Intel OpenVINO Export
In deze handleiding behandelen we het exporteren van YOLOv8 modellen naar het OpenVINO formaat, wat tot 3x CPU-snelheid kan opleveren, evenals het versnellen van YOLO inferentie op Intel GPU en NPU hardware.
OpenVINO, kort voor Open Visual Inference & Neural Network Optimization toolkit, is een uitgebreide toolkit voor het optimaliseren en inzetten van AI-inferentiemodellen. Hoewel de naam Visual bevat, ondersteunt OpenVINO ook verschillende andere taken, waaronder taal, audio, tijdreeksen, enz.
Kijken: Een Ultralytics YOLOv8 model exporteren en optimaliseren voor inferentie met OpenVINO.
Voorbeelden
Exporteer een YOLOv8n model naar OpenVINO formaat en voer inferentie uit met het geëxporteerde model.
Voorbeeld
from ultralytics import YOLO
# Load a YOLOv8n PyTorch model
model = YOLO('yolov8n.pt')
# Export the model
model.export(format='openvino') # creates 'yolov8n_openvino_model/'
# Load the exported OpenVINO model
ov_model = YOLO('yolov8n_openvino_model/')
# Run inference
results = ov_model('https://ultralytics.com/images/bus.jpg')
Argumenten
| Sleutel | Waarde | Beschrijving |
|---|---|---|
format |
'openvino' |
formaat om naar te exporteren |
imgsz |
640 |
afbeeldingsgrootte als scalair of (h, w) lijst, bijv. (640, 480) |
half |
False |
FP16 kwantisatie |
Voordelen van OpenVINO
- Prestaties: OpenVINO levert inferentie met hoge prestaties door gebruik te maken van de kracht van Intel CPU's, geïntegreerde en discrete GPU's en FPGA's.
- Ondersteuning voor Heterogene Uitvoering: OpenVINO biedt een API om eenmalig te schrijven en te implementeren op alle ondersteunde Intel-hardware (CPU, GPU, FPGA, VPU, etc.).
- Model Optimizer: OpenVINO biedt een Model Optimizer die modellen importeert, converteert en optimaliseert van populaire deep learning frameworks zoals PyTorch, TensorFlow, TensorFlow Lite, Keras, ONNX, PaddlePaddle, en Caffe.
- Gebruiksgemak: De toolkit wordt geleverd met meer dan 80 tutorials (inclusief YOLOv8 optimalisatie) waarin verschillende aspecten van de toolkit worden uitgelegd.
OpenVINO Exportstructuur
Wanneer je een model exporteert naar het formaat OpenVINO , resulteert dit in een map met daarin het volgende:
- XML-bestand: Beschrijft de netwerktopologie.
- BIN bestand: Bevat de weights and biases binaire gegevens.
- Mapping bestand: Bevat de mapping van originele modeluitgangstensoren naar OpenVINO tensor namen.
Je kunt deze bestanden gebruiken om inferentie uit te voeren met de OpenVINO Inference Engine.
OpenVINO exporteren in implementatie gebruiken
Zodra je de OpenVINO bestanden hebt, kun je de OpenVINO Runtime gebruiken om het model uit te voeren. De Runtime biedt een uniforme API voor inferentie op alle ondersteunde Intel hardware. Het biedt ook geavanceerde mogelijkheden zoals load balancing op Intel hardware en asynchrone uitvoering. Raadpleeg voor meer informatie over het uitvoeren van de inferentie de Handleiding voor inferentie met OpenVINO Runtime.
Onthoud dat je de XML- en BIN-bestanden nodig hebt, evenals toepassingsspecifieke instellingen zoals invoergrootte, schaalfactor voor normalisatie, enzovoort, om het model correct in te stellen en te gebruiken met de Runtime.
In je implementatietoepassing zou je normaal gesproken de volgende stappen uitvoeren:
- Initialiseer OpenVINO door
core = Core(). - Laad het model met de
core.read_model()methode. - Compileer het model met de
core.compile_model()functie. - Bereid de invoer voor (afbeelding, tekst, audio, enz.).
- Inferentie uitvoeren met
compiled_model(input_data).
Raadpleeg voor meer gedetailleerde stappen en codefragmenten de OpenVINO documentatie of API tutorial.
OpenVINO YOLOv8 Benchmarks
YOLOv8 De benchmarks hieronder zijn uitgevoerd door het Ultralytics team op 4 verschillende modelformaten die snelheid en nauwkeurigheid meten: PyTorch, TorchScript, ONNX en OpenVINO. De benchmarks werden uitgevoerd op Intel Flex en Arc GPU's en op Intel Xeon CPU's met FP32 precisie (met de half=False argument).
Opmerking
De benchmarkresultaten hieronder zijn ter referentie en kunnen variëren op basis van de exacte hardware- en softwareconfiguratie van een systeem en de huidige werkbelasting van het systeem op het moment dat de benchmarks worden uitgevoerd.
Alle benchmarks worden uitgevoerd met openvino Python pakketversie 2023.0.1.
Intel Flex GPU
De Intel® Data Center GPU Flex Series is een veelzijdige en robuuste oplossing die is ontworpen voor de intelligente visuele cloud. Deze GPU ondersteunt een breed scala aan werklasten, waaronder media streaming, cloud gaming, AI visual inference en virtual desktop Infrastructure werklasten. Hij onderscheidt zich door zijn open architectuur en ingebouwde ondersteuning voor de AV1 codering, waardoor een op standaarden gebaseerde softwarestack wordt geboden voor krachtige, cross-architecture toepassingen. De Flex Series GPU is geoptimaliseerd voor dichtheid en kwaliteit en biedt een hoge betrouwbaarheid, beschikbaarheid en schaalbaarheid.
Onderstaande benchmarks zijn uitgevoerd op Intel® Data Center GPU Flex 170 met FP32 precisie.
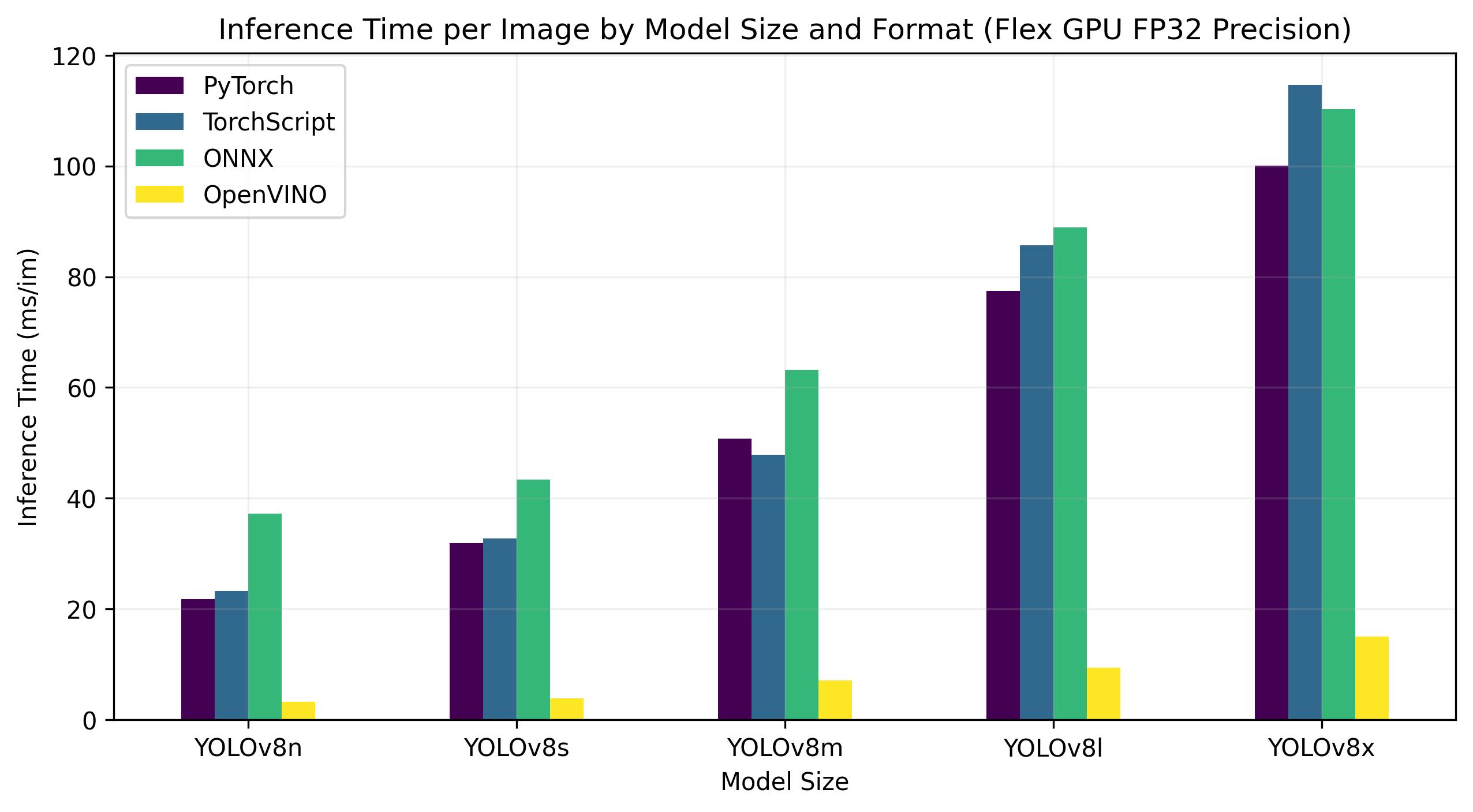
| Model | Formaat | Status | Grootte (MB) | mAP50-95(B) | Inferentietijd (ms/im) |
|---|---|---|---|---|---|
| YOLOv8n | PyTorch | ✅ | 6.2 | 0.3709 | 21.79 |
| YOLOv8n | TorchScript | ✅ | 12.4 | 0.3704 | 23.24 |
| YOLOv8n | ONNX | ✅ | 12.2 | 0.3704 | 37.22 |
| YOLOv8n | OpenVINO | ✅ | 12.3 | 0.3703 | 3.29 |
| YOLOv8s | PyTorch | ✅ | 21.5 | 0.4471 | 31.89 |
| YOLOv8s | TorchScript | ✅ | 42.9 | 0.4472 | 32.71 |
| YOLOv8s | ONNX | ✅ | 42.8 | 0.4472 | 43.42 |
| YOLOv8s | OpenVINO | ✅ | 42.9 | 0.4470 | 3.92 |
| YOLOv8m | PyTorch | ✅ | 49.7 | 0.5013 | 50.75 |
| YOLOv8m | TorchScript | ✅ | 99.2 | 0.4999 | 47.90 |
| YOLOv8m | ONNX | ✅ | 99.0 | 0.4999 | 63.16 |
| YOLOv8m | OpenVINO | ✅ | 49.8 | 0.4997 | 7.11 |
| YOLOv8l | PyTorch | ✅ | 83.7 | 0.5293 | 77.45 |
| YOLOv8l | TorchScript | ✅ | 167.2 | 0.5268 | 85.71 |
| YOLOv8l | ONNX | ✅ | 166.8 | 0.5268 | 88.94 |
| YOLOv8l | OpenVINO | ✅ | 167.0 | 0.5264 | 9.37 |
| YOLOv8x | PyTorch | ✅ | 130.5 | 0.5404 | 100.09 |
| YOLOv8x | TorchScript | ✅ | 260.7 | 0.5371 | 114.64 |
| YOLOv8x | ONNX | ✅ | 260.4 | 0.5371 | 110.32 |
| YOLOv8x | OpenVINO | ✅ | 260.6 | 0.5367 | 15.02 |
Deze tabel toont de benchmarkresultaten voor vijf verschillende modellen (YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, YOLOv8x) over vier verschillende indelingen (PyTorch, TorchScript, ONNX, OpenVINO), met de status, grootte, mAP50-95(B) metric en inferentietijd voor elke combinatie.
Intel Arc GPU
Intel® Arc™ vertegenwoordigt Intels intrede in de speciale GPU markt. De Arc™ serie, ontworpen om te concurreren met toonaangevende GPU fabrikanten als AMD en Nvidia, richt zich op zowel de laptop- als de desktopmarkt. De serie omvat mobiele versies voor compacte apparaten zoals laptops en grotere, krachtigere versies voor desktopcomputers.
De Arc™ serie is onderverdeeld in drie categorieën: Arc™ 3, Arc™ 5 en Arc™ 7, waarbij elk nummer het prestatieniveau aangeeft. Elke categorie omvat verschillende modellen en de 'M' in de modelnaam van de GPU staat voor een mobiele, geïntegreerde variant.
In de eerste reviews wordt de Arc™ serie, met name de geïntegreerde A770M GPU, geprezen om zijn indrukwekkende grafische prestaties. De beschikbaarheid van de Arc™ serie varieert per regio en er worden binnenkort extra modellen verwacht. Intel® Arc™ GPU's bieden krachtige oplossingen voor een scala aan computerbehoeften, van gaming tot het maken van content.
Onderstaande benchmarks zijn uitgevoerd op Intel® Arc 770 GPU met FP32 precisie.
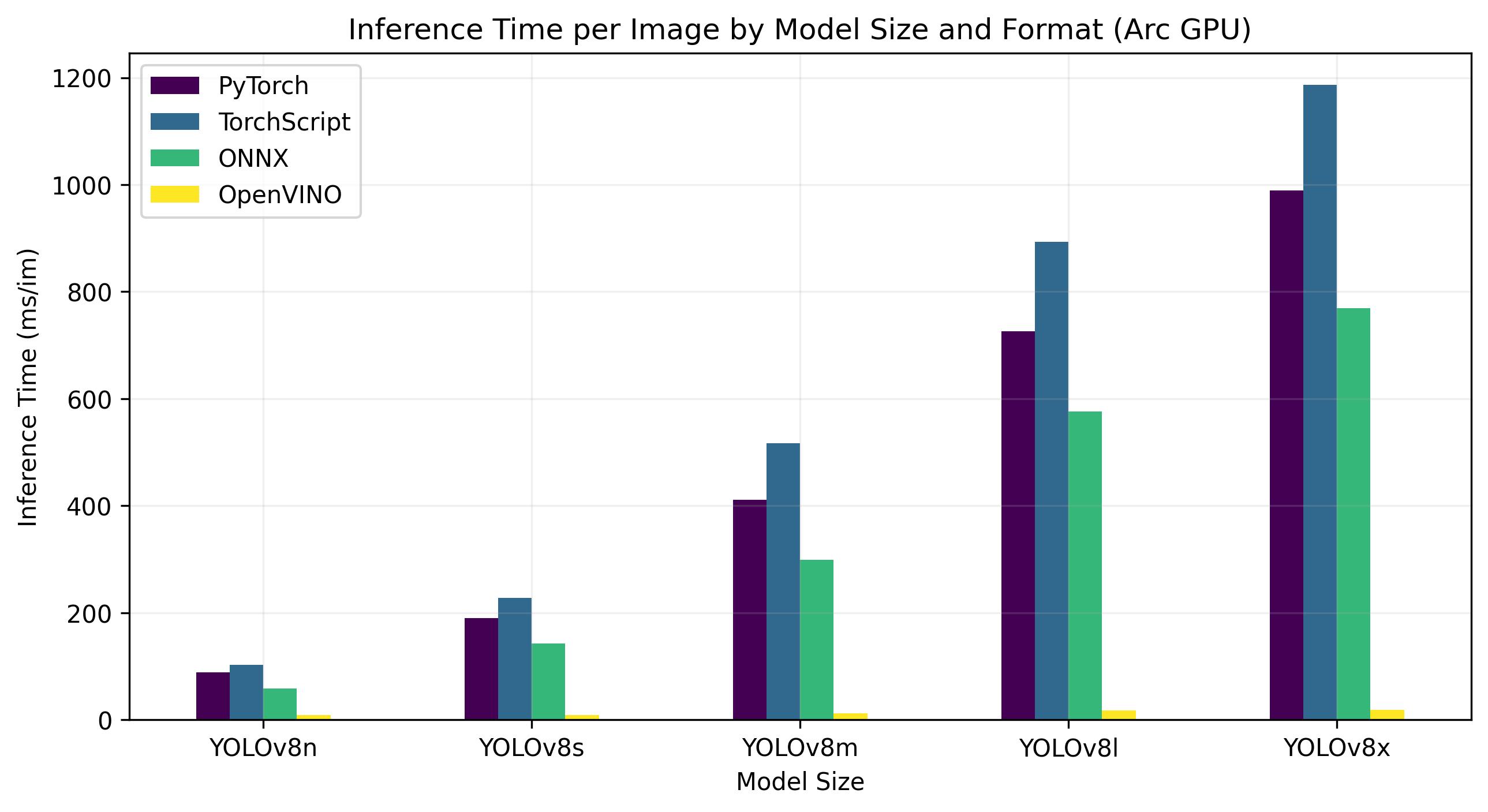
| Model | Formaat | Status | Grootte (MB) | metriek/mAP50-95(B) | Inferentietijd (ms/im) |
|---|---|---|---|---|---|
| YOLOv8n | PyTorch | ✅ | 6.2 | 0.3709 | 88.79 |
| YOLOv8n | TorchScript | ✅ | 12.4 | 0.3704 | 102.66 |
| YOLOv8n | ONNX | ✅ | 12.2 | 0.3704 | 57.98 |
| YOLOv8n | OpenVINO | ✅ | 12.3 | 0.3703 | 8.52 |
| YOLOv8s | PyTorch | ✅ | 21.5 | 0.4471 | 189.83 |
| YOLOv8s | TorchScript | ✅ | 42.9 | 0.4472 | 227.58 |
| YOLOv8s | ONNX | ✅ | 42.7 | 0.4472 | 142.03 |
| YOLOv8s | OpenVINO | ✅ | 42.9 | 0.4469 | 9.19 |
| YOLOv8m | PyTorch | ✅ | 49.7 | 0.5013 | 411.64 |
| YOLOv8m | TorchScript | ✅ | 99.2 | 0.4999 | 517.12 |
| YOLOv8m | ONNX | ✅ | 98.9 | 0.4999 | 298.68 |
| YOLOv8m | OpenVINO | ✅ | 99.1 | 0.4996 | 12.55 |
| YOLOv8l | PyTorch | ✅ | 83.7 | 0.5293 | 725.73 |
| YOLOv8l | TorchScript | ✅ | 167.1 | 0.5268 | 892.83 |
| YOLOv8l | ONNX | ✅ | 166.8 | 0.5268 | 576.11 |
| YOLOv8l | OpenVINO | ✅ | 167.0 | 0.5262 | 17.62 |
| YOLOv8x | PyTorch | ✅ | 130.5 | 0.5404 | 988.92 |
| YOLOv8x | TorchScript | ✅ | 260.7 | 0.5371 | 1186.42 |
| YOLOv8x | ONNX | ✅ | 260.4 | 0.5371 | 768.90 |
| YOLOv8x | OpenVINO | ✅ | 260.6 | 0.5367 | 19 |
Intel Xeon CPU
De Intel® Xeon® CPU is een krachtige processor van serverkwaliteit die is ontworpen voor complexe en veeleisende werklasten. Van high-end cloud computing en virtualisatie tot kunstmatige intelligentie en machine learning toepassingen, Xeon® CPU's bieden de kracht, betrouwbaarheid en flexibiliteit die nodig is voor de datacenters van vandaag.
Xeon® CPU's leveren met name een hoge computerdichtheid en schaalbaarheid, waardoor ze ideaal zijn voor zowel kleine bedrijven als grote ondernemingen. Door te kiezen voor Intel® Xeon® CPU's kunnen organisaties met vertrouwen hun meest veeleisende computertaken aan en innovatie stimuleren met behoud van kosteneffectiviteit en operationele efficiëntie.
Onderstaande benchmarks zijn uitgevoerd op 4e generatie Intel® Xeon® Scalable CPU met FP32 precisie.
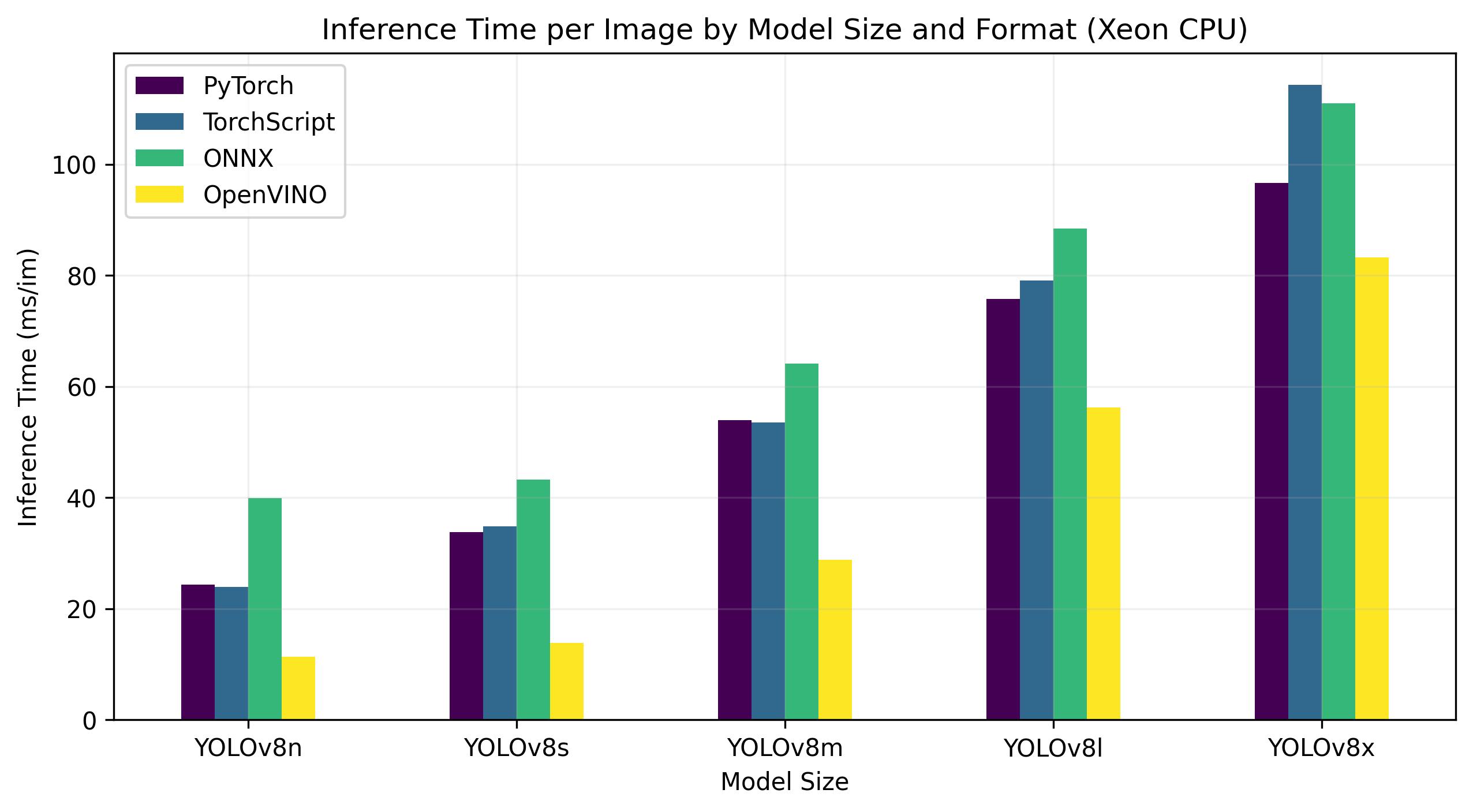
| Model | Formaat | Status | Grootte (MB) | metriek/mAP50-95(B) | Inferentietijd (ms/im) |
|---|---|---|---|---|---|
| YOLOv8n | PyTorch | ✅ | 6.2 | 0.3709 | 24.36 |
| YOLOv8n | TorchScript | ✅ | 12.4 | 0.3704 | 23.93 |
| YOLOv8n | ONNX | ✅ | 12.2 | 0.3704 | 39.86 |
| YOLOv8n | OpenVINO | ✅ | 12.3 | 0.3704 | 11.34 |
| YOLOv8s | PyTorch | ✅ | 21.5 | 0.4471 | 33.77 |
| YOLOv8s | TorchScript | ✅ | 42.9 | 0.4472 | 34.84 |
| YOLOv8s | ONNX | ✅ | 42.8 | 0.4472 | 43.23 |
| YOLOv8s | OpenVINO | ✅ | 42.9 | 0.4471 | 13.86 |
| YOLOv8m | PyTorch | ✅ | 49.7 | 0.5013 | 53.91 |
| YOLOv8m | TorchScript | ✅ | 99.2 | 0.4999 | 53.51 |
| YOLOv8m | ONNX | ✅ | 99.0 | 0.4999 | 64.16 |
| YOLOv8m | OpenVINO | ✅ | 99.1 | 0.4996 | 28.79 |
| YOLOv8l | PyTorch | ✅ | 83.7 | 0.5293 | 75.78 |
| YOLOv8l | TorchScript | ✅ | 167.2 | 0.5268 | 79.13 |
| YOLOv8l | ONNX | ✅ | 166.8 | 0.5268 | 88.45 |
| YOLOv8l | OpenVINO | ✅ | 167.0 | 0.5263 | 56.23 |
| YOLOv8x | PyTorch | ✅ | 130.5 | 0.5404 | 96.60 |
| YOLOv8x | TorchScript | ✅ | 260.7 | 0.5371 | 114.28 |
| YOLOv8x | ONNX | ✅ | 260.4 | 0.5371 | 111.02 |
| YOLOv8x | OpenVINO | ✅ | 260.6 | 0.5371 | 83.28 |
Intel Core CPU
De Intel® Core® serie is een reeks krachtige processors van Intel. De reeks omvat Core i3 (instapmodel), Core i5 (middenklasse), Core i7 (topklasse) en Core i9 (extreme prestaties). Elke serie is geschikt voor verschillende computerbehoeften en budgetten, van alledaagse taken tot veeleisende professionele werklasten. Bij elke nieuwe generatie worden verbeteringen aangebracht in prestaties, energiezuinigheid en functies.
Onderstaande benchmarks zijn uitgevoerd op een 13e generatie Intel® Core® i7-13700H CPU met FP32 precisie.
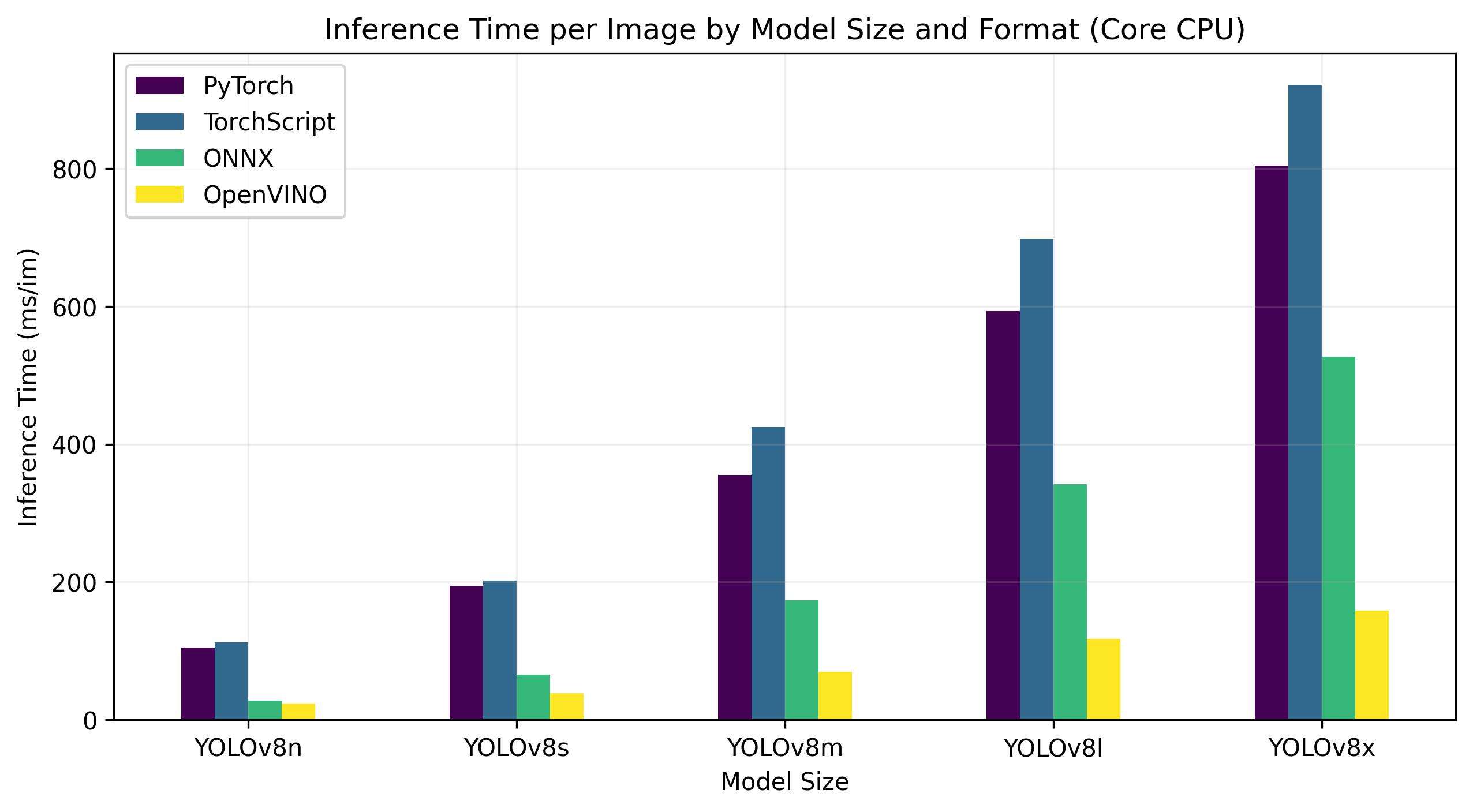
| Model | Formaat | Status | Grootte (MB) | metriek/mAP50-95(B) | Inferentietijd (ms/im) |
|---|---|---|---|---|---|
| YOLOv8n | PyTorch | ✅ | 6.2 | 0.4478 | 104.61 |
| YOLOv8n | TorchScript | ✅ | 12.4 | 0.4525 | 112.39 |
| YOLOv8n | ONNX | ✅ | 12.2 | 0.4525 | 28.02 |
| YOLOv8n | OpenVINO | ✅ | 12.3 | 0.4504 | 23.53 |
| YOLOv8s | PyTorch | ✅ | 21.5 | 0.5885 | 194.83 |
| YOLOv8s | TorchScript | ✅ | 43.0 | 0.5962 | 202.01 |
| YOLOv8s | ONNX | ✅ | 42.8 | 0.5962 | 65.74 |
| YOLOv8s | OpenVINO | ✅ | 42.9 | 0.5966 | 38.66 |
| YOLOv8m | PyTorch | ✅ | 49.7 | 0.6101 | 355.23 |
| YOLOv8m | TorchScript | ✅ | 99.2 | 0.6120 | 424.78 |
| YOLOv8m | ONNX | ✅ | 99.0 | 0.6120 | 173.39 |
| YOLOv8m | OpenVINO | ✅ | 99.1 | 0.6091 | 69.80 |
| YOLOv8l | PyTorch | ✅ | 83.7 | 0.6591 | 593.00 |
| YOLOv8l | TorchScript | ✅ | 167.2 | 0.6580 | 697.54 |
| YOLOv8l | ONNX | ✅ | 166.8 | 0.6580 | 342.15 |
| YOLOv8l | OpenVINO | ✅ | 167.0 | 0.0708 | 117.69 |
| YOLOv8x | PyTorch | ✅ | 130.5 | 0.6651 | 804.65 |
| YOLOv8x | TorchScript | ✅ | 260.8 | 0.6650 | 921.46 |
| YOLOv8x | ONNX | ✅ | 260.4 | 0.6650 | 526.66 |
| YOLOv8x | OpenVINO | ✅ | 260.6 | 0.6619 | 158.73 |
Onze resultaten reproduceren
Voer deze code uit om de bovenstaande Ultralytics benchmarks te reproduceren op alle exportformaten:
Voorbeeld
Merk op dat de benchmarkresultaten kunnen variëren op basis van de exacte hardware- en softwareconfiguratie van een systeem en de huidige werkbelasting van het systeem op het moment dat de benchmarks worden uitgevoerd. Gebruik voor de meest betrouwbare resultaten een dataset met een groot aantal afbeeldingen, d.w.z. data='coco128.yaml' (128 val images), ordata='coco.yaml'` (5000 valafbeeldingen).
Conclusie
De benchmarkresultaten laten duidelijk de voordelen zien van het exporteren van het YOLOv8 model naar het OpenVINO formaat. Bij verschillende modellen en hardwareplatforms presteert het OpenVINO formaat consequent beter dan andere formaten wat betreft inferentiesnelheid, terwijl de nauwkeurigheid vergelijkbaar blijft.
Voor de Intel® Data Center GPU Flex Series was de OpenVINO indeling in staat om inferentiesnelheden te leveren die bijna 10 keer sneller waren dan de oorspronkelijke PyTorch indeling. Op de Xeon CPU was de indeling OpenVINO twee keer zo snel als de indeling PyTorch . De nauwkeurigheid van de modellen bleef vrijwel identiek voor de verschillende indelingen.
De benchmarks onderstrepen de effectiviteit van OpenVINO als hulpmiddel voor het implementeren van deep learning modellen. Door modellen te converteren naar het OpenVINO formaat kunnen ontwikkelaars aanzienlijke prestatieverbeteringen bereiken, waardoor het eenvoudiger wordt om deze modellen in te zetten in echte toepassingen.
Voor meer gedetailleerde informatie en instructies over het gebruik van OpenVINO, raadpleeg je de officiële OpenVINO documentatie.
Aangemaakt 2023-11-12, Bijgewerkt 2024-04-18
Auteurs: glenn-jocher (9), abirami-vina (1), RizwanMunawar (1), Burhan-Q (1)