SAM 3: Segment Anything with Concepts
Теперь доступно в Ultralytics
SAM 3 полностью интегрирован в пакет Ultralytics начиная с версии 8.3.237 (PR #22897). Установите или обновите с помощью pip install -U ultralytics для доступа ко всем функциям SAM 3, включая сегментацию концепций на основе текста, подсказки на основе образцов изображений и отслеживание видео.
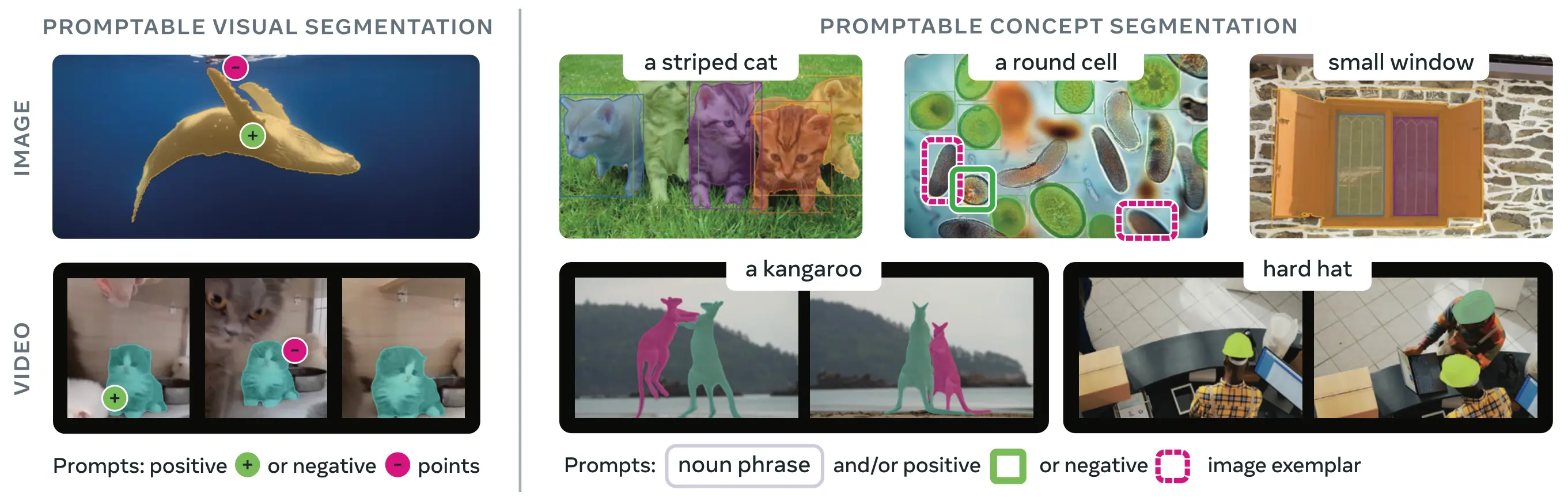
SAM 3 (Segment Anything Model 3) — это выпущенная Meta базовая модель для сегментации концепций с подсказками (Promptable Concept Segmentation, PCS). Основываясь на SAM 2, SAM 3 представляет принципиально новую возможность: обнаруживать, сегментировать и отслеживать все экземпляры визуальной концепции, заданной текстовыми подсказками, примерами изображений или и тем, и другим. В отличие от предыдущих версий SAM, которые сегментируют отдельные объекты по подсказке, SAM 3 может находить и сегментировать каждое появление концепции в любом месте изображений или видео, что соответствует целям открытого словаря в современной сегментации экземпляров.
Смотреть: Как использовать Meta Segment Anything 3 с Ultralytics | Сегментация по текстовым подсказкам на изображениях и видео
SAM 3 теперь полностью интегрирован в ultralytics пакет, обеспечивая нативную поддержку сегментации концепций с текстовыми подсказками, подсказками на основе образцов изображений и возможностями отслеживания видео.
Обзор
SAM 3 обеспечивает 2-кратный прирост производительности по сравнению с существующими системами в сегментации концепций с подсказками, сохраняя и улучшая возможности SAM 2 для интерактивной визуальной сегментации. Модель превосходно справляется с сегментацией с открытым словарем, позволяя пользователям указывать концепции, используя простые именные фразы (например, «желтый школьный автобус», «полосатый кот») или предоставляя примеры изображений целевого объекта. Эти возможности дополняют готовые к производству конвейеры, которые полагаются на оптимизированные рабочие процессы predict и track.
Что такое сегментация концепций с подсказками (Promptable Concept Segmentation, PCS)?
Задача PCS принимает concept prompt в качестве входных данных и возвращает маски segmentации с уникальными идентификаторами для всех совпадающих экземпляров объектов. Concept prompts могут быть:
- Текст: Простые существительные фразы, такие как "красное яблоко" или "человек в шляпе", аналогичные обучению zero-shot
- Образцы изображений: Ограничивающие рамки вокруг примеров объектов (положительных или отрицательных) для быстрой генерализации
- Вместе: Текстовые и графические примеры вместе для точного управления
Это отличается от традиционных визуальных подсказок (точки, рамки, маски), которые сегментируют только один конкретный экземпляр объекта, как это было популяризировано оригинальным семейством SAM.
Ключевые показатели производительности
| Метрика | Достижение SAM 3 |
|---|---|
| LVIS Zero-Shot Mask AP | 47.0 (по сравнению с предыдущим лучшим результатом 38.5, улучшение на +22%) |
| Бенчмарк SA-Co | В 2 раза лучше существующих систем |
| Скорость инференса (H200 GPU) | 30 мс на изображение при 100+ обнаруженных объектах |
| Производительность видео | Почти в реальном времени для ~5 параллельных объектов |
| MOSEv2 VOS Benchmark | 60.1 J&F (+25.5% по сравнению с SAM 2.1, +17% по сравнению с предыдущим SOTA) |
| Интерактивное уточнение | Улучшение на +18.6 CGF1 после 3 образцовых подсказок |
| Разрыв в производительности между человеком и машиной | Достигает 88% от оценочной нижней границы SA-Co/Gold |
Для получения информации о метриках модели и компромиссах в производстве см. анализ оценки модели и метрики производительности YOLO.
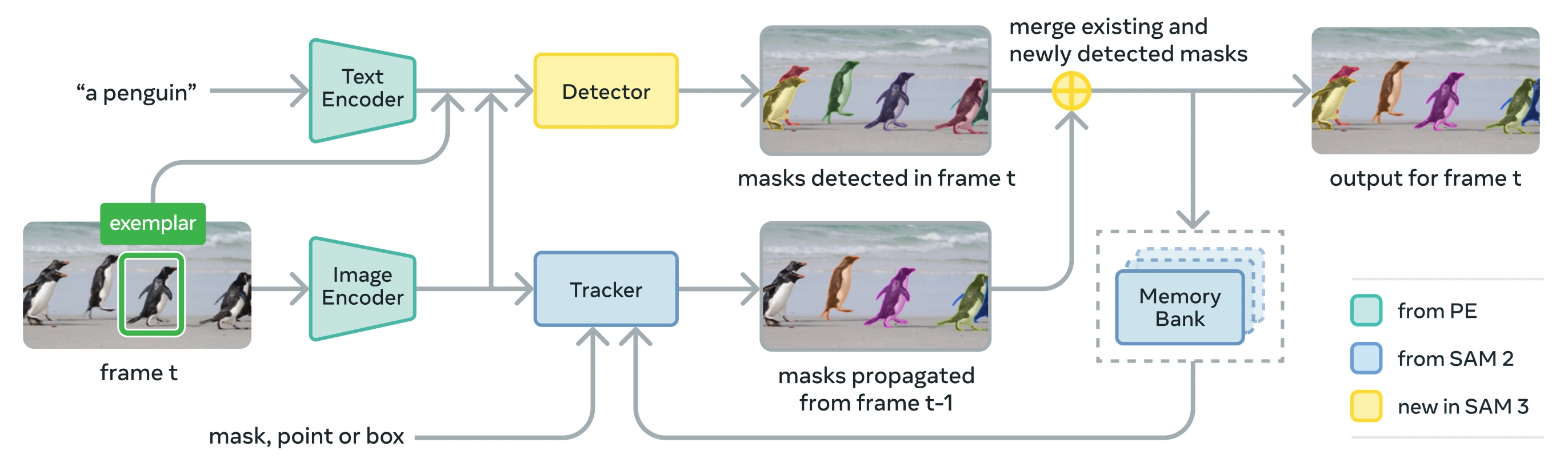
Архитектура
SAM 3 состоит из детектора и трекера, которые используют общую основу Perception Encoder (PE). Такая разделенная конструкция позволяет избежать конфликтов задач, обеспечивая как обнаружение на уровне изображений, так и отслеживание на уровне видео, с интерфейсом, совместимым с Ultralytics использованием Python и использованием CLI.
Основные компоненты
Детектор: Архитектура на основе DETR для обнаружения концепций на уровне изображений
- Текстовый энкодер для подсказок с именными группами
- Кодировщик образцов для подсказок на основе изображений
- Fusion encoder to condition image features on prompts
- Новая голова присутствия, которая разделяет распознавание («что») от локализации («где»)
- Mask head для генерации масок instance segmentation
Трекер: Сегментация видео на основе памяти, унаследованная от SAM 2
- Кодировщик запросов, декодер масок, кодировщик памяти
- Банк памяти для хранения внешнего вида объектов в разных кадрах
- Разрешение временной неоднозначности с помощью таких методов, как фильтр Калмана в условиях работы с несколькими объектами
Presence Token: Изученный глобальный токен, который предсказывает, присутствует ли целевая концепция в изображении/кадре, улучшая обнаружение за счет разделения распознавания и локализации.
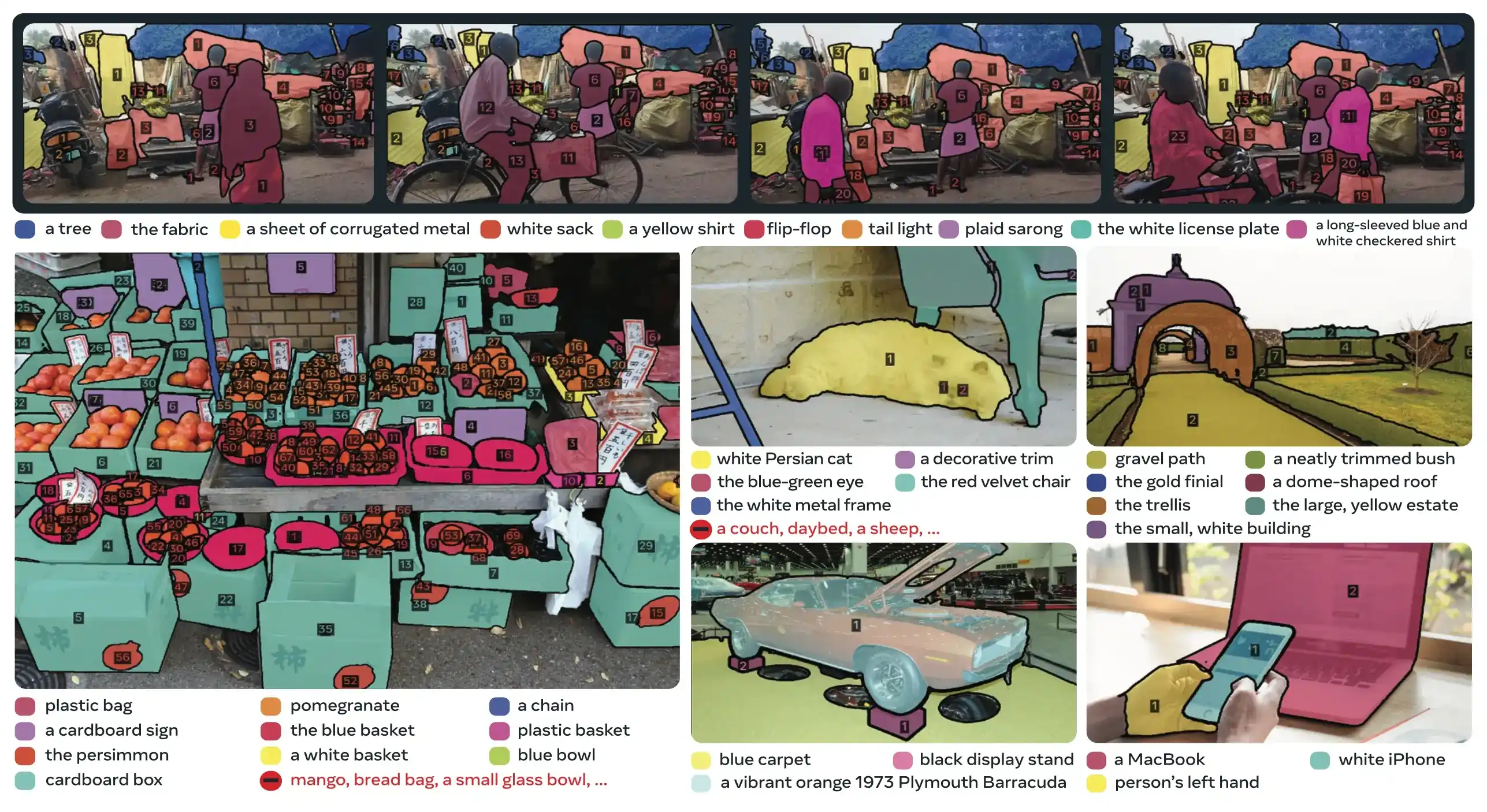
Основные инновации
- Разделенное распознавание и локализация: Голова присутствия предсказывает наличие концепции глобально, в то время как запросы предложений фокусируются только на локализации, избегая противоречивых целей.
- Унифицированные концептуальные и визуальные подсказки: Поддерживает как PCS (концептуальные подсказки), так и PVS (визуальные подсказки, такие как клики/боксы SAM 2) в одной модели.
- Интерактивное уточнение экземпляров: Пользователи могут добавлять положительные или отрицательные примеры изображений для итеративного уточнения результатов, при этом модель обобщает похожие объекты, а не просто исправляет отдельные экземпляры.
- Временная дезабигуация: Использует оценки обнаружения masklet и периодическое повторное запрограммирование для обработки окклюзий, переполненных сцен и сбоев отслеживания в видео, что соответствует лучшим практикам сегментации и отслеживания экземпляров.
Набор данных SA-Co
SAM 3 обучен на Segment Anything with Concepts (SA-Co), самом большом и разнообразном наборе данных для segment от Meta на сегодняшний день, выходящем за рамки общих бенчмарков, таких как COCO и LVIS.
Данные для обучения
| Компонент набора данных | Описание | Масштаб |
|---|---|---|
| SA-Co/HQ | Высококачественные изображения, аннотированные вручную, из 4-фазного механизма данных | 5.2M изображений, 4M уникальных именных групп |
| SA-Co/SYN | Синтетический набор данных, размеченный ИИ без участия человека | 38M именных групп, 1.4B масок |
| SA-Co/EXT | 15 внешних наборов данных, обогащенных сложными негативными примерами | Зависит от источника |
| SA-Co/VIDEO | Аннотации видео с отслеживанием времени | 52.5K видео, 24.8K уникальных именных групп |
Эталонные данные
Бенчмарк оценки SA-Co содержит 214 тыс. уникальных фраз на 126 тыс. изображениях и видео, предоставляя более чем в 50 раз больше концепций, чем существующие бенчмарки. Он включает в себя:
- SA-Co/Gold: 7 доменов, с тройной аннотацией для измерения границ производительности человека
- SA-Co/Silver: 10 доменов, единичная человеческая аннотация
- SA-Co/Bronze и SA-Co/Bio: 9 существующих наборов данных, адаптированных для концептуальной сегментации
- SA-Co/VEval: Видео бенчмарк с 3 доменами (SA-V, YT-Temporal-1B, SmartGlasses)
Инновации в механизме обработки данных
Масштабируемый механизм данных SAM 3 с участием человека и модели обеспечивает 2-кратное увеличение пропускной способности аннотаций за счет:
- AI Annotators: Модели на основе Llama предлагают разнообразные именные группы, включая сложные негативы
- AI Verifiers: Точно настроенные мультимодальные LLM проверяют качество маски и исчерпывающий характер с почти человеческой производительностью
- Активный майнинг: Сосредоточение усилий человека на сложных случаях с ошибками, с которыми сталкивается ИИ
- Основанный на онтологии: Использует большую онтологию, основанную на Wikidata, для охвата концепций
Установка
SAM 3 доступен в Ultralytics версии 8.3.237 и более поздних версиях. Установите или обновите с помощью:
pip install -U ultralytics
Требуются веса модели SAM 3
В отличие от других моделей Ultralytics, веса SAM 3 (sam3.pt) не загружаются автоматически. Сначала необходимо запросить доступ к весам модели на странице модели SAM 3 на Hugging Face , а затем, после одобрения, загрузить sam3.pt файла. Разместите загруженный sam3.pt файл в вашу рабочую директорию или укажите полный путь при загрузке модели.
TypeError: 'SimpleTokenizer' object is not callable
Если вы получаете указанную выше ошибку во время предсказания, это означает, что у вас установлена некорректная clip версия пакета. Установите правильный clip пакет, выполнив следующее:
pip uninstall clip -y
pip install git+https://github.com/ultralytics/CLIP.git
Как использовать SAM 3: Универсальность в концептуальной segmentации
SAM 3 поддерживает как задачи сегментации концепций по запросу (PCS), так и задачи визуальной сегментации по запросу (PVS) через различные интерфейсы предиктора:
Поддерживаемые задачи и модели
| Тип задачи | Типы запросов | Вывод |
|---|---|---|
| Сегментация концепций (PCS) | Текст (именные группы), образцы изображений | Все экземпляры, соответствующие концепции |
| Визуальная сегментация (PVS) | Points, boxes, masks | Единичный экземпляр объекта (стиль SAM 2) |
| Интерактивное уточнение | Итеративное добавление/удаление образцов или щелчков | Улучшенная сегментация с повышенной точностью |
Примеры сегментации концепций
Segment с использованием текстовых запросов
Сегментация концепций на основе текста
Найдите и segment все экземпляры концепции, используя текстовое описание. Текстовые подсказки требуют SAM3SemanticPredictor интерфейс.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor with configuration
overrides = dict(
conf=0.25,
task="segment",
mode="predict",
model="sam3.pt",
half=True, # Use FP16 for faster inference
save=True,
)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image once for multiple queries
predictor.set_image("path/to/image.jpg")
# Query with multiple text prompts
results = predictor(text=["person", "bus", "glasses"])
# Works with descriptive phrases
results = predictor(text=["person with red cloth", "person with blue cloth"])
# Query with a single concept
results = predictor(text=["a person"])
Segment с использованием образцов изображений
Сегментация на основе образцов изображений
Используйте ограничивающие рамки в качестве визуальных подсказок для поиска всех похожих экземпляров. Это также требует SAM3SemanticPredictor для сопоставления на основе концепций.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", half=True, save=True)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image
predictor.set_image("path/to/image.jpg")
# Provide bounding box examples to segment similar objects
results = predictor(bboxes=[[480.0, 290.0, 590.0, 650.0]])
# Multiple bounding boxes for different concepts
results = predictor(bboxes=[[539, 599, 589, 639], [343, 267, 499, 662]])
Инференс на основе признаков для повышения эффективности
Повторное использование признаков изображения для нескольких запросов
Извлечь признаки изображения один раз и повторно использовать их для множественных запросов сегментации для повышения эффективности.
import cv2
from ultralytics.models.sam import SAM3SemanticPredictor
from ultralytics.utils.plotting import Annotator, colors
# Initialize predictors
overrides = dict(conf=0.50, task="segment", mode="predict", model="sam3.pt", verbose=False)
predictor = SAM3SemanticPredictor(overrides=overrides)
predictor2 = SAM3SemanticPredictor(overrides=overrides)
# Extract features from the first predictor
source = "path/to/image.jpg"
predictor.set_image(source)
src_shape = cv2.imread(source).shape[:2]
# Setup second predictor and reuse features
predictor2.setup_model()
# Perform inference using shared features with text prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, text=["person"])
# Perform inference using shared features with bounding box prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, bboxes=[[439, 437, 524, 709]])
# Visualize results
if masks is not None:
masks, boxes = masks.cpu().numpy(), boxes.cpu().numpy()
im = cv2.imread(source)
annotator = Annotator(im, pil=False)
annotator.masks(masks, [colors(x, True) for x in range(len(masks))])
cv2.imshow("result", annotator.result())
cv2.waitKey(0)
Сегментация видео по концепциям
Отслеживание концепций по всему видео с помощью ограничивающих рамок
Отслеживание объектов на видео с визуальными подсказками
detect и track экземпляры объектов по видеокадрам, используя подсказки в виде ограничивающих рамок.
from ultralytics.models.sam import SAM3VideoPredictor
# Create video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", half=True)
predictor = SAM3VideoPredictor(overrides=overrides)
# Track objects using bounding box prompts
results = predictor(source="path/to/video.mp4", bboxes=[[706.5, 442.5, 905.25, 555], [598, 635, 725, 750]], stream=True)
# Process and display results
for r in results:
r.show() # Display frame with segmentation masks
Отслеживание концепций с помощью текстовых подсказок
Отслеживание объектов на видео с семантическими запросами
track все экземпляры концепций, заданных текстом, по видеокадрам.
from ultralytics.models.sam import SAM3VideoSemanticPredictor
# Initialize semantic video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=640, model="sam3.pt", half=True, save=True)
predictor = SAM3VideoSemanticPredictor(overrides=overrides)
# Track concepts using text prompts
results = predictor(source="path/to/video.mp4", text=["person", "bicycle"], stream=True)
# Process results
for r in results:
r.show() # Display frame with tracked objects
# Alternative: Track with bounding box prompts
results = predictor(
source="path/to/video.mp4",
bboxes=[[864, 383, 975, 620], [705, 229, 782, 402]],
labels=[1, 1], # Positive labels
stream=True,
)
Визуальные подсказки (совместимость с SAM 2)
SAM 3 поддерживает полную обратную совместимость с визуальными подсказками SAM 2 для сегментации одиночных объектов:
Визуальные подсказки в стиле SAM 2
Базовый SAM интерфейс ведет себя точно так же, как SAM 2, segment только определенную область, указанную визуальными подсказками (точки, рамки или маски).
from ultralytics import SAM
model = SAM("sam3.pt")
# Single point prompt - segments object at specific location
results = model.predict(source="path/to/image.jpg", points=[900, 370], labels=[1])
results[0].show()
# Multiple points - segments single object with multiple point hints
results = model.predict(source="path/to/image.jpg", points=[[400, 370], [900, 370]], labels=[1, 1])
# Box prompt - segments object within bounding box
results = model.predict(source="path/to/image.jpg", bboxes=[100, 150, 300, 400])
results[0].show()
Визуальные подсказки против сегментации концепций
Используя SAM("sam3.pt") с визуальными подсказками (точки/рамки/маски) будет segment только конкретный объект в этом месте, точно так же, как SAM 2. Чтобы segment все экземпляры концепции, используйте SAM3SemanticPredictor с текстовыми или образцовыми подсказками, как показано выше.
Ориентиры производительности
Сегментация изображений
SAM 3 достигает самых современных результатов по нескольким бенчмаркам, включая наборы данных реального мира, такие как LVIS и COCO для сегментации:
| Бенчмарк | Метрика | SAM 3 | Предыдущий лучший результат | Улучшение |
|---|---|---|---|---|
| LVIS (zero-shot) | Mask AP | 47.0 | 38.5 | +22.1% |
| SA-Co/Gold | CGF1 | 65.0 | 34.3 (OWLv2) | +89.5% |
| COCO (zero-shot) | AP ограничивающей рамки | 53.5 | 52.2 (T-Rex2) | +2.5% |
| ADE-847 (семантическая сегментация) | mIoU | 14.7 | 9.2 (APE-D) | +59.8% |
| PascalConcept-59 | mIoU | 59.4 | 58.5 (APE-D) | +1.5% |
| Cityscapes (семантическая сегментация) | mIoU | 65.1 | 44.2 (APE-D) | +47.3% |
Изучите варианты наборов данных для быстрого экспериментирования в наборах данных Ultralytics.
Производительность сегментации видео
SAM 3 показывает значительные улучшения по сравнению с SAM 2 и предыдущим уровнем техники в видео-бенчмарках, таких как DAVIS 2017 и YouTube-VOS:
| Бенчмарк | Метрика | SAM 3 | SAM 2.1 L | Улучшение |
|---|---|---|---|---|
| MOSEv2 | J&F | 60.1 | 47.9 | +25.5% |
| DAVIS 2017 | J&F | 92.0 | 90.7 | +1.4% |
| LVOSv2 | J&F | 88.2 | 79.6 | +10.8% |
| SA-V | J&F | 84.6 | 78.4 | +7.9% |
| YTVOS19 | J&F | 89.6 | 89.3 | +0.3% |
Адаптация при малом количестве примеров
SAM 3 отлично адаптируется к новым доменам с минимальным количеством примеров, что актуально для рабочих процессов ориентированного на данные ИИ:
| Бенчмарк | 0-shot AP | 10-shot AP | Предыдущий лучший результат (10 попыток) |
|---|---|---|---|
| ODinW13 | 59.9 | 71.6 | 67.9 (gDino1.5-Pro) |
| RF100-VL | 14.3 | 35.7 | 33.7 (gDino-T) |
Эффективность интерактивной доработки
Концептуальные подсказки с использованием образцов в SAM 3 сходятся гораздо быстрее, чем визуальные подсказки:
| Добавлены запросы | Оценка CGF1 | Gain vs Text-Only | Gain vs PVS Baseline |
|---|---|---|---|
| Только текст | 46.4 | базовая линия | базовая линия |
| +1 образец | 57.6 | +11.2 | +6.7 |
| +2 образца | 62.2 | +15.8 | +9.7 |
| +3 образца | 65.0 | +18.6 | +11.2 |
| +4 образца | 65.7 | +19.3 | +11.5 (плато) |
Точность подсчета объектов
SAM 3 обеспечивает точный подсчет путем segment всех экземпляров, что является общим требованием при подсчете объектов:
| Бенчмарк | Точность | MAE | vs Best MLLM |
|---|---|---|---|
| CountBench | 95.6% | 0.11 | 92.4% (Gemini 2.5) |
| PixMo-Count | 87.3% | 0.22 | 88.8% (Molmo-72B) |
Сравнение SAM 3, SAM 2 и YOLO
Здесь мы сравниваем возможности SAM с моделями SAM и YOLO26:
| Возможность | SAM 3 | SAM 2 | YOLO26n-seg |
|---|---|---|---|
| Сегментация концепций | ✅ Все экземпляры из текста/образцов | ❌ Не поддерживается | ❌ Не поддерживается |
| Визуальная сегментация | ✅ Единичный экземпляр (совместимо с SAM 2) | ✅ Единичный экземпляр | ✅ Все экземпляры |
| Zero-shot Capability | ✅ Открытый словарь | ✅ Геометрические подсказки | ❌ Закрытый набор |
| Интерактивное уточнение | ✅ Образцы + клики | ✅ Только клики | ❌ Не поддерживается |
| Video Tracking | ✅ Multi-object с идентификаторами | ✅ Multi-object | ✅ Multi-object |
| LVIS Mask AP (zero-shot) | 47.0 | Н/Д | Н/Д |
| MOSEv2 J&F | 60.1 | 47.9 | Н/Д |
| Скорость (GPU, мс/кадр) | 2921 | 857 | 8.4 |
| Размер модели | 3.45 ГБ | 162 MB (базовый) | 6,4 МБ |
Тестирование производительности проведено на NVIDIA PRO 6000 с torch==2.9.1 и ultralytics==8.4.19.
Основные выводы:
- SAM 3: Лучшее решение для сегментации концепций с открытым словарем, поиска всех экземпляров концепции с помощью текста или образцов подсказок
- SAM 2: Лучшее решение для интерактивной сегментации отдельных объектов на изображениях и видео с геометрическими подсказками
- YOLO26: оптимальный вариант для высокоскоростной сегментации в режиме реального времени с сквозным вычислением NMS, с возможностью экспорта в множество форматов для развертывания на графических процессорах, центральных процессорах и периферийных устройствах
Сравнение SAM и YOLO
Сравнение SAM , SAM , SAM, MobileSAM и FastSAM моделямиYOLO Ultralytics YOLO (YOLOv8, YOLO11, YOLO26) по размеру, параметрам и скорости GPU :
| Модель | Размер (МБ) | Параметры (M) | Скорость (GPU) (мс/изобр) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 1306 |
| Meta SAM2-b | 162 | 80.8 | 857 |
| Meta SAM2-t | 78.1 | 38.9 | 668 |
| Meta SAM3 | 3450 | 473.6 | 2921 |
| MobileSAM | 40.7 | 10.1 | 605 |
| FastSAM-s с backbone YOLOv8 | 23.7 | 11.8 | 55.9 |
| Ultralytics YOLOv8n-seg | 6,7 (в 515 раз меньше) | 3.4 (в 139.1 раза меньше) | 17.4 (в 167 раз быстрее) |
| Ultralytics YOLO11n-seg | 5,9 (в 585 раз меньше) | 2.9 (в 163.1 раза меньше) | 12.6 (в 231 раз быстрее) |
| Ultralytics YOLO26n-seg | 6,4 (в 539 раз меньше) | 2.7 (в 175.2 раза меньше) | 8.4 (в 347 раз быстрее) |
Это сравнение демонстрирует существенные различия в размерах и скоростях моделей между вариантами SAM и моделями segmentation YOLO. В то время как SAM предоставляет уникальные возможности автоматической segmentation, модели YOLO, в частности YOLOv8n-seg, YOLO11n-seg и YOLO26n-seg, значительно меньше, быстрее и более вычислительно эффективны.
Тесты проводились на NVIDIA RTX PRO 6000 с 96 ГБ VRAM с использованием torch==2.9.1 и ultralytics==8.4.19. Чтобы воспроизвести этот тест:
Пример
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# Profile SAM3, SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt", "sam3.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# Profile FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# Profile YOLO models
for file_name in ["yolov8n-seg.pt", "yolo11n-seg.pt", "yolo26n-seg.pt"]:
model = YOLO(file_name)
model.info()
model(ASSETS)
Метрики оценки
SAM 3 представляет новые метрики, разработанные для задачи PCS, дополняющие знакомые меры, такие как F1 score, precision и recall.
Classification-Gated F1 (CGF1)
Основная метрика, объединяющая локализацию и классификацию:
CGF1 = 100 × pmF1 × IL_MCC
Где:
- pmF1 (Positive Macro F1): Измеряет качество локализации на положительных примерах
- IL_MCC (коэффициент корреляции Мэтьюза на уровне изображения): Измеряет точность бинарной классификации («присутствует ли концепция?»)
Почему именно эти метрики?
Традиционные метрики AP не учитывают калибровку, что затрудняет использование моделей на практике. Оценивая только прогнозы с уверенностью выше 0,5, метрики SAM 3 обеспечивают хорошую калибровку и имитируют реальные сценарии использования в интерактивных циклах predict и track.
Ключевые Анализы и Выводы
Влияние Presence Head
Голова присутствия отделяет распознавание от локализации, обеспечивая значительные улучшения:
| Конфигурация | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Без присутствия | 57.6 | 0.77 | 74.7 |
| С присутствием | 63.3 | 0.82 | 77.1 |
Голова присутствия обеспечивает увеличение CGF1 на +5,7 (+9,9%), в первую очередь улучшая способность распознавания (IL_MCC +6,5%).
Влияние сложных негативных примеров
| Сложные негативные примеры / Изображение | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 0 | 31.8 | 0.44 | 70.2 |
| 5 | 44.8 | 0.62 | 71.9 |
| 30 | 49.2 | 0.68 | 72.3 |
Сложные негативные примеры имеют решающее значение для распознавания с открытым словарем, улучшая IL_MCC на 54.5% (0.44 → 0.68).
Масштабирование данных для обучения
| Источники данных | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Только внешние | 30.9 | 0.46 | 66.3 |
| Внешние + Синтетические | 39.7 | 0.57 | 70.6 |
| Внешние + HQ | 51.8 | 0.71 | 73.2 |
| Все три | 54.3 | 0.74 | 73.5 |
Высококачественная ручная аннотация дает большой прирост по сравнению только с синтетическими или внешними данными. Для получения информации о методах обеспечения качества данных см. сбор и аннотацию данных.
Приложения
Возможность концептуальной segment-ции SAM 3 открывает новые варианты использования:
- Модерация контента: Поиск всех экземпляров определенных типов контента в медиатеках
- Электронная коммерция: Segment все продукты определенного типа на изображениях каталога, поддерживая автоматическую аннотацию.
- Медицинская визуализация: Идентифицируйте все случаи конкретных типов тканей или аномалий
- Автономные системы: Track всех экземпляров дорожных знаков, пешеходов или транспортных средств по категориям
- Видеоаналитика: Подсчет и отслеживание всех людей, одетых в определенную одежду или выполняющих действия
- Аннотирование наборов данных: Быстрая аннотация всех экземпляров редких категорий объектов
- Научные исследования: Количественная оценка и анализ всех образцов, соответствующих определенным критериям
Агент SAM 3: Расширенное языковое рассуждение
SAM 3 можно комбинировать с большими мультимодальными языковыми моделями (MLLM) для обработки сложных запросов, требующих рассуждений, что похоже на системы с открытым словарем, такие как OWLv2 и T-Rex.
Производительность в задачах логического вывода
| Бенчмарк | Метрика | Агент SAM 3 (Gemini 2.5 Pro) | Предыдущий лучший результат |
|---|---|---|---|
| ReasonSeg (валидация) | GIoU | 76.0 | 65.0 (SoTA) |
| ReasonSeg (тест) | GIoU | 73.8 | 61.3 (SoTA) |
| OmniLabel (валидация) | AP | 46.7 | 36.5 (REAL) |
| RefCOCO+ | Точ | 91.2 | 89.3 (LISA) |
Примеры сложных запросов
Агент SAM 3 может обрабатывать запросы, требующие рассуждений:
- "Люди сидят, но не держат подарочную коробку в руках"
- "Собака, ближайшая к камере, на которой нет ошейника"
- "Красные объекты больше руки человека"
MLLM предлагает простые запросы с существительными фразами к SAM 3, анализирует возвращенные маски и выполняет итерации до тех пор, пока не будет достигнут желаемый результат.
Ограничения
Хотя SAM 3 представляет собой крупный шаг вперед, у него есть определенные ограничения:
- Сложность фраз: Лучше всего подходит для простых именных групп; длинные ссылочные выражения или сложные рассуждения могут потребовать интеграции MLLM
- Обработка неоднозначности: Некоторые концепции остаются по своей сути неоднозначными (например, «маленькое окно», «уютная комната»)
- Computational Requirements: Больше и медленнее, чем специализированные модели detect, такие как YOLO.
- Область словаря: Сосредоточенность на атомарных визуальных концепциях; композиционное рассуждение ограничено без помощи MLLM
- Редкие концепции: Производительность может ухудшиться на чрезвычайно редких или детализированных концепциях, недостаточно представленных в обучающих данных.
Цитата
@inproceedings{sam3_2025,
title = {SAM 3: Segment Anything with Concepts},
author = {Anonymous authors},
booktitle = {Submitted to ICLR 2026},
year = {2025},
url = {https://openreview.net/forum?id=r35clVtGzw},
note = {Paper ID: 4183, under double-blind review}
}
Часто задаваемые вопросы
Когда была выпущена SAM 3?
SAM 3 был выпущен Meta 20 ноября 2025 года и полностью интегрирован в Ultralytics начиная с версии 8.3.237 (PR #22897). Полная поддержка доступна для режима predict и режима track.
Интегрирована ли SAM 3 в Ultralytics?
Да! SAM полностью интегрирован вPython Ultralytics Python , включая концептуальную сегментацию, визуальные подсказки SAM и отслеживание нескольких объектов на видео. SAM также лежит в основе функции интеллектуальной аннотации на Ultralytics , где вы можете аннотировать изображения всего за несколько кликов.
Что такое сегментация концепций с подсказками (Promptable Concept Segmentation, PCS)?
PCS — это новая задача, представленная в SAM 3, которая segment все экземпляры визуального концепта на изображении или видео. В отличие от традиционной segmentации, которая нацелена на конкретный экземпляр объекта, PCS находит каждое появление категории. Например:
- Текстовый запрос: "желтый школьный автобус" → segment все желтые школьные автобусы в кадре
- Образец изображения: Обведите одного пса → segment всех псов на изображении
- Вместе: "полосатая кошка" + пример рамки → segment всех полосатых кошек, соответствующих примеру
См. соответствующую справочную информацию об обнаружении объектов и сегментации экземпляров.
Чем SAM 3 отличается от SAM 2?
| Функциональность | SAM 2 | SAM 3 |
|---|---|---|
| Задача | Один объект на запрос | Все экземпляры концепции |
| Типы запросов | Points, boxes, masks | + Текстовые фразы, образцы изображений |
| Возможности обнаружения | Требуется внешний детектор | Встроенный детектор с открытым словарем |
| Распознавание | Geometry-based only | Текстовое и визуальное распознавание |
| Архитектура | Только трекер | Детектор + Трекер с головкой присутствия |
| Производительность Zero-Shot | Н/Д (требуются визуальные подсказки) | 47.0 AP на LVIS, в 2 раза лучше на SA-Co |
| Интерактивное уточнение | Только клики | Клики + обобщение по образцу |
SAM 3 поддерживает обратную совместимость с визуальными подсказками SAM 2, добавляя возможности на основе концепций.
Какие наборы данных используются для обучения SAM 3?
SAM 3 обучен на наборе данных Segment Anything with Concepts (SA-Co):
Обучающие данные:
- 5,2 млн изображений с 4 млн уникальных имен существительных (SA-Co/HQ) - высококачественные аннотации, выполненные людьми
- 52,5 тыс. видео с 24,8 тыс. уникальных имен существительных (SA-Co/VIDEO)
- 1.4B синтетических масок по 38M имен существительных (SA-Co/SYN)
- 15 внешних наборов данных, обогащенных сложными негативными примерами (SA-Co/EXT)
Эталонные данные:
- 214 тыс. уникальных концепций на 126 тыс. изображениях/видео
- В 50 раз больше концепций, чем в существующих бенчмарках (например, LVIS имеет ~4 тыс. концепций)
- Тройная аннотация на SA-Co/Gold для измерения границ производительности человека
Этот огромный масштаб и разнообразие обеспечивают превосходное обобщение SAM 3 с нулевым выстрелом по концепциям с открытым словарем.
Как SAM сравнивается с YOLO26 в плане сегментации?
SAM и YOLO26 предназначены для разных задач:
SAM 3 Advantages:
- Открытый словарь: Сегментирует любую концепцию с помощью текстовых подсказок без обучения
- Zero-shot: Работает с новыми категориями немедленно
- Интерактивное: Уточнение на основе экземпляров обобщается на похожие объекты
- На основе концепций: Автоматически находит все экземпляры категории
- Точность: 47.0 AP при zero-shot сегментации экземпляров LVIS
Преимущества YOLO26:
- Скорость: инференс, выполняемый на порядок быстрее благодаря сквозной архитектуре NMS
- Эффективность: модели в 539 раз меньше (6,4 МБ против 3,45 ГБ)
- Экономичность ресурсов: Работает на периферийных устройствах и мобильных устройствах
- Реальное время: Оптимизировано для производственных развертываний
Рекомендация:
- Используйте SAM 3 для гибкой segment-ации с открытым словарем, когда вам нужно найти все экземпляры концепций, описанных текстом или примерами
- Используйте YOLO26 для высокоскоростного развертывания в производственной среде, когда категории известны заранее
- Используйте SAM 2 для интерактивной segment-ации отдельных объектов с геометрическими подсказками
Может ли SAM 3 обрабатывать сложные языковые запросы?
SAM 3 предназначен для простых существительных фраз (например, «красное яблоко», «человек в шляпе»). Для сложных запросов, требующих рассуждений, объедините SAM 3 с MLLM как SAM 3 Agent:
Простые запросы (нативный SAM 3):
- "желтый школьный автобус"
- "полосатая кошка"
- "человек в красной шляпе"
Сложные запросы (SAM 3 Agent с MLLM):
- "Люди сидят, но не держат подарочную коробку"
- "Собака, ближайшая к камере, без ошейника"
- "Красные объекты больше руки человека"
Агент SAM 3 достигает 76,0 gIoU на валидации ReasonSeg (по сравнению с 65,0 предыдущим лучшим результатом, улучшение на +16,9%) за счет объединения сегментации SAM 3 с возможностями рассуждения MLLM.
Насколько точен SAM 3 по сравнению с производительностью человека?
На бенчмарке SA-Co/Gold с тройной аннотацией человека:
- Нижняя граница для человека: 74.2 CGF1 (самый консервативный аннотатор)
- SAM 3 performance: 65.0 CGF1
- Достижение: 88% от оценочной нижней границы человеческих возможностей
- Верхняя граница для человека: 81.4 CGF1 (самый либеральный аннотатор)
SAM 3 демонстрирует высокую производительность, приближающуюся к точности человеческого уровня в сегментации концепций с открытым словарем, при этом разрыв в основном приходится на неоднозначные или субъективные концепции (например, «маленькое окно», «уютная комната»).







