Link to this sectionUltralytics YOLO26#
Link to this sectionPrésentation#
Ultralytics YOLO26 est une famille unifiée de modèles de vision en temps réel décrite dans le document Ultralytics YOLO26. Il introduit une inférence native de bout en bout, une tête de détection plus légère, une méthode d'entraînement mise à jour et des têtes spécifiques aux tâches pour la détection, la segmentation, l'estimation de pose, la classification et la détection orientée.
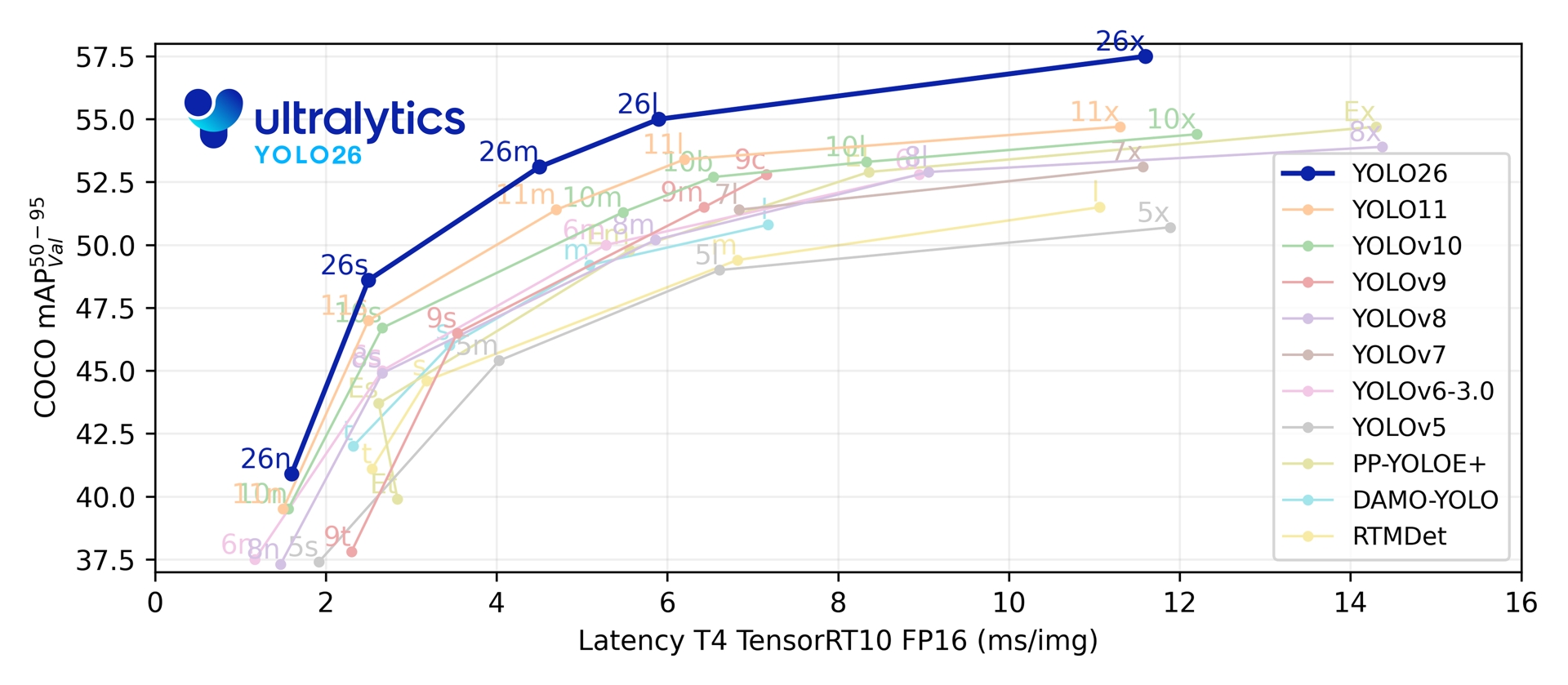
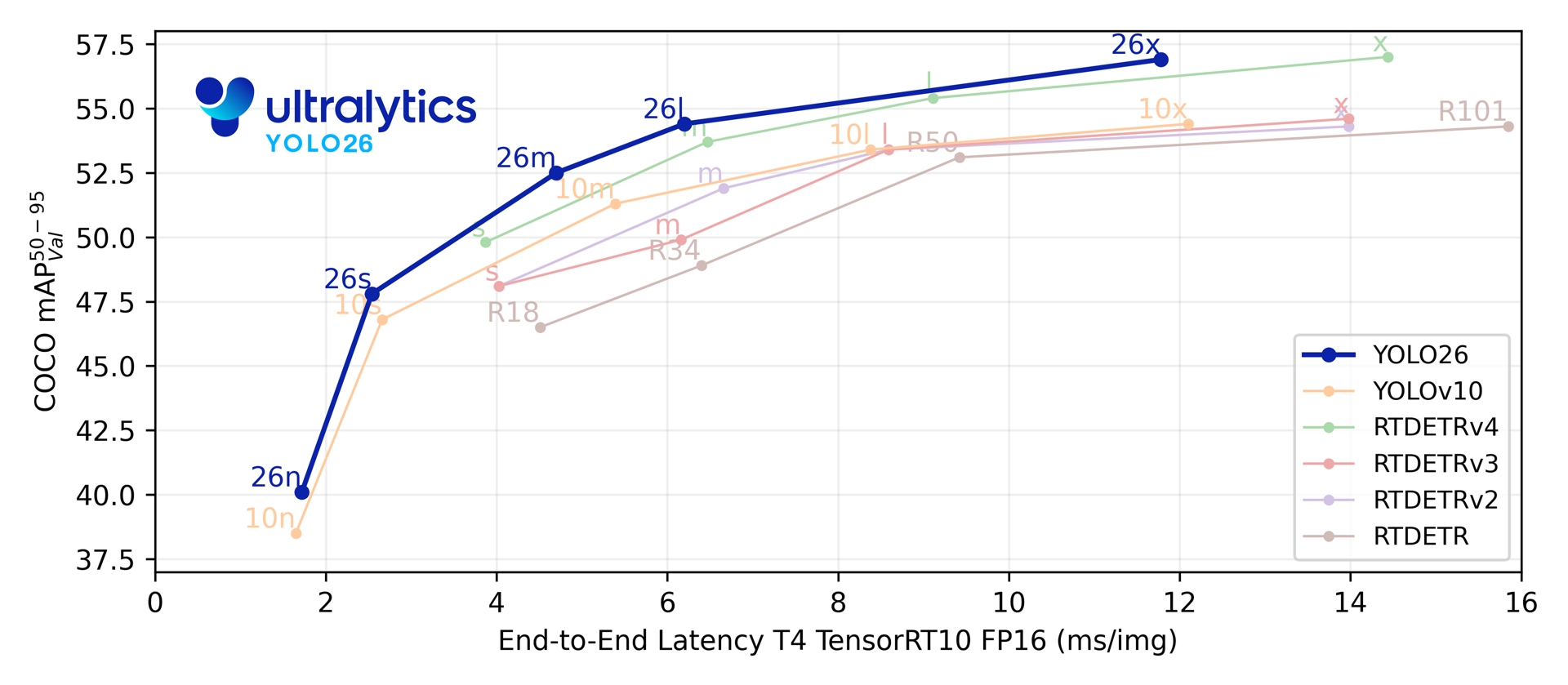
Sur ses cinq échelles de détection, YOLO26 atteint 40,9-57,5 mAP sur COCO avec une latence T4 TensorRT de 1,7-11,8 ms. Le document rapporte également jusqu'à 43 % d'inférence CPU ONNX plus rapide pour YOLO26n par rapport à YOLO11n sur un CPU Intel Xeon @ 2.00 GHz.
from ultralytics import YOLO
model = YOLO("yolo26n.pt") # load a pretrained YOLO26n model
results = model("path/to/bus.jpg") # run inferenceExplore et exécute les modèles YOLO26 directement sur Ultralytics Platform.
La famille de modèles YOLO26 est construite autour de quatre domaines de conception :
- Inférence native de bout en bout : La tête de détection par défaut un-pour-un génère des prédictions sans suppression non maximale (NMS), simplifiant le déploiement et réduisant le post-traitement.
- Régression de boîte plus légère : YOLO26 supprime la Distribution Focal Loss (DFL), réduisant la complexité de la tête de détection tout en préservant une plage de régression non contrainte.
- Mises à jour de la recette d'entraînement : Le pipeline d'entraînement combine MuSGD (un optimiseur hybride Muon + SGD), Progressive Loss et STAL (Small-Target-Aware Label Assignment) pour améliorer l'optimisation, orienter la supervision vers la tête d'inférence et maintenir une couverture d'étiquettes positives pour les petits objets. Les hyperparamètres complets utilisés pour les points de contrôle publiés sont documentés dans le guide de la recette d'entraînement YOLO26.
- Têtes et pertes spécifiques aux tâches : YOLO26 ajoute des conceptions ciblées pour la segmentation d'instance, les variantes de segmentation sémantique, l'estimation de pose et la détection orientée tout en conservant un pipeline de modèle unique pour toutes les tâches.
Ensemble, ces mises à jour améliorent le compromis précision-latence à travers les échelles de modèles et les cibles de déploiement.
Link to this sectionFonctionnalités clés#
-
Régression sans DFL YOLO26 supprime la Distribution Focal Loss (DFL), réduisant la complexité de la tête de détection et simplifiant l'exportation.
-
Inférence de bout en bout sans NMS Contrairement aux détecteurs traditionnels qui dépendent du NMS comme étape de post-traitement distincte, YOLO26 est nativement de bout en bout par défaut. Les prédictions sont générées directement, réduisant la latence et simplifiant l'intégration en production.
-
Progressive Loss + STAL Progressive Loss déplace l'accent de l'entraînement vers la tête d'inférence, tandis que STAL améliore la couverture des étiquettes positives pour les petits objets.
-
Optimiseur MuSGD Un optimiseur hybride qui combine SGD avec Muon, adaptant les idées d'optimisation issues de l'entraînement des grands modèles de langage à la vision par ordinateur.
-
Déploiement efficace La tête simplifiée et le chemin par défaut sans NMS réduisent la surcharge d'inférence sur les cibles d'exportation et les profils matériels, incluant l'accélération CPU ONNX rapportée pour YOLO26n par rapport à YOLO11n.
-
Améliorations de la segmentation d'instance Introduit une perte de segmentation sémantique pour améliorer la convergence du modèle et un module proto mis à niveau qui exploite des informations multi-échelles pour une qualité de masque supérieure. Le document rapporte des gains par rapport à YOLO11 allant jusqu'à +2,5 AP de boîte et +3,7 AP de masque sur la segmentation d'instance COCO.
-
Estimation de pose de précision Intègre l'estimation de log-vraisemblance résiduelle (RLE) pour une localisation plus précise des points clés et optimise le processus de décodage pour une vitesse d'inférence accrue. Le document rapporte jusqu'à +7,2 AP par rapport à YOLO11 sur l'estimation de pose COCO.
-
Décodage OBB raffiné Introduit une perte d'angle spécialisée pour améliorer la précision de détection des objets de forme carrée et optimise le décodage OBB pour résoudre les problèmes de discontinuité aux limites. Le document rapporte jusqu'à +3,4 mAP par rapport à YOLO11 sur la détection orientée DOTA-v1.0.
Link to this sectionTâches et modes pris en charge#
YOLO26 prend en charge l'ensemble de tâches standard d'Ultralytics sur cinq échelles de modèle :
| Modèle | Noms de fichiers | Tâche | Inférence | Validation | Entraînement | Exporter (Export) |
|---|---|---|---|---|---|---|
| YOLO26 | yolo26n.pt yolo26s.pt yolo26m.pt yolo26l.pt yolo26x.pt | Détection | ✅ | ✅ | ✅ | ✅ |
| YOLO26-seg | yolo26n-seg.pt yolo26s-seg.pt yolo26m-seg.pt yolo26l-seg.pt yolo26x-seg.pt | Segmentation d'instance | ✅ | ✅ | ✅ | ✅ |
| YOLO26-sem | yolo26n-sem.pt yolo26s-sem.pt yolo26m-sem.pt yolo26l-sem.pt yolo26x-sem.pt | Segmentation sémantique | ✅ | ✅ | ✅ | ✅ |
| YOLO26-pose | yolo26n-pose.pt yolo26s-pose.pt yolo26m-pose.pt yolo26l-pose.pt yolo26x-pose.pt | Pose/Points clés | ✅ | ✅ | ✅ | ✅ |
| YOLO26-obb | yolo26n-obb.pt yolo26s-obb.pt yolo26m-obb.pt yolo26l-obb.pt yolo26x-obb.pt | Détection orientée | ✅ | ✅ | ✅ | ✅ |
| YOLO26-cls | yolo26n-cls.pt yolo26s-cls.pt yolo26m-cls.pt yolo26l-cls.pt yolo26x-cls.pt | Classification | ✅ | ✅ | ✅ | ✅ |
Ce framework unifié couvre la détection en temps réel, la segmentation d'instance, la segmentation sémantique, la classification, l'estimation de pose et la détection d'objets orientés, avec prise en charge de l'entraînement, de la validation, de l'inférence et de l'exportation.
yolo26-p2.yaml et yolo26-p6.yaml ajoutent une tête de détection P2 (petits objets) ou P6 (entrée large) et sont livrés uniquement sous forme d'architectures YAML. Aucun poids spécifique à l'échelle yolo26*-p2.pt ou yolo26*-p6.pt n'est publié. Instancie une configuration mise à l'échelle à partir du YAML (par exemple, YOLO("yolo26n-p6.yaml")) et entraîne-la ou ajuste-la selon tes besoins.
Link to this sectionMétriques de performance#
Consulte les Docs de détection pour des exemples d'utilisation avec ces modèles entraînés sur COCO, qui incluent 80 classes pré-entraînées.
| Modèle | taille (pixels) | mAPval 50-95 | mAPval 50-95(e2e) | Vitesse CPU ONNX (ms) | Vitesse T4 TensorRT10 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO26n | 640 | 40,9 | 40,1 | 38,9 ± 0,7 | 1,7 ± 0,0 | 2,4 | 5,4 |
| YOLO26s | 640 | 48,6 | 47,8 | 87,2 ± 0,9 | 2,5 ± 0,0 | 9,5 | 20,7 |
| YOLO26m | 640 | 53,1 | 52,5 | 220,0 ± 1,4 | 4,7 ± 0,1 | 20,4 | 68,2 |
| YOLO26l | 640 | 55,0 | 54,4 | 286,2 ± 2,0 | 6,2 ± 0,2 | 24,8 | 86,4 |
| YOLO26x | 640 | 57,5 | 56,9 | 525,8 ± 4,0 | 11,8 ± 0,2 | 55,7 | 193,9 |
Les valeurs de paramètres et de FLOPs concernent le modèle fusionné après model.fuse(), qui combine les couches Conv et BatchNorm et supprime la tête de détection auxiliaire one-to-many. Les checkpoints pré-entraînés conservent l'architecture d'entraînement complète et peuvent afficher des nombres plus élevés.
Link to this sectionExemples d'utilisation#
Cette section fournit des exemples simples d'entraînement et d'inférence avec YOLO26. Pour une documentation complète sur ces modes et d'autres, consulte les pages de documentation Predict, Train, Val et Export.
Note que l'exemple ci-dessous concerne les modèles YOLO26 Detect pour la détection d'objets. Pour des tâches supplémentaires prises en charge, consulte la documentation Segment, Semantic Segmentation, Classify, OBB et Pose.
Les modèles pré-entraînés PyTorch *.pt ainsi que les fichiers de configuration *.yaml peuvent être transmis à la classe YOLO() pour créer une instance de modèle en Python :
from ultralytics import YOLO
# Load a COCO-pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Run inference with the YOLO26n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)Les modèles de détection YOLO26 utilisent une architecture à double tête qui offre de la flexibilité pour différents scénarios de déploiement :
- Tête One-to-One (par défaut) : Produit des prédictions de bout en bout sans NMS, sortant
(N, 300, 6)avec un maximum de 300 détections par image. Cette tête est optimisée pour une inférence rapide et un déploiement simplifié. - Tête One-to-Many : Génère des sorties YOLO traditionnelles nécessitant un post-traitement NMS, sortant
(N, nc + 4, 8400)oùncest le nombre de classes. Cette tête atteint généralement une précision légèrement supérieure au prix d'un traitement supplémentaire.
Tu peux basculer entre les têtes lors de l'exportation, de la prédiction ou de la validation :
from ultralytics import YOLO
model = YOLO("yolo26n.pt")
# Use one-to-one head (default, no NMS required)
results = model.predict("image.jpg") # inference
metrics = model.val(data="coco.yaml") # validation
model.export(format="onnx") # export
# Use one-to-many head (requires NMS)
results = model.predict("image.jpg", end2end=False) # inference
metrics = model.val(data="coco.yaml", end2end=False) # validation
model.export(format="onnx", end2end=False) # exportLe choix dépend de tes exigences de déploiement : utilise la tête one-to-one pour une vitesse et une simplicité maximales, ou la tête one-to-many lorsque la précision est la priorité absolue.
Link to this sectionYOLOE-26 : Détection et segmentation à vocabulaire ouvert#
YOLO26 alimente également YOLOE-26, une variante à vocabulaire ouvert qui détecte et segmente des catégories d'objets à partir de prompts textuels, de prompts visuels ou d'un mode sans prompt au lieu d'une liste de classes fixe apprise lors de l'entraînement. YOLOE-26 conserve la conception end-to-end (e2e) sans NMS de YOLO26, de sorte que l'inférence à vocabulaire ouvert reste assez rapide pour les environnements dynamiques où les catégories cibles changent au fil du temps. YOLOE-26x atteint 40,6 AP sur LVIS minival avec des prompts textuels, 38,5 AP avec des prompts visuels et 31,1 AP dans le paramétrage sans prompt Non-E2E.
Consulte la documentation YOLOE pour les tableaux de performance par échelle, les variantes sans prompt et des exemples d'utilisation complets.
Link to this sectionCitations et remerciements#
Pour une description technique complète de l'architecture YOLO26, de la recette d'entraînement, des têtes de tâches et de l'extension open-vocabulary YOLOE-26, lis Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models. Si tu utilises YOLO26 dans tes recherches, merci de citer :
@misc{jocher2026ultralyticsyolo26unifiedrealtime,
title = {Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models},
author = {Glenn Jocher and Jing Qiu and Mengyu Liu and Shuai Lyu and Fatih Cagatay Akyon and Muhammet Esat Kalfaoglu},
year = {2026},
eprint = {2606.03748},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
doi = {10.48550/arXiv.2606.03748},
url = {https://arxiv.org/abs/2606.03748},
}Le code, les modèles et la documentation de YOLO26 sont disponibles dans le dépôt GitHub d'Ultralytics et dans les Docs d'Ultralytics sous les licences AGPL-3.0 et Enterprise.
Link to this sectionFAQ#
Link to this sectionQuelles sont les principales améliorations de YOLO26 ?#
- Régression sans DFL : Simplifie la tête de détection et le chemin d'exportation
- Inférence end-to-end sans NMS : Supprime la NMS du chemin d'inférence par défaut
- Perte progressive + STAL : Améliore l'alignement de l'entraînement et la couverture des étiquettes pour les petits objets
- Optimiseur MuSGD : Combine SGD avec une optimisation inspirée de Muon pour un entraînement stable
- Têtes et pertes spécifiques aux tâches : Améliore la segmentation, la pose et la prise en charge de la détection orientée
Link to this sectionQuelles tâches YOLO26 prend-il en charge ?#
YOLO26 est une famille de modèles unifiée, offrant une prise en charge end-to-end pour plusieurs tâches de vision par ordinateur :
- Détection d'objets
- Segmentation d'instance
- Segmentation sémantique
- Classification d'images
- Estimation de pose
- Détection d'objets orientés (OBB)
Chaque variante de taille (n, s, m, l, x) prend en charge toutes les tâches, ainsi que les versions à vocabulaire ouvert via YOLOE-26.
Link to this sectionPourquoi YOLO26 est-il efficace pour le déploiement ?#
YOLO26 améliore l'efficacité du déploiement grâce à :
- Inférence native de bout en bout sans NMS par défaut
- Régression sans DFL et une tête de détection plus légère
- Exportation de modèle fusionné qui supprime les composants auxiliaires réservés à l'entraînement
- Jusqu'à 43 % plus rapide pour l'inférence CPU ONNX avec YOLO26n par rapport à YOLO11n sur un CPU Intel Xeon @ 2.00 GHz
- Des formats d'exportation flexibles incluant TensorRT, ONNX, CoreML, LiteRT et OpenVINO
Link to this sectionComment démarrer avec YOLO26 ?#
Les modèles YOLO26 sont disponibles en téléchargement via le package ultralytics. Installe ou mets à jour le package et charge un modèle :
from ultralytics import YOLO
# Load a pretrained YOLO26 nano model
model = YOLO("yolo26n.pt")
# Run inference on an image
results = model("image.jpg")Consulte la section Usage Examples pour les instructions d'entraînement, de validation et d'exportation.