Een handleiding voor het testen van modellen
Inleiding
Na het trainen en evalueren van je model is het tijd om het te testen. Het testen van een model houdt in dat je beoordeelt hoe goed het model presteert in echte scenario's. Bij het testen wordt rekening gehouden met factoren als nauwkeurigheid, betrouwbaarheid, eerlijkheid en hoe gemakkelijk het is om de beslissingen van het model te begrijpen. Het doel is om er zeker van te zijn dat het model presteert zoals bedoeld, de verwachte resultaten levert en past in de algemene doelstelling van je applicatie of project.
Het testen van modellen lijkt veel op modelevaluatie, maar het zijn twee verschillende stappen in een computervisieproject. Bij modelevaluatie worden metrieken en plots gebruikt om de nauwkeurigheid van het model te beoordelen. Aan de andere kant controleert het testen van modellen of het geleerde gedrag van het model overeenkomt met de verwachtingen. In deze gids verkennen we strategieën voor het testen van je computervisie modellen.
Model testen vs. Modelevaluatie
Laten we eerst het verschil tussen modelevaluatie en testen begrijpen aan de hand van een voorbeeld.
Stel dat je een computervisiemodel hebt getraind om katten en honden te herkennen en je wilt dit model inzetten in een dierenwinkel om de dieren te controleren. Tijdens de evaluatie van het model gebruik je een gelabelde dataset om metrieken als nauwkeurigheid, precisie, recall en F1 score te berekenen. Het model zou bijvoorbeeld een nauwkeurigheid van 98% kunnen hebben in het onderscheiden van katten en honden in een gegeven dataset.
Na de evaluatie test je het model met behulp van afbeeldingen uit een dierenwinkel om te zien hoe goed het katten en honden identificeert in meer gevarieerde en realistische omstandigheden. Je controleert of het model katten en honden correct kan labelen wanneer ze bewegen, in verschillende lichtomstandigheden of gedeeltelijk verborgen door objecten zoals speelgoed of meubels. Modeltests controleren of het model zich gedraagt zoals verwacht buiten de gecontroleerde evaluatieomgeving.
Model testen voorbereiden
Computer vision modellen leren van datasets door patronen te detecteren, voorspellingen te doen en hun prestaties te evalueren. Deze datasets worden meestal verdeeld in een trainings- en een testset om echte omstandigheden te simuleren. Trainingsgegevens leren het model terwijl testgegevens de nauwkeurigheid ervan controleren.
Hier zijn twee punten die je in gedachten moet houden voordat je je model gaat testen:
- Realistische representatie: De nog niet eerder geteste gegevens moeten lijken op de gegevens die het model zal moeten verwerken als het wordt ingezet. Dit helpt om een realistisch beeld te krijgen van de mogelijkheden van het model.
- Voldoende omvang: De omvang van de testdataset moet groot genoeg zijn om betrouwbare inzichten te geven in hoe goed het model presteert.
Je computervisiemodel testen
Dit zijn de belangrijkste stappen om je computervisiemodel te testen en de prestaties ervan te begrijpen.
- Voorspellingen uitvoeren: Gebruik het model om voorspellingen te doen op de testdataset.
- Voorspellingen vergelijken: Controleer hoe goed de voorspellingen van het model overeenkomen met de werkelijke labels (ground truth).
- Bereken prestatiecijfers: Bereken metrieken als nauwkeurigheid, precisie, recall en F1-score om de sterke en zwakke punten van het model te begrijpen. Testen richt zich op hoe deze statistieken de prestaties in de echte wereld weergeven.
- Resultaten visualiseren: Maak visuele hulpmiddelen zoals verwarringmatrices en ROC-curves. Deze helpen je om specifieke gebieden te vinden waar het model misschien niet goed presteert in praktische toepassingen.
Vervolgens kunnen de testresultaten worden geanalyseerd:
- Verkeerd geclassificeerde afbeeldingen: Identificeer en bekijk afbeeldingen die het model verkeerd heeft geclassificeerd om te begrijpen waar het fout gaat.
- Foutenanalyse: Voer een grondige foutenanalyse uit om inzicht te krijgen in de soorten fouten (bijv. fout-positieven vs. fout-negatieven) en hun mogelijke oorzaken.
- Vertekening en eerlijkheid: Controleer op eventuele vertekeningen in de voorspellingen van het model. Zorg ervoor dat het model even goed presteert over verschillende subsets van de gegevens, vooral als het gevoelige kenmerken bevat zoals ras, geslacht of leeftijd.
Je model YOLOv8 testen
Om je YOLOv8 model te testen kun je de validatiemodus gebruiken. Het is een eenvoudige manier om inzicht te krijgen in de sterke punten van het model en de gebieden die verbetering nodig hebben. Je moet ook je testdataset correct opmaken voor YOLOv8. Kijk voor meer informatie over het gebruik van de validatiemodus op de pagina Modelvalidatie docs.
YOLOv8 gebruiken om te voorspellen op meerdere testafbeeldingen
Als je je getrainde YOLOv8 model wilt testen op meerdere afbeeldingen die zijn opgeslagen in een map, dan kun je dat eenvoudig in één keer doen. In plaats van de validatiemodus te gebruiken, die meestal wordt gebruikt om de prestaties van het model te evalueren op een validatieset en gedetailleerde statistieken te geven, wil je misschien gewoon de voorspellingen zien op alle afbeeldingen in je testset. Hiervoor kun je de voorspellingsmodus gebruiken.
Verschil tussen validatie- en voorspellingsmodus
- Validatiemodus: Wordt gebruikt om de prestaties van het model te evalueren door voorspellingen te vergelijken met bekende labels (ground truth). Het geeft gedetailleerde statistieken zoals nauwkeurigheid, precisie, recall en F1 score.
- Voorspellingsmodus: Wordt gebruikt om het model te laten draaien op nieuwe, ongeziene gegevens om voorspellingen te genereren. Deze modus geeft geen gedetailleerde prestatiecijfers, maar stelt je in staat om te zien hoe het model presteert op echte afbeeldingen.
YOLOv8 voorspellingen uitvoeren zonder aangepaste training
Als je het basismodel YOLOv8 wilt testen om te begrijpen of het gebruikt kan worden voor jouw toepassing zonder aangepaste training, kun je de voorspellingsmodus gebruiken. Hoewel het model is voorgetraind op datasets zoals COCO, kun je door voorspellingen uit te voeren op je eigen dataset snel zien hoe goed het model zou kunnen presteren in jouw specifieke context.
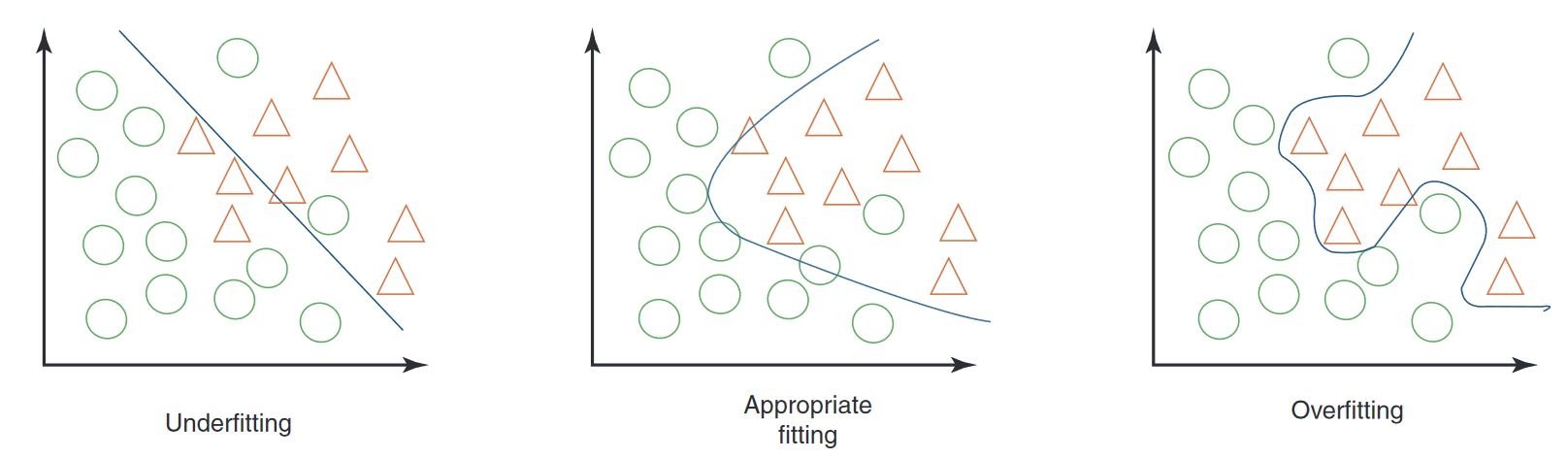
Overfitting en underfitting in machinaal leren
Bij het testen van een machine-learning model, vooral bij computer vision, is het belangrijk om te letten op overfitting en underfitting. Deze problemen kunnen van grote invloed zijn op hoe goed je model werkt met nieuwe gegevens.
Overpassing
Overfitting treedt op als je model de trainingsgegevens te goed leert, inclusief de ruis en details die niet generaliseren naar nieuwe gegevens. In computer vision betekent dit dat je model het geweldig kan doen met getrainde afbeeldingen, maar moeite heeft met nieuwe afbeeldingen.
Tekenen van overpassen
- Hoge trainingsnauwkeurigheid, lage validatienauwkeurigheid: Als je model erg goed presteert op trainingsgegevens maar slecht op validatie- of testgegevens, dan is er waarschijnlijk sprake van overfitting.
- Visuele inspectie: Soms kun je overfitting zien als je model te gevoelig is voor kleine veranderingen of irrelevante details in afbeeldingen.
Ondermaatse aanpassing
Underfitting treedt op wanneer je model de onderliggende patronen in de gegevens niet kan vastleggen. Bij computervisie kan een model met een te lage aanpassing zelfs objecten in de trainingsafbeeldingen niet correct herkennen.
Tekenen van een te lage pasvorm
- Lage trainingsnauwkeurigheid: Als je model geen hoge nauwkeurigheid kan bereiken op de trainingsset, is er mogelijk sprake van underfitting.
- Visuele misclassificatie: Het consequent niet herkennen van duidelijke kenmerken of objecten duidt op een te lage aanpassing.
Over- en underfitting in evenwicht brengen
De sleutel is om een balans te vinden tussen overfitting en underfitting. In het ideale geval presteert een model goed op zowel trainings- als validatiedatasets. Het regelmatig controleren van de prestaties van je model door middel van metrieken en visuele inspecties, samen met het toepassen van de juiste strategieën, kan je helpen om de beste resultaten te behalen.
Gegevenslekken in computervisie en hoe ze te vermijden
Bij het testen van je model is het belangrijk om rekening te houden met datalekken. Gegevenslekkage treedt op wanneer informatie van buiten de trainingsdataset per ongeluk wordt gebruikt om het model te trainen. Het model kan heel accuraat lijken tijdens het trainen, maar het zal niet goed presteren op nieuwe, ongeziene gegevens als er een datalek optreedt.
Waarom er gegevens uitlekken
Datalekken kunnen lastig te ontdekken zijn en komen vaak door verborgen vooroordelen in de trainingsgegevens. Hier zijn enkele veelvoorkomende manieren waarop dit kan gebeuren bij computervisie:
- Cameravertekening: Verschillende hoeken, belichting, schaduwen en camerabewegingen kunnen ongewenste patronen introduceren.
- Overlay Bias: Logo's, tijdstempels of andere overlays in afbeeldingen kunnen het model misleiden.
- Lettertype- en objectvooringenomenheid: Specifieke lettertypen of objecten die vaak voorkomen in bepaalde klassen kunnen het leren van het model vertekenen.
- Ruimtelijke vertekening: Onevenwichtigheden in voorgrond-achtergrond, bounding box distributies en objectlocaties kunnen de training beïnvloeden.
- Label- en domeinvertekening: Onjuiste labels of verschuivingen in gegevenstypen kunnen leiden tot lekkage.
Datalekken opsporen
Om datalekken te vinden, kun je:
- Prestaties controleren: Als de resultaten van het model verrassend goed zijn, kan het zijn dat het lekt.
- Kijk naar het belang van eigenschappen: Als één eigenschap veel belangrijker is dan andere, kan dit duiden op lekkage.
- Visuele inspectie: Dubbelcheck of de beslissingen van het model intuïtief kloppen.
- Controleer datascheiding: Controleer of de gegevens correct zijn gesplitst voordat ze worden verwerkt.
Het uitlekken van gegevens voorkomen
Om datalekken te voorkomen, gebruik je een gevarieerde dataset met beelden of video's van verschillende camera's en omgevingen. Bekijk je gegevens zorgvuldig en controleer of er geen verborgen vertekeningen zijn, zoals alle positieve monsters die op een bepaald tijdstip zijn genomen. Het vermijden van datalekken zal helpen om je computervisiemodellen betrouwbaarder en effectiever te maken in echte situaties.
Wat komt er na het testen van modellen?
Na het testen van je model zijn de volgende stappen afhankelijk van de resultaten. Als je model goed presteert, kun je het inzetten in een echte omgeving. Als de resultaten niet bevredigend zijn, moet je verbeteringen aanbrengen. Dit kan inhouden dat je fouten moet analyseren, meer gegevens moet verzamelen, de kwaliteit van de gegevens moet verbeteren, hyperparameters moet aanpassen en het model opnieuw moet trainen.
Doe mee aan het AI-gesprek
Deel uitmaken van een gemeenschap van computer vision-enthousiastelingen kan helpen om problemen op te lossen en efficiënter te leren. Hier zijn enkele manieren om in contact te komen, hulp te zoeken en je gedachten te delen.
Hulpbronnen van de Gemeenschap
- GitHub problemen: Verken de YOLOv8 GitHub repository en gebruik de Issues tab om vragen te stellen, bugs te melden en nieuwe functies voor te stellen. De gemeenschap en beheerders zijn erg actief en staan klaar om te helpen.
- Ultralytics Discord-server: Word lid van de Ultralytics Discord-server om te chatten met andere gebruikers en ontwikkelaars, ondersteuning te krijgen en je ervaringen te delen.
Officiële documentatie
- Ultralytics YOLOv8 Documentatie: Bekijk de officiële YOLOv8 documentatie voor gedetailleerde handleidingen en handige tips voor verschillende computer vision projecten.
Deze bronnen helpen je om uitdagingen het hoofd te bieden en op de hoogte te blijven van de nieuwste trends en praktijken binnen de computervisiegemeenschap.
Samengevat
Het bouwen van betrouwbare computervisiemodellen is afhankelijk van het rigoureus testen van modellen. Door het model te testen met ongeziene gegevens kunnen we het analyseren en zwakke punten zoals overfitting en datalekken opsporen. Door deze problemen aan te pakken voordat het model wordt ingezet, kan het goed presteren in echte toepassingen. Het is belangrijk om te onthouden dat het testen van modellen net zo cruciaal is als de evaluatie van modellen om het succes en de effectiviteit van het model op de lange termijn te garanderen.
FAQ
Wat zijn de belangrijkste verschillen tussen modelevaluatie en het testen van modellen bij computervisie?
Modelevaluatie en modeltesten zijn verschillende stappen in een computervisieproject. Modelevaluatie omvat het gebruik van een gelabelde dataset om metrieken te berekenen zoals nauwkeurigheid, precisie, recall en F1-score, die inzicht geven in de prestaties van het model met een gecontroleerde dataset. Modeltests daarentegen beoordelen de prestaties van het model in echte scenario's door het toe te passen op nieuwe, ongeziene gegevens, om ervoor te zorgen dat het geleerde gedrag van het model overeenkomt met de verwachtingen buiten de evaluatieomgeving. Raadpleeg voor een gedetailleerde handleiding de stappen in een computervisieproject.
Hoe kan ik mijn Ultralytics YOLOv8 model testen op meerdere afbeeldingen?
Om je Ultralytics YOLOv8 model op meerdere afbeeldingen te testen, kun je de voorspellingsmodus gebruiken. In deze modus kun je het model laten draaien op nieuwe, ongeziene gegevens om voorspellingen te genereren zonder gedetailleerde statistieken te geven. Dit is ideaal voor het testen van de prestaties in de echte wereld op grotere afbeeldingssets die zijn opgeslagen in een map. Gebruik in plaats daarvan de validatiemodus om de prestatiecijfers te evalueren.
Wat moet ik doen als mijn computervisiemodel tekenen van over- of underfitting vertoont?
Overfitting aanpakken:
- Regularisatietechnieken zoals dropout.
- Vergroot de grootte van de trainingsdataset.
- Vereenvoudig de modelarchitectuur.
Ondermaatse aanpassing aanpakken:
- Gebruik een complexer model.
- Meer relevante functies bieden.
- Trainingsiteraties of epochs verhogen.
Bekijk verkeerd geclassificeerde afbeeldingen, voer een grondige foutenanalyse uit en volg regelmatig de prestatiecijfers om een balans te behouden. Voor meer informatie over deze concepten, bekijk onze sectie over Overfitting en Underfitting.
Hoe kan ik datalekken detecteren en vermijden in computervisie?
Om gegevenslekken te detecteren:
- Controleer of de testprestaties niet ongewoon hoog zijn.
- Controleer het belang van eigenschappen voor onverwachte inzichten.
- Intuïtief modelbeslissingen beoordelen.
- Zorg voor een correcte gegevensverdeling vóór verwerking.
Om lekken van gegevens te voorkomen:
- Gebruik diverse datasets met verschillende omgevingen.
- Bekijk gegevens zorgvuldig op verborgen vooroordelen.
- Zorg ervoor dat er geen overlappende informatie is tussen de trainings- en testsets.
Raadpleeg voor gedetailleerde strategieën voor het voorkomen van gegevenslekken ons gedeelte over gegevenslekken in computervisie.
Welke stappen moet ik nemen na het testen van mijn computervisiemodel?
Als na het testen de prestaties van het model voldoen aan de projectdoelen, ga dan verder met de implementatie. Als de resultaten onbevredigend zijn, overweeg dan:
- Foutenanalyse.
- Meer diverse gegevens van hoge kwaliteit verzamelen.
- Hyperparameter afstemming.
- Het model hertrainen.
Verwerf inzichten uit de sectie Model Testing Vs. Modelevaluatie om de effectiviteit van modellen in echte toepassingen te verfijnen en te verbeteren.
Hoe voer ik YOLOv8 voorspellingen uit zonder aangepaste training?
Je kunt voorspellingen uitvoeren met het voorgetrainde YOLOv8 model op je dataset om te zien of het geschikt is voor je toepassing. Gebruik de voorspellingsmodus om snel een idee te krijgen van de prestatieresultaten zonder in aangepaste training te duiken.