COCO डेटासेट
COCO (कॉमन ऑब्जेक्ट्स इन कॉन्टेक्स्ट) डेटासेट एक बड़े पैमाने पर ऑब्जेक्ट डिटेक्शन, सेगमेंटेशन और कैप्शनिंग डेटासेट है। यह विभिन्न प्रकार की वस्तु श्रेणियों पर अनुसंधान को प्रोत्साहित करने के लिए डिज़ाइन किया गया है और आमतौर पर कंप्यूटर दृष्टि मॉडल को बेंचमार्किंग के लिए उपयोग किया जाता है। यह ऑब्जेक्ट डिटेक्शन, सेगमेंटेशन और पोज़ एस्टीमेशन कार्यों पर काम करने वाले शोधकर्ताओं और डेवलपर्स के लिए एक आवश्यक डेटासेट है।
सतर्कता: Ultralytics COCO डेटासेट अवलोकन
COCO पूर्व-प्रशिक्षित मॉडल
| को गढ़ना | आकार वाला (पिक्सेल) |
मानचित्रवैल 50-95 |
गति CPU ONNX (एमएस) |
गति ए100 TensorRT (एमएस) |
परम (एम) |
फ्लॉप (बी) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
प्रमुख विशेषताऐं
- COCO में 330K छवियां हैं, जिसमें 200K छवियां ऑब्जेक्ट डिटेक्शन, सेगमेंटेशन और कैप्शनिंग कार्यों के लिए एनोटेशन हैं।
- डेटासेट में 80 ऑब्जेक्ट श्रेणियां शामिल हैं, जिनमें कार, साइकिल और जानवरों जैसी सामान्य वस्तुओं के साथ-साथ छतरियां, हैंडबैग और खेल उपकरण जैसी अधिक विशिष्ट श्रेणियां शामिल हैं।
- एनोटेशन में ऑब्जेक्ट बाउंडिंग बॉक्स, सेगमेंटेशन मास्क और प्रत्येक छवि के लिए कैप्शन शामिल हैं।
- COCO ऑब्जेक्ट डिटेक्शन के लिए मीन एवरेज प्रिसिजन (mAP) जैसे मानकीकृत मूल्यांकन मेट्रिक्स प्रदान करता है, और सेगमेंटेशन कार्यों के लिए मीन एवरेज रिकॉल (mAR), जिससे यह मॉडल प्रदर्शन की तुलना करने के लिए उपयुक्त हो जाता है।
डेटासेट संरचना
COCO डेटासेट को तीन सबसेट में विभाजित किया गया है:
- ट्रेन2017: इस सबसेट में ऑब्जेक्ट डिटेक्शन, सेगमेंटेशन और कैप्शनिंग मॉडल के प्रशिक्षण के लिए 118K छवियां हैं।
- Val2017: इस सबसेट में मॉडल प्रशिक्षण के दौरान सत्यापन उद्देश्यों के लिए उपयोग की जाने वाली 5K छवियां हैं।
- Test2017: इस सबसेट में प्रशिक्षित मॉडलों के परीक्षण और बेंचमार्किंग के लिए उपयोग की जाने वाली 20K छवियां शामिल हैं। इस सबसेट के लिए ग्राउंड ट्रुथ एनोटेशन सार्वजनिक रूप से उपलब्ध नहीं हैं, और परिणाम प्रदर्शन मूल्यांकन के लिए COCO मूल्यांकन सर्वर पर सबमिट किए जाते हैं।
अनुप्रयोगों
COCO डेटासेट का व्यापक रूप से ऑब्जेक्ट डिटेक्शन में गहन शिक्षण मॉडल के प्रशिक्षण और मूल्यांकन के लिए उपयोग किया जाता है (जैसे कि YOLO, तेज़ आर-सीएनएन, और एसएसडी), उदाहरण विभाजन (जैसे मास्क आर-सीएनएन), और कीपॉइंट डिटेक्शन (जैसे ओपनपोज़)। डेटासेट की ऑब्जेक्ट श्रेणियों का विविध सेट, बड़ी संख्या में एनोटेट की गई छवियां और मानकीकृत मूल्यांकन मेट्रिक्स इसे कंप्यूटर दृष्टि शोधकर्ताओं और चिकित्सकों के लिए एक आवश्यक संसाधन बनाते हैं।
डेटासेट YAML
डेटासेट कॉन्फ़िगरेशन को परिभाषित करने के लिए एक YAML (अभी तक एक और मार्कअप भाषा) फ़ाइल का उपयोग किया जाता है। इसमें डेटासेट के पथ, कक्षाओं और अन्य प्रासंगिक जानकारी के बारे में जानकारी होती है। COCO डेटासेट के मामले में, coco.yaml फ़ाइल पर बनाए रखा जाता है https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml.
ultralytics/cfg/datasets/coco.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO 2017 dataset https://cocodataset.org by Microsoft
# Documentation: https://docs.ultralytics.com/datasets/detect/coco/
# Example usage: yolo train data=coco.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco ← downloads here (20.1 GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco # dataset root dir
train: train2017.txt # train images (relative to 'path') 118287 images
val: val2017.txt # val images (relative to 'path') 5000 images
test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush
# Download script/URL (optional)
download: |
from ultralytics.utils.downloads import download
from pathlib import Path
# Download labels
segments = True # segment or box labels
dir = Path(yaml['path']) # dataset root dir
url = 'https://github.com/ultralytics/assets/releases/download/v0.0.0/'
urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels
download(urls, dir=dir.parent)
# Download data
urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
download(urls, dir=dir / 'images', threads=3)
उपयोग
एक प्रशिक्षित करने के लिए YOLOv8n 640 के छवि आकार के साथ 100 युगों के लिए COCO डेटासेट पर मॉडल, आप निम्न कोड स्निपेट का उपयोग कर सकते हैं। उपलब्ध तर्कों की व्यापक सूची के लिए, मॉडल प्रशिक्षण पृष्ठ देखें।
ट्रेन का उदाहरण
नमूना छवियाँ और एनोटेशन
COCO डेटासेट में विभिन्न ऑब्जेक्ट श्रेणियों और जटिल दृश्यों के साथ छवियों का एक विविध सेट होता है। यहां डेटासेट से छवियों के कुछ उदाहरण दिए गए हैं, साथ ही उनके संबंधित एनोटेशन के साथ:
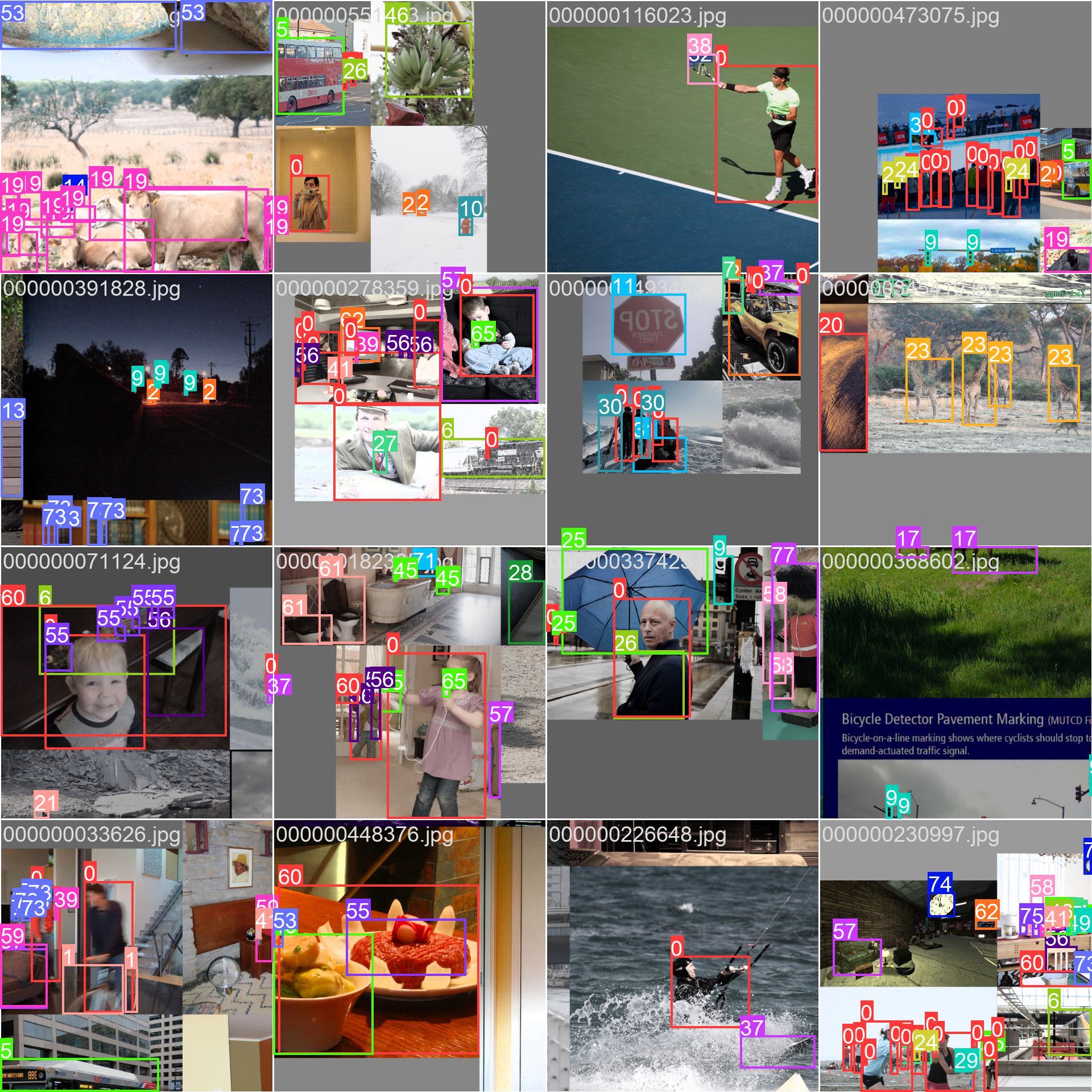
- मोज़ेड छवि: यह छवि मोज़ेक डेटासेट छवियों से बना एक प्रशिक्षण बैच प्रदर्शित करती है। मोज़ेसिंग प्रशिक्षण के दौरान उपयोग की जाने वाली एक तकनीक है जो प्रत्येक प्रशिक्षण बैच के भीतर वस्तुओं और दृश्यों की विविधता को बढ़ाने के लिए कई छवियों को एक ही छवि में जोड़ती है। यह विभिन्न ऑब्जेक्ट आकारों, पहलू अनुपात और संदर्भों को सामान्यीकृत करने की मॉडल की क्षमता को बेहतर बनाने में मदद करता है।
उदाहरण COCO डेटासेट में छवियों की विविधता और जटिलता और प्रशिक्षण प्रक्रिया के दौरान मोज़ेकिंग का उपयोग करने के लाभों को प्रदर्शित करता है।
प्रशंसा पत्र और पावती
यदि आप अपने शोध या विकास कार्य में COCO डेटासेट का उपयोग करते हैं, तो कृपया निम्नलिखित पेपर का हवाला दें:
@misc{lin2015microsoft,
title={Microsoft COCO: Common Objects in Context},
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
year={2015},
eprint={1405.0312},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
हम कंप्यूटर दृष्टि समुदाय के लिए इस मूल्यवान संसाधन को बनाने और बनाए रखने के लिए कोको कंसोर्टियम को स्वीकार करना चाहते हैं। COCO डेटासेट और इसके रचनाकारों के बारे में अधिक जानकारी के लिए, COCO डेटासेट वेबसाइट पर जाएँ।
अक्सर पूछे जाने वाले प्रश्न
COCO डेटासेट क्या है और यह कंप्यूटर विज़न के लिए क्यों महत्वपूर्ण है?
COCO डेटासेट (कॉमन ऑब्जेक्ट्स इन कॉन्टेक्स्ट) एक बड़े पैमाने पर डेटासेट है जिसका उपयोग ऑब्जेक्ट डिटेक्शन, सेगमेंटेशन और कैप्शनिंग के लिए किया जाता है। इसमें 80 ऑब्जेक्ट श्रेणियों के लिए विस्तृत एनोटेशन के साथ 330K छवियां हैं, जो इसे बेंचमार्किंग और कंप्यूटर विज़न मॉडल के प्रशिक्षण के लिए आवश्यक बनाती हैं। शोधकर्ता अपनी विविध श्रेणियों और औसत औसत परिशुद्धता (एमएपी) जैसे मानकीकृत मूल्यांकन मैट्रिक्स के कारण सीओसीओ का उपयोग करते हैं।
मैं कैसे प्रशिक्षित कर सकता हूं YOLO COCO डेटासेट का उपयोग करके मॉडल?
एक को प्रशिक्षित करने के लिए YOLOv8 COCO डेटासेट का उपयोग करने वाला मॉडल, आप निम्न कोड स्निपेट का उपयोग कर सकते हैं:
ट्रेन का उदाहरण
उपलब्ध तर्कों पर अधिक विवरण के लिए प्रशिक्षण पृष्ठ देखें।
COCO डेटासेट की प्रमुख विशेषताएं क्या हैं?
COCO डेटासेट में शामिल हैं:
- 330K छवियों, ऑब्जेक्ट का पता लगाने, विभाजन और कैप्शनिंग के लिए 200K एनोटेट के साथ।
- कारों और जानवरों जैसी सामान्य वस्तुओं से लेकर हैंडबैग और खेल उपकरण जैसे विशिष्ट लोगों तक की 80 ऑब्जेक्ट श्रेणियां।
- ऑब्जेक्ट डिटेक्शन (एमएपी) और सेगमेंटेशन (मतलब औसत रिकॉल, एमएआर) के लिए मानकीकृत मूल्यांकन मेट्रिक्स।
- विभिन्न वस्तु आकारों और संदर्भों में मॉडल सामान्यीकरण को बढ़ाने के लिए प्रशिक्षण बैचों में मोज़ेसिंग तकनीक।
मुझे पूर्व-प्रशिक्षित कहां मिल सकता है YOLOv8 COCO डेटासेट पर प्रशिक्षित मॉडल?
पूर्वप्रशिक्षित YOLOv8 COCO डेटासेट पर मॉडल प्रलेखन में दिए गए लिंक से डाउनलोड किए जा सकते हैं। उदाहरणों में शामिल:
ये मॉडल आकार, एमएपी और अनुमान गति में भिन्न होते हैं, जो विभिन्न प्रदर्शन और संसाधन आवश्यकताओं के लिए विकल्प प्रदान करते हैं।
COCO डेटासेट कैसे संरचित है और मैं इसका उपयोग कैसे करूं?
COCO डेटासेट को तीन सबसेट में विभाजित किया गया है:
- ट्रेन 2017: प्रशिक्षण के लिए 118 हजार छवियां।
- Val2017: प्रशिक्षण के दौरान सत्यापन के लिए 5K छवियां।
- Test2017: प्रशिक्षित मॉडल बेंचमार्किंग के लिए 20K छवियां। परिणाम प्रदर्शन मूल्यांकन के लिए COCO मूल्यांकन सर्वर को प्रस्तुत करने की आवश्यकता है।
डेटासेट की YAML कॉन्फ़िगरेशन फ़ाइल coco.yaml पर उपलब्ध है, जो पथ, वर्ग और डेटासेट विवरण को परिभाषित करती है।
बनाया गया 2023-11-12, अपडेट किया गया 2024-07-04
लेखक: ग्लेन-जोचर (7), रिजवान मुनव्वर (2), लाफिंग-क्यू (1)