कंप्यूटर विजन प्रोजेक्ट में महत्वपूर्ण चरणों को समझना
परिचय
कंप्यूटर दृष्टि कृत्रिम बुद्धिमत्ता (एआई) का एक उपक्षेत्र है जो कंप्यूटर को दुनिया को देखने और समझने में मदद करता है जैसे मनुष्य करते हैं। यह जानकारी निकालने, पैटर्न पहचानने और उस डेटा के आधार पर निर्णय लेने के लिए छवियों या वीडियो को संसाधित और विश्लेषण करता है।
ऑब्जेक्ट डिटेक्शन, इमेज क्लासिफिकेशन और इंस्टेंस सेगमेंटेशन जैसी कंप्यूटर विज़न तकनीकों को विभिन्न उद्योगों में लागू किया जा सकता है, स्वायत्त ड्राइविंग से लेकर मेडिकल इमेजिंग तक मूल्यवान अंतर्दृष्टि प्राप्त करने के लिए।

अपने स्वयं के कंप्यूटर विज़न प्रोजेक्ट्स पर काम करना कंप्यूटर विज़न के बारे में अधिक समझने और जानने का एक शानदार तरीका है। हालांकि, एक कंप्यूटर विज़न प्रोजेक्ट में कई चरण शामिल हो सकते हैं, और यह पहली बार में भ्रमित करने वाला लग सकता है। इस गाइड के अंत तक, आप कंप्यूटर विज़न प्रोजेक्ट में शामिल चरणों से परिचित होंगे। हम एक परियोजना की शुरुआत से अंत तक सब कुछ के माध्यम से चलेंगे, यह समझाते हुए कि प्रत्येक भाग महत्वपूर्ण क्यों है। आइए शुरू करें और अपने कंप्यूटर विज़न प्रोजेक्ट को सफल बनाएं!
एक कंप्यूटर विजन परियोजना का अवलोकन
कंप्यूटर विज़न प्रोजेक्ट में शामिल प्रत्येक चरण के विवरण पर चर्चा करने से पहले, आइए समग्र प्रक्रिया को देखें। यदि आपने आज एक कंप्यूटर विज़न प्रोजेक्ट शुरू किया है, तो आप निम्नलिखित कदम उठाएंगे:
- आपकी पहली प्राथमिकता आपकी परियोजना की आवश्यकताओं को समझना होगा।
- फिर, आप उन छवियों को एकत्र और सटीक रूप से लेबल करेंगे जो आपके मॉडल को प्रशिक्षित करने में मदद करेंगे।
- इसके बाद, आप अपने डेटा को साफ करेंगे और इसे मॉडल प्रशिक्षण के लिए तैयार करने के लिए वृद्धि तकनीकों को लागू करेंगे।
- मॉडल प्रशिक्षण के बाद, आप यह सुनिश्चित करने के लिए अपने मॉडल का पूरी तरह से परीक्षण और मूल्यांकन करेंगे कि यह विभिन्न परिस्थितियों में लगातार प्रदर्शन करता है।
- अंत में, आप अपने मॉडल को वास्तविक दुनिया में तैनात करेंगे और नई अंतर्दृष्टि और प्रतिक्रिया के आधार पर इसे अपडेट करेंगे।
.jpeg)
अब जब हम जानते हैं कि क्या उम्मीद करनी है, तो आइए चरणों में सही गोता लगाएँ और अपनी परियोजना को आगे बढ़ाएं।
चरण 1: अपनी परियोजना के लक्ष्यों को परिभाषित करना
किसी भी कंप्यूटर विज़न प्रोजेक्ट में पहला कदम उस समस्या को स्पष्ट रूप से परिभाषित करना है जिसे आप हल करने का प्रयास कर रहे हैं। अंतिम लक्ष्य जानने से आपको समाधान बनाने में मदद मिलती है। यह विशेष रूप से सच है जब कंप्यूटर दृष्टि की बात आती है क्योंकि आपकी परियोजना का उद्देश्य सीधे प्रभावित करेगा कि आपको किस कंप्यूटर दृष्टि कार्य पर ध्यान केंद्रित करने की आवश्यकता है।
यहाँ परियोजना उद्देश्यों और कंप्यूटर विज़न कार्यों के कुछ उदाहरण दिए गए हैं जिनका उपयोग इन उद्देश्यों तक पहुँचने के लिए किया जा सकता है:
-
वस्तुनिष्ठ: एक ऐसी प्रणाली विकसित करना जो राजमार्गों पर विभिन्न प्रकार के वाहनों के प्रवाह की निगरानी और प्रबंधन कर सके, यातायात प्रबंधन और सुरक्षा में सुधार कर सके।
- कंप्यूटर विजन टास्क: ऑब्जेक्ट डिटेक्शन ट्रैफ़िक मॉनिटरिंग के लिए आदर्श है क्योंकि यह कुशलता से कई वाहनों का पता लगाता है और उनकी पहचान करता है। यह छवि विभाजन की तुलना में कम कम्प्यूटेशनल रूप से मांग कर रहा है, जो इस कार्य के लिए अनावश्यक विवरण प्रदान करता है, तेजी से, वास्तविक समय विश्लेषण सुनिश्चित करता है।
-
वस्तुनिष्ठ: एक उपकरण विकसित करने के लिए जो मेडिकल इमेजिंग स्कैन में ट्यूमर की सटीक, पिक्सेल-स्तरीय रूपरेखा प्रदान करके रेडियोलॉजिस्ट की सहायता करता है।
- कंप्यूटर विजन टास्क: छवि विभाजन चिकित्सा इमेजिंग के लिए उपयुक्त है क्योंकि यह ट्यूमर की सटीक और विस्तृत सीमाएं प्रदान करता है जो आकार, आकार और उपचार योजना का आकलन करने के लिए महत्वपूर्ण हैं।
-
वस्तुनिष्ठ: एक डिजिटल सिस्टम बनाने के लिए जो संगठनात्मक दक्षता और दस्तावेज़ पुनर्प्राप्ति में सुधार के लिए विभिन्न दस्तावेजों (जैसे, चालान, रसीदें, कानूनी कागजी कार्रवाई) को वर्गीकृत करता है।
- कंप्यूटर विजन टास्क: छवि वर्गीकरण यहां आदर्श है क्योंकि यह छवि में दस्तावेज़ की स्थिति पर विचार करने की आवश्यकता के बिना, एक समय में एक दस्तावेज़ को संभालता है। यह दृष्टिकोण छँटाई प्रक्रिया को सरल और तेज करता है।
चरण 1.5: सही मॉडल और प्रशिक्षण दृष्टिकोण का चयन करना
परियोजना के उद्देश्य और उपयुक्त कंप्यूटर दृष्टि कार्यों को समझने के बाद, परियोजना लक्ष्य को परिभाषित करने का एक अनिवार्य हिस्सा सही मॉडल और प्रशिक्षण दृष्टिकोण का चयन कर रहा है।
उद्देश्य के आधार पर, आप पहले मॉडल का चयन करना चुन सकते हैं या यह देखने के बाद कि आप चरण 2 में कौन सा डेटा एकत्र करने में सक्षम हैं। उदाहरण के लिए, मान लें कि आपकी परियोजना विशिष्ट प्रकार के डेटा की उपलब्धता पर अत्यधिक निर्भर है। उस स्थिति में, मॉडल का चयन करने से पहले डेटा एकत्र करना और उसका विश्लेषण करना अधिक व्यावहारिक हो सकता है। दूसरी ओर, यदि आपको मॉडल आवश्यकताओं की स्पष्ट समझ है, तो आप पहले मॉडल चुन सकते हैं और फिर उन विनिर्देशों के अनुरूप डेटा एकत्र कर सकते हैं।
स्क्रैच से प्रशिक्षण या स्थानांतरण सीखने का उपयोग करने के बीच चयन करना प्रभावित करता है कि आप अपना डेटा कैसे तैयार करते हैं। खरोंच से प्रशिक्षण के लिए जमीन से मॉडल की समझ बनाने के लिए एक विविध डेटासेट की आवश्यकता होती है। दूसरी ओर, ट्रांसफर लर्निंग, आपको पूर्व-प्रशिक्षित मॉडल का उपयोग करने और इसे एक छोटे, अधिक विशिष्ट डेटासेट के साथ अनुकूलित करने की अनुमति देता है। साथ ही, प्रशिक्षित करने के लिए एक विशिष्ट मॉडल चुनना यह निर्धारित करेगा कि मॉडल की विशिष्ट आवश्यकताओं के अनुसार आपको अपना डेटा कैसे तैयार करना है, जैसे छवियों का आकार बदलना या एनोटेशन जोड़ना।
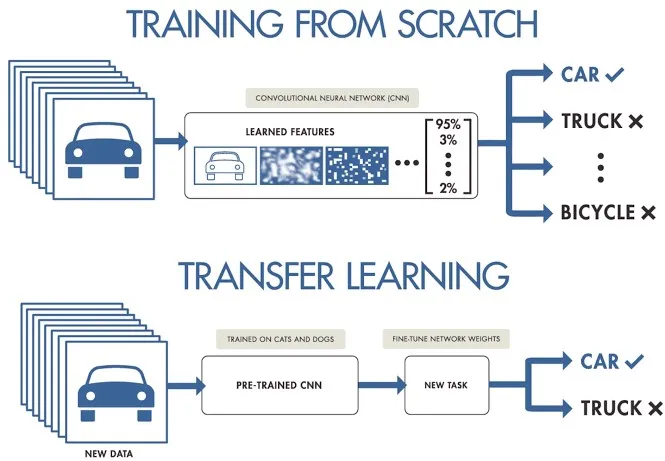
नोट: मॉडल चुनते समय, संगतता और प्रदर्शन सुनिश्चित करने के लिए इसके परिनियोजन पर विचार करें। उदाहरण के लिए, हल्के मॉडल संसाधन-विवश उपकरणों पर उनकी दक्षता के कारण एज कंप्यूटिंग के लिए आदर्श हैं। अपनी परियोजना को परिभाषित करने से संबंधित प्रमुख बिंदुओं के बारे में अधिक जानने के लिए, अपने प्रोजेक्ट के लक्ष्यों को परिभाषित करने और सही मॉडल का चयन करने के बारे में हमारी मार्गदर्शिका पढ़ें।
कंप्यूटर विज़न प्रोजेक्ट के हाथों में आने से पहले, इन विवरणों की स्पष्ट समझ होना महत्वपूर्ण है। चरण 2 पर जाने से पहले दोबारा जांच लें कि आपने निम्नलिखित पर विचार किया है:
- उस समस्या को स्पष्ट रूप से परिभाषित करें जिसे आप हल करने का प्रयास कर रहे हैं।
- अपनी परियोजना का अंतिम लक्ष्य निर्धारित करें।
- आवश्यक विशिष्ट कंप्यूटर दृष्टि कार्य की पहचान करें (जैसे, वस्तु का पता लगाने, छवि वर्गीकरण, छवि विभाजन)।
- तय करें कि किसी मॉडल को खरोंच से प्रशिक्षित करना है या स्थानांतरण सीखने का उपयोग करना है।
- अपने कार्य और परिनियोजन आवश्यकताओं के लिए उपयुक्त मॉडल का चयन करें।
चरण 2: डेटा संग्रह और डेटा एनोटेशन
आपके कंप्यूटर विज़न मॉडल की गुणवत्ता आपके डेटासेट की गुणवत्ता पर निर्भर करती है। आप या तो इंटरनेट से चित्र एकत्र कर सकते हैं, अपनी तस्वीरें ले सकते हैं या पहले से मौजूद डेटासेट का उपयोग कर सकते हैं। उच्च-गुणवत्ता वाले डेटासेट डाउनलोड करने के लिए यहां कुछ बेहतरीन संसाधन दिए गए हैं: Google डेटासेट सर्च इंजन, यूसी इरविन मशीन लर्निंग रिपोजिटरी और कैगल डेटासेट।
कुछ पुस्तकालय, जैसे Ultralytics, विभिन्न डेटासेट के लिए अंतर्निहित समर्थन प्रदान करते हैं, जिससे उच्च-गुणवत्ता वाले डेटा के साथ आरंभ करना आसान हो जाता है। इन पुस्तकालयों में अक्सर लोकप्रिय डेटासेट का निर्बाध रूप से उपयोग करने के लिए उपयोगिताओं को शामिल किया जाता है, जो आपकी परियोजना के प्रारंभिक चरणों में आपका बहुत समय और प्रयास बचा सकता है।
हालाँकि, यदि आप चित्र एकत्र करना या अपनी स्वयं की तस्वीरें लेना चुनते हैं, तो आपको अपना डेटा एनोटेट करना होगा। डेटा एनोटेशन आपके मॉडल को ज्ञान प्रदान करने के लिए आपके डेटा को लेबल करने की प्रक्रिया है। आप जिस प्रकार के डेटा एनोटेशन के साथ काम करेंगे, वह आपकी विशिष्ट कंप्यूटर विज़न तकनीक पर निर्भर करता है। यहां कुछ उदाहरण दिए गए हैं:
- छवि वर्गीकरण: आप पूरी छवि को एक ही वर्ग के रूप में लेबल करेंगे।
- वस्तु का पता लगाना: आप छवि में प्रत्येक ऑब्जेक्ट के चारों ओर बाउंडिंग बॉक्स खींचेंगे और प्रत्येक बॉक्स को लेबल करेंगे।
- छवि विभाजन: आप छवि में प्रत्येक पिक्सेल को उस वस्तु के अनुसार लेबल करेंगे, जिससे वह संबंधित है, विस्तृत ऑब्जेक्ट सीमाएँ बनाएँगे।
डेटा संग्रह और एनोटेशन एक समय लेने वाला मैनुअल प्रयास हो सकता है। एनोटेशन उपकरण इस प्रक्रिया को आसान बनाने में मदद कर सकते हैं। यहां कुछ उपयोगी ओपन एनोटेशन टूल दिए गए हैं: LabeI Studio, CVAT, और Labelme।
चरण 3: डेटा वृद्धि और अपने डेटासेट को विभाजित करना
अपने छवि डेटा को एकत्र करने और एनोटेट करने के बाद, डेटा वृद्धि करने से पहले अपने डेटासेट को प्रशिक्षण, सत्यापन और परीक्षण सेट में विभाजित करना महत्वपूर्ण है। वृद्धि से पहले अपने डेटासेट को विभाजित करना मूल, अनछुए डेटा पर अपने मॉडल का परीक्षण और सत्यापन करने के लिए महत्वपूर्ण है। यह सटीक रूप से आकलन करने में मदद करता है कि मॉडल नए, अनदेखे डेटा के लिए कितनी अच्छी तरह सामान्यीकृत है।
यहां अपना डेटा विभाजित करने का तरीका बताया गया है:
- प्रशिक्षण सेट: यह आपके डेटा का सबसे बड़ा हिस्सा है, आमतौर पर कुल का 70-80%, आपके मॉडल को प्रशिक्षित करने के लिए उपयोग किया जाता है।
- सत्यापन सेट: आमतौर पर आपके डेटा का लगभग 10-15%; इस सेट का उपयोग हाइपरपैरामीटर को ट्यून करने और प्रशिक्षण के दौरान मॉडल को मान्य करने के लिए किया जाता है, जिससे ओवरफिटिंग को रोकने में मदद मिलती है।
- टेस्ट सेट: आपके डेटा का शेष 10-15% परीक्षण सेट के रूप में अलग रखा जाता है। इसका उपयोग प्रशिक्षण पूरा होने के बाद अनदेखी डेटा पर मॉडल के प्रदर्शन का मूल्यांकन करने के लिए किया जाता है।
अपने डेटा को विभाजित करने के बाद, आप अपने डेटासेट के आकार को कृत्रिम रूप से बढ़ाने के लिए छवियों को घुमाने, स्केल करने और फ़्लिप करने जैसे परिवर्तनों को लागू करके डेटा वृद्धि कर सकते हैं। डेटा वृद्धि आपके मॉडल को विविधताओं के लिए अधिक मजबूत बनाती है और अनदेखी छवियों पर इसके प्रदर्शन में सुधार करती है।
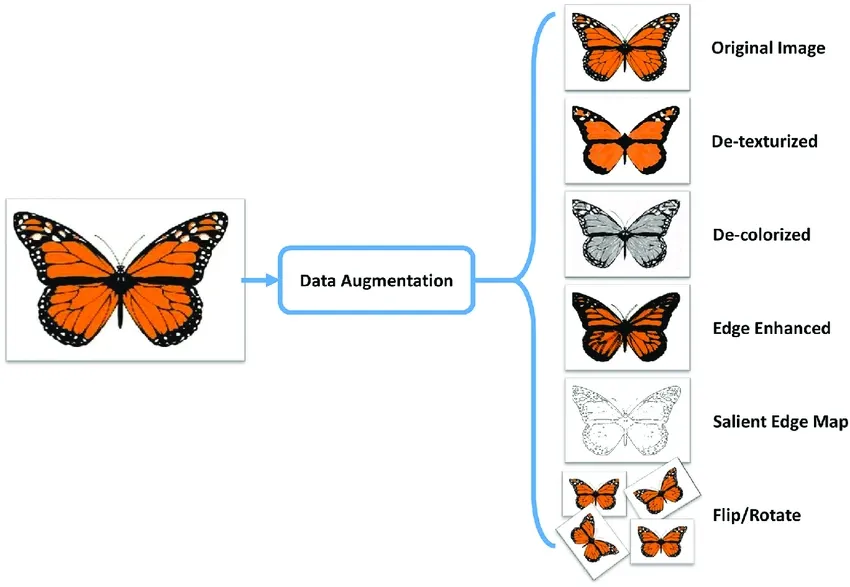
OpenCV, Albumentations, और जैसे पुस्तकालय TensorFlow लचीले वृद्धि कार्यों की पेशकश करें जिनका आप उपयोग कर सकते हैं। इसके अतिरिक्त, कुछ लाइब्रेरीज़, जैसे Ultralytics, प्रक्रिया को सरल बनाते हुए, सीधे अपने मॉडल प्रशिक्षण फ़ंक्शन के भीतर अंतर्निहित वृद्धि सेटिंग्स हैं।
अपने डेटा को बेहतर ढंग से समझने के लिए, आप छवियों की कल्पना करने और उनके वितरण और विशेषताओं का विश्लेषण करने के लिए Matplotlib या Seaborn जैसे टूल का उपयोग कर सकते हैं। अपने डेटा को विज़ुअलाइज़ करने से पैटर्न, विसंगतियों और आपकी वृद्धि तकनीकों की प्रभावशीलता की पहचान करने में मदद मिलती है। आप भी उपयोग कर सकते हैं Ultralytics एक्सप्लोरर, सिमेंटिक खोज, एसक्यूएल प्रश्नों और वेक्टर समानता खोज के साथ कंप्यूटर विज़न डेटासेट की खोज के लिए एक उपकरण।
अपने डेटा को ठीक से समझकर, विभाजित करके और बढ़ाकर, आप एक अच्छी तरह से प्रशिक्षित, मान्य और परीक्षण किया गया मॉडल विकसित कर सकते हैं जो वास्तविक दुनिया के अनुप्रयोगों में अच्छा प्रदर्शन करता है।
चरण 4: मॉडल प्रशिक्षण
एक बार जब आपका डेटासेट प्रशिक्षण के लिए तैयार हो जाता है, तो आप आवश्यक वातावरण स्थापित करने, अपने डेटासेट को प्रबंधित करने और अपने मॉडल को प्रशिक्षित करने पर ध्यान केंद्रित कर सकते हैं।
सबसे पहले, आपको यह सुनिश्चित करना होगा कि आपका परिवेश सही तरीके से कॉन्फ़िगर किया गया है। सामान्यतया, इसमें निम्न शामिल हैं:
- आवश्यक पुस्तकालयों और रूपरेखाओं को स्थापित करना जैसे TensorFlow, PyTorchनहीं तो Ultralytics.
- यदि आप एक का उपयोग कर रहे हैं GPU, जैसे पुस्तकालयों को स्थापित करना CUDA और cuDNN सक्षम करने में मदद करेगा GPU प्रशिक्षण प्रक्रिया में तेजी और तेजी लाएं।
फिर, आप अपने प्रशिक्षण और सत्यापन डेटासेट को अपने परिवेश में लोड कर सकते हैं। आकार बदलने, रूपांतरण, या वृद्धि के माध्यम से डेटा को सामान्य और पूर्वसंसाधित करें. अपने मॉडल के चयन के साथ, परतों को कॉन्फ़िगर करें और हाइपरपैरामीटर निर्दिष्ट करें। हानि फ़ंक्शन, अनुकूलक और प्रदर्शन मीट्रिक सेट करके मॉडल को संकलित करें।
पुस्तकालयों की तरह Ultralytics प्रशिक्षण प्रक्रिया को सरल बनाएं। आप न्यूनतम कोड के साथ मॉडल में डेटा फीड करके प्रशिक्षण शुरू कर सकते हैं। ये पुस्तकालय वजन समायोजन, बैकप्रोपैगेशन और सत्यापन को स्वचालित रूप से संभालते हैं। वे प्रगति की निगरानी करने और हाइपरपैरामीटर को आसानी से समायोजित करने के लिए उपकरण भी प्रदान करते हैं। प्रशिक्षण के बाद, कुछ आदेशों के साथ मॉडल और उसके वजन को बचाएं।
यह ध्यान रखना महत्वपूर्ण है कि कुशल प्रशिक्षण के लिए उचित डेटासेट प्रबंधन महत्वपूर्ण है। परिवर्तनों को ट्रैक करने और प्रजनन क्षमता सुनिश्चित करने के लिए डेटासेट के लिए संस्करण नियंत्रण का उपयोग करें। डीवीसी (डेटा वर्जन कंट्रोल) जैसे उपकरण बड़े डेटासेट को प्रबंधित करने में मदद कर सकते हैं।
चरण 5: मॉडल मूल्यांकन और मॉडल फाइनट्यूनिंग
विभिन्न मीट्रिक का उपयोग करके अपने मॉडल के प्रदर्शन का आकलन करना और सटीकता में सुधार के लिए इसे परिष्कृत करना महत्वपूर्ण है। मूल्यांकन उन क्षेत्रों की पहचान करने में मदद करता है जहां मॉडल उत्कृष्टता प्राप्त करता है और जहां इसमें सुधार की आवश्यकता हो सकती है। फ़ाइन-ट्यूनिंग सुनिश्चित करता है कि मॉडल को सर्वोत्तम संभव प्रदर्शन के लिए अनुकूलित किया गया है।
- प्रदर्शन मेट्रिक्स: अपने मॉडल के प्रदर्शन का मूल्यांकन करने के लिए सटीकता, सटीकता, याद और F1-स्कोर जैसे मीट्रिक का उपयोग करें। ये मीट्रिक इस बात की जानकारी प्रदान करते हैं कि आपका मॉडल कितनी अच्छी तरह भविष्यवाणियां कर रहा है।
-
हाइपरपैरामीटर ट्यूनिंग: मॉडल प्रदर्शन को अनुकूलित करने के लिए हाइपरपैरामीटर समायोजित करें। ग्रिड खोज या यादृच्छिक खोज जैसी तकनीकें सर्वोत्तम हाइपरपैरामीटर मान खोजने में मदद कर सकती हैं।
-
फ़ाइन-ट्यूनिंग: प्रदर्शन को बढ़ाने के लिए मॉडल आर्किटेक्चर या प्रशिक्षण प्रक्रिया में छोटे समायोजन करें। इसमें सीखने की दर, बैच आकार या अन्य मॉडल मापदंडों में बदलाव शामिल हो सकता है।
चरण 6: मॉडल परीक्षण
इस चरण में, आप यह सुनिश्चित कर सकते हैं कि आपका मॉडल पूरी तरह से अनदेखी डेटा पर अच्छा प्रदर्शन करता है, परिनियोजन के लिए इसकी तत्परता की पुष्टि करता है। मॉडल परीक्षण और मॉडल मूल्यांकन के बीच का अंतर यह है कि यह अंतिम मॉडल के प्रदर्शन को पुनरावृत्त रूप से सुधारने के बजाय सत्यापित करने पर केंद्रित है।
उत्पन्न होने वाली किसी भी सामान्य समस्या का पूरी तरह से परीक्षण और डीबग करना महत्वपूर्ण है। एक अलग परीक्षण डेटासेट पर अपने मॉडल का परीक्षण करें जिसका उपयोग प्रशिक्षण या सत्यापन के दौरान नहीं किया गया था। इस डेटासेट को यह सुनिश्चित करने के लिए वास्तविक दुनिया के परिदृश्यों का प्रतिनिधित्व करना चाहिए कि मॉडल का प्रदर्शन सुसंगत और विश्वसनीय है।
इसके अलावा, ओवरफिटिंग, अंडरफिटिंग और डेटा रिसाव जैसी सामान्य समस्याओं का समाधान करें। इन समस्याओं को पहचानने और ठीक करने के लिए क्रॉस-सत्यापन और विसंगति का पता लगाने जैसी तकनीकों का उपयोग करें।
चरण 7: मॉडल परिनियोजन
एक बार जब आपका मॉडल पूरी तरह से परीक्षण कर लिया जाता है, तो इसे तैनात करने का समय आ गया है। परिनियोजन में आपके मॉडल को उत्पादन वातावरण में उपयोग के लिए उपलब्ध कराना शामिल है। कंप्यूटर विज़न मॉडल को परिनियोजित करने के चरण यहां दिए गए हैं:
-
परिवेश की स्थापना: अपने चुने हुए परिनियोजन विकल्प के लिए आवश्यक बुनियादी ढाँचे को कॉन्फ़िगर करें, चाहे वह क्लाउड-आधारित हो (AWS, Google क्लाउड, एज़र) या एज-आधारित (स्थानीय डिवाइस, IoT)।
-
मॉडल का निर्यात: अपने मॉडल को उपयुक्त प्रारूप में निर्यात करें (जैसे, ONNX, TensorRT, CoreML के लिए YOLOv8) अपने परिनियोजन प्लेटफ़ॉर्म के साथ संगतता सुनिश्चित करने के लिए।
- मॉडल की तैनाती: एपीआई या एंडपॉइंट सेट करके और इसे अपने एप्लिकेशन के साथ एकीकृत करके मॉडल को परिनियोजित करें।
- मापनीयता सुनिश्चित करना: संसाधनों को प्रबंधित करने और बढ़ते डेटा और उपयोगकर्ता अनुरोधों को संभालने के लिए लोड बैलेंसर, ऑटो-स्केलिंग समूह और निगरानी उपकरण लागू करें।
चरण 8: निगरानी, रखरखाव और दस्तावेज़ीकरण
एक बार जब आपका मॉडल तैनात हो जाता है, तो इसके प्रदर्शन की लगातार निगरानी करना, किसी भी समस्या को संभालने के लिए इसे बनाए रखना और भविष्य के संदर्भ और सुधारों के लिए पूरी प्रक्रिया का दस्तावेजीकरण करना महत्वपूर्ण है।
निगरानी उपकरण आपको प्रमुख प्रदर्शन संकेतकों (KPI) को ट्रैक करने और सटीकता में विसंगतियों या बूंदों का पता लगाने में मदद कर सकते हैं। मॉडल की निगरानी करके, आप मॉडल बहाव से अवगत हो सकते हैं, जहां इनपुट डेटा में परिवर्तन के कारण समय के साथ मॉडल का प्रदर्शन घटता है। सटीकता और प्रासंगिकता बनाए रखने के लिए समय-समय पर अद्यतन डेटा के साथ मॉडल को फिर से प्रशिक्षित करें।
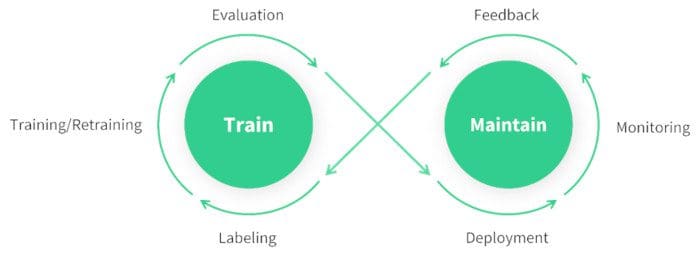
निगरानी और रखरखाव के अलावा, प्रलेखन भी महत्वपूर्ण है। मॉडल आर्किटेक्चर, प्रशिक्षण प्रक्रियाओं, हाइपरपैरामीटर, डेटा प्रीप्रोसेसिंग चरणों और तैनाती और रखरखाव के दौरान किए गए किसी भी परिवर्तन सहित पूरी प्रक्रिया को अच्छी तरह से दस्तावेज करें। अच्छा दस्तावेज़ीकरण प्रजनन क्षमता सुनिश्चित करता है और भविष्य के अपडेट या समस्या निवारण को आसान बनाता है। अपने मॉडल की प्रभावी ढंग से निगरानी, रखरखाव और दस्तावेजीकरण करके, आप यह सुनिश्चित कर सकते हैं कि यह अपने जीवनचक्र पर सटीक, विश्वसनीय और प्रबंधित करने में आसान बना रहे।
समुदाय के साथ जुड़ना
कंप्यूटर दृष्टि उत्साही लोगों के समुदाय के साथ जुड़ने से आपको आत्मविश्वास के साथ अपने कंप्यूटर विज़न प्रोजेक्ट पर काम करते समय किसी भी समस्या से निपटने में मदद मिल सकती है। प्रभावी ढंग से सीखने, समस्या निवारण और नेटवर्क बनाने के कुछ तरीके यहां दिए गए हैं।
सामुदायिक संसाधन
- GitHub मुद्दे: बाहर की जाँच करें YOLOv8 GitHub रिपॉजिटरी और प्रश्न पूछने, बग की रिपोर्ट करने और नई सुविधाओं का सुझाव देने के लिए मुद्दे टैब का उपयोग करें। विशिष्ट मुद्दों के साथ मदद करने के लिए सक्रिय समुदाय और अनुरक्षक हैं।
- Ultralytics डिस्कॉर्ड सर्वर: में शामिल हों Ultralytics डिस्कॉर्ड सर्वर अन्य उपयोगकर्ताओं और डेवलपर्स के साथ बातचीत करने, समर्थन प्राप्त करने और अंतर्दृष्टि साझा करने के लिए।
आधिकारिक दस्तावेज़ीकरण
- Ultralytics YOLOv8 दस्तावेज़ीकरण:अफ़सर YOLOv8 विभिन्न कंप्यूटर दृष्टि कार्यों और परियोजनाओं पर उपयोगी सुझावों के साथ विस्तृत गाइड के लिए दस्तावेज़ीकरण।
इन संसाधनों का उपयोग करने से आपको चुनौतियों से उबरने और कंप्यूटर दृष्टि समुदाय में नवीनतम रुझानों और सर्वोत्तम प्रथाओं के साथ अपडेट रहने में मदद मिलेगी।
आज ही अपने कंप्यूटर विजन प्रोजेक्ट को किकस्टार्ट करें!
कंप्यूटर विज़न प्रोजेक्ट लेना रोमांचक और फायदेमंद हो सकता है। इस गाइड के चरणों का पालन करके, आप सफलता के लिए एक ठोस आधार बना सकते हैं। प्रत्येक चरण एक समाधान विकसित करने के लिए महत्वपूर्ण है जो आपके उद्देश्यों को पूरा करता है और वास्तविक दुनिया के परिदृश्यों में अच्छी तरह से काम करता है। जैसे-जैसे आप अनुभव प्राप्त करते हैं, आप अपनी परियोजनाओं को बेहतर बनाने के लिए उन्नत तकनीकों और उपकरणों की खोज करेंगे। जिज्ञासु रहें, सीखते रहें, और नए तरीकों और नवाचारों का पता लगाएं!
अक्सर पूछे जाने वाले प्रश्न
मैं अपने प्रोजेक्ट के लिए सही कंप्यूटर विज़न कार्य कैसे चुनूं?
सही कंप्यूटर विज़न कार्य चुनना आपके प्रोजेक्ट के अंतिम लक्ष्य पर निर्भर करता है। उदाहरण के लिए, यदि आप ट्रैफ़िक की निगरानी करना चाहते हैं, तो ऑब्जेक्ट डिटेक्शन उपयुक्त है क्योंकि यह वास्तविक समय में कई प्रकार के वाहन का पता लगा सकता है और पहचान सकता है। चिकित्सा इमेजिंग के लिए, छवि विभाजन ट्यूमर की विस्तृत सीमाएं प्रदान करने, निदान और उपचार योजना में सहायता के लिए आदर्श है। ऑब्जेक्ट डिटेक्शन, इमेज वर्गीकरण और इंस्टेंस सेगमेंटेशन जैसे विशिष्ट कार्यों के बारे में अधिक जानें.
कंप्यूटर विज़न प्रोजेक्ट्स में डेटा एनोटेशन क्यों महत्वपूर्ण है?
पैटर्न को पहचानने के लिए अपने मॉडल को सिखाने के लिए डेटा एनोटेशन महत्वपूर्ण है। एनोटेशन का प्रकार कार्य के साथ बदलता रहता है:
- इमेज वर्गीकरण: पूरी इमेज को एक क्लास के रूप में लेबल किया गया है.
- ऑब्जेक्ट डिटेक्शन: वस्तुओं के चारों ओर खींचे गए बाउंडिंग बॉक्स।
- छवि विभाजन: प्रत्येक पिक्सेल को उस वस्तु के अनुसार लेबल किया जाता है जिससे वह संबंधित है।
Label Studio, CVAT और Labelme जैसे उपकरण इस प्रक्रिया में सहायता कर सकते हैं। अधिक विवरण के लिए, हमारे डेटा संग्रह और एनोटेशन गाइड देखें।
अपने डेटासेट को प्रभावी ढंग से बढ़ाने और विभाजित करने के लिए मुझे किन चरणों का पालन करना चाहिए?
वृद्धि से पहले अपने डेटासेट को विभाजित करने से मूल, अनछुए डेटा पर मॉडल प्रदर्शन को मान्य करने में मदद मिलती है। इन चरणों का पालन करें:
- प्रशिक्षण सेट: आपके डेटा का 70-80%।
- सत्यापन सेट: हाइपरपैरामीटर ट्यूनिंग के लिए 10-15%।
- टेस्ट सेट: अंतिम मूल्यांकन के लिए शेष 10-15%।
विभाजन के बाद, डेटासेट विविधता बढ़ाने के लिए रोटेशन, स्केलिंग और फ़्लिपिंग जैसी डेटा वृद्धि तकनीकों को लागू करें। Albumentations और OpenCV जैसे पुस्तकालय मदद कर सकते हैं। Ultralytics सुविधा के लिए अंतर्निहित वृद्धि सेटिंग्स भी प्रदान करता है।
मैं तैनाती के लिए अपने प्रशिक्षित कंप्यूटर विज़न मॉडल को कैसे निर्यात कर सकता हूं?
अपने मॉडल को निर्यात करना विभिन्न परिनियोजन प्लेटफार्मों के साथ संगतता सुनिश्चित करता है। Ultralytics सहित कई प्रारूप प्रदान करता है ONNX, TensorRTऔर CoreML. अपना निर्यात करने के लिए YOLOv8 मॉडल, इस गाइड का पालन करें:
- का उपयोग करें
exportवांछित प्रारूप पैरामीटर के साथ फ़ंक्शन। - सुनिश्चित करें कि निर्यात किया गया मॉडल आपके परिनियोजन वातावरण (जैसे, किनारे के उपकरण, क्लाउड) के विनिर्देशों में फिट बैठता है।
अधिक जानकारी के लिए, मॉडल निर्यात गाइड देखें।
तैनात कंप्यूटर विज़न मॉडल की निगरानी और रखरखाव के लिए सर्वोत्तम अभ्यास क्या हैं?
एक मॉडल की दीर्घकालिक सफलता के लिए निरंतर निगरानी और रखरखाव आवश्यक है। मुख्य प्रदर्शन संकेतकों (KPI) को ट्रैक करने और विसंगतियों का पता लगाने के लिए उपकरण लागू करें। मॉडल बहाव का मुकाबला करने के लिए अद्यतन डेटा के साथ मॉडल को नियमित रूप से फिर से प्रशिक्षित करें। मॉडल आर्किटेक्चर, हाइपरपैरामीटर और परिवर्तनों सहित पूरी प्रक्रिया का दस्तावेजीकरण करें, ताकि प्रजनन क्षमता और भविष्य के अपडेट में आसानी सुनिश्चित हो सके। हमारी निगरानी और रखरखाव गाइड में और जानें।