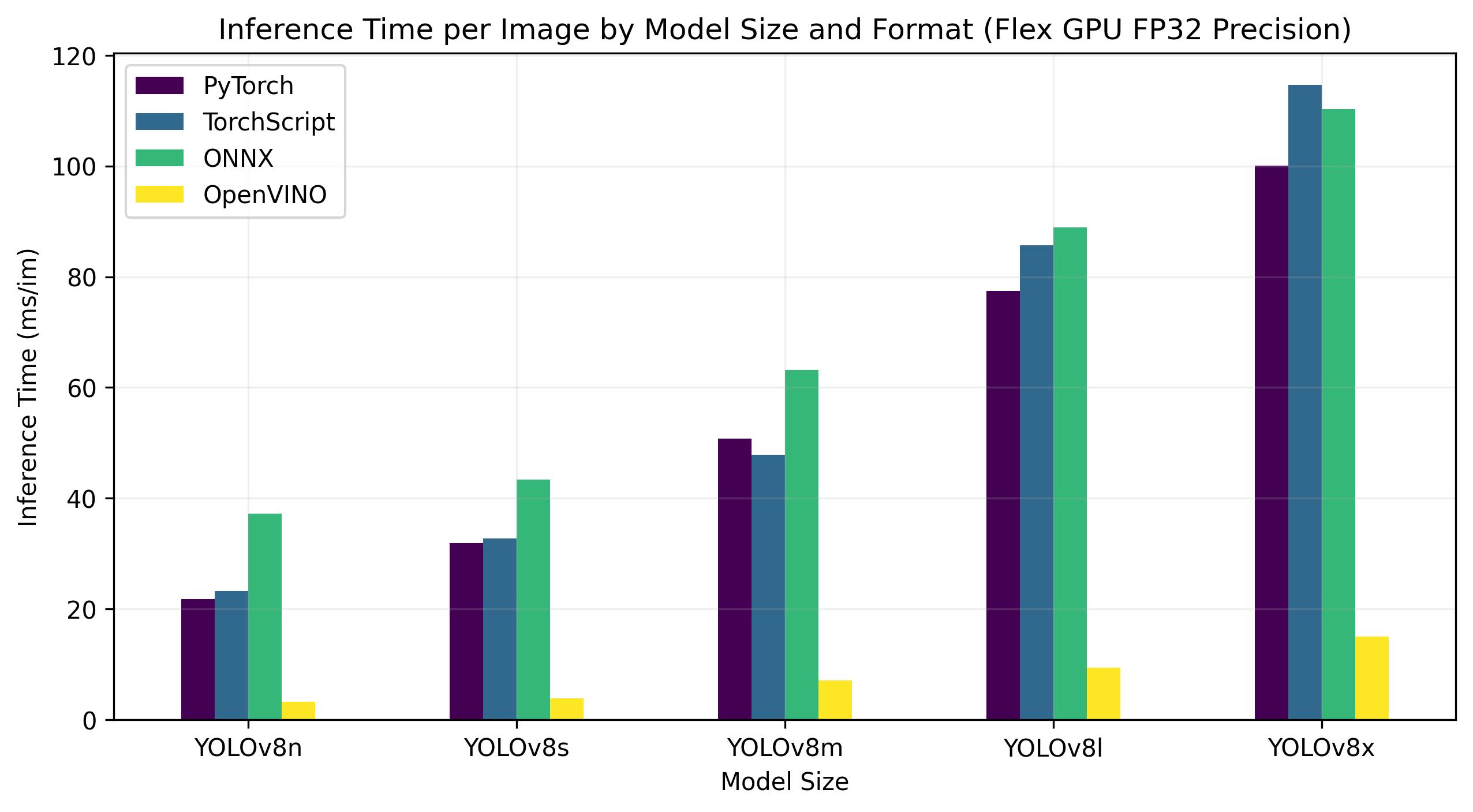
| को गढ़ना | प्रारूप | ओहदा | आकार (MB) | एमएपी 50-95 (बी) | अनुमान समय (ms/im) |
|---|---|---|---|---|---|
| YOLOv8n | PyTorch | ✅ | 6.2 | 0.3709 | 21.79 |
| YOLOv8n | TorchScript | ✅ | 12.4 | 0.3704 | 23.24 |
| YOLOv8n | ONNX | ✅ | 12.2 | 0.3704 | 37.22 |
| YOLOv8n | OpenVINO | ✅ | 12.3 | 0.3703 | 3.29 |
| YOLOv8s | PyTorch | ✅ | 21.5 | 0.4471 | 31.89 |
| YOLOv8s | TorchScript | ✅ | 42.9 | 0.4472 | 32.71 |
| YOLOv8s | ONNX | ✅ | 42.8 | 0.4472 | 43.42 |
| YOLOv8s | OpenVINO | ✅ | 42.9 | 0.4470 | 3.92 |
| YOLOv8m | PyTorch | ✅ | 49.7 | 0.5013 | 50.75 |
| YOLOv8m | TorchScript | ✅ | 99.2 | 0.4999 | 47.90 |
| YOLOv8m | ONNX | ✅ | 99.0 | 0.4999 | 63.16 |
| YOLOv8m | OpenVINO | ✅ | 49.8 | 0.4997 | 7.11 |
| YOLOv8l | PyTorch | ✅ | 83.7 | 0.5293 | 77.45 |
| YOLOv8l | TorchScript | ✅ | 167.2 | 0.5268 | 85.71 |
| YOLOv8l | ONNX | ✅ | 166.8 | 0.5268 | 88.94 |
| YOLOv8l | OpenVINO | ✅ | 167.0 | 0.5264 | 9.37 |
| YOLOv8x | PyTorch | ✅ | 130.5 | 0.5404 | 100.09 |
| YOLOv8x | TorchScript | ✅ | 260.7 | 0.5371 | 114.64 |
| YOLOv8x | ONNX | ✅ | 260.4 | 0.5371 | 110.32 |
| YOLOv8x | OpenVINO | ✅ | 260.6 | 0.5367 | 15.02 |
यह तालिका पांच अलग-अलग मॉडलों (YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, YOLOv8x) चार अलग-अलग स्वरूपों में (PyTorch, TorchScript, ONNX, OpenVINO), हमें प्रत्येक संयोजन के लिए स्थिति, आकार, mAP50-95 (B) मीट्रिक और अनुमान समय प्रदान करता है।
Intel वृत्तांश GPU
इंटेल® आर्क™ प्रतिनिधित्व करता है Intelसमर्पित में प्रवेश GPU बाज़ार। आर्क™ श्रृंखला, अग्रणी के साथ प्रतिस्पर्धा करने के लिए डिज़ाइन की गई GPU एएमडी जैसे निर्माता और Nvidia, लैपटॉप और डेस्कटॉप दोनों बाजारों को पूरा करता है। श्रृंखला में लैपटॉप जैसे कॉम्पैक्ट उपकरणों के लिए मोबाइल संस्करण और डेस्कटॉप कंप्यूटर के लिए बड़े, अधिक शक्तिशाली संस्करण शामिल हैं।
आर्क™ श्रृंखला को तीन श्रेणियों में विभाजित किया गया है: आर्क™ 3, आर्क™ 5 और आर्क™ 7, प्रत्येक संख्या प्रदर्शन स्तर को दर्शाती है। प्रत्येक श्रेणी में कई मॉडल शामिल हैं, और में 'एम' GPU मॉडल नाम एक मोबाइल, एकीकृत संस्करण को दर्शाता है।
शुरुआती समीक्षाओं ने आर्क™ श्रृंखला, विशेष रूप से एकीकृत ए 770 एम की प्रशंसा की है GPU, इसके प्रभावशाली ग्राफिक्स प्रदर्शन के लिए। आर्क™ श्रृंखला की उपलब्धता क्षेत्र के अनुसार भिन्न होती है, और अतिरिक्त मॉडल जल्द ही जारी होने की उम्मीद है। इंटेल® आर्क™ जीपीयू गेमिंग से लेकर सामग्री निर्माण तक कंप्यूटिंग आवश्यकताओं की एक श्रृंखला के लिए उच्च-प्रदर्शन समाधान प्रदान करते हैं।
नीचे दिए गए बेंचमार्क Intel® Arc 770 पर चलते हैं GPU FP32 परिशुद्धता पर।
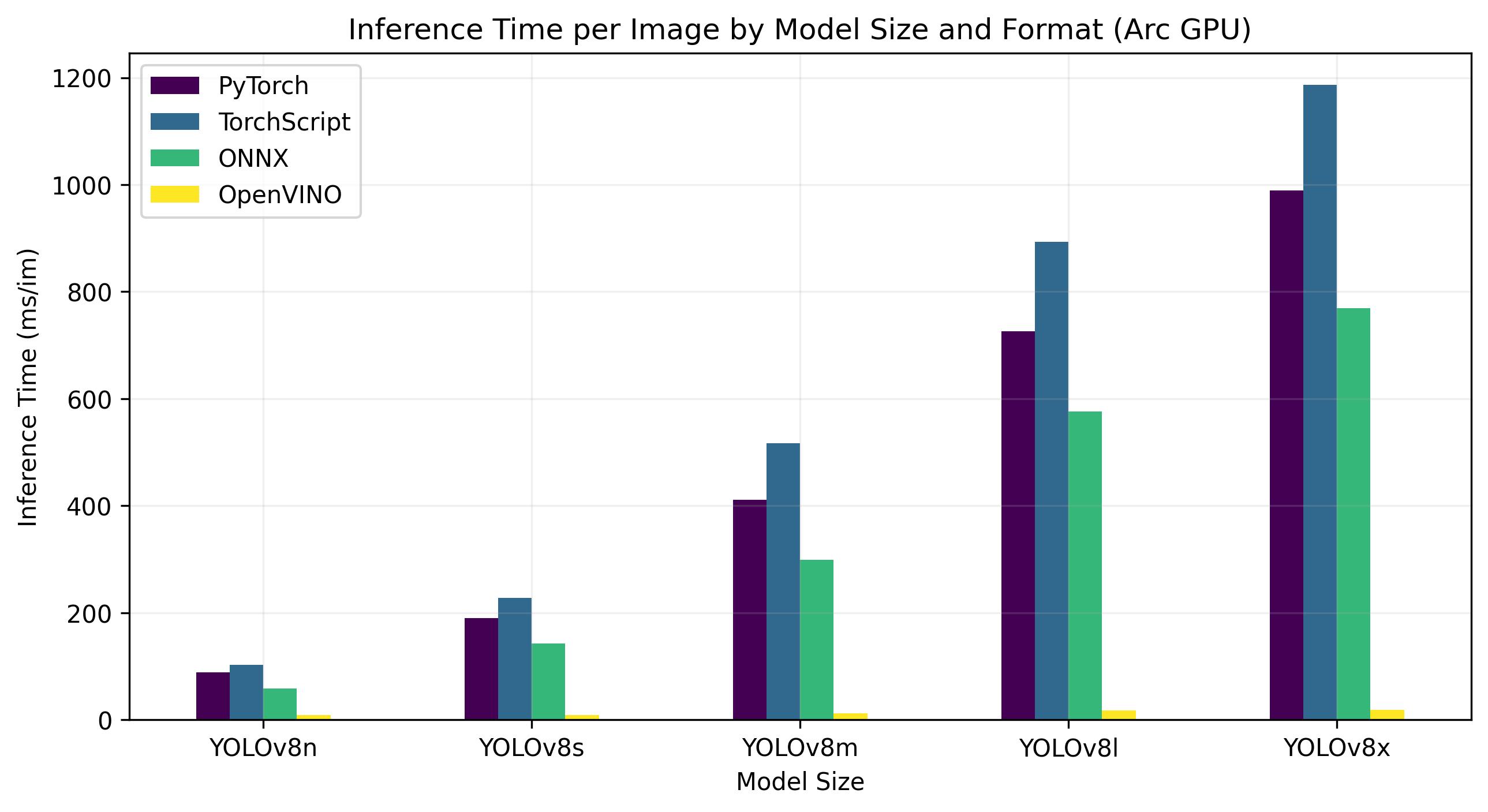
| को गढ़ना | प्रारूप | ओहदा | आकार (MB) | मेट्रिक्स/एमएपी50-95(बी) | अनुमान समय (ms/im) |
|---|---|---|---|---|---|
| YOLOv8n | PyTorch | ✅ | 6.2 | 0.3709 | 88.79 |
| YOLOv8n | TorchScript | ✅ | 12.4 | 0.3704 | 102.66 |
| YOLOv8n | ONNX | ✅ | 12.2 | 0.3704 | 57.98 |
| YOLOv8n | OpenVINO | ✅ | 12.3 | 0.3703 | 8.52 |
| YOLOv8s | PyTorch | ✅ | 21.5 | 0.4471 | 189.83 |
| YOLOv8s | TorchScript | ✅ | 42.9 | 0.4472 | 227.58 |
| YOLOv8s | ONNX | ✅ | 42.7 | 0.4472 | 142.03 |
| YOLOv8s | OpenVINO | ✅ | 42.9 | 0.4469 | 9.19 |
| YOLOv8m | PyTorch | ✅ | 49.7 | 0.5013 | 411.64 |
| YOLOv8m | TorchScript | ✅ | 99.2 | 0.4999 | 517.12 |
| YOLOv8m | ONNX | ✅ | 98.9 | 0.4999 | 298.68 |
| YOLOv8m | OpenVINO | ✅ | 99.1 | 0.4996 | 12.55 |
| YOLOv8l | PyTorch | ✅ | 83.7 | 0.5293 | 725.73 |
| YOLOv8l | TorchScript | ✅ | 167.1 | 0.5268 | 892.83 |
| YOLOv8l | ONNX | ✅ | 166.8 | 0.5268 | 576.11 |
| YOLOv8l | OpenVINO | ✅ | 167.0 | 0.5262 | 17.62 |
| YOLOv8x | PyTorch | ✅ | 130.5 | 0.5404 | 988.92 |
| YOLOv8x | TorchScript | ✅ | 260.7 | 0.5371 | 1186.42 |
| YOLOv8x | ONNX | ✅ | 260.4 | 0.5371 | 768.90 |
| YOLOv8x | OpenVINO | ✅ | 260.6 | 0.5367 | 19 |
Intel जिऑन CPU
इंटेल® Xeon® CPU एक उच्च-प्रदर्शन, सर्वर-ग्रेड प्रोसेसर है जिसे जटिल और मांग वाले वर्कलोड के लिए डिज़ाइन किया गया है। हाई-एंड क्लाउड कंप्यूटिंग और वर्चुअलाइजेशन से लेकर आर्टिफिशियल इंटेलिजेंस और मशीन लर्निंग एप्लिकेशन तक, Xeon® CPU आज के डेटा केंद्रों के लिए आवश्यक शक्ति, विश्वसनीयता और लचीलापन प्रदान करते हैं।
विशेष रूप से, Xeon® CPU उच्च गणना घनत्व और मापनीयता प्रदान करते हैं, जो उन्हें छोटे व्यवसायों और बड़े उद्यमों दोनों के लिए आदर्श बनाते हैं। Intel® Xeon® CPU का चयन करके, संगठन लागत-प्रभावशीलता और परिचालन दक्षता बनाए रखते हुए आत्मविश्वास से अपने सबसे अधिक मांग वाले कंप्यूटिंग कार्यों को संभाल सकते हैं और नवाचार को बढ़ावा दे सकते हैं।
नीचे दिए गए बेंचमार्क 4th Gen Intel® Xeon® स्केलेबल पर चलते हैं CPU FP32 परिशुद्धता पर।
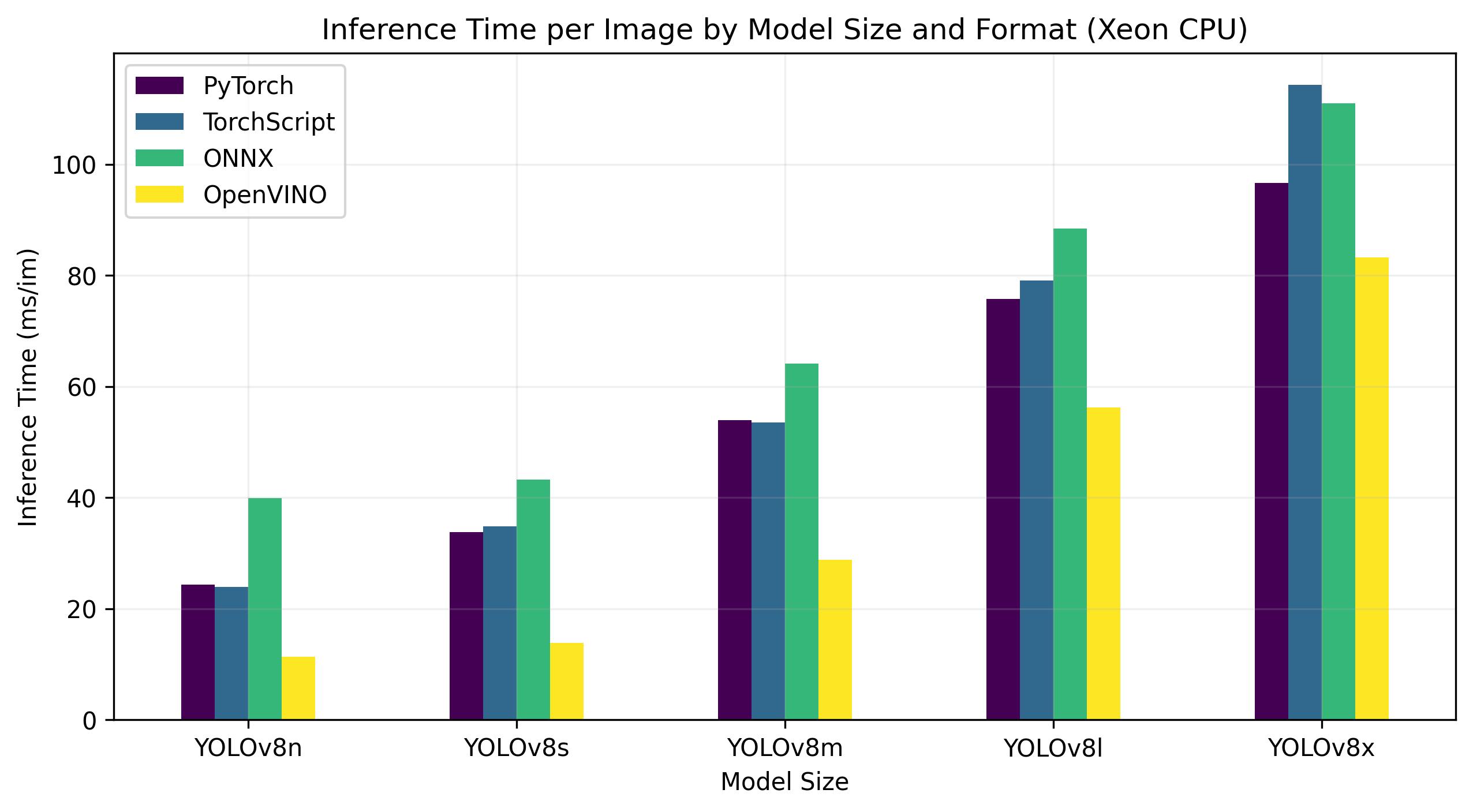
| को गढ़ना | प्रारूप | ओहदा | आकार (MB) | मेट्रिक्स/एमएपी50-95(बी) | अनुमान समय (ms/im) |
|---|---|---|---|---|---|
| YOLOv8n | PyTorch | ✅ | 6.2 | 0.3709 | 24.36 |
| YOLOv8n | TorchScript | ✅ | 12.4 | 0.3704 | 23.93 |
| YOLOv8n | ONNX | ✅ | 12.2 | 0.3704 | 39.86 |
| YOLOv8n | OpenVINO | ✅ | 12.3 | 0.3704 | 11.34 |
| YOLOv8s | PyTorch | ✅ | 21.5 | 0.4471 | 33.77 |
| YOLOv8s | TorchScript | ✅ | 42.9 | 0.4472 | 34.84 |
| YOLOv8s | ONNX | ✅ | 42.8 | 0.4472 | 43.23 |
| YOLOv8s | OpenVINO | ✅ | 42.9 | 0.4471 | 13.86 |
| YOLOv8m | PyTorch | ✅ | 49.7 | 0.5013 | 53.91 |
| YOLOv8m | TorchScript | ✅ | 99.2 | 0.4999 | 53.51 |
| YOLOv8m | ONNX | ✅ | 99.0 | 0.4999 | 64.16 |
| YOLOv8m | OpenVINO | ✅ | 99.1 | 0.4996 | 28.79 |
| YOLOv8l | PyTorch | ✅ | 83.7 | 0.5293 | 75.78 |
| YOLOv8l | TorchScript | ✅ | 167.2 | 0.5268 | 79.13 |
| YOLOv8l | ONNX | ✅ | 166.8 | 0.5268 | 88.45 |
| YOLOv8l | OpenVINO | ✅ | 167.0 | 0.5263 | 56.23 |
| YOLOv8x | PyTorch | ✅ | 130.5 | 0.5404 | 96.60 |
| YOLOv8x | TorchScript | ✅ | 260.7 | 0.5371 | 114.28 |
| YOLOv8x | ONNX | ✅ | 260.4 | 0.5371 | 111.02 |
| YOLOv8x | OpenVINO | ✅ | 260.6 | 0.5371 | 83.28 |
Intel अंतर्भाग CPU
इंटेल® कोर® श्रृंखला द्वारा उच्च प्रदर्शन प्रोसेसर की एक श्रृंखला है Intel. लाइनअप में Core i3 (एंट्री-लेवल), Core i5 (मिड-रेंज), Core i7 (हाई-एंड), और Core i9 (एक्सट्रीम परफॉर्मेंस) शामिल हैं। प्रत्येक श्रृंखला अलग-अलग कंप्यूटिंग आवश्यकताओं और बजट को पूरा करती है, रोजमर्रा के कार्यों से लेकर पेशेवर कार्यभार की मांग तक। प्रत्येक नई पीढ़ी के साथ, प्रदर्शन, ऊर्जा दक्षता और सुविधाओं में सुधार किए जाते हैं।
नीचे दिए गए बेंचमार्क 13th Gen Intel® Core® i7-13700H पर चलते हैं CPU FP32 परिशुद्धता पर।
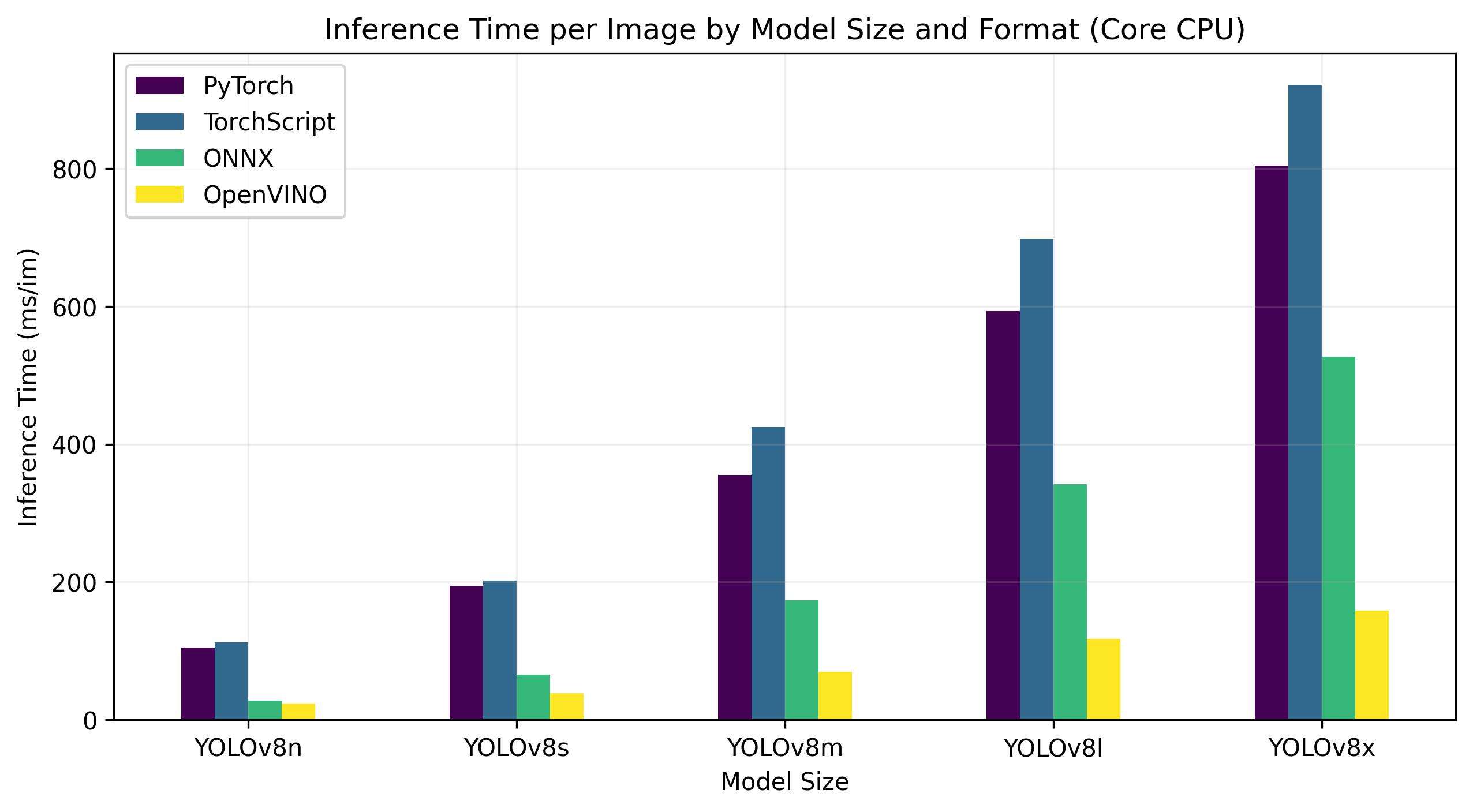
| को गढ़ना | प्रारूप | ओहदा | आकार (MB) | मेट्रिक्स/एमएपी50-95(बी) | अनुमान समय (ms/im) |
|---|---|---|---|---|---|
| YOLOv8n | PyTorch | ✅ | 6.2 | 0.4478 | 104.61 |
| YOLOv8n | TorchScript | ✅ | 12.4 | 0.4525 | 112.39 |
| YOLOv8n | ONNX | ✅ | 12.2 | 0.4525 | 28.02 |
| YOLOv8n | OpenVINO | ✅ | 12.3 | 0.4504 | 23.53 |
| YOLOv8s | PyTorch | ✅ | 21.5 | 0.5885 | 194.83 |
| YOLOv8s | TorchScript | ✅ | 43.0 | 0.5962 | 202.01 |
| YOLOv8s | ONNX | ✅ | 42.8 | 0.5962 | 65.74 |
| YOLOv8s | OpenVINO | ✅ | 42.9 | 0.5966 | 38.66 |
| YOLOv8m | PyTorch | ✅ | 49.7 | 0.6101 | 355.23 |
| YOLOv8m | TorchScript | ✅ | 99.2 | 0.6120 | 424.78 |
| YOLOv8m | ONNX | ✅ | 99.0 | 0.6120 | 173.39 |
| YOLOv8m | OpenVINO | ✅ | 99.1 | 0.6091 | 69.80 |
| YOLOv8l | PyTorch | ✅ | 83.7 | 0.6591 | 593.00 |
| YOLOv8l | TorchScript | ✅ | 167.2 | 0.6580 | 697.54 |
| YOLOv8l | ONNX | ✅ | 166.8 | 0.6580 | 342.15 |
| YOLOv8l | OpenVINO | ✅ | 167.0 | 0.0708 | 117.69 |
| YOLOv8x | PyTorch | ✅ | 130.5 | 0.6651 | 804.65 |
| YOLOv8x | TorchScript | ✅ | 260.8 | 0.6650 | 921.46 |
| YOLOv8x | ONNX | ✅ | 260.4 | 0.6650 | 526.66 |
| YOLOv8x | OpenVINO | ✅ | 260.6 | 0.6619 | 158.73 |
हमारे परिणामों को पुन: पेश करें
प्रजनन करना Ultralytics सभी निर्यात प्रारूपों पर उपरोक्त बेंचमार्क इस कोड को चलाते हैं:
उदाहरण
ध्यान दें कि बेंचमार्किंग परिणाम सिस्टम के सटीक हार्डवेयर और सॉफ़्टवेयर कॉन्फ़िगरेशन के साथ-साथ बेंचमार्क चलाए जाने के समय सिस्टम के वर्तमान कार्यभार के आधार पर भिन्न हो सकते हैं। सबसे विश्वसनीय परिणामों के लिए बड़ी संख्या में छवियों के साथ डेटासेट का उपयोग करें, अर्थात। data='coco128.yaml' (128 val images), ordata='coco.yaml'' (5000 val images).
समाप्ति
बेंचमार्किंग परिणाम स्पष्ट रूप से निर्यात के लाभों को प्रदर्शित करते हैं YOLOv8 के लिए मॉडल OpenVINO प्रारूप। विभिन्न मॉडलों और हार्डवेयर प्लेटफार्मों के पार, OpenVINO प्रारूप तुलनीय सटीकता बनाए रखते हुए अनुमान गति के मामले में अन्य प्रारूपों से लगातार बेहतर प्रदर्शन करता है।
इंटेल® डाटा सेंटर के लिए GPU फ्लेक्स श्रृंखला, OpenVINO प्रारूप मूल की तुलना में लगभग 10 गुना तेज अनुमान गति देने में सक्षम था PyTorch प्रारूप। Xeon पर CPUवही OpenVINO प्रारूप की तुलना में दोगुना तेज था PyTorch प्रारूप। मॉडलों की सटीकता विभिन्न प्रारूपों में लगभग समान रही।
बेंचमार्क की प्रभावशीलता को रेखांकित करते हैं OpenVINO गहन शिक्षण मॉडल को तैनात करने के लिए एक उपकरण के रूप में। मॉडल को में परिवर्तित करके OpenVINO प्रारूप, डेवलपर्स महत्वपूर्ण प्रदर्शन सुधार प्राप्त कर सकते हैं, जिससे इन मॉडलों को वास्तविक दुनिया के अनुप्रयोगों में तैनात करना आसान हो जाता है।
उपयोग करने के बारे में अधिक विस्तृत जानकारी और निर्देशों के लिए OpenVINO, देखें अफ़सर OpenVINO दस्तावेज़ीकरण।
अक्सर पूछे जाने वाले प्रश्न
मैं निर्यात कैसे करूं YOLOv8 करने के लिए मॉडल OpenVINO प्रारूप?
निर्यात YOLOv8 करने के लिए मॉडल OpenVINO प्रारूप में काफी वृद्धि हो सकती है CPU गति और सक्षम करें GPU और एनपीयू त्वरण पर Intel हार्डवेयर। निर्यात करने के लिए, आप या तो उपयोग कर सकते हैं Python नहीं तो CLI जैसा कि नीचे दिखाया गया है:
उदाहरण
from ultralytics import YOLO
# Load a YOLOv8n PyTorch model
model = YOLO("yolov8n.pt")
# Export the model
model.export(format="openvino") # creates 'yolov8n_openvino_model/'
अधिक जानकारी के लिए, निर्यात स्वरूप दस्तावेज़ देखें.
उपयोग करने के क्या लाभ हैं OpenVINO के साथ YOLOv8 मॉडल?
का उपयोग करके Intelका OpenVINO टूलकिट के साथ YOLOv8 मॉडल कई लाभ प्रदान करता है:
- प्रदर्शन: 3x स्पीडअप तक प्राप्त करें CPU अनुमान और उत्तोलन Intel त्वरण के लिए GPU और NPU।
- मॉडल ऑप्टिमाइज़र: जैसे लोकप्रिय ढांचे से मॉडल कन्वर्ट, ऑप्टिमाइज़ और निष्पादित करें PyTorch, TensorFlowऔर ONNX.
- उपयोग में आसानी: उपयोगकर्ताओं को आरंभ करने में मदद करने के लिए 80 से अधिक ट्यूटोरियल नोटबुक उपलब्ध हैं, जिनमें निम्नलिखित भी शामिल हैं YOLOv8.
- विषम निष्पादन: विभिन्न पर मॉडल तैनात करें Intel एक एकीकृत एपीआई के साथ हार्डवेयर।
विस्तृत प्रदर्शन तुलना के लिए, हमारे बेंचमार्क अनुभाग पर जाएं।
मैं एक का उपयोग करके अनुमान कैसे चला सकता हूं YOLOv8 मॉडल को निर्यात किया गया OpenVINO?
निर्यात करने के बाद एक YOLOv8 करने के लिए मॉडल OpenVINO format, आप का उपयोग करके अनुमान चला सकते हैं Python नहीं तो CLI:
उदाहरण
from ultralytics import YOLO
# Load the exported OpenVINO model
ov_model = YOLO("yolov8n_openvino_model/")
# Run inference
results = ov_model("https://ultralytics.com/images/bus.jpg")
अधिक विवरण के लिए हमारे पूर्वानुमान मोड प्रलेखन का संदर्भ लें।
मुझे क्यों चुनना चाहिए Ultralytics YOLOv8 के लिए अन्य मॉडलों पर OpenVINO निर्यातित माल?
Ultralytics YOLOv8 उच्च सटीकता और गति के साथ वास्तविक समय वस्तु का पता लगाने के लिए अनुकूलित है। विशेष रूप से, जब के साथ संयुक्त OpenVINO, YOLOv8 प्रदान करता है:
- 3x तक की स्पीड चालू Intel सीपीयू
- निर्बाध तैनाती चालू Intel जीपीयू और एनपीयू
- विभिन्न निर्यात प्रारूपों में लगातार और तुलनीय सटीकता
गहन प्रदर्शन विश्लेषण के लिए, हमारे विस्तृत की जाँच करें YOLOv8 विभिन्न हार्डवेयर पर बेंचमार्क ।
क्या मैं बेंचमार्क कर सकता हूं YOLOv8 विभिन्न स्वरूपों पर मॉडल जैसे PyTorch, ONNXऔर OpenVINO?
हां, आप बेंचमार्क कर सकते हैं YOLOv8 सहित विभिन्न स्वरूपों में मॉडल PyTorch, TorchScript, ONNXऔर OpenVINO. अपने चुने हुए डेटासेट पर बेंचमार्क चलाने के लिए निम्न कोड स्निपेट का उपयोग करें:
उदाहरण
from ultralytics import YOLO
# Load a YOLOv8n PyTorch model
model = YOLO("yolov8n.pt")
# Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all export formats
results = model.benchmarks(data="coco8.yaml")
विस्तृत बेंचमार्क परिणामों के लिए, हमारे बेंचमार्क अनुभाग और निर्यात प्रारूपों के दस्तावेज़ देखें।
बनाया गया 2023-11-12, अपडेट किया गया 2024-07-05
लेखक: ग्लेन-जोचर (14), आंद्रेई-कोचिन (1), अबिरामी-वीना (1), रिजवान मुनव्वर (1), बुरहान-क्यू (1)