COCO Dataset
De COCO (Common Objects in Context) dataset is een grootschalige dataset voor objectdetectie, segmentatie en bijschriften. Het is ontworpen om onderzoek naar een grote verscheidenheid aan objectcategorieën aan te moedigen en wordt vaak gebruikt voor het benchmarken van computervisie modellen. Het is een essentiële dataset voor onderzoekers en ontwikkelaars die werken aan objectdetectie, segmentatie en pose estimation taken.
Kijken: Ultralytics Overzicht COCO-dataset
COCO voorgetrainde modellen
| Model | grootte (pixels) |
mAPval 50-95 |
Snelheid CPU ONNX (ms) |
Snelheid A100 TensorRT (ms) |
params (M) |
FLOP's (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
Belangrijkste kenmerken
- COCO bevat 330K afbeeldingen, met 200K afbeeldingen met annotaties voor objectdetectie, segmentatie en onderschrifttaken.
- De dataset bestaat uit 80 objectcategorieën, waaronder veelvoorkomende objecten zoals auto's, fietsen en dieren, maar ook meer specifieke categorieën zoals paraplu's, handtassen en sportuitrusting.
- Annotaties bevatten objectgrenzen, segmentatiemaskers en bijschriften voor elke afbeelding.
- COCO biedt gestandaardiseerde evaluatiemetrieken zoals gemiddelde precisie (mAP) voor objectdetectie en gemiddelde recall (mAR) voor segmentatietaken, waardoor het geschikt is voor het vergelijken van modelprestaties.
Structuur dataset
De COCO dataset is opgesplitst in drie subsets:
- Train2017: Deze subset bevat 118K afbeeldingen voor het trainen van modellen voor objectdetectie, segmentatie en bijschriften.
- Val2017: Deze subset bevat 5K beelden die tijdens de modeltraining zijn gebruikt voor validatiedoeleinden.
- Test2017: Deze subset bestaat uit 20K afbeeldingen die worden gebruikt voor het testen en benchmarken van de getrainde modellen. De grondwaarheidsannotaties voor deze subset zijn niet openbaar en de resultaten worden ingediend bij de COCO evaluatieserver voor prestatie-evaluatie.
Toepassingen
De COCO dataset wordt veel gebruikt voor het trainen en evalueren van deep learning modellen in objectdetectie (zoals YOLO, Faster R-CNN en SSD), segmentatie van instanties (zoals Mask R-CNN) en sleutelpuntdetectie (zoals OpenPose). De diverse set objectcategorieën, het grote aantal geannoteerde afbeeldingen en de gestandaardiseerde evaluatiemetrieken maken de dataset tot een essentiële bron voor computer vision onderzoekers en praktijkmensen.
Dataset YAML
Een YAML (Yet Another Markup Language) bestand wordt gebruikt om de configuratie van de dataset te definiëren. Het bevat informatie over de paden, klassen en andere relevante informatie van de dataset. In het geval van de COCO dataset is de coco.yaml bestand wordt onderhouden op https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml.
ultralytics/cfg/datasets/coco.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO 2017 dataset https://cocodataset.org by Microsoft
# Documentation: https://docs.ultralytics.com/datasets/detect/coco/
# Example usage: yolo train data=coco.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco ← downloads here (20.1 GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco # dataset root dir
train: train2017.txt # train images (relative to 'path') 118287 images
val: val2017.txt # val images (relative to 'path') 5000 images
test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush
# Download script/URL (optional)
download: |
from ultralytics.utils.downloads import download
from pathlib import Path
# Download labels
segments = True # segment or box labels
dir = Path(yaml['path']) # dataset root dir
url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels
download(urls, dir=dir.parent)
# Download data
urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
download(urls, dir=dir / 'images', threads=3)
Gebruik
Om een YOLOv8n model te trainen op de COCO dataset voor 100 epochs met een afbeeldingsgrootte van 640, kun je de volgende codefragmenten gebruiken. Raadpleeg de pagina Model Training voor een uitgebreide lijst met beschikbare argumenten.
Voorbeeld trein
Voorbeeldafbeeldingen en -annotaties
De COCO dataset bevat een diverse set afbeeldingen met verschillende objectcategorieën en complexe scènes. Hier zijn enkele voorbeelden van afbeeldingen uit de dataset, samen met de bijbehorende annotaties:
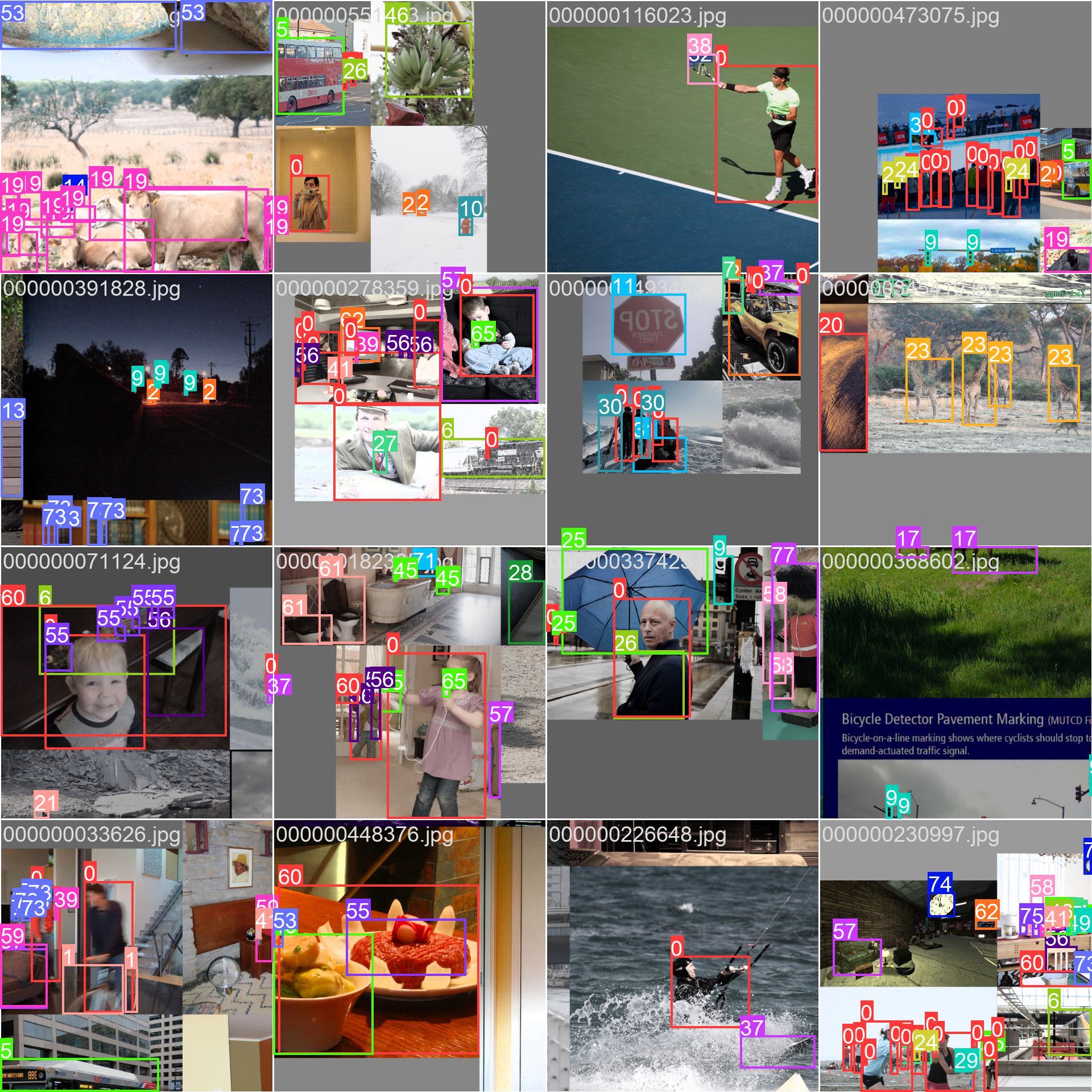
- Gemozaïekte afbeelding: Deze afbeelding toont een trainingsbatch die bestaat uit gemozaïekte afbeeldingen van de dataset. Mozaïeken is een techniek die tijdens het trainen wordt gebruikt om meerdere afbeeldingen te combineren tot één afbeelding om de verscheidenheid aan objecten en scènes binnen elke trainingsbatch te vergroten. Dit helpt het vermogen van het model om te generaliseren naar verschillende objectgroottes, beeldverhoudingen en contexten te verbeteren.
Het voorbeeld toont de verscheidenheid en complexiteit van de afbeeldingen in de COCO dataset en de voordelen van het gebruik van mozaïek tijdens het trainingsproces.
Citaten en erkenningen
Als je de COCO dataset gebruikt in je onderzoek of ontwikkeling, citeer dan het volgende document:
@misc{lin2015microsoft,
title={Microsoft COCO: Common Objects in Context},
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
year={2015},
eprint={1405.0312},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
We willen graag het COCO Consortium bedanken voor het maken en onderhouden van deze waardevolle bron voor de computer vision gemeenschap. Ga voor meer informatie over de COCO dataset en de makers naar de COCO dataset website.
Aangemaakt 2023-11-12, Bijgewerkt 2024-04-17
Auteurs: glenn-jocher (4), RizwanMunawar (2), Laughing-q (1)