Link to this sectionUltralytics YOLO26#
Link to this sectionÜbersicht#
Ultralytics YOLO26 ist eine einheitliche Familie von Echtzeit-Vision-Modellen, die im Ultralytics YOLO26-Paper beschrieben wird. Sie führt natives End-to-End-Inferenz-Verfahren ein, einen leichteren Detektionskopf, ein aktualisiertes Trainingsrezept und aufgabenspezifische Köpfe für Detektion, Segmentierung, Pose-Schätzung, Klassifizierung und orientierte Detektion.
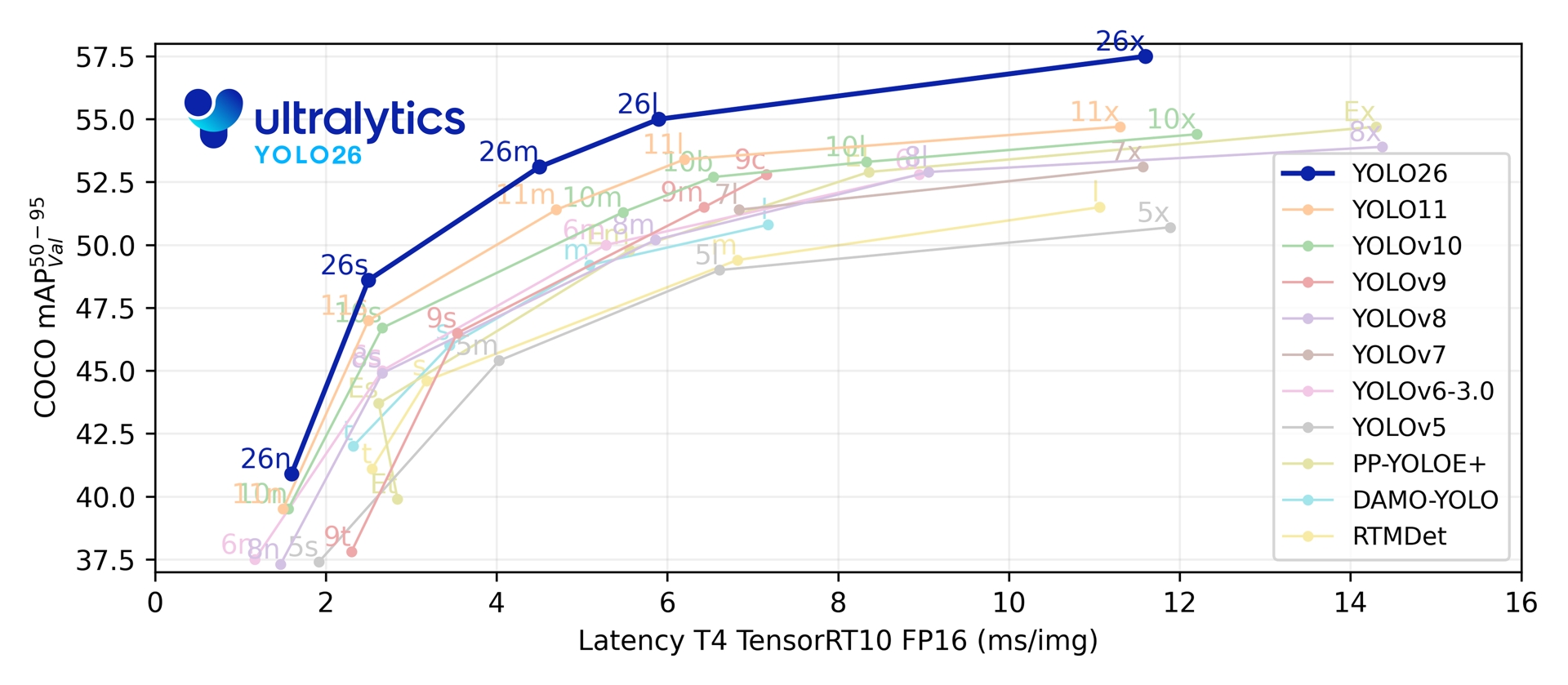
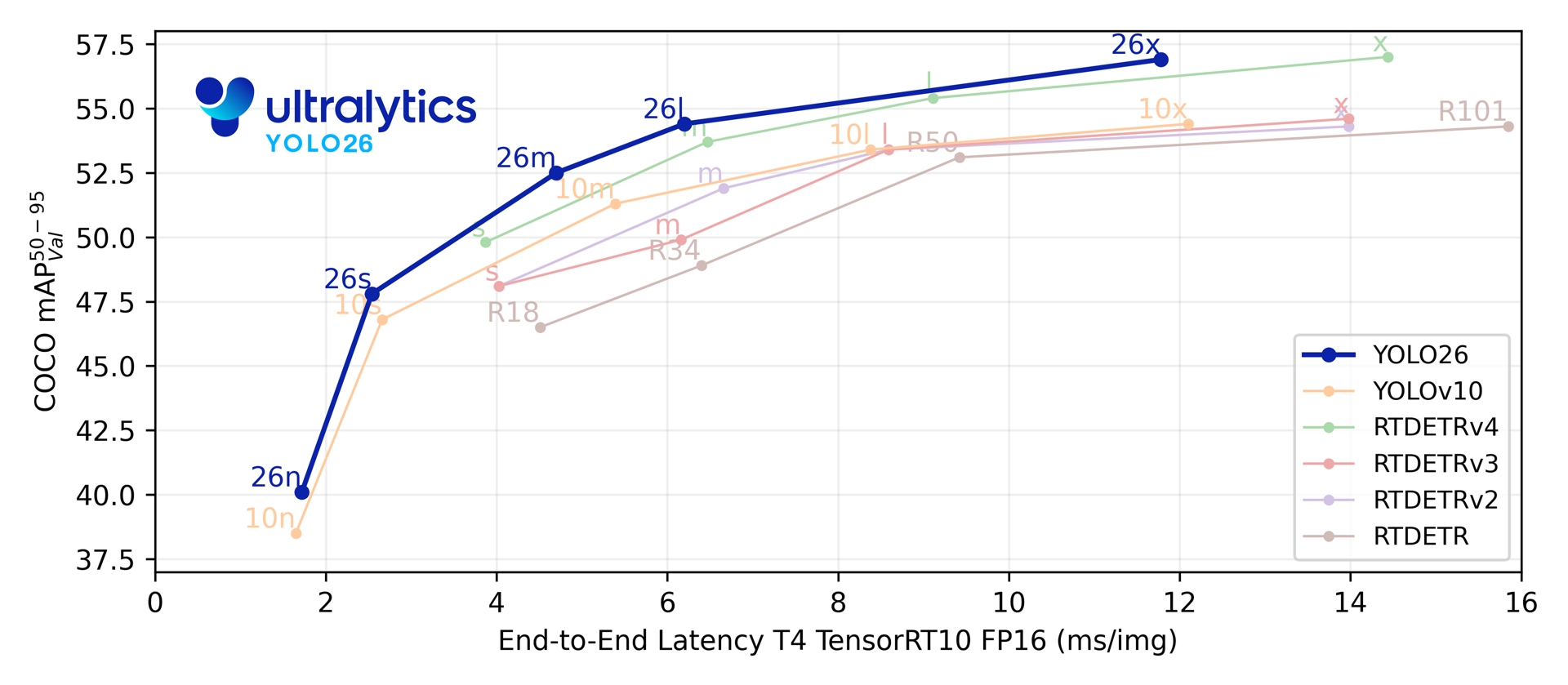
Über die fünf Detektionsskalen hinweg erreicht YOLO26 40,9-57,5 mAP auf COCO bei 1,7-11,8 ms T4 TensorRT-Latenz. Das Paper berichtet zudem von bis zu 43 % schnellerer CPU ONNX-Inferenz für YOLO26n im Vergleich zu YOLO11n auf einer Intel Xeon CPU mit 2,00 GHz.
Entdecke und führe YOLO26-Modelle direkt auf der Ultralytics Platform aus.
Die YOLO26-Modellfamilie ist um vier Designbereiche herum aufgebaut:
- Native End-to-End-Inferenz: Der standardmäßige One-to-One-Detektionskopf erzeugt Vorhersagen ohne Non-Maximum Suppression (NMS), was den Einsatz vereinfacht und die Nachbearbeitung reduziert.
- Leichtere Box-Regression: YOLO26 entfernt den Distribution Focal Loss (DFL), was die Komplexität des Detektionskopfes reduziert und gleichzeitig einen uneingeschränkten Regressionsbereich beibehält.
- Updates zum Trainingsrezept: Die Trainings-Pipeline kombiniert MuSGD, Progressive Loss und STAL, um die Optimierung zu verbessern, die Überwachung auf den Head zur Inferenzzeit zu verlagern und die Abdeckung positiver Labels für kleine Objekte beizubehalten. Die vollständigen Hyperparameter hinter den veröffentlichten Checkpoints sind im YOLO26 Training Recipe guide dokumentiert.
- Aufgabenspezifische Köpfe und Losses: YOLO26 fügt gezielte Designs für Instanz-Segmentierung, Varianten der semantischen Segmentierung, Pose-Schätzung und orientierte Detektion hinzu, während eine einheitliche Modell-Pipeline über Aufgaben hinweg beibehalten wird.
Zusammen verbessern diese Aktualisierungen das Verhältnis zwischen Genauigkeit und Latenz über verschiedene Modellskalen und Einsatzziele hinweg.
Link to this sectionHauptfunktionen#
-
DFL-freie Regression YOLO26 entfernt den Distribution Focal Loss (DFL), reduziert die Komplexität des Detektionskopfes und vereinfacht den Export.
-
End-to-End NMS-freie Inferenz Im Gegensatz zu herkömmlichen Detektoren, die auf NMS als separaten Nachbearbeitungsschritt angewiesen sind, ist YOLO26 standardmäßig nativ End-to-End. Vorhersagen werden direkt generiert, was die Latenz verringert und die Integration in die Produktion vereinfacht.
-
Progressive Loss + STAL Progressive Loss verlagert den Trainingsschwerpunkt auf den Inferenz-Kopf, während STAL die Abdeckung positiver Labels für kleine Objekte verbessert.
-
MuSGD-Optimierer Ein hybrider Optimierer, der SGD mit Muon kombiniert und Optimierungskonzepte aus dem Training großer Sprachmodelle auf Computer Vision anwendet.
-
Effiziente Bereitstellung Der vereinfachte Kopf und der NMS-freie Standardpfad reduzieren den Inferenz-Overhead über Exportziele und Hardwareprofile hinweg, einschließlich der im Paper berichteten CPU ONNX-Geschwindigkeitssteigerung für YOLO26n gegenüber YOLO11n.
-
Verbesserungen bei der Instanz-Segmentierung Führt einen Loss für semantische Segmentierung ein, um die Modellkonvergenz zu verbessern, sowie ein aktualisiertes Proto-Modul, das Informationen über mehrere Skalen hinweg für eine überragende Maskenqualität nutzt. Das Paper berichtet von Zuwächsen gegenüber YOLO11 von bis zu +2,5 Box AP und +3,7 Mask AP bei der COCO-Instanz-Segmentierung.
-
Präzise Pose-Schätzung Integriert Residual Log-Likelihood Estimation (RLE) für eine genauere Lokalisierung von Keypoints und optimiert den Dekodierungsprozess für eine erhöhte Inferenzgeschwindigkeit. Das Paper berichtet von bis zu +7,2 AP gegenüber YOLO11 bei der COCO-Pose-Schätzung.
-
Verfeinerte OBB-Dekodierung Führt einen spezialisierten Winkel-Loss ein, um die Detektionsgenauigkeit für quadratische Objekte zu verbessern, und optimiert die OBB-Dekodierung, um Probleme mit Grenzdiskontinuitäten zu lösen. Das Paper berichtet von bis zu +3,4 mAP gegenüber YOLO11 bei der DOTA-v1.0 orientierten Detektion.
Link to this sectionUnterstützte Aufgaben und Modi#
YOLO26 unterstützt das standardmäßige Ultralytics-Aufgabenset über fünf Modellskalen hinweg:
| Modell | Dateinamen | Aufgabe | Inference | Validation | Training | Exportieren |
|---|---|---|---|---|---|---|
| YOLO26 | yolo26n.pt yolo26s.pt yolo26m.pt yolo26l.pt yolo26x.pt | Detektion | ✅ | ✅ | ✅ | ✅ |
| YOLO26-seg | yolo26n-seg.pt yolo26s-seg.pt yolo26m-seg.pt yolo26l-seg.pt yolo26x-seg.pt | Instance Segmentation | ✅ | ✅ | ✅ | ✅ |
| YOLO26-sem | yolo26n-sem.pt yolo26s-sem.pt yolo26m-sem.pt yolo26l-sem.pt yolo26x-sem.pt | Semantische Segmentierung | ✅ | ✅ | ✅ | ✅ |
| YOLO26-pose | yolo26n-pose.pt yolo26s-pose.pt yolo26m-pose.pt yolo26l-pose.pt yolo26x-pose.pt | Pose/Keypoints | ✅ | ✅ | ✅ | ✅ |
| YOLO26-obb | yolo26n-obb.pt yolo26s-obb.pt yolo26m-obb.pt yolo26l-obb.pt yolo26x-obb.pt | Orientierte Detektion | ✅ | ✅ | ✅ | ✅ |
| YOLO26-cls | yolo26n-cls.pt yolo26s-cls.pt yolo26m-cls.pt yolo26l-cls.pt yolo26x-cls.pt | Klassifizierung | ✅ | ✅ | ✅ | ✅ |
Dieses einheitliche Framework deckt Echtzeit-Detektion, Instanz-Segmentierung, semantische Segmentierung, Klassifizierung, Pose-Schätzung und orientierte Objektdetektion mit Unterstützung für Training, Validierung, Inferenz und Export ab.
yolo26-p2.yaml und yolo26-p6.yaml fügen einen P2- (kleine Objekte) oder P6- (großer Input) Detektionskopf hinzu und werden nur als YAML-Architekturen ausgeliefert. Es werden keine skalierten yolo26*-p2.pt oder yolo26*-p6.pt Gewichte veröffentlicht. Erstelle eine skalierte Konfiguration aus YAML (zum Beispiel YOLO("yolo26n-p6.yaml")) und trainiere oder optimiere diese nach Bedarf.
Link to this sectionLeistungsmetriken#
Siehe Detektions-Dokumentation für Anwendungsbeispiele mit diesen Modellen, die auf COCO trainiert wurden und 80 vortrainierte Klassen enthalten.
| Modell | Größe (Pixel) | mAPval 50-95 | mAPval 50-95(e2e) | Geschwindigkeit CPU ONNX (ms) | Geschwindigkeit T4 TensorRT10 (ms) | Parameter (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO26n | 640 | 40,9 | 40,1 | 38,9 ± 0,7 | 1,7 ± 0,0 | 2,4 | 5,4 |
| YOLO26s | 640 | 48,6 | 47,8 | 87,2 ± 0,9 | 2,5 ± 0,0 | 9,5 | 20,7 |
| YOLO26m | 640 | 53,1 | 52,5 | 220,0 ± 1,4 | 4,7 ± 0,1 | 20,4 | 68,2 |
| YOLO26l | 640 | 55,0 | 54,4 | 286,2 ± 2,0 | 6,2 ± 0,2 | 24,8 | 86,4 |
| YOLO26x | 640 | 57,5 | 56,9 | 525,8 ± 4,0 | 11,8 ± 0,2 | 55,7 | 193,9 |
Params- und FLOPs-Werte beziehen sich auf das fusionierte Modell nach model.fuse(), das Conv- und BatchNorm-Schichten zusammenführt und den zusätzlichen One-to-Many-Erkennungskopf entfernt. Vortrainierte Checkpoints behalten die vollständige Trainingsarchitektur bei und können höhere Werte aufweisen.
Link to this sectionAnwendungsbeispiele#
Dieser Abschnitt enthält einfache YOLO26-Trainings- und Inferenzbeispiele. Für die vollständige Dokumentation zu diesen und anderen Modi, siehe die Dokumentationsseiten Predict, Train, Val und Export.
Beachte, dass sich das Beispiel unten auf YOLO26 Detect-Modelle für Objekterkennung bezieht. Für weitere unterstützte Aufgaben siehe die Dokumentation zu Segment, Semantic Segmentation, Classify, OBB und Pose.
PyTorch vortrainierte *.pt-Modelle sowie Konfigurations-*.yaml-Dateien können an die YOLO()-Klasse übergeben werden, um eine Modellinstanz in Python zu erstellen:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLO26n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")YOLO26-Erkennungsmodelle verwenden eine Dual-Head-Architektur, die Flexibilität für verschiedene Bereitstellungsszenarien bietet:
- One-to-One Head (Standard): Erzeugt End-to-End-Vorhersagen ohne NMS und gibt
(N, 300, 6)mit maximal 300 Erkennungen pro Bild aus. Dieser Kopf ist für schnelle Inferenz und vereinfachte Bereitstellung optimiert. - One-to-Many Head: Erzeugt traditionelle YOLO-Ausgaben, die eine NMS-Nachverarbeitung erfordern, und gibt
(N, nc + 4, 8400)aus, wobeincdie Anzahl der Klassen ist. Dieser Kopf erzielt normalerweise eine etwas höhere Genauigkeit auf Kosten zusätzlicher Verarbeitung.
Du kannst während des Exports, der Vorhersage oder der Validierung zwischen den Köpfen wechseln:
from ultralytics import YOLO
model = YOLO("yolo26n.pt")
# Use one-to-one head (default, no NMS required)
results = model.predict("image.jpg") # inference
metrics = model.val(data="coco.yaml") # validation
model.export(format="onnx") # export
# Use one-to-many head (requires NMS)
results = model.predict("image.jpg", end2end=False) # inference
metrics = model.val(data="coco.yaml", end2end=False) # validation
model.export(format="onnx", end2end=False) # exportDie Wahl hängt von deinen Bereitstellungsanforderungen ab: Verwende den One-to-One-Kopf für maximale Geschwindigkeit und Einfachheit oder den One-to-Many-Kopf, wenn Genauigkeit oberste Priorität hat.
Link to this sectionYOLOE-26: Open-Vocabulary-Erkennung und Segmentierung#
YOLOE-26 erweitert YOLO26 um die Open-Vocabulary-Funktionen der YOLOE-Serie. Es ermöglicht die Echtzeiterkennung und -segmentierung von Open-Set-Objektkategorien mithilfe von Text-Prompts, visuellen Prompts oder einem Prompt-freien Modus.
Durch die Nutzung von YOLO26s NMS-freiem End-to-End-Design bleibt die Open-Vocabulary-Inferenz von YOLOE-26 schnell genug für dynamische Umgebungen, in denen sich Zielkategorien im Laufe der Zeit ändern können. YOLOE-26x erreicht 40,6 AP auf LVIS minival bei Text-Prompting, 38,5 AP bei visueller Eingabeaufforderung und 31,1 AP in der Prompt-freien Non-E2E-Einstellung.
Siehe YOLOE-Dokumentation für Anwendungsbeispiele dieser Modelle, die mit den Datensätzen Objects365v1, GQA und Flickr30k trainiert wurden.
| Modell | Größe (Pixel) | Prompt-Typ | mAPminival 50-95(e2e) | mAPminival 50-95 | mAPr | mAPc | mAPf | Parameter (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOE-26n-seg | 640 | Text/Visuell | 23.7 / 20.9 | 24.7 / 21.9 | 20.5 / 17.6 | 24.1 / 22.3 | 26.1 / 22.4 | 4.8 | 6.0 |
| YOLOE-26s-seg | 640 | Text/Visuell | 29.9 / 27.1 | 30.8 / 28.6 | 23.9 / 25.1 | 29.6 / 27.8 | 33.0 / 29.9 | 13.1 | 21.7 |
| YOLOE-26m-seg | 640 | Text/Visuell | 35.4 / 31.3 | 35.4 / 33.9 | 31.1 / 33.4 | 34.7 / 34.0 | 36.9 / 33.8 | 27.9 | 70.1 |
| YOLOE-26l-seg | 640 | Text/Visuell | 36.8 / 33.7 | 37.8 / 36.3 | 35.1 / 37.6 | 37.6 / 36.2 | 38.5 / 36.1 | 32.3 | 88.3 |
| YOLOE-26x-seg | 640 | Text/Visuell | 39.5 / 36.2 | 40.6 / 38.5 | 37.4 / 35.3 | 40.9 / 38.8 | 41.0 / 38.8 | 69.9 | 196.7 |
Link to this sectionAnwendungsbeispiel#
YOLOE-26 unterstützt sowohl textbasierte als auch visuelle Prompts. Die Verwendung von Prompts ist unkompliziert – übergib sie einfach über die predict-Methode, wie unten dargestellt:
Text-Prompts ermöglichen es dir, die Klassen, die du erkennen möchtest, durch textuelle Beschreibungen festzulegen. Der folgende Code zeigt, wie du YOLOE-26 verwenden kannst, um Personen und Busse in einem Bild zu erkennen:
from ultralytics import YOLO
# Initialize model
model = YOLO("yoloe-26l-seg.pt") # or select yoloe-26s/m-seg.pt for different sizes
# Set text prompt to detect person and bus. You only need to do this once after you load the model.
model.set_classes(["person", "bus"])
# Run detection on the given image
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()Für Prompting-Techniken und vollständige Anwendungsbeispiele besuche die YOLOE-Dokumentation.
Link to this sectionZitate und Danksagungen#
Für eine vollständige technische Beschreibung der YOLO26-Architektur, des Trainingsrezepts, der Task-Heads und der YOLOE-26 Open-Vocabulary-Erweiterung, lies Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models. Wenn du YOLO26 in deiner Forschung verwendest, zitiere bitte:
@misc{jocher2026ultralyticsyolo26unifiedrealtime,
title = {Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models},
author = {Glenn Jocher and Jing Qiu and Mengyu Liu and Shuai Lyu and Fatih Cagatay Akyon and Muhammet Esat Kalfaoglu},
year = {2026},
eprint = {2606.03748},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
doi = {10.48550/arXiv.2606.03748},
url = {https://arxiv.org/abs/2606.03748},
}Der Code, die Modelle und die Dokumentation für YOLO26 sind im Ultralytics GitHub repository und unter Ultralytics Docs gemäß der AGPL-3.0 und Enterprise Lizenzen verfügbar.
Link to this sectionFAQ#
Link to this sectionWas sind die wichtigsten Verbesserungen in YOLO26?#
- DFL-freie Regression: Vereinfacht den Detection-Head und den Export-Pfad
- End-to-End NMS-freie Inferenz: Entfernt NMS aus dem Standard-Inferenzpfad
- Progressive Loss + STAL: Verbessert die Trainingsausrichtung und die Label-Abdeckung für kleine Objekte
- MuSGD-Optimierer: Kombiniert SGD mit einer von Muon inspirierten Optimierung für stabiles Training
- Aufgabenspezifische Heads und Losses: Verbessert die Unterstützung für Segmentierung, Pose-Schätzung und orientierte Objekterkennung
Link to this sectionWelche Aufgaben unterstützt YOLO26?#
YOLO26 ist eine einheitliche Modellfamilie, die End-to-End-Unterstützung für mehrere Computer-Vision-Aufgaben bietet:
- Objekterkennung
- Instance Segmentation
- Semantische Segmentierung
- Bildklassifizierung
- Pose-Schätzung
- Orientierte Objekterkennung (OBB)
Jede Größenvariante (n, s, m, l, x) unterstützt alle Aufgaben, sowie Open-Vocabulary-Versionen via YOLOE-26.
Link to this sectionWarum ist YOLO26 effizient für das Deployment?#
YOLO26 verbessert die Deployment-Effizienz durch:
- Native End-to-End-Inferenz ohne NMS standardmäßig
- DFL-freie Regression und ein leichterer Detection-Head
- Fused-Model-Export, der nur für das Training benötigte Hilfskomponenten entfernt
- Bis zu 43 % schnellere CPU-ONNX-Inferenz für YOLO26n gegenüber YOLO11n auf einer Intel Xeon CPU @ 2.00 GHz
- Flexible Exportformate wie TensorRT, ONNX, CoreML, LiteRT und OpenVINO
Link to this sectionWie lege ich mit YOLO26 los?#
YOLO26-Modelle stehen über das ultralytics-Paket zum Download bereit. Installiere oder aktualisiere das Paket und lade ein Modell:
from ultralytics import YOLO
# Load a pretrained YOLO26 nano model
model = YOLO("yolo26n.pt")
# Run inference on an image
results = model("image.jpg")Siehe den Abschnitt Anwendungsbeispiele für Anleitungen zu Training, Validierung und Export.