Link to this sectionUltralytics YOLO26#
Link to this section概要#
Ultralytics YOLO26は、Ultralytics YOLO26論文で説明されているリアルタイムビジョンモデルの統合ファミリーです。ネイティブなエンドツーエンド推論、より軽量な検出ヘッド、更新された学習レシピ、そして検出、セグメンテーション、ポーズ推定、分類、回転物体検出のためのタスク固有ヘッドを導入しています。
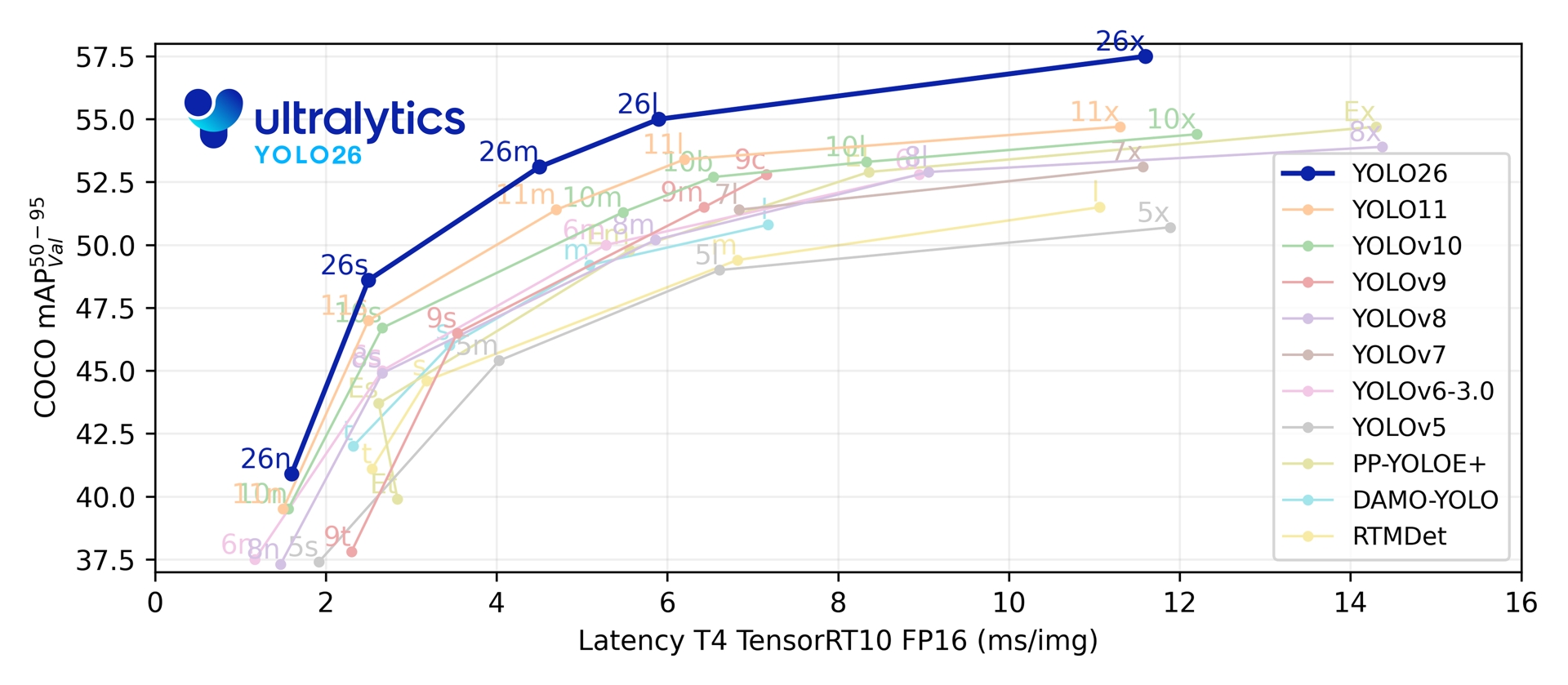
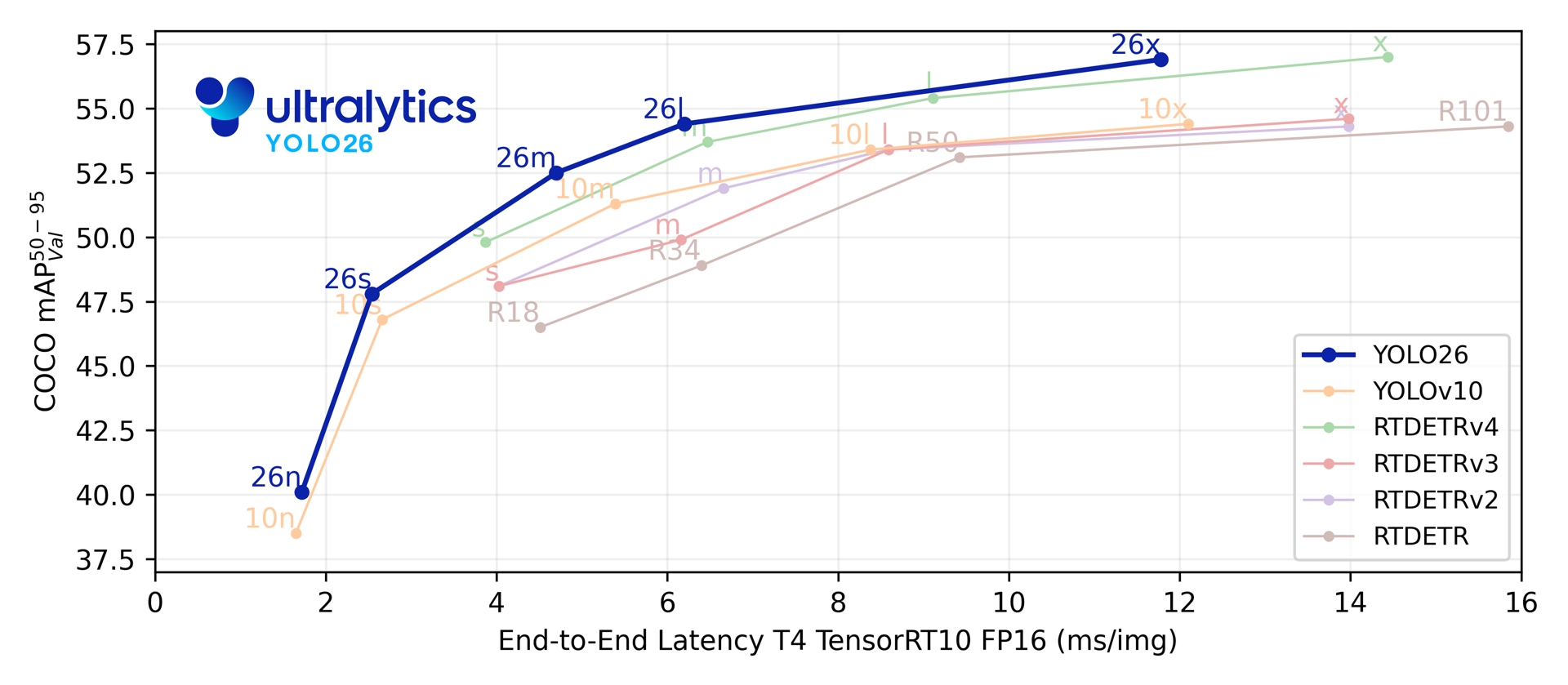
5つの検出スケール全体で、YOLO26は1.7-11.8 msのT4 TensorRTレイテンシで、COCO上で40.9-57.5 mAPを達成します。同論文では、Intel Xeon CPU @ 2.00 GHzにおいて、YOLO11nと比較してYOLO26nのCPU ONNX推論が最大43%高速化されたことも報告されています。
Ultralytics Platform上で、YOLO26モデルを直接探索して実行してください。
YOLO26モデルファミリーは、4つの設計領域を中心に構築されています。
- ネイティブなエンドツーエンド推論: デフォルトの1対1検出ヘッドは、非最大値抑制(NMS)なしで予測を生成するため、デプロイメントが簡素化され、後処理が軽減されます。
- 軽量なボックス回帰: YOLO26はDistribution Focal Loss (DFL)を削除し、制約のない回帰範囲を維持しながら検出ヘッドの複雑さを低減しています。
- トレーニングレシピの更新: トレーニングパイプラインは MuSGD、Progressive Loss、および STAL を組み合わせることで、最適化の向上、推論時のヘッドへの監視のシフト、そして小さなオブジェクトに対するポジティブラベルのカバレッジ維持を実現しています。公開されたチェックポイントの背後にある完全なハイパーパラメータは、YOLO26 Training Recipe guide に記載されています。
- タスク固有のヘッドとロス: YOLO26は、インスタンスセグメンテーション、セマンティックセグメンテーションのバリエーション、ポーズ推定、回転物体検出のためのターゲット設計を追加しつつ、タスク間で単一のモデルパイプラインを維持します。
これらのアップデートにより、モデルのスケールやデプロイ先全体での精度とレイテンシのトレードオフが向上します。
Link to this section主な特徴#
-
DFL不要の回帰 YOLO26はDistribution Focal Loss (DFL)を削除し、検出ヘッドの複雑さを低減してエクスポートを簡素化します。
-
エンドツーエンドのNMS不要推論 NMSを別個の後処理ステップとして依存する従来の検出器とは異なり、YOLO26はデフォルトでネイティブなエンドツーエンドです。予測が直接生成されるため、レイテンシが短縮され、本番環境への統合がより単純になります。
-
Progressive Loss + STAL Progressive Lossはトレーニングの重点を推論時のヘッドへとシフトさせ、STALは小さな物体に対する正解ラベルの網羅性を改善します。
-
MuSGDオプティマイザー SGDとMuonを組み合わせたハイブリッドなオプティマイザーであり、大規模言語モデルのトレーニングにおける最適化のアイデアをコンピュータビジョンに適応させています。
-
効率的なデプロイメント 簡素化されたヘッドとNMS不要のデフォルトパスにより、エクスポートターゲットやハードウェアプロファイル全体で推論のオーバーヘッドが削減されます。これには、YOLO11nに対するYOLO26nの論文で報告されたCPU ONNXの高速化も含まれます。
-
インスタンスセグメンテーションの強化 モデルの収束を改善するためのセマンティックセグメンテーションロスと、優れたマスク品質のためにマルチスケール情報を活用するアップグレードされたprotoモジュールが導入されました。論文では、COCOインスタンスセグメンテーションにおいて、YOLO11と比較して最大+2.5のボックスAPおよび+3.7のマスクAP向上が報告されています。
-
高精度ポーズ推定 Residual Log-Likelihood Estimation (RLE)を統合してキーポイントのローカリゼーション精度を高め、デコードプロセスを最適化して推論速度を向上させました。論文では、COCOポーズ推定においてYOLO11に対して最大+7.2 APの向上が報告されています。
-
OBDデコードの洗練 正方形の物体に対する検出精度を向上させるための特殊な角度ロスを導入し、境界の不連続性の問題を解決するためにOBDデコードを最適化しました。論文では、DOTA-v1.0の回転物体検出において、YOLO11に対して最大+3.4 mAPの向上が報告されています。
Link to this sectionサポートされるタスクとモード#
YOLO26は、5つのモデルスケール全体で標準的なUltralyticsタスクセットをサポートしています。
| モデル | ファイル名 | タスク | 推論 | バリデーション | トレーニング | エクスポート |
|---|---|---|---|---|---|---|
| YOLO26 | yolo26n.pt yolo26s.pt yolo26m.pt yolo26l.pt yolo26x.pt | 検出 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-seg | yolo26n-seg.pt yolo26s-seg.pt yolo26m-seg.pt yolo26l-seg.pt yolo26x-seg.pt | インスタンスセグメンテーション | ✅ | ✅ | ✅ | ✅ |
| YOLO26-sem | yolo26n-sem.pt yolo26s-sem.pt yolo26m-sem.pt yolo26l-sem.pt yolo26x-sem.pt | セマンティックセグメンテーション | ✅ | ✅ | ✅ | ✅ |
| YOLO26-pose | yolo26n-pose.pt yolo26s-pose.pt yolo26m-pose.pt yolo26l-pose.pt yolo26x-pose.pt | ポーズ/キーポイント | ✅ | ✅ | ✅ | ✅ |
| YOLO26-obb | yolo26n-obb.pt yolo26s-obb.pt yolo26m-obb.pt yolo26l-obb.pt yolo26x-obb.pt | 回転物体検出 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-cls | yolo26n-cls.pt yolo26s-cls.pt yolo26m-cls.pt yolo26l-cls.pt yolo26x-cls.pt | 分類 | ✅ | ✅ | ✅ | ✅ |
この統合フレームワークは、トレーニング、バリデーション、推論、およびエクスポートサポートを伴う、リアルタイムの検出、インスタンスセグメンテーション、セマンティックセグメンテーション、分類、ポーズ推定、および回転物体検出をカバーしています。
yolo26-p2.yamlおよびyolo26-p6.yamlは、P2(小物体)またはP6(大入力)検出ヘッドを追加しており、YAMLアーキテクチャとしてのみ提供されます。スケール固有のyolo26*-p2.ptやyolo26*-p6.ptウェイトはリリースされていません。YAMLからスケーリングされた設定をインスタンス化し(例: YOLO("yolo26n-p6.yaml"))、必要に応じてトレーニングや微調整を行ってください。
Link to this section性能メトリクス#
See Detection Docs for usage examples with these models trained on COCO, which include 80 pretrained classes.
| モデル | サイズ (ピクセル) | mAPval 50-95 | mAPval 50-95(e2e) | 速度 CPU ONNX (ms) | 速度 T4 TensorRT10 (ms) | パラメータ (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO26n | 640 | 40.9 | 40.1 | 38.9 ± 0.7 | 1.7 ± 0.0 | 2.4 | 5.4 |
| YOLO26s | 640 | 48.6 | 47.8 | 87.2 ± 0.9 | 2.5 ± 0.0 | 9.5 | 20.7 |
| YOLO26m | 640 | 53.1 | 52.5 | 220.0 ± 1.4 | 4.7 ± 0.1 | 20.4 | 68.2 |
| YOLO26l | 640 | 55.0 | 54.4 | 286.2 ± 2.0 | 6.2 ± 0.2 | 24.8 | 86.4 |
| YOLO26x | 640 | 57.5 | 56.9 | 525.8 ± 4.0 | 11.8 ± 0.2 | 55.7 | 193.9 |
ParamsおよびFLOPsの値は、Conv層とBatchNorm層を結合し、補助的なone-to-many検出ヘッドを削除した model.fuse() 後のフューズドモデルに対するものです。事前学習済みチェックポイントはトレーニング用の全アーキテクチャを保持しているため、より大きな値を示す場合があります。
Link to this section使用例#
このセクションでは、基本的なYOLO26のトレーニングおよび推論の例を紹介します。これらおよびその他の モード に関する完全なドキュメントについては、Predict、Train、Val、および Export のドキュメントページを参照してください。
以下の例は YOLO26 Detect モデルによる object detection のものです。その他のサポートされているタスクについては、Segment、Semantic Segmentation、Classify、OBB、および Pose のドキュメントを参照してください。
PyTorch の事前学習済み *.pt モデル、および設定用の *.yaml ファイルを YOLO() クラスに渡すことで、Pythonでモデルインスタンスを作成できます。
from ultralytics import YOLO
# Load a COCO-pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLO26n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")YOLO26検出モデルは、さまざまなデプロイシナリオに対応できる柔軟性を備えた デュアルヘッドアーキテクチャ を採用しています。
- One-to-One Head (デフォルト): NMSを使用しないエンドツーエンドの予測を生成し、1画像あたり最大300個の検出結果を
(N, 300, 6)として出力します。このヘッドは高速な推論とシンプルなデプロイに最適化されています。 - One-to-Many Head: NMS後処理を必要とする従来のYOLO出力を生成し、
(N, nc + 4, 8400)として出力します(ncはクラス数)。このヘッドは、追加の処理コストと引き換えに、通常わずかに高い精度を実現します。
エクスポート、予測、またはバリデーションの実行中にヘッドを切り替えることができます。
from ultralytics import YOLO
model = YOLO("yolo26n.pt")
# Use one-to-one head (default, no NMS required)
results = model.predict("image.jpg") # inference
metrics = model.val(data="coco.yaml") # validation
model.export(format="onnx") # export
# Use one-to-many head (requires NMS)
results = model.predict("image.jpg", end2end=False) # inference
metrics = model.val(data="coco.yaml", end2end=False) # validation
model.export(format="onnx", end2end=False) # export選択はデプロイ要件に依存します。最大限の速度とシンプルさを求める場合はone-to-oneヘッドを使用し、精度を最優先する場合はone-to-manyヘッドを使用してください。
Link to this sectionYOLOE-26: オープンボキャブラリー検出およびセグメンテーション#
YOLOE-26は、YOLOE シリーズのオープンボキャブラリー機能をYOLO26に拡張したものです。テキストプロンプト、ビジュアルプロンプト、または プロンプト不要モード を使用して、オープンセットのオブジェクトカテゴリをリアルタイムで検出およびセグメンテーションできます。
YOLO26の NMS不要なエンドツーエンド設計 を活用することで、YOLOE-26は、対象カテゴリが時間とともに変化する動的な環境でも十分な速さでオープンボキャブラリー推論を実行可能です。YOLOE-26xは、テキストプロンプト時にLVIS minivalで 40.6 AP、ビジュアルプロンプト時に 38.5 AP、プロンプト不要の非E2E設定で 31.1 AP を達成します。
See YOLOE Docs for usage examples with these models trained on Objects365v1, GQA and Flickr30k datasets.
| モデル | サイズ (ピクセル) | プロンプトタイプ | mAPminival 50-95(e2e) | mAPminival 50-95 | mAPr | mAPc | mAPf | パラメータ (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOE-26n-seg | 640 | テキスト/ビジュアル | 23.7 / 20.9 | 24.7 / 21.9 | 20.5 / 17.6 | 24.1 / 22.3 | 26.1 / 22.4 | 4.8 | 6.0 |
| YOLOE-26s-seg | 640 | テキスト/ビジュアル | 29.9 / 27.1 | 30.8 / 28.6 | 23.9 / 25.1 | 29.6 / 27.8 | 33.0 / 29.9 | 13.1 | 21.7 |
| YOLOE-26m-seg | 640 | テキスト/ビジュアル | 35.4 / 31.3 | 35.4 / 33.9 | 31.1 / 33.4 | 34.7 / 34.0 | 36.9 / 33.8 | 27.9 | 70.1 |
| YOLOE-26l-seg | 640 | テキスト/ビジュアル | 36.8 / 33.7 | 37.8 / 36.3 | 35.1 / 37.6 | 37.6 / 36.2 | 38.5 / 36.1 | 32.3 | 88.3 |
| YOLOE-26x-seg | 640 | テキスト/ビジュアル | 39.5 / 36.2 | 40.6 / 38.5 | 37.4 / 35.3 | 40.9 / 38.8 | 41.0 / 38.8 | 69.9 | 196.7 |
Link to this section使用例#
YOLOE-26は、テキストベースおよびビジュアルベースの両方のプロンプトをサポートしています。プロンプトの使用は簡単で、以下に示すように predict メソッドに渡すだけです。
テキストプロンプトを使用すると、テキストによる説明を通じて検出したいクラスを指定できます。以下のコードは、YOLOE-26を使用して画像内の人やバスを検出する方法を示しています。
from ultralytics import YOLO
# Initialize model
model = YOLO("yoloe-26l-seg.pt") # or select yoloe-26s/m-seg.pt for different sizes
# Set text prompt to detect person and bus. You only need to do this once after you load the model.
model.set_classes(["person", "bus"])
# Run detection on the given image
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()プロンプト技術や完全な使用例については、**YOLOE Documentation**を参照してください。
Link to this section引用と謝辞#
YOLO26のアーキテクチャ、学習レシピ、タスクヘッド、およびYOLOE-26オープンボキャブラリー拡張機能の詳細な技術説明については、Ultralytics YOLO26: Unified Real-Time End-to-End Vision Modelsをお読みください。研究でYOLO26を使用する場合は、以下を引用してください。
@misc{jocher2026ultralyticsyolo26unifiedrealtime,
title = {Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models},
author = {Glenn Jocher and Jing Qiu and Mengyu Liu and Shuai Lyu and Fatih Cagatay Akyon and Muhammet Esat Kalfaoglu},
year = {2026},
eprint = {2606.03748},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
doi = {10.48550/arXiv.2606.03748},
url = {https://arxiv.org/abs/2606.03748},
}YOLO26 のコード、モデル、ドキュメントは、Ultralytics GitHub リポジトリ および Ultralytics ドキュメント にて、AGPL-3.0 ライセンスおよび Enterprise ライセンスの下で提供されています。
Link to this sectionよくある質問 (FAQ)#
Link to this sectionYOLO26における主な改善点は何ですか?#
- DFL-free回帰: 検出ヘッドとエクスポートパスを簡素化します。
- エンドツーエンドのNMS-free推論: デフォルトの推論パスからNMSを削除します。
- Progressive Loss + STAL: 学習の整合性と小さなオブジェクトのラベルカバレッジを向上させます。
- MuSGDオプティマイザー: SGDとMuon風の最適化を組み合わせ、安定した学習を実現します。
- タスク固有のヘッドと損失: セグメンテーション、姿勢推定、回転オブジェクト検出のサポートを強化します。
Link to this sectionYOLO26はどのようなタスクをサポートしていますか?#
YOLO26は統合モデルファミリであり、複数のコンピュータビジョンのタスクに対してエンドツーエンドのサポートを提供します。
各サイズバリアント (n, s, m, l, x) はすべてのタスクをサポートしており、さらに YOLOE-26 を介したオープンボキャブラリー版も提供しています。
Link to this sectionなぜ YOLO26 はデプロイメントにおいて効率的なのでしょうか?#
YOLO26 は以下の点によりデプロイメントの効率を向上させます。
- デフォルトで NMS を必要としないネイティブなエンドツーエンド推論
- DFL 不要の回帰と軽量化された検出ヘッド
- トレーニング専用の補助コンポーネントを削除するフューズドモデルエクスポート
- Intel Xeon CPU @ 2.00 GHz における YOLO11n と比較して、YOLO26n は CPU ONNX 推論が最大 43% 高速化
- TensorRT、ONNX、CoreML、LiteRT、OpenVINOを含む柔軟なエクスポート形式
Link to this sectionYOLO26 はどのように始めればよいですか?#
YOLO26 モデルは ultralytics パッケージを通じてダウンロード可能です。パッケージをインストールまたは更新し、モデルを読み込んでください。
from ultralytics import YOLO
# Load a pretrained YOLO26 nano model
model = YOLO("yolo26n.pt")
# Run inference on an image
results = model("image.jpg")トレーニング、バリデーション、エクスポートの手順については、Usage Examples セクションを参照してください。