Link to this sectionUltralytics YOLO26#
Link to this sectionPanoramica#
Ultralytics YOLO26 è una famiglia unificata di modelli di visione in tempo reale descritta nel documento di ricerca Ultralytics YOLO26. Introduce l'inferenza nativa end-to-end, una head di rilevamento più leggera, una ricetta di addestramento aggiornata e head specifiche per compito per rilevamento, segmentazione, stima della posa, classificazione e rilevamento orientato.
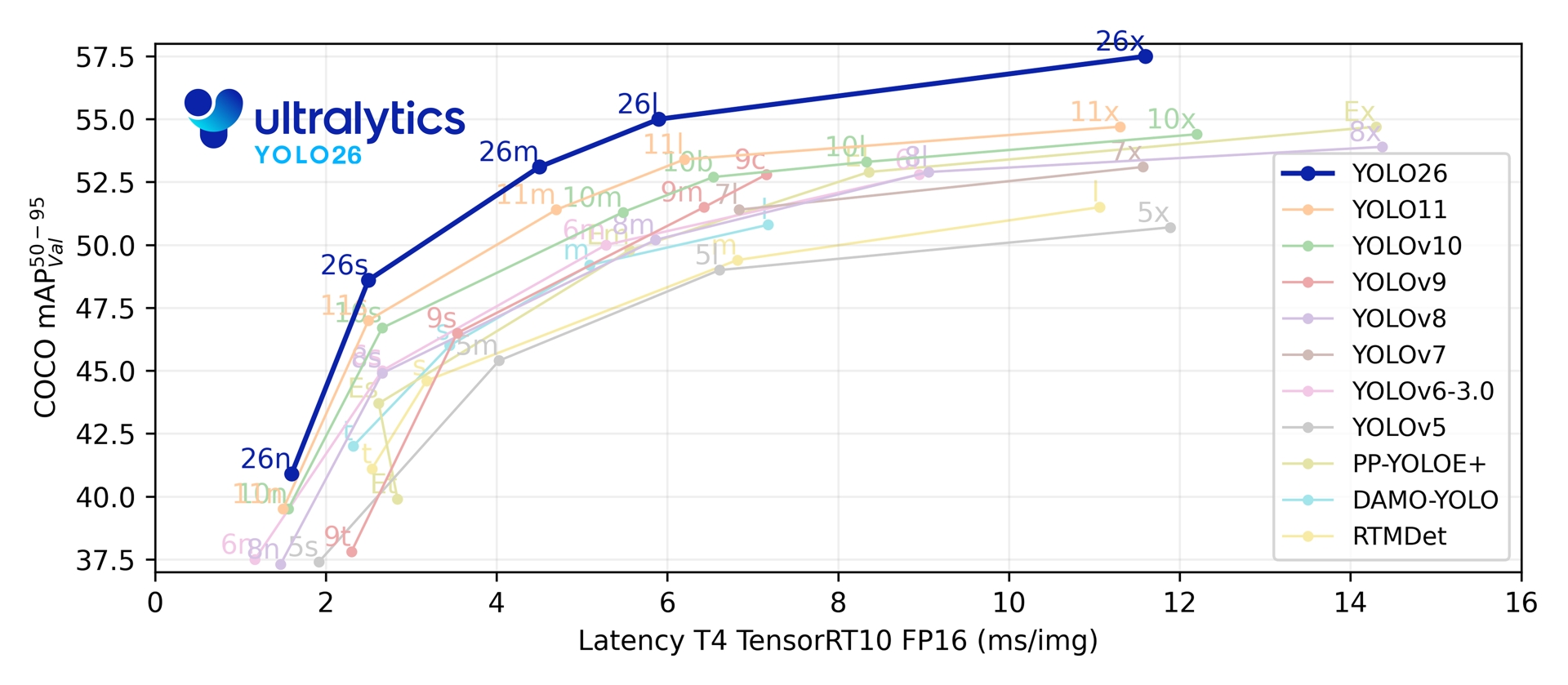
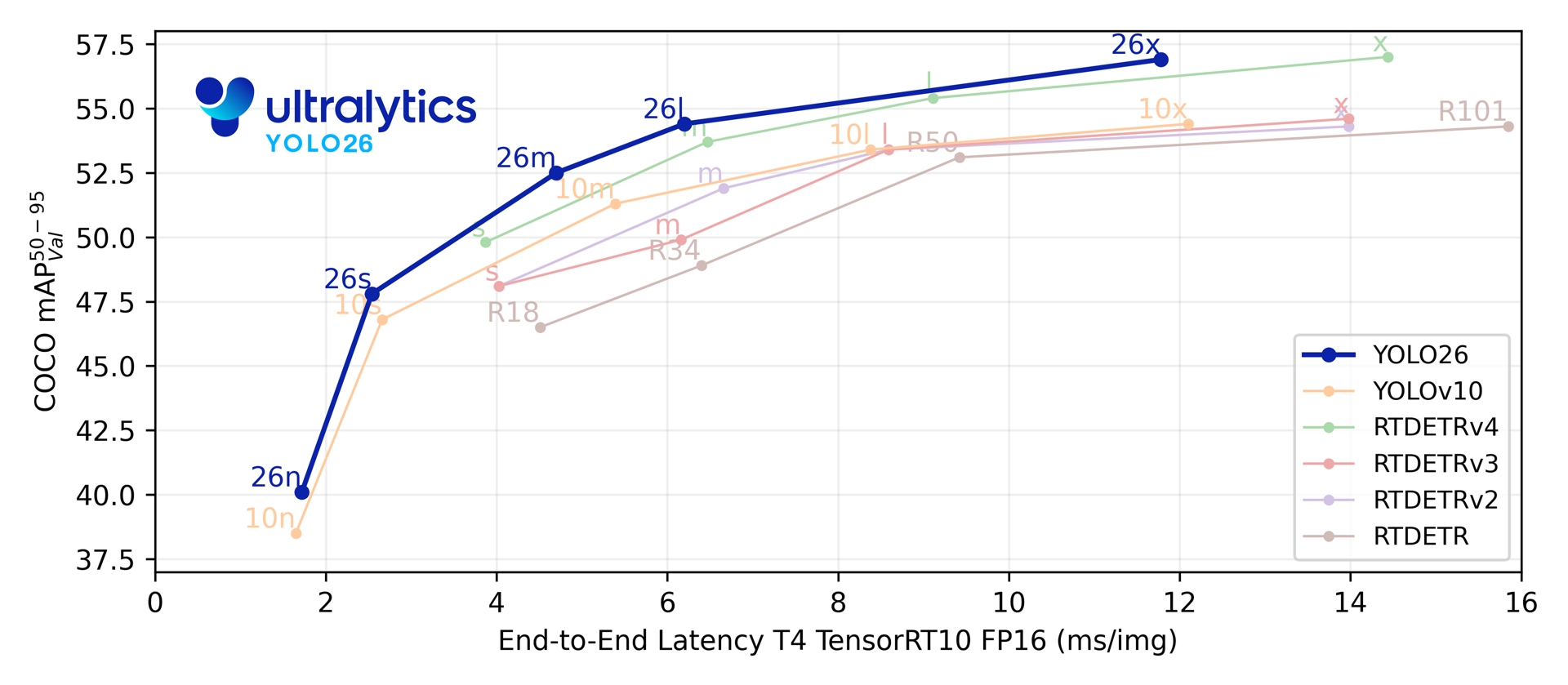
Attraverso le sue cinque scale di rilevamento, YOLO26 raggiunge un mAP 40.9-57.5 su COCO con una latenza TensorRT su T4 di 1.7-11.8 ms. Il documento riporta anche un'inferenza CPU ONNX fino al 43% più veloce per YOLO26n rispetto a YOLO11n su una CPU Intel Xeon @ 2.00 GHz.
Esplora ed esegui i modelli YOLO26 direttamente sulla piattaforma Ultralytics.
La famiglia di modelli YOLO26 è costruita attorno a quattro aree di progettazione:
- Inferenza nativa end-to-end: La head di rilevamento predefinita uno-a-uno produce predizioni senza non-maximum suppression (NMS), semplificando il deployment e riducendo il post-processing.
- Regressione del box più leggera: YOLO26 rimuove la Distribution Focal Loss (DFL), riducendo la complessità della head di rilevamento pur preservando un intervallo di regressione non vincolato.
- Aggiornamenti alla ricetta di addestramento: La pipeline di addestramento combina MuSGD, Progressive Loss e STAL per migliorare l'ottimizzazione, spostare la supervisione verso la testa in fase di inferenza e mantenere una copertura positiva delle etichette per gli oggetti di piccole dimensioni. Gli iperparametri completi alla base dei checkpoint rilasciati sono documentati nella guida alla ricetta di addestramento di YOLO26.
- Head e loss specifiche per compito: YOLO26 aggiunge design mirati per segmentazione di istanze, varianti di segmentazione semantica, stima della posa e rilevamento orientato, mantenendo una singola pipeline di modello attraverso i compiti.
Insieme, questi aggiornamenti migliorano il compromesso tra precisione e latenza su tutte le scale del modello e gli obiettivi di deployment.
Link to this sectionCaratteristiche principali#
-
Regressione DFL-Free YOLO26 rimuove la Distribution Focal Loss (DFL), riducendo la complessità della head di rilevamento e semplificando l'esportazione.
-
Inferenza End-to-End NMS-Free A differenza dei rilevatori tradizionali che si affidano alla NMS come fase di post-processing separata, YOLO26 è nativamente end-to-end per impostazione predefinita. Le predizioni vengono generate direttamente, riducendo la latenza e rendendo più semplice l'integrazione in produzione.
-
Progressive Loss + STAL La Progressive Loss sposta l'enfasi dell'addestramento verso la head in fase di inferenza, mentre STAL migliora la copertura delle etichette positive per gli oggetti piccoli.
-
Ottimizzatore MuSGD Un ottimizzatore ibrido che combina SGD con Muon, adattando idee di ottimizzazione dall'addestramento di modelli linguistici di grandi dimensioni alla visione artificiale.
-
Deployment efficiente La head semplificata e il percorso predefinito senza NMS riducono l'overhead di inferenza tra gli obiettivi di esportazione e i profili hardware, inclusa la velocizzazione della CPU ONNX riportata nel documento per YOLO26n rispetto a YOLO11n.
-
Miglioramenti alla segmentazione di istanze Introduce la loss di segmentazione semantica per migliorare la convergenza del modello e un modulo proto aggiornato che sfrutta informazioni multi-scala per una qualità superiore delle maschere. Il documento riporta guadagni rispetto a YOLO11 fino a +2.5 box AP e +3.7 mask AP sulla segmentazione di istanze COCO.
-
Stima della posa di precisione Integra la Residual Log-Likelihood Estimation (RLE) per una localizzazione più accurata dei keypoint e ottimizza il processo di decodifica per una maggiore velocità di inferenza. Il documento riporta fino a +7.2 AP rispetto a YOLO11 sulla stima della posa COCO.
-
Decodifica OBB raffinata Introduce una loss angolare specializzata per migliorare l'accuratezza del rilevamento per oggetti di forma quadrata e ottimizza la decodifica OBB per risolvere i problemi di discontinuità dei bordi. Il documento riporta fino a +3.4 mAP rispetto a YOLO11 sul rilevamento orientato DOTA-v1.0.
Link to this sectionCompiti e modalità supportati#
YOLO26 supporta il set di compiti standard di Ultralytics su cinque scale di modello:
| Modello | Nomi file | Compito | Inferenza | Validazione | Addestramento | Esportazione |
|---|---|---|---|---|---|---|
| YOLO26 | yolo26n.pt yolo26s.pt yolo26m.pt yolo26l.pt yolo26x.pt | Rilevamento | ✅ | ✅ | ✅ | ✅ |
| YOLO26-seg | yolo26n-seg.pt yolo26s-seg.pt yolo26m-seg.pt yolo26l-seg.pt yolo26x-seg.pt | Segmentazione di istanze | ✅ | ✅ | ✅ | ✅ |
| YOLO26-sem | yolo26n-sem.pt yolo26s-sem.pt yolo26m-sem.pt yolo26l-sem.pt yolo26x-sem.pt | Segmentazione semantica | ✅ | ✅ | ✅ | ✅ |
| YOLO26-pose | yolo26n-pose.pt yolo26s-pose.pt yolo26m-pose.pt yolo26l-pose.pt yolo26x-pose.pt | Posa/Keypoints | ✅ | ✅ | ✅ | ✅ |
| YOLO26-obb | yolo26n-obb.pt yolo26s-obb.pt yolo26m-obb.pt yolo26l-obb.pt yolo26x-obb.pt | Rilevamento orientato | ✅ | ✅ | ✅ | ✅ |
| YOLO26-cls | yolo26n-cls.pt yolo26s-cls.pt yolo26m-cls.pt yolo26l-cls.pt yolo26x-cls.pt | Classificazione | ✅ | ✅ | ✅ | ✅ |
Questo framework unificato copre rilevamento in tempo reale, segmentazione di istanze, segmentazione semantica, classificazione, stima della posa e rilevamento orientato di oggetti con supporto per addestramento, validazione, inferenza ed esportazione.
yolo26-p2.yaml e yolo26-p6.yaml aggiungono una head di rilevamento P2 (oggetti piccoli) o P6 (input grande) e vengono fornite solo come architetture YAML. Non vengono rilasciati pesi yolo26*-p2.pt o yolo26*-p6.pt specifici per scala. Istanzia una configurazione scalata da YAML (per esempio, YOLO("yolo26n-p6.yaml")) e addestrala o esegui il fine-tuning come necessario.
Link to this sectionMetriche di performance#
Vedi Documentazione Rilevamento per esempi di utilizzo con questi modelli addestrati su COCO, che includono 80 classi pre-addestrate.
| Modello | dimensione (pixel) | mAPval 50-95 | mAPval 50-95(e2e) | Velocità CPU ONNX (ms) | Velocità T4 TensorRT10 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO26n | 640 | 40.9 | 40.1 | 38.9 ± 0.7 | 1.7 ± 0.0 | 2.4 | 5.4 |
| YOLO26s | 640 | 48.6 | 47.8 | 87.2 ± 0.9 | 2.5 ± 0.0 | 9.5 | 20.7 |
| YOLO26m | 640 | 53.1 | 52.5 | 220.0 ± 1.4 | 4.7 ± 0.1 | 20.4 | 68.2 |
| YOLO26l | 640 | 55.0 | 54.4 | 286.2 ± 2.0 | 6.2 ± 0.2 | 24.8 | 86.4 |
| YOLO26x | 640 | 57.5 | 56.9 | 525.8 ± 4.0 | 11.8 ± 0.2 | 55.7 | 193.9 |
I valori di Params e FLOPs si riferiscono al modello fuso dopo model.fuse(), che unisce i layer Conv e BatchNorm e rimuove l'head di rilevamento ausiliaria one-to-many. I checkpoint preaddestrati mantengono l'intera architettura di addestramento e potrebbero mostrare conteggi più elevati.
Link to this sectionEsempi di Utilizzo#
Questa sezione fornisce esempi semplici di addestramento e inferenza con YOLO26. Per la documentazione completa su queste e altre modalità, consulta le pagine di documentazione Predict, Train, Val e Export.
Nota che l'esempio qui sotto riguarda i modelli YOLO26 Detect per l'object detection. Per ulteriori attività supportate, consulta la documentazione su Segment, Semantic Segmentation, Classify, OBB e Pose.
I modelli preaddestrati PyTorch *.pt e i file di configurazione *.yaml possono essere passati alla classe YOLO() per creare un'istanza del modello in Python:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLO26n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")I modelli di rilevamento YOLO26 utilizzano un'architettura dual-head che offre flessibilità per diversi scenari di distribuzione:
- One-to-One Head (Predefinita): Produce previsioni end-to-end senza NMS, generando
(N, 300, 6)con un massimo di 300 rilevamenti per immagine. Questa head è ottimizzata per un'inferenza veloce e una distribuzione semplificata. - One-to-Many Head: Genera output YOLO tradizionali che richiedono il post-processing NMS, generando
(N, nc + 4, 8400)dovencè il numero di classi. Questa head solitamente raggiunge una precisione leggermente superiore al costo di un'elaborazione aggiuntiva.
Puoi passare da una head all'altra durante l'esportazione, la previsione o la validazione:
from ultralytics import YOLO
model = YOLO("yolo26n.pt")
# Use one-to-one head (default, no NMS required)
results = model.predict("image.jpg") # inference
metrics = model.val(data="coco.yaml") # validation
model.export(format="onnx") # export
# Use one-to-many head (requires NMS)
results = model.predict("image.jpg", end2end=False) # inference
metrics = model.val(data="coco.yaml", end2end=False) # validation
model.export(format="onnx", end2end=False) # exportLa scelta dipende dai tuoi requisiti di distribuzione: usa la head one-to-one per la massima velocità e semplicità, o la head one-to-many quando la precisione è la priorità principale.
Link to this sectionYOLOE-26: Rilevamento e Segmentazione Open-Vocabulary#
YOLOE-26 estende YOLO26 con le funzionalità open-vocabulary della serie YOLOE. Abilita il rilevamento e la segmentazione in tempo reale di categorie di oggetti open-set utilizzando prompt testuali, prompt visivi o una modalità senza prompt (prompt-free).
Sfruttando il design NMS-free, end-to-end di YOLO26, YOLOE-26 mantiene l'inferenza open-vocabulary abbastanza veloce per ambienti dinamici dove le categorie target possono cambiare nel tempo. YOLOE-26x raggiunge 40.6 AP su LVIS minival con prompt testuali, 38.5 AP con prompt visivi e 31.1 AP nell'impostazione non-E2E senza prompt.
Consulta la documentazione YOLOE per esempi di utilizzo con questi modelli addestrati sui dataset Objects365v1, GQA e Flickr30k.
| Modello | dimensione (pixel) | Tipo di prompt | mAPminival 50-95(e2e) | mAPminival 50-95 | mAPr | mAPc | mAPf | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOE-26n-seg | 640 | Testo/Visivo | 23.7 / 20.9 | 24.7 / 21.9 | 20.5 / 17.6 | 24.1 / 22.3 | 26.1 / 22.4 | 4.8 | 6.0 |
| YOLOE-26s-seg | 640 | Testo/Visivo | 29.9 / 27.1 | 30.8 / 28.6 | 23.9 / 25.1 | 29.6 / 27.8 | 33.0 / 29.9 | 13.1 | 21.7 |
| YOLOE-26m-seg | 640 | Testo/Visivo | 35.4 / 31.3 | 35.4 / 33.9 | 31.1 / 33.4 | 34.7 / 34.0 | 36.9 / 33.8 | 27.9 | 70.1 |
| YOLOE-26l-seg | 640 | Testo/Visivo | 36.8 / 33.7 | 37.8 / 36.3 | 35.1 / 37.6 | 37.6 / 36.2 | 38.5 / 36.1 | 32.3 | 88.3 |
| YOLOE-26x-seg | 640 | Testo/Visivo | 39.5 / 36.2 | 40.6 / 38.5 | 37.4 / 35.3 | 40.9 / 38.8 | 41.0 / 38.8 | 69.9 | 196.7 |
Link to this sectionEsempio di utilizzo#
YOLOE-26 supporta sia prompt basati su testo che visivi. Usare i prompt è semplice: basta passarli attraverso il metodo predict come mostrato di seguito:
I prompt testuali ti consentono di specificare le classi che desideri rilevare attraverso descrizioni testuali. Il codice seguente mostra come puoi usare YOLOE-26 per rilevare persone e autobus in un'immagine:
from ultralytics import YOLO
# Initialize model
model = YOLO("yoloe-26l-seg.pt") # or select yoloe-26s/m-seg.pt for different sizes
# Set text prompt to detect person and bus. You only need to do this once after you load the model.
model.set_classes(["person", "bus"])
# Run detection on the given image
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()Per tecniche di prompting ed esempi di utilizzo completi, visita la Documentazione YOLOE.
Link to this sectionCitazioni e riconoscimenti#
Per una descrizione tecnica completa dell'architettura YOLO26, la ricetta di addestramento, le task head e l'estensione a vocabolario aperto YOLOE-26, leggi Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models. Se utilizzi YOLO26 nella tua ricerca, cita:
@misc{jocher2026ultralyticsyolo26unifiedrealtime,
title = {Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models},
author = {Glenn Jocher and Jing Qiu and Mengyu Liu and Shuai Lyu and Fatih Cagatay Akyon and Muhammet Esat Kalfaoglu},
year = {2026},
eprint = {2606.03748},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
doi = {10.48550/arXiv.2606.03748},
url = {https://arxiv.org/abs/2606.03748},
}Il codice, i modelli e la documentazione di YOLO26 sono disponibili nel repository GitHub di Ultralytics e nella documentazione di Ultralytics sotto licenze AGPL-3.0 ed Enterprise.
Link to this sectionFAQ#
Link to this sectionQuali sono i miglioramenti chiave in YOLO26?#
- Regressione senza DFL: Semplifica la head di rilevamento e il percorso di esportazione
- Inferenza end-to-end senza NMS: Rimuove la NMS dal percorso di inferenza predefinito
- Progressive Loss + STAL: Migliora l'allineamento dell'addestramento e la copertura delle etichette per oggetti piccoli
- Ottimizzatore MuSGD: Combina SGD con un'ottimizzazione ispirata a Muon per un addestramento stabile
- Head e loss specifiche per il task: Migliora il supporto per segmentazione, pose e rilevamento orientato
Link to this sectionQuali task supporta YOLO26?#
YOLO26 è una famiglia di modelli unificata, che fornisce supporto end-to-end per molteplici task di computer vision:
- Object Detection
- Segmentazione di istanze
- Segmentazione semantica
- Image Classification
- Pose Estimation
- Oriented Object Detection (OBB)
Ogni variante di dimensione (n, s, m, l, x) supporta tutte le attività, oltre alle versioni open-vocabulary tramite YOLOE-26.
Link to this sectionPerché YOLO26 è efficiente per il deployment?#
YOLO26 migliora l'efficienza del deployment con:
- Inferenza end-to-end nativa senza NMS per impostazione predefinita
- Regressione senza DFL e una detection head più leggera
- Esportazione del modello fuso che rimuove i componenti ausiliari usati solo per l'addestramento
- Inferenza ONNX su CPU fino al 43% più veloce per YOLO26n rispetto a YOLO11n su una CPU Intel Xeon a 2,00 GHz
- Formati di esportazione flessibili inclusi TensorRT, ONNX, CoreML, LiteRT e OpenVINO
Link to this sectionCome inizio a usare YOLO26?#
I modelli YOLO26 sono disponibili per il download tramite il pacchetto ultralytics. Installa o aggiorna il pacchetto e carica un modello:
from ultralytics import YOLO
# Load a pretrained YOLO26 nano model
model = YOLO("yolo26n.pt")
# Run inference on an image
results = model("image.jpg")Consulta la sezione Usage Examples per le istruzioni su training, validation ed export.