Ultralytics YOLOv5 स्थापत्यशैली
YOLOv5 (v6.0/6.1) किसके द्वारा विकसित एक शक्तिशाली ऑब्जेक्ट डिटेक्शन एल्गोरिथ्म है? Ultralytics. यह लेख गहराई में गोता लगाता है YOLOv5 वास्तुकला, डेटा वृद्धि रणनीतियाँ, प्रशिक्षण पद्धतियाँ और हानि गणना तकनीक। यह व्यापक समझ निगरानी, स्वायत्त वाहनों और छवि पहचान सहित विभिन्न क्षेत्रों में वस्तु का पता लगाने के आपके व्यावहारिक अनुप्रयोग को बेहतर बनाने में मदद करेगी।
1. मॉडल संरचना
YOLOv5वास्तुकला में तीन मुख्य भाग होते हैं:
- मेरुदंड: यह नेटवर्क का मुख्य भाग है। के लिए YOLOv5, रीढ़ की हड्डी का उपयोग करके डिज़ाइन किया गया है
New CSP-Darknet53संरचना, पिछले संस्करणों में उपयोग किए जाने वाले डार्कनेट आर्किटेक्चर का एक संशोधन। - गरदन: यह हिस्सा रीढ़ और सिर को जोड़ता है। में YOLOv5,
SPPFऔरNew CSP-PANसंरचनाओं का उपयोग किया जाता है। - सिर: यह हिस्सा अंतिम आउटपुट उत्पन्न करने के लिए जिम्मेदार है। YOLOv5 का उपयोग करता है
YOLOv3 Headइस उद्देश्य के लिए।
मॉडल की संरचना को नीचे दी गई छवि में दर्शाया गया है। मॉडल संरचना विवरण में पाया जा सकता है yolov5l.yaml.
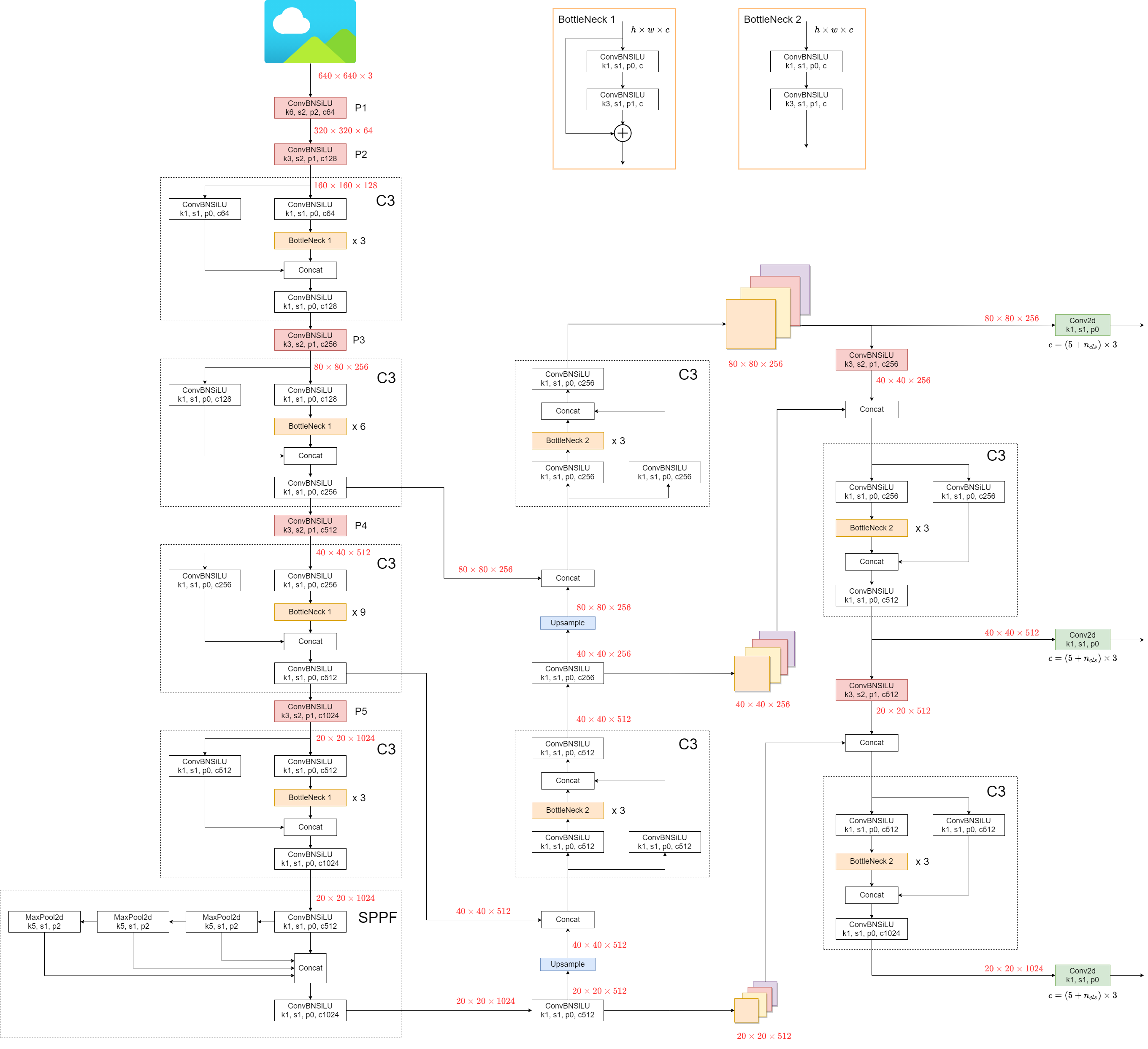
YOLOv5 अपने पूर्ववर्तियों की तुलना में कुछ मामूली बदलाव पेश करता है:
- वही
Focusसंरचना, पहले के संस्करणों में पाया जाता है, एक के साथ बदल दिया जाता है6x6 Conv2dसुव्यवस्थित करना। यह परिवर्तन दक्षता को बढ़ाता है #4825. - वही
SPPसंरचना के साथ बदल दिया गया हैSPPF. यह परिवर्तन प्रसंस्करण की गति को दोगुना से अधिक करता है।
की गति का परीक्षण करने के लिए SPP और SPPF, निम्नलिखित कोड का उपयोग किया जा सकता है:
एसपीपी बनाम एसपीपीएफ स्पीड प्रोफाइलिंग उदाहरण (खोलने के लिए क्लिक करें)
import time
import torch
import torch.nn as nn
class SPP(nn.Module):
def __init__(self):
"""Initializes an SPP module with three different sizes of max pooling layers."""
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
"""Applies three max pooling layers on input `x` and concatenates results along channel dimension."""
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3], dim=1)
class SPPF(nn.Module):
def __init__(self):
"""Initializes an SPPF module with a specific configuration of MaxPool2d layer."""
super().__init__()
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
def forward(self, x):
"""Applies sequential max pooling and concatenates results with input tensor."""
o1 = self.maxpool(x)
o2 = self.maxpool(o1)
o3 = self.maxpool(o2)
return torch.cat([x, o1, o2, o3], dim=1)
def main():
"""Compares outputs and performance of SPP and SPPF on a random tensor (8, 32, 16, 16)."""
input_tensor = torch.rand(8, 32, 16, 16)
spp = SPP()
sppf = SPPF()
output1 = spp(input_tensor)
output2 = sppf(input_tensor)
print(torch.equal(output1, output2))
t_start = time.time()
for _ in range(100):
spp(input_tensor)
print(f"SPP time: {time.time() - t_start}")
t_start = time.time()
for _ in range(100):
sppf(input_tensor)
print(f"SPPF time: {time.time() - t_start}")
if __name__ == "__main__":
main()
2. डेटा वृद्धि तकनीक
YOLOv5 ओवरफिटिंग को सामान्य बनाने और कम करने के लिए मॉडल की क्षमता में सुधार करने के लिए विभिन्न डेटा वृद्धि तकनीकों को नियोजित करता है। इन तकनीकों में शामिल हैं:
-
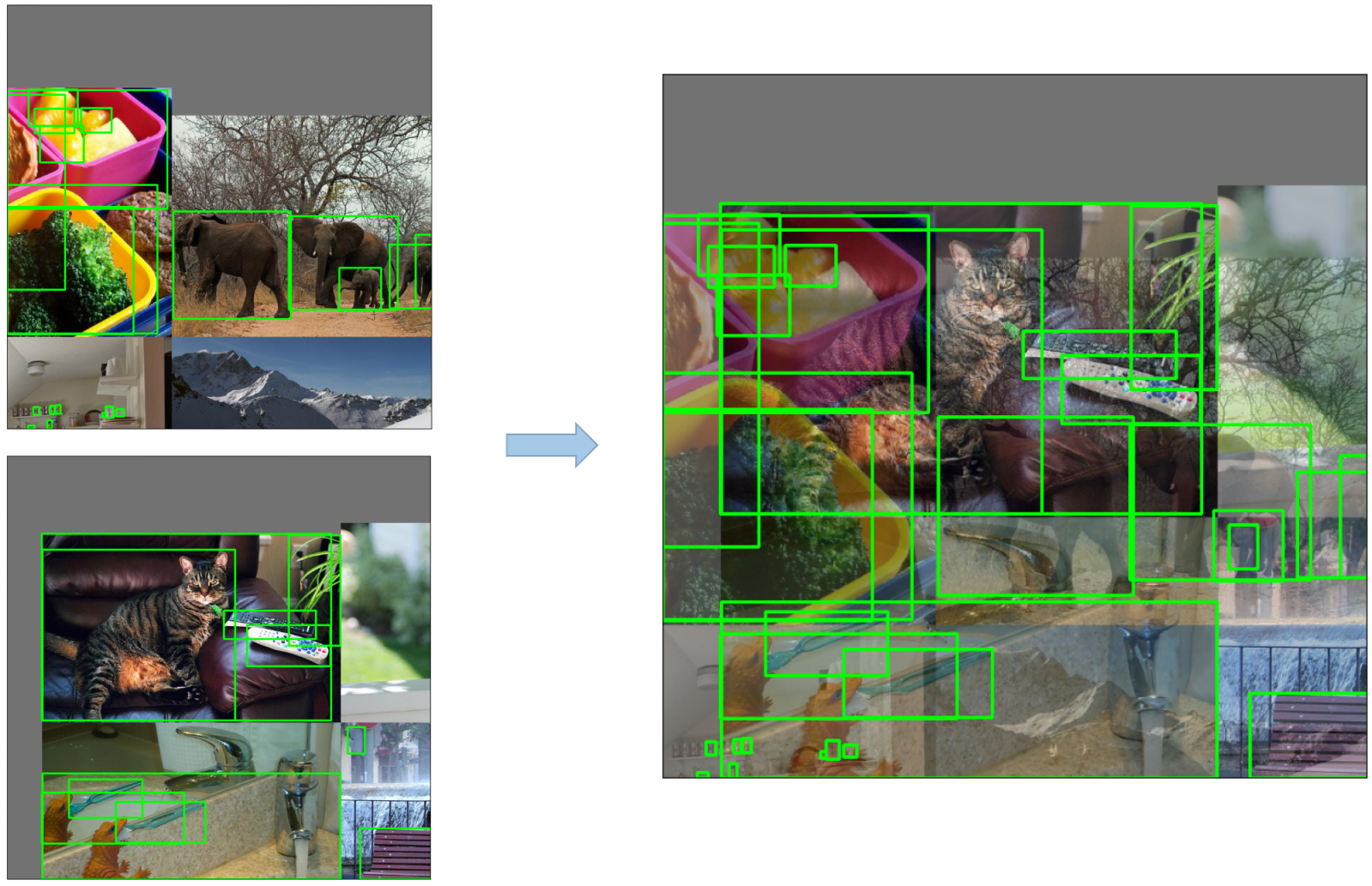
मोज़ेक ऑग्मेंटेशन: एक इमेज प्रोसेसिंग तकनीक जो चार प्रशिक्षण छवियों को एक में जोड़ती है जो ऑब्जेक्ट डिटेक्शन मॉडल को विभिन्न ऑब्जेक्ट स्केल और अनुवादों को बेहतर ढंग से संभालने के लिए प्रोत्साहित करती है।

-
कॉपी-पेस्ट ऑग्मेंटेशन: एक अभिनव डेटा वृद्धि विधि जो एक छवि से यादृच्छिक पैच की प्रतिलिपि बनाती है और उन्हें एक और यादृच्छिक रूप से चुनी गई छवि पर चिपकाती है, प्रभावी रूप से एक नया प्रशिक्षण नमूना उत्पन्न करती है।

-
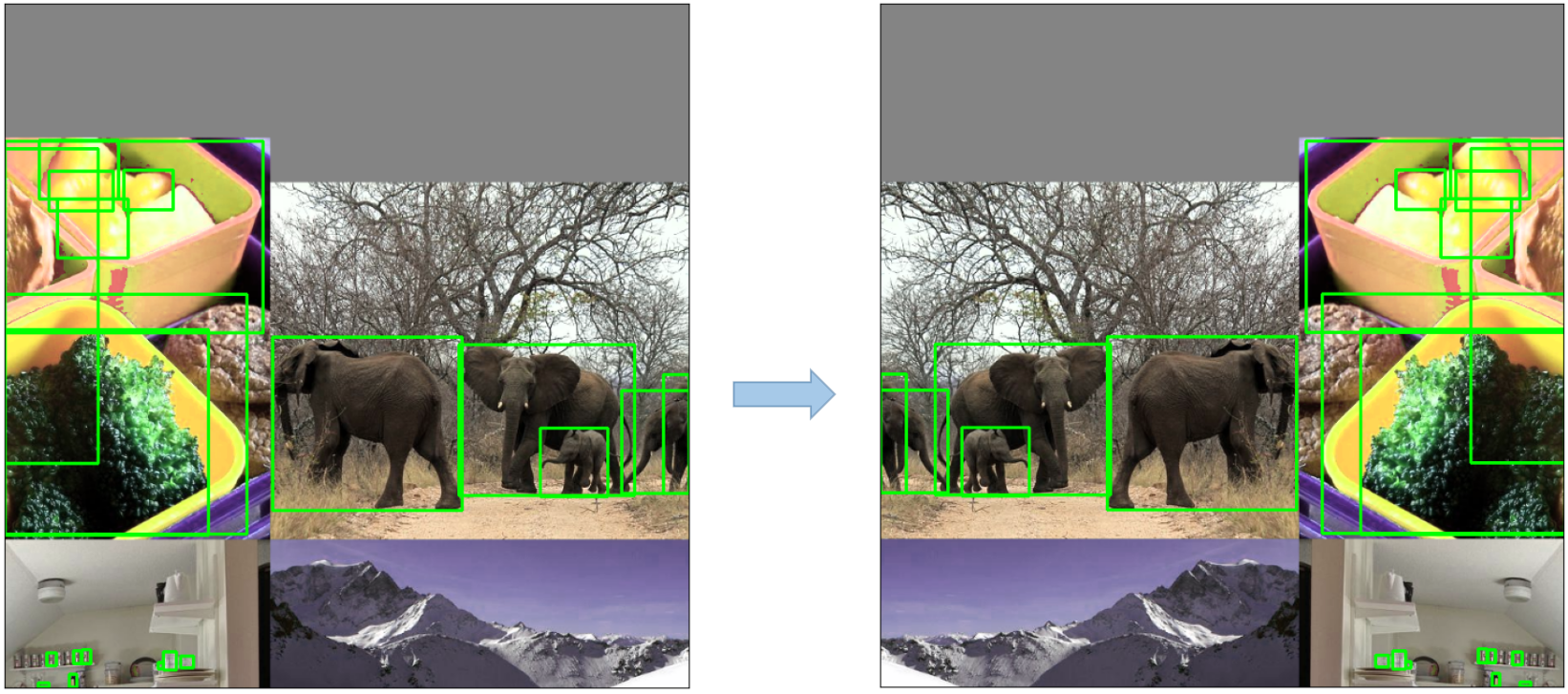
रैंडम एफिन ट्रांसफॉर्मेशन: इसमें छवियों का यादृच्छिक रोटेशन, स्केलिंग, अनुवाद और बाल काटना शामिल है।

-
मिक्सअप ऑग्मेंटेशन: एक विधि जो दो छवियों और उनके संबंधित लेबल का रैखिक संयोजन लेकर समग्र छवियां बनाती है।
-
एल्बममेंटेशन: छवि वृद्धि के लिए एक शक्तिशाली पुस्तकालय जो विभिन्न प्रकार की वृद्धि तकनीकों का समर्थन करता है।
-
एचएसवी वृद्धि: छवियों के रंग, संतृप्ति और मूल्य में यादृच्छिक परिवर्तन।

-
रैंडम हॉरिजॉन्टल फ्लिप: एक ऑग्मेंटेशन विधि जो छवियों को क्षैतिज रूप से बेतरतीब ढंग से फ़्लिप करती है।
3. प्रशिक्षण रणनीतियाँ
YOLOv5 मॉडल के प्रदर्शन को बढ़ाने के लिए कई परिष्कृत प्रशिक्षण रणनीतियों को लागू करता है। उनमे शामिल है:
- मल्टीस्केल ट्रेनिंग: प्रशिक्षण प्रक्रिया के दौरान इनपुट छवियों को उनके मूल आकार के 0.5 से 1.5 गुना की सीमा के भीतर बेतरतीब ढंग से रीस्केल किया जाता है।
- ऑटोएंकर: यह रणनीति आपके कस्टम डेटा में जमीनी सच्चाई बक्से की सांख्यिकीय विशेषताओं से मेल खाने के लिए पूर्व एंकर बॉक्स का अनुकूलन करती है।
- वार्मअप और कोसाइन एलआर शेड्यूलर: मॉडल प्रदर्शन को बढ़ाने के लिए सीखने की दर को समायोजित करने की एक विधि।
- घातांकीय मूविंग एवरेज (ईएमए): एक रणनीति जो प्रशिक्षण प्रक्रिया को स्थिर करने और सामान्यीकरण त्रुटि को कम करने के लिए पिछले चरणों में मापदंडों के औसत का उपयोग करती है।
- मिश्रित परिशुद्धता प्रशिक्षण: अर्ध-सटीक प्रारूप में संचालन करने की एक विधि, स्मृति उपयोग को कम करने और कम्प्यूटेशनल गति को बढ़ाने के लिए।
- हाइपरपैरामीटर इवोल्यूशन: इष्टतम प्रदर्शन प्राप्त करने के लिए हाइपरपैरामीटर को स्वचालित रूप से ट्यून करने की रणनीति।
4. अतिरिक्त सुविधाएँ
4.1 नुकसान की गणना करें
में नुकसान YOLOv5 तीन व्यक्तिगत हानि घटकों के संयोजन के रूप में गणना की जाती है:
- वर्ग हानि (बीसीई हानि): बाइनरी क्रॉस-एन्ट्रॉपी हानि, वर्गीकरण कार्य के लिए त्रुटि को मापता है।
- ऑब्जेक्टनेस लॉस (बीसीई लॉस): एक और बाइनरी क्रॉस-एंट्रॉपी नुकसान, यह पता लगाने में त्रुटि की गणना करता है कि कोई वस्तु किसी विशेष ग्रिड सेल में मौजूद है या नहीं।
- स्थान हानि (CIoU हानि): पूर्ण IoU हानि, ग्रिड सेल के भीतर ऑब्जेक्ट को स्थानीयकृत करने में त्रुटि को मापता है।
समग्र हानि समारोह द्वारा दर्शाया गया है:
4.2 शेष नुकसान
तीन भविष्यवाणी परतों की वस्तुनिष्ठता हानि (P3, P4, P5) को अलग तरह से भारित किया जाता है। शेष भार हैं [4.0, 1.0, 0.4] क्रमानुसार। यह दृष्टिकोण सुनिश्चित करता है कि विभिन्न पैमानों पर भविष्यवाणियां कुल नुकसान में उचित योगदान देती हैं।
4.3 ग्रिड संवेदनशीलता को दूर करें
वही YOLOv5 आर्किटेक्चर के पिछले संस्करणों की तुलना में बॉक्स भविष्यवाणी रणनीति में कुछ महत्वपूर्ण बदलाव करता है YOLO. YOLOv2 और YOLOv3 में, अंतिम परत के सक्रियण का उपयोग करके बॉक्स निर्देशांक की सीधे भविष्यवाणी की गई थी।

हालांकि, में YOLOv5, बॉक्स निर्देशांक की भविष्यवाणी करने के सूत्र को ग्रिड संवेदनशीलता को कम करने और मॉडल को असीमित बॉक्स आयामों की भविष्यवाणी करने से रोकने के लिए अद्यतन किया गया है।
अनुमानित बाउंडिंग बॉक्स की गणना के लिए संशोधित सूत्र इस प्रकार हैं:
स्केलिंग से पहले और बाद में केंद्र बिंदु ऑफसेट की तुलना करें। केंद्र बिंदु ऑफ़सेट सीमा (0, 1) से (-0.5, 1.5) तक समायोजित की जाती है। इसलिए, ऑफसेट आसानी से 0 या 1 प्राप्त कर सकता है।

समायोजन से पहले और बाद में ऊंचाई और चौड़ाई स्केलिंग अनुपात (लंगर के सापेक्ष) की तुलना करें। मूल yolo/darknet बॉक्स समीकरणों में एक गंभीर दोष है। चौड़ाई और ऊँचाई पूरी तरह से अनबाउंड हैं क्योंकि वे बस बाहर = exp(in) हैं, जो खतरनाक है, क्योंकि इससे भगोड़ा ढाल, अस्थिरता, NaN नुकसान और अंततः प्रशिक्षण का पूर्ण नुकसान हो सकता है। इस समस्या का संदर्भ लें

4.4 लक्ष्य बनाएं
में निर्माण लक्ष्य प्रक्रिया YOLOv5 प्रशिक्षण दक्षता और मॉडल सटीकता के लिए महत्वपूर्ण है। इसमें आउटपुट मैप में उपयुक्त ग्रिड कोशिकाओं को ग्राउंड ट्रुथ बॉक्स असाइन करना और उन्हें उपयुक्त एंकर बॉक्स के साथ मिलान करना शामिल है।
यह प्रक्रिया इन चरणों का पालन करती है:
- ग्राउंड ट्रुथ बॉक्स आयामों और प्रत्येक एंकर टेम्पलेट के आयामों के अनुपात की गणना करें।

- यदि गणना की गई अनुपात सीमा के भीतर है, तो संबंधित एंकर के साथ ग्राउंड ट्रुथ बॉक्स का मिलान करें।

- मिलान किए गए एंकर को उपयुक्त कोशिकाओं को असाइन करें, यह ध्यान में रखते हुए कि संशोधित केंद्र बिंदु ऑफसेट के कारण, एक ग्राउंड ट्रुथ बॉक्स को एक से अधिक एंकर को सौंपा जा सकता है। क्योंकि केंद्र बिंदु ऑफ़सेट सीमा (0, 1) से (-0.5, 1.5) तक समायोजित की जाती है। जीटी बॉक्स को अधिक एंकरों को सौंपा जा सकता है।

इस तरह, बिल्ड लक्ष्य प्रक्रिया यह सुनिश्चित करती है कि प्रशिक्षण प्रक्रिया के दौरान प्रत्येक जमीनी सच्चाई वस्तु को ठीक से सौंपा और मिलान किया जाए, जिससे अनुमति मिलती है YOLOv5 वस्तु का पता लगाने के कार्य को अधिक प्रभावी ढंग से सीखने के लिए।
समाप्ति
निष्कर्ष के तौर पर, YOLOv5 वास्तविक समय वस्तु का पता लगाने वाले मॉडल के विकास में एक महत्वपूर्ण कदम का प्रतिनिधित्व करता है। विभिन्न नई सुविधाओं, संवर्द्धन और प्रशिक्षण रणनीतियों को शामिल करके, यह पिछले संस्करणों को पार करता है YOLO प्रदर्शन और दक्षता में परिवार।
में प्राथमिक संवर्द्धन YOLOv5 एक गतिशील वास्तुकला का उपयोग, डेटा वृद्धि तकनीकों की एक विस्तृत श्रृंखला, नवीन प्रशिक्षण रणनीतियों, साथ ही कंप्यूटिंग घाटे में महत्वपूर्ण समायोजन और लक्ष्य निर्माण की प्रक्रिया शामिल है। ये सभी नवाचार उच्च स्तर की गति को बनाए रखते हुए वस्तु का पता लगाने की सटीकता और दक्षता में काफी सुधार करते हैं, जो कि ट्रेडमार्क है YOLO मॉडल।
बनाया गया 2023-11-12, अपडेट किया गया 2024-06-19
लेखक: महत्वाकांक्षी-ऑक्टोपस (1), ग्लेन-जोचर (9), सर्जियुवैक्समैन (1)