Link to this sectionSAM 3: 개념을 사용한 세그먼트(Segment Anything with Concepts)#
SAM 3는 버전 8.3.237(PR #22897)부터 Ultralytics 패키지에 완전히 통합되었습니다. pip install -U ultralytics를 통해 설치하거나 업그레이드하여 텍스트 기반 개념 세그멘테이션, 이미지 예제 프롬프트, 비디오 추적을 포함한 모든 SAM 3 기능을 이용하십시오.
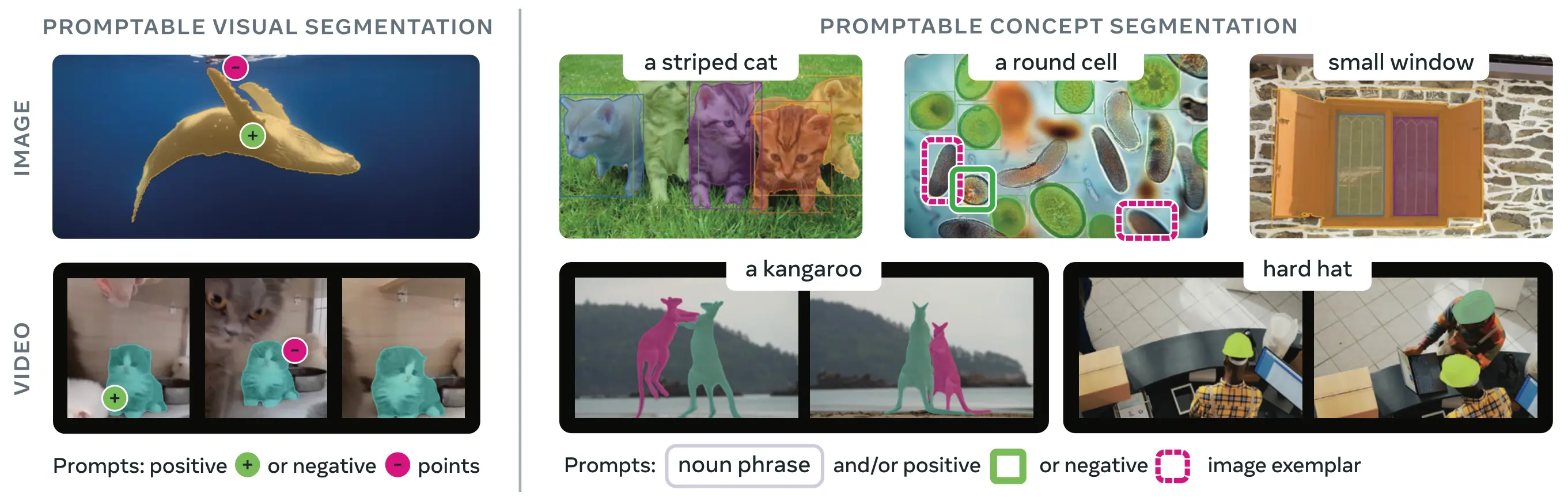
SAM 3(Segment Anything Model 3)는 Meta에서 출시한 **PCS(Promptable Concept Segmentation)**를 위한 파운데이션 모델입니다. SAM 2를 기반으로 구축된 SAM 3는 텍스트 프롬프트, 이미지 예제 또는 둘 다로 지정된 시각적 개념의 모든 인스턴스를 감지, 세그멘테이션 및 추적하는 근본적으로 새로운 기능을 도입합니다. 프롬프트당 단일 객체를 세그멘테이션하던 이전 SAM 버전과 달리, SAM 3는 이미지나 비디오의 어디에든 나타나는 개념의 모든 발생을 찾아 세그멘테이션할 수 있으며, 최신 인스턴스 세그멘테이션의 오픈 어휘 목표와 일치합니다.
Watch: How to Use Meta Segment Anything 3 with Ultralytics | Text-Prompt Segmentation on Images & Videos
SAM 3는 이제 ultralytics 패키지에 완전히 통합되어 텍스트 프롬프트, 이미지 예제 프롬프트 및 비디오 추적 기능을 사용한 개념 세그멘테이션을 기본적으로 지원합니다.
Link to this section개요#
SAM 3는 기존 시스템 대비 2배의 성능 향상을 달성함과 동시에 대화형 시각적 세그멘테이션에 대한 SAM 2의 기능을 유지 및 개선했습니다. 이 모델은 오픈 어휘 세그멘테이션에 탁월하여 사용자가 간단한 명사 구(예: "노란색 스쿨버스", "줄무늬 고양이")를 사용하거나 대상 객체의 예시 이미지를 제공하여 개념을 지정할 수 있습니다. 이러한 기능은 간소화된 predict 및 track 워크플로에 의존하는 생산 준비가 완료된 파이프라인을 보완합니다.
Link to this sectionPCS(Promptable Concept Segmentation)란 무엇입니까?#
PCS 작업은 입력으로 **개념 프롬프트(concept prompt)**를 받아 일치하는 모든 객체 인스턴스에 대한 고유 식별자가 포함된 세그멘테이션 마스크를 반환합니다. 개념 프롬프트는 다음과 같을 수 있습니다:
- 텍스트: 제로샷 학습과 유사한 "빨간 사과" 또는 "모자를 쓴 사람"과 같은 간단한 명사 구
- 이미지 예제: 빠른 일반화를 위해 객체 주변에 설정하는 바운딩 박스(긍정 또는 부정)
- 조합형: 정밀한 제어를 위해 텍스트와 이미지 예제를 함께 사용
이는 원래 SAM 제품군이 대중화한 단일 객체 인스턴스만 세그멘테이션하는 기존 시각적 프롬프트(포인트, 박스, 마스크)와 다릅니다.
Link to this section주요 성능 지표#
| 지표 | SAM 3 달성 성과 |
|---|---|
| LVIS 제로샷 마스크 AP | 47.0(이전 최고치 38.5 대비, +22% 향상) |
| SA-Co 벤치마크 | 기존 시스템 대비 2배 향상 |
| 추론 속도(H200 GPU) | 100개 이상의 객체를 감지할 때 이미지당 30 ms |
| 비디오 성능 | ~5개의 동시 객체에 대해 거의 실시간 처리 |
| MOSEv2 VOS 벤치마크 | 60.1 J&F(SAM 2.1 대비 +25.5%, 이전 SOTA 대비 +17%) |
| 대화형 정교화 | 3개의 예제 프롬프트 후 +18.6 CGF1 향상 |
| 인간 성능 격차 | SA-Co/Gold의 추정 하한선 중 88% 달성 |
생산 환경에서의 모델 지표 및 절충점에 대한 자세한 내용은 모델 평가 인사이트 및 YOLO 성능 지표를 참조하십시오.
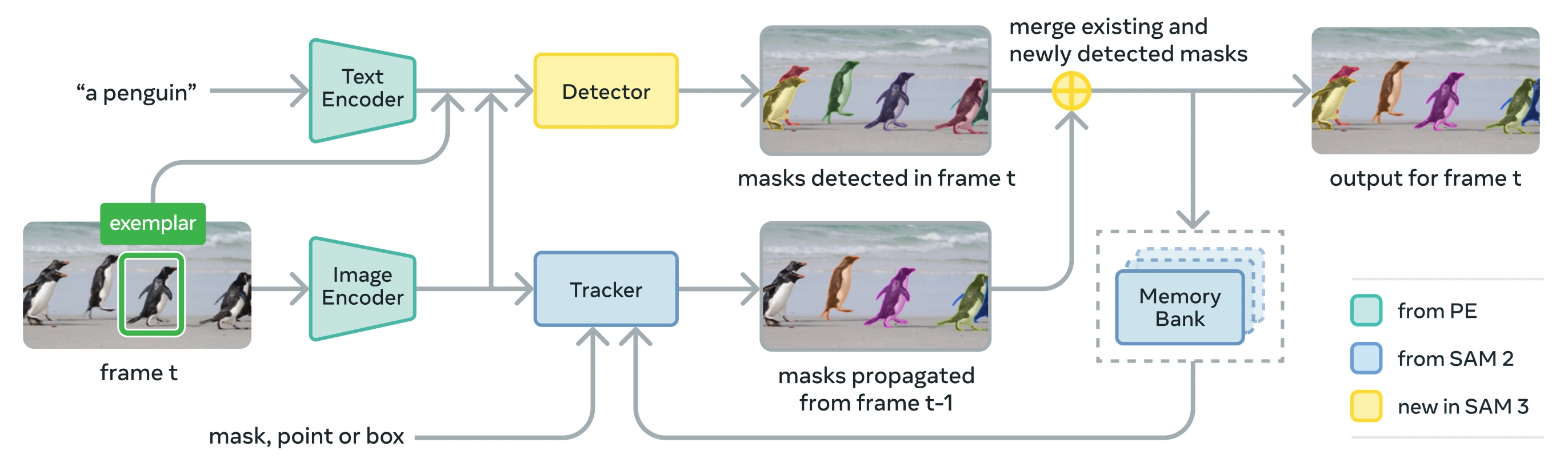
Link to this section아키텍처#
SAM 3는 PE(Perception Encoder) 비전 백본을 공유하는 **감지기(detector)**와 **추적기(tracker)**로 구성됩니다. 이 분리된 설계는 작업 충돌을 방지하면서 이미지 수준의 감지와 비디오 수준의 추적을 모두 가능하게 하며, Ultralytics Python 사용법 및 CLI 사용법과 호환되는 인터페이스를 제공합니다.
Link to this section핵심 구성 요소#
-
감지기: 이미지 수준의 개념 감지를 위한 DETR 기반 아키텍처
- 명사 구 프롬프트를 위한 텍스트 인코더
- 이미지 기반 프롬프트를 위한 예제 인코더
- 프롬프트를 기반으로 이미지 특징을 조건화하는 융합 인코더
- 인식("무엇")과 위치 지정("어디")을 분리하는 새로운 존재 헤드(presence head)
- 인스턴스 세그멘테이션 마스크 생성을 위한 마스크 헤드
-
추적기: SAM 2에서 계승된 메모리 기반 비디오 세그멘테이션
- 프롬프트 인코더, 마스크 디코더, 메모리 인코더
- 프레임 간 객체 외관을 저장하기 위한 메모리 뱅크
- 다중 객체 설정에서 칼만 필터와 같은 기술의 도움을 받는 시간적 모호성 해소
-
존재 토큰(Presence Token): 대상 개념이 이미지/프레임에 존재하는지 여부를 예측하는 학습된 글로벌 토큰으로, 인식과 위치 지정을 분리하여 감지 성능을 향상시킵니다.
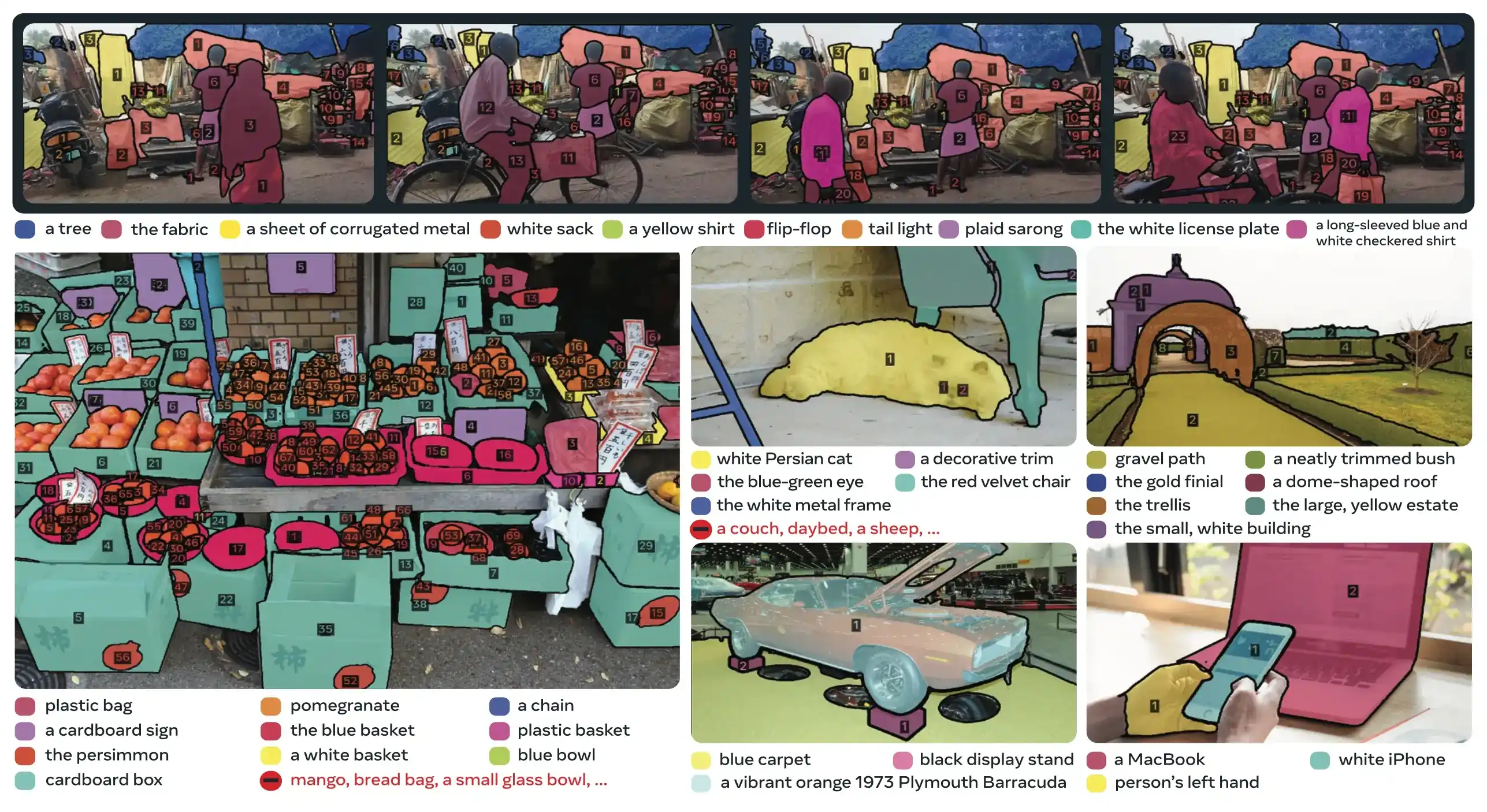
Link to this section주요 혁신 사항#
- 인식 및 위치 지정의 분리: 존재 헤드가 전역적으로 개념 존재 여부를 예측하는 동안 제안 쿼리는 위치 지정에만 집중하여 상충되는 목표를 방지합니다.
- 통합된 개념 및 시각적 프롬프트: 단일 모델에서 PCS(개념 프롬프트)와 PVS(SAM 2의 클릭/박스와 같은 시각적 프롬프트)를 모두 지원합니다.
- 대화형 예제 정교화: 사용자가 긍정 또는 부정 이미지 예제를 추가하여 결과를 반복적으로 다듬을 수 있으며, 모델은 개별 인스턴스 수정에 그치지 않고 유사한 객체로 일반화합니다.
- 시간적 모호성 해소: 마스크렛 감지 점수와 주기적인 재프롬프팅을 사용하여 비디오에서의 가림, 혼잡한 장면, 추적 실패 문제를 처리하며, 이는 인스턴스 세그멘테이션 및 추적 모범 사례와 일치합니다.
Link to this sectionSA-Co 데이터셋#
SAM 3는 COCO 및 LVIS와 같은 일반적인 벤치마크를 뛰어넘는, Meta의 현재까지 가장 크고 다양한 세그멘테이션 데이터셋인 **SA-Co(Segment Anything with Concepts)**로 학습되었습니다.
Link to this section학습 데이터#
| 데이터셋 구성 요소 | 설명 | 규모 |
|---|---|---|
| SA-Co/HQ | 4단계 데이터 엔진을 통해 생성된 고품질 인간 주석 이미지 데이터 | 520만 이미지, 400만 개의 고유 명사 구 |
| SA-Co/SYN | 인간 개입 없이 AI가 라벨링한 합성 데이터셋 | 3,800만 개의 명사 구, 14억 개의 마스크 |
| SA-Co/EXT | 하드 네거티브로 보강된 15개의 외부 데이터셋 | 출처별로 다름 |
| SA-Co/VIDEO | 시간적 추적 기능이 포함된 비디오 주석 | 52,500개 비디오, 24,800개의 고유 명사 구 |
Link to this section벤치마크 데이터#
SA-Co 평가 벤치마크는 126,000개의 이미지 및 비디오 전반에 걸쳐 214,000개의 고유 구문을 포함하며 기존 벤치마크보다 50배 이상의 개념을 제공합니다. 다음을 포함합니다:
- SA-Co/Gold: 7개 도메인, 인간 성능 범위 측정을 위한 삼중 주석
- SA-Co/Silver: 10개 도메인, 단일 인간 주석
- SA-Co/Bronze 및 SA-Co/Bio: 개념 세그멘테이션을 위해 조정된 9개의 기존 데이터셋
- SA-Co/VEval: 3개 도메인(SA-V, YT-Temporal-1B, SmartGlasses)을 포함한 비디오 벤치마크
Link to this section데이터 엔진 혁신#
SAM 3의 확장 가능한 인간-모델 루프 데이터 엔진은 다음을 통해 2배의 주석 처리량을 달성합니다:
- AI 주석 도구: Llama 기반 모델이 하드 네거티브를 포함한 다양한 명사 구를 제안
- AI 검증 도구: 미세 조정된 멀티모달 LLM이 거의 인간 수준의 성능으로 마스크 품질과 완전성을 검증
- 능동적 마이닝: AI가 어려워하는 까다로운 실패 사례에 인간의 노력을 집중
- 온톨로지 기반: 개념 커버리지를 위해 Wikidata에 기반한 방대한 온톨로지를 활용
Link to this section설치#
SAM 3는 Ultralytics 버전 8.3.237 이상에서 사용할 수 있습니다. 다음을 통해 설치하거나 업그레이드하십시오:
pip install -U ultralytics다른 Ultralytics 모델과 달리, SAM 3 가중치(sam3.pt)는 자동으로 다운로드되지 않습니다. 먼저 Hugging Face의 SAM 3 모델 페이지에서 모델 가중치에 대한 액세스 권한을 요청하고, 승인되면 해당 페이지에서 sam3.pt를 다운로드해야 합니다. 다운로드한 sam3.pt 파일을 작업 디렉터리에 넣거나 모델을 로드할 때 전체 경로를 지정하십시오.
예측 중 위 오류가 발생하면 올바르지 않은 clip 패키지가 설치된 것입니다. 다음을 실행하여 올바른 clip 패키지를 설치하십시오:
pip uninstall clip -y
pip install git+https://github.com/ultralytics/CLIP.gitLink to this sectionSAM 3 사용법: 개념 세그멘테이션에서의 다재다능함#
SAM 3는 서로 다른 예측기 인터페이스를 통해 PCS(Promptable Concept Segmentation) 및 PVS(Promptable Visual Segmentation) 작업을 모두 지원합니다:
Link to this section지원되는 작업 및 모델#
| 작업 유형 | 프롬프트 유형 | 출력 |
|---|---|---|
| 개념 세그멘테이션(PCS) | 텍스트(명사 구), 이미지 예제 | 개념과 일치하는 모든 인스턴스 |
| 시각적 세그멘테이션(PVS) | 포인트, 박스, 마스크 | 단일 객체 인스턴스(SAM 2 스타일) |
| 대화형 정교화 | 예제 또는 클릭을 반복적으로 추가/제거 | 정확도가 향상된 정교한 세그멘테이션 |
Link to this section개념 세그멘테이션 예시#
Link to this section텍스트 프롬프트로 세그멘테이션#
텍스트 설명을 사용하여 개념의 모든 인스턴스를 찾고 세그먼트합니다. 텍스트 프롬프트에는 SAM3SemanticPredictor 인터페이스가 필요합니다.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor with configuration
overrides = dict(
conf=0.25,
task="segment",
mode="predict",
model="sam3.pt",
quantize=16, # Use FP16 for faster inference
save=True,
)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image once for multiple queries
predictor.set_image("path/to/image.jpg")
# Query with multiple text prompts
results = predictor(text=["person", "bus", "glasses"])
# Works with descriptive phrases
results = predictor(text=["person with red cloth", "person with blue cloth"])
# Query with a single concept
results = predictor(text=["a person"])Link to this section이미지 예시를 통한 세그멘테이션#
바운딩 박스를 시각적 프롬프트로 사용하여 유사한 모든 인스턴스를 찾습니다. 이 기능 또한 개념 기반 매칭을 위해 SAM3SemanticPredictor가 필요합니다.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16, save=True)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image
predictor.set_image("path/to/image.jpg")
# Provide bounding box examples to segment similar objects
results = predictor(bboxes=[[480.0, 290.0, 590.0, 650.0]])
# Multiple bounding boxes as exemplars of the same visual concept
results = predictor(bboxes=[[539, 599, 589, 639], [343, 267, 499, 662]])Link to this section효율성을 위한 특징 기반 추론#
이미지 특징을 한 번 추출하고 이를 여러 세그멘테이션 쿼리에 재사용하여 효율성을 향상시킵니다.
import cv2
from ultralytics.models.sam import SAM3SemanticPredictor
from ultralytics.utils.plotting import Annotator, colors
# Initialize predictors
overrides = dict(conf=0.50, task="segment", mode="predict", model="sam3.pt", verbose=False)
predictor = SAM3SemanticPredictor(overrides=overrides)
predictor2 = SAM3SemanticPredictor(overrides=overrides)
# Extract features from the first predictor
source = "path/to/image.jpg"
predictor.set_image(source)
src_shape = cv2.imread(source).shape[:2]
# Setup second predictor and reuse features
predictor2.setup_model()
# Perform inference using shared features with text prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, text=["person"])
# Perform inference using shared features with bounding box prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, bboxes=[[439, 437, 524, 709]])
# Visualize results
if masks is not None:
masks, boxes = masks.cpu().numpy(), boxes.cpu().numpy()
im = cv2.imread(source)
annotator = Annotator(im, pil=False)
annotator.masks(masks, [colors(x, True) for x in range(len(masks))])
cv2.imshow("result", annotator.result())
cv2.waitKey(0)Link to this section비디오 개념 세그멘테이션#
Link to this section바운딩 박스를 사용하여 비디오 전체에서 개념 추적#
바운딩 박스 프롬프트를 사용하여 비디오 프레임 전체에서 객체 인스턴스를 감지하고 추적합니다.
from ultralytics.models.sam import SAM3VideoPredictor
# Create video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16)
predictor = SAM3VideoPredictor(overrides=overrides)
# Track objects using bounding box prompts
results = predictor(source="path/to/video.mp4", bboxes=[[706.5, 442.5, 905.25, 555], [598, 635, 725, 750]], stream=True)
# Process and display results
for r in results:
r.show() # Display frame with segmentation masksLink to this section텍스트 프롬프트를 사용한 개념 추적#
텍스트로 지정된 개념의 모든 인스턴스를 비디오 프레임 전체에서 추적합니다.
from ultralytics.models.sam import SAM3VideoSemanticPredictor
# Initialize semantic video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=640, model="sam3.pt", quantize=16, save=True)
predictor = SAM3VideoSemanticPredictor(overrides=overrides)
# Track concepts using text prompts
results = predictor(source="path/to/video.mp4", text=["person", "bicycle"], stream=True)
# Process results
for r in results:
r.show() # Display frame with tracked objects
# Alternative: Track with bounding box prompts
results = predictor(
source="path/to/video.mp4",
bboxes=[[864, 383, 975, 620], [705, 229, 782, 402]],
labels=[1, 1], # Positive labels
stream=True,
)Link to this section시각적 프롬프트 (SAM 2 호환성)#
SAM 3는 단일 객체 세그멘테이션을 위한 SAM 2의 시각적 프롬프트와 완벽한 하위 호환성을 유지합니다:
기본 SAM 인터페이스는 SAM 2와 정확히 동일하게 동작하며, 시각적 프롬프트(포인트, 박스 또는 마스크)로 표시된 특정 영역만 세그먼트합니다.
from ultralytics import SAM
model = SAM("sam3.pt")
# Single point prompt - segments object at specific location
results = model.predict(source="path/to/image.jpg", points=[900, 370], labels=[1])
results[0].show()
# Multiple points - segments single object with multiple point hints
results = model.predict(source="path/to/image.jpg", points=[[400, 370], [900, 370]], labels=[1, 1])
# Box prompt - segments object within bounding box
results = model.predict(source="path/to/image.jpg", bboxes=[100, 150, 300, 400])
results[0].show()시각적 프롬프트(포인트/박스/마스크)와 함께 SAM("sam3.pt")를 사용하면 SAM 2와 마찬가지로 해당 위치의 특정 객체만 세그먼트합니다. 개념의 모든 인스턴스를 세그먼트하려면 위에 표시된 것처럼 텍스트 또는 예시 프롬프트와 함께 SAM3SemanticPredictor를 사용하십시오.
Link to this section성능 벤치마크#
Link to this section이미지 세그멘테이션#
SAM 3는 LVIS 및 COCO for segmentation와 같은 실제 데이터셋을 포함한 여러 벤치마크에서 최첨단 결과를 달성했습니다:
| 벤치마크 | 지표 | SAM 3 | 이전 최고 기록 | 개선 사항 |
|---|---|---|---|---|
| LVIS (제로샷) | Mask AP | 47.0 | 38.5 | +22.1% |
| SA-Co/Gold | CGF1 | 65.0 | 34.3 (OWLv2) | +89.5% |
| COCO (제로샷) | Box AP | 53.5 | 52.2 (T-Rex2) | +2.5% |
| ADE-847 (의미론적 세그멘테이션) | mIoU | 14.7 | 9.2 (APE-D) | +59.8% |
| PascalConcept-59 | mIoU | 59.4 | 58.5 (APE-D) | +1.5% |
| Cityscapes (의미론적 세그멘테이션) | mIoU | 65.1 | 44.2 (APE-D) | +47.3% |
Ultralytics datasets에서 빠른 실험을 위한 데이터셋 옵션을 살펴보십시오.
Link to this section비디오 세그멘테이션 성능#
SAM 3는 DAVIS 2017 및 YouTube-VOS와 같은 비디오 벤치마크 전반에서 SAM 2 및 이전의 최첨단 모델 대비 상당한 성능 향상을 보여줍니다:
| 벤치마크 | 지표 | SAM 3 | SAM 2.1 L | 개선 사항 |
|---|---|---|---|---|
| MOSEv2 | J&F | 60.1 | 47.9 | +25.5% |
| DAVIS 2017 | J&F | 92.0 | 90.7 | +1.4% |
| LVOSv2 | J&F | 88.2 | 79.6 | +10.8% |
| SA-V | J&F | 84.6 | 78.4 | +7.9% |
| YTVOS19 | J&F | 89.6 | 89.3 | +0.3% |
Link to this section퓨샷(Few-Shot) 적응#
SAM 3는 data-centric AI 워크플로우와 관련된 최소한의 예시만으로 새로운 도메인에 적응하는 데 탁월합니다:
| 벤치마크 | 0-샷 AP | 10-샷 AP | 이전 최고 기록 (10-샷) |
|---|---|---|---|
| ODinW13 | 59.9 | 71.6 | 67.9 (gDino1.5-Pro) |
| RF100-VL | 14.3 | 35.7 | 33.7 (gDino-T) |
Link to this section대화형 개선 효율성#
예시를 포함한 SAM 3의 개념 기반 프롬프팅은 시각적 프롬프팅보다 훨씬 빠르게 수렴합니다:
| 추가된 프롬프트 | CGF1 점수 | 텍스트 전용 대비 향상 | PVS 기준 대비 향상 |
|---|---|---|---|
| 텍스트 전용 | 46.4 | 기준 | 기준 |
| +1 예시 | 57.6 | +11.2 | +6.7 |
| +2 예시 | 62.2 | +15.8 | +9.7 |
| +3 예시 | 65.0 | +18.6 | +11.2 |
| +4 예시 | 65.7 | +19.3 | +11.5 (고원 현상) |
Link to this section객체 계수 정확도#
SAM 3는 객체 계수에서 흔히 요구되는 모든 인스턴스를 세분화하여 정확한 계수를 제공합니다:
| 벤치마크 | 정확도 | MAE | 최고 MLLM 대비 |
|---|---|---|---|
| CountBench | 95.6% | 0.11 | 92.4% (Gemini 2.5) |
| PixMo-Count | 87.3% | 0.22 | 88.8% (Molmo-72B) |
Link to this sectionSAM 3, SAM 2 및 YOLO 비교#
여기에서는 SAM 3의 기능을 SAM 2 및 YOLO26 모델과 비교합니다:
| 기능 | SAM 3 | SAM 2 | YOLO26n-seg |
|---|---|---|---|
| 개념 세분화 | ✅ 텍스트/예시를 통한 모든 인스턴스 | ❌ 지원 안 함 | ❌ 지원 안 함 |
| 시각적 세분화 | ✅ 단일 인스턴스 (SAM 2 호환) | ✅ 단일 인스턴스 | ✅ 모든 인스턴스 |
| 제로샷 기능 | ✅ 오픈 어휘 | ✅ 기하학적 프롬프트 | ❌ 폐쇄형 세트 |
| 대화형 정교화 | ✅ 예시 + 클릭 | ✅ 클릭 전용 | ❌ 지원 안 함 |
| 비디오 추적 | ✅ 식별자를 포함한 다중 객체 | ✅ 다중 객체 | ✅ 다중 객체 |
| LVIS Mask AP (제로샷) | 47.0 | 해당 없음 | 해당 없음 |
| MOSEv2 J&F | 60.1 | 47.9 | 해당 없음 |
| 속도 (GPU, ms/im) | 2921 | 857 | 8.4 |
| 모델 크기 | 3.45 GB | 162 MB (base) | 6.4 MB |
torch==2.9.1 및 ultralytics==8.4.19를 사용하는 NVIDIA RTX PRO 6000에서 벤치마킹된 속도입니다.
핵심 요약:
- SAM 3: 오픈 어휘 개념 세분화에 가장 적합하며, 텍스트 또는 예시 프롬프트를 사용하여 개념의 모든 인스턴스를 찾습니다.
- SAM 2: 기하학적 프롬프트를 사용하여 이미지 및 비디오에서 대화형 단일 객체 세분화에 가장 적합합니다.
- YOLO26: NMS 없는 엔드투엔드 추론으로 실시간 고속 세분화에 가장 적합하며, GPU, CPU 및 엣지 장치에 배포하기 위해 다양한 형식으로 내보내기가 가능합니다.
Link to this sectionSAM과 YOLO 비교#
크기, 매개변수 및 GPU 추론 속도 면에서 Ultralytics YOLO 세분화 모델(YOLOv8, YOLO11, YOLO26)과 SAM 3, SAM 2, SAM, MobileSAM, FastSAM을 비교합니다:
| 모델 | 크기 (MB) | 매개변수 (M) | 속도 (GPU) (ms/im) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 1306 |
| Meta SAM2-b | 162 | 80.8 | 857 |
| Meta SAM2-t | 78.1 | 38.9 | 668 |
| Meta SAM3 | 3450 | 473.6 | 2921 |
| MobileSAM | 40.7 | 10.1 | 605 |
| FastSAM-s with YOLOv8 backbone | 23.7 | 11.8 | 55.9 |
| Ultralytics YOLOv8n-seg | 6.7 (515배 작음) | 3.4 (139.1배 적음) | 17.4 (167배 빠름) |
| Ultralytics YOLO11n-seg | 5.9 (585배 작음) | 2.9 (163.1배 적음) | 12.6 (231배 빠름) |
| Ultralytics YOLO26n-seg | 6.4 (539배 작음) | 2.7 (175.2배 적음) | 8.4 (347배 빠름) |
이 비교는 SAM 변형 모델과 YOLO 세그멘테이션 모델 간의 모델 크기와 속도에 대한 상당한 차이를 보여줍니다. SAM이 고유한 자동 세그멘테이션 기능을 제공하는 반면, YOLO 모델(특히 YOLOv8n-seg, YOLO11n-seg 및 YOLO26n-seg)은 훨씬 작고 빠르며 계산 효율성이 뛰어납니다.
torch==2.9.1 및 ultralytics==8.4.19를 사용하여 96GB VRAM이 장착된 NVIDIA RTX PRO 6000에서 실행된 테스트입니다. 이 테스트를 재현하려면:
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# Profile SAM3, SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt", "sam3.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# Profile FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# Profile YOLO models
for file_name in ["yolov8n-seg.pt", "yolo11n-seg.pt", "yolo26n-seg.pt"]:
model = YOLO(file_name)
model.info()
model(ASSETS)Link to this section평가 지표#
SAM 3는 F1 점수, 정밀도 및 재현율과 같은 익숙한 측정값을 보완하는 PCS 작업용으로 설계된 새로운 지표를 도입했습니다.
Link to this section분류 기반 F1 (CGF1)#
위치 파악과 분류를 결합한 주요 지표:
CGF1 = 100 × pmF1 × IL_MCC
구문 설명:
- pmF1 (양수 매크로 F1): 양수 예제에서의 위치 파악 품질 측정
- IL_MCC (이미지 수준 매튜 상관 계수): 이진 분류 정확도 측정 ("개념이 존재하는가?")
Link to this section왜 이 지표인가?#
전통적인 AP 지표는 보정을 고려하지 않아 실제 환경에서 모델을 사용하기 어렵게 만듭니다. 0.5 신뢰도 이상의 예측만 평가함으로써 SAM 3의 지표는 우수한 보정을 강제하며, 대화형 predict 및 track 루프에서의 실제 사용 패턴을 모방합니다.
Link to this section주요 어블레이션 및 인사이트#
Link to this section존재 헤드의 영향#
존재 헤드는 인식과 위치 파악을 분리하여 상당한 개선을 제공합니다:
| 설정 | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 존재 헤드 없음 | 57.6 | 0.77 | 74.7 |
| 존재 헤드 포함 | 63.3 | 0.82 | 77.1 |
존재 헤드는 +5.7 CGF1 향상 (+9.9%)을 제공하며, 주로 인식 능력(IL_MCC +6.5%)을 개선합니다.
Link to this section하드 네거티브의 효과#
| 하드 네거티브(Hard Negatives)/이미지 | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 0 | 31.8 | 0.44 | 70.2 |
| 5 | 44.8 | 0.62 | 71.9 |
| 30 | 49.2 | 0.68 | 72.3 |
하드 네거티브는 오픈 어휘 인식(open-vocabulary recognition)에 매우 중요하며, IL_MCC를 54.5%(0.44 → 0.68) 향상시킵니다.
Link to this section학습 데이터 확장#
| 데이터 소스 | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 외부 데이터만 사용 | 30.9 | 0.46 | 66.3 |
| 외부 + 합성 데이터 | 39.7 | 0.57 | 70.6 |
| 외부 + HQ 데이터 | 51.8 | 0.71 | 73.2 |
| 세 가지 모두 | 54.3 | 0.74 | 73.5 |
고품질 인간 주석은 합성 또는 외부 데이터만 사용할 때보다 큰 성능 향상을 제공합니다. 데이터 품질 관리에 대한 배경 지식은 데이터 수집 및 주석을 참조하십시오.
Link to this section응용 분야#
SAM 3의 개념 분할(concept segmentation) 기능은 새로운 활용 사례를 가능하게 합니다:
- 콘텐츠 조정(Content Moderation): 미디어 라이브러리 전체에서 특정 콘텐츠 유형의 모든 사례를 찾습니다.
- E-commerce: 카탈로그 이미지에서 특정 유형의 모든 제품을 세그먼트하며, auto-annotation을 지원합니다.
- 의료 영상: 특정 조직 유형이나 이상 증상의 모든 발생 사례를 식별합니다.
- 자율 시스템: 교통 표지판, 보행자 또는 차량의 모든 사례를 카테고리별로 추적합니다.
- 영상 분석: 특정 의상을 입거나 특정 행동을 수행하는 모든 사람을 계수하고 추적합니다.
- 데이터셋 주석: 희귀 객체 카테고리의 모든 사례를 신속하게 주석 처리합니다.
- 과학 연구: 특정 기준에 부합하는 모든 표본을 정량화하고 분석합니다.
Link to this sectionSAM 3 에이전트: 확장된 언어 추론#
SAM 3는 OWLv2 및 T-Rex와 같은 오픈 어휘 시스템과 유사한 원리로, 추론이 필요한 복잡한 쿼리를 처리하기 위해 멀티모달 대규모 언어 모델(MLLM)과 결합할 수 있습니다.
Link to this section추론 작업 성능#
| 벤치마크 | 지표 | SAM 3 에이전트 (Gemini 2.5 Pro) | 이전 최고 기록 |
|---|---|---|---|
| ReasonSeg (검증) | gIoU | 76.0 | 65.0 (SoTA) |
| ReasonSeg (테스트) | gIoU | 73.8 | 61.3 (SoTA) |
| OmniLabel (검증) | 아시아 태평양(AP) | 46.7 | 36.5 (REAL) |
| RefCOCO+ | Acc | 91.2 | 89.3 (LISA) |
Link to this section복잡한 쿼리 예시#
SAM 3 에이전트는 추론이 필요한 쿼리를 처리할 수 있습니다:
- "앉아 있지만 손에 선물 상자를 들고 있지 않은 사람들"
- "카메라와 가장 가깝고 목걸이를 착용하지 않은 개"
- "사람의 손보다 큰 빨간색 물체"
MLLM은 SAM 3에 간단한 명사구 쿼리를 제안하고, 반환된 마스크를 분석하며 만족스러운 결과가 나올 때까지 반복합니다.
Link to this section한계점#
SAM 3는 큰 발전을 이루었지만, 다음과 같은 특정 한계가 있습니다:
- 구문 복잡성: 간단한 명사구에 가장 적합하며, 긴 참조 표현이나 복잡한 추론은 MLLM 통합이 필요할 수 있습니다.
- 모호성 처리: 일부 개념은 본질적으로 모호합니다(예: "작은 창문", "아늑한 방").
- 연산 요구 사항: YOLO와 같은 특화된 탐지 모델보다 더 크고 느립니다.
- 어휘 범위: 원자적 시각적 개념에 초점을 맞추고 있으며, MLLM 지원 없이는 구성적 추론에 한계가 있습니다.
- 희귀 개념: 학습 데이터에 충분히 표현되지 않은 매우 희귀하거나 세분화된 개념에서는 성능이 저하될 수 있습니다.
Link to this section인용#
@inproceedings{sam3_2025,
title = {SAM 3: Segment Anything with Concepts},
author = {Anonymous authors},
booktitle = {Submitted to ICLR 2026},
year = {2025},
url = {https://openreview.net/forum?id=r35clVtGzw},
note = {Paper ID: 4183, under double-blind review}
}Link to this sectionFAQ#
Link to this sectionSAM 3는 언제 출시되었습니까?#
SAM 3는 Meta에 의해 2025년 11월 20일에 출시되었으며, 버전 8.3.237(PR #22897)부터 Ultralytics에 완전히 통합되었습니다. 예측 모드 및 추적 모드에 대한 전체 지원을 제공합니다.
Link to this sectionSAM 3가 Ultralytics에 통합되어 있습니까?#
Yes! SAM 3 is fully integrated into the Ultralytics Python package, including concept segmentation, SAM 2–style visual prompts, and multi-object video tracking. SAM 3 also powers the smart annotation feature on Ultralytics Platform, where you can annotate images with just a few clicks.
Link to this section프롬프트 기반 개념 분할(PCS)이란 무엇입니까?#
PCS는 SAM 3에서 도입된 새로운 작업으로, 이미지나 영상 내의 모든 시각적 개념 사례를 분할합니다. 특정 객체 인스턴스를 대상으로 하는 기존의 분할 방식과 달리, PCS는 카테고리의 모든 발생 사례를 찾습니다. 예를 들어:
- 텍스트 프롬프트: "노란색 스쿨버스" → 장면 내의 모든 노란색 스쿨버스 분할
- 이미지 예시(exemplar): 개 주위에 상자 표시 → 이미지 내의 모든 개 분할
- 결합: "줄무늬 고양이" + 예시 상자 → 예시와 일치하는 모든 줄무늬 고양이 분할
객체 탐지 및 인스턴스 분할에 대한 관련 배경 지식을 참조하십시오.
Link to this sectionSAM 3는 SAM 2와 어떻게 다릅니까?#
| 기능 | SAM 2 | SAM 3 |
|---|---|---|
| 작업 | 프롬프트당 단일 객체 | 개념의 모든 사례 |
| 프롬프트 유형 | 포인트, 박스, 마스크 | 텍스트 구문, 이미지 예시 |
| 탐지 기능 | 외부 탐지기 필요 | 내장형 오픈 어휘 탐지기 |
| 인식 | 기하학 기반 전용 | 텍스트 및 시각적 인식 |
| 아키텍처 | 추적기 전용 | 존재 헤드가 있는 탐지기 + 추적기 |
| 제로샷 성능 | 해당 없음 (시각적 프롬프트 필요) | LVIS에서 47.0 AP, SA-Co에서 2배 더 나은 성능 |
| 대화형 정교화 | 클릭 전용 | 클릭 + 예시 일반화 |
SAM 3는 SAM 2의 시각적 프롬프트 기능에 대한 하위 호환성을 유지하면서 개념 기반 기능을 추가했습니다.
Link to this sectionSAM 3 학습에는 어떤 데이터셋이 사용됩니까?#
SAM 3는 Segment Anything with Concepts (SA-Co) 데이터셋으로 학습되었습니다.
학습 데이터:
- 520만 장의 이미지와 400만 개의 고유 명사구(SA-Co/HQ) - 고품질 인간 주석
- 5만 2,500개의 동영상과 2만 4,800개의 고유 명사구(SA-Co/VIDEO)
- 3,800만 개의 명사구에 걸친 14억 개의 합성 마스크(SA-Co/SYN)
- Hard Negative로 보강된 15개의 외부 데이터셋(SA-Co/EXT)
벤치마크 데이터:
- 12만 6,000개의 이미지/동영상에 걸친 21만 4,000개의 고유 개념
- 기존 벤치마크 대비 50배 더 많은 개념(예: LVIS는 약 4,000개의 개념 보유)
- 인간 성능 한계 측정을 위한 SA-Co/Gold의 3중 주석
이러한 방대한 규모와 다양성 덕분에 SAM 3는 오픈 어휘 개념 전반에서 뛰어난 제로샷 일반화 성능을 제공합니다.
Link to this section세그멘테이션 작업에서 SAM 3는 YOLO26과 어떻게 비교됩니까?#
SAM 3와 YOLO26은 서로 다른 사용 사례를 제공합니다:
SAM 3의 장점:
- 오픈 어휘: 학습 없이 텍스트 프롬프트를 통해 모든 개념을 세그멘테이션
- 제로샷: 새로운 카테고리에 즉시 작동
- 대화형: 예시 기반 개선으로 유사한 객체로 일반화 가능
- 개념 기반: 특정 카테고리의 모든 인스턴스를 자동으로 검색
- 정확도: LVIS 제로샷 인스턴스 세그멘테이션에서 47.0 AP 달성
YOLO26의 장점:
- 속도: NMS가 필요 없는 엔드투엔드 설계로 몇 배 더 빠른 추론
- 효율성: 539배 더 작은 모델(6.4MB 대 3.45GB)
- 리소스 친화적: 엣지 디바이스 및 모바일에서 실행 가능
- 실시간: 프로덕션 배포에 최적화
권장 사항:
- 텍스트나 예시로 설명된 개념의 모든 인스턴스를 찾아야 하는 유연한 오픈 어휘 세그멘테이션에는 SAM 3를 사용하십시오.
- 카테고리가 사전에 알려진 고속 프로덕션 배포에는 YOLO26을 사용하십시오.
- 기하학적 프롬프트를 사용하는 대화형 단일 객체 세그멘테이션에는 SAM 2를 사용하십시오.
Link to this sectionSAM 3는 복잡한 언어 쿼리를 처리할 수 있습니까?#
SAM 3는 간단한 명사구(예: "빨간 사과", "모자를 쓴 사람")를 위해 설계되었습니다. 추론이 필요한 복잡한 쿼리의 경우, SAM 3를 MLLM과 결합하여 SAM 3 Agent로 사용하십시오:
간단한 쿼리(기본 SAM 3):
- "노란색 스쿨버스"
- "줄무늬 고양이"
- "빨간 모자를 쓴 사람"
복잡한 쿼리(MLLM을 결합한 SAM 3 Agent):
- "앉아 있지만 선물 상자를 들고 있지 않은 사람들"
- "목걸이를 하지 않은 카메라에서 가장 가까운 개"
- "사람의 손보다 큰 빨간색 물체"
SAM 3 Agent는 SAM 3의 세그멘테이션과 MLLM의 추론 능력을 결합하여 ReasonSeg 검증에서 76.0 gIoU를 달성했습니다(기존 최고 기록 65.0 대비 16.9% 향상).
Link to this sectionSAM 3의 정확도는 인간의 성능과 비교했을 때 어느 정도입니까?#
3중 인간 주석이 포함된 SA-Co/Gold 벤치마크 기준:
- 인간 하한치: 74.2 CGF1(가장 보수적인 주석자)
- SAM 3 성능: 65.0 CGF1
- 성과: 추정된 인간 하한치의 88% 달성
- 인간 상한치: 81.4 CGF1(가장 관대한 주석자)
SAM 3는 오픈 어휘 개념 세그멘테이션에서 인간 수준의 정확도에 근접하는 강력한 성능을 달성했으며, 격차는 주로 모호하거나 주관적인 개념(예: "작은 창문", "아늑한 방")에서 나타납니다.