Link to this sectionSAM 3: Segment Anything with Concepts#
SAM 3 ist ab Version 8.3.237 (PR #22897) vollständig in das Ultralytics-Paket integriert. Installiere oder aktualisiere es mit pip install -U ultralytics, um auf alle SAM 3-Funktionen zuzugreifen, einschließlich textbasierter Konzept-Segmentierung, Bildbeispiel-Prompts und Video-Tracking.
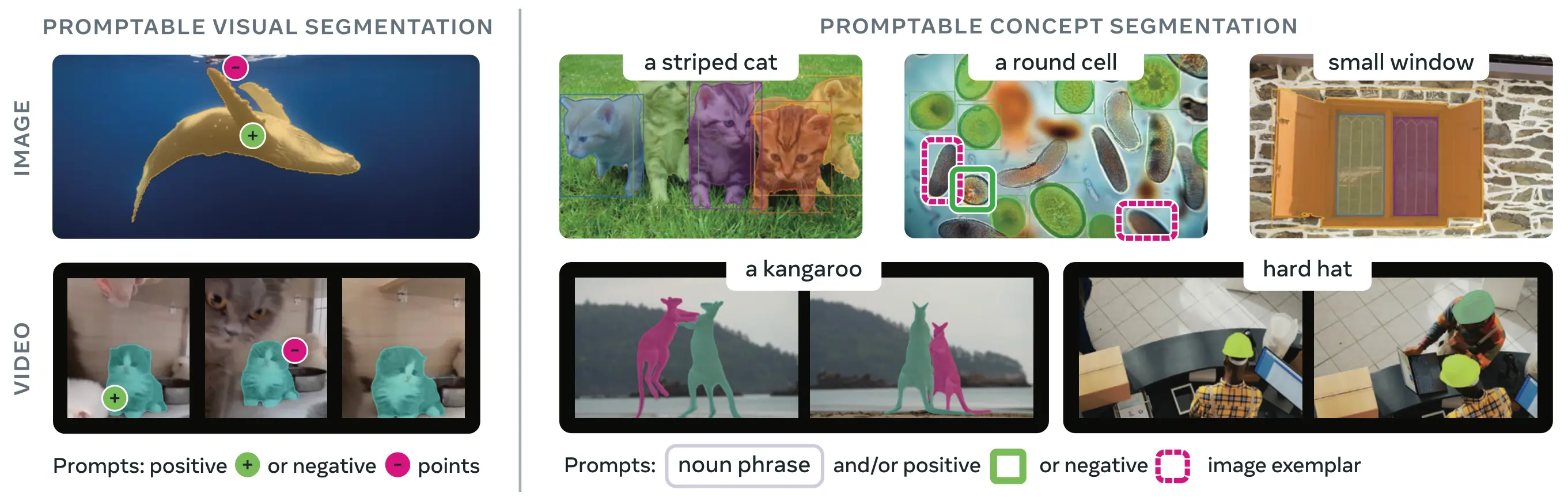
SAM 3 (Segment Anything Model 3) ist das von Meta veröffentlichte Basismodell für Promptable Concept Segmentation (PCS). Aufbauend auf SAM 2 führt SAM 3 eine grundlegend neue Fähigkeit ein: das Erkennen, Segmentieren und Verfolgen aller Instanzen eines visuellen Konzepts, das durch Text-Prompts, Bildbeispiele oder beides spezifiziert wird. Im Gegensatz zu früheren SAM-Versionen, die einzelne Objekte pro Prompt segmentieren, kann SAM 3 jedes Vorkommen eines Konzepts, das irgendwo in Bildern oder Videos erscheint, finden und segmentieren, was den Open-Vocabulary-Zielen bei moderner instance segmentation entspricht.
Watch: How to Use Meta Segment Anything 3 with Ultralytics | Text-Prompt Segmentation on Images & Videos
SAM 3 ist jetzt vollständig in das ultralytics-Paket integriert und bietet native Unterstützung für Konzept-Segmentierung mit Text-Prompts, Bildbeispiel-Prompts und Video-Tracking-Funktionen.
Link to this sectionÜbersicht#
SAM 3 erzielt einen 2-fachen Leistungszuwachs gegenüber bestehenden Systemen bei der Promptable Concept Segmentation, während die Fähigkeiten von SAM 2 für interaktive visual segmentation beibehalten und verbessert werden. Das Modell zeichnet sich bei der Open-Vocabulary-Segmentierung aus und ermöglicht es Benutzern, Konzepte durch einfache Substantivphrasen (z. B. "gelber Schulbus", "gestreifte Katze") oder durch die Bereitstellung von Beispielbildern des Zielobjekts zu spezifizieren. Diese Fähigkeiten ergänzen produktionsreife Pipelines, die auf optimierten predict und track Workflows basieren.
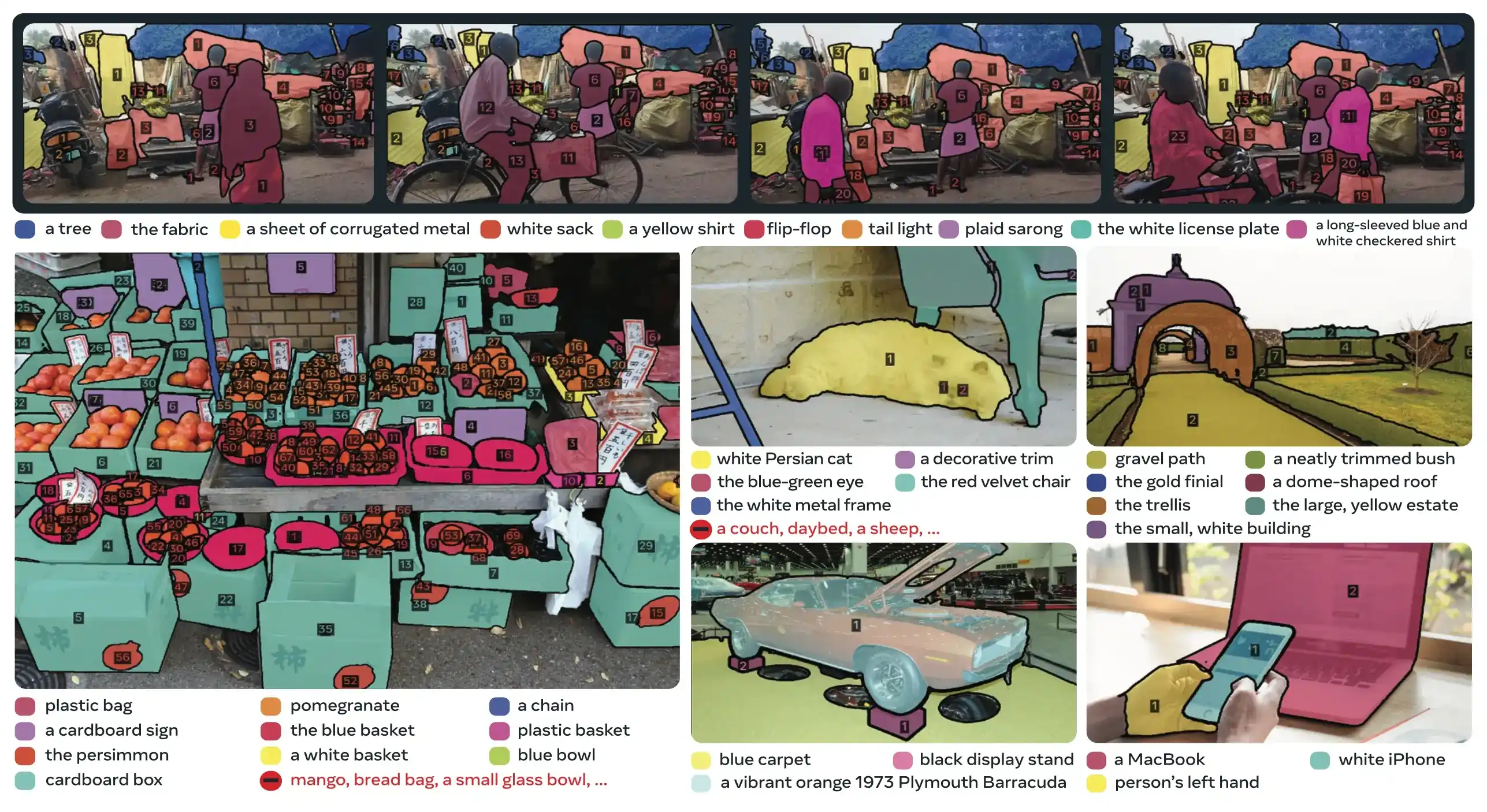
Link to this sectionWas ist Promptable Concept Segmentation (PCS)?#
Die PCS-Aufgabe nimmt einen Konzept-Prompt als Eingabe und gibt Segmentierungsmasken mit eindeutigen Identitäten für alle übereinstimmenden Objektinstanzen zurück. Konzept-Prompts können sein:
- Text: Einfache Substantivphrasen wie "roter Apfel" oder "Person mit Hut", ähnlich wie zero-shot learning
- Bildbeispiele: Begrenzungsrahmen (Bounding Boxes) um Beispielobjekte (positiv oder negativ) für schnelle Generalisierung
- Kombiniert: Sowohl Text als auch Bildbeispiele zusammen für präzise Steuerung
Dies unterscheidet sich von traditionellen visuellen Prompts (Punkte, Boxen, Masken), die nur eine einzelne spezifische Objektinstanz segmentieren, wie es durch die ursprüngliche SAM family populär wurde.
Link to this sectionWichtige Leistungsmetriken#
| Metrik | SAM 3 Errungenschaft |
|---|---|
| LVIS Zero-Shot Mask AP | 47.0 (gegenüber dem bisherigen Bestwert 38.5, +22% Verbesserung) |
| SA-Co Benchmark | 2-mal besser als bestehende Systeme |
| Inferenzgeschwindigkeit (H200 GPU) | 30 ms pro Bild mit 100+ erkannten Objekten |
| Video-Leistung | Nahezu Echtzeit für ~5 gleichzeitige Objekte |
| MOSEv2 VOS Benchmark | 60.1 J&F (+25.5% gegenüber SAM 2.1, +17% gegenüber vorherigem SOTA) |
| Interaktive Verfeinerung | +18.6 CGF1 Verbesserung nach 3 Beispiel-Prompts |
| Lücke zur menschlichen Leistung | Erreicht 88% der geschätzten Untergrenze auf SA-Co/Gold |
Für Kontext zu Modellmetriken und Abwägungen in der Produktion, siehe model evaluation insights und YOLO performance metrics.
Link to this sectionArchitektur#
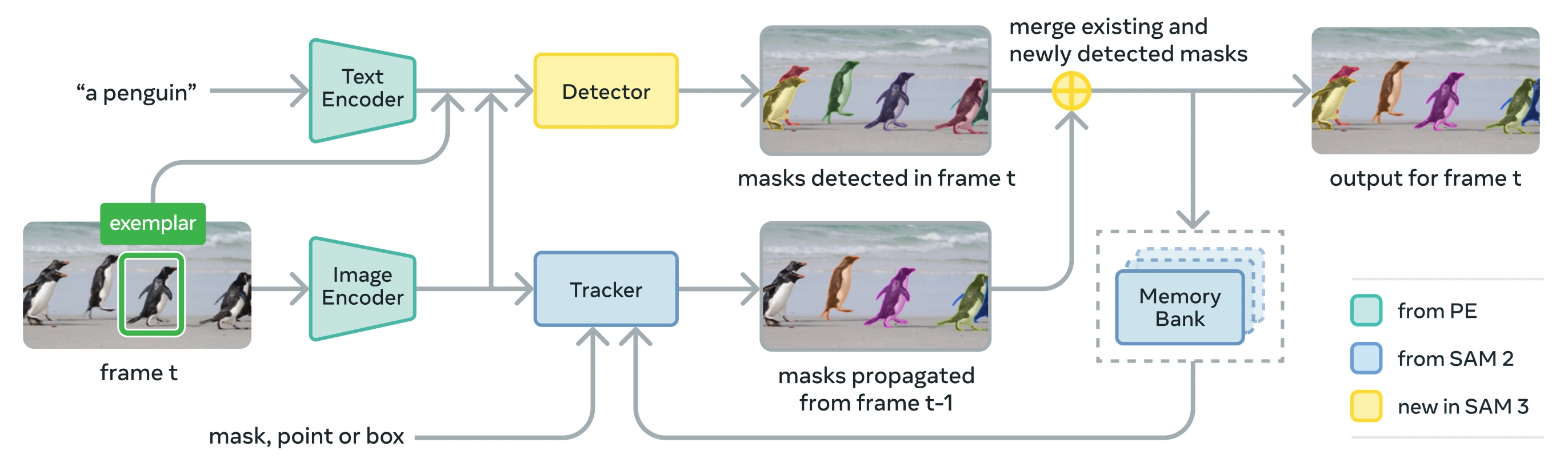
SAM 3 besteht aus einem Detektor und einem Tracker, die sich ein Perception Encoder (PE) Vision-Backbone teilen. Dieses entkoppelte Design vermeidet Aufgabenkonflikte und ermöglicht sowohl die Erkennung auf Bildebene als auch das Tracking auf Videoebene, mit einer Schnittstelle, die mit der Ultralytics Python usage und CLI usage kompatibel ist.
Link to this sectionKernkomponenten#
-
Detektor: DETR-basierte Architektur für die Konzept-Erkennung auf Bildebene
- Text-Encoder für Substantivphrasen-Prompts
- Beispiel-Encoder für bildbasierte Prompts
- Fusions-Encoder zur Konditionierung von Bildmerkmalen auf Prompts
- Neuartiger Presence Head, der Erkennung ("was") von Lokalisierung ("wo") entkoppelt
- Mask-Head zur Generierung von Instanz-Segmentierungsmasken
-
Tracker: Speicherbasierte Videosegmentierung, geerbt von SAM 2
- Prompt-Encoder, Mask-Decoder, Speicher-Encoder
- Speicherbank zum Speichern des Objekterscheinungsbildes über Frames hinweg
- Zeitliche Disambiguierung, unterstützt durch Techniken wie einen Kalman filter in Multi-Objekt-Umgebungen
-
Presence Token: Ein erlernter globaler Token, der vorhersagt, ob das Zielkonzept im Bild/Frame vorhanden ist, was die Erkennung verbessert, indem Erkennung von Lokalisierung getrennt wird.
Link to this sectionWichtige Innovationen#
- Entkoppelte Erkennung und Lokalisierung: Der Presence Head sagt die Konzeptpräsenz global voraus, während sich Vorschlagsabfragen (Proposal Queries) nur auf die Lokalisierung konzentrieren, wodurch widersprüchliche Ziele vermieden werden.
- Vereinigte Konzept- und visuelle Prompts: Unterstützt sowohl PCS (Konzept-Prompts) als auch PVS (visuelle Prompts wie SAM 2's Klicks/Boxen) in einem einzigen Modell.
- Interaktive Beispiel-Verfeinerung: Benutzer können positive oder negative Bildbeispiele hinzufügen, um Ergebnisse iterativ zu verfeinern, wobei das Modell auf ähnliche Objekte generalisiert, anstatt nur einzelne Instanzen zu korrigieren.
- Zeitliche Disambiguierung: Verwendet Masklet-Erkennungs-Scores und periodisches Re-Prompting, um mit Verdeckungen, überfüllten Szenen und Tracking-Fehlern in Videos umzugehen, was den Best Practices für instance segmentation and tracking entspricht.
Link to this sectionSA-Co Datensatz#
SAM 3 wird auf Segment Anything with Concepts (SA-Co) trainiert, Metas bisher größtem und vielfältigstem Segmentierungsdatensatz, der über gängige Benchmarks wie COCO und LVIS hinausgeht.
Link to this sectionTrainingsdaten#
| Datensatz-Komponente | Beschreibung | Skala |
|---|---|---|
| SA-Co/HQ | Hochwertige, von Menschen annotierte Bilddaten aus einer 4-Phasen-Daten-Engine | 5.2 Mio. Bilder, 4 Mio. einzigartige Substantivphrasen |
| SA-Co/SYN | Synthetischer Datensatz, der von KI ohne menschliches Eingreifen gelabelt wurde | 38 Mio. Substantivphrasen, 1.4 Mrd. Masken |
| SA-Co/EXT | 15 externe Datensätze, angereichert mit harten Negativbeispielen | Variiert je nach Quelle |
| SA-Co/VIDEO | Video-Annotationen mit zeitlichem Tracking | 52.5 Tsd. Videos, 24.8 Tsd. einzigartige Substantivphrasen |
Link to this sectionBenchmark-Daten#
Der SA-Co Evaluierungs-Benchmark enthält 214 Tsd. einzigartige Phrasen über 126 Tsd. Bilder und Videos und bietet über 50-mal mehr Konzepte als bestehende Benchmarks. Er umfasst:
- SA-Co/Gold: 7 Domänen, dreifach annotiert zur Messung der Grenzen menschlicher Leistung
- SA-Co/Silver: 10 Domänen, einfache menschliche Annotation
- SA-Co/Bronze und SA-Co/Bio: 9 bestehende Datensätze, die für die Konzept-Segmentierung angepasst wurden
- SA-Co/VEval: Video-Benchmark mit 3 Domänen (SA-V, YT-Temporal-1B, SmartGlasses)
Link to this sectionInnovationen der Daten-Engine#
Die skalierbare Human- und Model-in-the-Loop-Daten-Engine von SAM 3 erreicht einen 2-fachen Annotationsdurchsatz durch:
- KI-Annotatoren: Auf Llama basierende Modelle schlagen vielfältige Substantivphrasen vor, einschließlich harter Negativbeispiele
- KI-Verifizierer: Feinabgestimmte multimodale LLMs verifizieren die Maskenqualität und Vollständigkeit bei nahezu menschlicher Leistung
- Aktives Mining: Konzentriert menschliche Arbeit auf schwierige Fehlerfälle, bei denen die KI Probleme hat
- Ontologie-getrieben: Nutzt eine große Ontologie, die in Wikidata für die Konzeptabdeckung verankert ist
Link to this sectionInstallation#
SAM 3 ist in Ultralytics Version 8.3.237 und später verfügbar. Installiere oder aktualisiere mit:
pip install -U ultralyticsIm Gegensatz zu anderen Ultralytics-Modellen werden SAM 3-Gewichte (sam3.pt) nicht automatisch heruntergeladen. Du musst zuerst Zugriff auf die Modellgewichte auf der SAM 3 Modellseite auf Hugging Face anfordern und dann, nach Genehmigung, sam3.pt von dieser Seite herunterladen. Platziere die heruntergeladene sam3.pt Datei in deinem Arbeitsverzeichnis oder gib den vollständigen Pfad beim Laden des Modells an.
Wenn du während der Vorhersage den obigen Fehler erhältst, bedeutet dies, dass du das falsche clip-Paket installiert hast. Installiere das korrekte clip-Paket, indem du Folgendes ausführst:
pip uninstall clip -y
pip install git+https://github.com/ultralytics/CLIP.gitLink to this sectionWie man SAM 3 verwendet: Vielseitigkeit bei der Konzept-Segmentierung#
SAM 3 unterstützt sowohl Promptable Concept Segmentation (PCS) als auch Promptable Visual Segmentation (PVS) Aufgaben über verschiedene Prädiktor-Schnittstellen:
Link to this sectionUnterstützte Aufgaben und Modelle#
| Aufgabentyp | Prompt-Typen | Ausgabe |
|---|---|---|
| Konzept-Segmentierung (PCS) | Text (Substantivphrasen), Bildbeispiele | Alle Instanzen, die dem Konzept entsprechen |
| Visuelle Segmentierung (PVS) | Punkte, Boxen, Masken | Einzelne Objektinstanz (SAM 2 Stil) |
| Interaktive Verfeinerung | Beispiele oder Klicks iterativ hinzufügen/entfernen | Verfeinerte Segmentierung mit verbesserter Genauigkeit |
Link to this sectionBeispiele zur Konzept-Segmentierung#
Link to this sectionSegmentieren mit Text-Prompts#
Finde und segmentiere alle Instanzen eines Konzepts mithilfe einer Textbeschreibung. Text-Prompts erfordern die SAM3SemanticPredictor-Schnittstelle.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor with configuration
overrides = dict(
conf=0.25,
task="segment",
mode="predict",
model="sam3.pt",
quantize=16, # Use FP16 for faster inference
save=True,
)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image once for multiple queries
predictor.set_image("path/to/image.jpg")
# Query with multiple text prompts
results = predictor(text=["person", "bus", "glasses"])
# Works with descriptive phrases
results = predictor(text=["person with red cloth", "person with blue cloth"])
# Query with a single concept
results = predictor(text=["a person"])Link to this sectionSegmentierung mit Bildbeispielen#
Verwende Bounding Boxen als visuelle Prompts, um alle ähnlichen Instanzen zu finden. Dies erfordert ebenfalls SAM3SemanticPredictor für den konzeptbasierten Abgleich.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16, save=True)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image
predictor.set_image("path/to/image.jpg")
# Provide bounding box examples to segment similar objects
results = predictor(bboxes=[[480.0, 290.0, 590.0, 650.0]])
# Multiple bounding boxes as exemplars of the same visual concept
results = predictor(bboxes=[[539, 599, 589, 639], [343, 267, 499, 662]])Link to this sectionMerkmalsbasierte Inferenz für Effizienz#
Extrahiere Bildmerkmale einmal und verwende sie für mehrere Segmentierungsabfragen wieder, um die Effizienz zu verbessern.
import cv2
from ultralytics.models.sam import SAM3SemanticPredictor
from ultralytics.utils.plotting import Annotator, colors
# Initialize predictors
overrides = dict(conf=0.50, task="segment", mode="predict", model="sam3.pt", verbose=False)
predictor = SAM3SemanticPredictor(overrides=overrides)
predictor2 = SAM3SemanticPredictor(overrides=overrides)
# Extract features from the first predictor
source = "path/to/image.jpg"
predictor.set_image(source)
src_shape = cv2.imread(source).shape[:2]
# Setup second predictor and reuse features
predictor2.setup_model()
# Perform inference using shared features with text prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, text=["person"])
# Perform inference using shared features with bounding box prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, bboxes=[[439, 437, 524, 709]])
# Visualize results
if masks is not None:
masks, boxes = masks.cpu().numpy(), boxes.cpu().numpy()
im = cv2.imread(source)
annotator = Annotator(im, pil=False)
annotator.masks(masks, [colors(x, True) for x in range(len(masks))])
cv2.imshow("result", annotator.result())
cv2.waitKey(0)Link to this sectionVideokonzept-Segmentierung#
Link to this sectionKonzepte über Videos hinweg mit Bounding Boxen verfolgen#
Erkenne und verfolge Objektinstanzen über Videobilder hinweg mithilfe von Bounding Box-Prompts.
from ultralytics.models.sam import SAM3VideoPredictor
# Create video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16)
predictor = SAM3VideoPredictor(overrides=overrides)
# Track objects using bounding box prompts
results = predictor(source="path/to/video.mp4", bboxes=[[706.5, 442.5, 905.25, 555], [598, 635, 725, 750]], stream=True)
# Process and display results
for r in results:
r.show() # Display frame with segmentation masksLink to this sectionKonzepte mit Text-Prompts verfolgen#
Verfolge alle Instanzen von Konzepten, die durch Text spezifiziert wurden, über Videobilder hinweg.
from ultralytics.models.sam import SAM3VideoSemanticPredictor
# Initialize semantic video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=640, model="sam3.pt", quantize=16, save=True)
predictor = SAM3VideoSemanticPredictor(overrides=overrides)
# Track concepts using text prompts
results = predictor(source="path/to/video.mp4", text=["person", "bicycle"], stream=True)
# Process results
for r in results:
r.show() # Display frame with tracked objects
# Alternative: Track with bounding box prompts
results = predictor(
source="path/to/video.mp4",
bboxes=[[864, 383, 975, 620], [705, 229, 782, 402]],
labels=[1, 1], # Positive labels
stream=True,
)Link to this sectionVisuelle Prompts (SAM 2-Kompatibilität)#
SAM 3 behält die vollständige Abwärtskompatibilität zur visuellen Prompting-Funktion von SAM 2 für die Segmentierung einzelner Objekte bei:
Die grundlegende SAM-Schnittstelle verhält sich exakt wie SAM 2 und segmentiert nur den spezifischen Bereich, der durch visuelle Prompts (Punkte, Boxen oder Masken) angegeben wird.
from ultralytics import SAM
model = SAM("sam3.pt")
# Single point prompt - segments object at specific location
results = model.predict(source="path/to/image.jpg", points=[900, 370], labels=[1])
results[0].show()
# Multiple points - segments single object with multiple point hints
results = model.predict(source="path/to/image.jpg", points=[[400, 370], [900, 370]], labels=[1, 1])
# Box prompt - segments object within bounding box
results = model.predict(source="path/to/image.jpg", bboxes=[100, 150, 300, 400])
results[0].show()Die Verwendung von SAM("sam3.pt") mit visuellen Prompts (Punkte/Boxen/Masken) segmentiert nur das spezifische Objekt an dieser Position, genau wie SAM 2. Um alle Instanzen eines Konzepts zu segmentieren, verwende SAM3SemanticPredictor mit Text- oder Beispiel-Prompts, wie oben gezeigt.
Link to this sectionPerformance-Benchmarks#
Link to this sectionBildsegmentierung#
SAM 3 erzielt branchenführende Ergebnisse in verschiedenen Benchmarks, einschließlich realer Datensätze wie LVIS und COCO für Segmentierung:
| Benchmark | Metrik | SAM 3 | Bisheriges Bestwert | Verbesserung |
|---|---|---|---|---|
| LVIS (Zero-Shot) | Mask AP | 47.0 | 38,5 | +22,1% |
| SA-Co/Gold | CGF1 | 65,0 | 34,3 (OWLv2) | +89,5% |
| COCO (Zero-Shot) | Box AP | 53,5 | 52,2 (T-Rex2) | +2,5% |
| ADE-847 (semantische Seg.) | mIoU | 14,7 | 9,2 (APE-D) | +59,8% |
| PascalConcept-59 | mIoU | 59,4 | 58,5 (APE-D) | +1,5% |
| Cityscapes (semantische Seg.) | mIoU | 65,1 | 44,2 (APE-D) | +47,3% |
Entdecke Datensatzoptionen für schnelle Experimente in Ultralytics-Datensätzen.
Link to this sectionLeistung bei der Videosegmentierung#
SAM 3 zeigt signifikante Verbesserungen gegenüber SAM 2 und dem bisherigen Stand der Technik in Video-Benchmarks wie DAVIS 2017 und YouTube-VOS:
| Benchmark | Metrik | SAM 3 | SAM 2.1 L | Verbesserung |
|---|---|---|---|---|
| MOSEv2 | J&F | 60,1 | 47,9 | +25,5% |
| DAVIS 2017 | J&F | 92,0 | 90,7 | +1,4% |
| LVOSv2 | J&F | 88,2 | 79,6 | +10,8% |
| SA-V | J&F | 84,6 | 78,4 | +7,9% |
| YTVOS19 | J&F | 89,6 | 89,3 | +0,3% |
Link to this sectionFew-Shot-Adaptation#
SAM 3 zeichnet sich durch die Anpassung an neue Domänen mit minimalen Beispielen aus, was für datenzentrierte KI-Workflows relevant ist:
| Benchmark | 0-Shot AP | 10-Shot AP | Bisheriges Bestwert (10-Shot) |
|---|---|---|---|
| ODinW13 | 59.9 | 71,6 | 67,9 (gDino1.5-Pro) |
| RF100-VL | 14.3 | 35,7 | 33,7 (gDino-T) |
Link to this sectionEffektivität der interaktiven Verfeinerung#
Das konzeptbasierte Prompting von SAM 3 mit Beispielen konvergiert deutlich schneller als visuelles Prompting:
| Hinzugefügte Prompts | CGF1-Score | Gewinn vs. nur Text | Gewinn vs. PVS-Baseline |
|---|---|---|---|
| Nur Text | 46,4 | Baseline | Baseline |
| +1 Beispiel | 57,6 | +11,2 | +6,7 |
| +2 Beispiele | 62.2 | +15.8 | +9.7 |
| +3 Exemplare | 65,0 | +18.6 | +11.2 |
| +4 Exemplare | 65.7 | +19.3 | +11.5 (Plateau) |
Link to this sectionGenauigkeit der Objektzählung#
SAM 3 ermöglicht eine präzise Zählung durch Segmentierung aller Instanzen, eine gängige Anforderung bei der Objektzählung:
| Benchmark | Genauigkeit | MAE | vs. bestes MLLM |
|---|---|---|---|
| CountBench | 95,6 % | 0,11 | 92,4 % (Gemini 2.5) |
| PixMo-Count | 87,3 % | 0,22 | 88,8 % (Molmo-72B) |
Link to this sectionVergleich: SAM 3 vs. SAM 2 vs. YOLO#
Hier vergleichen wir die Fähigkeiten von SAM 3 mit SAM 2 und YOLO26-Modellen:
| Fähigkeit | SAM 3 | SAM 2 | YOLO26n-seg |
|---|---|---|---|
| Konzeptsegmentierung | ✅ Alle Instanzen aus Text/Exemplaren | ❌ Nicht unterstützt | ❌ Nicht unterstützt |
| Visuelle Segmentierung | ✅ Einzelinstanz (SAM 2-kompatibel) | ✅ Einzelinstanz | ✅ Alle Instanzen |
| Zero-Shot-Fähigkeit | ✅ Offenes Vokabular | ✅ Geometrische Prompts | ❌ Geschlossenes Set |
| Interaktive Verfeinerung | ✅ Exemplare + Klicks | ✅ Nur Klicks | ❌ Nicht unterstützt |
| Video-Tracking | ✅ Multi-Objekt mit Identitäten | ✅ Multi-Objekt | ✅ Multi-Objekt |
| LVIS Mask AP (Zero-Shot) | 47.0 | N/A | N/A |
| MOSEv2 J&F | 60,1 | 47,9 | N/A |
| Geschwindigkeit (GPU, ms/Bild) | 2921 | 857 | 8.4 |
| Modellgröße | 3.45 GB | 162 MB (Basis) | 6,4 MB |
Geschwindigkeit gemessen auf NVIDIA RTX PRO 6000 mit torch==2.9.1 und ultralytics==8.4.19.
Wichtige Erkenntnisse:
- SAM 3: Am besten geeignet für die Konzeptsegmentierung mit offenem Vokabular; findet alle Instanzen eines Konzepts anhand von Text- oder Exemplar-Prompts.
- SAM 2: Am besten geeignet für die interaktive Einzelobjektsegmentierung in Bildern und Videos mit geometrischen Prompts.
- YOLO26: Am besten geeignet für Echtzeit-Hochgeschwindigkeitssegmentierung mit NMS-freier End-to-End-Inferenz, exportierbar in viele Formate für die Bereitstellung auf GPUs, CPUs und Edge-Geräten.
Link to this sectionSAM-Vergleich vs. YOLO#
Vergleich von SAM 3, SAM 2, SAM, MobileSAM und FastSAM mit Ultralytics YOLO-Segmentierungsmodellen (YOLOv8, YOLO11, YOLO26) hinsichtlich Größe, Parametern und GPU-Inferenzgeschwindigkeit:
| Modell | Größe (MB) | Parameter (M) | Geschwindigkeit (GPU) (ms/Bild) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 1306 |
| Meta SAM2-b | 162 | 80.8 | 857 |
| Meta SAM2-t | 78.1 | 38.9 | 668 |
| Meta SAM3 | 3450 | 473.6 | 2921 |
| MobileSAM | 40.7 | 10.1 | 605 |
| FastSAM-s mit YOLOv8 backbone | 23.7 | 11.8 | 55,9 |
| Ultralytics YOLOv8n-seg | 6.7 (515x kleiner) | 3.4 (139.1x weniger) | 17.4 (167x schneller) |
| Ultralytics YOLO11n-seg | 5.9 (585x kleiner) | 2.9 (163.1x weniger) | 12.6 (231x schneller) |
| Ultralytics YOLO26n-seg | 6.4 (539x kleiner) | 2.7 (175.2x weniger) | 8.4 (347x schneller) |
Dieser Vergleich demonstriert die erheblichen Unterschiede in Modellgrößen und Geschwindigkeiten zwischen SAM-Varianten und YOLO-Segmentierungsmodellen. Während SAM einzigartige automatische Segmentierungsfunktionen bietet, sind YOLO-Modelle, insbesondere YOLOv8n-seg, YOLO11n-seg und YOLO26n-seg, deutlich kleiner, schneller und recheneffizienter.
Tests durchgeführt auf einer NVIDIA RTX PRO 6000 mit 96 GB VRAM unter Verwendung von torch==2.9.1 und ultralytics==8.4.19. So reproduzierst du diesen Test:
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# Profile SAM3, SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt", "sam3.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# Profile FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# Profile YOLO models
for file_name in ["yolov8n-seg.pt", "yolo11n-seg.pt", "yolo26n-seg.pt"]:
model = YOLO(file_name)
model.info()
model(ASSETS)Link to this sectionBewertungsmetriken#
SAM 3 führt neue Metriken für die PCS-Aufgabe ein, die vertraute Maße wie F1-Score, Präzision und Recall ergänzen.
Link to this sectionClassification-Gated F1 (CGF1)#
Die primäre Metrik zur Kombination von Lokalisierung und Klassifizierung:
CGF1 = 100 × pmF1 × IL_MCC
Wobei:
- pmF1 (Positive Macro F1): Misst die Lokalisierungsqualität bei positiven Beispielen.
- IL_MCC (Image-Level Matthews Correlation Coefficient): Misst die Genauigkeit der binären Klassifizierung ("Ist das Konzept vorhanden?").
Link to this sectionWarum diese Metriken?#
Herkömmliche AP-Metriken berücksichtigen keine Kalibrierung, was den praktischen Einsatz von Modellen erschwert. Durch die ausschließliche Bewertung von Vorhersagen mit einer Konfidenz über 0,5 erzwingen die Metriken von SAM 3 eine gute Kalibrierung und imitieren reale Nutzungsmuster in interaktiven Predict- und Track-Schleifen.
Link to this sectionWichtige Ablationen und Erkenntnisse#
Link to this sectionAuswirkung des Presence-Heads#
Der Presence-Head entkoppelt Erkennung von Lokalisierung und sorgt für signifikante Verbesserungen:
| Konfiguration | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Ohne Presence | 57,6 | 0.77 | 74.7 |
| Mit Presence | 63.3 | 0.82 | 77.1 |
Der Presence-Head liefert einen +5.7 CGF1-Schub (+9,9 %) und verbessert vor allem die Erkennungsfähigkeit (IL_MCC +6,5 %).
Link to this sectionAuswirkung von Hard Negatives#
| Hard Negatives/Bild | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 0 | 31.8 | 0.44 | 70.2 |
| 5 | 44.8 | 0.62 | 71.9 |
| 30 | 49.2 | 0.68 | 72.3 |
Harte Negative sind entscheidend für die Open-Vocabulary-Erkennung und verbessern IL_MCC um 54.5% (0.44 → 0.68).
Link to this sectionSkalierung der Trainingsdaten#
| Datenquellen | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Nur extern | 30.9 | 0.46 | 66.3 |
| Extern + synthetisch | 39.7 | 0.57 | 70.6 |
| Extern + HQ | 51.8 | 0.71 | 73.2 |
| Alle drei | 54.3 | 0.74 | 73.5 |
Hochwertige menschliche Annotationen bieten große Vorteile gegenüber rein synthetischen oder externen Daten. Hintergrundinformationen zu Datenqualitätspraktiken findest du unter Datenerfassung und Annotation.
Link to this sectionAnwendungen#
Die Konzept-Segmentierungsfunktion von SAM 3 ermöglicht neue Anwendungsfälle:
- Content-Moderation: Finde alle Instanzen spezifischer Inhaltstypen in Medienbibliotheken
- E-Commerce: Segmentiere alle Produkte eines bestimmten Typs in Katalogbildern und unterstütze auto-annotation
- Medizinische Bildgebung: Identifiziere alle Vorkommen spezifischer Gewebetypen oder Anomalien
- Autonome Systeme: Verfolge alle Instanzen von Verkehrsschildern, Fußgängern oder Fahrzeugen nach Kategorie
- Videoanalyse: Zähle und verfolge alle Personen, die bestimmte Kleidung tragen oder Aktionen ausführen
- Dataset-Annotation: Annotiere schnell alle Instanzen seltener Objektkategorien
- Wissenschaftliche Forschung: Quantifiziere und analysiere alle Proben, die spezifische Kriterien erfüllen
Link to this sectionSAM 3 Agent: Erweiterte Sprachlogik#
SAM 3 kann mit multimodalen großen Sprachmodellen (MLLMs) kombiniert werden, um komplexe Anfragen zu verarbeiten, die logisches Denken erfordern – ähnlich wie bei Open-Vocabulary-Systemen wie OWLv2 und T-Rex.
Link to this sectionLeistung bei logischen Aufgaben#
| Benchmark | Metrik | SAM 3 Agent (Gemini 2.5 Pro) | Bisheriges Bestwert |
|---|---|---|---|
| ReasonSeg (Validierung) | gIoU | 76.0 | 65.0 (SoTA) |
| ReasonSeg (Test) | gIoU | 73.8 | 61.3 (SoTA) |
| OmniLabel (Validierung) | AP | 46.7 | 36.5 (REAL) |
| RefCOCO+ | Acc | 91.2 | 89.3 (LISA) |
Link to this sectionBeispiele für komplexe Anfragen#
Der SAM 3 Agent kann Anfragen bearbeiten, die logisches Denken erfordern:
- "Personen, die sitzen, aber kein Geschenkpaket in den Händen halten"
- "Der Hund, der der Kamera am nächsten ist und kein Halsband trägt"
- "Rote Objekte, die größer als die Hand der Person sind"
Das MLLM schlägt SAM 3 einfache Substantivgruppen-Anfragen vor, analysiert die zurückgegebenen Masken und iteriert, bis das Ergebnis zufriedenstellend ist.
Link to this sectionEinschränkungen#
Obwohl SAM 3 einen bedeutenden Fortschritt darstellt, weist es gewisse Einschränkungen auf:
- Komplexität von Phrasen: Am besten für einfache Substantivgruppen geeignet; lange Bezugsausdrücke oder komplexe logische Zusammenhänge erfordern möglicherweise eine MLLM-Integration
- Umgang mit Mehrdeutigkeit: Einige Konzepte bleiben von Natur aus mehrdeutig (z. B. "kleines Fenster", "gemütlicher Raum")
- Rechenanforderungen: Größer und langsamer als spezialisierte Erkennungsmodelle wie YOLO
- Umfang des Vokabulars: Fokus auf atomare visuelle Konzepte; kompositorisches Denken ist ohne MLLM-Unterstützung begrenzt
- Seltene Konzepte: Die Leistung kann bei extrem seltenen oder sehr spezifischen Konzepten nachlassen, die in den Trainingsdaten nicht gut repräsentiert sind
Link to this sectionZitierung#
@inproceedings{sam3_2025,
title = {SAM 3: Segment Anything with Concepts},
author = {Anonymous authors},
booktitle = {Submitted to ICLR 2026},
year = {2025},
url = {https://openreview.net/forum?id=r35clVtGzw},
note = {Paper ID: 4183, under double-blind review}
}Link to this sectionFAQ#
Link to this sectionWann wurde SAM 3 veröffentlicht?#
SAM 3 wurde von Meta am 20. November 2025 veröffentlicht und ist ab Version 8.3.237 vollständig in Ultralytics integriert (PR #22897). Volle Unterstützung ist für den Predict-Modus und den Track-Modus verfügbar.
Link to this sectionIst SAM 3 in Ultralytics integriert?#
Ja! SAM 3 ist vollständig in das Ultralytics Python-Paket integriert, einschließlich Konzeptsegmentierung, visuellen Prompts im SAM 2-Stil und Video-Tracking von mehreren Objekten. SAM 3 unterstützt auch die Funktion Smart Annotation auf der Ultralytics Platform, mit der du Bilder mit nur wenigen Klicks annotieren kannst.
Link to this sectionWas ist Promptable Concept Segmentation (PCS)?#
PCS ist eine neue Aufgabe, die mit SAM 3 eingeführt wurde und alle Instanzen eines visuellen Konzepts in einem Bild oder Video segmentiert. Im Gegensatz zur traditionellen Segmentierung, die auf eine spezifische Objektinstanz abzielt, findet PCS jedes Vorkommen einer Kategorie. Zum Beispiel:
- Text-Prompt: "gelber Schulbus" → segmentiert alle gelben Schulbusse in der Szene
- Bild-Beispiel: Rahmen um einen Hund → segmentiert alle Hunde im Bild
- Kombiniert: "gestreifte Katze" + Beispiel-Rahmen → segmentiert alle gestreiften Katzen, die dem Beispiel entsprechen
Siehe Hintergrundinformationen zu Objekterkennung und Instanzsegmentierung.
Link to this sectionWie unterscheidet sich SAM 3 von SAM 2?#
| Funktion | SAM 2 | SAM 3 |
|---|---|---|
| Aufgabe | Ein Objekt pro Prompt | Alle Instanzen eines Konzepts |
| Prompt-Typen | Punkte, Boxen, Masken | + Textphrasen, Bildbeispiele |
| Erkennungsfähigkeit | Erfordert externen Detektor | Eingebauter Open-Vocabulary-Detektor |
| Erkennung | Nur geometriebasiert | Text- und visuelle Erkennung |
| Architektur | Nur Tracker | Detektor + Tracker mit Präsenz-Head |
| Zero-Shot-Leistung | Nicht zutreffend (erfordert visuelle Prompts) | 47.0 AP auf LVIS, 2× besser auf SA-Co |
| Interaktive Verfeinerung | Nur Klicks | Klicks + Beispiel-Generalisierung |
SAM 3 behält die Abwärtskompatibilität mit SAM 2 visuellen Prompts bei und fügt gleichzeitig konzeptbasierte Funktionen hinzu.
Link to this sectionWelche Datensätze werden zum Training von SAM 3 verwendet?#
SAM 3 wurde mit dem Datensatz Segment Anything with Concepts (SA-Co) trainiert:
Trainingsdaten:
- 5,2M Bilder mit 4M einzigartigen Substantivphrasen (SA-Co/HQ) – hochwertige menschliche Annotationen
- 52,5K Videos mit 24,8K einzigartigen Substantivphrasen (SA-Co/VIDEO)
- 1,4B synthetische Masken über 38M Substantivphrasen (SA-Co/SYN)
- 15 externe Datensätze, angereichert mit schwerwiegenden Negativen (SA-Co/EXT)
Benchmark-Daten:
- 214K einzigartige Konzepte über 126K Bilder/Videos
- 50× mehr Konzepte als in bestehenden Benchmarks (z. B. hat LVIS ~4K Konzepte)
- Dreifache Annotation auf SA-Co/Gold zur Messung der menschlichen Leistungsgrenzen
Dieser enorme Umfang und diese Vielfalt ermöglichen die überlegene Zero-Shot-Generalisierung von SAM 3 über Open-Vocabulary-Konzepte hinweg.
Link to this sectionWie schneidet SAM 3 im Vergleich zu YOLO26 bei der Segmentierung ab?#
SAM 3 und YOLO26 dienen unterschiedlichen Anwendungsfällen:
Vorteile von SAM 3:
- Open-Vocabulary: Segmentiert jedes Konzept per Texteingabe ohne Training
- Zero-Shot: Funktioniert sofort mit neuen Kategorien
- Interaktiv: Exemplarbasierte Verfeinerung generalisiert auf ähnliche Objekte
- Konzeptbasiert: Findet automatisch alle Instanzen einer Kategorie
- Genauigkeit: 47,0 AP bei LVIS Zero-Shot-Instanzsegmentierung
Vorteile von YOLO26:
- Geschwindigkeit: Um Größenordnungen schnellere Inferenz durch NMS-freies End-to-End-Design
- Effizienz: 539× kleinere Modelle (6,4MB vs 3,45GB)
- Ressourcenschonend: Läuft auf Edge-Geräten und Mobiltelefonen
- Echtzeit: Optimiert für Produktionseinsätze
Empfehlung:
- Nutze SAM 3 für flexible Open-Vocabulary-Segmentierung, wenn du alle Instanzen von Konzepten finden musst, die durch Text oder Beispiele beschrieben werden
- Nutze YOLO26 für High-Speed-Produktionseinsätze, bei denen die Kategorien im Voraus bekannt sind
- Nutze SAM 2 für interaktive Einzelobjektsegmentierung mit geometrischen Prompts
Link to this sectionKann SAM 3 komplexe Sprachabfragen verarbeiten?#
SAM 3 ist für einfache Substantivphrasen konzipiert (z. B. „roter Apfel“, „Person mit Hut“). Für komplexe Anfragen, die Schlussfolgerungen erfordern, kombiniere SAM 3 mit einem MLLM als SAM 3 Agent:
Einfache Abfragen (natives SAM 3):
- „gelber Schulbus“
- „gestreifte Katze“
- „Person mit rotem Hut“
Komplexe Abfragen (SAM 3 Agent mit MLLM):
- „Menschen, die sitzen, aber keine Geschenkbox halten“
- „Der Hund, der der Kamera am nächsten ist, ohne Halsband“
- "Rote Objekte, die größer als die Hand der Person sind"
Der SAM 3 Agent erreicht 76,0 gIoU bei der ReasonSeg-Validierung (vs 65,0 beim vorherigen Bestwert, +16,9 % Verbesserung), indem er die Segmentierung von SAM 3 mit den Schlussfolgerungsfähigkeiten eines MLLM kombiniert.
Link to this sectionWie genau ist SAM 3 im Vergleich zur menschlichen Leistung?#
Auf dem SA-Co/Gold-Benchmark mit dreifacher menschlicher Annotation:
- Untere menschliche Grenze: 74,2 CGF1 (konservativster Annotator)
- SAM 3 Leistung: 65,0 CGF1
- Ergebnis: 88 % der geschätzten unteren menschlichen Grenze
- Obere menschliche Grenze: 81,4 CGF1 (liberalster Annotator)
SAM 3 erzielt eine starke Leistung, die sich bei der Open-Vocabulary-Konzeptsegmentierung der Genauigkeit auf menschlichem Niveau annähert, wobei die Lücke hauptsächlich bei mehrdeutigen oder subjektiven Konzepten liegt (z. B. „kleines Fenster“, „gemütliches Zimmer“).