TensorRT Exporteren voor YOLOv8 modellen
Het implementeren van computervisie modellen in omgevingen met hoge prestaties kan een formaat vereisen dat snelheid en efficiëntie maximaliseert. Dit geldt vooral als je je model inzet op NVIDIA GPU's.
Door het exportformaat TensorRT te gebruiken, kun je je Ultralytics YOLOv8 modellen verbeteren voor snelle en efficiënte inferentie op NVIDIA hardware. Deze gids geeft je eenvoudig te volgen stappen voor het conversieproces en helpt je om de geavanceerde technologie van NVIDIA optimaal te benutten voor je deep learning-projecten.
TensorRT
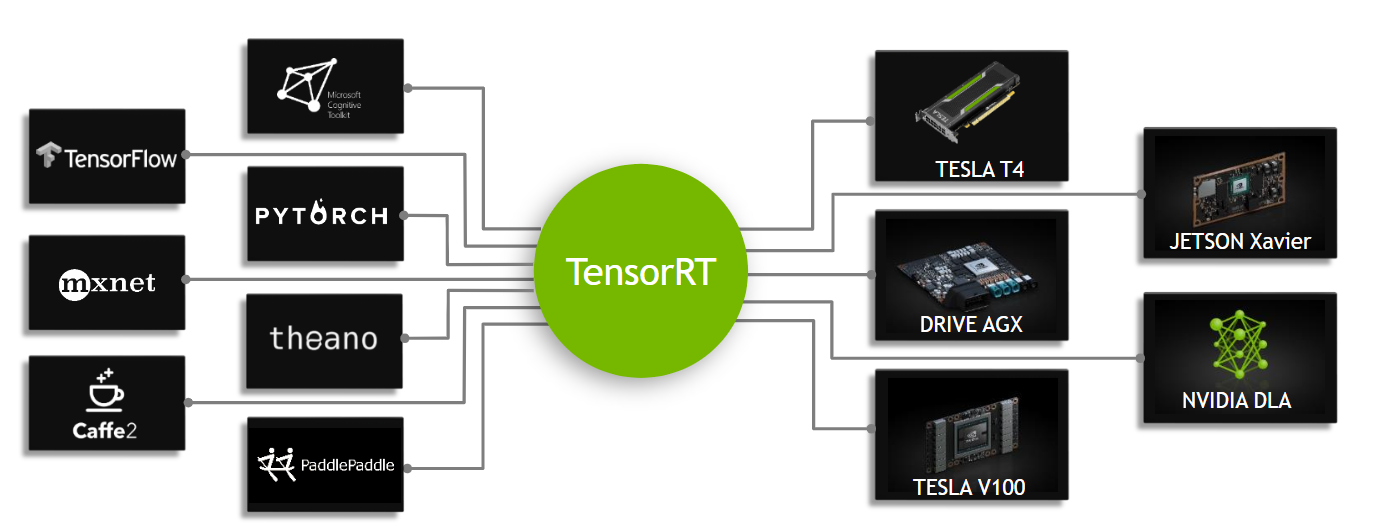
TensorRT, ontwikkeld door NVIDIA, is een geavanceerde software development kit (SDK) die is ontworpen voor high-speed deep learning inferentie. Het is zeer geschikt voor real-time toepassingen zoals objectdetectie.
Deze toolkit optimaliseert deep learning modellen voor NVIDIA GPU's en resulteert in snellere en efficiëntere bewerkingen. TensorRT modellen ondergaan TensorRT optimalisatie, waaronder technieken als layer fusion, precisiekalibratie (INT8 en FP16), dynamisch tensor geheugenbeheer en kernel auto-tuning. Door deep learning modellen om te zetten naar het TensorRT formaat kunnen ontwikkelaars het potentieel van NVIDIA GPU's volledig benutten.
TensorRT staat bekend om zijn compatibiliteit met verschillende modelformaten, waaronder TensorFlow, PyTorch, en ONNX, waardoor ontwikkelaars een flexibele oplossing hebben voor het integreren en optimaliseren van modellen uit verschillende frameworks. Deze veelzijdigheid maakt het mogelijk om modellen efficiënt in te zetten in verschillende hardware- en softwareomgevingen.
Belangrijkste kenmerken van TensorRT modellen
TensorRT modellen bieden een aantal belangrijke eigenschappen die bijdragen aan hun efficiëntie en effectiviteit in snelle deep learning inferentie:
-
Precisiekalibratie: TensorRT ondersteunt precisiekalibratie, waardoor modellen nauwkeurig kunnen worden afgestemd op specifieke nauwkeurigheidseisen. Dit omvat ondersteuning voor gereduceerde precisieformaten zoals INT8 en FP16, die de inferentiesnelheid verder kunnen verhogen met behoud van acceptabele nauwkeurigheidsniveaus.
-
Laagfusie: Het TensorRT optimalisatieproces omvat laagfusie, waarbij meerdere lagen van een neuraal netwerk worden gecombineerd in een enkele bewerking. Dit vermindert de computationele overhead en verbetert de inferentiesnelheid door de geheugentoegang en het rekenwerk te minimaliseren.
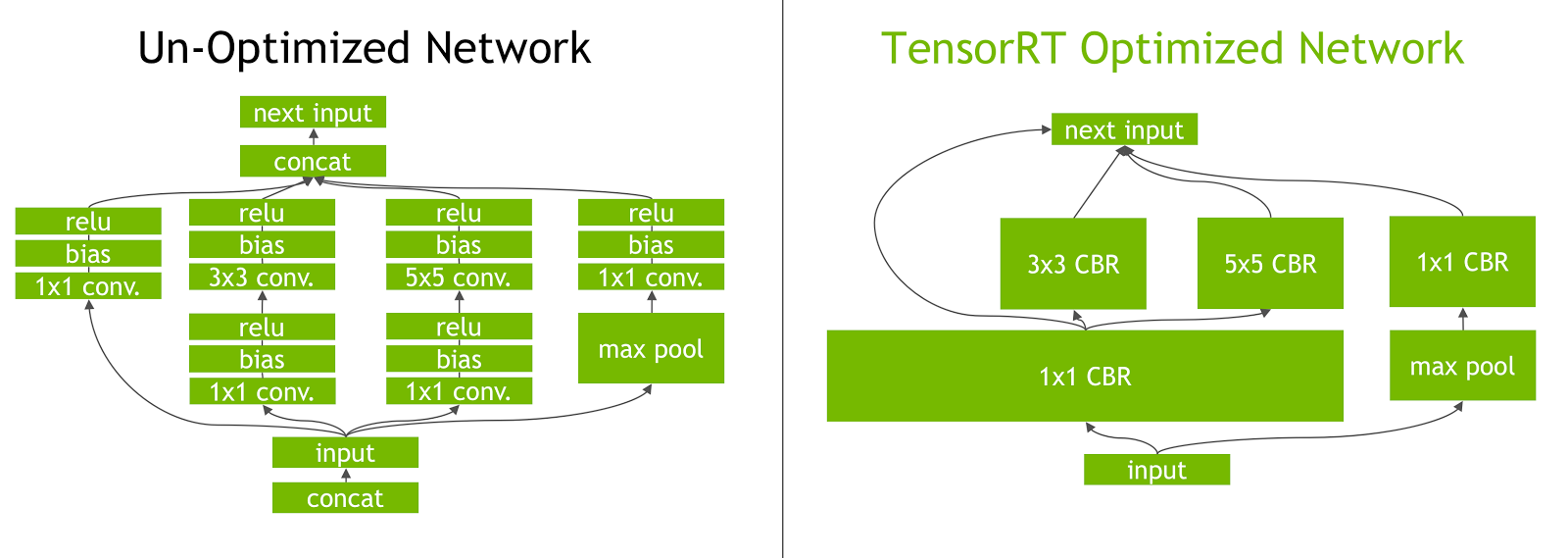
-
Dynamisch Tensor geheugenbeheer: TensorRT beheert efficiënt tensor geheugengebruik tijdens inferentie, waardoor geheugenoverhead wordt verminderd en geheugentoewijzing wordt geoptimaliseerd. Dit resulteert in een efficiënter gebruik van GPU-geheugen.
-
Automatische kerneltuning: TensorRT past automatische kerneltuning toe om de meest geoptimaliseerde GPU kernel te selecteren voor elke laag van het model. Deze adaptieve aanpak zorgt ervoor dat het model optimaal gebruik maakt van de rekenkracht van de GPU.
Inzetmogelijkheden in TensorRT
Voordat we kijken naar de code voor het exporteren van YOLOv8 modellen naar het TensorRT formaat, moeten we eerst begrijpen waar TensorRT modellen normaal gesproken worden gebruikt.
TensorRT biedt verschillende implementatieopties en elke optie heeft een andere balans tussen integratiegemak, prestatieoptimalisatie en flexibiliteit:
- Implementeren binnen TensorFlow: Deze methode integreert TensorRT in TensorFlow, waardoor geoptimaliseerde modellen kunnen draaien in een vertrouwde TensorFlow omgeving. Het is handig voor modellen met een mix van ondersteunde en niet-ondersteunde lagen, omdat TF-TRT deze efficiënt kan afhandelen.
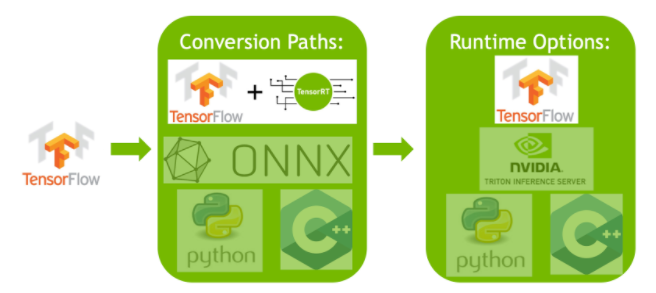
-
Standalone TensorRT Runtime API: Biedt fijnmazige controle, ideaal voor toepassingen die kritisch zijn voor prestaties. Het is complexer, maar maakt aangepaste implementatie van niet-ondersteunde operatoren mogelijk.
-
NVIDIA Triton Inferentieserver: Een optie die modellen van verschillende frameworks ondersteunt. Deze is met name geschikt voor cloud- of edge-inferentie en biedt functies als gelijktijdige modeluitvoering en modelanalyse.
YOLOv8 modellen exporteren naar TensorRT
Je kunt de uitvoeringsefficiëntie verbeteren en de prestaties optimaliseren door YOLOv8 modellen te converteren naar de indeling TensorRT .
Installatie
Voer het volgende uit om het vereiste pakket te installeren:
Bekijk voor gedetailleerde instructies en best practices met betrekking tot het installatieproces onze YOLOv8 Installatiegids. Als je tijdens de installatie van de vereiste pakketten voor YOLOv8 problemen tegenkomt, raadpleeg dan onze gids Veelgestelde problemen voor oplossingen en tips.
Gebruik
Voordat je in de gebruiksaanwijzing duikt, moet je eerst het assortiment YOLOv8 modellen bekijken dat Ultralytics aanbiedt. Dit zal je helpen het meest geschikte model te kiezen voor jouw projectvereisten.
Gebruik
from ultralytics import YOLO
# Load the YOLOv8 model
model = YOLO('yolov8n.pt')
# Export the model to TensorRT format
model.export(format='engine') # creates 'yolov8n.engine'
# Load the exported TensorRT model
tensorrt_model = YOLO('yolov8n.engine')
# Run inference
results = tensorrt_model('https://ultralytics.com/images/bus.jpg')
Ga voor meer informatie over het exportproces naar de Ultralytics documentatiepagina over exporteren.
TensorRT exporteren met INT8 kwantisatie
Het exporteren van Ultralytics YOLO modellen met TensorRT met INT8 precisie voert post-training kwantisatie (PTQ) uit. TensorRT gebruikt kalibratie voor PTQ, die de verdeling van activeringen binnen elke activering tensor meet terwijl het YOLO model inferentie verwerkt op representatieve invoergegevens, en gebruikt vervolgens die verdeling om schaalwaarden te schatten voor elke tensor. Elke activering tensor die in aanmerking komt voor kwantisatie heeft een bijbehorende schaal die wordt afgeleid door een kalibratieproces.
Bij het verwerken van impliciet gekwantiseerde netwerken gebruikt TensorRT INT8 opportunistisch om de laaguitvoeringstijd te optimaliseren. Als een laag sneller werkt in INT8 en kwantisatieschalen heeft toegewezen aan de gegevensingangen en -uitgangen, dan wordt een kernel met INT8-precisie toegewezen aan die laag, anders selecteert TensorRT een precisie van FP32 of FP16 voor de kernel op basis van wat resulteert in een snellere uitvoeringstijd voor die laag.
Tip
Het is belangrijk om ervoor te zorgen dat hetzelfde apparaat dat de TensorRT modelgewichten gaat gebruiken voor de inzet, wordt gebruikt voor het exporteren met INT8 precisie, omdat de kalibratieresultaten per apparaat kunnen verschillen.
INT8 export configureren
De argumenten bij het gebruik van export voor een Ultralytics YOLO model zal zeer beïnvloeden de prestaties van het geëxporteerde model. Ze moeten ook worden geselecteerd op basis van de beschikbare apparaatbronnen, maar de standaardargumenten moet werken voor de meeste Ampère (of nieuwer) NVIDIA discrete GPU's. Het gebruikte kalibratiealgoritme is "ENTROPY_CALIBRATION_2" en je kunt meer details lezen over de beschikbare opties in de TensorRT Gids voor ontwikkelaars. Ultralytics tests toonden aan dat "ENTROPY_CALIBRATION_2" was de beste keuze en de export is vast ingesteld op het gebruik van dit algoritme.
-
workspace: Bepaalt de grootte (in GiB) van het toegewezen apparaatgeheugen tijdens het converteren van de modelgewichten.-
Probeer de minimaal
workspacewaarde vereist, omdat dit het testen van algoritmen verhindert die meerworkspaceniet in aanmerking worden genomen door de TensorRT bouwer. Een hogere waarde instellen voorworkspacekunnen aanzienlijk langer om te kalibreren en exporteren. -
Standaard is
workspace=4(GiB), deze waarde moet mogelijk worden verhoogd als kalibratie vastloopt (zonder waarschuwing wordt afgesloten). -
TensorRT zal rapporteren
UNSUPPORTED_STATEtijdens het exporteren als de waarde voorworkspacegroter is dan het geheugen dat beschikbaar is voor het apparaat, wat betekent dat de waarde voorworkspacemoet worden verlaagd. -
Als
workspaceis ingesteld op de maximumwaarde en de kalibratie mislukt/crasht, overweeg dan om de waarden voorimgszenbatchom minder geheugen nodig te hebben. -
Onthoud dat kalibratie voor INT8 specifiek is voor elk apparaat. Een "high-end" GPU lenen voor kalibratie kan resulteren in slechte prestaties wanneer de inferentie wordt uitgevoerd op een ander apparaat.
-
-
batch: De maximale batchgrootte die wordt gebruikt voor inferentie. Tijdens inferentie kunnen kleinere batches worden gebruikt, maar inferentie zal geen batches accepteren die groter zijn dan wat is opgegeven.Opmerking
Tijdens het kalibreren moet tweemaal de
batchverstrekte maat worden gebruikt. Het gebruik van kleine batches kan leiden tot onnauwkeurig schalen tijdens het kalibreren. Dit komt doordat het proces zich aanpast op basis van de gegevens die het ziet. Het is mogelijk dat kleine batches niet het volledige waardenbereik vastleggen, wat leidt tot problemen met de uiteindelijke kalibratie.batchgrootte automatisch verdubbeld. Als er geen partijgrootte is opgegevenbatch=1wordt de kalibratie uitgevoerd opbatch=1 * 2om schaalfouten bij kalibratie te verminderen.
Experimenten van NVIDIA hebben ertoe geleid dat ze aanbevelen om ten minste 500 kalibratieafbeeldingen te gebruiken die representatief zijn voor de gegevens van je model, met INT8 kwantiseringskalibratie. Dit is een richtlijn en geen hard vereiste, en moet je experimenteren met wat nodig is om goed te presteren voor jouw dataset. Omdat de kalibratiegegevens nodig zijn voor INT8-kalibratie met TensorRT, moet je de optie data argument wanneer int8=True voor TensorRT en gebruik data="my_dataset.yaml"die de afbeeldingen van validatie om mee te kalibreren. Als er geen waarde wordt doorgegeven voor data met export naar TensorRT met INT8 kwantisatie, wordt standaard een van de "kleine" voorbeelddatasets op basis van de modeltaak in plaats van een foutmelding te geven.
Voorbeeld
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
model.export(
format="engine",
dynamic=True, #(1)!
batch=8, #(2)!
workspace=4, #(3)!
int8=True,
data="coco.yaml", #(4)!
)
model = YOLO("yolov8n.engine", task="detect") # load the model
- Exporteert met dynamische assen, dit is standaard ingeschakeld bij exporteren met
int8=Truezelfs als het niet expliciet is ingesteld. Zie uitvoerargumenten voor meer informatie. - Stelt de maximale partijgrootte in op 8 voor het geëxporteerde model, dat kalibreert met
batch = 2 *×* 8om schaalfouten tijdens het kalibreren te voorkomen. - Wijst 4 GiB geheugen toe in plaats van het hele apparaat toe te wijzen voor het conversieproces.
- Gebruikt COCO-dataset voor kalibratie, in het bijzonder de beelden die worden gebruikt voor validatie (5.000 in totaal).
Kalibratie cache
TensorRT genereert een kalibratie .cache die kan worden hergebruikt om de export van toekomstige modelgewichten met dezelfde gegevens te versnellen, maar dit kan resulteren in een slechte kalibratie als de gegevens enorm verschillen of als de batch waarde drastisch wordt veranderd. In deze omstandigheden kan de bestaande .cache moet worden hernoemd en verplaatst naar een andere map of helemaal worden verwijderd.
Voordelen van het gebruik van YOLO met TensorRT INT8
-
Kleinere modelgrootte: Quantisatie van FP32 naar INT8 kan de grootte van het model 4x kleiner maken (op schijf of in het geheugen), wat leidt tot snellere downloadtijden, lagere opslagvereisten en een kleinere geheugenvoetafdruk bij het implementeren van een model.
-
Lager stroomverbruik: Gereduceerde precisiebewerkingen voor INT8 geëxporteerde YOLO modellen kunnen minder stroom verbruiken in vergelijking met FP32 modellen, vooral voor apparaten die op batterijen werken.
-
Verbeterde inferentiesnelheden: TensorRT optimaliseert het model voor de doelhardware, wat kan leiden tot hogere inferentiesnelheden op GPU's, embedded apparaten en versnellers.
Opmerking over inferentiesnelheden
De eerste paar inferentie-aanroepen met een model dat geëxporteerd is naar TensorRT INT8 zullen naar verwachting langer duren dan gebruikelijk bij preprocessing, inferentie en/of postprocessing. Dit kan ook voorkomen bij het veranderen van imgsz tijdens inferentie, vooral wanneer imgsz niet hetzelfde is als wat werd opgegeven tijdens het exporteren (export imgsz is ingesteld als TensorRT "optimaal" profiel).
Nadelen van het gebruik van YOLO met TensorRT INT8
-
Afname in evaluatiecijfers: Het gebruik van een lagere precisie betekent dat
mAP,Precision,Recallof een andere metriek die wordt gebruikt om de modelprestaties te evalueren is waarschijnlijk iets erger. Zie de Prestatieresultaten om de verschillen inmAP50enmAP50-95bij het exporteren met INT8 op een kleine steekproef van verschillende apparaten. -
Langere ontwikkeltijden: Het vinden van de "optimale" instellingen voor INT8 kalibratie voor dataset en apparaat kan een aanzienlijke hoeveelheid testen vergen.
-
Afhankelijkheid van hardware: Kalibratie en prestatiewinst kunnen sterk hardwareafhankelijk zijn en modelgewichten zijn minder overdraagbaar.
Ultralytics YOLO TensorRT Exportprestaties
NVIDIA A100
Prestaties
Getest met Ubuntu 22.04.3 LTS, python 3.10.12, ultralytics==8.2.4, tensorrt==8.6.1.post1
Zie Detection Docs voor gebruiksvoorbeelden met deze modellen getraind op COCO, die 80 voorgetrainde klassen bevatten.
Opmerking
Inferentietijden getoond voor mean, min (snelste), en max (langzaamste) voor elke test met behulp van voorgetrainde gewichten yolov8n.engine
| Precisie | Eval test | gemiddelde (ms) |
min | max (ms) |
mAPval 50(B) |
mAPval 50-95(B) |
batch |
grootte (pixels) |
|---|---|---|---|---|---|---|---|
| FP32 | Voorspel | 0.52 | 0.51 | 0.56 | 8 | 640 | ||
| FP32 | COCOval | 0.52 | 0.52 | 0.37 | 1 | 640 | |
| FP16 | Voorspel | 0.34 | 0.34 | 0.41 | 8 | 640 | ||
| FP16 | COCOval | 0.33 | 0.52 | 0.37 | 1 | 640 | |
| INT8 | Voorspel | 0.28 | 0.27 | 0.31 | 8 | 640 | ||
| INT8 | COCOval | 0.29 | 0.47 | 0.33 | 1 | 640 |
Zie Segmentatiedocumenten voor gebruiksvoorbeelden met deze modellen getraind op COCO, die 80 voorgetrainde klassen bevatten.
Opmerking
Inferentietijden getoond voor mean, min (snelste), en max (langzaamste) voor elke test met behulp van voorgetrainde gewichten yolov8n-seg.engine
| Precisie | Eval test | gemiddelde (ms) |
min | max (ms) |
mAPval 50(B) |
mAPval 50-95(B) |
mAPval 50(M) |
mAPval 50-95(M) |
batch |
grootte (pixels) |
|---|---|---|---|---|---|---|---|---|---|
| FP32 | Voorspel | 0.62 | 0.61 | 0.68 | 8 | 640 | ||||
| FP32 | COCOval | 0.63 | 0.52 | 0.36 | 0.49 | 0.31 | 1 | 640 | |
| FP16 | Voorspel | 0.40 | 0.39 | 0.44 | 8 | 640 | ||||
| FP16 | COCOval | 0.43 | 0.52 | 0.36 | 0.49 | 0.30 | 1 | 640 | |
| INT8 | Voorspel | 0.34 | 0.33 | 0.37 | 8 | 640 | ||||
| INT8 | COCOval | 0.36 | 0.46 | 0.32 | 0.43 | 0.27 | 1 | 640 |
Zie Classificatie Documenten voor gebruiksvoorbeelden met deze modellen getraind op ImageNet, die 1000 voorgetrainde klassen bevatten.
Opmerking
Inferentietijden getoond voor mean, min (snelste), en max (langzaamste) voor elke test met behulp van voorgetrainde gewichten yolov8n-cls.engine
| Precisie | Eval test | gemiddelde (ms) |
min | max (ms) |
top-1 | top-5 | batch |
grootte (pixels) |
|---|---|---|---|---|---|---|---|
| FP32 | Voorspel | 0.26 | 0.25 | 0.28 | 0.35 | 0.61 | 8 | 640 |
| FP32 | BeeldNetval | 0.26 | 1 | 640 | |||
| FP16 | Voorspel | 0.18 | 0.17 | 0.19 | 0.35 | 0.61 | 8 | 640 |
| FP16 | BeeldNetval | 0.18 | 1 | 640 | |||
| INT8 | Voorspel | 0.16 | 0.15 | 0.57 | 0.32 | 0.59 | 8 | 640 |
| INT8 | BeeldNetval | 0.15 | 1 | 640 |
Zie Pose Estimation Docs voor gebruiksvoorbeelden met deze modellen getraind op COCO, die 1 voorgetrainde klasse, "persoon", bevatten.
Opmerking
Inferentietijden getoond voor mean, min (snelste), en max (langzaamste) voor elke test met behulp van voorgetrainde gewichten yolov8n-pose.engine
| Precisie | Eval test | gemiddelde (ms) |
min | max (ms) |
mAPval 50(B) |
mAPval 50-95(B) |
mAPval 50(P) |
mAPval 50-95(P) |
batch |
grootte (pixels) |
|---|---|---|---|---|---|---|---|---|---|
| FP32 | Voorspel | 0.54 | 0.53 | 0.58 | 8 | 640 | ||||
| FP32 | COCOval | 0.55 | 0.91 | 0.69 | 0.80 | 0.51 | 1 | 640 | |
| FP16 | Voorspel | 0.37 | 0.35 | 0.41 | 8 | 640 | ||||
| FP16 | COCOval | 0.36 | 0.91 | 0.69 | 0.80 | 0.51 | 1 | 640 | |
| INT8 | Voorspel | 0.29 | 0.28 | 0.33 | 8 | 640 | ||||
| INT8 | COCOval | 0.30 | 0.90 | 0.68 | 0.78 | 0.47 | 1 | 640 |
Zie Oriented Detection Docs voor gebruiksvoorbeelden met deze modellen getraind op DOTAv1, die 15 voorgetrainde klassen bevatten.
Opmerking
Inferentietijden getoond voor mean, min (snelste), en max (langzaamste) voor elke test met behulp van voorgetrainde gewichten yolov8n-obb.engine
| Precisie | Eval test | gemiddelde (ms) |
min | max (ms) |
mAPval 50(B) |
mAPval 50-95(B) |
batch |
grootte (pixels) |
|---|---|---|---|---|---|---|---|
| FP32 | Voorspel | 0.52 | 0.51 | 0.59 | 8 | 640 | ||
| FP32 | DOTAv1val | 0.76 | 0.50 | 0.36 | 1 | 640 | |
| FP16 | Voorspel | 0.34 | 0.33 | 0.42 | 8 | 640 | ||
| FP16 | DOTAv1val | 0.59 | 0.50 | 0.36 | 1 | 640 | |
| INT8 | Voorspel | 0.29 | 0.28 | 0.33 | 8 | 640 | ||
| INT8 | DOTAv1val | 0.32 | 0.45 | 0.32 | 1 | 640 |
GPU's voor consumenten
Detectieprestaties (COCO)
Getest met Windows 10.0.19045, python 3.10.9, ultralytics==8.2.4, tensorrt==10.0.0b6
Opmerking
Inferentietijden getoond voor mean, min (snelste), en max (langzaamste) voor elke test met behulp van voorgetrainde gewichten yolov8n.engine
| Precisie | Eval test | gemiddelde (ms) |
min | max (ms) |
mAPval 50(B) |
mAPval 50-95(B) |
batch |
grootte (pixels) |
|---|---|---|---|---|---|---|---|
| FP32 | Voorspel | 1.06 | 0.75 | 1.88 | 8 | 640 | ||
| FP32 | COCOval | 1.37 | 0.52 | 0.37 | 1 | 640 | |
| FP16 | Voorspel | 0.62 | 0.75 | 1.13 | 8 | 640 | ||
| FP16 | COCOval | 0.85 | 0.52 | 0.37 | 1 | 640 | |
| INT8 | Voorspel | 0.52 | 0.38 | 1.00 | 8 | 640 | ||
| INT8 | COCOval | 0.74 | 0.47 | 0.33 | 1 | 640 |
Getest met Windows 10.0.22631, python 3.11.9, ultralytics==8.2.4, tensorrt==10.0.1
Opmerking
Inferentietijden getoond voor mean, min (snelste), en max (langzaamste) voor elke test met behulp van voorgetrainde gewichten yolov8n.engine
| Precisie | Eval test | gemiddelde (ms) |
min | max (ms) |
mAPval 50(B) |
mAPval 50-95(B) |
batch |
grootte (pixels) |
|---|---|---|---|---|---|---|---|
| FP32 | Voorspel | 1.76 | 1.69 | 1.87 | 8 | 640 | ||
| FP32 | COCOval | 1.94 | 0.52 | 0.37 | 1 | 640 | |
| FP16 | Voorspel | 0.86 | 0.75 | 1.00 | 8 | 640 | ||
| FP16 | COCOval | 1.43 | 0.52 | 0.37 | 1 | 640 | |
| INT8 | Voorspel | 0.80 | 0.75 | 1.00 | 8 | 640 | ||
| INT8 | COCOval | 1.35 | 0.47 | 0.33 | 1 | 640 |
Getest met Pop!_OS 22.04 LTS, python 3.10.12, ultralytics==8.2.4, tensorrt==8.6.1.post1
Opmerking
Inferentietijden getoond voor mean, min (snelste), en max (langzaamste) voor elke test met behulp van voorgetrainde gewichten yolov8n.engine
| Precisie | Eval test | gemiddelde (ms) |
min | max (ms) |
mAPval 50(B) |
mAPval 50-95(B) |
batch |
grootte (pixels) |
|---|---|---|---|---|---|---|---|
| FP32 | Voorspel | 2.84 | 2.84 | 2.85 | 8 | 640 | ||
| FP32 | COCOval | 2.94 | 0.52 | 0.37 | 1 | 640 | |
| FP16 | Voorspel | 1.09 | 1.09 | 1.10 | 8 | 640 | ||
| FP16 | COCOval | 1.20 | 0.52 | 0.37 | 1 | 640 | |
| INT8 | Voorspel | 0.75 | 0.74 | 0.75 | 8 | 640 | ||
| INT8 | COCOval | 0.76 | 0.47 | 0.33 | 1 | 640 |
Ingebedde apparaten
Detectieprestaties (COCO)
Getest met JetPack 5.1.3 (L4T 35.5.0) Ubuntu 20.04.6, python 3.8.10, ultralytics==8.2.4, tensorrt==8.5.2.2
Opmerking
Inferentietijden getoond voor mean, min (snelste), en max (langzaamste) voor elke test met behulp van voorgetrainde gewichten yolov8n.engine
| Precisie | Eval test | gemiddelde (ms) |
min | max (ms) |
mAPval 50(B) |
mAPval 50-95(B) |
batch |
grootte (pixels) |
|---|---|---|---|---|---|---|---|
| FP32 | Voorspel | 6.90 | 6.89 | 6.93 | 8 | 640 | ||
| FP32 | COCOval | 6.97 | 0.52 | 0.37 | 1 | 640 | |
| FP16 | Voorspel | 3.36 | 3.35 | 3.39 | 8 | 640 | ||
| FP16 | COCOval | 3.39 | 0.52 | 0.37 | 1 | 640 | |
| INT8 | Voorspel | 2.32 | 2.32 | 2.34 | 8 | 640 | ||
| INT8 | COCOval | 2.33 | 0.47 | 0.33 | 1 | 640 |
Info
Evaluatiemethoden
Vouw de paragrafen hieronder uit voor informatie over hoe deze modellen zijn geëxporteerd en getest.
Configuraties exporteren
Zie Exportmodus voor meer informatie over argumenten voor de exportconfiguratie.
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
# TensorRT FP32
out = model.export(
format="engine",
imgsz:640,
dynamic:True,
verbose:False,
batch:8,
workspace:2
)
# TensorRT FP16
out = model.export(
format="engine",
imgsz:640,
dynamic:True,
verbose:False,
batch:8,
workspace:2,
half=True
)
# TensorRT INT8
out = model.export(
format="engine",
imgsz:640,
dynamic:True,
verbose:False,
batch:8,
workspace:2,
int8=True,
data:"data.yaml" # COCO, ImageNet, or DOTAv1 for appropriate model task
)
Voorspel lus
Zie Voorspellingsmodus voor meer informatie.
Configuratie validatie
Zie val stand om meer te leren over validatie configuratieargumenten.
Geëxporteerde YOLOv8 TensorRT modellen inzetten
Nadat je je Ultralytics YOLOv8 modellen met succes hebt geëxporteerd naar het TensorRT formaat, ben je nu klaar om ze te implementeren. Voor uitgebreide instructies over het implementeren van je TensorRT modellen in verschillende instellingen, kun je een kijkje nemen in de volgende bronnen:
-
Ultralytics implementeren met een Triton server: Onze gids over het gebruik van NVIDIA's Triton Inference (voorheen TensorRT Inference) Server, specifiek voor gebruik met Ultralytics YOLO modellen.
-
Diepe neurale netwerken inzetten met NVIDIA TensorRT: Dit artikel legt uit hoe je NVIDIA TensorRT kunt gebruiken om diepe neurale netwerken efficiënt in te zetten op GPU-gebaseerde inzetplatforms.
-
End-to-end AI voor op NVIDIA gebaseerde pc's: NVIDIA TensorRT Inzet: In deze blogpost wordt het gebruik van NVIDIA TensorRT uitgelegd voor het optimaliseren en implementeren van AI-modellen op NVIDIA-gebaseerde pc's.
-
GitHub Repository voor NVIDIA TensorRT:: Dit is de officiële GitHub repository die de broncode en documentatie voor NVIDIA TensorRT bevat.
Samenvatting
In deze gids hebben we ons gericht op het converteren van Ultralytics YOLOv8 modellen naar NVIDIA's TensorRT modelformaat. Deze conversiestap is cruciaal voor het verbeteren van de efficiëntie en snelheid van YOLOv8 modellen, waardoor ze effectiever worden en geschikt zijn voor diverse inzetomgevingen.
Kijk voor meer informatie over gebruiksdetails in de officiële documentatie opTensorRT .
Als je nieuwsgierig bent naar aanvullende Ultralytics YOLOv8 integraties, vind je op onze integratiegids pagina een uitgebreide selectie informatieve bronnen en inzichten.
Gemaakt op 2024-01-28, Bijgewerkt op 2024-05-08
Auteurs: Burhan-Q (1), glenn-jocher (1), abirami-vina (1)