कस्टम डेटा को प्रशिक्षित करें
📚 यह मार्गदर्शिका बताती है कि अपने स्वयं के कस्टम डेटासेट को कैसे प्रशिक्षित किया जाए YOLOv5 🚀.
शुरू करने से पहले
रेपो को क्लोन करें और requirements.txt को एक में स्थापित करें Python> = 3.8.0 पर्यावरण, सहित PyTorch>=1.8। मॉडल और डेटासेट नवीनतम से स्वचालित रूप से डाउनलोड होते हैं YOLOv5 रिलीज।
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
कस्टम डेटा पर ट्रेन

अपनी वस्तुओं का पता लगाने के लिए एक कस्टम मॉडल बनाना छवियों को इकट्ठा करने और व्यवस्थित करने, अपनी रुचि की वस्तुओं को लेबल करने, एक मॉडल को प्रशिक्षित करने, भविष्यवाणियां करने के लिए इसे जंगली में तैनात करने और फिर उस तैनात मॉडल का उपयोग करने के लिए किनारे के मामलों के उदाहरणों को इकट्ठा करने की एक पुनरावृत्ति प्रक्रिया है।
लाइसेंस
Ultralytics दो लाइसेंसिंग विकल्प प्रदान करता है:
- वही AGPL-3.0 लाइसेंस, छात्रों और उत्साही लोगों के लिए एक OSI- अनुमोदित ओपन-सोर्स लाइसेंस।
- हमारे एआई मॉडल को अपने उत्पादों और सेवाओं में शामिल करने के इच्छुक व्यवसायों के लिए एंटरप्राइज़ लाइसेंस ।
अधिक जानकारी के लिए देखें Ultralytics लाइसेंसिंग।
YOLOv5 उस डेटा में वस्तुओं के वर्गों को सीखने के लिए मॉडल को लेबल किए गए डेटा पर प्रशिक्षित किया जाना चाहिए। प्रशिक्षण शुरू करने से पहले अपना डेटासेट बनाने के लिए दो विकल्प हैं:
विकल्प 1: Roboflow डेटासेट
1.1 छवियाँ एकत्र करें
आपका मॉडल उदाहरण के द्वारा सीखेगा। जंगली में दिखाई देने वाली छवियों के समान छवियों पर प्रशिक्षण अत्यंत महत्वपूर्ण है। आदर्श रूप से, आप एक ही कॉन्फ़िगरेशन (कैमरा, कोण, प्रकाश व्यवस्था, आदि) से विभिन्न प्रकार की छवियां एकत्र करेंगे क्योंकि आप अंततः अपनी परियोजना को तैनात करेंगे।
यदि यह संभव नहीं है, तो आप अपने प्रारंभिक मॉडल को प्रशिक्षित करने के लिए एक सार्वजनिक डेटासेट से शुरू कर सकते हैं और फिर अपने डेटासेट और मॉडल को पुनरावृत्त रूप से बेहतर बनाने के लिए अनुमान के दौरान जंगली से छवियों का नमूना ले सकते हैं।
1.2 लेबल बनाएं
एक बार जब आप चित्र एकत्र कर लेते हैं, तो आपको अपने मॉडल से सीखने के लिए जमीनी सच्चाई बनाने के लिए रुचि की वस्तुओं को एनोटेट करना होगा।
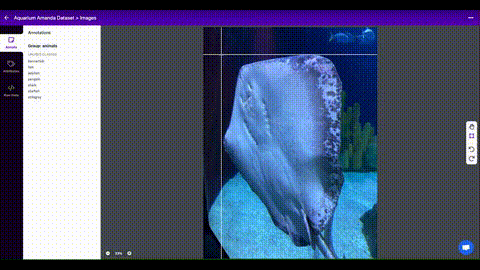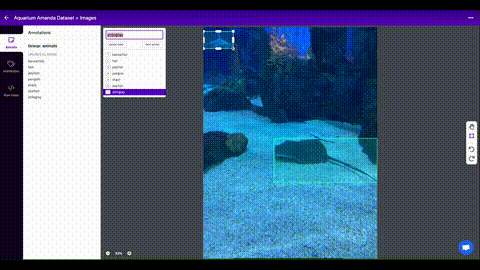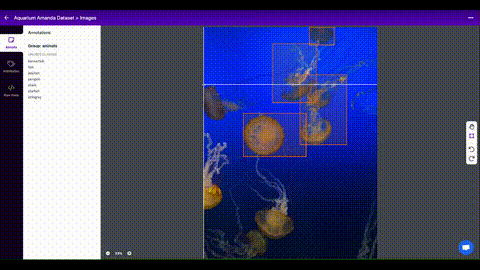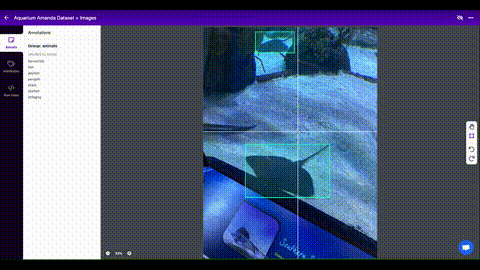
Roboflow एनोटेट आपकी टीम के साथ आपकी छवियों को प्रबंधित करने और लेबल करने और उन्हें निर्यात करने के लिए एक सरल वेब-आधारित उपकरण है YOLOv5एनोटेशन प्रारूप।
1.3 के लिए डेटासेट तैयार करें YOLOv5
चाहे आप अपनी छवियों को लेबल करें Roboflow या नहीं, आप इसका उपयोग अपने डेटासेट को YOLO प्रारूप, एक YOLOv5 YAML कॉन्फ़िगरेशन फ़ाइल, और इसे अपनी प्रशिक्षण स्क्रिप्ट में आयात करने के लिए होस्ट करें।
एक नि: शुल्क बनाएँ Roboflow खाता और अपने डेटासेट को एक Public कार्यस्थान, किसी भी गैर-टिप्पणी की गई छवियों को लेबल करें, फिर अपने डेटासेट का एक संस्करण उत्पन्न और निर्यात करें YOLOv5 Pytorch प्रारूप।
नोट: YOLOv5 प्रशिक्षण के दौरान ऑनलाइन वृद्धि करता है, इसलिए हम किसी भी वृद्धि कदम को लागू करने की अनुशंसा नहीं करते हैं Roboflow के साथ प्रशिक्षण के लिए YOLOv5. लेकिन हम निम्नलिखित प्रीप्रोसेसिंग चरणों को लागू करने की सलाह देते हैं:
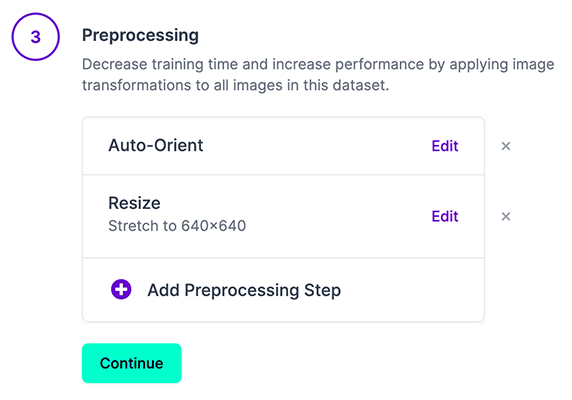
- ऑटो-ओरिएंट - अपनी छवियों से EXIF अभिविन्यास पट्टी करने के लिए।
- आकार बदलें (खिंचाव) - अपने मॉडल के वर्ग इनपुट आकार के लिए (640x640 है YOLOv5 डिफ़ॉल्ट)।
एक संस्करण बनाने से आपको अपने डेटासेट का एक स्नैपशॉट मिलेगा, इसलिए आप हमेशा वापस जा सकते हैं और इसके खिलाफ अपने भविष्य के मॉडल प्रशिक्षण रन की तुलना कर सकते हैं, भले ही आप अधिक चित्र जोड़ें या बाद में इसका कॉन्फ़िगरेशन बदलें।
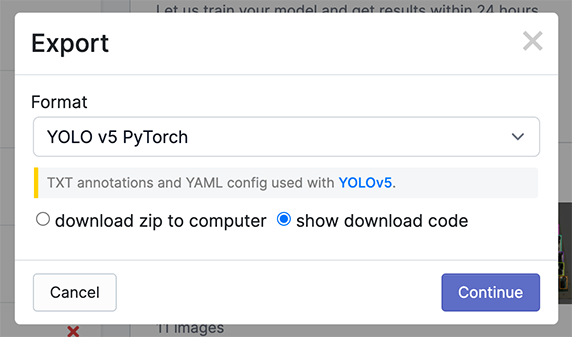
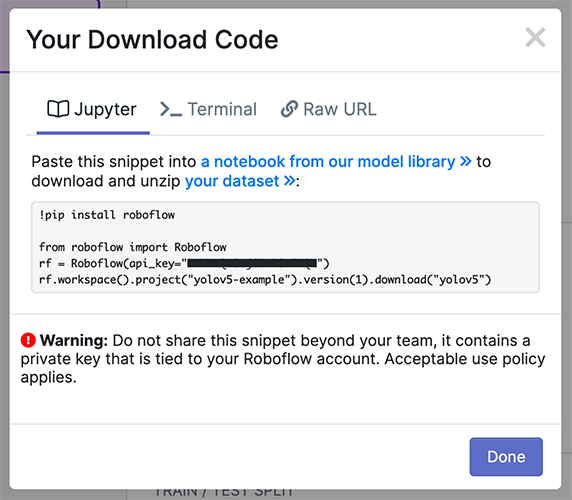
में निर्यात करें YOLOv5 Pytorch फ़ॉर्मैट करें, फिर अपना डेटासेट डाउनलोड करने के लिए स्निपेट को अपनी ट्रेनिंग स्क्रिप्ट या नोटबुक में कॉपी करें.
विकल्प 2: मैन्युअल डेटासेट बनाएं
2.1 बनाएँ dataset.yaml
COCO128 एक उदाहरण है छोटा ट्यूटोरियल डेटासेट में पहली 128 छवियों से बना है कोको ट्रेन2017. ये वही 128 छवियां प्रशिक्षण और सत्यापन दोनों के लिए उपयोग की जाती हैं ताकि यह सत्यापित किया जा सके कि हमारी प्रशिक्षण पाइपलाइन ओवरफिटिंग में सक्षम है। data/coco128.yaml, नीचे दिखाया गया है, डेटासेट कॉन्फ़िगरेशन फ़ाइल है जो परिभाषित करती है 1) डेटासेट रूट निर्देशिका path और सापेक्ष पथ train / val / test छवि निर्देशिका (या *.txt छवि पथ के साथ फ़ाइलें) और 2) एक वर्ग names विश्वकोशीय शब्दकोश:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes (80 COCO classes)
names:
0: person
1: bicycle
2: car
# ...
77: teddy bear
78: hair drier
79: toothbrush
2.2 लेबल बनाएं
अपनी छवियों को लेबल करने के लिए एक एनोटेशन टूल का उपयोग करने के बाद, अपने लेबल को निर्यात करें YOLO प्रारूप, एक के साथ *.txt प्रति छवि फ़ाइल (यदि छवि में कोई ऑब्जेक्ट नहीं है, तो नहीं *.txt फ़ाइल आवश्यक है)। वही *.txt फ़ाइल विनिर्देश हैं:
- प्रति ऑब्जेक्ट एक पंक्ति
- प्रत्येक पंक्ति है
class x_center y_center width heightप्रारूप। - बॉक्स निर्देशांक अंदर होना चाहिए सामान्यीकृत XYWH फ़ॉर्मैट (0 से 1 तक). यदि आपके बॉक्स पिक्सेल में हैं, तो विभाजित करें
x_centerऔरwidthछवि चौड़ाई द्वारा, औरy_centerऔरheightछवि ऊंचाई से। - वर्ग संख्याएँ शून्य-अनुक्रमित हैं (0 से प्रारंभ करें)।

उपरोक्त छवि के अनुरूप लेबल फ़ाइल में 2 व्यक्ति (वर्ग ) शामिल हैं 0) और एक टाई (वर्ग 27):

2.3 निर्देशिकाओं को व्यवस्थित करें
नीचे दिए गए उदाहरण के अनुसार अपनी ट्रेन और वैल छवियों और लेबल को व्यवस्थित करें। YOLOv5 मानता /coco128 एक के अंदर है /datasets डायरेक्टरी इसके बाद वही /yolov5 डायरेक्टरी। YOLOv5 प्रत्येक छवि के लिए स्वचालित रूप से लेबल का पता लगाता है के अंतिम उदाहरण को प्रतिस्थापित करके /images/ प्रत्येक छवि पथ में /labels/. उदाहरण के लिए:

3. एक मॉडल का चयन करें
प्रशिक्षण शुरू करने के लिए एक पूर्व-प्रशिक्षित मॉडल का चयन करें। यहां हम YOLOv5s का चयन करते हैं, जो दूसरा सबसे छोटा और सबसे तेज़ मॉडल उपलब्ध है। सभी मॉडलों की पूरी तुलना के लिए हमारी README तालिका देखें।

4. ट्रेन
डेटासेट, बैच-आकार, छवि आकार और या तो पूर्व-प्रशिक्षित निर्दिष्ट करके COCO128 पर एक YOLOv5s मॉडल को प्रशिक्षित करें --weights yolov5s.pt (अनुशंसित), या बेतरतीब ढंग से प्रारंभ किया गया --weights '' --cfg yolov5s.yaml (अनुशंसित नहीं)। पूर्व-प्रशिक्षित भार स्वतः डाउनलोड किए जाते हैं बिलकुल नया YOLOv5 निर्गमन.
नोक
💡 आगे कहना --cache ram नहीं तो --cache disk प्रशिक्षण में तेजी लाने के लिए (महत्वपूर्ण रैम / डिस्क संसाधनों की आवश्यकता होती है)।
नोक
💡 हमेशा स्थानीय डेटासेट से प्रशिक्षण लें। माउंटेड या नेटवर्क ड्राइव जैसे Google ड्राइव बहुत धीमी होगी।
सभी प्रशिक्षण परिणाम सहेजे जाते हैं runs/train/ रन निर्देशिकाओं को बढ़ाने के साथ, अर्थात। runs/train/exp2, runs/train/exp3 आदि। अधिक जानकारी के लिए हमारे ट्यूटोरियल नोटबुक का प्रशिक्षण अनुभाग देखें। ![]()

5. विज़ुअलाइज़ करें
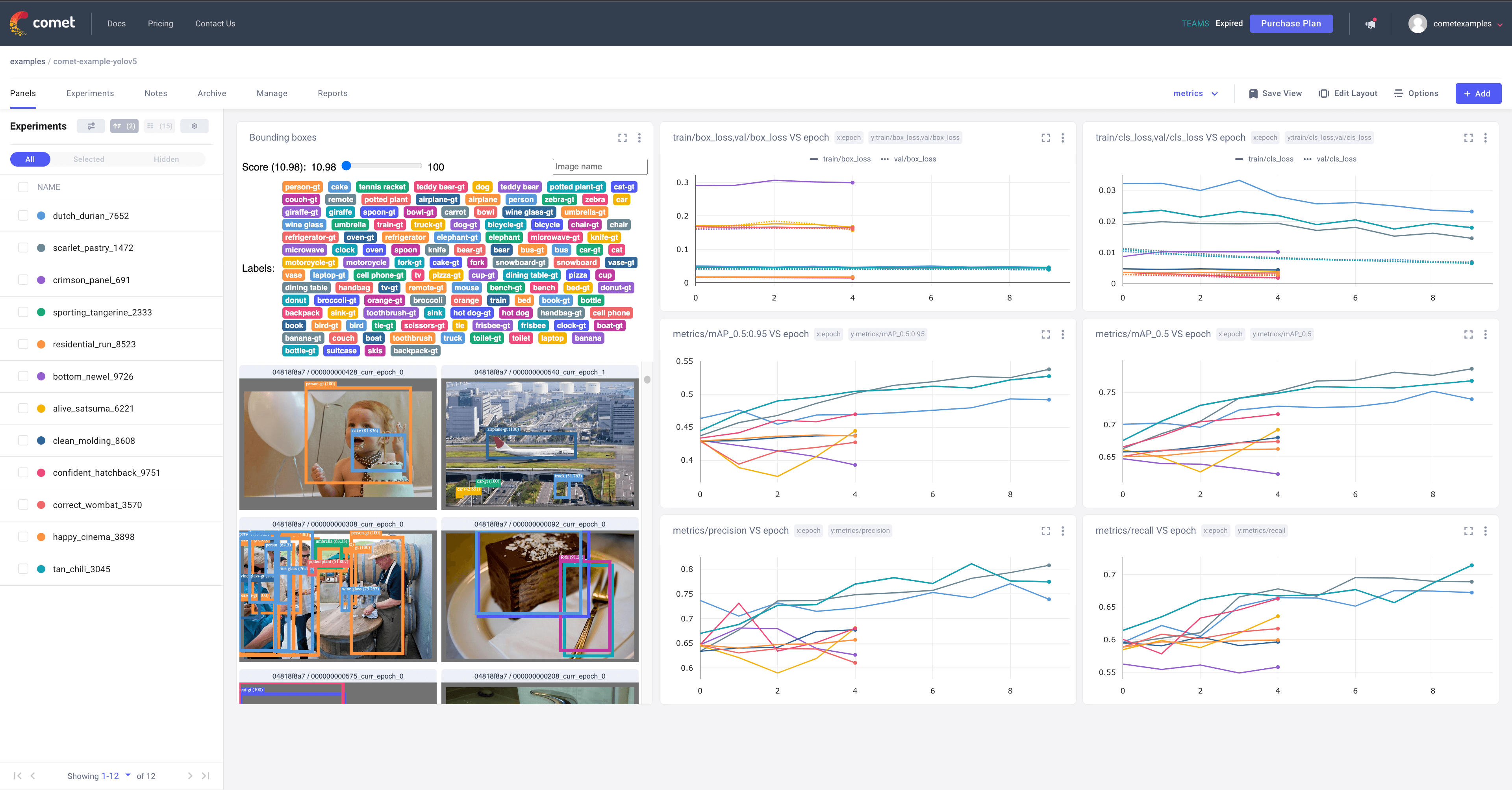
Comet लॉगिंग और विज़ुअलाइज़ेशन 🌟 नया
Comet अब पूरी तरह से एकीकृत है YOLOv5. वास्तविक समय में मॉडल मेट्रिक्स को ट्रैक और विज़ुअलाइज़ करें, अपने हाइपरपैरामीटर, डेटासेट और मॉडल चौकियों को सहेजें, और अपने मॉडल भविष्यवाणियों की कल्पना करें Comet कस्टम पैनल! Comet सुनिश्चित करता है कि आप अपने काम का ट्रैक कभी न खोएं और परिणाम साझा करना और सभी आकारों की टीमों में सहयोग करना आसान बनाता है!
आरंभ करना आसान है:
pip install comet_ml # 1. install
export COMET_API_KEY=<Your API Key> # 2. paste API key
python train.py --img 640 --epochs 3 --data coco128.yaml --weights yolov5s.pt # 3. train
सभी समर्थित के बारे में अधिक जानने के लिए Comet इस एकीकरण के लिए सुविधाएँ, देखें Comet अनुशिक्षण-कक्ष. यदि आप इसके बारे में अधिक जानना चाहते हैं Comet, हमारे सिर पर प्रलेखन. कोशिश करके शुरू करें Comet Colab नोटबुक: ![]()
ClearML लॉगिंग और स्वचालन 🌟 नया
ClearML में पूरी तरह से एकीकृत है YOLOv5 अपने प्रयोग को ट्रैक करने के लिए, डेटासेट संस्करणों को प्रबंधित करें और यहां तक कि दूरस्थ रूप से प्रशिक्षण रन निष्पादित करें। सक्षम करने के लिए ClearML:
pip install clearml- चलाना
clearml-initएक से कनेक्ट करने के लिए ClearML सर्वर
आपको प्रयोग प्रबंधक से सभी बेहतरीन अपेक्षित सुविधाएं मिलेंगी: लाइव अपडेट, मॉडल अपलोड, प्रयोग तुलना आदि। लेकिन ClearML उदाहरण के लिए अप्रतिबद्ध परिवर्तनों और स्थापित पैकेजों को भी ट्रैक करता है। इसके लिए धन्यवाद ClearML कार्य (जिसे हम प्रयोग कहते हैं) विभिन्न मशीनों पर भी प्रतिलिपि प्रस्तुत करने योग्य हैं! केवल 1 अतिरिक्त लाइन के साथ, हम एक शेड्यूल कर सकते हैं YOLOv5 एक कतार पर प्रशिक्षण कार्य किसी भी संख्या द्वारा निष्पादित किया जाना है ClearML एजेंट (श्रमिक)।
आप उपयोग कर सकते हैं ClearML आपके डेटासेट को संस्करण करने के लिए डेटा और फिर इसे पास करें YOLOv5 बस अपनी विशिष्ट आईडी का उपयोग करना। यह आपको अतिरिक्त परेशानी जोड़े बिना अपने डेटा पर नज़र रखने में मदद करेगा। अन्वेषण करें ClearML विवरण के लिए ट्यूटोरियल !

स्थानीय लॉगिंग
प्रशिक्षण परिणाम स्वचालित रूप से लॉग इन होते हैं टेन्सरबोर्ड और सीएसवी लकड़हारे को runs/train, प्रत्येक नए प्रशिक्षण के लिए बनाई गई एक नई प्रयोग निर्देशिका के साथ runs/train/exp2, runs/train/exp3आदि।
इस निर्देशिका में ट्रेन और वैल आँकड़े, मोज़ाइक, लेबल, भविष्यवाणियां और संवर्धित मोज़ाइक, साथ ही सटीक-याद (पीआर) घटता और भ्रम मैट्रिक्स सहित मैट्रिक्स और चार्ट शामिल हैं।

परिणाम फ़ाइल results.csv प्रत्येक युग के बाद अद्यतन किया जाता है, और फिर के रूप में प्लॉट किया जाता है results.png (नीचे) प्रशिक्षण पूरा होने के बाद। आप कोई भी प्लॉट कर सकते हैं results.csv मैन्युअल रूप से फ़ाइल:
from utils.plots import plot_results
plot_results("path/to/results.csv") # plot 'results.csv' as 'results.png'

अगले कदम
एक बार जब आपका मॉडल प्रशिक्षित हो जाता है तो आप अपने सर्वश्रेष्ठ चेकपॉइंट का उपयोग कर सकते हैं best.pt तक:
- चलाना CLI नहीं तो Python नई छवियों और वीडियो पर अनुमान
- ट्रेन, वैल और टेस्ट स्प्लिट पर सटीकता को मान्य करें
- को निर्यात करें TensorFlow, केरास, ONNX, लाइट, TF।जे एस CoreML और TensorRT स्वरूपों
- प्रदर्शन में सुधार के लिए हाइपरपैरामीटर विकसित करें
- वास्तविक दुनिया की छवियों का नमूना लेकर और उन्हें अपने डेटासेट में जोड़कर अपने मॉडल को बेहतर बनाएं
समर्थित वातावरण
Ultralytics उपयोग के लिए तैयार वातावरण की एक श्रृंखला प्रदान करता है, प्रत्येक आवश्यक निर्भरताओं के साथ पूर्व-स्थापित होता है जैसे कि CUDA, सीयूडीएनएन, Pythonऔर PyTorch, अपनी परियोजनाओं को किकस्टार्ट करने के लिए।
- उचित GPU नोटबुक:


- Google बादल: जीसीपी क्विकस्टार्ट गाइड
- Amazon: AWS क्विकस्टार्ट गाइड
- Azure: AzureML क्विकस्टार्ट गाइड
- बंदरगाह-मज़दूर: डॉकर क्विकस्टार्ट गाइड

परियोजना की स्थिति
![]()
यह बैज इंगित करता है कि सभी YOLOv5 GitHub क्रियाएँ सतत एकीकरण (CI) परीक्षण सफलतापूर्वक पास हो रहे हैं। ये सीआई परीक्षण सख्ती से कार्यक्षमता और प्रदर्शन की जांच करते हैं YOLOv5 विभिन्न प्रमुख पहलुओं के पार: प्रशिक्षण, सत्यापन, अनुमान, निर्यात और बेंचमार्क। वे macOS, Windows और Ubuntu पर लगातार और विश्वसनीय संचालन सुनिश्चित करते हैं, हर 24 घंटे में और प्रत्येक नई प्रतिबद्धता पर परीक्षण किए जाते हैं।
अक्सर पूछे जाने वाले प्रश्न
मैं कैसे प्रशिक्षित करूं YOLOv5 मेरे कस्टम डेटासेट पर?
प्रशिक्षण YOLOv5 कस्टम डेटासेट पर कई चरण शामिल हैं:
- अपना डेटासेट तैयार करें: छवियों को एकत्र और लेबल करें। जैसे उपकरणों का प्रयोग करें Roboflow डेटा व्यवस्थित करने और निर्यात करने के लिए YOLOv5 प्रारूप।
- सेटअप वातावरण: क्लोन करें YOLOv5 रेपो और स्थापना निर्भरताएं:
- डेटासेट कॉन्फ़िगरेशन बनाएँ: एक लिखें
dataset.yamlट्रेन / वैल पथ और वर्ग के नामों को परिभाषित करने वाली फ़ाइल। - मॉडल को प्रशिक्षित करें:
मैं अपने एनोटेट करने के लिए किन उपकरणों का उपयोग कर सकता हूं YOLOv5 डेटासेट?
आप उपयोग कर सकते हैं Roboflow एनोटेट, छवियों को लेबल करने के लिए एक सहज वेब-आधारित उपकरण। यह टीम सहयोग और निर्यात का समर्थन करता है YOLOv5 प्रारूप। छवियों को इकट्ठा करने के बाद, उपयोग करें Roboflow एनोटेशन को कुशलतापूर्वक बनाने और प्रबंधित करने के लिए। अन्य विकल्पों में स्थानीय एनोटेशन के लिए LabelImg और CVAT जैसे उपकरण शामिल हैं।
मुझे क्यों उपयोग करना चाहिए Ultralytics मेरे प्रशिक्षण के लिए हब YOLO मॉडल?
Ultralytics HUB प्रशिक्षण, तैनाती और प्रबंधन के लिए एंड-टू-एंड प्लेटफॉर्म प्रदान करता है YOLO व्यापक कोडिंग कौशल की आवश्यकता के बिना मॉडल। उपयोग करने के लाभ Ultralytics हब में शामिल हैं:
- आसान मॉडल प्रशिक्षण: पूर्व-कॉन्फ़िगर किए गए वातावरण के साथ प्रशिक्षण प्रक्रिया को सरल करता है।
- डेटा प्रबंधन: आसानी से डेटासेट और संस्करण नियंत्रण प्रबंधित करें।
- वास्तविक समय की निगरानी: जैसे उपकरणों को एकीकृत करता है Comet रीयल-टाइम मेट्रिक्स ट्रैकिंग और विज़ुअलाइज़ेशन के लिए।
- सहयोग: साझा संसाधनों और आसान प्रबंधन के साथ टीम परियोजनाओं के लिए आदर्श।
मैं अपने एनोटेट किए गए डेटा को कैसे परिवर्तित करूं YOLOv5 प्रारूप?
एनोटेट किए गए डेटा को YOLOv5 उपयोग करके स्वरूपित करें Roboflow:
- अपने डेटासेट को एक पर अपलोड करें Roboflow कार्यक्षेत्र।
- लेबल छवियाँ यदि पहले से लेबल नहीं हैं।
- उत्पन्न और निर्यात करें डेटासेट में
YOLOv5 Pytorchप्रारूप। सुनिश्चित करें कि ऑटो-ओरिएंट और आकार बदलें (खिंचाव) जैसे वर्ग इनपुट आकार (जैसे, 640x640) पर लागू होते हैं। - डेटासेट डाउनलोड करें और इसे अपने YOLOv5 प्रशिक्षण स्क्रिप्ट।
उपयोग करने के लिए लाइसेंसिंग विकल्प क्या हैं YOLOv5 वाणिज्यिक अनुप्रयोगों में?
Ultralytics दो लाइसेंसिंग विकल्प प्रदान करता है:
- AGPL-3.0 लाइसेंस: गैर-व्यावसायिक उपयोग के लिए उपयुक्त एक ओपन-सोर्स लाइसेंस, छात्रों और उत्साही लोगों के लिए आदर्श।
- एंटरप्राइज़ लाइसेंस: एकीकृत करने के इच्छुक व्यवसायों के लिए सिलवाया गया YOLOv5 वाणिज्यिक उत्पादों और सेवाओं में। विस्तृत जानकारी के लिए, हमारे लाइसेंसिंग पृष्ठ पर जाएँ.
अधिक जानकारी के लिए, हमारे गाइड को देखें Ultralytics लाइसेंसिंग।