SAM 3: Segmenta qualsiasi cosa con i concetti
Ora Disponibile in Ultralytics
SAM 3 è completamente integrato nel pacchetto Ultralytics a partire da versione 8.3.237 (PR #22897). Installa o aggiorna con pip install -U ultralytics per accedere a tutte le funzionalità di SAM 3, inclusa la segmentazione concettuale basata su testo, i prompt di esempio di immagini e il tracciamento video.
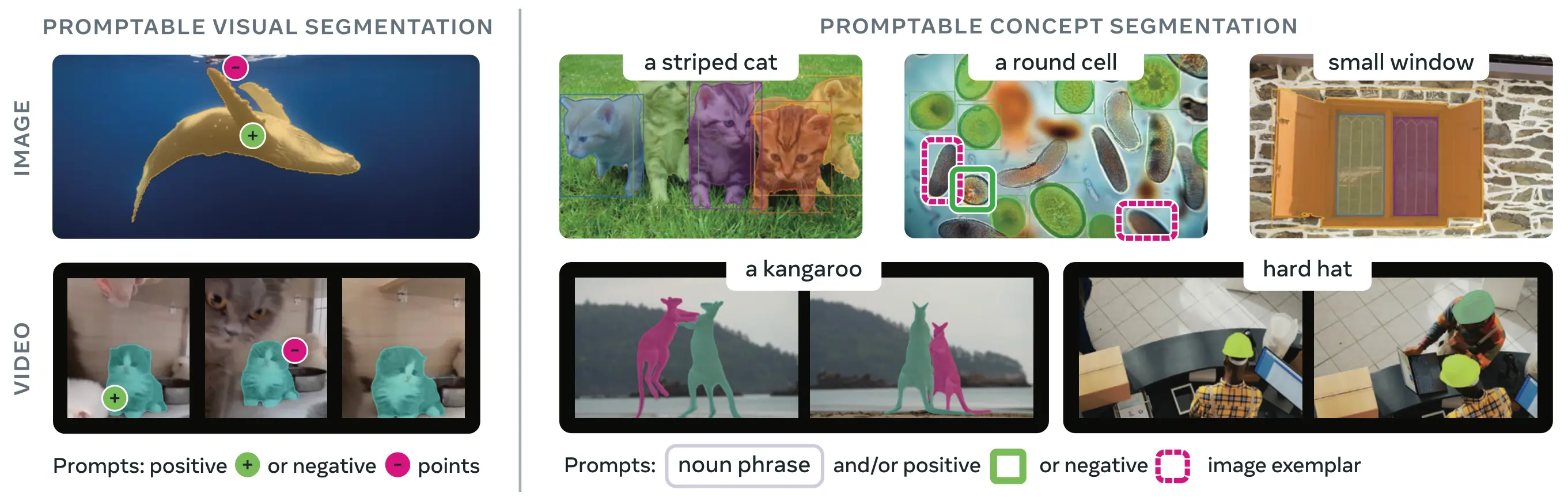
SAM 3 (Segment Anything Model 3) è il modello di base rilasciato da Meta per la Promptable Concept Segmentation (PCS). Basato su SAM 2, SAM 3 introduce una funzionalità fondamentalmente nuova: il detect, la segmentazione e il track di tutte le istanze di un concetto visivo specificato da prompt testuali, esemplari di immagini o entrambi. A differenza delle versioni precedenti di SAM che segmentano singoli oggetti per prompt, SAM 3 può trovare e segmentare ogni occorrenza di un concetto che appare ovunque in immagini o video, allineandosi con gli obiettivi di open-vocabulary nella moderna instance segmentation.
Guarda: Come usare Meta Segment Anything 3 con Ultralytics | Segmentation basata su prompt testuali su immagini e video
SAM 3 è ora completamente integrato nel ultralytics pacchetto, fornendo supporto nativo per la segmentazione concettuale con prompt testuali, prompt di esempio di immagini e funzionalità di tracciamento video.
Panoramica
SAM 3 ottiene un guadagno di prestazioni di 2× rispetto ai sistemi esistenti nella Promptable Concept Segmentation, mantenendo e migliorando le capacità di SAM 2 per la segmentazione visuale interattiva. Il modello eccelle nella segmentazione a vocabolario aperto, consentendo agli utenti di specificare i concetti utilizzando semplici sintagmi nominali (ad esempio, "scuolabus giallo", "gatto a strisce") o fornendo immagini di esempio dell'oggetto target. Queste funzionalità completano le pipeline pronte per la produzione che si basano su flussi di lavoro semplificati di predict e track.
Cos'è la Segmentazione Concettuale Richiedibile (Promptable Concept Segmentation, PCS)?
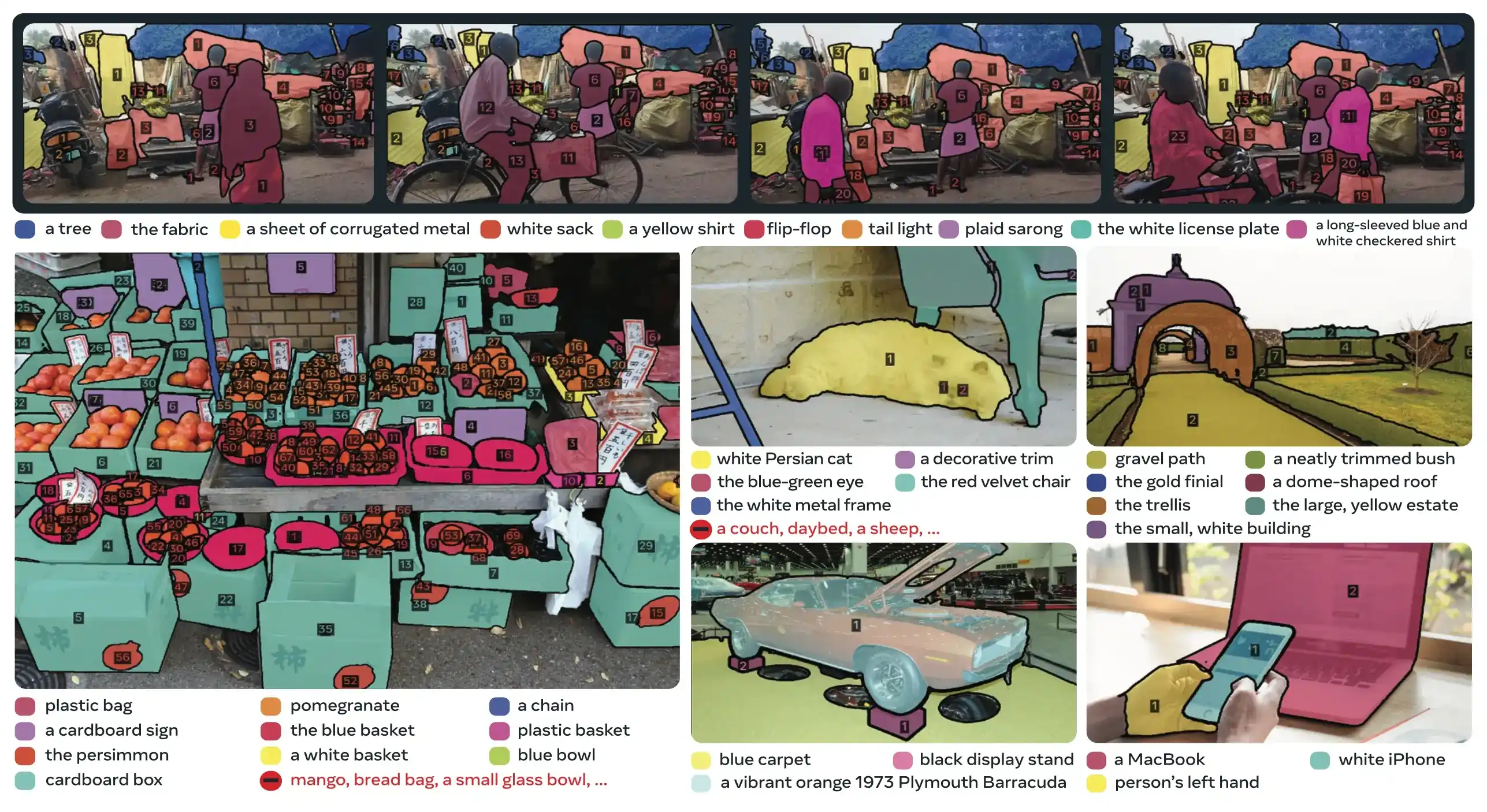
L'attività PCS prende un concept prompt come input e restituisce maschere di segmentazione con identità univoche per tutte le istanze di oggetti corrispondenti. I concept prompt possono essere:
- Testo: Sintagmi nominali semplici come "mela rossa" o "persona che indossa un cappello", simile all'apprendimento zero-shot
- Esemplari di immagine: Riquadri di delimitazione attorno a oggetti di esempio (positivi o negativi) per una rapida generalizzazione
- Combinato: Sia testo che immagini esemplari insieme per un controllo preciso
Questo si differenzia dai tradizionali prompt visivi (punti, riquadri, maschere) che segmentano solo una singola istanza specifica di un oggetto, come reso popolare dalla famiglia SAM originale.
Principali Metriche di Performance
| Metrica | Risultati di SAM 3 |
|---|---|
| AP Maschera Zero-Shot LVIS | 47.0 (vs il precedente miglior risultato di 38.5, +22% di miglioramento) |
| Benchmark SA-Co | 2 volte meglio dei sistemi esistenti |
| Velocità di Inference (GPU H200) | 30 ms per immagine con oltre 100 oggetti detect |
| Prestazioni video | Quasi in tempo reale per ~5 oggetti concorrenti |
| MOSEv2 VOS Benchmark | 60.1 J&F (+25.5% rispetto a SAM 2.1, +17% rispetto al precedente SOTA) |
| Rifinitura interattiva | Miglioramento di +18.6 CGF1 dopo 3 prompt esemplari |
| Divario nelle prestazioni umane | Raggiunge l' 88% del limite inferiore stimato su SA-Co/Gold |
Per il contesto sulle metriche del modello e i compromessi nella produzione, consulta approfondimenti sulla valutazione del modello e metriche di performance YOLO.
Architettura
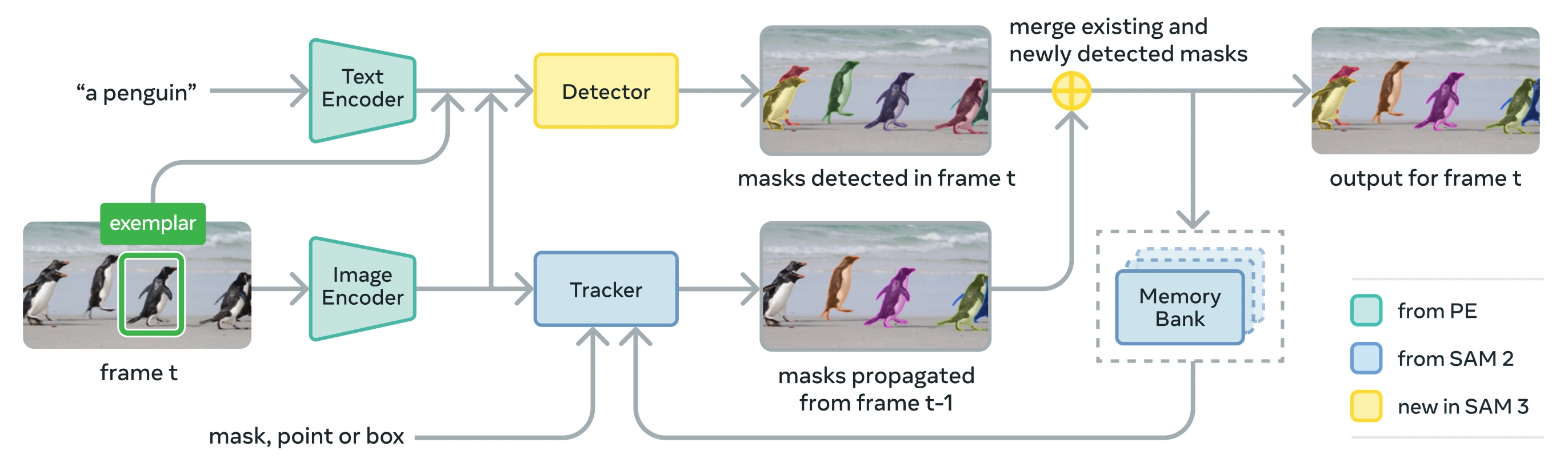
SAM 3 è composto da un detector e un tracker che condividono un backbone di visione Perception Encoder (PE). Questo design disaccoppiato evita conflitti tra compiti, consentendo sia il detection a livello di immagine che il track a livello di video, con un'interfaccia compatibile con l'utilizzo di Ultralytics Python e l'CLI.
Componenti Principali
Detector: Architettura basata su DETR per la concept detection a livello di immagine
- Codificatore di testo per prompt di sintagmi nominali
- Encoder esemplare per prompt basati su immagini
- Codificatore di fusione per condizionare le caratteristiche dell'immagine sui prompt
- Nuovo presence head che disaccoppia il riconoscimento ("cosa") dalla localizzazione ("dove")
- Head maschera per generare maschere di segmentazione dell'istanza
Tracker: Segmentazione video basata sulla memoria ereditata da SAM 2
- Codificatore di prompt, decodificatore di maschere, codificatore di memoria
- Banca di memoria per memorizzare l'aspetto degli oggetti tra i frame
- Disambiguazione temporale supportata da tecniche come un filtro di Kalman in contesti multi-oggetto
Token di Presenza: Un token globale appreso che prevede se il concetto target è presente nell'immagine/frame, migliorando la detection separando il riconoscimento dalla localizzazione.
Innovazioni Chiave
- Riconoscimento e localizzazione disaccoppiati: L'head di presenza prevede la presenza del concetto a livello globale, mentre le query di proposta si concentrano solo sulla localizzazione, evitando obiettivi contrastanti.
- Concetti unificati e prompt visivi: Supporta sia PCS (prompt concettuali) che PVS (prompt visivi come i clic/riquadri di SAM 2) in un singolo modello.
- Rifinitura interattiva basata su esemplari: Gli utenti possono aggiungere esemplari di immagini positivi o negativi per affinare iterativamente i risultati, con il modello che generalizza a oggetti simili piuttosto che correggere solo singole istanze.
- Disambiguazione temporale: utilizza i punteggi di rilevamento masklet e il re-prompting periodico per gestire occlusioni, scene affollate e fallimenti di tracking nei video, in linea con le best practice di segmentazione e tracking di istanze.
Dataset SA-Co
SAM 3 è addestrato su Segment Anything with Concepts (SA-Co), il set di dati di segmentazione più grande e diversificato di Meta fino ad oggi, che si espande oltre i benchmark comuni come COCO e LVIS.
Dati di addestramento
| Componente del Dataset | Descrizione | Scala |
|---|---|---|
| SA-Co/HQ | Dati di immagini annotati da umani di alta qualità dal motore di dati a 4 fasi | 5.2M immagini, 4M sintagmi nominali unici |
| SA-Co/SYN | Set di dati sintetici etichettato dall'IA senza coinvolgimento umano | 38M sintagmi nominali, 1.4B maschere |
| SA-Co/EXT | 15 dataset esterni arricchiti con negativi difficili | Varia in base alla fonte |
| SA-Co/VIDEO | Annotazioni video con temporal track | 52.5K video, 24.8K sintagmi nominali unici |
Dati di benchmark
Il benchmark di valutazione SA-Co contiene 214.000 frasi uniche in 126.000 immagini e video, fornendo oltre 50 volte più concetti rispetto ai benchmark esistenti. Include:
- SA-Co/Gold: 7 domini, con tripla annotazione per misurare i limiti delle prestazioni umane
- SA-Co/Silver: 10 domini, singola annotazione umana
- SA-Co/Bronze e SA-Co/Bio: 9 dataset esistenti adattati per la segmentazione concettuale
- SA-Co/VEval: Benchmark video con 3 domini (SA-V, YT-Temporal-1B, SmartGlasses)
Innovazioni del Motore di Dati
Il motore dati scalabile human- and model-in-the-loop di SAM 3 raggiunge una produttività di annotazione 2× tramite:
- Annotatori AI: I modelli basati su Llama propongono diverse frasi nominali, inclusi i negativi difficili
- Verificatori AI: I LLM multimodali ottimizzati verificano la qualità e l'esaustività della maschera con prestazioni quasi umane
- Active Mining: Concentra lo sforzo umano sui casi di errore impegnativi in cui l'IA fatica
- Basato Sull'Ontologia: Sfrutta una vasta ontologia basata su Wikidata per la copertura dei concetti
Installazione
SAM 3 è disponibile in Ultralytics versione 8.3.237 e successive. Installa o aggiorna con:
pip install -U ultralytics
Pesi del Modello SAM 3 Richiesti
A differenza di altri modelli Ultralytics, i pesi di SAM 3 (sam3.pt) non sono scaricati automaticamente. È necessario prima richiedere l'accesso ai pesi del modello sulla pagina del modello SAM 3 su Hugging Face e poi, una volta approvato, scaricare il sam3.pt file. Posizionare il file scaricato sam3.pt nella directory di lavoro o specificare il percorso completo durante il caricamento del modello.
TypeError: 'SimpleTokenizer' object is not callable
Se durante la previsione viene visualizzato il messaggio di errore sopra riportato, significa che hai inserito un valore errato. clip pacchetto installato. Installare quello corretto. clip pacchetto eseguendo quanto segue:
pip uninstall clip -y
pip install git+https://github.com/ultralytics/CLIP.git
Come utilizzare SAM 3: Versatilità nella segmentazione concettuale
SAM 3 supporta sia i compiti di Promptable Concept Segmentation (PCS) che di Promptable Visual Segmentation (PVS) tramite diverse interfacce predittive:
Modelli e attività supportati
| Tipo di attività | Tipi di prompt | Output |
|---|---|---|
| Segmentazione concettuale (PCS) | Testo (sintagmi nominali), esempi di immagini | Tutte le istanze corrispondenti al concetto |
| Segmentazione visiva (PVS) | Punti, box, maschere | Istanza di singolo oggetto (stile SAM 2) |
| Rifinitura interattiva | Aggiungi/rimuovi esemplari o clic in modo iterativo | Segmentazione raffinata con maggiore accuratezza |
Esempi di segmentazione concettuale
Segmenta con prompt di testo
Segmentazione concettuale basata su testo
Trova e segmenta tutte le istanze di un concetto utilizzando una descrizione testuale. I prompt testuali richiedono l' SAM3SemanticPredictor interfaccia.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor with configuration
overrides = dict(
conf=0.25,
task="segment",
mode="predict",
model="sam3.pt",
half=True, # Use FP16 for faster inference
save=True,
)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image once for multiple queries
predictor.set_image("path/to/image.jpg")
# Query with multiple text prompts
results = predictor(text=["person", "bus", "glasses"])
# Works with descriptive phrases
results = predictor(text=["person with red cloth", "person with blue cloth"])
# Query with a single concept
results = predictor(text=["a person"])
Segmenta con esemplari di immagini
Segmentazione basata su esemplari di immagini
Utilizza i bounding box come prompt visivi per trovare tutte le istanze simili. Questo richiede anche SAM3SemanticPredictor per la corrispondenza basata su concetti.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", half=True, save=True)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image
predictor.set_image("path/to/image.jpg")
# Provide bounding box examples to segment similar objects
results = predictor(bboxes=[[480.0, 290.0, 590.0, 650.0]])
# Multiple bounding boxes for different concepts
results = predictor(bboxes=[[539, 599, 589, 639], [343, 267, 499, 662]])
Inferenza basata su funzionalità per l'efficienza
Riutilizzo delle Caratteristiche dell'Immagine per Query Multiple
Estrai le caratteristiche dell'immagine una volta e riutilizzale per query di segmentazione multiple per migliorare l'efficienza.
import cv2
from ultralytics.models.sam import SAM3SemanticPredictor
from ultralytics.utils.plotting import Annotator, colors
# Initialize predictors
overrides = dict(conf=0.50, task="segment", mode="predict", model="sam3.pt", verbose=False)
predictor = SAM3SemanticPredictor(overrides=overrides)
predictor2 = SAM3SemanticPredictor(overrides=overrides)
# Extract features from the first predictor
source = "path/to/image.jpg"
predictor.set_image(source)
src_shape = cv2.imread(source).shape[:2]
# Setup second predictor and reuse features
predictor2.setup_model()
# Perform inference using shared features with text prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, text=["person"])
# Perform inference using shared features with bounding box prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, bboxes=[[439, 437, 524, 709]])
# Visualize results
if masks is not None:
masks, boxes = masks.cpu().numpy(), boxes.cpu().numpy()
im = cv2.imread(source)
annotator = Annotator(im, pil=False)
annotator.masks(masks, [colors(x, True) for x in range(len(masks))])
cv2.imshow("result", annotator.result())
cv2.waitKey(0)
Segmentazione concettuale video
Tracciare Concetti Attraverso il Video con Bounding Box
Tracciamento Video con Prompt Visivi
detect e track istanze di oggetti attraverso i fotogrammi video utilizzando prompt di bounding box.
from ultralytics.models.sam import SAM3VideoPredictor
# Create video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", half=True)
predictor = SAM3VideoPredictor(overrides=overrides)
# Track objects using bounding box prompts
results = predictor(source="path/to/video.mp4", bboxes=[[706.5, 442.5, 905.25, 555], [598, 635, 725, 750]], stream=True)
# Process and display results
for r in results:
r.show() # Display frame with segmentation masks
Tracciare Concetti con Prompt Testuali
Tracking Video con Query Semantiche
track tutte le istanze di concetti specificati dal testo attraverso i fotogrammi video.
from ultralytics.models.sam import SAM3VideoSemanticPredictor
# Initialize semantic video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=640, model="sam3.pt", half=True, save=True)
predictor = SAM3VideoSemanticPredictor(overrides=overrides)
# Track concepts using text prompts
results = predictor(source="path/to/video.mp4", text=["person", "bicycle"], stream=True)
# Process results
for r in results:
r.show() # Display frame with tracked objects
# Alternative: Track with bounding box prompts
results = predictor(
source="path/to/video.mp4",
bboxes=[[864, 383, 975, 620], [705, 229, 782, 402]],
labels=[1, 1], # Positive labels
stream=True,
)
Prompt visivi (Compatibilità SAM 2)
SAM 3 mantiene la piena compatibilità retroattiva con il prompting visivo di SAM 2 per la segmentazione di oggetti singoli:
Prompt visivi di stile SAM 2
L'interfaccia base SAM si comporta esattamente come SAM 2, segmentando solo l'area specifica indicata da prompt visivi (punti, box o maschere).
from ultralytics import SAM
model = SAM("sam3.pt")
# Single point prompt - segments object at specific location
results = model.predict(source="path/to/image.jpg", points=[900, 370], labels=[1])
results[0].show()
# Multiple points - segments single object with multiple point hints
results = model.predict(source="path/to/image.jpg", points=[[400, 370], [900, 370]], labels=[1, 1])
# Box prompt - segments object within bounding box
results = model.predict(source="path/to/image.jpg", bboxes=[100, 150, 300, 400])
results[0].show()
Prompt Visivi vs Segmentazione di Concetti
L'utilizzo di SAM("sam3.pt") con prompt visivi (punti/box/maschere) segmenterà solo l'oggetto specifico in quella posizione, proprio come SAM 2. Per segment tutte le istanze di un concetto, usa SAM3SemanticPredictor con prompt testuali o esemplari come mostrato sopra.
Benchmark delle prestazioni
Segmentazione delle immagini
SAM 3 ottiene risultati all'avanguardia in diversi benchmark, inclusi set di dati del mondo reale come LVIS e COCO per la segmentazione:
| Benchmark | Metrica | SAM 3 | Migliore precedente | Miglioramento |
|---|---|---|---|---|
| LVIS (zero-shot) | AP maschera | 47.0 | 38.5 | +22.1% |
| SA-Co/Gold | CGF1 | 65.0 | 34.3 (OWLv2) | +89.5% |
| COCO (zero-shot) | AP Box | 53.5 | 52.2 (T-Rex2) | +2.5% |
| ADE-847 (segmentazione semantica) | mIoU | 14.7 | 9.2 (APE-D) | +59.8% |
| PascalConcept-59 | mIoU | 59.4 | 58.5 (APE-D) | +1.5% |
| Cityscapes (segmentazione semantica) | mIoU | 65.1 | 44.2 (APE-D) | +47.3% |
Esplora le opzioni di dataset per una rapida sperimentazione nei dataset Ultralytics.
Prestazioni di segmentazione video
SAM 3 mostra miglioramenti significativi rispetto a SAM 2 e allo stato dell'arte precedente nei benchmark video come DAVIS 2017 e YouTube-VOS:
| Benchmark | Metrica | SAM 3 | SAM 2.1 L | Miglioramento |
|---|---|---|---|---|
| MOSEv2 | J&F | 60.1 | 47.9 | +25.5% |
| DAVIS 2017 | J&F | 92.0 | 90.7 | +1.4% |
| LVOSv2 | J&F | 88.2 | 79.6 | +10.8% |
| SA-V | J&F | 84.6 | 78.4 | +7.9% |
| YTVOS19 | J&F | 89.6 | 89.3 | +0.3% |
Adattamento Few-Shot
SAM 3 eccelle nell'adattarsi a nuovi domini con esempi minimi, rilevante per i flussi di lavoro di AI incentrata sui dati:
| Benchmark | AP 0-shot | AP 10-shot | Migliore precedente (10-shot) |
|---|---|---|---|
| ODinW13 | 59.9 | 71.6 | 67.9 (gDino1.5-Pro) |
| RF100-VL | 14.3 | 35.7 | 33.7 (gDino-T) |
Efficacia della rifinitura interattiva
Il prompting basato su concetti di SAM 3 con esemplari converge molto più velocemente del prompting visivo:
| Prompt aggiunti | Punteggio CGF1 | Guadagno rispetto al solo testo | Guadagno rispetto alla baseline PVS |
|---|---|---|---|
| Solo testo | 46.4 | baseline | baseline |
| +1 esemplare | 57.6 | +11.2 | +6.7 |
| +2 esemplari | 62.2 | +15.8 | +9.7 |
| +3 esemplari | 65.0 | +18.6 | +11.2 |
| +4 esemplari | 65.7 | +19.3 | +11.5 (plateau) |
Precisione nel conteggio degli oggetti
SAM 3 fornisce un conteggio accurato segmentando tutte le istanze, un requisito comune nel conteggio degli oggetti:
| Benchmark | Accuratezza | MAE | vs Miglior MLLM |
|---|---|---|---|
| CountBench | 95.6% | 0.11 | 92.4% (Gemini 2.5) |
| PixMo-Count | 87.3% | 0.22 | 88.8% (Molmo-72B) |
Confronto tra SAM 3, SAM 2 e YOLO
Qui mettiamo a confronto le prestazioni SAM con quelle dei modelli SAM e YOLO26:
| Capacità | SAM 3 | SAM 2 | YOLO26n-seg |
|---|---|---|---|
| Segmentazione concettuale | ✅ Tutte le istanze da testo/esemplari | ❌ Non supportato | ❌ Non supportato |
| Segmentazione visiva | ✅ Singola istanza (compatibile con SAM 2) | ✅ Singola istanza | ✅ Tutte le istanze |
| Capacità Zero-shot | ✅ Vocabolario aperto | ✅ Prompt geometrici | ❌ Set chiuso |
| Rifinitura interattiva | ✅ Esemplari + clic | ✅ Solo clic | ❌ Non supportato |
| Video track | ✅ Multi-oggetto con identità | ✅ Multi-oggetto | ✅ Multi-oggetto |
| AP Maschera LVIS (zero-shot) | 47.0 | N/A | N/A |
| MOSEv2 J&F | 60.1 | 47.9 | N/A |
| Velocità (GPU, ms/immagine) | 2921 | 857 | 8.4 |
| Dimensione del modello | 3,45 GB | 162 MB (base) | 6,4 MB |
Prestazioni di velocità misurate su NVIDIA PRO 6000 con torch==2.9.1 e ultralytics==8.4.19.
Punti chiave:
- SAM 3: Ottimale per la segmentazione di concetti open-vocabulary, trovando tutte le istanze di un concetto con prompt testuali o esemplari
- SAM 2: Ottimale per la segmentazione interattiva di singoli oggetti in immagini e video con prompt geometrici
- YOLO26: ideale per la segmentazione in tempo reale ad alta velocità con inferenza end-to-end NMS, esportabile in numerosi formati per l'implementazione su GPU, CPU e dispositivi edge
Confronto tra SAM e YOLO
Confronto FastSAM SAM , SAM , SAM, MobileSAM e FastSAM i modelliYOLO Ultralytics (YOLOv8, YOLO11, YOLO26) in termini di dimensioni, parametri e velocità GPU :
| Modello | Dimensione (MB) | Parametri (M) | Velocità (GPU) (ms/im) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 1306 |
| Meta SAM2-b | 162 | 80.8 | 857 |
| Meta SAM2-t | 78.1 | 38.9 | 668 |
| Meta SAM3 | 3450 | 473.6 | 2921 |
| MobileSAM | 40.7 | 10.1 | 605 |
| FastSAM-s con backbone YOLOv8 | 23.7 | 11.8 | 55.9 |
| Ultralytics YOLOv8n-seg | 6,7 (515 volte più piccolo) | 3.4 (139.1x minore) | 17.4 (167x più veloce) |
| Ultralytics YOLO11n-seg | 5,9 (585 volte più piccolo) | 2.9 (163.1x minore) | 12.6 (231x più veloce) |
| Ultralytics YOLO26n-seg | 6,4 (539 volte più piccolo) | 2.7 (175.2x minore) | 8.4 (347x più veloce) |
Questo confronto dimostra le differenze sostanziali nelle dimensioni e nelle velocità dei modelli tra le varianti SAM e i modelli di segmentazione YOLO. Mentre SAM offre capacità di segmentazione automatica uniche, i modelli YOLO, in particolare YOLOv8n-seg, YOLO11n-seg e YOLO26n-seg, sono significativamente più piccoli, veloci e computazionalmente più efficienti.
Test eseguiti su una NVIDIA RTX PRO 6000 con 96GB di VRAM utilizzando torch==2.9.1 e ultralytics==8.4.19. Per riprodurre questo test:
Esempio
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# Profile SAM3, SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt", "sam3.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# Profile FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# Profile YOLO models
for file_name in ["yolov8n-seg.pt", "yolo11n-seg.pt", "yolo26n-seg.pt"]:
model = YOLO(file_name)
model.info()
model(ASSETS)
Metriche di valutazione
SAM 3 introduce nuove metriche progettate per il compito PCS, che completano le misure familiari come il punteggio F1, la precisione e il richiamo.
F1 con gate di classificazione (CGF1)
La metrica principale che combina localizzazione e classificazione:
CGF1 = 100 × pmF1 × IL_MCC
Dove:
- pmF1 (Macro F1 Positivo): Misura la qualità della localizzazione su esempi positivi
- IL_MCC (Coefficiente di correlazione di Matthews a livello di immagine): Misura l'accuratezza della classificazione binaria ("il concetto è presente?")
Perché queste metriche?
Le metriche AP tradizionali non tengono conto della calibrazione, rendendo i modelli difficili da usare nella pratica. Valutando solo le predizioni con un livello di confidenza superiore a 0.5, le metriche di SAM 3 impongono una buona calibrazione e simulano i modelli di utilizzo nel mondo reale nei loop interattivi di predict e track.
Ablazioni e approfondimenti chiave
Impatto dell'Head di Presenza
L'head di presenza disaccoppia il riconoscimento dalla localizzazione, fornendo miglioramenti significativi:
| Configurazione | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Senza presenza | 57.6 | 0.77 | 74.7 |
| Con presenza | 63.3 | 0.82 | 77.1 |
L'head di presenza fornisce un aumento di +5,7 CGF1 (+9,9%), migliorando principalmente la capacità di riconoscimento (IL_MCC +6,5%).
Effetto dei negativi difficili
| Negativi Difficili/Immagine | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 0 | 31.8 | 0.44 | 70.2 |
| 5 | 44.8 | 0.62 | 71.9 |
| 30 | 49.2 | 0.68 | 72.3 |
I negativi difficili sono fondamentali per il riconoscimento a vocabolario aperto, migliorando IL_MCC del 54,5% (0,44 → 0,68).
Ridimensionamento dei dati di addestramento
| Fonti di Dati | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Solo esterno | 30.9 | 0.46 | 66.3 |
| Esterno + Sintetico | 39.7 | 0.57 | 70.6 |
| Esterno + HQ | 51.8 | 0.71 | 73.2 |
| Tutti e tre | 54.3 | 0.74 | 73.5 |
Annotazioni umane di alta qualità forniscono grandi vantaggi rispetto ai soli dati sintetici o esterni. Per informazioni di base sulle pratiche di qualità dei dati, consultare raccolta e annotazione dei dati.
Applicazioni
La capacità di segmentazione concettuale di SAM 3 abilita nuovi casi d'uso:
- Moderazione dei contenuti: Trova tutte le istanze di specifici tipi di contenuto nelle librerie multimediali
- E-commerce: segment tutti i prodotti di un certo tipo nelle immagini del catalogo, supportando l'auto-annotazione.
- Imaging medicale: Identifica tutte le occorrenze di specifici tipi di tessuto o anomalie
- Sistemi autonomi: Esegui il track di tutte le istanze di segnali stradali, pedoni o veicoli per categoria
- Analisi video: Contare e tracciare tutte le persone che indossano abiti specifici o che eseguono determinate azioni
- Annotazione del dataset: Annota rapidamente tutte le istanze di categorie di oggetti rari
- Ricerca scientifica: Quantificare e analizzare tutti i campioni che corrispondono a criteri specifici
SAM 3 Agent: Ragionamento linguistico esteso
SAM 3 può essere combinato con modelli linguistici di grandi dimensioni multimodali (MLLM) per gestire query complesse che richiedono ragionamento, in modo simile ai sistemi a vocabolario aperto come OWLv2 e T-Rex.
Performance su attività di ragionamento
| Benchmark | Metrica | SAM 3 Agent (Gemini 2.5 Pro) | Migliore precedente |
|---|---|---|---|
| ReasonSeg (convalida) | gIoU | 76.0 | 65.0 (SoTA) |
| ReasonSeg (test) | gIoU | 73.8 | 61.3 (SoTA) |
| OmniLabel (convalida) | AP | 46.7 | 36.5 (REAL) |
| RefCOCO+ | Acc | 91.2 | 89.3 (LISA) |
Esempio di query complesse
SAM 3 Agent è in grado di gestire query che richiedono ragionamento:
- "Persone sedute che non tengono in mano una confezione regalo"
- "Il cane più vicino alla telecamera che non indossa un collare"
- "Oggetti rossi più grandi della mano della persona"
L'MLLM propone semplici query di sintagmi nominali a SAM 3, analizza le maschere restituite e itera fino a quando non è soddisfatto.
Limitazioni
Sebbene SAM 3 rappresenti un importante progresso, presenta alcune limitazioni:
- Complessità delle Frasi: Più adatto per semplici sintagmi nominali; espressioni referenziali lunghe o ragionamenti complessi potrebbero richiedere l'integrazione di MLLM.
- Gestione dell'ambiguità: Alcuni concetti rimangono intrinsecamente ambigui (ad esempio, "finestra piccola", "stanza accogliente")
- Requisiti computazionali: Più grande e più lento dei modelli di detect specializzati come YOLO
- Ambito del vocabolario: Focalizzato su concetti visivi atomici; il ragionamento compositivo è limitato senza l'assistenza di MLLM.
- Concetti Rari: Le prestazioni possono peggiorare su concetti estremamente rari o granulari non ben rappresentati nei dati di addestramento
Citazione
@inproceedings{sam3_2025,
title = {SAM 3: Segment Anything with Concepts},
author = {Anonymous authors},
booktitle = {Submitted to ICLR 2026},
year = {2025},
url = {https://openreview.net/forum?id=r35clVtGzw},
note = {Paper ID: 4183, under double-blind review}
}
FAQ
Quando è stato rilasciato SAM 3?
SAM 3 è stato rilasciato da Meta il 20 novembre 2025 ed è completamente integrato in Ultralytics a partire dalla versione 8.3.237 (PR #22897). Il supporto completo è disponibile per la modalità predict e la modalità track.
SAM 3 è integrato in Ultralytics?
Sì! SAM è completamente integrato nelPython Ultralytics , compresi la segmentazione per concetti, i prompt visivi SAM e il tracciamento video multi-oggetto. SAM è inoltre alla base della funzione di annotazione intelligente della Ultralytics , che consente di annotare le immagini con pochi clic.
Cos'è la Segmentazione Concettuale Richiedibile (Promptable Concept Segmentation, PCS)?
PCS è una nuova attività introdotta in SAM 3 che segmenta tutte le istanze di un concetto visivo in un'immagine o in un video. A differenza della segmentazione tradizionale che mira a una specifica istanza di oggetto, PCS trova ogni occorrenza di una categoria. Per esempio:
- Testo prompt: "scuolabus giallo" → segmenta tutti gli scuolabus gialli nella scena
- Esemplare di immagine: Riquadro attorno a un cane → segment tutti i cani nell'immagine
- Combinato: "gatto tigrato" + box esemplare → segment tutti i gatti tigrati corrispondenti all'esempio
Vedi informazioni di background correlate su object detection e instance segmentation.
In cosa si differenzia SAM 3 da SAM 2?
| Funzionalità | SAM 2 | SAM 3 |
|---|---|---|
| Task | Singolo oggetto per prompt | Tutte le istanze di un concetto |
| Tipi di prompt | Punti, box, maschere | + Frasi di testo, esemplari di immagini |
| Capacità di detection | Richiede un detector esterno | Detector open-vocabulary integrato |
| Riconoscimento | Solo basato sulla geometria | Riconoscimento testuale e visivo |
| Architettura | Solo tracker | Detector + Tracker con presence head |
| Prestazioni Zero-Shot | N/D (richiede prompt visivi) | 47.0 AP su LVIS, 2× migliore su SA-Co |
| Rifinitura interattiva | Solo clic | Clic + generalizzazione esemplare |
SAM 3 mantiene la compatibilità con le versioni precedenti con il prompting visivo di SAM 2 aggiungendo al contempo funzionalità basate su concetti.
Quali dataset vengono utilizzati per addestrare SAM 3?
SAM 3 è addestrato sul set di dati Segment Anything with Concepts (SA-Co):
Dati di addestramento:
- 5,2 milioni di immagini con 4 milioni di sintagmi nominali unici (SA-Co/HQ) - annotazioni umane di alta qualità
- 52.500 video con 24.800 sintagmi nominali unici (SA-Co/VIDEO)
- 1.4B di maschere sintetiche attraverso 38M di sintagmi nominali (SA-Co/SYN)
- 15 dataset esterni arricchiti con negativi difficili (SA-Co/EXT)
Dati di benchmark:
- 214K concetti unici attraverso 126K immagini/video
- 50 volte più concetti rispetto ai benchmark esistenti (ad esempio, LVIS ha circa 4.000 concetti)
- Annotazione tripla su SA-Co/Gold per misurare i limiti delle prestazioni umane
Questa massiccia scala e diversità consente la generalizzazione zero-shot superiore di SAM 3 attraverso concetti di vocabolario aperto.
Come si comporta SAM rispetto a YOLO26 nella segmentazione?
SAM e YOLO26 sono destinati a casi d'uso diversi:
Vantaggi di SAM 3:
- Vocabolario aperto: Segmenta qualsiasi concetto tramite prompt testuali senza addestramento
- Zero-shot: Funziona immediatamente su nuove categorie
- Interattivo: La rifinitura basata su esemplari si generalizza a oggetti simili
- Basato su concetti: Trova automaticamente tutte le istanze di una categoria
- Accuratezza: 47.0 AP sulla segmentazione di istanze zero-shot LVIS
Vantaggi di YOLO26:
- Velocità: inferenza di gran lunga più veloce grazie a un design end-to-end NMS
- Efficienza: modelli 539 volte più piccoli (6,4 MB contro 3,45 GB)
- A basso consumo di risorse: Funziona su dispositivi edge e dispositivi mobili
- Tempo reale: Ottimizzato per implementazioni di produzione
Raccomandazione:
- Usa SAM 3 per una segmentazione flessibile e a vocabolario aperto, dove è necessario trovare tutte le istanze di concetti descritti da testo o esempi
- Utilizza YOLO26 per implementazioni in produzione ad alta velocità in cui le categorie sono note in anticipo
- Usa SAM 2 per la segmentazione interattiva di singoli oggetti con prompt geometrici
SAM 3 è in grado di gestire query linguistiche complesse?
SAM 3 è progettato per semplici sintagmi nominali (ad esempio, "mela rossa", "persona che indossa un cappello"). Per query complesse che richiedono ragionamento, combina SAM 3 con un MLLM come SAM 3 Agent:
Query semplici (SAM 3 nativo):
- "Scuolabus giallo"
- "Gatto tigrato"
- "Persona che indossa un cappello rosso"
Query complesse (SAM 3 Agent con MLLM):
- "Persone sedute che non tengono in mano una confezione regalo"
- "Il cane più vicino alla telecamera senza collare"
- "Oggetti rossi più grandi della mano della persona"
SAM 3 Agent ottiene 76.0 gIoU sulla convalida ReasonSeg (vs 65.0 il miglior risultato precedente, +16.9% di miglioramento) combinando la segmentazione di SAM 3 con le capacità di ragionamento MLLM.
Quanto è preciso SAM 3 rispetto alle prestazioni umane?
Sul benchmark SA-Co/Gold con tripla annotazione umana:
- Limite inferiore umano: 74.2 CGF1 (annotatore più conservativo)
- Prestazioni di SAM 3: 65.0 CGF1
- Risultato: 88% del limite inferiore umano stimato
- Limite superiore umano: 81.4 CGF1 (annotatore più liberale)
SAM 3 ottiene prestazioni elevate, avvicinandosi all'accuratezza del livello umano nella segmentazione di concetti a vocabolario aperto, con il divario principalmente su concetti ambigui o soggettivi (ad esempio, "finestra piccola", "stanza accogliente").







