Link to this sectionSAM 3: Segment Anything with Concepts#
SAM 3 is fully integrated into the Ultralytics package as of version 8.3.237 (PR #22897). Install or upgrade with pip install -U ultralytics to access all SAM 3 features including text-based concept segmentation, image exemplar prompts, and video tracking.
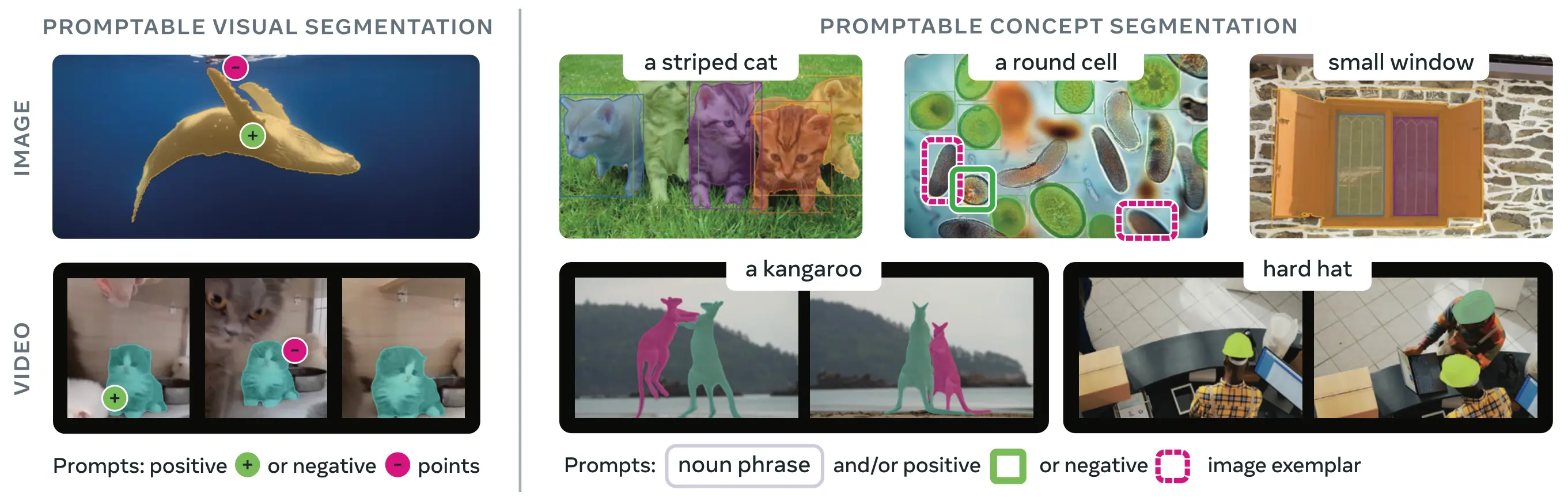
SAM 3 (Segment Anything Model 3) is Meta's released foundation model for Promptable Concept Segmentation (PCS). Building upon SAM 2, SAM 3 introduces a fundamentally new capability: detecting, segmenting, and tracking all instances of a visual concept specified by text prompts, image exemplars, or both. Unlike previous SAM versions that segment single objects per prompt, SAM 3 can find and segment every occurrence of a concept appearing anywhere in images or videos, aligning with open-vocabulary goals in modern instance segmentation.
Watch: How to Use Meta Segment Anything 3 with Ultralytics | Text-Prompt Segmentation on Images & Videos
SAM 3 is now fully integrated into the ultralytics package, providing native support for concept segmentation with text prompts, image exemplar prompts, and video tracking capabilities.
Link to this sectionOverview#
SAM 3 achieves a 2× performance gain over existing systems in Promptable Concept Segmentation while maintaining and improving SAM 2's capabilities for interactive visual segmentation. The model excels at open-vocabulary segmentation, allowing users to specify concepts using simple noun phrases (e.g., "yellow school bus", "striped cat") or by providing example images of the target object. These capabilities complement production-ready pipelines that rely on streamlined predict and track workflows.
Link to this sectionWhat is Promptable Concept Segmentation (PCS)?#
The PCS task takes a concept prompt as input and returns segmentation masks with unique identities for all matching object instances. Concept prompts can be:
- Text: Simple noun phrases like "red apple" or "person wearing a hat", similar to zero-shot learning
- Image exemplars: Bounding boxes around example objects (positive or negative) for fast generalization
- Combined: Both text and image exemplars together for precise control
This differs from traditional visual prompts (points, boxes, masks) which segment only a single specific object instance, as popularized by the original SAM family.
Link to this sectionKey Performance Metrics#
| Metric | SAM 3 Achievement |
|---|---|
| LVIS Zero-Shot Mask AP | 47.0 (vs previous best 38.5, +22% improvement) |
| SA-Co Benchmark | 2× better than existing systems |
| Inference Speed (H200 GPU) | 30 ms per image with 100+ detected objects |
| Video Performance | Near real-time for ~5 concurrent objects |
| MOSEv2 VOS Benchmark | 60.1 J&F (+25.5% over SAM 2.1, +17% over prior SOTA) |
| Interactive Refinement | +18.6 CGF1 improvement after 3 exemplar prompts |
| Human Performance Gap | Achieves 88% of estimated lower bound on SA-Co/Gold |
For context on model metrics and trade-offs in production, see model evaluation insights and YOLO performance metrics.
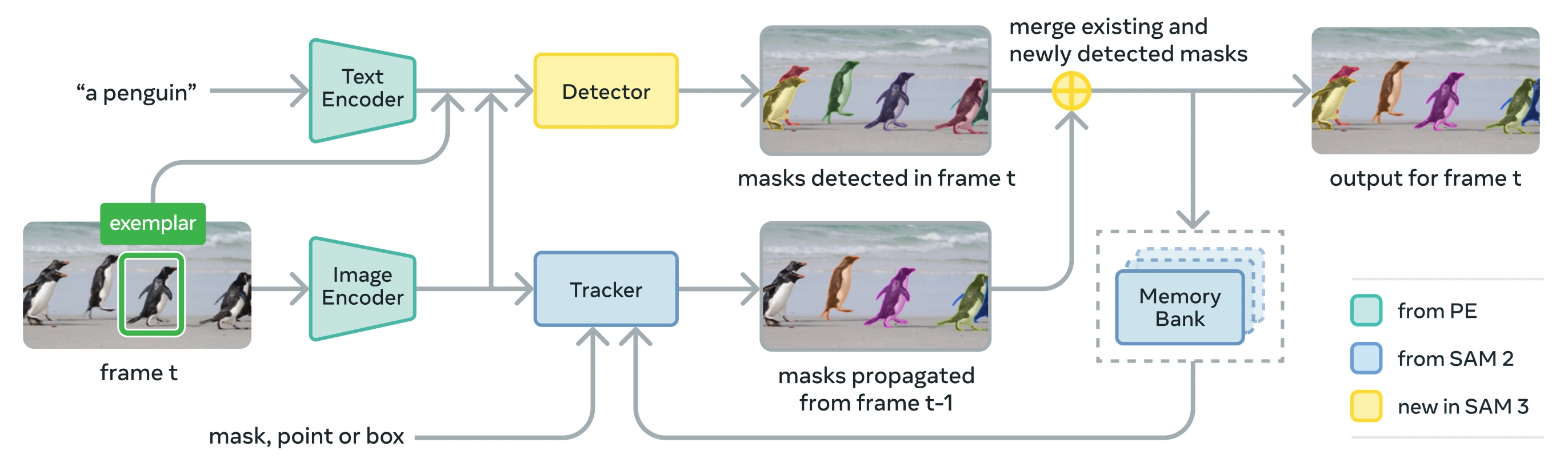
Link to this sectionArchitecture#
SAM 3 consists of a detector and tracker that share a Perception Encoder (PE) vision backbone. This decoupled design avoids task conflicts while enabling both image-level detection and video-level tracking, with an interface compatible with Ultralytics Python usage and CLI usage.
Link to this sectionCore Components#
-
Detector: DETR-based architecture for image-level concept detection
- Text encoder for noun phrase prompts
- Exemplar encoder for image-based prompts
- Fusion encoder to condition image features on prompts
- Novel presence head that decouples recognition ("what") from localization ("where")
- Mask head for generating instance segmentation masks
-
Tracker: Memory-based video segmentation inherited from SAM 2
- Prompt encoder, mask decoder, memory encoder
- Memory bank for storing object appearance across frames
- Temporal disambiguation aided by techniques like a Kalman filter in multi-object settings
-
Presence Token: A learned global token that predicts whether the target concept is present in the image/frame, improving detection by separating recognition from localization.
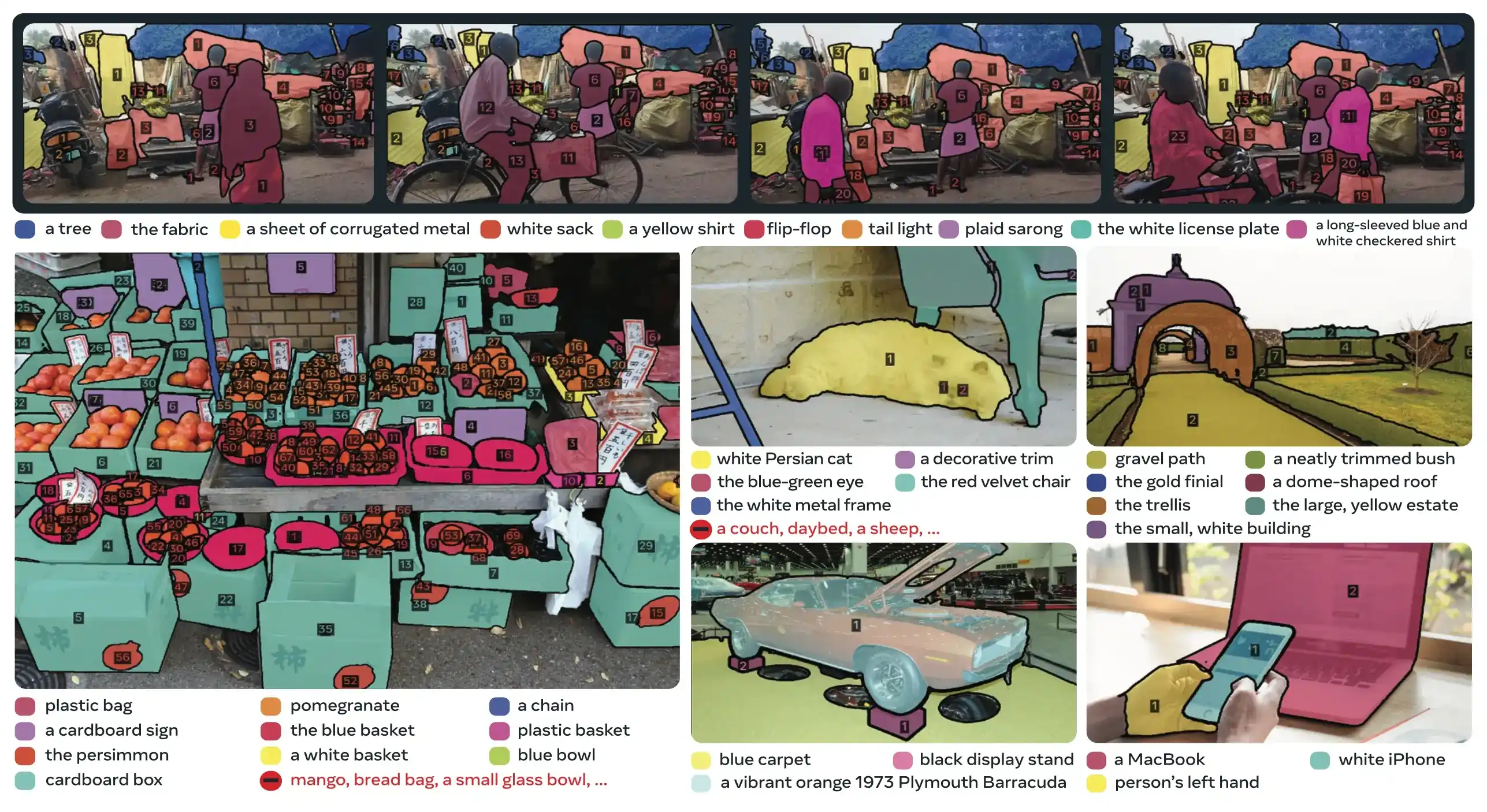
Link to this sectionKey Innovations#
- Decoupled Recognition and Localization: The presence head predicts concept presence globally, while proposal queries focus only on localization, avoiding conflicting objectives.
- Unified Concept and Visual Prompts: Supports both PCS (concept prompts) and PVS (visual prompts like SAM 2's clicks/boxes) in a single model.
- Interactive Exemplar Refinement: Users can add positive or negative image exemplars to iteratively refine results, with the model generalizing to similar objects rather than just correcting individual instances.
- Temporal Disambiguation: Uses masklet detection scores and periodic re-prompting to handle occlusions, crowded scenes, and tracking failures in video, aligning with instance segmentation and tracking best practices.
Link to this sectionSA-Co Dataset#
SAM 3 is trained on Segment Anything with Concepts (SA-Co), Meta's largest and most diverse segmentation dataset to date, expanding beyond common benchmarks like COCO and LVIS.
Link to this sectionTraining Data#
| Dataset Component | Description | Scale |
|---|---|---|
| SA-Co/HQ | High-quality human-annotated image data from 4-phase data engine | 5.2M images, 4M unique noun phrases |
| SA-Co/SYN | Synthetic dataset labeled by AI without human involvement | 38M noun phrases, 1.4B masks |
| SA-Co/EXT | 15 external datasets enriched with hard negatives | Varies by source |
| SA-Co/VIDEO | Video annotations with temporal tracking | 52.5K videos, 24.8K unique noun phrases |
Link to this sectionBenchmark Data#
The SA-Co evaluation benchmark contains 214K unique phrases across 126K images and videos, providing over 50× more concepts than existing benchmarks. It includes:
- SA-Co/Gold: 7 domains, triple-annotated for measuring human performance bounds
- SA-Co/Silver: 10 domains, single human annotation
- SA-Co/Bronze and SA-Co/Bio: 9 existing datasets adapted for concept segmentation
- SA-Co/VEval: Video benchmark with 3 domains (SA-V, YT-Temporal-1B, SmartGlasses)
Link to this sectionData Engine Innovations#
SAM 3's scalable human- and model-in-the-loop data engine achieves 2× annotation throughput through:
- AI Annotators: Llama based models propose diverse noun phrases including hard negatives
- AI Verifiers: Fine-tuned multimodal LLMs verify mask quality and exhaustivity at near-human performance
- Active Mining: Focuses human effort on challenging failure cases where AI struggles
- Ontology-Driven: Leverages a large ontology grounded in Wikidata for concept coverage
Link to this sectionInstallation#
SAM 3 is available in Ultralytics version 8.3.237 and later. Install or upgrade with:
pip install -U ultralyticsUnlike other Ultralytics models, SAM 3 weights (sam3.pt) are not automatically downloaded. You must first request access for the model weights on the SAM 3 model page on Hugging Face and then, once approved, download sam3.pt from that page. Place the downloaded sam3.pt file in your working directory or specify the full path when loading the model.
If you get the above error during prediction, it means you have the incorrect clip package installed. Install the correct clip package by running the following:
pip uninstall clip -y
pip install git+https://github.com/ultralytics/CLIP.gitLink to this sectionHow to Use SAM 3: Versatility in Concept Segmentation#
SAM 3 supports both Promptable Concept Segmentation (PCS) and Promptable Visual Segmentation (PVS) tasks through different predictor interfaces:
Link to this sectionSupported Tasks and Models#
| Task Type | Prompt Types | Output |
|---|---|---|
| Concept Segmentation (PCS) | Text (noun phrases), image exemplars | All instances matching the concept |
| Visual Segmentation (PVS) | Points, boxes, masks | Single object instance (SAM 2 style) |
| Interactive Refinement | Add/remove exemplars or clicks iteratively | Refined segmentation with improved accuracy |
Link to this sectionConcept Segmentation Examples#
Link to this sectionSegment with Text Prompts#
Find and segment all instances of a concept using a text description. Text prompts require the SAM3SemanticPredictor interface.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor with configuration
overrides = dict(
conf=0.25,
task="segment",
mode="predict",
model="sam3.pt",
quantize=16, # Use FP16 for faster inference
save=True,
)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image once for multiple queries
predictor.set_image("path/to/image.jpg")
# Query with multiple text prompts
results = predictor(text=["person", "bus", "glasses"])
# Works with descriptive phrases
results = predictor(text=["person with red cloth", "person with blue cloth"])
# Query with a single concept
results = predictor(text=["a person"])Link to this sectionSegment with Image Exemplars#
Use bounding boxes as visual prompts to find all similar instances. This also requires SAM3SemanticPredictor for concept-based matching.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16, save=True)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image
predictor.set_image("path/to/image.jpg")
# Provide bounding box examples to segment similar objects
results = predictor(bboxes=[[480.0, 290.0, 590.0, 650.0]])
# Multiple bounding boxes as exemplars of the same visual concept
results = predictor(bboxes=[[539, 599, 589, 639], [343, 267, 499, 662]])Link to this sectionFeature-based Inference for Efficiency#
Extract image features once and reuse them for multiple segmentation queries to improve efficiency.
import cv2
from ultralytics.models.sam import SAM3SemanticPredictor
from ultralytics.utils.plotting import Annotator, colors
# Initialize predictors
overrides = dict(conf=0.50, task="segment", mode="predict", model="sam3.pt", verbose=False)
predictor = SAM3SemanticPredictor(overrides=overrides)
predictor2 = SAM3SemanticPredictor(overrides=overrides)
# Extract features from the first predictor
source = "path/to/image.jpg"
predictor.set_image(source)
src_shape = cv2.imread(source).shape[:2]
# Setup second predictor and reuse features
predictor2.setup_model()
# Perform inference using shared features with text prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, text=["person"])
# Perform inference using shared features with bounding box prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, bboxes=[[439, 437, 524, 709]])
# Visualize results
if masks is not None:
masks, boxes = masks.cpu().numpy(), boxes.cpu().numpy()
im = cv2.imread(source)
annotator = Annotator(im, pil=False)
annotator.masks(masks, [colors(x, True) for x in range(len(masks))])
cv2.imshow("result", annotator.result())
cv2.waitKey(0)Link to this sectionVideo Concept Segmentation#
Link to this sectionTrack Concepts Across Video with Bounding Boxes#
Detect and track object instances across video frames using bounding box prompts.
from ultralytics.models.sam import SAM3VideoPredictor
# Create video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16)
predictor = SAM3VideoPredictor(overrides=overrides)
# Track objects using bounding box prompts
results = predictor(source="path/to/video.mp4", bboxes=[[706.5, 442.5, 905.25, 555], [598, 635, 725, 750]], stream=True)
# Process and display results
for r in results:
r.show() # Display frame with segmentation masksLink to this sectionTrack Concepts with Text Prompts#
Track all instances of concepts specified by text across video frames.
from ultralytics.models.sam import SAM3VideoSemanticPredictor
# Initialize semantic video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=640, model="sam3.pt", quantize=16, save=True)
predictor = SAM3VideoSemanticPredictor(overrides=overrides)
# Track concepts using text prompts
results = predictor(source="path/to/video.mp4", text=["person", "bicycle"], stream=True)
# Process results
for r in results:
r.show() # Display frame with tracked objects
# Alternative: Track with bounding box prompts
results = predictor(
source="path/to/video.mp4",
bboxes=[[864, 383, 975, 620], [705, 229, 782, 402]],
labels=[1, 1], # Positive labels
stream=True,
)Link to this sectionVisual Prompts (SAM 2 Compatibility)#
SAM 3 maintains full backward compatibility with SAM 2's visual prompting for single-object segmentation:
The basic SAM interface behaves exactly like SAM 2, segmenting only the specific area indicated by visual prompts (points, boxes, or masks).
from ultralytics import SAM
model = SAM("sam3.pt")
# Single point prompt - segments object at specific location
results = model.predict(source="path/to/image.jpg", points=[900, 370], labels=[1])
results[0].show()
# Multiple points - segments single object with multiple point hints
results = model.predict(source="path/to/image.jpg", points=[[400, 370], [900, 370]], labels=[1, 1])
# Box prompt - segments object within bounding box
results = model.predict(source="path/to/image.jpg", bboxes=[100, 150, 300, 400])
results[0].show()Using SAM("sam3.pt") with visual prompts (points/boxes/masks) will segment only the specific object at that location, just like SAM 2. To segment all instances of a concept, use SAM3SemanticPredictor with text or exemplar prompts as shown above.
Link to this sectionPerformance Benchmarks#
Link to this sectionImage Segmentation#
SAM 3 achieves state-of-the-art results across multiple benchmarks, including real-world datasets like LVIS and COCO for segmentation:
| Benchmark | Metric | SAM 3 | Previous Best | Improvement |
|---|---|---|---|---|
| LVIS (zero-shot) | Mask AP | 47.0 | 38.5 | +22.1% |
| SA-Co/Gold | CGF1 | 65.0 | 34.3 (OWLv2) | +89.5% |
| COCO (zero-shot) | Box AP | 53.5 | 52.2 (T-Rex2) | +2.5% |
| ADE-847 (semantic seg) | mIoU | 14.7 | 9.2 (APE-D) | +59.8% |
| PascalConcept-59 | mIoU | 59.4 | 58.5 (APE-D) | +1.5% |
| Cityscapes (semantic seg) | mIoU | 65.1 | 44.2 (APE-D) | +47.3% |
Explore dataset options for quick experimentation in Ultralytics datasets.
Link to this sectionVideo Segmentation Performance#
SAM 3 shows significant improvements over SAM 2 and prior state-of-the-art across video benchmarks such as DAVIS 2017 and YouTube-VOS:
| Benchmark | Metric | SAM 3 | SAM 2.1 L | Improvement |
|---|---|---|---|---|
| MOSEv2 | J&F | 60.1 | 47.9 | +25.5% |
| DAVIS 2017 | J&F | 92.0 | 90.7 | +1.4% |
| LVOSv2 | J&F | 88.2 | 79.6 | +10.8% |
| SA-V | J&F | 84.6 | 78.4 | +7.9% |
| YTVOS19 | J&F | 89.6 | 89.3 | +0.3% |
Link to this sectionFew-Shot Adaptation#
SAM 3 excels at adapting to new domains with minimal examples, relevant for data-centric AI workflows:
| Benchmark | 0-shot AP | 10-shot AP | Previous Best (10-shot) |
|---|---|---|---|
| ODinW13 | 59.9 | 71.6 | 67.9 (gDino1.5-Pro) |
| RF100-VL | 14.3 | 35.7 | 33.7 (gDino-T) |
Link to this sectionInteractive Refinement Effectiveness#
SAM 3's concept-based prompting with exemplars converges much faster than visual prompting:
| Prompts Added | CGF1 Score | Gain vs Text-Only | Gain vs PVS Baseline |
|---|---|---|---|
| Text only | 46.4 | baseline | baseline |
| +1 exemplar | 57.6 | +11.2 | +6.7 |
| +2 exemplars | 62.2 | +15.8 | +9.7 |
| +3 exemplars | 65.0 | +18.6 | +11.2 |
| +4 exemplars | 65.7 | +19.3 | +11.5 (plateau) |
Link to this sectionObject Counting Accuracy#
SAM 3 provides accurate counting by segmenting all instances, a common requirement in object counting:
| Benchmark | Accuracy | MAE | vs Best MLLM |
|---|---|---|---|
| CountBench | 95.6% | 0.11 | 92.4% (Gemini 2.5) |
| PixMo-Count | 87.3% | 0.22 | 88.8% (Molmo-72B) |
Link to this sectionSAM 3 vs SAM 2 vs YOLO Comparison#
Here we compare SAM 3's capabilities with SAM 2 and YOLO26 models:
| Capability | SAM 3 | SAM 2 | YOLO26n-seg |
|---|---|---|---|
| Concept Segmentation | ✅ All instances from text/exemplars | ❌ Not supported | ❌ Not supported |
| Visual Segmentation | ✅ Single instance (SAM 2 compatible) | ✅ Single instance | ✅ All instances |
| Zero-shot Capability | ✅ Open vocabulary | ✅ Geometric prompts | ❌ Closed set |
| Interactive Refinement | ✅ Exemplars + clicks | ✅ Clicks only | ❌ Not supported |
| Video Tracking | ✅ Multi-object with identities | ✅ Multi-object | ✅ Multi-object |
| LVIS Mask AP (zero-shot) | 47.0 | N/A | N/A |
| MOSEv2 J&F | 60.1 | 47.9 | N/A |
| Speed (GPU, ms/im) | 2921 | 857 | 8.4 |
| Model Size | 3.45 GB | 162 MB (base) | 6.4 MB |
Speed benchmarked on NVIDIA RTX PRO 6000 with torch==2.9.1 and ultralytics==8.4.19.
Key Takeaways:
- SAM 3: Best for open-vocabulary concept segmentation, finding all instances of a concept with text or exemplar prompts
- SAM 2: Best for interactive single-object segmentation in images and videos with geometric prompts
- YOLO26: Best for real-time, high-speed segmentation with NMS-free end-to-end inference, exportable to many formats for deployment on GPUs, CPUs, and edge devices
Link to this sectionSAM Comparison vs YOLO#
Comparing SAM 3, SAM 2, SAM, MobileSAM, and FastSAM against Ultralytics YOLO segmentation models (YOLOv8, YOLO11, YOLO26) in size, parameters, and GPU inference speed:
| Model | Size (MB) | Parameters (M) | Speed (GPU) (ms/im) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 1306 |
| Meta SAM2-b | 162 | 80.8 | 857 |
| Meta SAM2-t | 78.1 | 38.9 | 668 |
| Meta SAM3 | 3450 | 473.6 | 2921 |
| MobileSAM | 40.7 | 10.1 | 605 |
| FastSAM-s with YOLOv8 backbone | 23.7 | 11.8 | 55.9 |
| Ultralytics YOLOv8n-seg | 6.7 (515x smaller) | 3.4 (139.1x less) | 17.4 (167x faster) |
| Ultralytics YOLO11n-seg | 5.9 (585x smaller) | 2.9 (163.1x less) | 12.6 (231x faster) |
| Ultralytics YOLO26n-seg | 6.4 (539x smaller) | 2.7 (175.2x less) | 8.4 (347x faster) |
This comparison demonstrates the substantial differences in model sizes and speeds between SAM variants and YOLO segmentation models. While SAM provides unique automatic segmentation capabilities, YOLO models, particularly YOLOv8n-seg, YOLO11n-seg and YOLO26n-seg, are significantly smaller, faster, and more computationally efficient.
Tests run on a NVIDIA RTX PRO 6000 with 96GB of VRAM using torch==2.9.1 and ultralytics==8.4.19. To reproduce this test:
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# Profile SAM3, SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt", "sam3.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# Profile FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# Profile YOLO models
for file_name in ["yolov8n-seg.pt", "yolo11n-seg.pt", "yolo26n-seg.pt"]:
model = YOLO(file_name)
model.info()
model(ASSETS)Link to this sectionEvaluation Metrics#
SAM 3 introduces new metrics designed for the PCS task, complementing familiar measures like F1 score, precision, and recall.
Link to this sectionClassification-Gated F1 (CGF1)#
The primary metric combining localization and classification:
CGF1 = 100 × pmF1 × IL_MCC
Where:
- pmF1 (Positive Macro F1): Measures localization quality on positive examples
- IL_MCC (Image-Level Matthews Correlation Coefficient): Measures binary classification accuracy ("is the concept present?")
Link to this sectionWhy These Metrics?#
Traditional AP metrics don't account for calibration, making models difficult to use in practice. By evaluating only predictions above 0.5 confidence, SAM 3's metrics enforce good calibration and mimic real-world usage patterns in interactive predict and track loops.
Link to this sectionKey Ablations and Insights#
Link to this sectionImpact of Presence Head#
The presence head decouples recognition from localization, providing significant improvements:
| Configuration | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Without presence | 57.6 | 0.77 | 74.7 |
| With presence | 63.3 | 0.82 | 77.1 |
The presence head provides a +5.7 CGF1 boost (+9.9%), primarily improving recognition ability (IL_MCC +6.5%).
Link to this sectionEffect of Hard Negatives#
| Hard Negatives/Image | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 0 | 31.8 | 0.44 | 70.2 |
| 5 | 44.8 | 0.62 | 71.9 |
| 30 | 49.2 | 0.68 | 72.3 |
Hard negatives are crucial for open-vocabulary recognition, improving IL_MCC by 54.5% (0.44 → 0.68).
Link to this sectionTraining Data Scaling#
| Data Sources | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| External only | 30.9 | 0.46 | 66.3 |
| External + Synthetic | 39.7 | 0.57 | 70.6 |
| External + HQ | 51.8 | 0.71 | 73.2 |
| All three | 54.3 | 0.74 | 73.5 |
High-quality human annotations provide large gains over synthetic or external data alone. For background on data quality practices, see data collection and annotation.
Link to this sectionApplications#
SAM 3's concept segmentation capability enables new use cases:
- Content Moderation: Find all instances of specific content types across media libraries
- E-commerce: Segment all products of a certain type in catalog images, supporting auto-annotation
- Medical Imaging: Identify all occurrences of specific tissue types or abnormalities
- Autonomous Systems: Track all instances of traffic signs, pedestrians, or vehicles by category
- Video Analytics: Count and track all people wearing specific clothing or performing actions
- Dataset Annotation: Rapidly annotate all instances of rare object categories
- Scientific Research: Quantify and analyze all specimens matching specific criteria
Link to this sectionSAM 3 Agent: Extended Language Reasoning#
SAM 3 can be combined with Multimodal Large Language Models (MLLMs) to handle complex queries requiring reasoning, similar in spirit to open-vocabulary systems like OWLv2 and T-Rex.
Link to this sectionPerformance on Reasoning Tasks#
| Benchmark | Metric | SAM 3 Agent (Gemini 2.5 Pro) | Previous Best |
|---|---|---|---|
| ReasonSeg (validation) | gIoU | 76.0 | 65.0 (SoTA) |
| ReasonSeg (test) | gIoU | 73.8 | 61.3 (SoTA) |
| OmniLabel (validation) | AP | 46.7 | 36.5 (REAL) |
| RefCOCO+ | Acc | 91.2 | 89.3 (LISA) |
Link to this sectionExample Complex Queries#
SAM 3 Agent can handle queries requiring reasoning:
- "People sitting down but not holding a gift box in their hands"
- "The dog closest to the camera that is not wearing a collar"
- "Red objects larger than the person's hand"
The MLLM proposes simple noun phrase queries to SAM 3, analyzes returned masks, and iterates until satisfied.
Link to this sectionLimitations#
While SAM 3 represents a major advancement, it has certain limitations:
- Phrase Complexity: Best suited for simple noun phrases; long referring expressions or complex reasoning may require MLLM integration
- Ambiguity Handling: Some concepts remain inherently ambiguous (e.g., "small window", "cozy room")
- Computational Requirements: Larger and slower than specialized detection models like YOLO
- Vocabulary Scope: Focused on atomic visual concepts; compositional reasoning is limited without MLLM assistance
- Rare Concepts: Performance may degrade on extremely rare or fine-grained concepts not well-represented in training data
Link to this sectionCitation#
@inproceedings{sam3_2025,
title = {SAM 3: Segment Anything with Concepts},
author = {Anonymous authors},
booktitle = {Submitted to ICLR 2026},
year = {2025},
url = {https://openreview.net/forum?id=r35clVtGzw},
note = {Paper ID: 4183, under double-blind review}
}Link to this sectionFAQ#
Link to this sectionWhen Was SAM 3 Released?#
SAM 3 was released by Meta on November 20th, 2025 and is fully integrated into Ultralytics as of version 8.3.237 (PR #22897). Full support is available for predict mode and track mode.
Link to this sectionIs SAM 3 Integrated Into Ultralytics?#
Yes! SAM 3 is fully integrated into the Ultralytics Python package, including concept segmentation, SAM 2–style visual prompts, and multi-object video tracking. SAM 3 also powers the smart annotation feature on Ultralytics Platform, where you can annotate images with just a few clicks.
Link to this sectionWhat Is Promptable Concept Segmentation (PCS)?#
PCS is a new task introduced in SAM 3 that segments all instances of a visual concept in an image or video. Unlike traditional segmentation that targets a specific object instance, PCS finds every occurrence of a category. For example:
- Text prompt: "yellow school bus" → segments all yellow school buses in the scene
- Image exemplar: Box around one dog → segments all dogs in the image
- Combined: "striped cat" + exemplar box → segments all striped cats matching the example
See related background on object detection and instance segmentation.
Link to this sectionHow Does SAM 3 Differ From SAM 2?#
| Feature | SAM 2 | SAM 3 |
|---|---|---|
| Task | Single object per prompt | All instances of a concept |
| Prompt Types | Points, boxes, masks | + Text phrases, image exemplars |
| Detection Capability | Requires external detector | Built-in open-vocabulary detector |
| Recognition | Geometry-based only | Text and visual recognition |
| Architecture | Tracker only | Detector + Tracker with presence head |
| Zero-Shot Performance | N/A (requires visual prompts) | 47.0 AP on LVIS, 2× better on SA-Co |
| Interactive Refinement | Clicks only | Clicks + exemplar generalization |
SAM 3 maintains backward compatibility with SAM 2 visual prompting while adding concept-based capabilities.
Link to this sectionWhat datasets are used to train SAM 3?#
SAM 3 is trained on the Segment Anything with Concepts (SA-Co) dataset:
Training Data:
- 5.2M images with 4M unique noun phrases (SA-Co/HQ) - high-quality human annotations
- 52.5K videos with 24.8K unique noun phrases (SA-Co/VIDEO)
- 1.4B synthetic masks across 38M noun phrases (SA-Co/SYN)
- 15 external datasets enriched with hard negatives (SA-Co/EXT)
Benchmark Data:
- 214K unique concepts across 126K images/videos
- 50× more concepts than existing benchmarks (e.g., LVIS has ~4K concepts)
- Triple annotation on SA-Co/Gold for measuring human performance bounds
This massive scale and diversity enables SAM 3's superior zero-shot generalization across open-vocabulary concepts.
Link to this sectionHow does SAM 3 compare to YOLO26 for segmentation?#
SAM 3 and YOLO26 serve different use cases:
SAM 3 Advantages:
- Open-vocabulary: Segments any concept via text prompts without training
- Zero-shot: Works on new categories immediately
- Interactive: Exemplar-based refinement generalizes to similar objects
- Concept-based: Automatically finds all instances of a category
- Accuracy: 47.0 AP on LVIS zero-shot instance segmentation
YOLO26 Advantages:
- Speed: Orders of magnitude faster inference with NMS-free end-to-end design
- Efficiency: 539× smaller models (6.4MB vs 3.45GB)
- Resource-friendly: Runs on edge devices and mobile
- Real-time: Optimized for production deployments
Recommendation:
- Use SAM 3 for flexible, open-vocabulary segmentation where you need to find all instances of concepts described by text or examples
- Use YOLO26 for high-speed, production deployments where categories are known in advance
- Use SAM 2 for interactive single-object segmentation with geometric prompts
Link to this sectionCan SAM 3 handle complex language queries?#
SAM 3 is designed for simple noun phrases (e.g., "red apple", "person wearing hat"). For complex queries requiring reasoning, combine SAM 3 with an MLLM as SAM 3 Agent:
Simple queries (native SAM 3):
- "yellow school bus"
- "striped cat"
- "person wearing red hat"
Complex queries (SAM 3 Agent with MLLM):
- "People sitting down but not holding a gift box"
- "The dog closest to the camera without a collar"
- "Red objects larger than the person's hand"
SAM 3 Agent achieves 76.0 gIoU on ReasonSeg validation (vs 65.0 previous best, +16.9% improvement) by combining SAM 3's segmentation with MLLM reasoning capabilities.
Link to this sectionHow accurate is SAM 3 compared to human performance?#
On the SA-Co/Gold benchmark with triple human annotation:
- Human lower bound: 74.2 CGF1 (most conservative annotator)
- SAM 3 performance: 65.0 CGF1
- Achievement: 88% of estimated human lower bound
- Human upper bound: 81.4 CGF1 (most liberal annotator)
SAM 3 achieves strong performance approaching human-level accuracy on open-vocabulary concept segmentation, with the gap primarily on ambiguous or subjective concepts (e.g., "small window", "cozy room").