जमी हुई परतों के साथ सीखने को स्थानांतरित करें
📚 यह मार्गदर्शिका बताती है कि फ्रीज कैसे करें YOLOv5 🚀 सीखने को स्थानांतरित करते समय परतें। स्थानांतरण सीखना पूरे नेटवर्क को फिर से प्रशिक्षित किए बिना नए डेटा पर एक मॉडल को जल्दी से फिर से प्रशिक्षित करने का एक उपयोगी तरीका है। इसके बजाय, प्रारंभिक वजन का हिस्सा जगह में जमे हुए हैं, और बाकी वजन का उपयोग नुकसान की गणना करने के लिए किया जाता है और अनुकूलक द्वारा अपडेट किया जाता है। इसके लिए सामान्य प्रशिक्षण की तुलना में कम संसाधनों की आवश्यकता होती है और तेजी से प्रशिक्षण समय की अनुमति मिलती है, हालांकि इसके परिणामस्वरूप अंतिम प्रशिक्षित सटीकता में कमी भी हो सकती है।
शुरू करने से पहले
रेपो को क्लोन करें और requirements.txt को एक में स्थापित करें Python> = 3.8.0 पर्यावरण, सहित PyTorch>=1.8। मॉडल और डेटासेट नवीनतम से स्वचालित रूप से डाउनलोड होते हैं YOLOv5 रिलीज।
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
फ्रीज बैकबोन
सभी परतें जो train.py से मेल खाती हैं freeze प्रशिक्षण शुरू होने से पहले उनके ग्रेडिएंट को शून्य पर सेट करके train.py में सूची को फ्रीज कर दिया जाएगा।
# Freeze
freeze = [f"model.{x}." for x in range(freeze)] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
print(f"freezing {k}")
v.requires_grad = False
मॉड्यूल नामों की सूची देखने के लिए:
for k, v in model.named_parameters():
print(k)
"""Output:
model.0.conv.conv.weight
model.0.conv.bn.weight
model.0.conv.bn.bias
model.1.conv.weight
model.1.bn.weight
model.1.bn.bias
model.2.cv1.conv.weight
model.2.cv1.bn.weight
...
model.23.m.0.cv2.bn.weight
model.23.m.0.cv2.bn.bias
model.24.m.0.weight
model.24.m.0.bias
model.24.m.1.weight
model.24.m.1.bias
model.24.m.2.weight
model.24.m.2.bias
"""
मॉडल आर्किटेक्चर को देखते हुए हम देख सकते हैं कि मॉडल बैकबोन परतें 0-9 हैं:
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
- [-1, 1, Conv, [64, 6, 2, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C3, [128]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C3, [256]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 9, C3, [512]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C3, [1024]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv5 v6.0 head
head:
- [-1, 1, Conv, [512, 1, 1]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C3, [512, False]] # 13
- [-1, 1, Conv, [256, 1, 1]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C3, [256, False]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 3, C3, [512, False]] # 20 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C3, [1024, False]] # 23 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
इसलिए हम फ्रीज सूची को परिभाषित कर सकते हैं जिसमें सभी मॉड्यूल 'model.0.' - 'model.9.' के साथ उनके नाम हैं:
सभी परतों को फ्रीज करें
Detect() में अंतिम आउटपुट कनवल्शन परतों को छोड़कर पूर्ण मॉडल को फ्रीज करने के लिए, हम 'model.0.' - 'model.23.' के साथ सभी मॉड्यूल को शामिल करने के लिए फ्रीज सूची सेट करते हैं।
परिणाम
हम उपरोक्त दोनों परिदृश्यों पर VOC पर YOLOv5m को प्रशिक्षित करते हैं, साथ ही एक डिफ़ॉल्ट मॉडल (कोई ठंड नहीं) के साथ, आधिकारिक COCO पूर्वप्रशिक्षित से शुरू होता है --weights yolov5m.pt:
train.py --batch 48 --weights yolov5m.pt --data voc.yaml --epochs 50 --cache --img 512 --hyp hyp.finetune.yaml
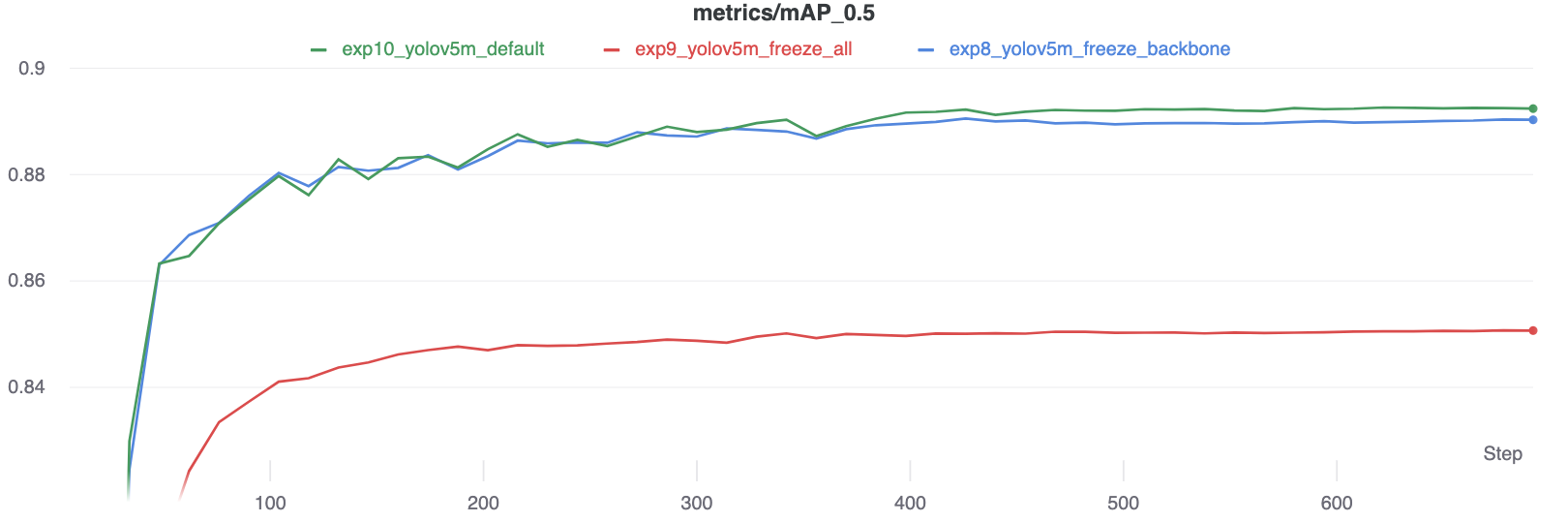
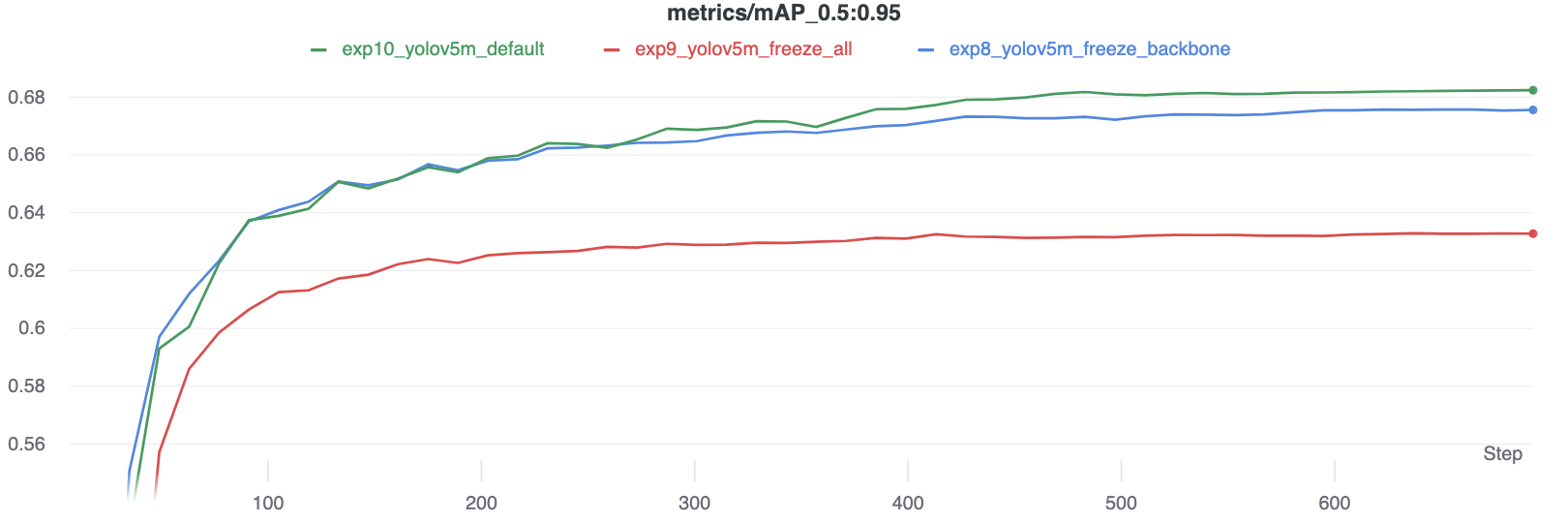
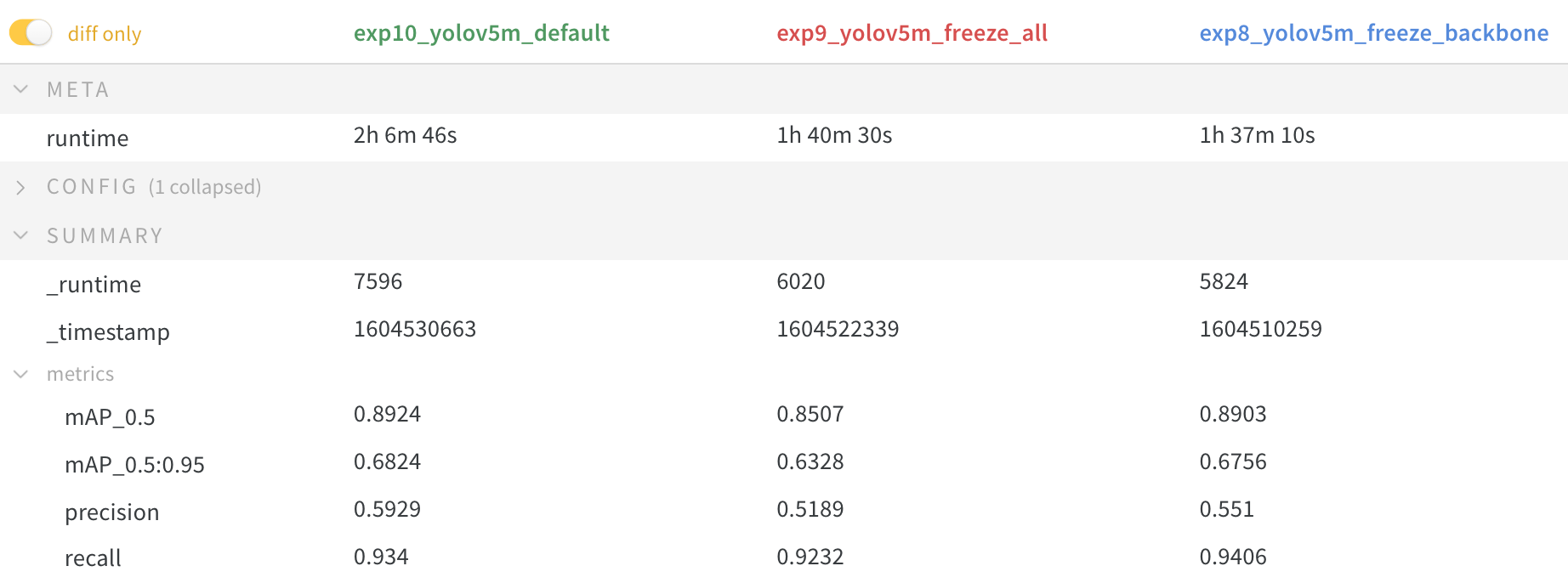
सटीकता तुलना
परिणाम बताते हैं कि ठंड प्रशिक्षण को गति देती है, लेकिन अंतिम सटीकता को थोड़ा कम कर देती है।
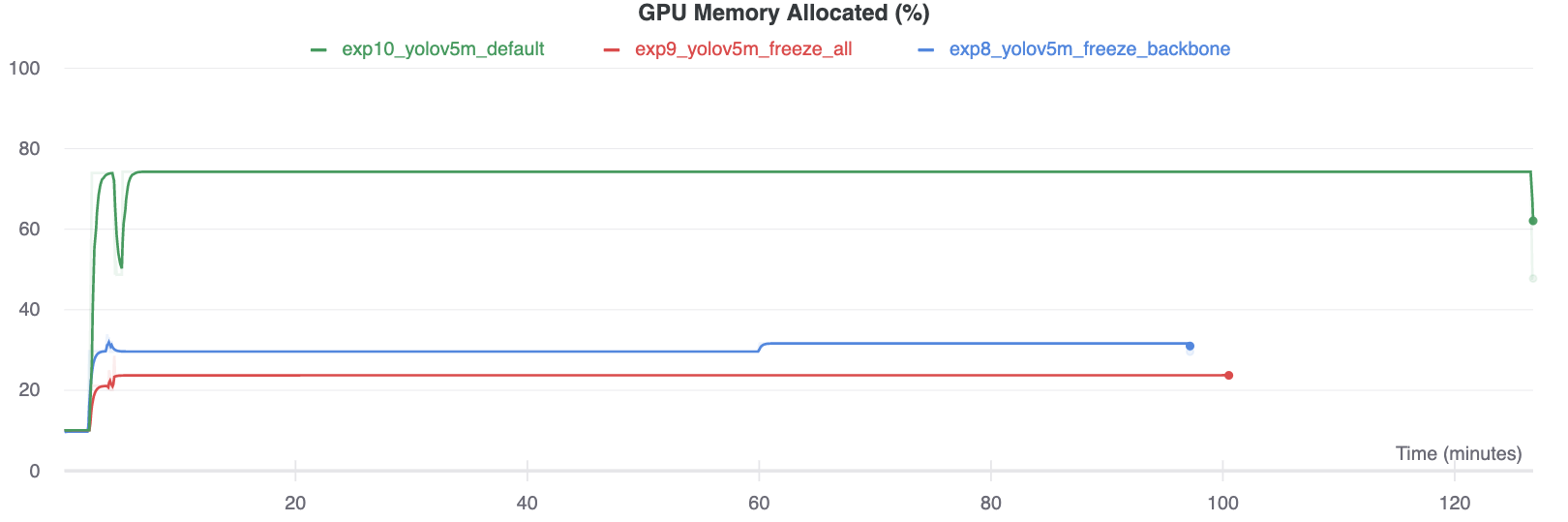
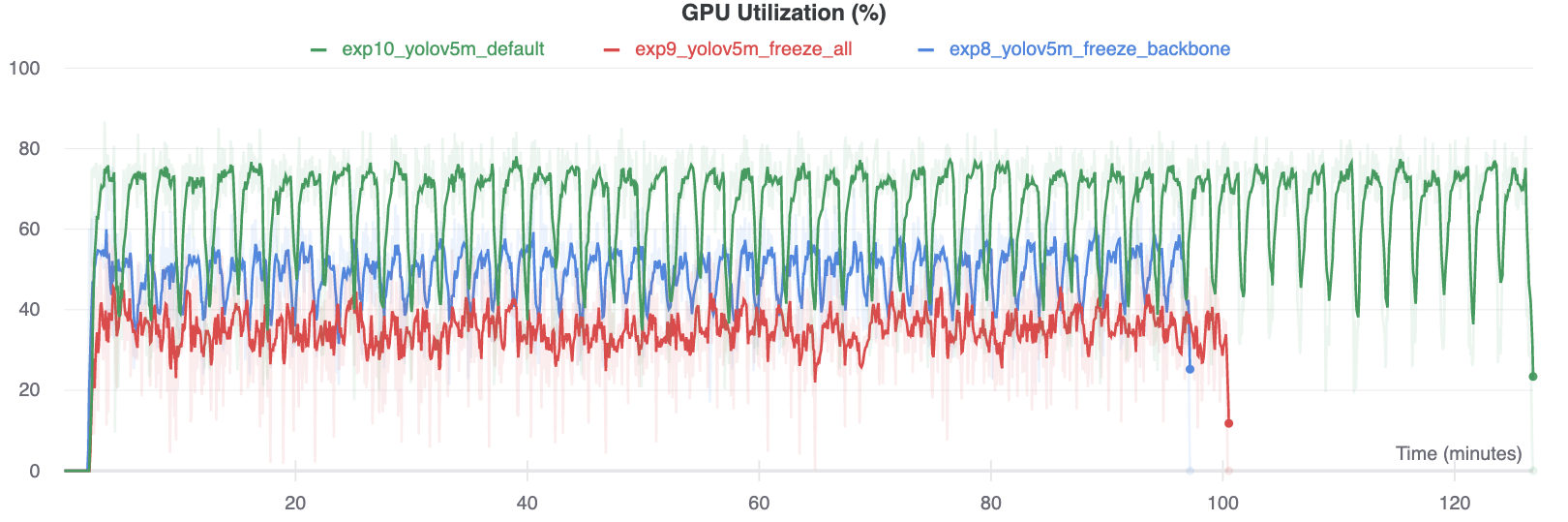
GPU उपयोग की तुलना
दिलचस्प बात यह है कि जितने अधिक मॉड्यूल जमे हुए होते हैं उतने कम होते हैं GPU प्रशिक्षित करने के लिए मेमोरी की आवश्यकता होती है, और कम GPU उपयोग। यह इंगित करता है कि बड़े मॉडल, या बड़े --छवि-आकार में प्रशिक्षित मॉडल तेजी से प्रशिक्षित करने के लिए ठंड से लाभ उठा सकते हैं।
समर्थित वातावरण
Ultralytics उपयोग के लिए तैयार वातावरण की एक श्रृंखला प्रदान करता है, प्रत्येक आवश्यक निर्भरताओं के साथ पूर्व-स्थापित होता है जैसे कि CUDA, सीयूडीएनएन, Pythonऔर PyTorch, अपनी परियोजनाओं को किकस्टार्ट करने के लिए।
- उचित GPU नोटबुक:



- Google बादल: जीसीपी क्विकस्टार्ट गाइड
- Amazon: AWS क्विकस्टार्ट गाइड
- Azure: AzureML क्विकस्टार्ट गाइड
- बंदरगाह-मज़दूर: डॉकर क्विकस्टार्ट गाइड

परियोजना की स्थिति
![]()
यह बैज इंगित करता है कि सभी YOLOv5 GitHub क्रियाएँ सतत एकीकरण (CI) परीक्षण सफलतापूर्वक पास हो रहे हैं। ये सीआई परीक्षण सख्ती से कार्यक्षमता और प्रदर्शन की जांच करते हैं YOLOv5 विभिन्न प्रमुख पहलुओं के पार: प्रशिक्षण, सत्यापन, अनुमान, निर्यात और बेंचमार्क। वे macOS, Windows और Ubuntu पर लगातार और विश्वसनीय संचालन सुनिश्चित करते हैं, हर 24 घंटे में और प्रत्येक नई प्रतिबद्धता पर परीक्षण किए जाते हैं।