ONNX Exporteren voor YOLOv8 modellen
Vaak heb je bij het implementeren van computer vision modellen een modelformaat nodig dat zowel flexibel is als compatibel met meerdere platforms.
Het exporteren van Ultralytics YOLOv8 modellen naar het formaat ONNX stroomlijnt de implementatie en zorgt voor optimale prestaties in verschillende omgevingen. Deze gids laat je zien hoe je eenvoudig je YOLOv8 modellen kunt converteren naar ONNX en hun schaalbaarheid en effectiviteit in echte toepassingen kunt verbeteren.
ONNX en ONNX Runtime
ONNXwat staat voor Open Neural Network Exchange, is een gemeenschapsproject dat in eerste instantie door Facebook en Microsoft is ontwikkeld. De voortdurende ontwikkeling van ONNX is een gezamenlijke inspanning die wordt ondersteund door verschillende organisaties zoals IBM, Amazon (via AWS) en Google. Het project heeft als doel om een open bestandsformaat te creëren dat ontworpen is om modellen voor machinaal leren te representeren op een manier die het mogelijk maakt om ze te gebruiken in verschillende AI raamwerken en hardware.
ONNX modellen kunnen worden gebruikt om naadloos over te schakelen tussen verschillende raamwerken. Zo kan een deep learning model dat is getraind in PyTorch worden geëxporteerd naar het formaat ONNX en vervolgens eenvoudig worden geïmporteerd in TensorFlow.
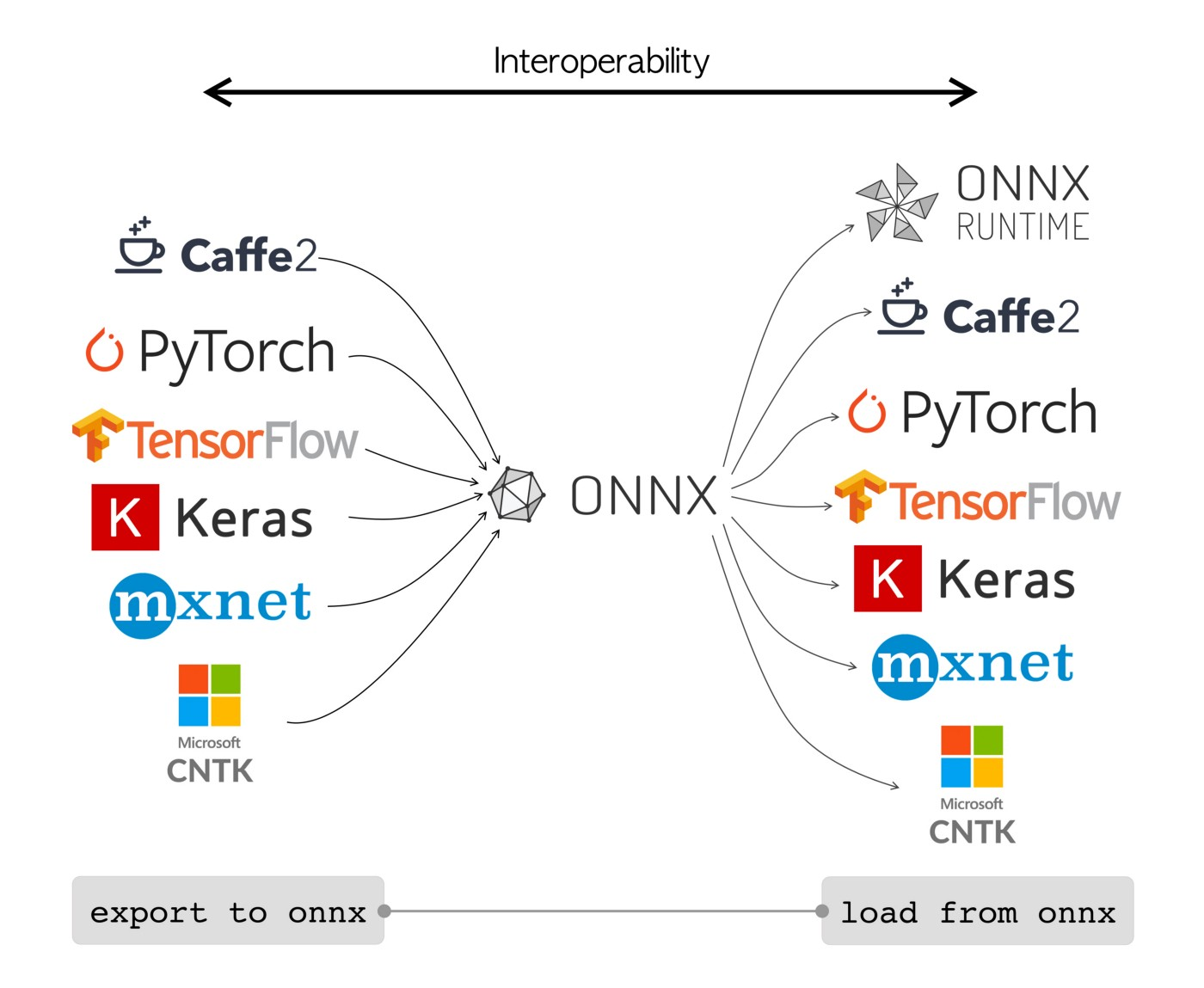
Als alternatief kunnen ONNX modellen gebruikt worden met ONNX Runtime. ONNX Runtime is een veelzijdige cross-platform versneller voor machine learning modellen die compatibel is met frameworks zoals PyTorch, TensorFlow, TFLite, scikit-learn, enz.
ONNX Runtime optimaliseert de uitvoering van ONNX modellen door gebruik te maken van hardwarespecifieke mogelijkheden. Door deze optimalisatie kunnen de modellen efficiënt en met hoge prestaties worden uitgevoerd op verschillende hardwareplatforms, waaronder CPU's, GPU's en gespecialiseerde versnellers.
Of het nu zelfstandig wordt gebruikt of in combinatie met ONNX Runtime, ONNX biedt een flexibele oplossing voor het implementeren en compatibel maken van machine learning modellen.
Belangrijkste kenmerken van ONNX modellen
Het vermogen van ONNX om met verschillende formaten om te gaan kan worden toegeschreven aan de volgende belangrijke eigenschappen:
-
Gemeenschappelijke modelrepresentatie: ONNX definieert een gemeenschappelijke set operatoren (zoals convoluties, lagen, etc.) en een standaard gegevensformaat. Wanneer een model wordt geconverteerd naar het ONNX formaat, worden de architectuur en gewichten vertaald naar deze gemeenschappelijke representatie. Deze uniformiteit zorgt ervoor dat het model begrepen kan worden door elk framework dat ONNX ondersteunt.
-
Versiebeheer en achterwaartse compatibiliteit: ONNX onderhoudt een versiebeheersysteem voor zijn gebruikers. Dit zorgt ervoor dat zelfs als de standaard evolueert, modellen die in oudere versies zijn gemaakt bruikbaar blijven. Achterwaartse compatibiliteit is een cruciale eigenschap die voorkomt dat modellen snel verouderd raken.
-
Modelrepresentatie op basis van grafieken: ONNX representeert modellen als computationele grafieken. Deze op grafieken gebaseerde structuur is een universele manier om modellen voor machinaal leren te representeren, waarbij knooppunten bewerkingen of berekeningen representeren en randen de tensoren die daartussen stromen. Deze indeling is gemakkelijk aan te passen aan verschillende raamwerken die modellen ook als grafieken representeren.
-
Hulpmiddelen en ecosysteem: Er is een rijk ecosysteem van tools rondom ONNX die helpen bij modelconversie, visualisatie en optimalisatie. Deze tools maken het voor ontwikkelaars gemakkelijker om te werken met ONNX modellen en om modellen naadloos te converteren tussen verschillende frameworks.
Gebruik van ONNX
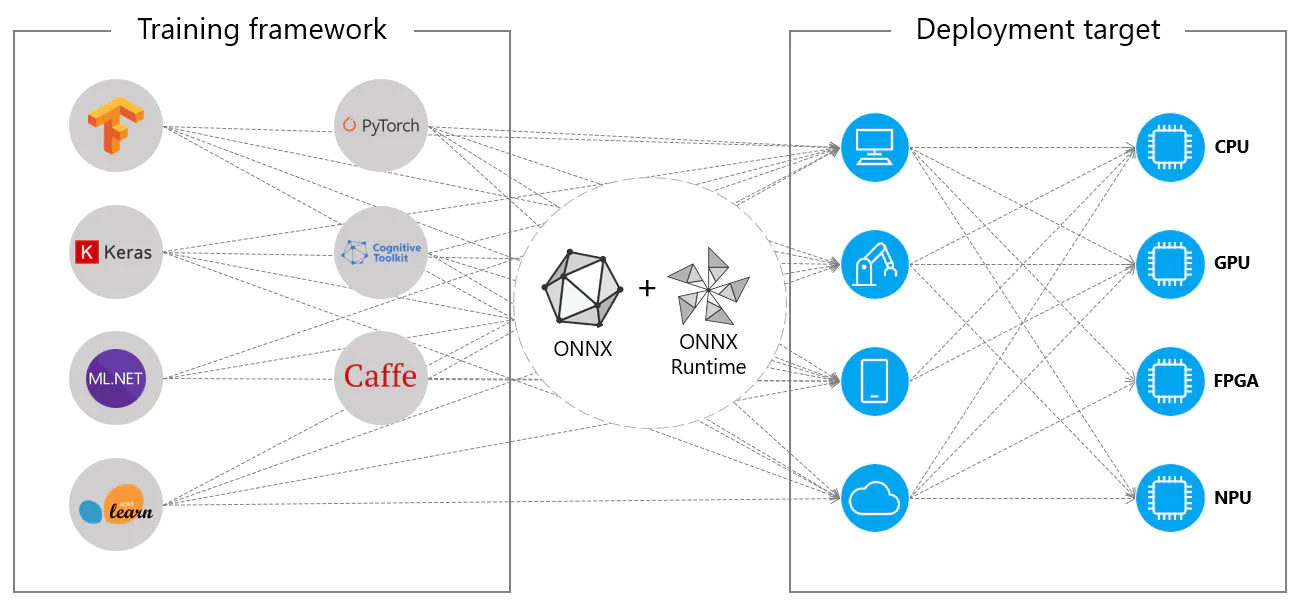
Voordat we ingaan op hoe je YOLOv8 modellen kunt exporteren naar het ONNX formaat, laten we eens kijken waar ONNX modellen meestal worden gebruikt.
CPU Inzet
ONNX modellen worden vaak ingezet op CPU's vanwege hun compatibiliteit met ONNX Runtime. Deze runtime is geoptimaliseerd voor CPU uitvoering. Het verbetert de inferentiesnelheid aanzienlijk en maakt real-time CPU implementaties haalbaar.
Ondersteunde implementatieopties
Hoewel ONNX modellen meestal worden gebruikt op CPU's, kunnen ze ook worden ingezet op de volgende platformen:
-
GPU-versnelling: ONNX ondersteunt GPU-versnelling volledig, met name NVIDIA CUDA. Dit maakt efficiënte uitvoering op NVIDIA GPU's mogelijk voor taken die veel rekenkracht vereisen.
-
Rand en mobiele apparaten: ONNX is ook beschikbaar voor rand en mobiele apparaten, perfect voor inferentiescenario's op het apparaat en in realtime. Het is lichtgewicht en compatibel met randapparatuur.
-
Webbrowsers: ONNX kan direct in webbrowsers draaien, waardoor interactieve en dynamische webgebaseerde AI-toepassingen mogelijk worden.
YOLOv8 modellen exporteren naar ONNX
Je kunt modelcompatibiliteit en inzetflexibiliteit uitbreiden door YOLOv8 modellen te converteren naar ONNX formaat.
Installatie
Voer het volgende uit om het vereiste pakket te installeren:
Bekijk voor gedetailleerde instructies en best practices met betrekking tot het installatieproces onze YOLOv8 Installatiegids. Als je tijdens de installatie van de vereiste pakketten voor YOLOv8 problemen tegenkomt, raadpleeg dan onze gids Veelgestelde problemen voor oplossingen en tips.
Gebruik
Voordat je in de gebruiksaanwijzing duikt, moet je eerst het assortiment YOLOv8 modellen bekijken dat Ultralytics aanbiedt. Dit zal je helpen het meest geschikte model te kiezen voor jouw projectvereisten.
Gebruik
from ultralytics import YOLO
# Load the YOLOv8 model
model = YOLO('yolov8n.pt')
# Export the model to ONNX format
model.export(format='onnx') # creates 'yolov8n.onnx'
# Load the exported ONNX model
onnx_model = YOLO('yolov8n.onnx')
# Run inference
results = onnx_model('https://ultralytics.com/images/bus.jpg')
Ga voor meer informatie over het exportproces naar de Ultralytics documentatiepagina over exporteren.
Geëxporteerde YOLOv8 ONNX modellen inzetten
Als je je Ultralytics YOLOv8 modellen met succes hebt geëxporteerd naar het ONNX formaat, is de volgende stap het implementeren van deze modellen in verschillende omgevingen. Voor gedetailleerde instructies over het implementeren van je ONNX modellen, kun je een kijkje nemen in de volgende bronnen:
-
ONNX Runtime Python API-documentatie: Deze handleiding biedt essentiële informatie voor het laden en uitvoeren van ONNX modellen met ONNX Runtime.
-
Inzetten op randapparaten: Bekijk deze documentatiepagina voor verschillende voorbeelden van het inzetten van ONNX modellen op randapparaten.
-
ONNX Handleidingen op GitHub: Een verzameling uitgebreide tutorials die verschillende aspecten van het gebruik en de implementatie van ONNX modellen in verschillende scenario's behandelen.
Samenvatting
In deze handleiding heb je geleerd hoe je Ultralytics YOLOv8 modellen kunt exporteren naar ONNX formaat om hun interoperabiliteit en prestaties op verschillende platforms te verbeteren. Je hebt ook kennis gemaakt met de ONNX Runtime en ONNX deployment opties.
Ga voor meer informatie over het gebruik naar de officiële documentatie opONNX .
Als je meer wilt weten over andere Ultralytics YOLOv8 integraties, bezoek dan onze integratiegids pagina. Daar vind je veel nuttige bronnen en inzichten.