हाइपरपैरामीटर विकास
📚 यह मार्गदर्शिका हाइपरपैरामीटर विकास के लिए बताती है YOLOv5 🚀 हाइपरपैरामीटर विकास अनुकूलन के लिए जेनेटिक एल्गोरिथम (जीए) का उपयोग करके हाइपरपैरामीटर अनुकूलन की एक विधि है।
एमएल में हाइपरपैरामीटर प्रशिक्षण के विभिन्न पहलुओं को नियंत्रित करते हैं, और उनके लिए इष्टतम मूल्य खोजना एक चुनौती हो सकती है। ग्रिड खोजों जैसे पारंपरिक तरीके 1) उच्च आयामी खोज स्थान 2) आयामों के बीच अज्ञात सहसंबंध, और 3) प्रत्येक बिंदु पर फिटनेस का मूल्यांकन करने की महंगी प्रकृति के कारण जल्दी से असभ्य हो सकते हैं, जिससे जीए हाइपरपैरामीटर खोजों के लिए उपयुक्त उम्मीदवार बन जाता है।
शुरू करने से पहले
रेपो को क्लोन करें और requirements.txt को एक में स्थापित करें Python> = 3.8.0 पर्यावरण, सहित PyTorch>=1.8। मॉडल और डेटासेट नवीनतम से स्वचालित रूप से डाउनलोड होते हैं YOLOv5 रिलीज।
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
1. हाइपरपैरामीटर प्रारंभ करें
YOLOv5 विभिन्न प्रशिक्षण सेटिंग्स के लिए उपयोग किए जाने वाले लगभग 30 हाइपरपैरामीटर हैं। इन्हें में परिभाषित किया गया है *.yaml में फ़ाइलें /data/hyps डायरेक्टरी। बेहतर प्रारंभिक अनुमान बेहतर अंतिम परिणाम देंगे, इसलिए विकसित होने से पहले इन मूल्यों को ठीक से प्रारंभ करना महत्वपूर्ण है। यदि संदेह है, तो बस डिफ़ॉल्ट मानों का उपयोग करें, जो इसके लिए अनुकूलित हैं YOLOv5 खरोंच से COCO प्रशिक्षण।
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Hyperparameters for low-augmentation COCO training from scratch
# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear
# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)
2. फिटनेस को परिभाषित करें
फिटनेस वह मूल्य है जिसे हम अधिकतम करना चाहते हैं। में YOLOv5 हम एक डिफ़ॉल्ट फिटनेस फ़ंक्शन को मीट्रिक के भारित संयोजन के रूप में परिभाषित करते हैं: mAP@0.5 वजन का 10% योगदान देता है और mAP@0.5:0.95 शेष 90% का योगदान देता है, के साथ यथार्थता P और याद करते हैं R अन्यमनस्क। आप इन्हें समायोजित कर सकते हैं जैसा कि आप फिट देखते हैं या उपयोग/metrics.py (अनुशंसित) में डिफ़ॉल्ट फिटनेस परिभाषा का उपयोग कर सकते हैं।
def fitness(x):
"""Return model fitness as the sum of weighted metrics [P, R, mAP@0.5, mAP@0.5:0.95]."""
w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
return (x[:, :4] * w).sum(1)
3. विकसित
विकास एक आधार परिदृश्य के बारे में किया जाता है जिसे हम सुधारना चाहते हैं। इस उदाहरण में आधार परिदृश्य पूर्व-प्रशिक्षित YOLOv10s का उपयोग करके 5 युगों के लिए COCO128 को परिष्कृत कर रहा है। आधार परिदृश्य प्रशिक्षण आदेश है:
हाइपरपैरामीटर विकसित करने के लिए इस परिदृश्य के लिए विशिष्ट, में परिभाषित हमारे प्रारंभिक मूल्यों से शुरू धारा 1., और में परिभाषित फिटनेस को अधिकतम करना धारा 2.संलग्न --evolve:
# Single-GPU
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve
# Multi-GPU
for i in 0 1 2 3 4 5 6 7; do
sleep $(expr 30 \* $i) && # 30-second delay (optional)
echo 'Starting GPU '$i'...' &&
nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --device $i --evolve > evolve_gpu_$i.log &
done
# Multi-GPU bash-while (not recommended)
for i in 0 1 2 3 4 5 6 7; do
sleep $(expr 30 \* $i) && # 30-second delay (optional)
echo 'Starting GPU '$i'...' &&
"$(while true; do nohup python train.py... --device $i --evolve 1 > evolve_gpu_$i.log; done)" &
done
डिफ़ॉल्ट विकास सेटिंग्स आधार परिदृश्य को 300 बार चलेंगी, यानी 300 पीढ़ियों के लिए। आप के माध्यम से पीढ़ियों को संशोधित कर सकते हैं --evolve तर्क, अर्थात। python train.py --evolve 1000.
मुख्य आनुवंशिक ऑपरेटर हैं क्रॉसओवर और उत्परिवर्तन. इस कार्य में उत्परिवर्तन का उपयोग 80% संभावना और 0.04 विचरण के साथ किया जाता है, जो पिछली सभी पीढ़ियों के सर्वश्रेष्ठ माता-पिता के संयोजन के आधार पर नई संतान पैदा करता है। परिणाम लॉग इन हैं runs/evolve/exp/evolve.csv, और उच्चतम फिटनेस संतान को हर पीढ़ी के रूप में बचाया जाता है runs/evolve/hyp_evolved.yaml:
# YOLOv5 Hyperparameter Evolution Results
# Best generation: 287
# Last generation: 300
# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss
# 0.54634, 0.55625, 0.58201, 0.33665, 0.056451, 0.042892, 0.013441
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)
हम सर्वोत्तम परिणामों के लिए विकास की न्यूनतम 300 पीढ़ियों की सलाह देते हैं। ध्यान दें कि विकास आम तौर पर महंगा और समय लेने वाला होता है, क्योंकि आधार परिदृश्य को सैकड़ों बार प्रशिक्षित किया जाता है, संभवतः सैकड़ों या हजारों की आवश्यकता होती है GPU घंटे।
4. विज़ुअलाइज़ करें
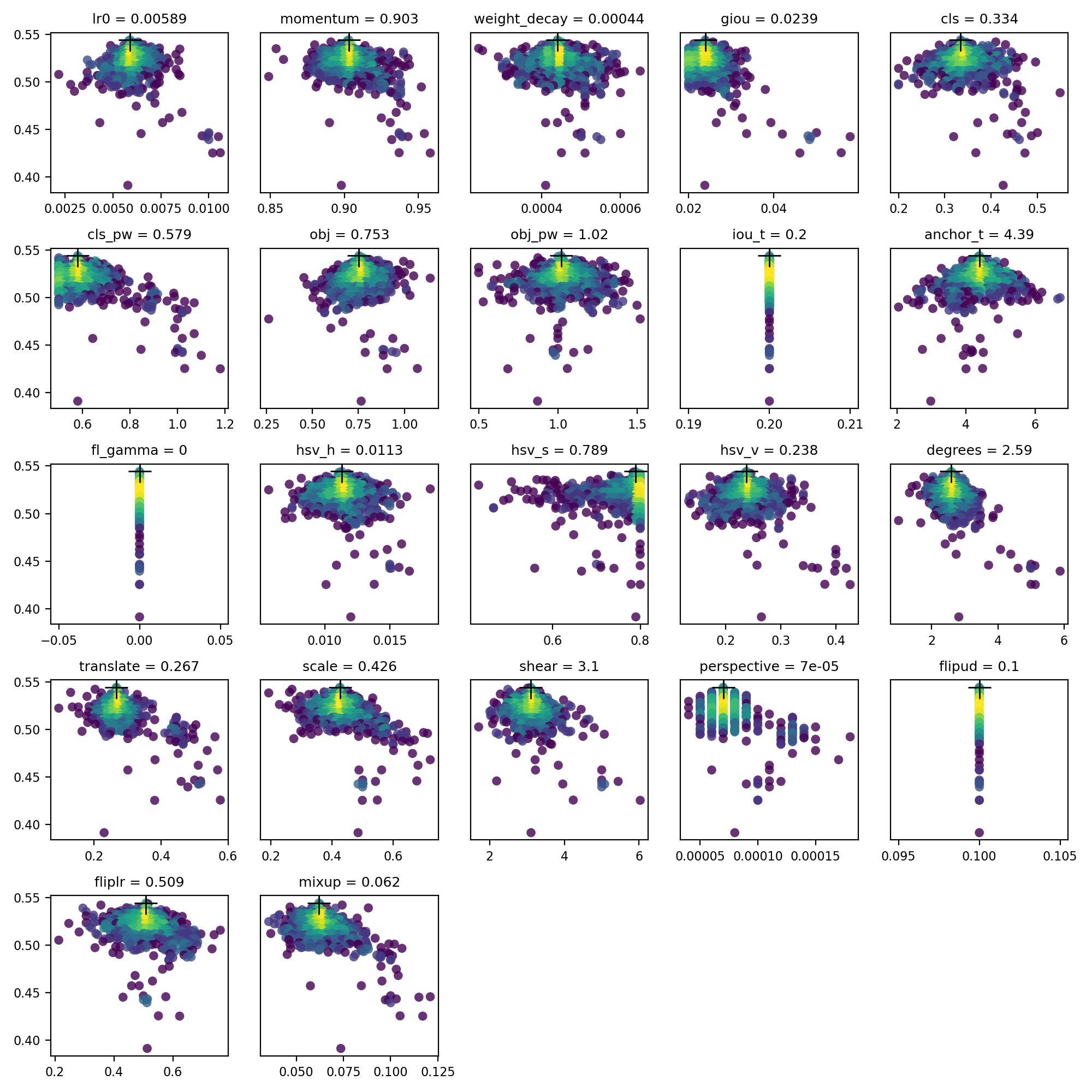
evolve.csv के रूप में प्लॉट किया गया है evolve.png द्वारा utils.plots.plot_evolve() विकास के बाद फिटनेस (वाई-अक्ष) बनाम हाइपरपैरामीटर मान (एक्स-अक्ष) दिखाते हुए हाइपरपैरामीटर प्रति एक सबप्लॉट के साथ समाप्त होता है। पीला उच्च सांद्रता को इंगित करता है। ऊर्ध्वाधर वितरण इंगित करते हैं कि एक पैरामीटर अक्षम कर दिया गया है और उत्परिवर्तित नहीं होता है। यह उपयोगकर्ता में चयन योग्य है meta train.py में शब्दकोश, और मापदंडों को ठीक करने और उन्हें विकसित होने से रोकने के लिए उपयोगी है।
समर्थित वातावरण
Ultralytics उपयोग के लिए तैयार वातावरण की एक श्रृंखला प्रदान करता है, प्रत्येक आवश्यक निर्भरताओं के साथ पूर्व-स्थापित होता है जैसे कि CUDA, सीयूडीएनएन, Pythonऔर PyTorch, अपनी परियोजनाओं को किकस्टार्ट करने के लिए।
- उचित GPU नोटबुक:



- Google बादल: जीसीपी क्विकस्टार्ट गाइड
- Amazon: AWS क्विकस्टार्ट गाइड
- Azure: AzureML क्विकस्टार्ट गाइड
- बंदरगाह-मज़दूर: डॉकर क्विकस्टार्ट गाइड

परियोजना की स्थिति
![]()
यह बैज इंगित करता है कि सभी YOLOv5 GitHub क्रियाएँ सतत एकीकरण (CI) परीक्षण सफलतापूर्वक पास हो रहे हैं। ये सीआई परीक्षण सख्ती से कार्यक्षमता और प्रदर्शन की जांच करते हैं YOLOv5 विभिन्न प्रमुख पहलुओं के पार: प्रशिक्षण, सत्यापन, अनुमान, निर्यात और बेंचमार्क। वे macOS, Windows और Ubuntu पर लगातार और विश्वसनीय संचालन सुनिश्चित करते हैं, हर 24 घंटे में और प्रत्येक नई प्रतिबद्धता पर परीक्षण किए जाते हैं।