TensorRT के लिए निर्यात करें YOLOv8 मॉडल
उच्च-प्रदर्शन वातावरण में कंप्यूटर विज़न मॉडल को तैनात करने के लिए एक प्रारूप की आवश्यकता हो सकती है जो गति और दक्षता को अधिकतम करता है। यह विशेष रूप से सच है जब आप अपने मॉडल को तैनात कर रहे हैं NVIDIA जीपीयू।
का उपयोग करके TensorRT निर्यात प्रारूप, आप अपना बढ़ा सकते हैं Ultralytics YOLOv8 पर तेज और कुशल अनुमान के लिए मॉडल NVIDIA हार्डवेयर। यह मार्गदर्शिका आपको रूपांतरण प्रक्रिया के लिए पालन करने में आसान कदम देगी और आपको इसका अधिकतम लाभ उठाने में मदद करेगी NVIDIAआपकी गहरी शिक्षण परियोजनाओं में उन्नत तकनीक।
TensorRT
TensorRT, द्वारा विकसित NVIDIA, एक उन्नत सॉफ्टवेयर डेवलपमेंट किट (एसडीके) है जिसे उच्च गति वाले गहन शिक्षण अनुमान के लिए डिज़ाइन किया गया है। यह ऑब्जेक्ट डिटेक्शन जैसे रीयल-टाइम अनुप्रयोगों के लिए अच्छी तरह से अनुकूल है।
यह टूलकिट गहन शिक्षण मॉडल का अनुकूलन करता है NVIDIA GPU और परिणाम तेज और अधिक कुशल संचालन में। TensorRT मॉडल से गुजरना पड़ता है TensorRT अनुकूलन, जिसमें परत संलयन, सटीक अंशांकन (INT8 और FP16), गतिशील जैसी तकनीकें शामिल हैं tensor मेमोरी प्रबंधन, और कर्नेल ऑटो-ट्यूनिंग। गहन शिक्षण मॉडल को में परिवर्तित करना TensorRT प्रारूप डेवलपर्स को क्षमता का एहसास करने की अनुमति देता है NVIDIA जीपीयू पूरी तरह से।
TensorRT विभिन्न मॉडल प्रारूपों के साथ अपनी संगतता के लिए जाना जाता है, जिसमें शामिल हैं TensorFlow, PyTorchऔर ONNX, डेवलपर्स को विभिन्न रूपरेखाओं से मॉडल को एकीकृत और अनुकूलित करने के लिए एक लचीला समाधान प्रदान करना। यह बहुमुखी प्रतिभा विविध हार्डवेयर और सॉफ्टवेयर वातावरण में कुशल मॉडल परिनियोजन को सक्षम बनाती है।
की मुख्य विशेषताएं TensorRT मॉडल
TensorRT मॉडल कई प्रमुख विशेषताओं की पेशकश करते हैं जो उच्च गति वाले गहन शिक्षण अनुमान में उनकी दक्षता और प्रभावशीलता में योगदान करते हैं:
-
सटीक अंशांकन: TensorRT सटीक अंशांकन का समर्थन करता है, जिससे मॉडल को विशिष्ट सटीकता आवश्यकताओं के लिए ठीक-ठीक ट्यून किया जा सकता है। इसमें INT8 और FP16 जैसे कम सटीक प्रारूपों के लिए समर्थन शामिल है, जो स्वीकार्य सटीकता स्तरों को बनाए रखते हुए अनुमान गति को और बढ़ा सकता है।
-
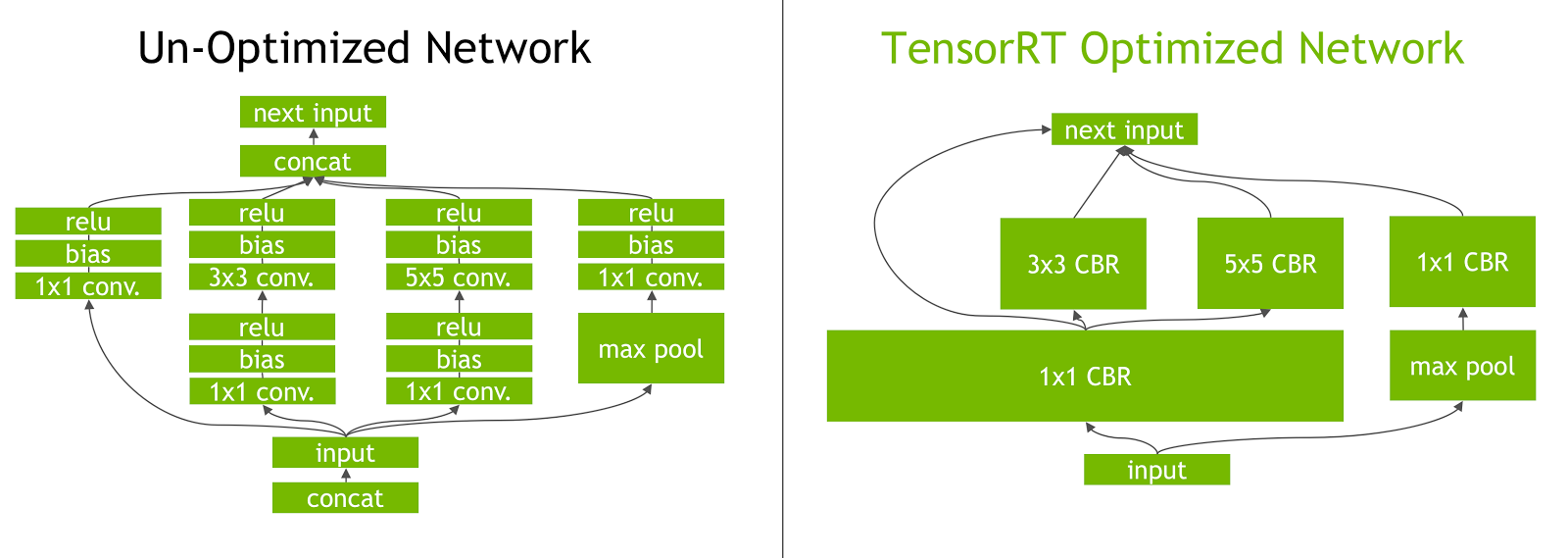
लेयर फ्यूजन: TensorRT अनुकूलन प्रक्रिया में परत संलयन शामिल है, जहां एक तंत्रिका नेटवर्क की कई परतों को एक ही ऑपरेशन में जोड़ा जाता है। यह कम्प्यूटेशनल ओवरहेड को कम करता है और मेमोरी एक्सेस और कम्प्यूटेशन को कम करके अनुमान की गति में सुधार करता है।
-
गतिशील Tensor स्मृति प्रबंधन: TensorRT कुशलता से प्रबंधन करता है tensor अनुमान के दौरान मेमोरी उपयोग, मेमोरी ओवरहेड को कम करना और मेमोरी आवंटन का अनुकूलन करना। इसका परिणाम अधिक कुशल होता है GPU स्मृति उपयोग।
-
स्वचालित कर्नेल ट्यूनिंग: TensorRT सबसे अनुकूलित का चयन करने के लिए स्वचालित कर्नेल ट्यूनिंग लागू करता है GPU मॉडल की प्रत्येक परत के लिए कर्नेल। यह अनुकूली दृष्टिकोण सुनिश्चित करता है कि मॉडल का पूरा लाभ उठाए GPUकी कम्प्यूटेशनल शक्ति।
में परिनियोजन विकल्प TensorRT
इससे पहले कि हम निर्यात के लिए कोड देखें YOLOv8 करने के लिए मॉडल TensorRT प्रारूप, आइए समझते हैं कि कहां TensorRT मॉडल आमतौर पर उपयोग किए जाते हैं।
TensorRT कई परिनियोजन विकल्प प्रदान करता है, और प्रत्येक विकल्प एकीकरण में आसानी, प्रदर्शन अनुकूलन और लचीलेपन को अलग-अलग तरीके से संतुलित करता है:
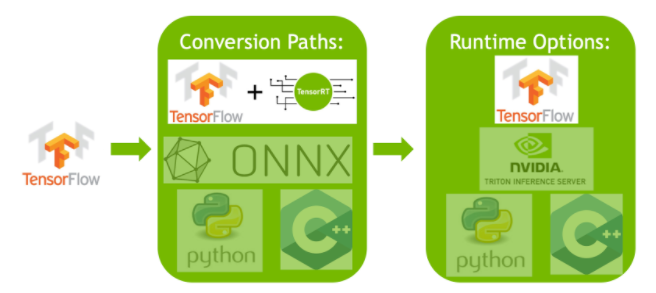
- भीतर परिनियोजन TensorFlow: यह विधि एकीकृत करती है TensorRT में TensorFlow, अनुकूलित मॉडल को एक परिचित में चलाने की अनुमति देता है TensorFlow पर्यावरण। यह समर्थित और असमर्थित परतों के मिश्रण वाले मॉडल के लिए उपयोगी है, जैसा कि TF-TRT इन कुशलता से संभाल सकते हैं.
-
स्टैंडअलोन TensorRT रनटाइम एपीआई: दानेदार नियंत्रण प्रदान करता है, प्रदर्शन-महत्वपूर्ण अनुप्रयोगों के लिए आदर्श है। यह अधिक जटिल है लेकिन असमर्थित ऑपरेटरों के कस्टम कार्यान्वयन की अनुमति देता है।
-
NVIDIA Triton अनुमान सर्वर: एक विकल्प जो विभिन्न ढांचे से मॉडल का समर्थन करता है। क्लाउड या एज अनुमान के लिए विशेष रूप से अनुकूल, यह समवर्ती मॉडल निष्पादन और मॉडल विश्लेषण जैसी सुविधाएँ प्रदान करता है।
निर्यात YOLOv8 करने के लिए मॉडल TensorRT
आप निष्पादन दक्षता में सुधार कर सकते हैं और परिवर्तित करके प्रदर्शन को अनुकूलित कर सकते हैं YOLOv8 करने के लिए मॉडल TensorRT प्रारूप।
संस्थापन
आवश्यक पैकेज स्थापित करने के लिए, चलाएं:
स्थापना प्रक्रिया से संबंधित विस्तृत निर्देशों और सर्वोत्तम प्रथाओं के लिए, हमारी जाँच करें YOLOv8 इंस्टालेशन गाइड। के लिए आवश्यक पैकेज स्थापित करते समय YOLOv8, अगर आपको कोई कठिनाई आती है, तो समाधान और सुझावों के लिए हमारी सामान्य समस्याएं मार्गदर्शिका देखें.
उपयोग
उपयोग निर्देशों में गोता लगाने से पहले, की सीमा की जांच करना सुनिश्चित करें YOLOv8 द्वारा पेश किए गए मॉडल Ultralytics. इससे आपको अपनी परियोजना आवश्यकताओं के लिए सबसे उपयुक्त मॉडल चुनने में मदद मिलेगी।
उपयोग
from ultralytics import YOLO
# Load the YOLOv8 model
model = YOLO("yolov8n.pt")
# Export the model to TensorRT format
model.export(format="engine") # creates 'yolov8n.engine'
# Load the exported TensorRT model
tensorrt_model = YOLO("yolov8n.engine")
# Run inference
results = tensorrt_model("https://ultralytics.com/images/bus.jpg")
निर्यात प्रक्रिया के बारे में अधिक जानकारी के लिए, पर जाएँ Ultralytics निर्यात पर प्रलेखन पृष्ठ।
निर्यात TensorRT INT8 परिमाणीकरण के साथ
निर्यात Ultralytics YOLO का उपयोग कर मॉडल TensorRT INT8 के साथ परिशुद्धता पोस्ट-ट्रेनिंग परिमाणीकरण (PTQ) निष्पादित करती है। TensorRT पीटीक्यू के लिए अंशांकन का उपयोग करता है, जो प्रत्येक सक्रियण के भीतर सक्रियण के वितरण को मापता है tensor के रूप में YOLO मॉडल प्रतिनिधि इनपुट डेटा पर अनुमान संसाधित करता है, और फिर प्रत्येक के लिए स्केल मानों का अनुमान लगाने के लिए उस वितरण का उपयोग करता है tensor. प्रत्येक सक्रियण tensor यही है, परिमाणीकरण के लिए एक उम्मीदवार के पास एक संबद्ध पैमाना है जो एक अंशांकन प्रक्रिया द्वारा घटाया जाता है।
अंतर्निहित रूप से मात्रात्मक नेटवर्क को संसाधित करते समय TensorRT परत निष्पादन समय को अनुकूलित करने के लिए अवसरवादी रूप से INT8 का उपयोग करता है। यदि एक परत INT8 में तेजी से चलती है और उसके डेटा इनपुट और आउटपुट पर परिमाणीकरण पैमाने को सौंपा गया है, तो INT8 परिशुद्धता वाला कर्नेल उस परत को सौंपा गया है, अन्यथा TensorRT कर्नेल के लिए FP32 या FP16 की सटीकता का चयन करता है, जो उस परत के लिए तेजी से निष्पादन समय में परिणाम देता है।
नोक
यह सुनिश्चित करना महत्वपूर्ण है कि वही उपकरण जो TensorRT परिनियोजन के लिए मॉडल भार का उपयोग INT8 परिशुद्धता के साथ निर्यात करने के लिए किया जाता है, क्योंकि अंशांकन परिणाम सभी उपकरणों में भिन्न हो सकते हैं।
INT8 निर्यात कॉन्फ़िगर करना
उपयोग करते समय प्रदान किए गए तर्क निर्यातित माल एक के लिए Ultralytics YOLO मॉडल होगा अत्यधिक निर्यात किए गए मॉडल के प्रदर्शन को प्रभावित करते हैं। उन्हें उपलब्ध डिवाइस संसाधनों के आधार पर भी चुनना होगा, हालांकि डिफ़ॉल्ट तर्क चाहिए अधिकांश के लिए काम एम्पीयर (या नया) NVIDIA असतत GPU. उपयोग किया जाने वाला अंशांकन एल्गोरिथ्म है "ENTROPY_CALIBRATION_2" और आप उपलब्ध विकल्पों के बारे में अधिक विवरण पढ़ सकते हैं में TensorRT डेवलपर गाइड. Ultralytics परीक्षणों में पाया गया कि "ENTROPY_CALIBRATION_2" सबसे अच्छा विकल्प था और निर्यात इस एल्गोरिथ्म का उपयोग करने के लिए तय कर रहे हैं.
-
workspace: मॉडल भार को परिवर्तित करते समय डिवाइस मेमोरी आवंटन के आकार (जीआईबी में) को नियंत्रित करता है।-
समायोजित करें
workspaceआपकी अंशांकन आवश्यकताओं और संसाधन उपलब्धता के अनुसार मूल्य। जबकि एक बड़ाworkspaceअंशांकन समय बढ़ा सकता है, यह अनुमति देता है TensorRT अनुकूलन रणनीति की एक विस्तृत श्रृंखला का पता लगाने के लिए, संभावित रूप से मॉडल प्रदर्शन और सटीकता को बढ़ाना। इसके विपरीत, एक छोटाworkspaceअंशांकन समय को कम कर सकते हैं लेकिन अनुकूलन रणनीतियों को सीमित कर सकते हैं, मात्रात्मक मॉडल की गुणवत्ता को प्रभावित कर सकते हैं। -
डिफ़ॉल्ट है
workspace=4(GiB), अंशांकन क्रैश होने पर इस मान को बढ़ाने की आवश्यकता हो सकती है (बिना चेतावनी के बाहर निकलता है)। -
TensorRT रिपोर्ट करेंगे
UNSUPPORTED_STATEनिर्यात के दौरान यदि के लिए मूल्यworkspaceडिवाइस के लिए उपलब्ध मेमोरी से बड़ा है, जिसका अर्थ हैworkspaceकम किया जाना चाहिए। -
अगर
workspaceअधिकतम मान पर सेट है और अंशांकन विफल रहता है/क्रैश होता है, के लिए मानों को कम करने पर विचार करेंimgszऔरbatchस्मृति आवश्यकताओं को कम करने के लिए। -
याद रखें कि INT8 के लिए अंशांकन प्रत्येक डिवाइस के लिए विशिष्ट है, एक "उच्च अंत" उधार लेना GPU अंशांकन के लिए, खराब प्रदर्शन में परिणाम हो सकता है जब अनुमान किसी अन्य डिवाइस पर चलाया जाता है।
-
-
batch: अधिकतम बैच-आकार जिसका उपयोग अनुमान के लिए किया जाएगा। अनुमान के दौरान छोटे बैचों का उपयोग किया जा सकता है, लेकिन अनुमान निर्दिष्ट बैचों से बड़े बैचों को स्वीकार नहीं करेगा।
नोट
अंशांकन के दौरान, दो बार batch प्रदान किए गए आकार का उपयोग किया जाएगा। छोटे बैचों का उपयोग करने से अंशांकन के दौरान गलत स्केलिंग हो सकती है। ऐसा इसलिए है क्योंकि प्रक्रिया उसके द्वारा देखे जाने वाले डेटा के आधार पर समायोजित होती है। छोटे बैच मूल्यों की पूरी श्रृंखला पर कब्जा नहीं कर सकते हैं, जिससे अंतिम अंशांकन के साथ समस्याएं हो सकती हैं, इसलिए batch आकार स्वचालित रूप से दोगुना हो जाता है। यदि कोई बैच आकार निर्दिष्ट नहीं है batch=1, अंशांकन पर चलाया जाएगा batch=1 * 2 अंशांकन स्केलिंग त्रुटियों को कम करने के लिए।
द्वारा प्रयोग NVIDIA उन्हें कम से कम 500 अंशांकन छवियों का उपयोग करने की सिफारिश करने के लिए प्रेरित किया जो आपके मॉडल के लिए डेटा के प्रतिनिधि हैं, INT8 परिमाणीकरण अंशांकन के साथ। यह एक दिशानिर्देश है और एक नहीं कठिन आवश्यकता, और आपको अपने डेटासेट के लिए अच्छा प्रदर्शन करने के लिए आवश्यक चीज़ों के साथ प्रयोग करने की आवश्यकता होगी। अंशांकन डेटा INT8 अंशांकन के साथ के लिए आवश्यक है के बाद से TensorRT, का उपयोग करना सुनिश्चित करें data तर्क जब int8=True के लिए TensorRT और उपयोग करें data="my_dataset.yaml", जो से छवियों का उपयोग करेगा मान्यता के साथ जांचने के लिए। जब कोई मान के लिए पारित नहीं किया जाता है data को निर्यात के साथ TensorRT INT8 परिमाणीकरण के साथ, डिफ़ॉल्ट में से एक का उपयोग करना होगा मॉडल कार्य के आधार पर "छोटा" उदाहरण डेटासेट एक त्रुटि फेंकने के बजाय।
उदाहरण
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
model.export(
format="engine",
dynamic=True, # (1)!
batch=8, # (2)!
workspace=4, # (3)!
int8=True,
data="coco.yaml", # (4)!
)
# Load the exported TensorRT INT8 model
model = YOLO("yolov8n.engine", task="detect")
# Run inference
result = model.predict("https://ultralytics.com/images/bus.jpg")
- गतिशील अक्षों के साथ निर्यात करता है, यह निर्यात करते समय डिफ़ॉल्ट रूप से सक्षम हो जाएगा
int8=Trueयहां तक कि जब स्पष्ट रूप से सेट नहीं किया गया हो। देखना निर्यात तर्क अतिरिक्त जानकारी के लिए। - निर्यात किए गए मॉडल के लिए 8 का अधिकतम बैच आकार सेट करता है, जो इसके साथ कैलिब्रेट करता है
batch = 2 * 8अंशांकन के दौरान स्केलिंग त्रुटियों से बचने के लिए। - रूपांतरण प्रक्रिया के लिए संपूर्ण डिवाइस आवंटित करने के बजाय 4 GiB मेमोरी आवंटित करता है।
- अंशांकन के लिए COCO डेटासेट का उपयोग करता है, विशेष रूप से सत्यापन के लिए उपयोग की जाने वाली छवियां (कुल 5,000)।
# Export a YOLOv8n PyTorch model to TensorRT format with INT8 quantization
yolo export model=yolov8n.pt format=engine batch=8 workspace=4 int8=True data=coco.yaml # creates 'yolov8n.engine''
# Run inference with the exported TensorRT quantized model
yolo predict model=yolov8n.engine source='https://ultralytics.com/images/bus.jpg'
अंशांकन कैश
TensorRT एक अंशांकन उत्पन्न करेगा .cache जिसे उसी डेटा का उपयोग करके भविष्य के मॉडल वजन के निर्यात में तेजी लाने के लिए फिर से उपयोग किया जा सकता है, लेकिन इसके परिणामस्वरूप खराब अंशांकन हो सकता है जब डेटा बहुत अलग होता है या यदि batch मूल्य काफी बदल जाता है। इन परिस्थितियों में, मौजूदा .cache इसका नाम बदला जाना चाहिए और एक अलग निर्देशिका में ले जाया जाना चाहिए या पूरी तरह से हटा दिया जाना चाहिए।
उपयोग करने के लाभ YOLO के साथ TensorRT इंट8
-
मॉडल का आकार कम होना: FP32 से INT8 तक परिमाणीकरण मॉडल के आकार को 4x (डिस्क पर या मेमोरी में) कम कर सकता है, जिससे डाउनलोड समय तेजी से बढ़ सकता है। कम भंडारण आवश्यकताएं, और मॉडल को तैनात करते समय मेमोरी पदचिह्न कम हो जाता है।
-
कम बिजली की खपत: निर्यात किए गए INT8 के लिए कम सटीक संचालन YOLO FP32 मॉडल की तुलना में मॉडल कम बिजली की खपत कर सकते हैं, खासकर बैटरी से चलने वाले उपकरणों के लिए।
-
बेहतर अनुमान गति: TensorRT लक्ष्य हार्डवेयर के लिए मॉडल का अनुकूलन करता है, संभावित रूप से GPU, एम्बेडेड डिवाइस और त्वरक पर तेज अनुमान गति की ओर ले जाता है।
अनुमान गति पर ध्यान दें
निर्यात किए गए मॉडल के साथ पहले कुछ अनुमान कॉल TensorRT INT8 से सामान्य प्रीप्रोसेसिंग, अनुमान और/या पोस्टप्रोसेसिंग समय से अधिक होने की उम्मीद की जा सकती है। बदलते समय भी ऐसा हो सकता है imgsz अनुमान के दौरान, खासकर जब imgsz निर्यात (निर्यात) के दौरान निर्दिष्ट किए गए के समान नहीं है imgsz के रूप में सेट किया गया है TensorRT "इष्टतम" प्रोफ़ाइल)।
उपयोग करने की कमियां YOLO के साथ TensorRT इंट8
-
मूल्यांकन मेट्रिक्स में कमी: कम परिशुद्धता का उपयोग करने का मतलब यह होगा कि
mAP,Precision,Recallया कोई भी मॉडल के प्रदर्शन का मूल्यांकन करने के लिए उपयोग किए जाने वाले अन्य मीट्रिक कुछ हद तक बदतर होने की संभावना है। देखें प्रदर्शन परिणाम अनुभाग में अंतर की तुलना करने के लिएmAP50औरmAP50-95विभिन्न उपकरणों के छोटे नमूने पर INT8 के साथ निर्यात करते समय। -
विकास के समय में वृद्धि: डेटासेट और डिवाइस के लिए INT8 अंशांकन के लिए "इष्टतम" सेटिंग्स ढूँढना परीक्षण की एक महत्वपूर्ण राशि ले सकता है।
-
हार्डवेयर निर्भरता: अंशांकन और प्रदर्शन लाभ अत्यधिक हार्डवेयर निर्भर हो सकते हैं और मॉडल भार कम हस्तांतरणीय हैं।
Ultralytics YOLO TensorRT निर्यात प्रदर्शन
NVIDIA ए100
प्रदर्शन
उबंटू 22.04.3 एलटीएस के साथ परीक्षण किया गया, python 3.10.12, ultralytics==8.2.4, tensorrt==8.6.1.post1
COCO पर प्रशिक्षित इन मॉडलों के साथ उपयोग के उदाहरणों के लिए डिटेक्शन डॉक्स देखें, जिसमें 80 पूर्व-प्रशिक्षित कक्षाएं शामिल हैं।
नोट
के लिए दिखाया गया अनुमान समय mean, min (सबसे तेज़), और max (सबसे धीमा) पूर्व-प्रशिक्षित वजन का उपयोग करके प्रत्येक परीक्षण के लिए yolov8n.engine
| यथार्थता | इवल परीक्षण | औसत (एमएस) |
मिनट | अधिकतम (एमएस) |
मानचित्रवैल 50(ख) |
मानचित्रवैल 50-95 (बी) |
batch |
आकार वाला (पिक्सेल) |
|---|---|---|---|---|---|---|---|
| एफपी32 | भविष्यवाणी करना | 0.52 | 0.51 | 0.56 | 8 | 640 | ||
| एफपी32 | COCOval | 0.52 | 0.52 | 0.37 | 1 | 640 | |
| एफपी16 | भविष्यवाणी करना | 0.34 | 0.34 | 0.41 | 8 | 640 | ||
| एफपी16 | COCOval | 0.33 | 0.52 | 0.37 | 1 | 640 | |
| INT8 | भविष्यवाणी करना | 0.28 | 0.27 | 0.31 | 8 | 640 | ||
| INT8 | COCOval | 0.29 | 0.47 | 0.33 | 1 | 640 |
COCO पर प्रशिक्षित इन मॉडलों के साथ उपयोग के उदाहरणों के लिए सेगमेंटेशन डॉक्स देखें, जिसमें 80 पूर्व-प्रशिक्षित कक्षाएं शामिल हैं।
नोट
के लिए दिखाया गया अनुमान समय mean, min (सबसे तेज़), और max (सबसे धीमा) पूर्व-प्रशिक्षित वजन का उपयोग करके प्रत्येक परीक्षण के लिए yolov8n-seg.engine
| यथार्थता | इवल परीक्षण | औसत (एमएस) |
मिनट | अधिकतम (एमएस) |
मानचित्रवैल 50(ख) |
मानचित्रवैल 50-95 (बी) |
मानचित्रवैल 50 (एम) |
मानचित्रवैल 50-95 (एम) |
batch |
आकार वाला (पिक्सेल) |
|---|---|---|---|---|---|---|---|---|---|
| एफपी32 | भविष्यवाणी करना | 0.62 | 0.61 | 0.68 | 8 | 640 | ||||
| एफपी32 | COCOval | 0.63 | 0.52 | 0.36 | 0.49 | 0.31 | 1 | 640 | |
| एफपी16 | भविष्यवाणी करना | 0.40 | 0.39 | 0.44 | 8 | 640 | ||||
| एफपी16 | COCOval | 0.43 | 0.52 | 0.36 | 0.49 | 0.30 | 1 | 640 | |
| INT8 | भविष्यवाणी करना | 0.34 | 0.33 | 0.37 | 8 | 640 | ||||
| INT8 | COCOval | 0.36 | 0.46 | 0.32 | 0.43 | 0.27 | 1 | 640 |
इमेजनेट पर प्रशिक्षित इन मॉडलों के साथ उपयोग के उदाहरणों के लिए वर्गीकरण डॉक्स देखें, जिसमें 1000 पूर्व-प्रशिक्षित कक्षाएं शामिल हैं।
नोट
के लिए दिखाया गया अनुमान समय mean, min (सबसे तेज़), और max (सबसे धीमा) पूर्व-प्रशिक्षित वजन का उपयोग करके प्रत्येक परीक्षण के लिए yolov8n-cls.engine
| यथार्थता | इवल परीक्षण | औसत (एमएस) |
मिनट | अधिकतम (एमएस) |
शीर्ष-1 | शीर्ष-5 | batch |
आकार वाला (पिक्सेल) |
|---|---|---|---|---|---|---|---|
| एफपी32 | भविष्यवाणी करना | 0.26 | 0.25 | 0.28 | 8 | 640 | ||
| एफपी32 | इमेजनेटवैल | 0.26 | 0.35 | 0.61 | 1 | 640 | |
| एफपी16 | भविष्यवाणी करना | 0.18 | 0.17 | 0.19 | 8 | 640 | ||
| एफपी16 | इमेजनेटवैल | 0.18 | 0.35 | 0.61 | 1 | 640 | |
| INT8 | भविष्यवाणी करना | 0.16 | 0.15 | 0.57 | 8 | 640 | ||
| INT8 | इमेजनेटवैल | 0.15 | 0.32 | 0.59 | 1 | 640 |
COCO पर प्रशिक्षित इन मॉडलों के साथ उपयोग के उदाहरणों के लिए पोज़ एस्टीमेशन डॉक्स देखें, जिसमें 1 पूर्व-प्रशिक्षित वर्ग, "व्यक्ति" शामिल हैं।
नोट
के लिए दिखाया गया अनुमान समय mean, min (सबसे तेज़), और max (सबसे धीमा) पूर्व-प्रशिक्षित वजन का उपयोग करके प्रत्येक परीक्षण के लिए yolov8n-pose.engine
| यथार्थता | इवल परीक्षण | औसत (एमएस) |
मिनट | अधिकतम (एमएस) |
मानचित्रवैल 50(ख) |
मानचित्रवैल 50-95 (बी) |
मानचित्रवैल 50(पी) |
मानचित्रवैल 50-95 (पी) |
batch |
आकार वाला (पिक्सेल) |
|---|---|---|---|---|---|---|---|---|---|
| एफपी32 | भविष्यवाणी करना | 0.54 | 0.53 | 0.58 | 8 | 640 | ||||
| एफपी32 | COCOval | 0.55 | 0.91 | 0.69 | 0.80 | 0.51 | 1 | 640 | |
| एफपी16 | भविष्यवाणी करना | 0.37 | 0.35 | 0.41 | 8 | 640 | ||||
| एफपी16 | COCOval | 0.36 | 0.91 | 0.69 | 0.80 | 0.51 | 1 | 640 | |
| INT8 | भविष्यवाणी करना | 0.29 | 0.28 | 0.33 | 8 | 640 | ||||
| INT8 | COCOval | 0.30 | 0.90 | 0.68 | 0.78 | 0.47 | 1 | 640 |
DOTAv1 पर प्रशिक्षित इन मॉडलों के साथ उपयोग के उदाहरणों के लिए ओरिएंटेड डिटेक्शन डॉक्स देखें, जिसमें 15 पूर्व-प्रशिक्षित कक्षाएं शामिल हैं।
नोट
के लिए दिखाया गया अनुमान समय mean, min (सबसे तेज़), और max (सबसे धीमा) पूर्व-प्रशिक्षित वजन का उपयोग करके प्रत्येक परीक्षण के लिए yolov8n-obb.engine
| यथार्थता | इवल परीक्षण | औसत (एमएस) |
मिनट | अधिकतम (एमएस) |
मानचित्रवैल 50(ख) |
मानचित्रवैल 50-95 (बी) |
batch |
आकार वाला (पिक्सेल) |
|---|---|---|---|---|---|---|---|
| एफपी32 | भविष्यवाणी करना | 0.52 | 0.51 | 0.59 | 8 | 640 | ||
| एफपी32 | DOTAv1val | 0.76 | 0.50 | 0.36 | 1 | 640 | |
| एफपी16 | भविष्यवाणी करना | 0.34 | 0.33 | 0.42 | 8 | 640 | ||
| एफपी16 | DOTAv1val | 0.59 | 0.50 | 0.36 | 1 | 640 | |
| INT8 | भविष्यवाणी करना | 0.29 | 0.28 | 0.33 | 8 | 640 | ||
| INT8 | DOTAv1val | 0.32 | 0.45 | 0.32 | 1 | 640 |
उपभोक्ता GPU
डिटेक्शन परफॉर्मेंस (COCO)
विंडोज 10.0.19045 के साथ परीक्षण किया गया, python 3.10.9, ultralytics==8.2.4, tensorrt==10.0.0b6
नोट
के लिए दिखाया गया अनुमान समय mean, min (सबसे तेज़), और max (सबसे धीमा) पूर्व-प्रशिक्षित वजन का उपयोग करके प्रत्येक परीक्षण के लिए yolov8n.engine
| यथार्थता | इवल परीक्षण | औसत (एमएस) |
मिनट | अधिकतम (एमएस) |
मानचित्रवैल 50(ख) |
मानचित्रवैल 50-95 (बी) |
batch |
आकार वाला (पिक्सेल) |
|---|---|---|---|---|---|---|---|
| एफपी32 | भविष्यवाणी करना | 1.06 | 0.75 | 1.88 | 8 | 640 | ||
| एफपी32 | COCOval | 1.37 | 0.52 | 0.37 | 1 | 640 | |
| एफपी16 | भविष्यवाणी करना | 0.62 | 0.75 | 1.13 | 8 | 640 | ||
| एफपी16 | COCOval | 0.85 | 0.52 | 0.37 | 1 | 640 | |
| INT8 | भविष्यवाणी करना | 0.52 | 0.38 | 1.00 | 8 | 640 | ||
| INT8 | COCOval | 0.74 | 0.47 | 0.33 | 1 | 640 |
विंडोज 10.0.22631 के साथ परीक्षण किया गया, python 3.11.9, ultralytics==8.2.4, tensorrt==10.0.1
नोट
के लिए दिखाया गया अनुमान समय mean, min (सबसे तेज़), और max (सबसे धीमा) पूर्व-प्रशिक्षित वजन का उपयोग करके प्रत्येक परीक्षण के लिए yolov8n.engine
| यथार्थता | इवल परीक्षण | औसत (एमएस) |
मिनट | अधिकतम (एमएस) |
मानचित्रवैल 50(ख) |
मानचित्रवैल 50-95 (बी) |
batch |
आकार वाला (पिक्सेल) |
|---|---|---|---|---|---|---|---|
| एफपी32 | भविष्यवाणी करना | 1.76 | 1.69 | 1.87 | 8 | 640 | ||
| एफपी32 | COCOval | 1.94 | 0.52 | 0.37 | 1 | 640 | |
| एफपी16 | भविष्यवाणी करना | 0.86 | 0.75 | 1.00 | 8 | 640 | ||
| एफपी16 | COCOval | 1.43 | 0.52 | 0.37 | 1 | 640 | |
| INT8 | भविष्यवाणी करना | 0.80 | 0.75 | 1.00 | 8 | 640 | ||
| INT8 | COCOval | 1.35 | 0.47 | 0.33 | 1 | 640 |
पॉप के साथ परीक्षण किया गया!_OS 22.04 एलटीएस, python 3.10.12, ultralytics==8.2.4, tensorrt==8.6.1.post1
नोट
के लिए दिखाया गया अनुमान समय mean, min (सबसे तेज़), और max (सबसे धीमा) पूर्व-प्रशिक्षित वजन का उपयोग करके प्रत्येक परीक्षण के लिए yolov8n.engine
| यथार्थता | इवल परीक्षण | औसत (एमएस) |
मिनट | अधिकतम (एमएस) |
मानचित्रवैल 50(ख) |
मानचित्रवैल 50-95 (बी) |
batch |
आकार वाला (पिक्सेल) |
|---|---|---|---|---|---|---|---|
| एफपी32 | भविष्यवाणी करना | 2.84 | 2.84 | 2.85 | 8 | 640 | ||
| एफपी32 | COCOval | 2.94 | 0.52 | 0.37 | 1 | 640 | |
| एफपी16 | भविष्यवाणी करना | 1.09 | 1.09 | 1.10 | 8 | 640 | ||
| एफपी16 | COCOval | 1.20 | 0.52 | 0.37 | 1 | 640 | |
| INT8 | भविष्यवाणी करना | 0.75 | 0.74 | 0.75 | 8 | 640 | ||
| INT8 | COCOval | 0.76 | 0.47 | 0.33 | 1 | 640 |
एम्बेडेड डिवाइस
डिटेक्शन परफॉर्मेंस (COCO)
JetPack 6.0 (L4T 36.3) Ubuntu 22.04.4 LTS के साथ परीक्षण किया गया, python 3.10.12, ultralytics==8.2.16, tensorrt==10.0.1
नोट
के लिए दिखाया गया अनुमान समय mean, min (सबसे तेज़), और max (सबसे धीमा) पूर्व-प्रशिक्षित वजन का उपयोग करके प्रत्येक परीक्षण के लिए yolov8n.engine
| यथार्थता | इवल परीक्षण | औसत (एमएस) |
मिनट | अधिकतम (एमएस) |
मानचित्रवैल 50(ख) |
मानचित्रवैल 50-95 (बी) |
batch |
आकार वाला (पिक्सेल) |
|---|---|---|---|---|---|---|---|
| एफपी32 | भविष्यवाणी करना | 6.11 | 6.10 | 6.29 | 8 | 640 | ||
| एफपी32 | COCOval | 6.17 | 0.52 | 0.37 | 1 | 640 | |
| एफपी16 | भविष्यवाणी करना | 3.18 | 3.18 | 3.20 | 8 | 640 | ||
| एफपी16 | COCOval | 3.19 | 0.52 | 0.37 | 1 | 640 | |
| INT8 | भविष्यवाणी करना | 2.30 | 2.29 | 2.35 | 8 | 640 | ||
| INT8 | COCOval | 2.32 | 0.46 | 0.32 | 1 | 640 |
सूचना-विषयक
हमारे देखें क्विकस्टार्ट गाइड ऑन NVIDIA जेटसन के साथ Ultralytics YOLO सेटअप और कॉन्फ़िगरेशन के बारे में अधिक जानने के लिए।
मूल्यांकन के तरीके
इन मॉडलों के निर्यात और परीक्षण के तरीके के बारे में जानकारी के लिए नीचे दिए गए अनुभागों को विस्तृत करें.
निर्यात कॉन्फ़िगरेशन
निर्यात कॉन्फ़िगरेशन तर्कों से संबंधित विवरण के लिए निर्यात मोड देखें.
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
# TensorRT FP32
out = model.export(format="engine", imgsz=640, dynamic=True, verbose=False, batch=8, workspace=2)
# TensorRT FP16
out = model.export(format="engine", imgsz=640, dynamic=True, verbose=False, batch=8, workspace=2, half=True)
# TensorRT INT8 with calibration `data` (i.e. COCO, ImageNet, or DOTAv1 for appropriate model task)
out = model.export(
format="engine", imgsz=640, dynamic=True, verbose=False, batch=8, workspace=2, int8=True, data="coco8.yaml"
)
लूप की भविष्यवाणी करें
अतिरिक्त जानकारी के लिए भविष्यवाणी मोड देखें।
सत्यापन कॉन्फ़िगरेशन
देखना val मोड समूह सत्यापन कॉन्फ़िगरेशन तर्कों के बारे में अधिक जानने के लिए.
निर्यात की गई तैनाती YOLOv8 TensorRT मॉडल
सफलतापूर्वक अपने निर्यात करने के बाद Ultralytics YOLOv8 करने के लिए मॉडल TensorRT प्रारूप, अब आप उन्हें तैनात करने के लिए तैयार हैं। अपने परिनियोजन पर गहन निर्देशों के लिए TensorRT विभिन्न सेटिंग्स में मॉडल, निम्नलिखित संसाधनों पर एक नज़र डालें:
-
तैनात Ultralytics एक के साथ Triton सर्वर: उपयोग करने के तरीके पर हमारा गाइड NVIDIAका Triton अनुमान (पूर्व में TensorRT अनुमान) सर्वर विशेष रूप से के साथ उपयोग के लिए Ultralytics YOLO मॉडल।
-
के साथ डीप न्यूरल नेटवर्क तैनात करना NVIDIA TensorRT: यह लेख बताता है कि इसका उपयोग कैसे करें NVIDIA TensorRT पर गहरे तंत्रिका नेटवर्क तैनात करने के लिए GPU-आधारित तैनाती प्लेटफार्मों को कुशलता से।
-
के लिए एंड-टू-एंड एआई NVIDIA-आधारित पीसी: NVIDIA TensorRT परिनियोजन: यह ब्लॉग पोस्ट इसके उपयोग की व्याख्या करता है NVIDIA TensorRT एआई मॉडल को अनुकूलित करने और तैनात करने के लिए NVIDIA-आधारित पीसी।
-
GitHub रिपोजिटरी के लिए NVIDIA TensorRT:: यह आधिकारिक GitHub रिपॉजिटरी है जिसमें स्रोत कोड और प्रलेखन शामिल है NVIDIA TensorRT.
सारांश
इस गाइड में, हमने परिवर्तित करने पर ध्यान केंद्रित किया Ultralytics YOLOv8 करने के लिए मॉडल NVIDIAका TensorRT मॉडल प्रारूप। यह रूपांतरण चरण दक्षता और गति में सुधार के लिए महत्वपूर्ण है YOLOv8 मॉडल, उन्हें विविध परिनियोजन वातावरण के लिए अधिक प्रभावी और उपयुक्त बनाते हैं।
उपयोग विवरण के बारे में अधिक जानकारी के लिए, पर एक नज़र डालें TensorRT आधिकारिक दस्तावेज।
यदि आप अतिरिक्त के बारे में उत्सुक हैं Ultralytics YOLOv8 एकीकरण, हमारा एकीकरण गाइड पृष्ठ सूचनात्मक संसाधनों और अंतर्दृष्टि का व्यापक चयन प्रदान करता है।
अक्सर पूछे जाने वाले प्रश्न
मैं कैसे रूपांतरित करूं YOLOv8 करने के लिए मॉडल TensorRT प्रारूप?
अपना रूपांतरण करने के लिए Ultralytics YOLOv8 करने के लिए मॉडल TensorRT अनुकूलित के लिए प्रारूप NVIDIA GPU निष्कर्ष, इन चरणों का पालन करें:
-
आवश्यक पैकेज स्थापित करें:
-
अपना निर्यात करें YOLOv8 नमूना:
अधिक जानकारी के लिए, पर जाएँ YOLOv8 स्थापना गाइड और निर्यात प्रलेखन।
उपयोग करने के क्या लाभ हैं TensorRT के लिए YOLOv8 मॉडल?
का उपयोग करके TensorRT अनुकूलित करने के लिए YOLOv8 मॉडल कई लाभ प्रदान करता है:
- तेज़ अनुमान गति: TensorRT मॉडल परतों का अनुकूलन करता है और सटीकता का त्याग किए बिना अनुमान को तेज करने के लिए सटीक अंशांकन (INT8 और FP16) का उपयोग करता है।
- स्मृति क्षमता: TensorRT प्रबंधन tensor गतिशील रूप से स्मृति, ओवरहेड को कम करना और सुधार करना GPU स्मृति उपयोग।
- परत संलयन: कम्प्यूटेशनल जटिलता को कम करते हुए, एकल संचालन में कई परतों को जोड़ती है।
- कर्नेल ऑटो-ट्यूनिंग: स्वचालित रूप से अनुकूलित का चयन करता है GPU प्रत्येक मॉडल परत के लिए गुठली, अधिकतम प्रदर्शन सुनिश्चित करना।
अधिक जानकारी के लिए, की विस्तृत विशेषताओं का अन्वेषण करें TensorRT यहाँ और हमारे पढ़ें TensorRT अवलोकन अनुभाग।
क्या मैं INT8 परिमाणीकरण का उपयोग कर सकता हूं TensorRT के लिए YOLOv8 मॉडल?
हाँ, आप निर्यात कर सकते हैं YOLOv8 का उपयोग कर मॉडल TensorRT INT8 परिमाणीकरण के साथ। इस प्रक्रिया में प्रशिक्षण के बाद परिमाणीकरण (PTQ) और अंशांकन शामिल हैं:
-
INT8 के साथ निर्यात करें:
-
रन अनुमान:
अधिक जानकारी के लिए, देखें निर्यात TensorRT INT8 परिमाणीकरण अनुभाग के साथ।
मैं कैसे तैनात करूं YOLOv8 TensorRT एक पर मॉडल NVIDIA Triton अनुमान सर्वर?
परिनियोजन YOLOv8 TensorRT एक पर मॉडल NVIDIA Triton निम्न संसाधनों का उपयोग करके अनुमान सर्वर किया जा सकता है:
- तैनात Ultralytics YOLOv8 के साथ Triton सर्वर: स्थापित करने और उपयोग करने पर चरण-दर-चरण मार्गदर्शन Triton अनुमान सर्वर।
- NVIDIA Triton अनुमान सर्वर दस्तावेज़ीकरण: आधिकारिक NVIDIA विस्तृत परिनियोजन विकल्पों और कॉन्फ़िगरेशन के लिए दस्तावेज़ीकरण।
ये मार्गदर्शिकाएँ आपको एकीकृत करने में मदद करेंगी YOLOv8 विभिन्न तैनाती वातावरण में कुशलतापूर्वक मॉडल।
प्रदर्शन में क्या सुधार देखे गए हैं YOLOv8 मॉडल निर्यात किए गए TensorRT?
के साथ प्रदर्शन में सुधार TensorRT उपयोग किए गए हार्डवेयर के आधार पर भिन्न हो सकते हैं। यहां कुछ विशिष्ट बेंचमार्क दिए गए हैं:
-
NVIDIA ए100:
- एफपी32 निष्कर्ष: ~ 0.52 एमएस / छवि
- एफपी16 अनुमान: ~ 0.34 एमएस / छवि
- आईएनटी8 अनुमान: ~ 0.28 एमएस / छवि
- INT8 परिशुद्धता के साथ एमएपी में मामूली कमी, लेकिन गति में महत्वपूर्ण सुधार।
-
उपभोक्ता GPU (जैसे, RTX 3080):
- एफपी32 अनुमान: ~ 1.06 एमएस / छवि
- एफपी16 अनुमान: ~ 0.62 एमएस / छवि
- आईएनटी8 निष्कर्ष: ~ 0.52 एमएस / छवि
विभिन्न हार्डवेयर कॉन्फ़िगरेशन के लिए विस्तृत प्रदर्शन बेंचमार्क प्रदर्शन अनुभाग में पाए जा सकते हैं।
में अधिक व्यापक अंतर्दृष्टि के लिए TensorRT प्रदर्शन, देखें Ultralytics दस्तावेज़ीकरण और हमारी प्रदर्शन विश्लेषण रिपोर्ट।
बनाया गया 2024-01-28, अद्यतन किया गया 2024-07-10
लेखक: ग्लेन-जोचर (10), महत्वाकांक्षी-ऑक्टोपस (1), लक्षांथाद (1), इवोरझू331 (1), बुरहान-क्यू (2), अबिरामी-वीना (1)