Ultralytics YOLO26
Panoramica
Ultralytics YOLO26 è l'ultima evoluzione della serie YOLO di rilevatori di oggetti in tempo reale, progettata da zero per dispositivi edge e a bassa potenza. Introduce un design semplificato che elimina la complessità non necessaria integrando al contempo innovazioni mirate per offrire una distribuzione più rapida, leggera e accessibile.
Prova Ultralytics
Esplora ed esegui i modelli YOLO26 direttamente sulla Ultralytics .
L'architettura di YOLO26 è guidata da tre principi fondamentali:
- Semplicità: YOLO26 è un modello end-to-end nativo, che produce previsioni direttamente senza la necessità di una soppressione non massima (NMS). Eliminando questa fase di post-elaborazione, l'inferenza diventa più veloce, leggera e facile da implementare nei sistemi del mondo reale. Questo approccio innovativo è stato introdotto per la prima volta in YOLOv10 da Ao Wang alla Tsinghua University ed è stato ulteriormente sviluppato in YOLO26.
- Efficienza di implementazione: Il design end-to-end elimina un'intera fase della pipeline, semplificando notevolmente l'integrazione, riducendo la latenza e rendendo l'implementazione più robusta in diversi ambienti.
- Innovazione nell'addestramento: YOLO26 introduce l'ottimizzatore MuSGD, un ibrido di SGD e Muon — ispirato alle scoperte di Kimi K2 di Moonshot AI nell'addestramento di LLM. Questo ottimizzatore offre una maggiore stabilità e una convergenza più rapida, trasferendo i progressi dell'ottimizzazione dai modelli linguistici alla computer vision.
- Ottimizzazioni Specifiche per Task: YOLO26 introduce miglioramenti mirati per task specializzati, inclusa la loss di segmentazione semantica e moduli proto multiscala per la Segmentazione, la Stima della Log-Verosimiglianza Residua (RLE) per l'alta precisione nella Posa, e il decoding ottimizzato con angle loss per risolvere i problemi di confine in OBB.
Insieme, queste innovazioni offrono una famiglia di modelli che raggiunge una maggiore accuratezza su piccoli oggetti, fornisce un'implementazione senza interruzioni e funziona fino al 43% più velocemente sulle CPU — rendendo YOLO26 uno dei modelli YOLO più pratici e implementabili fino ad oggi per ambienti con risorse limitate.
Caratteristiche principali
Rimozione di DFL
Il modulo Distribution Focal Loss (DFL), sebbene efficace, spesso complicava l'esportazione e limitava la compatibilità hardware. YOLO26 rimuove completamente DFL, semplificando l'inferenza e ampliando il supporto per dispositivi edge e a bassa potenza.Inferenza End-to-End NMS-Free
A differenza dei rivelatori tradizionali che si affidano a NMS come fase di post-elaborazione separata, YOLO26 è nativamente end-to-end. Le previsioni vengono generate direttamente, riducendo la latenza e rendendo l'integrazione nei sistemi di produzione più veloce, leggera e affidabile.ProgLoss + STAL
Funzioni di perdita migliorate aumentano l'accuratezza del detection, con notevoli miglioramenti nel riconoscimento di oggetti piccoli, un requisito fondamentale per IoT, robotica, immagini aeree e altre applicazioni edge.Ottimizzatore MuSGD
Un nuovo ottimizzatore ibrido che combina SGD con Muon. Ispirato a Kimi K2 di Moonshot AI, MuSGD introduce metodi di ottimizzazione avanzati dall'addestramento LLM nella computer vision, consentendo un addestramento più stabile e una convergenza più rapida.Inferenza CPU fino al 43% più veloce
Specificamente ottimizzato per l'edge computing, YOLO26 offre un'inferenza CPU significativamente più veloce, garantendo prestazioni in tempo reale su dispositivi senza GPU.Miglioramenti nella Segmentazione di Istanza
Introduce la loss di segmentazione semantica per migliorare la convergenza del modello e un modulo proto aggiornato che sfrutta le informazioni multiscala per una qualità superiore delle maschere.Stima Precisa della Posa
Integra la Stima della Log-Verosimiglianza Residua (RLE) per una localizzazione più accurata dei keypoint e ottimizza il processo di decodifica per una maggiore velocità di inferenza.Decodifica OBB Raffinata
Introduce una loss angolare specializzata per migliorare la precisione di detect per oggetti di forma quadrata e ottimizza la decodifica OBB per risolvere i problemi di discontinuità dei bordi.
Attività e modalità supportate
YOLO26 si basa sulla versatile gamma di modelli stabilita dalle precedenti release di Ultralytics YOLO, offrendo un supporto migliorato per diverse attività di visione artificiale:
| Modello | Nomi dei file | Task | Inferenza | Validazione | Training | Esportazione |
|---|---|---|---|---|---|---|
| YOLO26 | yolo26n.pt yolo26s.pt yolo26m.pt yolo26l.pt yolo26x.pt | Rilevamento | ✅ | ✅ | ✅ | ✅ |
| YOLO26-seg | yolo26n-seg.pt yolo26s-seg.pt yolo26m-seg.pt yolo26l-seg.pt yolo26x-seg.pt | Segmentazione delle istanze | ✅ | ✅ | ✅ | ✅ |
| YOLO26-pose | yolo26n-pose.pt yolo26s-pose.pt yolo26m-pose.pt yolo26l-pose.pt yolo26x-pose.pt | Posa/Punti chiave | ✅ | ✅ | ✅ | ✅ |
| YOLO26-obb | yolo26n-obb.pt yolo26s-obb.pt yolo26m-obb.pt yolo26l-obb.pt yolo26x-obb.pt | Rilevamento orientato | ✅ | ✅ | ✅ | ✅ |
| YOLO26-cls | yolo26n-cls.pt yolo26s-cls.pt yolo26m-cls.pt yolo26l-cls.pt yolo26x-cls.pt | Classificazione | ✅ | ✅ | ✅ | ✅ |
Questo framework unificato garantisce che YOLO26 sia applicabile al rilevamento in tempo reale, alla segmentazione, alla classificazione, alla stima della posa e al rilevamento di oggetti orientati — il tutto con supporto per addestramento, convalida, inferenza ed esportazione.
Varianti solo architettura
yolo26-p2.yaml e yolo26-p6.yaml è possibile aggiungere una testina di rilevamento P2 (per oggetti di piccole dimensioni) o P6 (per oggetti di grandi dimensioni) e vengono fornite esclusivamente in configurazione YAML. Nessuna configurazione specifica per la bilancia yolo26*-p2.pt oppure yolo26*-p6.pt i pesi vengono rilasciati. Istanziare una configurazione ridimensionata da YAML (ad esempio, YOLO("yolo26n-p6.yaml")) e addestrarlo o perfezionarlo secondo necessità.
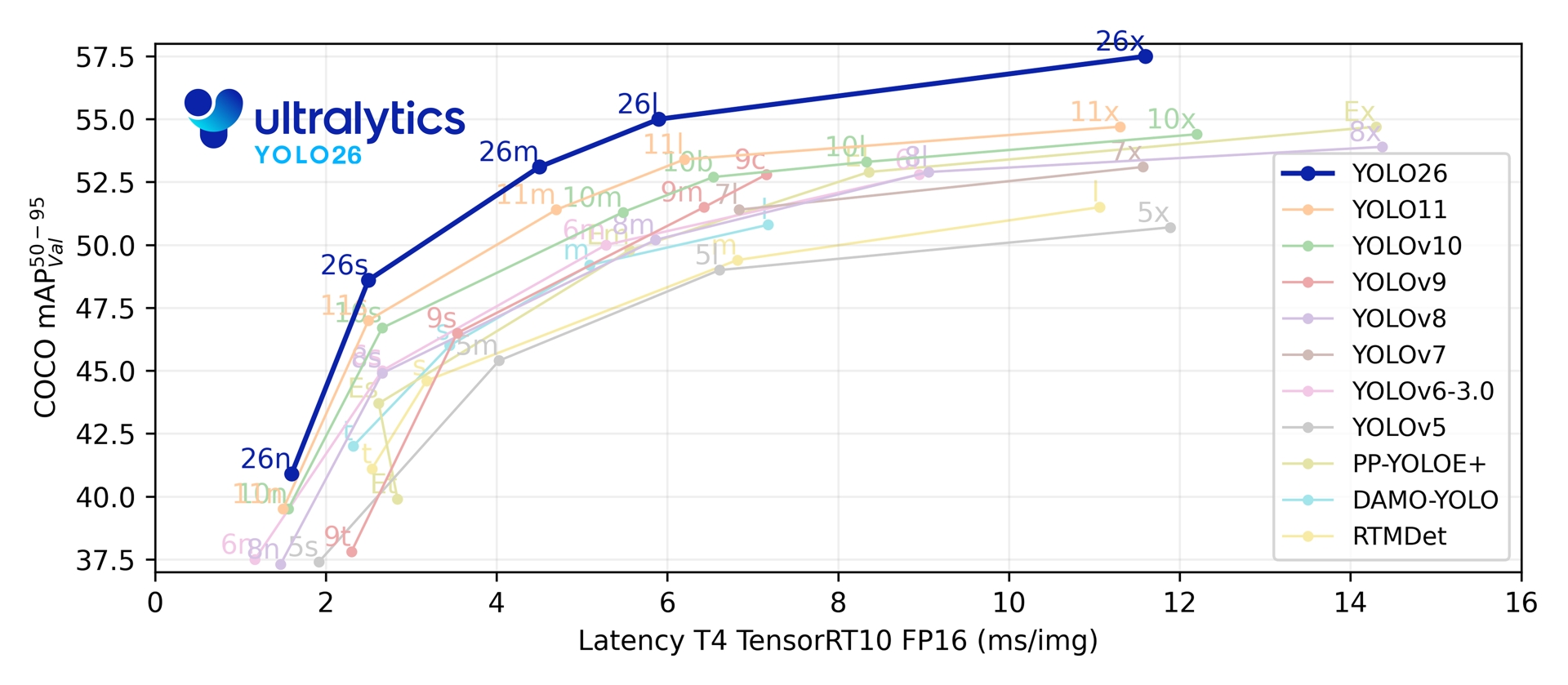
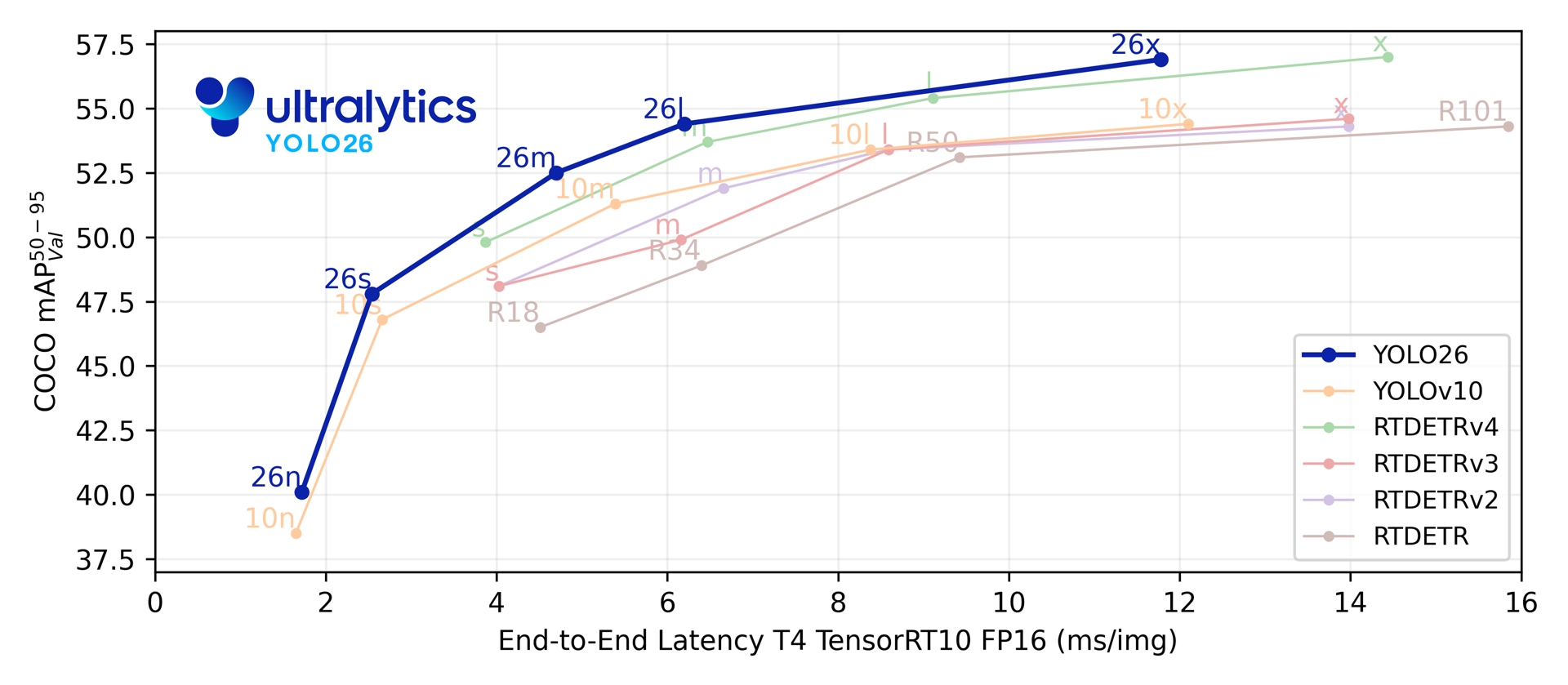
Metriche di performance
Prestazioni
Vedere la Documentazione sulla Detection per esempi di utilizzo con questi modelli addestrati su COCO, che includono 80 classi pre-addestrate.
| Modello | dimensione (pixel) | mAPval 50-95 | mAPval 50-95(e2e) | Velocità CPU ONNX (ms) | Velocità T4 TensorRT10 (ms) | parametri (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO26n | 640 | 40.9 | 40.1 | 38.9 ± 0.7 | 1.7 ± 0.0 | 2.4 | 5.4 |
| YOLO26s | 640 | 48.6 | 47.8 | 87.2 ± 0.9 | 2.5 ± 0.0 | 9.5 | 20.7 |
| YOLO26m | 640 | 53.1 | 52.5 | 220.0 ± 1.4 | 4.7 ± 0.1 | 20.4 | 68.2 |
| YOLO26l | 640 | 55.0 | 54.4 | 286.2 ± 2.0 | 6.2 ± 0.2 | 24.8 | 86.4 |
| YOLO26x | 640 | 57.5 | 56.9 | 525.8 ± 4.0 | 11.8 ± 0.2 | 55.7 | 193.9 |
Vedere la Documentazione sulla Segmentazione per esempi di utilizzo con questi modelli addestrati su COCO, che includono 80 classi pre-addestrate.
| Modello | dimensione (pixel) | mAPbox 50-95(e2e) | mAPmask 50-95(e2e) | Velocità CPU ONNX (ms) | Velocità T4 TensorRT10 (ms) | parametri (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO26n-seg | 640 | 39.6 | 33.9 | 53.3 ± 0.5 | 2.1 ± 0.0 | 2.7 | 9.1 |
| YOLO26s-seg | 640 | 47.3 | 40.0 | 118.4 ± 0.9 | 3.3 ± 0.0 | 10.4 | 34.2 |
| YOLO26m-seg | 640 | 52.5 | 44.1 | 328.2 ± 2.4 | 6.7 ± 0.1 | 23.6 | 121.5 |
| YOLO26l-seg | 640 | 54.4 | 45.5 | 387.0 ± 3.7 | 8.0 ± 0.1 | 28.0 | 139.8 |
| YOLO26x-seg | 640 | 56.5 | 47.0 | 787.0 ± 6.8 | 16.4 ± 0.1 | 62.8 | 313.5 |
Vedere la Documentazione sulla Classificazione per esempi di utilizzo con questi modelli addestrati su ImageNet, che includono 1000 classi pre-addestrate.
| Modello | dimensione (pixel) | acc top1 | acc top5 | Velocità CPU ONNX (ms) | Velocità T4 TensorRT10 (ms) | parametri (M) | FLOPs (B) a 224 |
|---|---|---|---|---|---|---|---|
| YOLO26n-cls | 224 | 71.4 | 90.1 | 5.0 ± 0.3 | 1.1 ± 0.0 | 2.8 | 0.5 |
| YOLO26s-cls | 224 | 76.0 | 92.9 | 7.9 ± 0.2 | 1.3 ± 0.0 | 6.7 | 1.6 |
| YOLO26m-cls | 224 | 78.1 | 94.2 | 17.2 ± 0.4 | 2.0 ± 0.0 | 11.6 | 4.9 |
| YOLO26l-cls | 224 | 79.0 | 94.6 | 23.2 ± 0.3 | 2.8 ± 0.0 | 14.1 | 6.2 |
| YOLO26x-cls | 224 | 79.9 | 95.0 | 41.4 ± 0.9 | 3.8 ± 0.0 | 29.6 | 13.6 |
Vedere la Documentazione sulla Stima della Posa per esempi di utilizzo con questi modelli addestrati su COCO, che includono 1 classe pre-addestrata, 'persona'.
| Modello | dimensione (pixel) | mAPpose 50-95(e2e) | mAPpose 50(e2e) | Velocità CPU ONNX (ms) | Velocità T4 TensorRT10 (ms) | parametri (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO26n-pose | 640 | 57.2 | 83.3 | 40.3 ± 0.5 | 1.8 ± 0.0 | 2.9 | 7.5 |
| YOLO26s-pose | 640 | 63.0 | 86.6 | 85.3 ± 0.9 | 2.7 ± 0.0 | 10.4 | 23.9 |
| YOLO26m-pose | 640 | 68.8 | 89.6 | 218.0 ± 1.5 | 5.0 ± 0.1 | 21.5 | 73.1 |
| YOLO26l-pose | 640 | 70.4 | 90.5 | 275.4 ± 2.4 | 6.5 ± 0.1 | 25.9 | 91.3 |
| YOLO26x-pose | 640 | 71.6 | 91.6 | 565.4 ± 3.0 | 12.2 ± 0.2 | 57.6 | 201.7 |
Vedere la Documentazione sulla Detection Orientata per esempi di utilizzo con questi modelli addestrati su DOTAv1, che includono 15 classi pre-addestrate.
| Modello | dimensione (pixel) | mAPtest 50-95(e2e) | mAPtest 50(e2e) | Velocità CPU ONNX (ms) | Velocità T4 TensorRT10 (ms) | parametri (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO26n-obb | 1024 | 52.4 | 78.9 | 97.7 ± 0.9 | 2.8 ± 0.0 | 2.5 | 14.0 |
| YOLO26s-obb | 1024 | 54.8 | 80.9 | 218.0 ± 1.4 | 4.9 ± 0.1 | 9.8 | 55.1 |
| YOLO26m-obb | 1024 | 55.3 | 81.0 | 579.2 ± 3.8 | 10.2 ± 0.3 | 21.2 | 183.3 |
| YOLO26l-obb | 1024 | 56.2 | 81.6 | 735.6 ± 3.1 | 13.0 ± 0.2 | 25.6 | 230.0 |
| YOLO26x-obb | 1024 | 56.7 | 81.7 | 1485.7 ± 11.5 | 30.5 ± 0.9 | 57.6 | 516.5 |
I valori dei parametri e dei FLOPs sono per il modello fuso dopo model.fuse(), che unisce i layer Conv e BatchNorm e rimuove l'head di rilevamento ausiliario one-to-many. I checkpoint pre-addestrati mantengono l'architettura di training completa e potrebbero mostrare conteggi più elevati.
Esempi di utilizzo
Questa sezione fornisce semplici esempi di training e inferenza YOLO26. Per la documentazione completa su queste e altre modalità, consultare le pagine della documentazione Predict, Train, Val ed Export.
Si noti che l'esempio seguente è per i modelli YOLO26 Detect per il rilevamento di oggetti. Per ulteriori attività supportate, consultare la documentazione Segment, Classify, OBB e Pose.
Esempio
PyTorch pre-addestrato *.pt modelli, così come la configurazione *.yaml file possono essere passati alla YOLO() classe per creare un'istanza del modello in Python:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLO26n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")
Sono disponibili comandi CLI per eseguire direttamente i modelli:
# Load a COCO-pretrained YOLO26n model and train it on the COCO8 example dataset for 100 epochs
yolo train model=yolo26n.pt data=coco8.yaml epochs=100 imgsz=640
# Load a COCO-pretrained YOLO26n model and run inference on the 'bus.jpg' image
yolo predict model=yolo26n.pt source=path/to/bus.jpg
Architettura a doppia testa
YOLO26 presenta un'architettura a doppia testa che offre flessibilità per diversi scenari di implementazione:
- Testa uno a uno (impostazione predefinita): Produce predizioni end-to-end senza NMS, generando
(N, 300, 6)con un massimo di 300 rilevamenti per immagine. Questa testa è ottimizzata per un'inferenza veloce e un'implementazione semplificata. - Testa uno-a-molti: Genera output YOLO tradizionali che richiedono post-elaborazione NMS, producendo
(N, nc + 4, 8400)dovencè il numero di classi. Questo approccio raggiunge in genere una precisione leggermente superiore a scapito di un'elaborazione aggiuntiva.
È possibile passare da una testa all'altra durante l'esportazione, la previsione o la convalida:
from ultralytics import YOLO
model = YOLO("yolo26n.pt")
# Use one-to-one head (default, no NMS required)
results = model.predict("image.jpg") # inference
metrics = model.val(data="coco.yaml") # validation
model.export(format="onnx") # export
# Use one-to-many head (requires NMS)
results = model.predict("image.jpg", end2end=False) # inference
metrics = model.val(data="coco.yaml", end2end=False) # validation
model.export(format="onnx", end2end=False) # export
# Use one-to-one head (default, no NMS required)
yolo predict model=yolo26n.pt source=image.jpg
yolo val model=yolo26n.pt data=coco.yaml
yolo export model=yolo26n.pt format=onnx
# Use one-to-many head (requires NMS)
yolo predict model=yolo26n.pt source=image.jpg end2end=False
yolo val model=yolo26n.pt data=coco.yaml end2end=False
yolo export model=yolo26n.pt format=onnx end2end=False
La scelta dipende dai requisiti di implementazione: utilizzare la testa uno-a-uno per ottenere la massima velocità e semplicità, oppure la testa uno-a-molti quando la precisione è la priorità assoluta.
YOLOE-26: Segmentazione di Istanza a Vocabolario Aperto
YOLOE-26 integra l'architettura ad alte prestazioni YOLO26 con le capacità di vocabolario aperto della serie YOLOE. Consente il rilevamento e la segmentazione in tempo reale di qualsiasi classe di oggetti utilizzando prompt testuali, prompt visivi o una modalità senza prompt per l'inferenza zero-shot, rimuovendo efficacemente i vincoli del training a categoria fissa.
Sfruttando il design NMS-free e end-to-end di YOLO26, YOLOE-26 offre un'inferenza open-world rapida. Ciò lo rende una soluzione potente per applicazioni edge in ambienti dinamici, dove gli oggetti di interesse rappresentano un vocabolario ampio e in evoluzione.
Prestazioni
Vedere la documentazione YOLOE per esempi di utilizzo con questi modelli addestrati sui dataset Objects365v1, GQA e Flickr30k.
| Modello | dimensione (pixel) | Tipo di Prompt | mAPminival 50-95(e2e) | mAPminival 50-95 | mAPr | mAPc | mAPf | parametri (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOE-26n-seg | 640 | Testuale/Visivo | 23.7 / 20.9 | 24.7 / 21.9 | 20.5 / 17.6 | 24.1 / 22.3 | 26.1 / 22.4 | 4.8 | 6.0 |
| YOLOE-26s-seg | 640 | Testuale/Visivo | 29.9 / 27.1 | 30.8 / 28.6 | 23.9 / 25.1 | 29.6 / 27.8 | 33.0 / 29.9 | 13.1 | 21.7 |
| YOLOE-26m-seg | 640 | Testuale/Visivo | 35.4 / 31.3 | 35.4 / 33.9 | 31.1 / 33.4 | 34.7 / 34.0 | 36.9 / 33.8 | 27.9 | 70.1 |
| YOLOE-26l-seg | 640 | Testuale/Visivo | 36.8 / 33.7 | 37.8 / 36.3 | 35.1 / 37.6 | 37.6 / 36.2 | 38.5 / 36.1 | 32.3 | 88.3 |
| YOLOE-26x-seg | 640 | Testuale/Visivo | 39.5 / 36.2 | 40.6 / 38.5 | 37.4 / 35.3 | 40.9 / 38.8 | 41.0 / 38.8 | 69.9 | 196.7 |
Vedere la documentazione YOLOE per esempi di utilizzo con questi modelli addestrati sui dataset Objects365v1, GQA e Flickr30k.
| Modello | dimensione (pixel) | mAPminival 50-95(e2e) | mAPminival 50(e2e) | parametri (M) | FLOPs (B) |
|---|---|---|---|---|---|
| YOLOE-26n-seg-pf | 640 | 16.6 | 22.7 | 6.5 | 15.8 |
| YOLOE-26s-seg-pf | 640 | 21.4 | 28.6 | 16.2 | 35.5 |
| YOLOE-26m-seg-pf | 640 | 25.7 | 33.6 | 36.2 | 122.1 |
| YOLOE-26l-seg-pf | 640 | 27.2 | 35.4 | 40.6 | 140.4 |
| YOLOE-26x-seg-pf | 640 | 29.9 | 38.7 | 86.3 | 314.4 |
Esempio di utilizzo
YOLOE-26 supporta il prompting sia testuale che visivo. L'utilizzo dei prompt è semplice: basta passarli attraverso il predict method come mostrato di seguito:
Esempio
I prompt testuali consentono di specificare le classi che si desidera detectare tramite descrizioni testuali. Il seguente codice mostra come utilizzare YOLOE-26 per detectare persone e autobus in un'immagine:
from ultralytics import YOLO
# Initialize model
model = YOLO("yoloe-26l-seg.pt") # or select yoloe-26s/m-seg.pt for different sizes
# Set text prompt to detect person and bus. You only need to do this once after you load the model.
model.set_classes(["person", "bus"])
# Run detection on the given image
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()
I prompt visivi ti consentono di guidare il modello mostrandogli esempi visivi delle classi target, anziché descriverle nel testo.
import numpy as np
from ultralytics import YOLO
from ultralytics.models.yolo.yoloe import YOLOEVPSegPredictor
# Initialize model
model = YOLO("yoloe-26l-seg.pt")
# Define visual prompts using bounding boxes and their corresponding class IDs.
# Each box highlights an example of the object you want the model to detect.
visual_prompts = dict(
bboxes=np.array(
[
[221.52, 405.8, 344.98, 857.54], # Box enclosing person
[120, 425, 160, 445], # Box enclosing glasses
],
),
cls=np.array(
[
0, # ID to be assigned for person
1, # ID to be assigned for glasses
]
),
)
# Run inference on an image, using the provided visual prompts as guidance
results = model.predict(
"ultralytics/assets/bus.jpg",
visual_prompts=visual_prompts,
predictor=YOLOEVPSegPredictor,
)
# Show results
results[0].show()
YOLOE-26 include varianti senza prompt che dispongono di un vocabolario integrato. Questi modelli non richiedono alcun prompt e funzionano come i modelli YOLO tradizionali. Invece di affidarsi a etichette fornite dall'utente o esempi visivi, detectano oggetti da un elenco predefinito di 4.585 classi basato sul set di tag utilizzato dal Recognize Anything Model Plus (RAM++).
from ultralytics import YOLO
# Initialize model
model = YOLO("yoloe-26l-seg-pf.pt")
# Run prediction. No prompts required.
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()
Per un'analisi approfondita delle tecniche di prompting, dell'addestramento da zero e degli esempi di utilizzo completi, visita la documentazione di YOLOE.
Citazioni e ringraziamenti
Pubblicazione Ultralytics YOLO26
Ultralytics non ha pubblicato un articolo di ricerca formale per YOLO26 a causa della rapida evoluzione dei modelli. Ci concentriamo invece sulla fornitura di modelli all'avanguardia e sulla loro facilità d'uso. Per gli ultimi aggiornamenti sulle funzionalità, le architetture e l'utilizzo di YOLO, visita il nostro repository GitHub e la documentazione.
Se utilizzi YOLO26 o altro software Ultralytics nel tuo lavoro, cita il progetto come:
@software{yolo26_ultralytics,
author = {Glenn Jocher and Jing Qiu},
title = {Ultralytics YOLO26},
version = {26.0.0},
year = {2026},
url = {https://github.com/ultralytics/ultralytics},
orcid = {0000-0001-5950-6979, 0000-0003-3783-7069},
license = {AGPL-3.0}
}
DOI in sospeso. YOLO26 è disponibile con licenze AGPL-3.0 ed Enterprise.
FAQ
Quali sono i principali miglioramenti di YOLO26 rispetto a YOLO11?
- Rimozione DFL: Semplifica l'esportazione ed espande la compatibilità edge
- Inferenza End-to-End NMS-Free: Elimina NMS per una distribuzione più rapida e semplice
- ProgLoss + STAL: Aumenta la precisione, specialmente su piccoli oggetti
- Ottimizzatore MuSGD: Combina SGD e Muon (ispirato al Kimi K2 di Moonshot) per un addestramento più stabile ed efficiente.
- Inferenza su CPU fino al 43% più veloce: Importanti miglioramenti delle prestazioni per i dispositivi solo CPU
Quali attività supporta YOLO26?
YOLO26 è una famiglia di modelli unificata, che fornisce supporto end-to-end per molteplici attività di visione artificiale:
- Rilevamento di oggetti
- Segmentazione delle istanze
- Classificazione delle immagini
- Stima della posa
- Rilevamento di oggetti orientati (OBB)
Ogni variante di dimensione (n, s, m, l, x) supporta tutte le attività, oltre alle versioni a vocabolario aperto tramite YOLOE-26.
Perché YOLO26 è ottimizzato per la distribuzione edge?
YOLO26 offre prestazioni edge all'avanguardia con:
- Inferenza su CPU fino al 43% più veloce
- Dimensione del modello e ingombro di memoria ridotti
- Architettura semplificata per la compatibilità (senza DFL, senza NMS)
- Formati di esportazione flessibili tra cui TensorRT, ONNX, CoreML, TFLite e OpenVINO
Come iniziare con YOLO26?
I modelli YOLO26 sono stati rilasciati il 14 gennaio 2026 e sono disponibili per il download. Installa o aggiorna il ultralytics pacchetto e carica un modello:
from ultralytics import YOLO
# Load a pretrained YOLO26 nano model
model = YOLO("yolo26n.pt")
# Run inference on an image
results = model("image.jpg")
Consulta la sezione Esempi di utilizzo per le istruzioni di addestramento, validazione ed esportazione.






