Link to this sectionSAM 3: Phân đoạn mọi thứ với các khái niệm (Segment Anything with Concepts)#
SAM 3 đã được tích hợp đầy đủ vào gói Ultralytics kể từ phiên bản 8.3.237 (PR #22897). Hãy cài đặt hoặc nâng cấp bằng pip install -U ultralytics để truy cập tất cả các tính năng của SAM 3 bao gồm phân đoạn khái niệm dựa trên văn bản, gợi ý mẫu hình ảnh và theo dõi video.
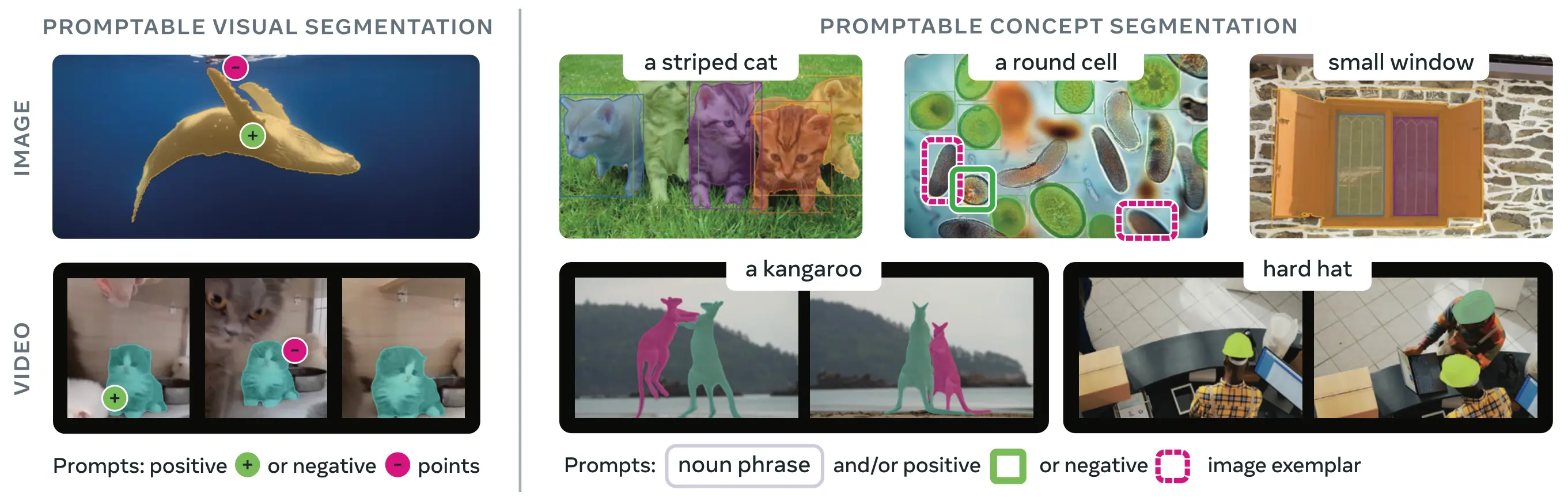
SAM 3 (Segment Anything Model 3) là mô hình nền tảng do Meta phát hành cho Phân đoạn Khái niệm có thể nhắc (PCS - Promptable Concept Segmentation). Xây dựng dựa trên SAM 2, SAM 3 giới thiệu một khả năng hoàn toàn mới: phát hiện, phân đoạn và theo dõi tất cả các thực thể của một khái niệm trực quan được chỉ định bởi các gợi ý văn bản, mẫu hình ảnh hoặc cả hai. Không giống như các phiên bản SAM trước đây chỉ phân đoạn từng đối tượng đơn lẻ cho mỗi gợi ý, SAM 3 có thể tìm và phân đoạn mọi sự xuất hiện của một khái niệm ở bất kỳ đâu trong hình ảnh hoặc video, phù hợp với các mục tiêu từ vựng mở trong phân đoạn thực thể hiện đại.
Watch: How to Use Meta Segment Anything 3 with Ultralytics | Text-Prompt Segmentation on Images & Videos
SAM 3 hiện đã được tích hợp đầy đủ vào gói ultralytics, cung cấp hỗ trợ gốc cho phân đoạn khái niệm với các gợi ý văn bản, gợi ý mẫu hình ảnh và khả năng theo dõi video.
Link to this sectionTổng quan#
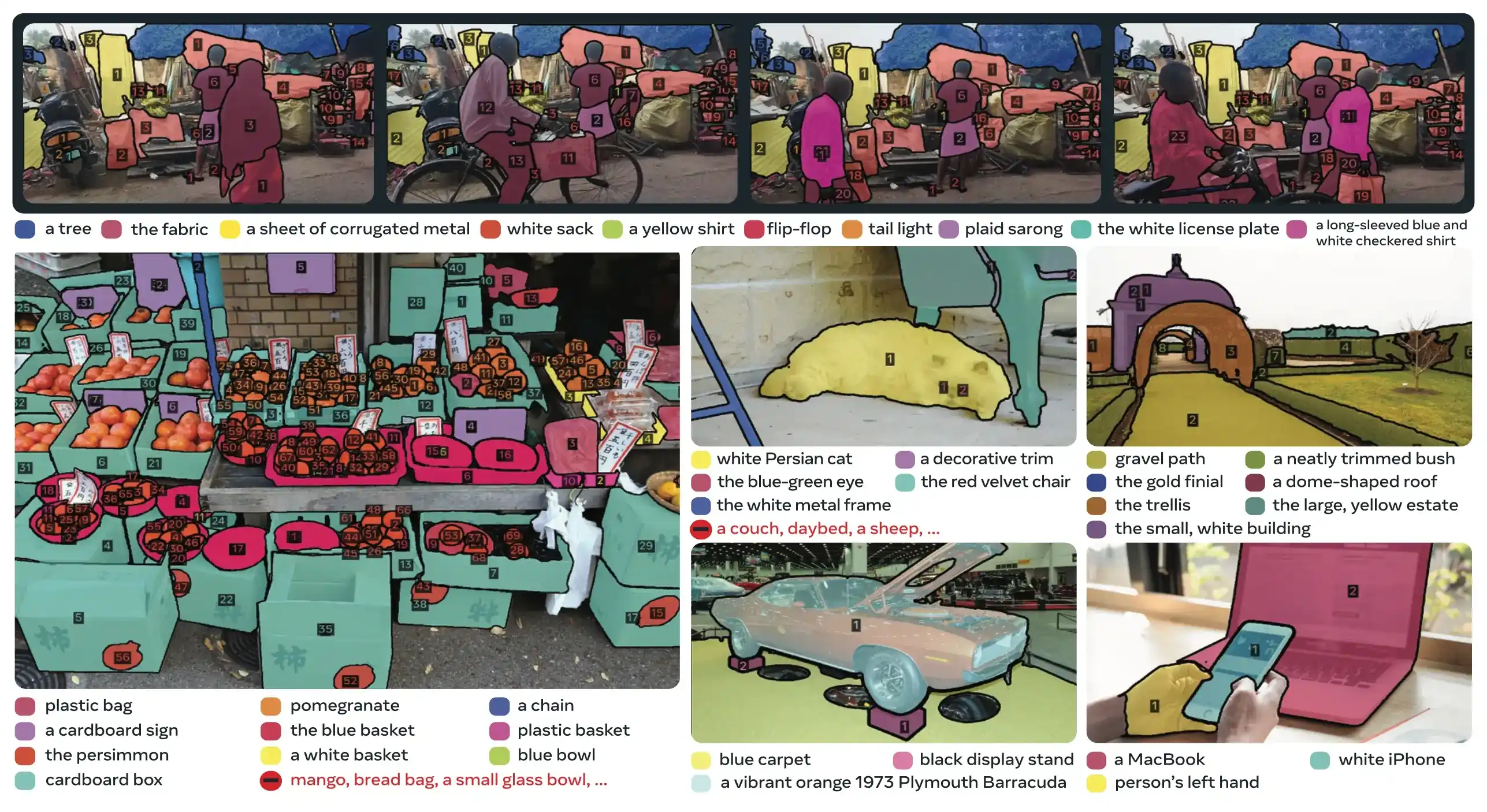
SAM 3 đạt hiệu suất tăng gấp 2 lần so với các hệ thống hiện có trong Phân đoạn Khái niệm có thể nhắc (Promptable Concept Segmentation) trong khi vẫn duy trì và cải thiện các khả năng của SAM 2 cho phân đoạn thị giác tương tác. Model này vượt trội trong việc phân đoạn từ vựng mở, cho phép người dùng chỉ định các khái niệm bằng cách sử dụng các cụm danh từ đơn giản (ví dụ: "xe buýt trường học màu vàng", "mèo vằn") hoặc bằng cách cung cấp các hình ảnh mẫu của đối tượng mục tiêu. Những khả năng này bổ sung cho các quy trình sẵn sàng cho sản xuất dựa trên các luồng công việc predict (dự đoán) và track (theo dõi) được tối ưu hóa.
Link to this sectionPhân đoạn Khái niệm có thể nhắc (PCS) là gì?#
Tác vụ PCS lấy một gợi ý khái niệm làm đầu vào và trả về các mặt nạ phân đoạn với định danh duy nhất cho tất cả các thực thể đối tượng khớp. Các gợi ý khái niệm có thể là:
- Văn bản: Các cụm danh từ đơn giản như "quả táo đỏ" hoặc "người đội mũ", tương tự như zero-shot learning
- Mẫu hình ảnh: Các khung bao (bounding box) xung quanh các đối tượng ví dụ (tích cực hoặc tiêu cực) để tổng quát hóa nhanh
- Kết hợp: Cả văn bản và mẫu hình ảnh cùng nhau để kiểm soát chính xác
Điều này khác với các gợi ý trực quan truyền thống (điểm, hộp, mặt nạ) vốn chỉ phân đoạn một thực thể đối tượng cụ thể duy nhất, như đã được phổ biến bởi họ SAM ban đầu.
Link to this sectionCác chỉ số hiệu suất chính#
| Chỉ số | Thành tựu của SAM 3 |
|---|---|
| LVIS Zero-Shot Mask AP | 47.0 (so với mức tốt nhất trước đó là 38.5, cải thiện +22%) |
| Điểm chuẩn SA-Co | Tốt hơn 2 lần so với các hệ thống hiện có |
| Tốc độ suy luận (GPU H200) | 30 ms mỗi hình ảnh với hơn 100 đối tượng được phát hiện |
| Hiệu suất video | Gần thời gian thực cho ~5 đối tượng đồng thời |
| Điểm chuẩn MOSEv2 VOS | 60.1 J&F (+25.5% so với SAM 2.1, +17% so với SOTA trước đó) |
| Tinh chỉnh tương tác | Cải thiện +18.6 CGF1 sau 3 gợi ý mẫu |
| Khoảng cách hiệu suất con người | Đạt 88% cận dưới ước tính trên SA-Co/Gold |
Để biết bối cảnh về các chỉ số mô hình và đánh đổi trong sản xuất, hãy xem thông tin chi tiết về đánh giá mô hình và các chỉ số hiệu suất YOLO.
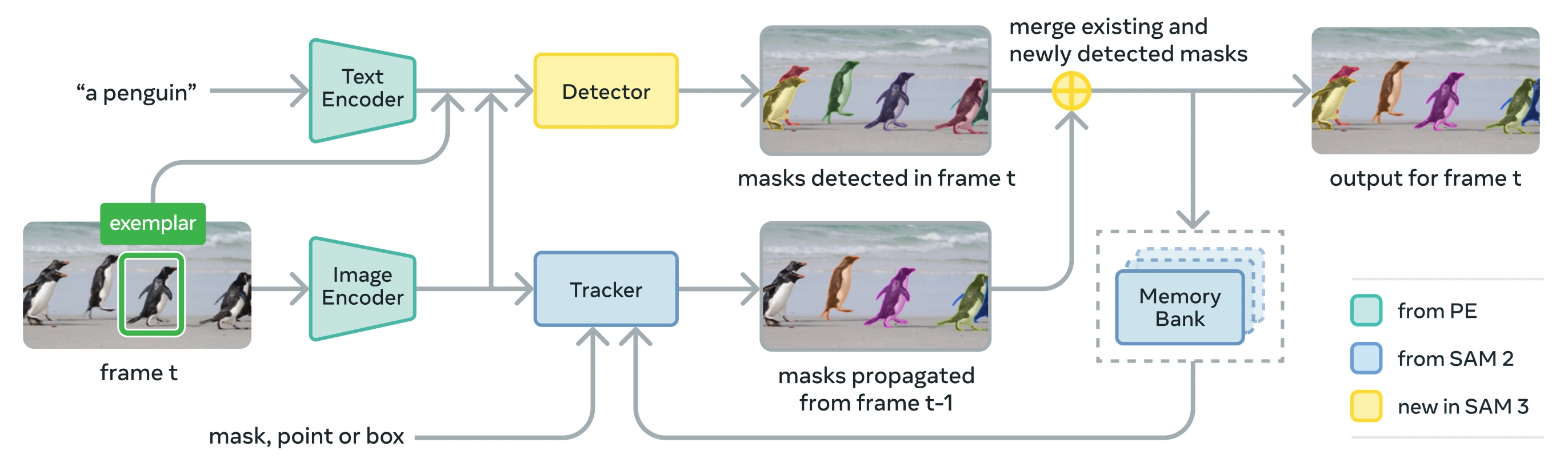
Link to this sectionKiến trúc#
SAM 3 bao gồm một bộ phát hiện (detector) và bộ theo dõi (tracker) cùng chia sẻ một xương sống thị giác Perception Encoder (PE). Thiết kế tách rời này tránh xung đột tác vụ trong khi cho phép cả phát hiện cấp độ hình ảnh và theo dõi cấp độ video, với giao diện tương thích với cách sử dụng Python và cách sử dụng CLI của Ultralytics.
Link to this sectionCác thành phần cốt lõi#
-
Bộ phát hiện: Kiến trúc dựa trên DETR để phát hiện khái niệm ở cấp độ hình ảnh
- Bộ mã hóa văn bản cho các gợi ý cụm danh từ
- Bộ mã hóa mẫu cho các gợi ý dựa trên hình ảnh
- Bộ mã hóa hợp nhất để điều kiện hóa các đặc trưng hình ảnh dựa trên gợi ý
- Presence head mới giúp tách biệt nhận dạng ("cái gì") khỏi định vị ("ở đâu")
- Mask head để tạo các mặt nạ phân đoạn thực thể
-
Bộ theo dõi: Phân đoạn video dựa trên bộ nhớ được thừa hưởng từ SAM 2
- Bộ mã hóa gợi ý, bộ giải mã mặt nạ, bộ mã hóa bộ nhớ
- Ngân hàng bộ nhớ để lưu trữ ngoại hình đối tượng qua các khung hình
- Giải quyết nhập nhằng thời gian được hỗ trợ bởi các kỹ thuật như bộ lọc Kalman trong các cài đặt đa đối tượng
-
Presence Token: Một token toàn cầu đã học giúp dự đoán liệu khái niệm mục tiêu có xuất hiện trong hình ảnh/khung hình hay không, cải thiện khả năng phát hiện bằng cách tách biệt nhận dạng khỏi định vị.
Link to this sectionNhững cải tiến chính#
- Nhận dạng và Định vị Tách biệt: Presence head dự đoán sự hiện diện của khái niệm trên toàn cầu, trong khi các truy vấn đề xuất chỉ tập trung vào định vị, tránh các mục tiêu xung đột.
- Gợi ý Khái niệm và Hình ảnh Hợp nhất: Hỗ trợ cả PCS (gợi ý khái niệm) và PVS (gợi ý trực quan như các cú nhấp chuột/hộp của SAM 2) trong một mô hình duy nhất.
- Tinh chỉnh Mẫu Tương tác: Người dùng có thể thêm các mẫu hình ảnh tích cực hoặc tiêu cực để tinh chỉnh kết quả một cách lặp đi lặp lại, với việc mô hình tổng quát hóa sang các đối tượng tương tự thay vì chỉ sửa từng thực thể riêng lẻ.
- Giải quyết Nhập nhằng Thời gian: Sử dụng điểm phát hiện masklet và nhắc lại định kỳ để xử lý các trường hợp bị che khuất, cảnh đông đúc và lỗi theo dõi trong video, phù hợp với các thực tiễn tốt nhất về phân đoạn và theo dõi thực thể.
Link to this sectionTập dữ liệu SA-Co#
SAM 3 được huấn luyện trên Segment Anything with Concepts (SA-Co), tập dữ liệu phân đoạn lớn nhất và đa dạng nhất của Meta cho đến nay, mở rộng ra ngoài các điểm chuẩn phổ biến như COCO và LVIS.
Link to this sectionDữ liệu huấn luyện#
| Thành phần tập dữ liệu | Mô tả | Quy mô |
|---|---|---|
| SA-Co/HQ | Dữ liệu hình ảnh chất lượng cao được con người chú thích từ công cụ dữ liệu 4 giai đoạn | 5.2 triệu hình ảnh, 4 triệu cụm danh từ duy nhất |
| SA-Co/SYN | Tập dữ liệu tổng hợp được gắn nhãn bởi AI mà không cần sự tham gia của con người | 38 triệu cụm danh từ, 1.4 tỷ mặt nạ |
| SA-Co/EXT | 15 tập dữ liệu bên ngoài được làm giàu với các ví dụ tiêu cực khó (hard negatives) | Thay đổi theo nguồn |
| SA-Co/VIDEO | Các chú thích video với theo dõi thời gian | 52.5 nghìn video, 24.8 nghìn cụm danh từ duy nhất |
Link to this sectionDữ liệu điểm chuẩn#
Điểm chuẩn đánh giá SA-Co chứa 214 nghìn cụm từ duy nhất trên 126 nghìn hình ảnh và video, cung cấp hơn 50 lần số lượng khái niệm so với các điểm chuẩn hiện có. Nó bao gồm:
- SA-Co/Gold: 7 miền, được chú thích ba lần để đo lường giới hạn hiệu suất của con người
- SA-Co/Silver: 10 miền, một chú thích của con người
- SA-Co/Bronze và SA-Co/Bio: 9 tập dữ liệu hiện có được điều chỉnh cho phân đoạn khái niệm
- SA-Co/VEval: Điểm chuẩn video với 3 miền (SA-V, YT-Temporal-1B, SmartGlasses)
Link to this sectionNhững cải tiến của công cụ dữ liệu#
Công cụ dữ liệu có sự tham gia của con người và mô hình có khả năng mở rộng của SAM 3 đạt được thông lượng chú thích gấp 2 lần thông qua:
- Người chú thích AI: Các mô hình dựa trên Llama đề xuất các cụm danh từ đa dạng bao gồm các ví dụ tiêu cực khó
- Người xác minh AI: LLM đa phương thức được tinh chỉnh xác minh chất lượng và tính đầy đủ của mặt nạ ở hiệu suất gần bằng con người
- Khai thác chủ động (Active Mining): Tập trung nỗ lực của con người vào các trường hợp thất bại đầy thách thức nơi AI gặp khó khăn
- Định hướng bản thể luận (Ontology-Driven): Tận dụng một bản thể luận lớn dựa trên Wikidata để bao phủ khái niệm
Link to this sectionCài đặt#
SAM 3 khả dụng trong Ultralytics phiên bản 8.3.237 trở lên. Cài đặt hoặc nâng cấp bằng:
pip install -U ultralyticsKhông giống như các mô hình Ultralytics khác, trọng số SAM 3 (sam3.pt) không tự động tải xuống. Bạn phải yêu cầu quyền truy cập cho các trọng số mô hình trên trang mô hình SAM 3 trên Hugging Face và sau đó, khi đã được chấp thuận, hãy tải xuống sam3.pt từ trang đó. Đặt tệp sam3.pt đã tải xuống vào thư mục làm việc của bạn hoặc chỉ định đường dẫn đầy đủ khi tải mô hình.
Nếu bạn gặp lỗi trên trong quá trình dự đoán, điều đó có nghĩa là bạn đã cài đặt sai gói clip. Hãy cài đặt gói clip chính xác bằng cách chạy lệnh sau:
pip uninstall clip -y
pip install git+https://github.com/ultralytics/CLIP.gitLink to this sectionCách sử dụng SAM 3: Sự linh hoạt trong phân đoạn khái niệm#
SAM 3 hỗ trợ cả tác vụ Phân đoạn Khái niệm có thể nhắc (PCS) và Phân đoạn Trực quan có thể nhắc (PVS) thông qua các giao diện dự đoán khác nhau:
Link to this sectionCác tác vụ và mô hình được hỗ trợ#
| Loại tác vụ | Các loại gợi ý | Đầu ra |
|---|---|---|
| Phân đoạn Khái niệm (PCS) | Văn bản (cụm danh từ), mẫu hình ảnh | Tất cả các thực thể khớp với khái niệm |
| Phân đoạn Trực quan (PVS) | Điểm, hộp, mặt nạ | Thực thể đối tượng đơn lẻ (kiểu SAM 2) |
| Tinh chỉnh tương tác | Thêm/xóa các mẫu hoặc cú nhấp chuột một cách lặp đi lặp lại | Phân đoạn được tinh chỉnh với độ chính xác được cải thiện |
Link to this sectionVí dụ về phân đoạn khái niệm#
Link to this sectionPhân đoạn với gợi ý văn bản#
Tìm và phân đoạn tất cả các thực thể của một khái niệm bằng cách sử dụng mô tả văn bản. Các câu lệnh văn bản yêu cầu giao diện SAM3SemanticPredictor.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor with configuration
overrides = dict(
conf=0.25,
task="segment",
mode="predict",
model="sam3.pt",
quantize=16, # Use FP16 for faster inference
save=True,
)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image once for multiple queries
predictor.set_image("path/to/image.jpg")
# Query with multiple text prompts
results = predictor(text=["person", "bus", "glasses"])
# Works with descriptive phrases
results = predictor(text=["person with red cloth", "person with blue cloth"])
# Query with a single concept
results = predictor(text=["a person"])Link to this sectionPhân đoạn bằng ảnh mẫu#
Sử dụng các bounding box làm câu lệnh trực quan để tìm tất cả các thực thể tương tự. Điều này cũng yêu cầu SAM3SemanticPredictor để khớp dựa trên khái niệm.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16, save=True)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image
predictor.set_image("path/to/image.jpg")
# Provide bounding box examples to segment similar objects
results = predictor(bboxes=[[480.0, 290.0, 590.0, 650.0]])
# Multiple bounding boxes as exemplars of the same visual concept
results = predictor(bboxes=[[539, 599, 589, 639], [343, 267, 499, 662]])Link to this sectionSuy luận dựa trên đặc trưng để tối ưu hiệu suất#
Trích xuất đặc trưng ảnh một lần và tái sử dụng chúng cho nhiều truy vấn phân đoạn để cải thiện hiệu suất.
import cv2
from ultralytics.models.sam import SAM3SemanticPredictor
from ultralytics.utils.plotting import Annotator, colors
# Initialize predictors
overrides = dict(conf=0.50, task="segment", mode="predict", model="sam3.pt", verbose=False)
predictor = SAM3SemanticPredictor(overrides=overrides)
predictor2 = SAM3SemanticPredictor(overrides=overrides)
# Extract features from the first predictor
source = "path/to/image.jpg"
predictor.set_image(source)
src_shape = cv2.imread(source).shape[:2]
# Setup second predictor and reuse features
predictor2.setup_model()
# Perform inference using shared features with text prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, text=["person"])
# Perform inference using shared features with bounding box prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, bboxes=[[439, 437, 524, 709]])
# Visualize results
if masks is not None:
masks, boxes = masks.cpu().numpy(), boxes.cpu().numpy()
im = cv2.imread(source)
annotator = Annotator(im, pil=False)
annotator.masks(masks, [colors(x, True) for x in range(len(masks))])
cv2.imshow("result", annotator.result())
cv2.waitKey(0)Link to this sectionPhân đoạn khái niệm trong video#
Link to this sectionTheo dõi các khái niệm xuyên suốt video bằng bounding box#
Phát hiện và theo dõi các thực thể đối tượng qua các khung hình video bằng cách sử dụng câu lệnh bounding box.
from ultralytics.models.sam import SAM3VideoPredictor
# Create video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16)
predictor = SAM3VideoPredictor(overrides=overrides)
# Track objects using bounding box prompts
results = predictor(source="path/to/video.mp4", bboxes=[[706.5, 442.5, 905.25, 555], [598, 635, 725, 750]], stream=True)
# Process and display results
for r in results:
r.show() # Display frame with segmentation masksLink to this sectionTheo dõi các khái niệm với câu lệnh văn bản#
Theo dõi tất cả các thực thể của khái niệm được chỉ định bằng văn bản qua các khung hình video.
from ultralytics.models.sam import SAM3VideoSemanticPredictor
# Initialize semantic video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=640, model="sam3.pt", quantize=16, save=True)
predictor = SAM3VideoSemanticPredictor(overrides=overrides)
# Track concepts using text prompts
results = predictor(source="path/to/video.mp4", text=["person", "bicycle"], stream=True)
# Process results
for r in results:
r.show() # Display frame with tracked objects
# Alternative: Track with bounding box prompts
results = predictor(
source="path/to/video.mp4",
bboxes=[[864, 383, 975, 620], [705, 229, 782, 402]],
labels=[1, 1], # Positive labels
stream=True,
)Link to this sectionCác câu lệnh trực quan (Khả năng tương thích SAM 2)#
SAM 3 duy trì khả năng tương thích ngược hoàn toàn với các câu lệnh trực quan của SAM 2 cho việc phân đoạn đơn đối tượng:
Giao diện SAM cơ bản hoạt động chính xác như SAM 2, chỉ phân đoạn vùng cụ thể được chỉ định bởi các câu lệnh trực quan (điểm, hộp hoặc mặt nạ).
from ultralytics import SAM
model = SAM("sam3.pt")
# Single point prompt - segments object at specific location
results = model.predict(source="path/to/image.jpg", points=[900, 370], labels=[1])
results[0].show()
# Multiple points - segments single object with multiple point hints
results = model.predict(source="path/to/image.jpg", points=[[400, 370], [900, 370]], labels=[1, 1])
# Box prompt - segments object within bounding box
results = model.predict(source="path/to/image.jpg", bboxes=[100, 150, 300, 400])
results[0].show()Việc sử dụng SAM("sam3.pt") với các câu lệnh trực quan (điểm/hộp/mặt nạ) sẽ chỉ phân đoạn đối tượng cụ thể tại vị trí đó, giống như SAM 2. Để phân đoạn tất cả các thực thể của một khái niệm, hãy sử dụng SAM3SemanticPredictor với câu lệnh văn bản hoặc câu lệnh mẫu như đã hiển thị ở trên.
Link to this sectionĐiểm chuẩn hiệu năng#
Link to this sectionPhân đoạn ảnh#
SAM 3 đạt được kết quả hiện đại nhất trên nhiều bộ kiểm chuẩn, bao gồm các bộ dữ liệu thực tế như LVIS và COCO for segmentation:
| Đánh giá hiệu năng (Benchmark) | Chỉ số | SAM 3 | Kết quả tốt nhất trước đó | Cải thiện |
|---|---|---|---|---|
| LVIS (zero-shot) | Mask AP | 47.0 | 38.5 | +22.1% |
| SA-Co/Gold | CGF1 | 65.0 | 34.3 (OWLv2) | +89.5% |
| COCO (zero-shot) | Box AP | 53.5 | 52.2 (T-Rex2) | +2.5% |
| ADE-847 (semantic seg) | mIoU | 14.7 | 9.2 (APE-D) | +59.8% |
| PascalConcept-59 | mIoU | 59.4 | 58.5 (APE-D) | +1.5% |
| Cityscapes (semantic seg) | mIoU | 65.1 | 44.2 (APE-D) | +47.3% |
Khám phá các tùy chọn bộ dữ liệu để thử nghiệm nhanh trong Ultralytics datasets.
Link to this sectionHiệu suất phân đoạn video#
SAM 3 cho thấy những cải tiến đáng kể so với SAM 2 và các trạng thái tiền nhiệm trên các bộ kiểm chuẩn video như DAVIS 2017 và YouTube-VOS:
| Đánh giá hiệu năng (Benchmark) | Chỉ số | SAM 3 | SAM 2.1 L | Cải thiện |
|---|---|---|---|---|
| MOSEv2 | J&F | 60.1 | 47.9 | +25.5% |
| DAVIS 2017 | J&F | 92.0 | 90.7 | +1.4% |
| LVOSv2 | J&F | 88.2 | 79.6 | +10.8% |
| SA-V | J&F | 84.6 | 78.4 | +7.9% |
| YTVOS19 | J&F | 89.6 | 89.3 | +0.3% |
Link to this sectionThích ứng Few-Shot#
SAM 3 xuất sắc trong việc thích ứng với các miền mới chỉ với ít ví dụ, phù hợp cho các quy trình công việc data-centric AI:
| Đánh giá hiệu năng (Benchmark) | 0-shot AP | 10-shot AP | Kết quả tốt nhất trước đó (10-shot) |
|---|---|---|---|
| ODinW13 | 59.9 | 71.6 | 67.9 (gDino1.5-Pro) |
| RF100-VL | 14.3 | 35.7 | 33.7 (gDino-T) |
Link to this sectionHiệu quả tinh chỉnh tương tác#
Việc sử dụng câu lệnh dựa trên khái niệm của SAM 3 với các mẫu hội tụ nhanh hơn nhiều so với câu lệnh trực quan:
| Câu lệnh đã thêm | Điểm CGF1 | Độ tăng so với chỉ dùng văn bản | Độ tăng so với PVS cơ sở |
|---|---|---|---|
| Chỉ văn bản | 46.4 | cơ sở | cơ sở |
| +1 mẫu | 57.6 | +11.2 | +6.7 |
| +2 mẫu | 62.2 | +15.8 | +9.7 |
| +3 mẫu | 65.0 | +18.6 | +11.2 |
| +4 mẫu | 65.7 | +19.3 | +11.5 (đạt đỉnh) |
Link to this sectionĐộ chính xác đếm đối tượng#
SAM 3 cung cấp khả năng đếm chính xác bằng cách phân đoạn tất cả các thực thể, một yêu cầu phổ biến trong đếm đối tượng:
| Đánh giá hiệu năng (Benchmark) | Độ chính xác | MAE | vs MLLM tốt nhất |
|---|---|---|---|
| CountBench | 95.6% | 0.11 | 92.4% (Gemini 2.5) |
| PixMo-Count | 87.3% | 0.22 | 88.8% (Molmo-72B) |
Link to this sectionSo sánh SAM 3, SAM 2 và YOLO#
Tại đây chúng tôi so sánh khả năng của SAM 3 với các model SAM 2 và YOLO26:
| Khả năng | SAM 3 | SAM 2 | YOLO26n-seg |
|---|---|---|---|
| Phân đoạn khái niệm | ✅ Tất cả thực thể từ văn bản/mẫu | ❌ Không hỗ trợ | ❌ Không hỗ trợ |
| Phân đoạn trực quan | ✅ Một thực thể duy nhất (tương thích SAM 2) | ✅ Một thực thể duy nhất | ✅ Tất cả thực thể |
| Khả năng Zero-shot | ✅ Từ vựng mở | ✅ Gợi ý hình học | ❌ Tập hợp đóng |
| Tinh chỉnh tương tác | ✅ Mẫu + nhấp chuột | ✅ Chỉ nhấp chuột | ❌ Không hỗ trợ |
| Theo dõi video | ✅ Đa đối tượng với danh tính | ✅ Đa đối tượng | ✅ Đa đối tượng |
| LVIS Mask AP (zero-shot) | 47.0 | N/A | N/A |
| MOSEv2 J&F | 60.1 | 47.9 | N/A |
| Tốc độ (GPU, ms/im) | 2921 | 857 | 8.4 |
| Kích thước mô hình (Model Size) | 3.45 GB | 162 MB (cơ bản) | 6.4 MB |
Tốc độ được đo trên NVIDIA RTX PRO 6000 với torch==2.9.1 và ultralytics==8.4.19.
Điểm chính:
- SAM 3: Tốt nhất cho phân đoạn khái niệm từ vựng mở, tìm tất cả các thực thể của một khái niệm bằng văn bản hoặc gợi ý mẫu
- SAM 2: Tốt nhất cho phân đoạn tương tác một đối tượng trong hình ảnh và video với gợi ý hình học
- YOLO26: Tốt nhất cho phân đoạn tốc độ cao, thời gian thực với suy luận end-to-end không cần NMS, có thể xuất sang nhiều định dạng để triển khai trên GPU, CPU và thiết bị biên
Link to this sectionSo sánh SAM với YOLO#
So sánh SAM 3, SAM 2, SAM, MobileSAM và FastSAM với các model phân đoạn Ultralytics YOLO (YOLOv8, YOLO11, YOLO26) về kích thước, tham số và tốc độ suy luận GPU:
| Mô hình | Kích thước (MB) | Tham số (M) | Tốc độ (GPU) (ms/im) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 1306 |
| Meta SAM2-b | 162 | 80.8 | 857 |
| Meta SAM2-t | 78.1 | 38.9 | 668 |
| Meta SAM3 | 3450 | 473.6 | 2921 |
| MobileSAM | 40.7 | 10.1 | 605 |
| FastSAM-s với YOLOv8 backbone | 23.7 | 11.8 | 55.9 |
| Ultralytics YOLOv8n-seg | 6.7 (nhỏ hơn 515 lần) | 3.4 (ít hơn 139.1 lần) | 17.4 (nhanh hơn 167 lần) |
| Ultralytics YOLO11n-seg | 5.9 (nhỏ hơn 585 lần) | 2.9 (ít hơn 163.1 lần) | 12.6 (nhanh hơn 231 lần) |
| Ultralytics YOLO26n-seg | 6.4 (nhỏ hơn 539 lần) | 2.7 (ít hơn 175.2 lần) | 8.4 (nhanh hơn 347 lần) |
So sánh này cho thấy sự khác biệt đáng kể về kích thước và tốc độ model giữa các biến thể SAM và các model phân đoạn YOLO. Trong khi SAM cung cấp các khả năng phân đoạn tự động độc đáo, các model YOLO, đặc biệt là YOLOv8n-seg, YOLO11n-seg và YOLO26n-seg, nhỏ hơn, nhanh hơn và hiệu quả tính toán hơn đáng kể.
Các thử nghiệm được chạy trên NVIDIA RTX PRO 6000 với 96GB VRAM sử dụng torch==2.9.1 và ultralytics==8.4.19. Để tái lập thử nghiệm này:
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# Profile SAM3, SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt", "sam3.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# Profile FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# Profile YOLO models
for file_name in ["yolov8n-seg.pt", "yolo11n-seg.pt", "yolo26n-seg.pt"]:
model = YOLO(file_name)
model.info()
model(ASSETS)Link to this sectionSố liệu đánh giá#
SAM 3 giới thiệu các số liệu mới được thiết kế cho tác vụ PCS, bổ sung cho các phép đo quen thuộc như điểm F1, độ chính xác và độ hồi tưởng.
Link to this sectionClassification-Gated F1 (CGF1)#
Số liệu chính kết hợp giữa bản địa hóa và phân loại:
CGF1 = 100 × pmF1 × IL_MCC
Trong đó:
- pmF1 (Positive Macro F1): Đo lường chất lượng bản địa hóa trên các ví dụ dương tính
- IL_MCC (Image-Level Matthews Correlation Coefficient): Đo lường độ chính xác phân loại nhị phân ("khái niệm có hiện diện không?")
Link to this sectionTại sao lại là những số liệu này?#
Các số liệu AP truyền thống không tính đến hiệu chuẩn, khiến các model khó sử dụng trong thực tế. Bằng cách chỉ đánh giá các dự đoán có độ tin cậy trên 0.5, các số liệu của SAM 3 thực thi hiệu chuẩn tốt và bắt chước các mô hình sử dụng trong thực tế trong các vòng lặp predict và track tương tác.
Link to this sectionCác điểm loại bỏ và thông tin chi tiết chính#
Link to this sectionTác động của Presence Head#
Presence head tách biệt việc nhận diện khỏi bản địa hóa, mang lại những cải tiến đáng kể:
| Cấu hình | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Không có presence | 57.6 | 0.77 | 74.7 |
| Có presence | 63.3 | 0.82 | 77.1 |
Presence head cung cấp tăng 5.7 CGF1 (+9.9%), cải thiện chính khả năng nhận diện (IL_MCC +6.5%).
Link to this sectionTác động của Hard Negatives#
| Hard Negatives/Ảnh | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 0 | 31.8 | 0.44 | 70.2 |
| 5 | 44.8 | 0.62 | 71.9 |
| 30 | 49.2 | 0.68 | 72.3 |
Các ví dụ phủ định khó (hard negatives) rất quan trọng đối với khả năng nhận diện theo từ vựng mở, giúp cải thiện IL_MCC lên 54.5% (0.44 → 0.68).
Link to this sectionMở rộng quy mô dữ liệu huấn luyện#
| Nguồn dữ liệu | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Chỉ dữ liệu bên ngoài | 30.9 | 0.46 | 66.3 |
| Bên ngoài + Tổng hợp | 39.7 | 0.57 | 70.6 |
| Bên ngoài + HQ | 51.8 | 0.71 | 73.2 |
| Tất cả ba loại | 54.3 | 0.74 | 73.5 |
Các chú thích chất lượng cao do con người thực hiện mang lại sự cải thiện lớn so với chỉ sử dụng dữ liệu tổng hợp hoặc dữ liệu bên ngoài. Để biết thông tin cơ bản về thực tiễn chất lượng dữ liệu, hãy xem thu thập và chú thích dữ liệu.
Link to this sectionỨng dụng#
Khả năng phân đoạn theo khái niệm của SAM 3 cho phép áp dụng các trường hợp sử dụng mới:
- Kiểm duyệt nội dung: Tìm tất cả các trường hợp của loại nội dung cụ thể trên các thư viện phương tiện
- Thương mại điện tử: Phân đoạn tất cả các sản phẩm thuộc một loại nhất định trong hình ảnh danh mục, hỗ trợ auto-annotation (tự động chú thích)
- Hình ảnh y tế: Xác định tất cả các trường hợp xảy ra của các loại mô hoặc bất thường cụ thể
- Hệ thống tự hành: Theo dõi tất cả các trường hợp của biển báo giao thông, người đi bộ hoặc phương tiện theo danh mục
- Phân tích video: Đếm và theo dõi tất cả những người đang mặc quần áo cụ thể hoặc thực hiện hành động
- Chú thích tập dữ liệu: Nhanh chóng chú thích tất cả các trường hợp của các danh mục đối tượng hiếm
- Nghiên cứu khoa học: Định lượng và phân tích tất cả các mẫu phù hợp với các tiêu chí cụ thể
Link to this sectionSAM 3 Agent: Khả năng suy luận ngôn ngữ mở rộng#
SAM 3 có thể được kết hợp với các Mô hình Ngôn ngữ Lớn Đa phương thức (MLLMs) để xử lý các truy vấn phức tạp đòi hỏi suy luận, tương tự về ý tưởng với các hệ thống từ vựng mở như OWLv2 và T-Rex.
Link to this sectionHiệu suất trên các tác vụ suy luận#
| Đánh giá hiệu năng (Benchmark) | Chỉ số | SAM 3 Agent (Gemini 2.5 Pro) | Kết quả tốt nhất trước đó |
|---|---|---|---|
| ReasonSeg (validation) | gIoU | 76.0 | 65.0 (SoTA) |
| ReasonSeg (test) | gIoU | 73.8 | 61.3 (SoTA) |
| OmniLabel (validation) | AP | 46.7 | 36.5 (REAL) |
| RefCOCO+ | Acc | 91.2 | 89.3 (LISA) |
Link to this sectionVí dụ về các truy vấn phức tạp#
SAM 3 Agent có thể xử lý các truy vấn đòi hỏi suy luận:
- "Những người đang ngồi nhưng không cầm hộp quà trên tay"
- "Con chó gần máy ảnh nhất mà không đeo vòng cổ"
- "Các vật thể màu đỏ lớn hơn bàn tay của người đó"
MLLM đề xuất các truy vấn cụm danh từ đơn giản cho SAM 3, phân tích các mask được trả về và lặp lại cho đến khi hài lòng.
Link to this sectionHạn chế#
Mặc dù SAM 3 đại diện cho một bước tiến lớn, nhưng nó vẫn có những hạn chế nhất định:
- Độ phức tạp của cụm từ: Phù hợp nhất với các cụm danh từ đơn giản; các biểu thức tham chiếu dài hoặc suy luận phức tạp có thể yêu cầu tích hợp MLLM
- Xử lý sự mơ hồ: Một số khái niệm vẫn vốn dĩ mơ hồ (ví dụ: "cửa sổ nhỏ", "căn phòng ấm cúng")
- Yêu cầu tính toán: Lớn hơn và chậm hơn so với các model phát hiện chuyên dụng như YOLO
- Phạm vi từ vựng: Tập trung vào các khái niệm hình ảnh nguyên tử; suy luận thành phần bị hạn chế nếu không có sự hỗ trợ của MLLM
- Khái niệm hiếm: Hiệu suất có thể giảm đối với các khái niệm cực kỳ hiếm hoặc có độ chi tiết cao không được thể hiện rõ trong dữ liệu huấn luyện
Link to this sectionTrích dẫn#
@inproceedings{sam3_2025,
title = {SAM 3: Segment Anything with Concepts},
author = {Anonymous authors},
booktitle = {Submitted to ICLR 2026},
year = {2025},
url = {https://openreview.net/forum?id=r35clVtGzw},
note = {Paper ID: 4183, under double-blind review}
}Link to this sectionCâu hỏi thường gặp#
Link to this sectionSAM 3 được phát hành khi nào?#
SAM 3 được Meta phát hành vào ngày 20 tháng 11 năm 2025 và được tích hợp hoàn toàn vào Ultralytics kể từ phiên bản 8.3.237 (PR #22897). Hỗ trợ đầy đủ có sẵn cho chế độ dự đoán và chế độ theo dõi.
Link to this sectionSAM 3 có được tích hợp vào Ultralytics không?#
Có! SAM 3 được tích hợp hoàn toàn vào gói Python Ultralytics, bao gồm phân đoạn khái niệm, gợi ý hình ảnh kiểu SAM 2 và theo dõi video đa đối tượng. SAM 3 cũng hỗ trợ tính năng chú thích thông minh trên Ultralytics Platform, nơi bạn có thể chú thích hình ảnh chỉ với vài cú nhấp chuột.
Link to this sectionPhân đoạn khái niệm có thể gợi ý (PCS) là gì?#
PCS là một tác vụ mới được giới thiệu trong SAM 3 giúp phân đoạn tất cả các trường hợp của một khái niệm hình ảnh trong hình ảnh hoặc video. Không giống như phân đoạn truyền thống nhắm mục tiêu vào một trường hợp đối tượng cụ thể, PCS tìm thấy mọi sự xuất hiện của một danh mục. Ví dụ:
- Gợi ý văn bản: "xe buýt trường học màu vàng" → phân đoạn tất cả xe buýt trường học màu vàng trong cảnh
- Ví dụ hình ảnh: Hộp bao quanh một con chó → phân đoạn tất cả con chó trong ảnh
- Kết hợp: "con mèo có sọc" + hộp ví dụ → phân đoạn tất cả con mèo có sọc khớp với ví dụ
Xem thông tin cơ bản liên quan về phát hiện đối tượng và phân đoạn đối tượng.
Link to this sectionSAM 3 khác SAM 2 như thế nào?#
| Tính năng | SAM 2 | SAM 3 |
|---|---|---|
| Tác vụ | Một đối tượng cho mỗi gợi ý | Tất cả các trường hợp của một khái niệm |
| Các loại gợi ý | Điểm, hộp, mặt nạ | + Các cụm từ văn bản, ví dụ hình ảnh |
| Khả năng phát hiện | Yêu cầu detector bên ngoài | Detector từ vựng mở tích hợp sẵn |
| Nhận dạng | Chỉ dựa trên hình học | Nhận dạng văn bản và hình ảnh |
| Kiến trúc | Chỉ tracker | Detector + Tracker với presence head |
| Hiệu suất Zero-Shot | N/A (yêu cầu gợi ý hình ảnh) | 47.0 AP trên LVIS, tốt hơn 2 lần trên SA-Co |
| Tinh chỉnh tương tác | Chỉ các cú nhấp chuột | Cú nhấp chuột + tổng quát hóa ví dụ |
SAM 3 duy trì khả năng tương thích ngược với gợi ý hình ảnh SAM 2 trong khi bổ sung các khả năng dựa trên khái niệm.
Link to this sectionCác tập dữ liệu nào được sử dụng để huấn luyện SAM 3?#
SAM 3 được huấn luyện trên tập dữ liệu Segment Anything with Concepts (SA-Co):
Dữ liệu huấn luyện:
- 5,2 triệu hình ảnh với 4 triệu cụm danh từ duy nhất (SA-Co/HQ) - chú thích chất lượng cao từ con người
- 52,5 nghìn video với 24,8 nghìn cụm danh từ duy nhất (SA-Co/VIDEO)
- 1,4 tỷ mask tổng hợp trên 38 triệu cụm danh từ (SA-Co/SYN)
- 15 tập dữ liệu bên ngoài được làm giàu với các hard negative (SA-Co/EXT)
Dữ liệu Benchmark:
- 214 nghìn khái niệm duy nhất trên 126 nghìn hình ảnh/video
- Số lượng khái niệm nhiều gấp 50 lần so với các benchmark hiện có (ví dụ: LVIS có khoảng 4 nghìn khái niệm)
- Chú thích bộ ba trên SA-Co/Gold để đo lường giới hạn hiệu suất của con người
Quy mô và sự đa dạng khổng lồ này mang lại khả năng tổng quát hóa zero-shot vượt trội của SAM 3 trên các khái niệm mở (open-vocabulary).
Link to this sectionSAM 3 so với YOLO26 trong phân đoạn (segmentation) như thế nào?#
SAM 3 và YOLO26 phục vụ các trường hợp sử dụng khác nhau:
Ưu điểm của SAM 3:
- Open-vocabulary: Phân đoạn bất kỳ khái niệm nào thông qua text prompt mà không cần huấn luyện
- Zero-shot: Hoạt động ngay lập tức với các danh mục mới
- Interactive: Cơ chế tinh chỉnh dựa trên ví dụ (exemplar) có thể tổng quát hóa sang các đối tượng tương tự
- Concept-based: Tự động tìm tất cả các instance của một danh mục
- Độ chính xác: 47.0 AP trên tác vụ instance segmentation LVIS zero-shot
Ưu điểm của YOLO26:
- Tốc độ: Suy luận nhanh hơn nhiều bậc với thiết kế end-to-end không cần NMS
- Hiệu quả: Mô hình nhỏ hơn 539 lần (6.4MB so với 3.45GB)
- Tiết kiệm tài nguyên: Chạy trên các thiết bị edge và mobile
- Real-time: Tối ưu hóa cho triển khai production
Khuyến nghị:
- Sử dụng SAM 3 cho các tác vụ phân đoạn linh hoạt, open-vocabulary khi bạn cần tìm tất cả các instance của khái niệm được mô tả bằng văn bản hoặc ví dụ
- Sử dụng YOLO26 cho các triển khai production tốc độ cao, nơi các danh mục đã được biết trước
- Sử dụng SAM 2 cho phân đoạn đơn đối tượng tương tác với các prompt hình học
Link to this sectionSAM 3 có thể xử lý các truy vấn ngôn ngữ phức tạp không?#
SAM 3 được thiết kế cho các cụm danh từ đơn giản (ví dụ: "quả táo đỏ", "người đội mũ"). Đối với các truy vấn phức tạp yêu cầu suy luận, hãy kết hợp SAM 3 với một MLLM dưới dạng SAM 3 Agent:
Truy vấn đơn giản (SAM 3 gốc):
- "xe buýt trường học màu vàng"
- "con mèo có sọc"
- "người đội mũ đỏ"
Truy vấn phức tạp (SAM 3 Agent với MLLM):
- "Người đang ngồi nhưng không cầm hộp quà"
- "Chú chó ở gần camera nhất mà không có vòng cổ"
- "Các vật thể màu đỏ lớn hơn bàn tay của người đó"
SAM 3 Agent đạt 76.0 gIoU trên tập validation ReasonSeg (so với mức tốt nhất trước đó là 65.0, cải thiện +16,9%) bằng cách kết hợp khả năng phân đoạn của SAM 3 với năng lực suy luận của MLLM.
Link to this sectionĐộ chính xác của SAM 3 so với hiệu suất con người là bao nhiêu?#
Trên benchmark SA-Co/Gold với bộ ba chú thích từ con người:
- Giới hạn dưới của con người: 74.2 CGF1 (người chú thích thận trọng nhất)
- Hiệu suất SAM 3: 65.0 CGF1
- Thành tựu: 88% giới hạn dưới ước tính của con người
- Giới hạn trên của con người: 81.4 CGF1 (người chú thích tự do nhất)
SAM 3 đạt hiệu suất mạnh mẽ tiệm cận độ chính xác ở mức con người trong phân đoạn khái niệm open-vocabulary, với khoảng cách chủ yếu nằm ở các khái niệm mơ hồ hoặc mang tính chủ quan (ví dụ: "cửa sổ nhỏ", "căn phòng ấm cúng").