Link to this sectionSAM 3: Сегментация всего с помощью концептов#
SAM 3 полностью интегрирована в пакет Ultralytics начиная с версии 8.3.237 (PR #22897). Установи или обнови пакет командой pip install -U ultralytics, чтобы получить доступ ко всем функциям SAM 3, включая текстовую сегментацию концептов, подсказки на основе примеров изображений и видео-трекинг.
SAM 3 (Segment Anything Model 3) — это выпущенная Meta фундаментальная модель для сегментации концептов с подсказками (PCS). Основываясь на SAM 2, SAM 3 внедряет принципиально новую возможность: обнаружение, сегментацию и отслеживание всех экземпляров визуального концепта, заданного текстовыми подсказками, примерами изображений или и тем, и другим одновременно. В отличие от предыдущих версий SAM, которые сегментировали отдельные объекты по подсказке, SAM 3 может находить и сегментировать каждое появление концепта в любом месте на изображениях или видео, что соответствует целям работы с открытым словарем в современной инстанс-сегментации.
Watch: How to Use Meta Segment Anything 3 with Ultralytics | Text-Prompt Segmentation on Images & Videos
SAM 3 теперь полностью интегрирована в пакет ultralytics, обеспечивая нативную поддержку сегментации концептов с помощью текстовых подсказок, примеров изображений и функций видео-трекинга.
Link to this sectionОбзор#
SAM 3 обеспечивает двукратный прирост производительности по сравнению с существующими системами в области сегментации концептов с подсказками, сохраняя и улучшая при этом возможности SAM 2 для интерактивной визуальной сегментации. Модель превосходно справляется с сегментацией с открытым словарем, позволяя пользователям указывать концепты с помощью простых именных фраз (например, "желтый школьный автобус", "полосатый кот") или предоставляя примеры изображений целевого объекта. Эти возможности дополняют готовые к промышленному использованию конвейеры, опирающиеся на оптимизированные рабочие процессы predict и track.
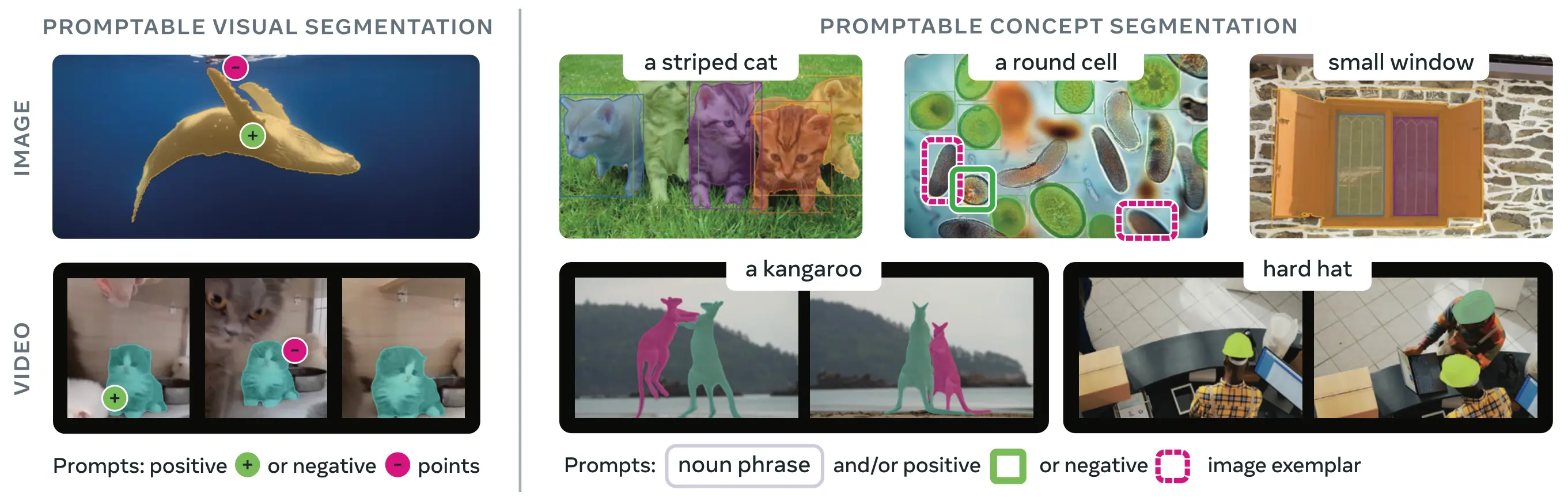
Link to this sectionЧто такое сегментация концептов с подсказками (PCS)?#
Задача PCS принимает концептуальную подсказку в качестве входных данных и возвращает маски сегментации с уникальными идентификаторами для всех соответствующих экземпляров объектов. Концептуальные подсказки могут быть:
- Текст: Простые именные фразы, такие как "красное яблоко" или "человек в шляпе", аналогично обучению с нулевым примером
- Примеры изображений: Ограничивающие рамки вокруг примеров объектов (положительных или отрицательных) для быстрой генерализации
- Комбинированные: И текст, и примеры изображений вместе для точного контроля
Это отличается от традиционных визуальных подсказок (точки, рамки, маски), которые сегментируют только один конкретный экземпляр объекта, как это было популяризировано оригинальным семейством SAM.
Link to this sectionОсновные метрики производительности#
| Метрика | Достижение SAM 3 |
|---|---|
| LVIS Zero-Shot Mask AP | 47.0 (против предыдущего лучшего результата 38.5, улучшение на +22%) |
| Бенчмарк SA-Co | В 2 раза лучше, чем существующие системы |
| Скорость вывода (GPU H200) | 30 мс на изображение с 100+ обнаруженными объектами |
| Производительность видео | Почти в реальном времени для ~5 одновременных объектов |
| Бенчмарк MOSEv2 VOS | 60.1 J&F (+25.5% по сравнению с SAM 2.1, +17% по сравнению с предыдущим SOTA) |
| Интерактивное уточнение | Улучшение +18.6 CGF1 после 3 подсказок с примерами |
| Разрыв в производительности с человеком | Достигает 88% от расчетной нижней границы на SA-Co/Gold |
Для контекста по метрикам моделей и компромиссам в продакшене, ознакомься с инсайтами по оценке моделей и метриками производительности YOLO.
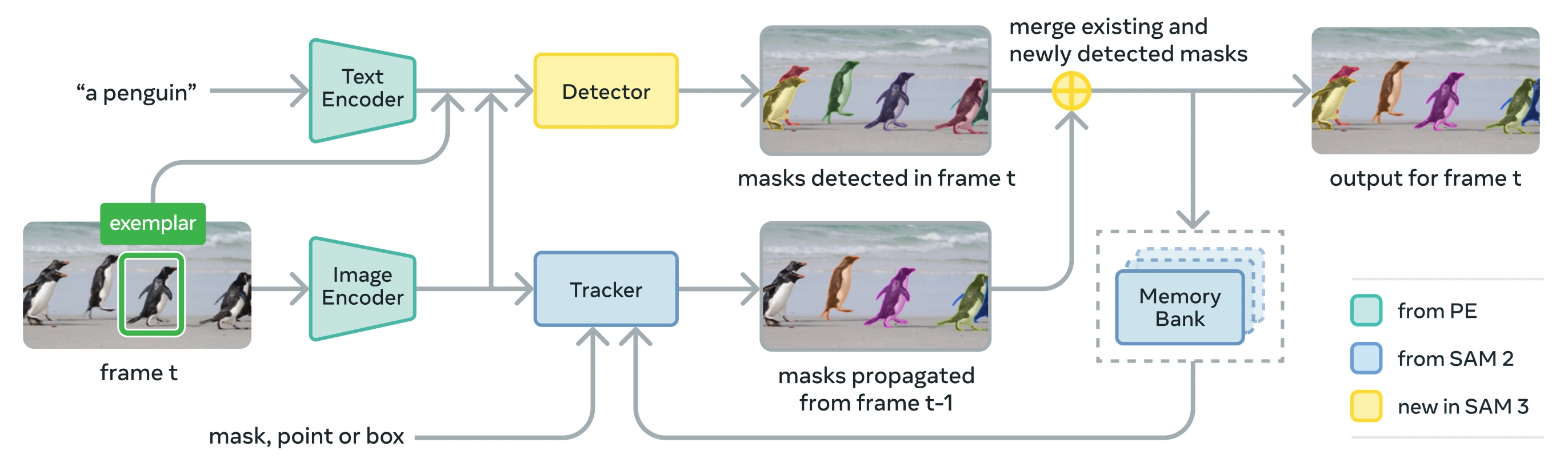
Link to this sectionАрхитектура#
SAM 3 состоит из детектора и трекера, которые используют общий визуальный бэкбон Perception Encoder (PE). Такая раздельная конструкция позволяет избежать конфликтов задач, одновременно обеспечивая детекцию на уровне изображений и трекинг на уровне видео с интерфейсом, совместимым с использованием Python и CLI в Ultralytics.
Link to this sectionОсновные компоненты#
-
Детектор: архитектура на базе DETR для обнаружения концептов на уровне изображения
- Текстовый энкодер для подсказок в виде именных фраз
- Энкодер примеров для подсказок на основе изображений
- Fusion-энкодер для обусловливания признаков изображения на основе подсказок
- Новаторская голова присутствия (presence head), которая отделяет распознавание ("что") от локализации ("где")
- Голова маски для генерации масок инстанс-сегментации
-
Трекер: Видеосегментация на основе памяти, унаследованная от SAM 2
- Энкодер подсказок, декодер масок, энкодер памяти
- Банк памяти для хранения внешнего вида объектов в разных кадрах
- Временная дезамбигуация с помощью таких методов, как фильтр Калмана в сценариях с множеством объектов
-
Токен присутствия (Presence Token): Обучаемый глобальный токен, который предсказывает, присутствует ли целевой концепт на изображении/кадре, улучшая детекцию путем отделения распознавания от локализации.
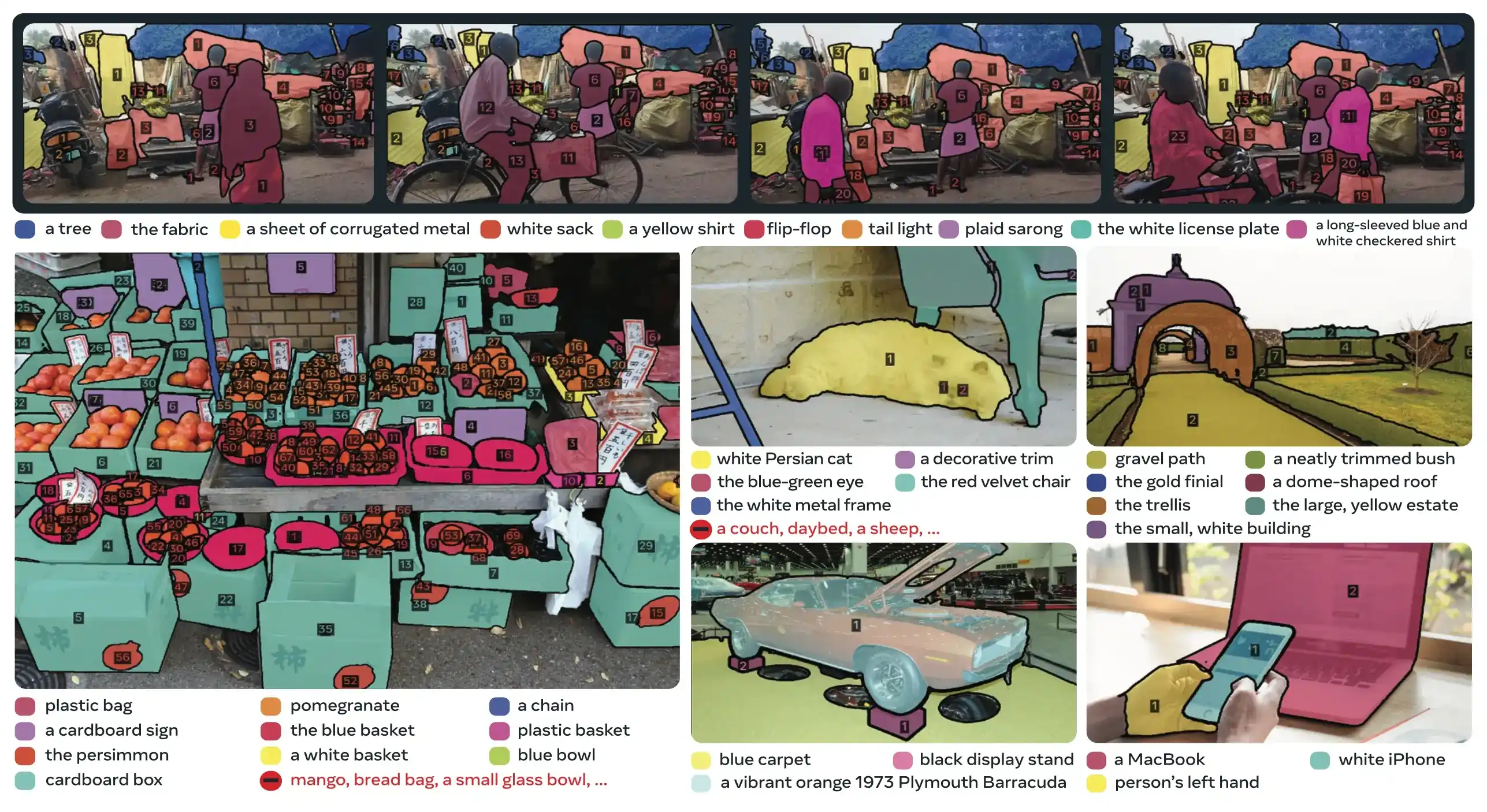
Link to this sectionКлючевые инновации#
- Разделение распознавания и локализации: Голова присутствия предсказывает наличие концепта глобально, в то время как запросы предложений фокусируются только на локализации, что позволяет избежать конфликтующих целей.
- Единые концептуальные и визуальные подсказки: Поддерживает как PCS (концептуальные подсказки), так и PVS (визуальные подсказки, такие как клики/рамки в SAM 2) в одной модели.
- Интерактивное уточнение примерами: Ты можешь добавлять положительные или отрицательные примеры изображений для итеративного уточнения результатов, при этом модель обобщает их до похожих объектов, а не просто исправляет отдельные экземпляры.
- Временная дезамбигуация: Использует оценки детекции масок и периодические повторные подсказки для обработки окклюзий, переполненных сцен и сбоев трекинга в видео, в соответствии с лучшими практиками инстанс-сегментации и трекинга.
Link to this sectionДатасет SA-Co#
SAM 3 обучена на Segment Anything with Concepts (SA-Co), крупнейшем и самом разнообразном на сегодняшний день датасете сегментации от Meta, выходящем за рамки стандартных бенчмарков, таких как COCO и LVIS.
Link to this sectionДанные для обучения#
| Компонент датасета | Описание | Масштаб |
|---|---|---|
| SA-Co/HQ | Высококачественные размеченные человеком данные изображений из 4-фазного движка данных | 5.2 млн изображений, 4 млн уникальных именных фраз |
| SA-Co/SYN | Синтетический датасет, размеченный ИИ без участия человека | 38 млн именных фраз, 1.4 млрд масок |
| SA-Co/EXT | 15 внешних датасетов, обогащенных сложными негативными примерами | Зависит от источника |
| SA-Co/VIDEO | Видеоаннотации с временным трекингом | 52.5 тыс. видео, 24.8 тыс. уникальных именных фраз |
Link to this sectionБенчмарк данных#
Бенчмарк оценки SA-Co содержит 214 тыс. уникальных фраз на 126 тыс. изображений и видео, предоставляя более чем в 50 раз больше концептов, чем существующие бенчмарки. Он включает:
- SA-Co/Gold: 7 доменов, тройная аннотация для измерения границ человеческой производительности
- SA-Co/Silver: 10 доменов, одинарная аннотация человеком
- SA-Co/Bronze и SA-Co/Bio: 9 существующих датасетов, адаптированных для сегментации концептов
- SA-Co/VEval: Видео-бенчмарк с 3 доменами (SA-V, YT-Temporal-1B, SmartGlasses)
Link to this sectionИнновации движка данных#
Масштабируемый движок данных SAM 3 с участием человека и модели обеспечивает удвоенную пропускную способность аннотирования за счет:
- ИИ-аннотаторы: Модели на базе Llama предлагают разнообразные именные фразы, включая сложные негативные примеры
- ИИ-верификаторы: Дообученные мультимодальные LLM проверяют качество масок и полноту разметки с производительностью, близкой к человеческой
- Активное майнинг: Фокусирует усилия человека на сложных случаях, где ИИ испытывает трудности
- Онтологически-ориентированный подход: Использует большую онтологию, основанную на Wikidata для покрытия концептов
Link to this sectionУстановка#
SAM 3 доступна в Ultralytics версии 8.3.237 и выше. Установи или обнови пакет командой:
pip install -U ultralyticsВ отличие от других моделей Ultralytics, веса SAM 3 (sam3.pt) не загружаются автоматически. Тебе необходимо сначала запросить доступ к весам модели на странице модели SAM 3 на Hugging Face, а затем, после одобрения, скачать sam3.pt с этой страницы. Помести скачанный файл sam3.pt в рабочую директорию или укажи полный путь при загрузке модели.
Если ты получаешь эту ошибку во время предсказания, это означает, что у тебя установлен некорректный пакет clip. Установи правильный пакет clip, выполнив следующую команду:
pip uninstall clip -y
pip install git+https://github.com/ultralytics/CLIP.gitLink to this sectionКак использовать SAM 3: Универсальность в сегментации концептов#
SAM 3 поддерживает как задачи сегментации концептов с подсказками (PCS), так и задачи визуальной сегментации с подсказками (PVS) через различные интерфейсы предиктора:
Link to this sectionПоддерживаемые задачи и модели#
| Тип задачи | Типы подсказок | Выходные данные |
|---|---|---|
| Сегментация концептов (PCS) | Текст (именные фразы), примеры изображений | Все экземпляры, соответствующие концепту |
| Визуальная сегментация (PVS) | Точки, рамки, маски | Одиночный экземпляр объекта (в стиле SAM 2) |
| Интерактивное уточнение | Итеративное добавление/удаление примеров или кликов | Уточненная сегментация с повышенной точностью |
Link to this sectionПримеры сегментации концептов#
Link to this sectionСегментация с помощью текстовых подсказок#
Находи и сегментируй все экземпляры концепта с помощью текстового описания. Текстовые промпты требуют интерфейса SAM3SemanticPredictor.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor with configuration
overrides = dict(
conf=0.25,
task="segment",
mode="predict",
model="sam3.pt",
quantize=16, # Use FP16 for faster inference
save=True,
)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image once for multiple queries
predictor.set_image("path/to/image.jpg")
# Query with multiple text prompts
results = predictor(text=["person", "bus", "glasses"])
# Works with descriptive phrases
results = predictor(text=["person with red cloth", "person with blue cloth"])
# Query with a single concept
results = predictor(text=["a person"])Link to this sectionСегментация с помощью примеров изображений#
Используй ограничивающие рамки (bounding boxes) в качестве визуальных промптов для поиска всех похожих экземпляров. Это также требует SAM3SemanticPredictor для сопоставления на основе концептов.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16, save=True)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image
predictor.set_image("path/to/image.jpg")
# Provide bounding box examples to segment similar objects
results = predictor(bboxes=[[480.0, 290.0, 590.0, 650.0]])
# Multiple bounding boxes as exemplars of the same visual concept
results = predictor(bboxes=[[539, 599, 589, 639], [343, 267, 499, 662]])Link to this sectionВывод на основе признаков для повышения эффективности#
Извлекай признаки изображения один раз и используй их повторно для нескольких запросов сегментации, чтобы повысить эффективность.
import cv2
from ultralytics.models.sam import SAM3SemanticPredictor
from ultralytics.utils.plotting import Annotator, colors
# Initialize predictors
overrides = dict(conf=0.50, task="segment", mode="predict", model="sam3.pt", verbose=False)
predictor = SAM3SemanticPredictor(overrides=overrides)
predictor2 = SAM3SemanticPredictor(overrides=overrides)
# Extract features from the first predictor
source = "path/to/image.jpg"
predictor.set_image(source)
src_shape = cv2.imread(source).shape[:2]
# Setup second predictor and reuse features
predictor2.setup_model()
# Perform inference using shared features with text prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, text=["person"])
# Perform inference using shared features with bounding box prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, bboxes=[[439, 437, 524, 709]])
# Visualize results
if masks is not None:
masks, boxes = masks.cpu().numpy(), boxes.cpu().numpy()
im = cv2.imread(source)
annotator = Annotator(im, pil=False)
annotator.masks(masks, [colors(x, True) for x in range(len(masks))])
cv2.imshow("result", annotator.result())
cv2.waitKey(0)Link to this sectionСегментация концептов в видео#
Link to this sectionОтслеживай концепты в видео с помощью ограничивающих рамок#
Обнаруживай и отслеживай экземпляры объектов в кадрах видео с помощью промптов в виде ограничивающих рамок.
from ultralytics.models.sam import SAM3VideoPredictor
# Create video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16)
predictor = SAM3VideoPredictor(overrides=overrides)
# Track objects using bounding box prompts
results = predictor(source="path/to/video.mp4", bboxes=[[706.5, 442.5, 905.25, 555], [598, 635, 725, 750]], stream=True)
# Process and display results
for r in results:
r.show() # Display frame with segmentation masksLink to this sectionОтслеживай концепты с помощью текстовых промптов#
Отслеживай все экземпляры концептов, заданные текстом, во всех кадрах видео.
from ultralytics.models.sam import SAM3VideoSemanticPredictor
# Initialize semantic video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=640, model="sam3.pt", quantize=16, save=True)
predictor = SAM3VideoSemanticPredictor(overrides=overrides)
# Track concepts using text prompts
results = predictor(source="path/to/video.mp4", text=["person", "bicycle"], stream=True)
# Process results
for r in results:
r.show() # Display frame with tracked objects
# Alternative: Track with bounding box prompts
results = predictor(
source="path/to/video.mp4",
bboxes=[[864, 383, 975, 620], [705, 229, 782, 402]],
labels=[1, 1], # Positive labels
stream=True,
)Link to this sectionВизуальные промпты (совместимость с SAM 2)#
SAM 3 сохраняет полную обратную совместимость с визуальными промптами SAM 2 для сегментации отдельных объектов:
Базовый интерфейс SAM работает точно так же, как SAM 2, сегментируя только конкретную область, указанную визуальными промптами (точками, рамками или масками).
from ultralytics import SAM
model = SAM("sam3.pt")
# Single point prompt - segments object at specific location
results = model.predict(source="path/to/image.jpg", points=[900, 370], labels=[1])
results[0].show()
# Multiple points - segments single object with multiple point hints
results = model.predict(source="path/to/image.jpg", points=[[400, 370], [900, 370]], labels=[1, 1])
# Box prompt - segments object within bounding box
results = model.predict(source="path/to/image.jpg", bboxes=[100, 150, 300, 400])
results[0].show()Использование SAM("sam3.pt") с визуальными промптами (точки/рамки/маски) будет сегментировать только конкретный объект в этом месте, как и в SAM 2. Чтобы сегментировать все экземпляры концепта, используй SAM3SemanticPredictor с текстовыми промптами или примерами, как показано выше.
Link to this sectionТесты производительности#
Link to this sectionСегментация изображений#
SAM 3 достигает лучших в своем классе результатов по нескольким бенчмаркам, включая реальные наборы данных, такие как LVIS и COCO для сегментации:
| Бенчмарк | Метрика | SAM 3 | Предыдущий лучший результат | Улучшение |
|---|---|---|---|---|
| LVIS (zero-shot) | Mask AP | 47.0 | 38.5 | +22.1% |
| SA-Co/Gold | CGF1 | 65.0 | 34.3 (OWLv2) | +89.5% |
| COCO (zero-shot) | Box AP | 53.5 | 52.2 (T-Rex2) | +2.5% |
| ADE-847 (семантическая сегментация) | mIoU | 14.7 | 9.2 (APE-D) | +59.8% |
| PascalConcept-59 | mIoU | 59.4 | 58.5 (APE-D) | +1.5% |
| Cityscapes (семантическая сегментация) | mIoU | 65.1 | 44.2 (APE-D) | +47.3% |
Изучи варианты наборов данных для быстрой экспериментирования в Ultralytics datasets.
Link to this sectionПроизводительность сегментации видео#
SAM 3 демонстрирует значительные улучшения по сравнению с SAM 2 и предыдущими лучшими результатами на видео-бенчмарках, таких как DAVIS 2017 и YouTube-VOS:
| Бенчмарк | Метрика | SAM 3 | SAM 2.1 L | Улучшение |
|---|---|---|---|---|
| MOSEv2 | J&F | 60.1 | 47.9 | +25.5% |
| DAVIS 2017 | J&F | 92.0 | 90.7 | +1.4% |
| LVOSv2 | J&F | 88.2 | 79.6 | +10.8% |
| SA-V | J&F | 84.6 | 78.4 | +7.9% |
| YTVOS19 | J&F | 89.6 | 89.3 | +0.3% |
Link to this sectionАдаптация few-shot#
SAM 3 превосходно адаптируется к новым доменам с минимальным количеством примеров, что актуально для рабочих процессов data-centric AI:
| Бенчмарк | 0-shot AP | 10-shot AP | Предыдущий лучший (10-shot) |
|---|---|---|---|
| ODinW13 | 59.9 | 71.6 | 67.9 (gDino1.5-Pro) |
| RF100-VL | 14.3 | 35.7 | 33.7 (gDino-T) |
Link to this sectionЭффективность интерактивного уточнения#
Промпты SAM 3 на основе концептов с примерами сходятся гораздо быстрее, чем визуальные промпты:
| Добавлено промптов | Оценка CGF1 | Прирост по сравнению с только текстом | Прирост по сравнению с базовым PVS |
|---|---|---|---|
| Только текст | 46.4 | база | база |
| +1 пример | 57.6 | +11.2 | +6.7 |
| +2 примера | 62.2 | +15.8 | +9.7 |
| +3 примера | 65.0 | +18.6 | +11.2 |
| +4 примера | 65.7 | +19.3 | +11.5 (плато) |
Link to this sectionТочность подсчета объектов#
SAM 3 обеспечивает точный подсчет, сегментируя все экземпляры — частое требование при подсчете объектов:
| Бенчмарк | Точность | MAE | против лучшей MLLM |
|---|---|---|---|
| CountBench | 95.6% | 0.11 | 92.4% (Gemini 2.5) |
| PixMo-Count | 87.3% | 0.22 | 88.8% (Molmo-72B) |
Link to this sectionСравнение SAM 3, SAM 2 и YOLO#
Здесь мы сравниваем возможности SAM 3 с моделями SAM 2 и YOLO26:
| Возможность | SAM 3 | SAM 2 | YOLO26n-seg |
|---|---|---|---|
| Сегментация по концептам | ✅ Все экземпляры по тексту/примерам | ❌ Не поддерживается | ❌ Не поддерживается |
| Визуальная сегментация | ✅ Один экземпляр (совместимо с SAM 2) | ✅ Один экземпляр | ✅ Все экземпляры |
| Zero-shot возможности | ✅ Открытый словарь | ✅ Геометрические подсказки | ❌ Закрытый набор |
| Интерактивное уточнение | ✅ Примеры + клики | ✅ Только клики | ❌ Не поддерживается |
| Отслеживание видео | ✅ Несколько объектов с идентификаторами | ✅ Несколько объектов | ✅ Несколько объектов |
| LVIS Mask AP (zero-shot) | 47.0 | Н/Д | Н/Д |
| MOSEv2 J&F | 60.1 | 47.9 | Н/Д |
| Скорость (GPU, мс/изобр.) | 2921 | 857 | 8.4 |
| Размер модели | 3.45 ГБ | 162 МБ (базовая) | 6.4 МБ |
Скорость протестирована на NVIDIA RTX PRO 6000 с использованием torch==2.9.1 и ultralytics==8.4.19.
Основные выводы:
- SAM 3: лучше всего подходит для сегментации концептов с открытым словарем, поиска всех экземпляров концепта с помощью текстовых или примерочных подсказок
- SAM 2: лучше всего подходит для интерактивной сегментации одного объекта на изображениях и видео с использованием геометрических подсказок
- YOLO26: лучше всего подходит для высокоскоростной сегментации в реальном времени с выводом end-to-end без NMS, экспортируется во многие форматы для развертывания на GPU, CPU и edge-устройствах
Link to this sectionСравнение SAM и YOLO#
Сравнение SAM 3, SAM 2, SAM, MobileSAM и FastSAM с моделями сегментации Ultralytics YOLO (YOLOv8, YOLO11, YOLO26) по размеру, параметрам и скорости вывода на GPU:
| Модель | Размер (МБ) | Параметры (М) | Скорость (GPU) (мс/изобр.) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 1306 |
| Meta SAM2-b | 162 | 80.8 | 857 |
| Meta SAM2-t | 78.1 | 38.9 | 668 |
| Meta SAM3 | 3450 | 473.6 | 2921 |
| MobileSAM | 40.7 | 10.1 | 605 |
| FastSAM-s с backbone YOLOv8 | 23.7 | 11.8 | 55.9 |
| Ultralytics YOLOv8n-seg | 6.7 (в 515 раз меньше) | 3.4 (в 139.1 раз меньше) | 17.4 (в 167 раз быстрее) |
| Ultralytics YOLO11n-seg | 5.9 (в 585 раз меньше) | 2.9 (в 163.1 раз меньше) | 12.6 (в 231 раз быстрее) |
| Ultralytics YOLO26n-seg | 6.4 (в 539 раз меньше) | 2.7 (в 175.2 раз меньше) | 8.4 (в 347 раз быстрее) |
Это сравнение демонстрирует существенные различия в размерах моделей и скорости между вариантами SAM и моделями сегментации YOLO. В то время как SAM обеспечивает уникальные возможности автоматической сегментации, модели YOLO, в частности YOLOv8n-seg, YOLO11n-seg и YOLO26n-seg, значительно меньше, быстрее и вычислительно эффективнее.
Тесты проведены на NVIDIA RTX PRO 6000 с 96 ГБ VRAM с использованием torch==2.9.1 и ultralytics==8.4.19. Чтобы воспроизвести этот тест:
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# Profile SAM3, SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt", "sam3.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# Profile FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# Profile YOLO models
for file_name in ["yolov8n-seg.pt", "yolo11n-seg.pt", "yolo26n-seg.pt"]:
model = YOLO(file_name)
model.info()
model(ASSETS)Link to this sectionМетрики оценки#
SAM 3 представляет новые метрики, разработанные для задачи PCS, дополняющие привычные меры, такие как F1 score, precision и recall.
Link to this sectionClassification-Gated F1 (CGF1)#
Основная метрика, объединяющая локализацию и классификацию:
CGF1 = 100 × pmF1 × IL_MCC
Где:
- pmF1 (Positive Macro F1): измеряет качество локализации на положительных примерах
- IL_MCC (Image-Level Matthews Correlation Coefficient): измеряет точность бинарной классификации ("присутствует ли концепт?")
Link to this sectionПочему именно эти метрики?#
Традиционные метрики AP не учитывают калибровку, что затрудняет практическое использование моделей. Оценивая только предсказания с уверенностью выше 0.5, метрики SAM 3 обеспечивают хорошую калибровку и имитируют реальные сценарии использования в интерактивных циклах predict и track.
Link to this sectionКлючевые абляции и инсайты#
Link to this sectionВлияние заголовка присутствия (Presence Head)#
Заголовок присутствия отделяет распознавание от локализации, обеспечивая значительные улучшения:
| Конфигурация | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Без присутствия | 57.6 | 0.77 | 74.7 |
| С присутствием | 63.3 | 0.82 | 77.1 |
Заголовок присутствия дает прирост +5.7 CGF1 (+9.9%), в первую очередь улучшая способность к распознаванию (IL_MCC +6.5%).
Link to this sectionЭффект сложных негативных примеров (Hard Negatives)#
| Сложные негативные примеры/изображение | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 0 | 31.8 | 0.44 | 70.2 |
| 5 | 44.8 | 0.62 | 71.9 |
| 30 | 49.2 | 0.68 | 72.3 |
Трудные примеры (hard negatives) критически важны для распознавания с открытым словарем, улучшая IL_MCC на 54.5% (0.44 → 0.68).
Link to this sectionМасштабирование обучающих данных#
| Источники данных | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Только внешние | 30.9 | 0.46 | 66.3 |
| Внешние + Синтетические | 39.7 | 0.57 | 70.6 |
| Внешние + HQ | 51.8 | 0.71 | 73.2 |
| Все три | 54.3 | 0.74 | 73.5 |
Высококачественные человеческие аннотации обеспечивают значительный прирост по сравнению с одними только синтетическими или внешними данными. Справочную информацию о методах обеспечения качества данных см. в разделе сбор и аннотирование данных.
Link to this sectionПрименение#
Возможность сегментации концептов в SAM 3 открывает новые сценарии использования:
- Модерация контента: находи все экземпляры определенных типов контента в медиабиблиотеках
- Электронная коммерция: сегментируй все товары определенного типа на изображениях каталога, поддерживая автоматическую разметку
- Медицинская визуализация: выявляй все случаи появления специфических типов тканей или патологий
- Автономные системы: отслеживай все экземпляры дорожных знаков, пешеходов или транспортных средств по категориям
- Видеоаналитика: подсчитывай и отслеживай всех людей, одетых в определенную одежду или выполняющих действия
- Аннотирование наборов данных: быстро аннотируй все экземпляры редких категорий объектов
- Научные исследования: проводи количественный анализ всех образцов, соответствующих заданным критериям
Link to this sectionАгент SAM 3: Расширенное языковое мышление#
SAM 3 можно объединить с мультимодальными большими языковыми моделями (MLLM) для обработки сложных запросов, требующих рассуждения, аналогично тому, как это реализовано в системах с открытым словарем, таких как OWLv2 и T-Rex.
Link to this sectionПроизводительность в задачах на логическое мышление#
| Бенчмарк | Метрика | Агент SAM 3 (Gemini 2.5 Pro) | Предыдущий лучший результат |
|---|---|---|---|
| ReasonSeg (валидация) | gIoU | 76.0 | 65.0 (SoTA) |
| ReasonSeg (тест) | gIoU | 73.8 | 61.3 (SoTA) |
| OmniLabel (валидация) | Азиатско-Тихоокеанский регион | 46.7 | 36.5 (REAL) |
| RefCOCO+ | Acc | 91.2 | 89.3 (LISA) |
Link to this sectionПримеры сложных запросов#
Агент SAM 3 может обрабатывать запросы, требующие рассуждения:
- "Люди, которые сидят, но не держат в руках подарочную коробку"
- "Собака, которая ближе всего к камере и не носит ошейник"
- "Красные объекты, которые больше, чем рука человека"
MLLM предлагает простые запросы с именными фразами для SAM 3, анализирует возвращенные маски и итерирует до достижения результата.
Link to this sectionОграничения#
Хотя SAM 3 представляет собой серьезный шаг вперед, у него есть определенные ограничения:
- Сложность фраз: лучше всего подходит для простых именных фраз; для длинных ссылочных выражений или сложных рассуждений может потребоваться интеграция с MLLM
- Обработка неоднозначности: некоторые концепты остаются по своей сути двусмысленными (например, "маленькое окно", "уютная комната")
- Вычислительные требования: крупнее и медленнее, чем специализированные модели обнаружения, такие как YOLO
- Область словаря: ориентирован на атомарные визуальные концепты; композиционное мышление ограничено без помощи MLLM
- Редкие концепты: производительность может снижаться на очень редких или узкоспециализированных концептах, недостаточно представленных в обучающих данных
Link to this sectionЦитирование#
@inproceedings{sam3_2025,
title = {SAM 3: Segment Anything with Concepts},
author = {Anonymous authors},
booktitle = {Submitted to ICLR 2026},
year = {2025},
url = {https://openreview.net/forum?id=r35clVtGzw},
note = {Paper ID: 4183, under double-blind review}
}Link to this sectionFAQ#
Link to this sectionКогда был выпущен SAM 3?#
SAM 3 был выпущен компанией Meta 20 ноября 2025 года и полностью интегрирован в Ultralytics начиная с версии 8.3.237 (PR #22897). Полная поддержка доступна для режима предсказания и режима отслеживания.
Link to this sectionИнтегрирован ли SAM 3 в Ultralytics?#
Да! SAM 3 полностью интегрирован в пакет Ultralytics для Python, включая сегментацию концептов, визуальные подсказки в стиле SAM 2 и многообъектное отслеживание в видео. SAM 3 также обеспечивает функцию умного аннотирования на Ultralytics Platform, где ты можешь аннотировать изображения всего несколькими кликами.
Link to this sectionЧто такое сегментация концептов с подсказками (PCS)?#
PCS — это новая задача, представленная в SAM 3, которая сегментирует все экземпляры визуального концепта на изображении или видео. В отличие от традиционной сегментации, которая нацелена на конкретный экземпляр объекта, PCS находит каждое вхождение категории. Например:
- Текстовая подсказка: "желтый школьный автобус" → сегментирует все желтые школьные автобусы на сцене
- Пример изображения: рамка вокруг одной собаки → сегментирует всех собак на изображении
- Комбинированный: "полосатый кот" + рамка-пример → сегментирует всех полосатых котов, соответствующих примеру
См. соответствующую справочную информацию по обнаружению объектов и сегментации экземпляров.
Link to this sectionЧем SAM 3 отличается от SAM 2?#
| Функция | SAM 2 | SAM 3 |
|---|---|---|
| Задача | Один объект на подсказку | Все экземпляры концепта |
| Типы подсказок | Точки, рамки, маски | + Текстовые фразы, примеры изображений |
| Возможность обнаружения | Требует внешнего детектора | Встроенный детектор с открытым словарем |
| Распознавание | Только на основе геометрии | Текстовое и визуальное распознавание |
| Архитектура | Только трекер | Детектор + трекер с головкой наличия (presence head) |
| Производительность Zero-Shot | Нет (требуются визуальные подсказки) | 47.0 AP на LVIS, в 2 раза лучше на SA-Co |
| Интерактивное уточнение | Только клики | Клики + обобщение по примерам |
SAM 3 сохраняет обратную совместимость с визуальными подсказками SAM 2, добавляя при этом возможности, основанные на концептах.
Link to this sectionКакие наборы данных используются для обучения SAM 3?#
SAM 3 обучается на наборе данных Segment Anything with Concepts (SA-Co):
Обучающие данные:
- 5,2 млн изображений с 4 млн уникальных именных фраз (SA-Co/HQ) — высококачественные аннотации, выполненные людьми
- 52,5 тыс. видео с 24,8 тыс. уникальных именных фраз (SA-Co/VIDEO)
- 1,4 млрд синтетических масок для 38 млн именных фраз (SA-Co/SYN)
- 15 внешних наборов данных, дополненных сложными негативными примерами (SA-Co/EXT)
Данные для бенчмаркинга:
- 214 тыс. уникальных концептов для 126 тыс. изображений/видео
- В 50 раз больше концептов, чем в существующих бенчмарках (например, LVIS имеет ~4 тыс. концептов)
- Тройная аннотация в SA-Co/Gold для измерения границ человеческой производительности
Такой огромный масштаб и разнообразие обеспечивают превосходную способность SAM 3 к zero-shot обобщению концептов с открытым словарем.
Link to this sectionКак SAM 3 соотносится с YOLO26 в задачах сегментации?#
SAM 3 и YOLO26 предназначены для разных сценариев использования:
Преимущества SAM 3:
- Открытый словарь (Open-vocabulary): сегментирует любой концепт с помощью текстовых подсказок без дополнительного обучения
- Zero-shot: сразу работает с новыми категориями
- Интерактивность: уточнение на основе примеров обобщается на похожие объекты
- Концептуальный подход: автоматически находит все экземпляры категории
- Точность: 47.0 AP в задаче zero-shot сегментации экземпляров на LVIS
Преимущества YOLO26:
- Скорость: на порядок более быстрый вывод благодаря сквозной архитектуре без NMS
- Эффективность: модели в 539 раз меньше (6.4 МБ против 3.45 ГБ)
- Легкость для ресурсов: работает на периферийных (edge) устройствах и мобильных телефонах
- Реальное время: оптимизировано для промышленных развертываний
Рекомендация:
- Используй SAM 3 для гибкой сегментации с открытым словарем, когда нужно найти все экземпляры концептов, описанных текстом или примерами
- Используй YOLO26 для высокоскоростных промышленных развертываний, где категории известны заранее
- Используй SAM 2 для интерактивной сегментации отдельных объектов с геометрическими подсказками
Link to this sectionМожет ли SAM 3 обрабатывать сложные языковые запросы?#
SAM 3 предназначен для простых именных фраз (например, «красное яблоко», «человек в шляпе»). Для сложных запросов, требующих логического вывода, объединяй SAM 3 с MLLM как SAM 3 Agent:
Простые запросы (стандартный SAM 3):
- «желтый школьный автобус»
- «полосатый кот»
- «человек в красной шляпе»
Сложные запросы (SAM 3 Agent с MLLM):
- «Люди, которые сидят, но не держат подарочную коробку»
- «Собака, ближайшая к камере, без ошейника»
- "Красные объекты, которые больше, чем рука человека"
SAM 3 Agent достигает 76.0 gIoU на валидационном наборе ReasonSeg (против 65.0 предыдущего лучшего результата, улучшение на +16.9%), сочетая сегментацию SAM 3 с возможностями логического вывода MLLM.
Link to this sectionНасколько точен SAM 3 по сравнению с результатами человека?#
На бенчмарке SA-Co/Gold с тройной человеческой аннотацией:
- Нижняя граница (человек): 74.2 CGF1 (самый консервативный аннотатор)
- Производительность SAM 3: 65.0 CGF1
- Достижение: 88% от расчетной нижней границы производительности человека
- Верхняя граница (человек): 81.4 CGF1 (самый либеральный аннотатор)
SAM 3 достигает высокой производительности, приближаясь к точности уровня человека в сегментации концептов с открытым словарем, при этом разрыв в основном проявляется на неоднозначных или субъективных концептах (например, «маленькое окно», «уютная комната»).