Link to this sectionUltralytics YOLO11#
Link to this sectionÜbersicht#
YOLO11 wurde am 10. September 2024 von Ultralytics veröffentlicht und bietet hervorragende Genauigkeit, Geschwindigkeit und Effizienz. Aufbauend auf den beeindruckenden Fortschritten früherer YOLO-Versionen führt YOLO11 signifikante Verbesserungen in der Architektur und bei den Trainingsmethoden ein, was es zu einer vielseitigen Wahl für eine breite Palette von Computer Vision-Aufgaben macht. Für das neueste Ultralytics-Modell mit End-to-End NMS-freier Inferenz und optimiertem Edge-Deployment, siehe YOLO26.
Ultralytics YOLO11 🚀 Podcast generated by NotebookLM
Watch: How to Use Ultralytics YOLO11 for Object Detection and Tracking | How to Benchmark | YOLO11 RELEASED🚀
Entdecke und führe YOLO11-Modelle direkt auf der Ultralytics Platform aus.
Link to this sectionHauptfunktionen#
- Erweiterte Merkmalsextraktion: YOLO11 verwendet eine verbesserte Backbone- und Neck-Architektur, welche die Fähigkeiten zur Merkmalsextraktion für eine präzisere Objekterkennung und komplexere Aufgabenleistung verbessert.
- Optimiert für Effizienz und Geschwindigkeit: YOLO11 führt verfeinerte Architekturdesigns und optimierte Trainingspipelines ein, die schnellere Verarbeitungsgeschwindigkeiten liefern und gleichzeitig eine optimale Balance zwischen Genauigkeit und Leistung wahren.
- Höhere Genauigkeit mit weniger Parametern: Dank Fortschritten im Modelldesign erreicht YOLO11m eine höhere mean Average Precision (mAP) auf dem COCO-Datensatz bei 22 % weniger Parametern als YOLOv8m, was es rechnerisch effizient macht, ohne die Genauigkeit zu beeinträchtigen.
- Anpassungsfähigkeit über verschiedene Umgebungen: YOLO11 lässt sich nahtlos in verschiedenen Umgebungen einsetzen, einschließlich Edge-Geräten, Cloud-Plattformen und Systemen, die NVIDIA GPUs unterstützen, was maximale Flexibilität gewährleistet.
- Breite Palette unterstützter Aufgaben: Ob Objekterkennung, Instanzsegmentierung, Bildklassifizierung, Pose-Schätzung oder orientierte Objekterkennung (OBB), YOLO11 ist darauf ausgelegt, eine Vielzahl von Computer-Vision-Herausforderungen zu bewältigen.
Link to this sectionUnterstützte Aufgaben und Modi#
YOLO11 baut auf dem vielseitigen Modellangebot früherer Ultralytics YOLO-Veröffentlichungen auf und bietet verbesserte Unterstützung für verschiedene Computer-Vision-Aufgaben:
| Modell | Dateinamen | Aufgabe | Inference | Validation | Training | Exportieren |
|---|---|---|---|---|---|---|
| YOLO11 | yolo11n.pt yolo11s.pt yolo11m.pt yolo11l.pt yolo11x.pt | Detektion | ✅ | ✅ | ✅ | ✅ |
| YOLO11-seg | yolo11n-seg.pt yolo11s-seg.pt yolo11m-seg.pt yolo11l-seg.pt yolo11x-seg.pt | Instance Segmentation | ✅ | ✅ | ✅ | ✅ |
| YOLO11-pose | yolo11n-pose.pt yolo11s-pose.pt yolo11m-pose.pt yolo11l-pose.pt yolo11x-pose.pt | Pose/Keypoints | ✅ | ✅ | ✅ | ✅ |
| YOLO11-obb | yolo11n-obb.pt yolo11s-obb.pt yolo11m-obb.pt yolo11l-obb.pt yolo11x-obb.pt | Orientierte Detektion | ✅ | ✅ | ✅ | ✅ |
| YOLO11-cls | yolo11n-cls.pt yolo11s-cls.pt yolo11m-cls.pt yolo11l-cls.pt yolo11x-cls.pt | Klassifizierung | ✅ | ✅ | ✅ | ✅ |
Diese Tabelle bietet einen Überblick über die YOLO11-Modellvarianten und zeigt ihre Anwendbarkeit bei spezifischen Aufgaben sowie ihre Kompatibilität mit operativen Modi wie Inferenz, Validierung, Training und Export. Diese Flexibilität macht YOLO11 für eine breite Palette von Anwendungen im Bereich Computer Vision geeignet, von Echtzeiterkennung bis hin zu komplexen Segmentierungsaufgaben.
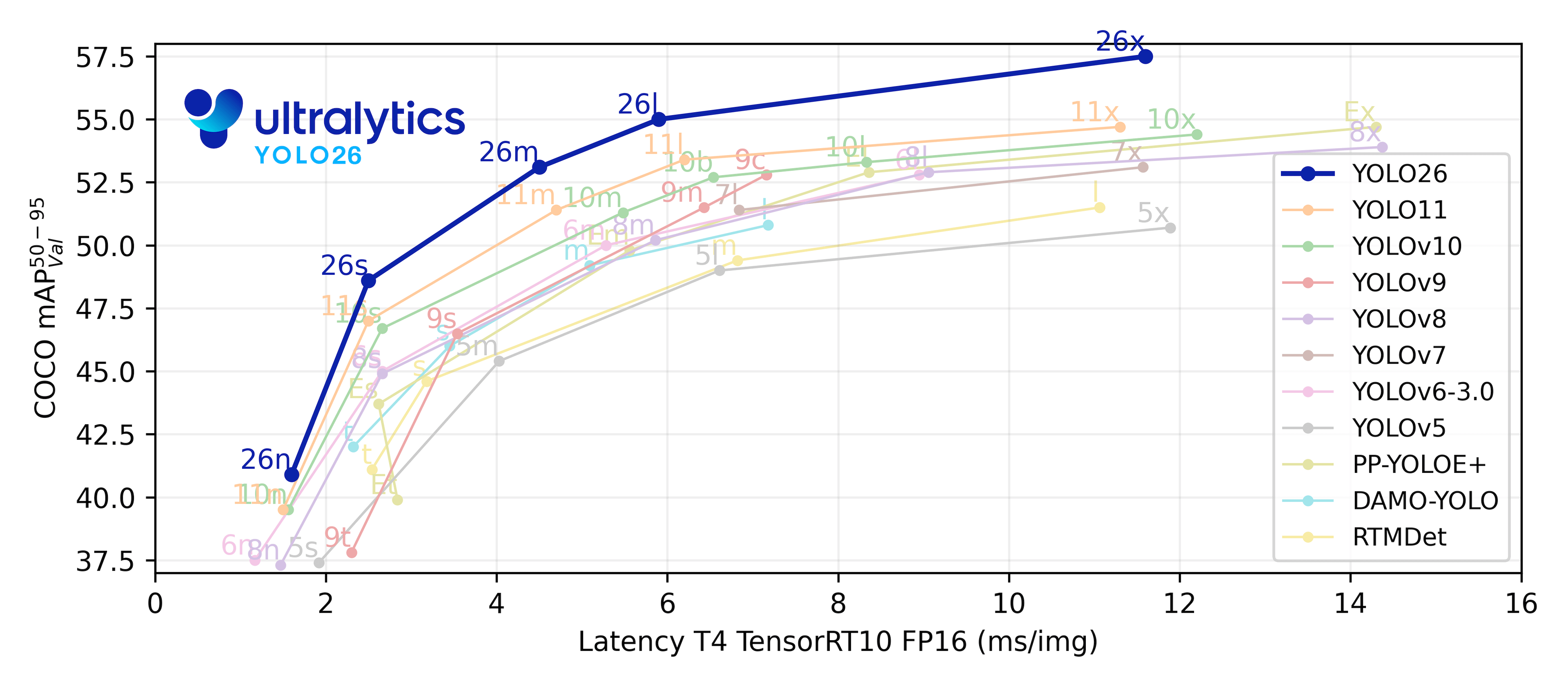
Link to this sectionLeistungsmetriken#
Siehe Detektions-Dokumentation für Anwendungsbeispiele mit diesen Modellen, die auf COCO trainiert wurden und 80 vortrainierte Klassen enthalten.
| Modell | Größe (Pixel) | mAPval 50-95 | Geschwindigkeit CPU ONNX (ms) | Geschwindigkeit T4 TensorRT10 (ms) | Parameter (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLO11n | 640 | 39.5 | 56,1 ± 0,8 | 1,5 ± 0,0 | 2.6 | 6.5 |
| YOLO11s | 640 | 47.0 | 90,0 ± 1,2 | 2,5 ± 0,0 | 9.4 | 21,5 |
| YOLO11m | 640 | 51.5 | 183,2 ± 2,0 | 4,7 ± 0,1 | 20,1 | 68.0 |
| YOLO11l | 640 | 53.4 | 238,6 ± 1,4 | 6,2 ± 0,1 | 25.3 | 86.9 |
| YOLO11x | 640 | 54.7 | 462,8 ± 6,7 | 11,3 ± 0,2 | 56,9 | 194.9 |
Link to this sectionAnwendungsbeispiele#
Dieser Abschnitt bietet einfache Beispiele für das Training und die Inferenz mit YOLO11. Vollständige Dokumentationen zu diesen und anderen Modi findest du auf den Dokumentationsseiten Predict, Train, Val und Export.
Beachte, dass das folgende Beispiel für YOLO11 Detect-Modelle zur Objekterkennung gilt. Für weitere unterstützte Aufgaben siehe die Dokumentation zu Segment, Classify, OBB und Pose.
PyTorch vortrainierte *.pt-Modelle sowie Konfigurations-*.yaml-Dateien können an die YOLO()-Klasse übergeben werden, um eine Modellinstanz in Python zu erstellen:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLO11n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")Link to this sectionZitate und Danksagungen#
Ultralytics hat kein formelles Forschungspapier für YOLO11 veröffentlicht, da sich die Modelle so schnell weiterentwickeln. Wir konzentrieren uns darauf, die Technologie voranzubringen und die Nutzung zu erleichtern, anstatt statische Dokumentationen zu erstellen. Die aktuellsten Informationen zur YOLO-Architektur, zu Funktionen und zur Verwendung findest du in unserem GitHub-Repository und in der Dokumentation.
Wenn du YOLO11 oder andere Software aus diesem Repository in deiner Arbeit verwendest, zitiere sie bitte im folgenden Format:
@software{yolo11_ultralytics,
author = {Glenn Jocher and Jing Qiu},
title = {Ultralytics YOLO11},
version = {11.0.0},
year = {2024},
url = {https://github.com/ultralytics/ultralytics},
orcid = {0000-0001-5950-6979, 0000-0003-3783-7069},
license = {AGPL-3.0}
}Bitte beachte, dass die DOI noch aussteht und zur Zitierung hinzugefügt wird, sobald sie verfügbar ist. YOLO11-Modelle werden unter AGPL-3.0- und Enterprise-Lizenzen bereitgestellt.
Link to this sectionFAQ#
Link to this sectionWas sind die wichtigsten Verbesserungen bei Ultralytics YOLO11 im Vergleich zu YOLOv8?#
Ultralytics YOLO11 führt einige bedeutende Verbesserungen gegenüber YOLOv8 ein. Die wichtigsten Verbesserungen sind:
- Verbesserte Merkmalsextraktion: YOLO11 verwendet eine verbesserte Backbone- und Neck-Architektur, die die Funktionen zur Merkmalsextraktion für eine präzisere Objekterkennung verbessert.
- Optimierte Effizienz und Geschwindigkeit: Durchdachte Architekturdesigns und optimierte Trainings-Pipelines sorgen für schnellere Verarbeitungsgeschwindigkeiten bei gleichzeitigem Ausgleich zwischen Genauigkeit und Leistung.
- Höhere Genauigkeit bei weniger Parametern: YOLO11m erreicht eine höhere durchschnittliche Präzision (mAP) auf dem COCO-Datensatz mit 22 % weniger Parametern als YOLOv8m, was es recheneffizient macht, ohne die Genauigkeit zu beeinträchtigen.
- Anpassungsfähigkeit an verschiedene Umgebungen: YOLO11 kann in verschiedenen Umgebungen eingesetzt werden, einschließlich Edge-Geräten, Cloud-Plattformen und Systemen, die NVIDIA GPUs unterstützen.
- Breites Spektrum unterstützter Aufgaben: YOLO11 unterstützt vielfältige Computer-Vision-Aufgaben wie Objekterkennung, Instanzsegmentierung, Bildklassifizierung, Pose-Schätzung und orientierte Objekterkennung (OBB).
Link to this sectionWie trainiere ich ein YOLO11-Modell für die Objekterkennung?#
Das Training eines YOLO11-Modells zur Objekterkennung kann über Python oder CLI-Befehle erfolgen. Nachfolgend findest du Beispiele für beide Methoden:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)Ausführlichere Anweisungen findest du in der Train-Dokumentation.
Link to this sectionWelche Aufgaben können YOLO11-Modelle ausführen?#
YOLO11-Modelle sind vielseitig und unterstützen eine breite Palette an Computer-Vision-Aufgaben, darunter:
- Objekterkennung: Identifizieren und Lokalisieren von Objekten innerhalb eines Bildes.
- Instanzsegmentierung: Erkennen von Objekten und Abgrenzen ihrer Begrenzungen.
- Bildklassifizierung: Kategorisierung von Bildern in vordefinierte Klassen.
- Pose-Schätzung: Erkennen und Verfolgen von Schlüsselpunkten auf menschlichen Körpern.
- Orientierte Objekterkennung (OBB): Erkennen von Objekten mit Rotation für höhere Präzision.
Weitere Informationen zu jeder Aufgabe findest du in der Dokumentation zu Detection, Instance Segmentation, Classification, Pose Estimation und Oriented Detection.
Link to this sectionWie erreicht YOLO11 eine höhere Genauigkeit bei weniger Parametern?#
YOLO11 erreicht eine höhere Genauigkeit mit weniger Parametern durch Fortschritte im Modelldesign und in Optimierungstechniken. Die verbesserte Architektur ermöglicht eine effiziente Merkmalsextraktion und -verarbeitung, was zu einer höheren mittleren durchschnittlichen Genauigkeit (mAP) auf Datensätzen wie COCO führt, während 22 % weniger Parameter als bei YOLOv8m verwendet werden. Dies macht YOLO11 recheneffizient, ohne die Genauigkeit zu beeinträchtigen, und eignet sich somit für den Einsatz auf Geräten mit begrenzten Ressourcen.
Link to this sectionKann YOLO11 auf Edge-Geräten eingesetzt werden?#
Ja, YOLO11 ist für die Anpassungsfähigkeit an verschiedene Umgebungen konzipiert, einschließlich Edge-Geräten. Seine optimierte Architektur und effizienten Verarbeitungsfähigkeiten machen es für den Einsatz auf Edge-Geräten, Cloud-Plattformen und Systemen mit Unterstützung für NVIDIA GPUs geeignet. Diese Flexibilität stellt sicher, dass YOLO11 in vielfältigen Anwendungen eingesetzt werden kann, von der Echtzeiterkennung auf mobilen Geräten bis hin zu komplexen Segmentierungsaufgaben in Cloud-Umgebungen. Weitere Einzelheiten zu den Bereitstellungsoptionen findest du in der Export-Dokumentation.