Link to this sectionSAM 3: コンセプトによるセグメンテーション#
SAM 3は、version 8.3.237 (PR #22897) 以降、Ultralyticsパッケージに完全に統合されています。pip install -U ultralyticsでインストールまたはアップグレードを行うことで、テキストベースのコンセプト・セグメンテーション、画像例示プロンプト、ビデオトラッキングなど、すべてのSAM 3機能にアクセスできます。
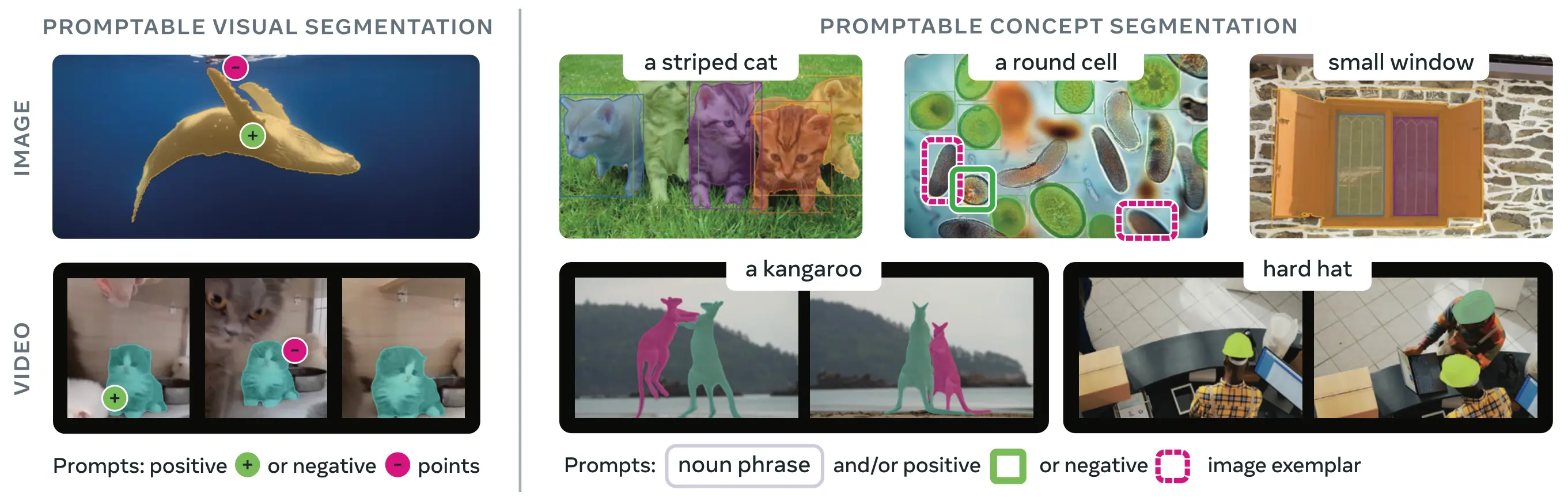
SAM 3 (Segment Anything Model 3) は、Metaが公開したプロンプト可能なコンセプト・セグメンテーション (PCS) のための基盤モデルです。SAM 2をベースに構築されたSAM 3は、テキストプロンプト、画像例示、またはその両方で指定された視覚的コンセプトのすべてのインスタンスを検出し、セグメント化し、追跡するという根本的に新しい機能を導入しました。プロンプトごとに単一のオブジェクトをセグメント化する従来のSAMバージョンとは異なり、SAM 3は画像やビデオ内のどこに現れるコンセプトでもすべての発生箇所を検索およびセグメント化でき、現代のinstance segmentationにおけるオープンボキャブラリーの目標と一致しています。
Watch: How to Use Meta Segment Anything 3 with Ultralytics | Text-Prompt Segmentation on Images & Videos
SAM 3はultralyticsパッケージに完全に統合されており、テキストプロンプト、画像例示プロンプト、ビデオトラッキング機能を用いたコンセプト・セグメンテーションをネイティブでサポートします。
Link to this section概要#
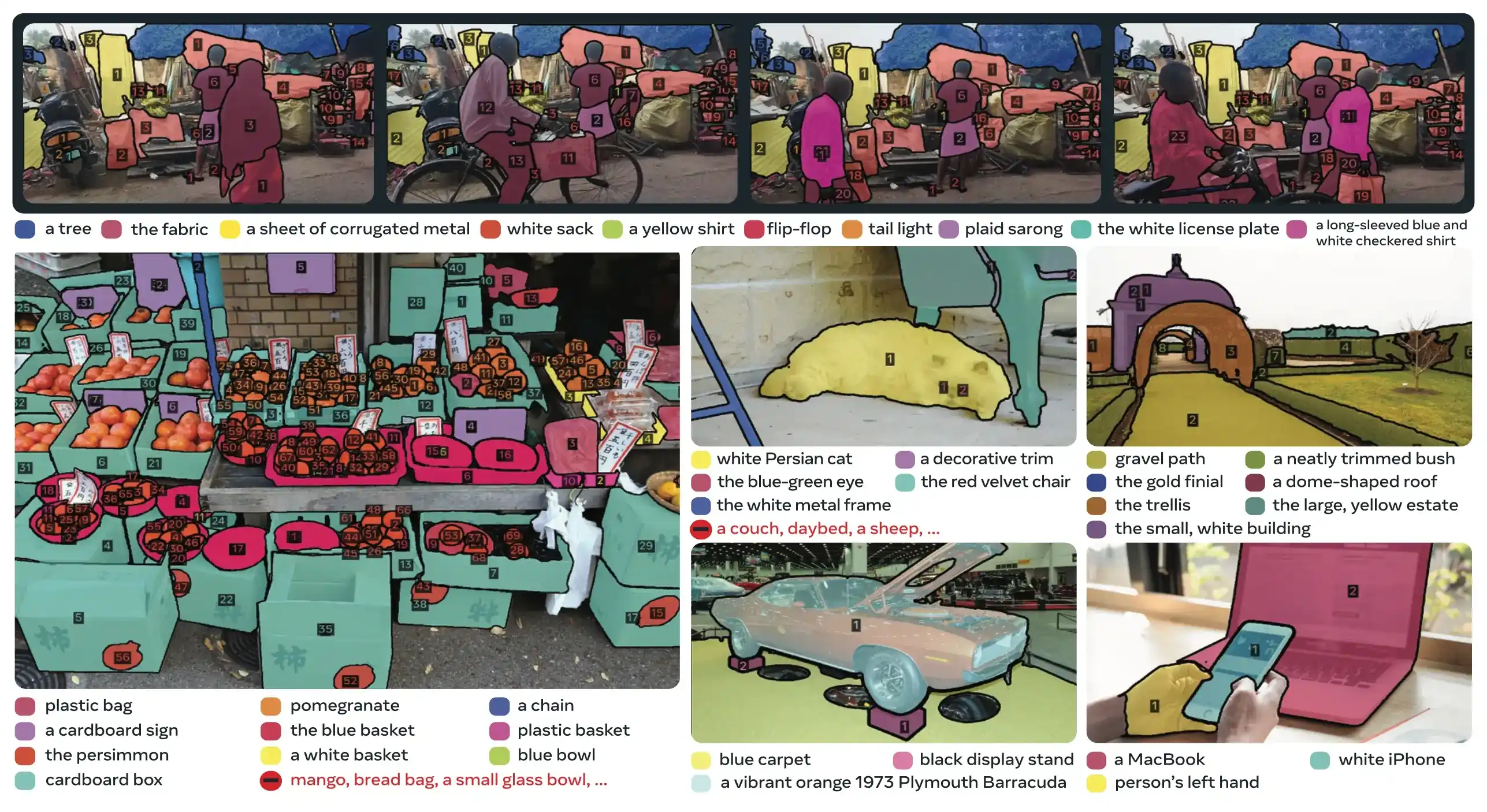
SAM 3は、プロンプト可能なコンセプト・セグメンテーションにおいて、既存システムと比較して2倍のパフォーマンス向上を達成しつつ、インタラクティブなvisual segmentationに向けたSAM 2の能力を維持・改善しています。このモデルはオープンボキャブラリー・セグメンテーションに優れており、ユーザーはシンプルな名詞句(例: 「黄色いスクールバス」、「縞模様の猫」)を使用したり、対象オブジェクトのサンプル画像を提供したりしてコンセプトを指定できます。これらの機能は、合理化されたpredictおよびtrackワークフローに依存する本番環境向けのパイプラインを補完します。
Link to this sectionプロンプト可能なコンセプト・セグメンテーション (PCS) とは?#
PCSタスクは、入力としてコンセプトプロンプトを受け取り、すべての一致するオブジェクトインスタンスに対して固有のIDを持つセグメンテーションマスクを返します。コンセプトプロンプトには以下のようなものがあります:
- テキスト: zero-shot learningと同様に、「赤いリンゴ」や「帽子を被った人」のようなシンプルな名詞句
- 画像例示: 高速な汎化のための(ポジティブまたはネガティブな)ターゲットオブジェクト周辺のバウンディングボックス
- 組み合わせ: 精密な制御のためのテキストと画像例示の両方
これは、初代SAM familyによって普及した、単一の特定のオブジェクトインスタンスのみをセグメント化する従来の視覚的プロンプト(ポイント、ボックス、マスク)とは異なります。
Link to this section主要なパフォーマンス指標#
| メトリクス | SAM 3の達成度 |
|---|---|
| LVIS ゼロショット Mask AP | 47.0 (従来最高38.5に対し、22%向上) |
| SA-Co ベンチマーク | 既存システムより2倍優れている |
| 推論速度 (H200 GPU) | 100個以上のオブジェクトを検出して画像あたり30 ms |
| ビデオパフォーマンス | 約5個の同時オブジェクトに対してほぼリアルタイム |
| MOSEv2 VOS ベンチマーク | 60.1 J&F (SAM 2.1より25.5%向上、従来のSOTAより17%向上) |
| インタラクティブな洗練 | 3つの例示プロンプト後に**+18.6 CGF1**向上 |
| 人間のパフォーマンスとの差 | SA-Co/Goldにおける推定下限の**88%**を達成 |
本番環境でのモデル指標とトレードオフに関する背景については、model evaluation insightsおよびYOLO performance metricsを参照してください。
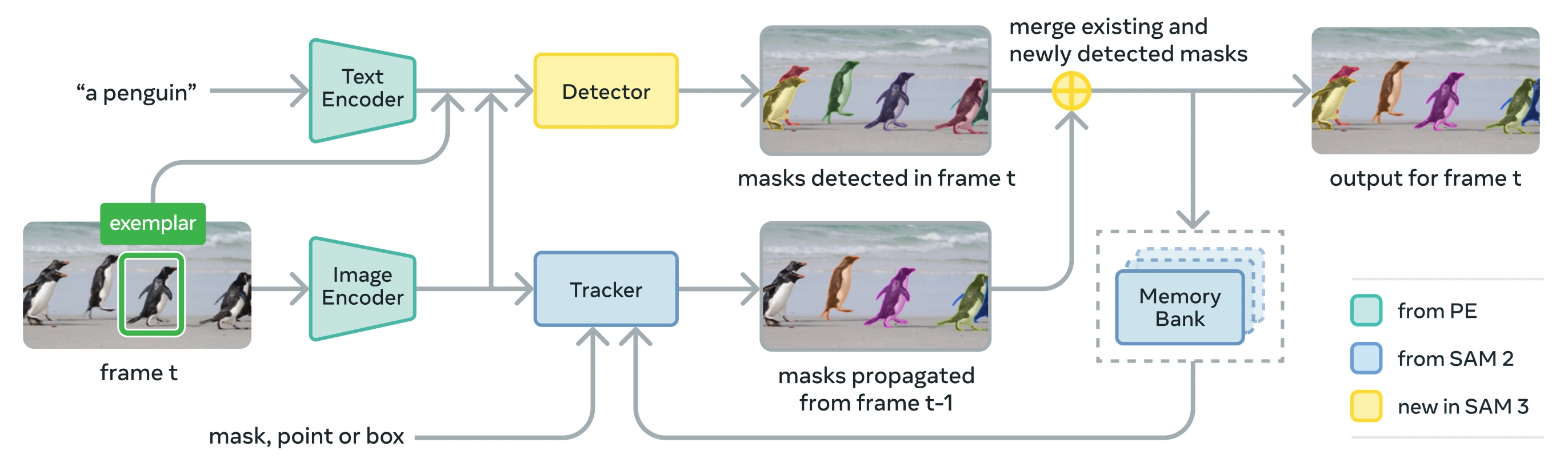
Link to this sectionアーキテクチャ#
SAM 3は、Perception Encoder (PE) ビジョンバックボーンを共有する検出器と追跡器で構成されています。このデカップルされた設計は、タスク間の競合を回避しつつ、画像レベルの検出とビデオレベルの追跡の両方を可能にし、UltralyticsのPython usageおよびCLI usageと互換性のあるインターフェースを提供します。
Link to this sectionコアコンポーネント#
-
検出器: 画像レベルのコンセプト検出のためのDETR-based architecture
- 名詞句プロンプトのためのテキストエンコーダー
- 画像ベースのプロンプトのための例示エンコーダー
- プロンプトに基づいて画像特徴量を条件付ける融合エンコーダー
- 認識(「何」)をローカライゼーション(「どこ」)から切り離す新規のプレゼンスヘッド
- インスタンス・セグメンテーションマスクを生成するためのマスクヘッド
-
追跡器: SAM 2から継承されたメモリベースのビデオセグメンテーション
- プロンプトエンコーダー、マスクデコーダー、メモリエンコーダー
- フレーム間でオブジェクトの外観を保存するためのメモリバンク
- マルチオブジェクト設定におけるKalman filterのような手法によって支援される時間的曖昧さ解消
-
プレゼンス・トークン: ターゲットコンセプトが画像/フレーム内に存在するかどうかを予測し、認識とローカライゼーションを分離することで検出を改善する学習済みグローバルトークン。
Link to this section主要なイノベーション#
- 認識とローカライゼーションの分離: プレゼンスヘッドがコンセプトの存在をグローバルに予測し、提案クエリはローカライゼーションのみに焦点を当てることで、競合する目的を回避します。
- コンセプトプロンプトと視覚的プロンプトの統合: PCS(コンセプトプロンプト)とPVS(SAM 2のようなクリック/ボックスなどの視覚的プロンプト)の両方を単一のモデルでサポートします。
- インタラクティブな例示の洗練: ユーザーはポジティブまたはネガティブな画像例示を追加して結果を反復的に改善でき、モデルは個々のインスタンスを修正するだけでなく、類似のオブジェクトに対しても汎化します。
- 時間的曖昧さ解消: マスクレットの検出スコアと定期的な再プロンプトを使用して、ビデオ内のオクルージョン、混雑したシーン、追跡エラーを処理し、instance segmentation and trackingのベストプラクティスと整合させます。
Link to this sectionSA-Co データセット#
SAM 3は、COCOやLVISのような一般的なベンチマークを超えて拡張された、Meta史上最大かつ最も多様なセグメンテーションデータセットであるSegment Anything with Concepts (SA-Co) でトレーニングされています。
Link to this sectionトレーニングデータ#
| データセットコンポーネント | 説明 | 規模 |
|---|---|---|
| SA-Co/HQ | 4フェーズのデータエンジンによる高品質な人間による注釈付き画像データ | 520万枚の画像、400万個の固有名詞句 |
| SA-Co/SYN | 人間の関与なしにAIによってラベル付けされた合成データセット | 3800万個の名詞句、14億個のマスク |
| SA-Co/EXT | ハードネガティブで強化された15個の外部データセット | ソースにより異なる |
| SA-Co/VIDEO | 時間的追跡を含むビデオ注釈 | 52.5Kのビデオ、24.8Kの固有名詞句 |
Link to this sectionベンチマークデータ#
SA-Co評価ベンチマークには、126Kの画像とビデオにわたる214Kの固有フレーズが含まれており、既存のベンチマークよりも50倍以上多いコンセプトを提供します。これには以下が含まれます:
- SA-Co/Gold: 7つのドメイン、人間のパフォーマンス境界を測定するための3重注釈
- SA-Co/Silver: 10のドメイン、単一の人間による注釈
- SA-Co/BronzeおよびSA-Co/Bio: コンセプト・セグメンテーションに適応された9つの既存データセット
- SA-Co/VEval: 3つのドメイン(SA-V、YT-Temporal-1B、SmartGlasses)を備えたビデオベンチマーク
Link to this sectionデータエンジンのイノベーション#
SAM 3のスケーラブルな人間とモデルのループによるデータエンジンは、以下を通じて2倍の注釈スループットを達成しています:
- AI注釈者: Llamaベースのモデルが、ハードネガティブを含む多様な名詞句を提案
- AI検証者: 微調整されたmultimodal LLMsが、人間に近いパフォーマンスでマスクの品質と網羅性を検証
- アクティブマイニング: AIが苦戦する困難な失敗ケースに人間の努力を集中
- オントロジー駆動: Wikidataに根ざした大規模なオントロジーを活用してコンセプトを網羅
Link to this sectionインストール#
SAM 3は、Ultralytics version 8.3.237以降で利用可能です。以下でインストールまたはアップグレードしてください:
pip install -U ultralytics他のUltralyticsモデルとは異なり、SAM 3のウェイト(sam3.pt)は自動的にダウンロードされません。まずHugging FaceのSAM 3モデルページでモデルウェイトへのアクセスをリクエストし、承認された後にそのページからsam3.ptをダウンロードする必要があります。ダウンロードしたsam3.ptファイルを作業ディレクトリに配置するか、モデルを読み込む際にフルパスを指定してください。
予測中に上記のエラーが発生した場合、clipパッケージが正しくインストールされていないことを意味します。以下を実行して正しいclipパッケージをインストールしてください:
pip uninstall clip -y
pip install git+https://github.com/ultralytics/CLIP.gitLink to this sectionSAM 3の使用方法:コンセプト・セグメンテーションにおける汎用性#
SAM 3は、異なる予測インターフェースを通じて、プロンプト可能なコンセプト・セグメンテーション (PCS) とプロンプト可能な視覚的セグメンテーション (PVS) の両方のタスクをサポートします:
Link to this sectionサポートされるタスクとモデル#
| タスクタイプ | プロンプトタイプ | 出力 |
|---|---|---|
| コンセプト・セグメンテーション (PCS) | テキスト(名詞句)、画像例示 | コンセプトに一致するすべてのインスタンス |
| 視覚的セグメンテーション (PVS) | ポイント、ボックス、マスク | 単一のオブジェクトインスタンス (SAM 2スタイル) |
| インタラクティブな洗練 | 例示やクリックを反復的に追加/削除 | 精度が向上した洗練されたセグメンテーション |
Link to this sectionコンセプト・セグメンテーションの例#
Link to this sectionテキストプロンプトによるセグメンテーション#
テキスト記述を使用して、コンセプトのすべてのインスタンスを検索およびセグメント化します。テキストプロンプトには SAM3SemanticPredictor インターフェースが必要です。
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor with configuration
overrides = dict(
conf=0.25,
task="segment",
mode="predict",
model="sam3.pt",
quantize=16, # Use FP16 for faster inference
save=True,
)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image once for multiple queries
predictor.set_image("path/to/image.jpg")
# Query with multiple text prompts
results = predictor(text=["person", "bus", "glasses"])
# Works with descriptive phrases
results = predictor(text=["person with red cloth", "person with blue cloth"])
# Query with a single concept
results = predictor(text=["a person"])Link to this section画像例を用いたセグメンテーション#
バウンディングボックスを視覚的プロンプトとして使用し、類似するすべてのインスタンスを検索します。これには、コンセプトベースのマッチングのために SAM3SemanticPredictor も必要です。
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16, save=True)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image
predictor.set_image("path/to/image.jpg")
# Provide bounding box examples to segment similar objects
results = predictor(bboxes=[[480.0, 290.0, 590.0, 650.0]])
# Multiple bounding boxes as exemplars of the same visual concept
results = predictor(bboxes=[[539, 599, 589, 639], [343, 267, 499, 662]])Link to this section効率化のための特徴量ベースの推論#
画像特徴量を一度抽出し、複数のセグメンテーションクエリで再利用することで効率を向上させます。
import cv2
from ultralytics.models.sam import SAM3SemanticPredictor
from ultralytics.utils.plotting import Annotator, colors
# Initialize predictors
overrides = dict(conf=0.50, task="segment", mode="predict", model="sam3.pt", verbose=False)
predictor = SAM3SemanticPredictor(overrides=overrides)
predictor2 = SAM3SemanticPredictor(overrides=overrides)
# Extract features from the first predictor
source = "path/to/image.jpg"
predictor.set_image(source)
src_shape = cv2.imread(source).shape[:2]
# Setup second predictor and reuse features
predictor2.setup_model()
# Perform inference using shared features with text prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, text=["person"])
# Perform inference using shared features with bounding box prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, bboxes=[[439, 437, 524, 709]])
# Visualize results
if masks is not None:
masks, boxes = masks.cpu().numpy(), boxes.cpu().numpy()
im = cv2.imread(source)
annotator = Annotator(im, pil=False)
annotator.masks(masks, [colors(x, True) for x in range(len(masks))])
cv2.imshow("result", annotator.result())
cv2.waitKey(0)Link to this section動画コンセプトセグメンテーション#
Link to this sectionバウンディングボックスを使用して動画全体でコンセプトを追跡#
バウンディングボックスプロンプトを使用して、動画フレーム全体でオブジェクトインスタンスを検出および追跡します。
from ultralytics.models.sam import SAM3VideoPredictor
# Create video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16)
predictor = SAM3VideoPredictor(overrides=overrides)
# Track objects using bounding box prompts
results = predictor(source="path/to/video.mp4", bboxes=[[706.5, 442.5, 905.25, 555], [598, 635, 725, 750]], stream=True)
# Process and display results
for r in results:
r.show() # Display frame with segmentation masksLink to this sectionテキストプロンプトによるコンセプトの追跡#
テキストで指定されたコンセプトのすべてのインスタンスを、動画フレーム全体で追跡します。
from ultralytics.models.sam import SAM3VideoSemanticPredictor
# Initialize semantic video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=640, model="sam3.pt", quantize=16, save=True)
predictor = SAM3VideoSemanticPredictor(overrides=overrides)
# Track concepts using text prompts
results = predictor(source="path/to/video.mp4", text=["person", "bicycle"], stream=True)
# Process results
for r in results:
r.show() # Display frame with tracked objects
# Alternative: Track with bounding box prompts
results = predictor(
source="path/to/video.mp4",
bboxes=[[864, 383, 975, 620], [705, 229, 782, 402]],
labels=[1, 1], # Positive labels
stream=True,
)Link to this section視覚的プロンプト (SAM 2 との互換性)#
SAM 3 は、単一オブジェクトセグメンテーションのための SAM 2 の視覚的プロンプトとの完全な下位互換性を維持しています。
基本的な SAM インターフェースは SAM 2 とまったく同じように動作し、視覚的プロンプト (点、ボックス、またはマスク) で示された特定の領域のみをセグメント化します。
from ultralytics import SAM
model = SAM("sam3.pt")
# Single point prompt - segments object at specific location
results = model.predict(source="path/to/image.jpg", points=[900, 370], labels=[1])
results[0].show()
# Multiple points - segments single object with multiple point hints
results = model.predict(source="path/to/image.jpg", points=[[400, 370], [900, 370]], labels=[1, 1])
# Box prompt - segments object within bounding box
results = model.predict(source="path/to/image.jpg", bboxes=[100, 150, 300, 400])
results[0].show()視覚的プロンプト (点/ボックス/マスク) で SAM("sam3.pt") を使用すると、SAM 2 と同様に、その場所にある 特定のオブジェクトのみ がセグメント化されます。コンセプトのすべてのインスタンス をセグメント化するには、上記のようにテキストプロンプトまたは画像例プロンプトを使用して SAM3SemanticPredictor を使用してください。
Link to this sectionパフォーマンスベンチマーク#
Link to this section画像セグメンテーション#
SAM 3 は、LVIS や COCO for segmentation といった現実世界のデータセットを含む、複数のベンチマークで最先端の成果を上げています。
| ベンチマーク | メトリクス | SAM 3 | 従来のベスト | 改善率 |
|---|---|---|---|---|
| LVIS (ゼロショット) | Mask AP | 47.0 | 38.5 | +22.1% |
| SA-Co/Gold | CGF1 | 65.0 | 34.3 (OWLv2) | +89.5% |
| COCO (ゼロショット) | Box AP | 53.5 | 52.2 (T-Rex2) | +2.5% |
| ADE-847 (セマンティックセグメンテーション) | mIoU | 14.7 | 9.2 (APE-D) | +59.8% |
| PascalConcept-59 | mIoU | 59.4 | 58.5 (APE-D) | +1.5% |
| Cityscapes (セマンティックセグメンテーション) | mIoU | 65.1 | 44.2 (APE-D) | +47.3% |
Ultralytics datasets で、簡単な実験のためのデータセットオプションを探索してください。
Link to this section動画セグメンテーションのパフォーマンス#
SAM 3 は、DAVIS 2017 や YouTube-VOS といった動画ベンチマーク全体で、SAM 2 や以前の最先端モデルを大幅に上回る改善を示しています。
| ベンチマーク | メトリクス | SAM 3 | SAM 2.1 L | 改善率 |
|---|---|---|---|---|
| MOSEv2 | J&F | 60.1 | 47.9 | +25.5% |
| DAVIS 2017 | J&F | 92.0 | 90.7 | +1.4% |
| LVOSv2 | J&F | 88.2 | 79.6 | +10.8% |
| SA-V | J&F | 84.6 | 78.4 | +7.9% |
| YTVOS19 | J&F | 89.6 | 89.3 | +0.3% |
Link to this sectionフューショット適応#
SAM 3 は、data-centric AI ワークフローに関連する最小限の例を用いて新しいドメインに適応することに優れています。
| ベンチマーク | 0-shot AP | 10-shot AP | 従来のベスト (10-shot) |
|---|---|---|---|
| ODinW13 | 59.9 | 71.6 | 67.9 (gDino1.5-Pro) |
| RF100-VL | 14.3 | 35.7 | 33.7 (gDino-T) |
Link to this sectionインタラクティブな修正の有効性#
SAM 3 の画像例を使用したコンセプトベースのプロンプトは、視覚的プロンプトよりもはるかに速く収束します。
| 追加されたプロンプト | CGF1 スコア | テキストのみに対するゲイン | PVS ベースラインに対するゲイン |
|---|---|---|---|
| テキストのみ | 46.4 | ベースライン | ベースライン |
| +1 画像例 | 57.6 | +11.2 | +6.7 |
| +2 画像例 | 62.2 | +15.8 | +9.7 |
| +3個の例示 | 65.0 | +18.6 | +11.2 |
| +4個の例示 | 65.7 | +19.3 | +11.5 (プラトー) |
Link to this section物体カウント精度#
SAM 3は、物体カウントにおいて一般的な要件であるすべてのインスタンスをセグメンテーションすることで、正確なカウントを提供します。
| ベンチマーク | 精度 | MAE | 対 最良のMLLM |
|---|---|---|---|
| CountBench | 95.6% | 0.11 | 92.4% (Gemini 2.5) |
| PixMo-Count | 87.3% | 0.22 | 88.8% (Molmo-72B) |
Link to this sectionSAM 3、SAM 2、およびYOLOの比較#
ここでは、SAM 3の機能をSAM 2およびYOLO26モデルと比較します。
| 機能 | SAM 3 | SAM 2 | YOLO26n-seg |
|---|---|---|---|
| コンセプトセグメンテーション | ✅ テキスト/例示からのすべてのインスタンス | ❌ 非対応 | ❌ 非対応 |
| 視覚的セグメンテーション | ✅ 単一インスタンス (SAM 2互換) | ✅ 単一インスタンス | ✅ すべてのインスタンス |
| ゼロショット機能 | ✅ オープンボキャブラリー | ✅ 幾何学的プロンプト | ❌ クローズドセット |
| インタラクティブな洗練 | ✅ 例示 + クリック | ✅ クリックのみ | ❌ 非対応 |
| ビデオトラッキング | ✅ 識別子付きマルチオブジェクト | ✅ マルチオブジェクト | ✅ マルチオブジェクト |
| LVISマスク AP (ゼロショット) | 47.0 | N/A | N/A |
| MOSEv2 J&F | 60.1 | 47.9 | N/A |
| 速度 (GPU, ms/im) | 2921 | 857 | 8.4 |
| モデルサイズ | 3.45 GB | 162 MB (ベース) | 6.4 MB |
速度は、torch==2.9.1およびultralytics==8.4.19を使用したNVIDIA RTX PRO 6000でベンチマークされました。
重要なポイント:
- SAM 3: オープンボキャブラリーのコンセプトセグメンテーションに最適。テキストまたは例示プロンプトを使用してコンセプトのすべてのインスタンスを検出します。
- SAM 2: 幾何学的プロンプトを使用した画像およびビデオ内の対話型単一オブジェクトセグメンテーションに最適です。
- YOLO26: NMS不要のエンドツーエンド推論によるリアルタイムの高速セグメンテーションに最適であり、GPU、CPU、エッジデバイスへのデプロイ用に多くの形式へエクスポート可能です。
Link to this sectionSAMとYOLOの比較#
SAM 3、SAM 2、SAM、MobileSAM、FastSAMを、Ultralytics YOLOセグメンテーションモデル(YOLOv8、YOLO11、YOLO26)とサイズ、パラメータ、GPU推論速度で比較します。
| モデル | サイズ (MB) | パラメータ (M) | 速度 (GPU) (ms/im) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 1306 |
| Meta SAM2-b | 162 | 80.8 | 857 |
| Meta SAM2-t | 78.1 | 38.9 | 668 |
| Meta SAM3 | 3450 | 473.6 | 2921 |
| MobileSAM | 40.7 | 10.1 | 605 |
| FastSAM-s with YOLOv8 backbone | 23.7 | 11.8 | 55.9 |
| Ultralytics YOLOv8n-seg | 6.7 (515倍小型) | 3.4 (139.1倍削減) | 17.4 (167倍高速) |
| Ultralytics YOLO11n-seg | 5.9 (585倍小型) | 2.9 (163.1倍削減) | 12.6 (231倍高速) |
| Ultralytics YOLO26n-seg | 6.4 (539倍小型) | 2.7 (175.2倍削減) | 8.4 (347倍高速) |
この比較は、SAMバリアントとYOLOセグメンテーションモデル間のモデルサイズと速度における大きな違いを示しています。SAMは独自の自動セグメンテーション機能を提供しますが、YOLOモデル、特にYOLOv8n-seg、YOLO11n-seg、およびYOLO26n-segは、大幅に小さく、高速で、計算効率に優れています。
テストは、torch==2.9.1およびultralytics==8.4.19を使用し、96GBのVRAMを搭載したNVIDIA RTX PRO 6000で実行されました。このテストを再現するには:
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# Profile SAM3, SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt", "sam3.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# Profile FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# Profile YOLO models
for file_name in ["yolov8n-seg.pt", "yolo11n-seg.pt", "yolo26n-seg.pt"]:
model = YOLO(file_name)
model.info()
model(ASSETS)Link to this section評価メトリクス#
SAM 3は、PCSタスク用に設計された新しいメトリクスを導入しており、F1スコア、適合率、再現率といった馴染みのある指標を補完します。
Link to this sectionClassification-Gated F1 (CGF1)#
ローカリゼーションと分類を組み合わせた主要なメトリクス:
CGF1 = 100 × pmF1 × IL_MCC
各項目の説明:
- pmF1 (Positive Macro F1): ポジティブな例におけるローカリゼーションの品質を測定します
- IL_MCC (Image-Level Matthews Correlation Coefficient): 二値分類の精度(「コンセプトは存在するか?」)を測定します
Link to this sectionなぜこれらのメトリクスなのか?#
従来のAPメトリクスはキャリブレーションを考慮していないため、実際の環境でモデルを使用することが困難です。0.5以上の信頼度を持つ予測のみを評価することで、SAM 3のメトリクスは適切なキャリブレーションを強制し、インタラクティブな予測およびトラッキングループにおける実世界の利用パターンを模倣します。
Link to this section主なアブレーションと知見#
Link to this section存在ヘッドの影響#
存在ヘッドは認識をローカリゼーションから分離し、大幅な改善をもたらします:
| 設定 | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 存在ヘッドなし | 57.6 | 0.77 | 74.7 |
| 存在ヘッドあり | 63.3 | 0.82 | 77.1 |
存在ヘッドは**+5.7 CGF1の向上**(+9.9%)をもたらし、主に認識能力(IL_MCC +6.5%)を改善します。
Link to this sectionハードネガティブの影響#
| ハードネガティブ/画像 | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 0 | 31.8 | 0.44 | 70.2 |
| 5 | 44.8 | 0.62 | 71.9 |
| 30 | 49.2 | 0.68 | 72.3 |
ハードネガティブはオープンボキャブラリー認識において極めて重要であり、IL_MCCを54.5% (0.44 → 0.68) 改善します。
Link to this section学習データのスケーリング#
| データソース | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 外部のみ | 30.9 | 0.46 | 66.3 |
| 外部 + 合成 | 39.7 | 0.57 | 70.6 |
| 外部 + HQ | 51.8 | 0.71 | 73.2 |
| すべて | 54.3 | 0.74 | 73.5 |
高品質な人間によるアノテーションは、合成データや外部データのみを使用する場合と比較して大幅な向上をもたらします。データ品質の実践に関する背景については、データ収集とアノテーションを参照してください。
Link to this sectionアプリケーション#
SAM 3のコンセプトセグメンテーション機能は、新しいユースケースを可能にします。
- コンテンツモデレーション: メディアライブラリ全体から特定のコンテンツタイプのすべてのインスタンスを検索
- Eコマース: カタログ画像内の特定のタイプの製品をすべてセグメント化し、自動アノテーションをサポートします
- 医療画像: 特定の組織タイプや異常のすべての発生箇所を特定
- 自律システム: カテゴリ別に交通標識、歩行者、または車両のすべてのインスタンスを追跡
- ビデオ分析: 特定の衣服を着用している、または特定の行動を行っているすべての人をカウントおよび追跡
- データセットアノテーション: レアなオブジェクトカテゴリのすべてのインスタンスを迅速にアノテーション
- 科学研究: 特定の基準に一致するすべての標本を定量化および分析
Link to this sectionSAM 3 Agent: 拡張された言語推論#
SAM 3は、マルチモーダル大規模言語モデル(MLLM)と組み合わせることで、OWLv2やT-Rexのようなオープンボキャブラリーシステムと同様の精神で、推論を必要とする複雑なクエリを処理できます。
Link to this section推論タスクにおけるパフォーマンス#
| ベンチマーク | メトリクス | SAM 3 Agent (Gemini 2.5 Pro) | 従来のベスト |
|---|---|---|---|
| ReasonSeg (検証) | gIoU | 76.0 | 65.0 (SoTA) |
| ReasonSeg (テスト) | gIoU | 73.8 | 61.3 (SoTA) |
| OmniLabel (検証) | アジア太平洋 | 46.7 | 36.5 (REAL) |
| RefCOCO+ | Acc | 91.2 | 89.3 (LISA) |
Link to this section複雑なクエリの例#
SAM 3 Agentは推論を必要とするクエリを処理できます。
- 「座っているが、手にギフトボックスを持っていない人々」
- 「首輪をしていない、カメラに最も近い犬」
- 「人の手よりも大きい赤いオブジェクト」
MLLMはSAM 3に対して単純な名詞句クエリを提案し、返されたマスクを分析し、満足するまで繰り返します。
Link to this section制限事項#
SAM 3は大きな進歩を遂げましたが、いくつかの制限があります。
- フレーズの複雑さ: 単純な名詞句に最適です。長い参照表現や複雑な推論にはMLLMの統合が必要な場合があります。
- 曖昧さの処理: 一部のコンセプトは本質的に曖昧なままです(例:「小さな窓」、「居心地の良い部屋」)。
- 計算要件: YOLOのような特殊な検出モデルよりも大きく、低速です。
- 語彙の範囲: 原子的な視覚コンセプトに焦点を当てており、MLLMの支援なしでは合成的な推論は制限されます。
- レアなコンセプト: 学習データに十分に表現されていない、非常にレアまたは細かなコンセプトではパフォーマンスが低下する可能性があります。
Link to this section引用#
@inproceedings{sam3_2025,
title = {SAM 3: Segment Anything with Concepts},
author = {Anonymous authors},
booktitle = {Submitted to ICLR 2026},
year = {2025},
url = {https://openreview.net/forum?id=r35clVtGzw},
note = {Paper ID: 4183, under double-blind review}
}Link to this sectionよくある質問 (FAQ)#
Link to this sectionSAM 3はいつリリースされましたか?#
SAM 3はMetaによって2025年11月20日にリリースされ、バージョン8.3.237(PR #22897)からUltralyticsに完全に統合されています。予測モードと追跡モードのフルサポートが利用可能です。
Link to this sectionSAM 3はUltralyticsに統合されていますか?#
Yes! SAM 3 is fully integrated into the Ultralytics Python package, including concept segmentation, SAM 2–style visual prompts, and multi-object video tracking. SAM 3 also powers the smart annotation feature on Ultralytics Platform, where you can annotate images with just a few clicks.
Link to this sectionプロンプト可能なコンセプトセグメンテーション(PCS)とは何ですか?#
PCSはSAM 3で導入された新しいタスクであり、画像またはビデオ内のすべてのインスタンスの視覚コンセプトをセグメント化します。特定のオブジェクトインスタンスをターゲットにする従来のセグメンテーションとは異なり、PCSはカテゴリのすべての出現箇所を見つけます。例:
- テキストプロンプト: 「黄色いスクールバス」 → シーン内のすべての黄色いスクールバスをセグメント化
- 画像エグザンプラ: 1匹の犬を囲むボックス → 画像内のすべての犬をセグメント化
- 組み合わせ: 「縞模様の猫」 + エグザンプラボックス → サンプルと一致するすべての縞模様の猫をセグメント化
オブジェクト検出とインスタンスセグメンテーションに関する関連背景を参照してください。
Link to this sectionSAM 3はSAM 2とどう違いますか?#
| 機能 | SAM 2 | SAM 3 |
|---|---|---|
| タスク | プロンプトごとに単一のオブジェクト | コンセプトのすべてのインスタンス |
| プロンプトタイプ | ポイント、ボックス、マスク | + テキストフレーズ、画像エグザンプラ |
| 検出能力 | 外部検出器が必要 | 組み込みのオープンボキャブラリー検出器 |
| 認識 | 幾何学ベースのみ | テキストおよび視覚認識 |
| アーキテクチャ | トラッカーのみ | 存在ヘッドを備えた検出器 + トラッカー |
| ゼロショットパフォーマンス | N/A(視覚プロンプトが必要) | LVISで47.0 AP、SA-Coで2倍向上 |
| インタラクティブな洗練 | クリックのみ | クリック + エグザンプラの一般化 |
SAM 3は、コンセプトベースの機能を追加しながら、SAM 2の視覚プロンプトとの下位互換性を維持しています。
Link to this sectionSAM 3の学習にはどのデータセットが使用されますか?#
SAM 3は**Segment Anything with Concepts (SA-Co)**データセットで学習されています。
トレーニングデータ:
- 520万枚の画像と400万件のユニークな名詞句 (SA-Co/HQ) - 高品質な人間によるアノテーション
- 5万2500本の動画と2万4800件のユニークな名詞句 (SA-Co/VIDEO)
- 3800万件の名詞句にわたる14億件の合成マスク (SA-Co/SYN)
- ハードネガティブで強化された15件の外部データセット (SA-Co/EXT)
ベンチマークデータ:
- 12万6000件の画像/動画にわたる21万4000件のユニークなコンセプト
- 既存のベンチマークより50倍多くのコンセプト (例: LVISは約4000コンセプト)
- 人間のパフォーマンス限界を測定するためのSA-Co/Goldにおけるトリプルアノテーション
この膨大なスケールと多様性により、SAM 3はオープンボキャブラリーのコンセプト全体で優れたゼロショット汎化を実現します。
Link to this sectionセグメンテーションにおいて、SAM 3とYOLO26はどのように比較されますか?#
SAM 3とYOLO26はそれぞれ異なるユースケースに対応しています。
SAM 3の利点:
- オープンボキャブラリー: トレーニングなしでテキストプロンプトを介してあらゆるコンセプトをセグメント化します
- ゼロショット: 新しいカテゴリに対して即座に機能します
- インタラクティブ: 実例に基づくリファインメントが類似のオブジェクトへ汎化されます
- コンセプトベース: カテゴリのすべてのインスタンスを自動的に検出します
- 精度: LVISゼロショットインスタンスセグメンテーションで47.0 AP
YOLO26の利点:
- 速度: NMS不要のエンドツーエンド設計により桁違いに高速な推論
- 効率: 539倍の軽量モデル (6.4MB vs 3.45GB)
- リソースフレンドリー: エッジデバイスやモバイルで動作
- リアルタイム: 本番環境での展開に最適化
推奨:
- テキストや実例で記述されたコンセプトのすべてのインスタンスを見つける必要がある、柔軟なオープンボキャブラリーセグメンテーションにはSAM 3を使用してください
- カテゴリが事前に判明している高速な本番環境での展開にはYOLO26を使用してください
- 幾何学的プロンプトを用いたインタラクティブな単一オブジェクトセグメンテーションにはSAM 2を使用してください
Link to this sectionSAM 3は複雑な言語クエリを処理できますか?#
SAM 3は単純な名詞句(例:「赤いリンゴ」、「帽子をかぶった人」)を対象として設計されています。推論を必要とする複雑なクエリには、SAM 3とMLLMを組み合わせたSAM 3 Agentを使用してください。
単純なクエリ(ネイティブのSAM 3):
- 「黄色いスクールバス」
- 「縞模様の猫」
- 「赤い帽子をかぶった人」
複雑なクエリ(MLLMを使用したSAM 3 Agent):
- 「座っているがギフトボックスを持っていない人々」
- 「首輪をしていないカメラに最も近い犬」
- 「人の手よりも大きい赤いオブジェクト」
SAM 3 Agentは、SAM 3のセグメンテーションとMLLMの推論能力を組み合わせることで、ReasonSegの検証で76.0 gIoUを達成しました(従来の最高値は65.0、16.9%の改善)。
Link to this sectionSAM 3の精度は人間のパフォーマンスと比較してどの程度ですか?#
トリプル人間アノテーションを用いたSA-Co/Goldベンチマークにおいて:
- 人間の下限: 74.2 CGF1(最も保守的なアノテーター)
- SAM 3のパフォーマンス: 65.0 CGF1
- 達成値: 推定された人間の下限の88%
- 人間の上限: 81.4 CGF1(最も自由なアノテーター)
SAM 3はオープンボキャブラリーのコンセプトセグメンテーションにおいて、人間レベルの精度に迫る強力なパフォーマンスを達成しています。その差は主に、曖昧または主観的なコンセプト(例:「小さな窓」、「居心地の良い部屋」)に見られます。