Link to this sectionSAM 3: Segment Anything with Concepts#
SAM 3 está totalmente integrado en el paquete Ultralytics desde la versión 8.3.237 (PR #22897). Instala o actualiza con pip install -U ultralytics para acceder a todas las funciones de SAM 3, incluida la segmentación de conceptos basada en texto, ejemplos de imágenes y seguimiento de vídeo.
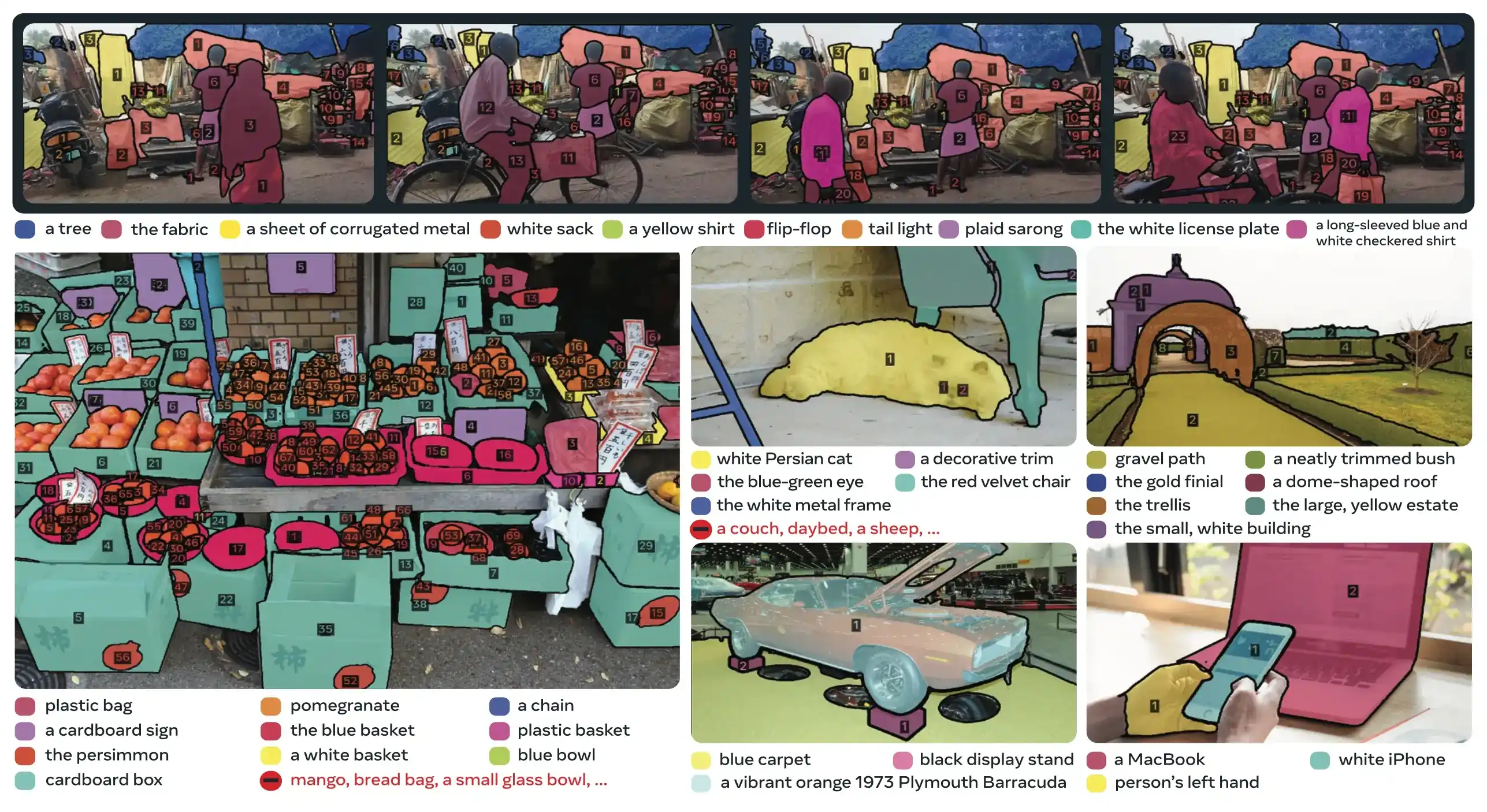
SAM 3 (Segment Anything Model 3) es el modelo fundacional lanzado por Meta para la Segmentación de Conceptos Promptable (PCS). Basándose en SAM 2, SAM 3 introduce una capacidad fundamentalmente nueva: detectar, segmentar y realizar el seguimiento de todas las instancias de un concepto visual especificado mediante prompts de texto, ejemplos de imágenes, o ambos. A diferencia de las versiones anteriores de SAM que segmentan objetos individuales por prompt, SAM 3 puede encontrar y segmentar cada aparición de un concepto presente en imágenes o vídeos, alineándose con los objetivos de vocabulario abierto en la segmentación de instancias moderna.
Watch: How to Use Meta Segment Anything 3 with Ultralytics | Text-Prompt Segmentation on Images & Videos
SAM 3 está ya totalmente integrado en el paquete ultralytics, proporcionando soporte nativo para segmentación de conceptos con prompts de texto, ejemplos de imágenes y capacidades de seguimiento de vídeo.
Link to this sectionDescripción general#
SAM 3 logra una mejora de rendimiento de 2× sobre los sistemas existentes en la Segmentación de Conceptos Promptable, manteniendo y mejorando las capacidades de SAM 2 para la segmentación visual interactiva. El modelo destaca en la segmentación de vocabulario abierto, permitiendo a los usuarios especificar conceptos usando frases nominales simples (p. ej., "autobús escolar amarillo", "gato rayado") o proporcionando imágenes de ejemplo del objeto objetivo. Estas capacidades complementan los pipelines listos para producción que dependen de flujos de trabajo optimizados de predict y track.
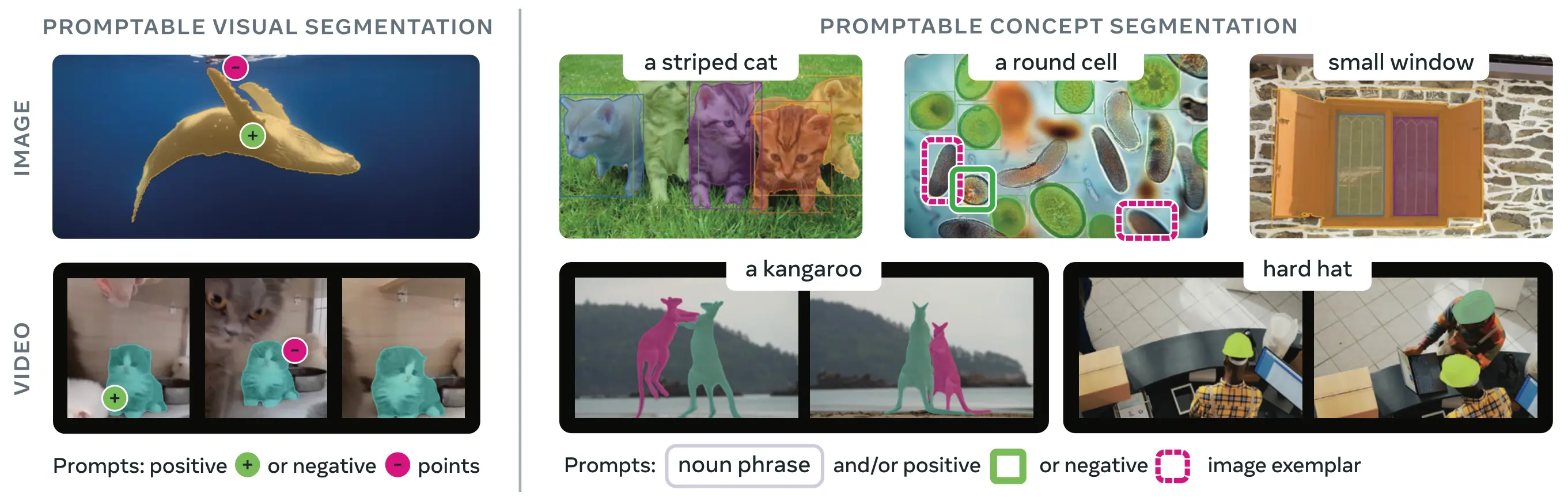
Link to this section¿Qué es la Segmentación de Conceptos Promptable (PCS)?#
La tarea PCS toma un prompt de concepto como entrada y devuelve máscaras de segmentación con identidades únicas para todas las instancias de objeto que coincidan. Los prompts de concepto pueden ser:
- Texto: Frases nominales simples como "manzana roja" o "persona con sombrero", similar al zero-shot learning
- Ejemplos de imagen: Cajas delimitadoras alrededor de objetos de ejemplo (positivos o negativos) para una generalización rápida
- Combinado: Tanto texto como ejemplos de imagen juntos para un control preciso
Esto difiere de los prompts visuales tradicionales (puntos, cajas, máscaras) que segmentan solo una instancia específica de un objeto, tal como popularizó la familia SAM original.
Link to this sectionMétricas de rendimiento clave#
| Métrica | Logro de SAM 3 |
|---|---|
| LVIS Zero-Shot Mask AP | 47.0 (vs el mejor anterior de 38.5, +22% de mejora) |
| Benchmark SA-Co | 2× mejor que los sistemas existentes |
| Velocidad de inferencia (GPU H200) | 30 ms por imagen con más de 100 objetos detectados |
| Rendimiento en vídeo | Casi tiempo real para ~5 objetos simultáneos |
| Benchmark MOSEv2 VOS | 60.1 J&F (+25.5% sobre SAM 2.1, +17% sobre el SOTA anterior) |
| Refinamiento interactivo | Mejora de +18.6 CGF1 después de 3 prompts de ejemplo |
| Brecha de rendimiento humano | Logra el 88% del límite inferior estimado en SA-Co/Gold |
Para conocer el contexto sobre métricas de modelos y compensaciones en producción, consulta model evaluation insights y YOLO performance metrics.
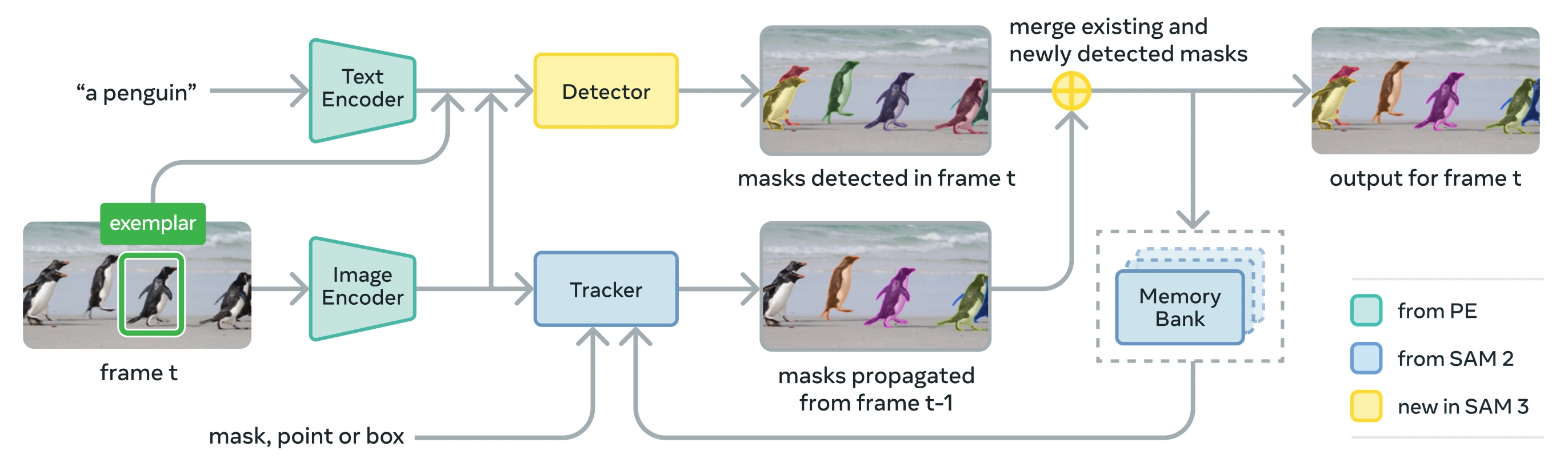
Link to this sectionArquitectura#
SAM 3 consiste en un detector y un tracker que comparten un backbone de visión Perception Encoder (PE). Este diseño desacoplado evita conflictos de tareas mientras permite tanto la detección a nivel de imagen como el seguimiento a nivel de vídeo, con una interfaz compatible con el uso de Python y el uso de CLI de Ultralytics.
Link to this sectionComponentes principales#
-
Detector: Arquitectura basada en DETR para detección de conceptos a nivel de imagen
- Codificador de texto para prompts de frases nominales
- Codificador de ejemplos para prompts basados en imágenes
- Codificador de fusión para condicionar las características de la imagen a los prompts
- Innovadora presence head que desacopla el reconocimiento ("qué") de la localización ("dónde")
- Mask head para generar máscaras de segmentación de instancias
-
Tracker: Segmentación de vídeo basada en memoria heredada de SAM 2
- Codificador de prompts, decodificador de máscaras, codificador de memoria
- Banco de memoria para almacenar la apariencia del objeto a través de los frames
- Desambiguación temporal ayudada por técnicas como un Kalman filter en entornos multi-objeto
-
Presence Token: Un token global aprendido que predice si el concepto objetivo está presente en la imagen/frame, mejorando la detección al separar el reconocimiento de la localización.
Link to this sectionInnovaciones clave#
- Reconocimiento y localización desacoplados: La presence head predice la presencia del concepto globalmente, mientras que las consultas de propuesta se centran solo en la localización, evitando objetivos conflictivos.
- Prompts unificados de concepto y visuales: Soporta tanto PCS (prompts de concepto) como PVS (prompts visuales como los clics/cajas de SAM 2) en un único modelo.
- Refinamiento de ejemplos interactivos: Los usuarios pueden añadir ejemplos de imagen positivos o negativos para refinar iterativamente los resultados, con el modelo generalizando a objetos similares en lugar de solo corregir instancias individuales.
- Desambiguación temporal: Utiliza puntuaciones de detección de masklet y re-prompteado periódico para manejar oclusiones, escenas concurridas y fallos de seguimiento en vídeo, alineándose con las mejores prácticas de instance segmentation and tracking.
Link to this sectionDataset SA-Co#
SAM 3 está entrenado en Segment Anything with Concepts (SA-Co), el dataset de segmentación más grande y diverso de Meta hasta la fecha, expandiéndose más allá de los benchmarks comunes como COCO y LVIS.
Link to this sectionDatos de entrenamiento#
| Componente del dataset | Descripción | Escala |
|---|---|---|
| SA-Co/HQ | Datos de imagen de alta calidad anotados por humanos desde un motor de datos de 4 fases | 5.2M imágenes, 4M frases nominales únicas |
| SA-Co/SYN | Dataset sintético etiquetado por IA sin intervención humana | 38M frases nominales, 1.4B máscaras |
| SA-Co/EXT | 15 datasets externos enriquecidos con negativos difíciles | Varía según la fuente |
| SA-Co/VIDEO | Anotaciones de vídeo con seguimiento temporal | 52.5K vídeos, 24.8K frases nominales únicas |
Link to this sectionDatos de benchmark#
El benchmark de evaluación SA-Co contiene 214K frases únicas a través de 126K imágenes y vídeos, proporcionando más de 50× más conceptos que los benchmarks existentes. Incluye:
- SA-Co/Gold: 7 dominios, triple anotación para medir los límites del rendimiento humano
- SA-Co/Silver: 10 dominios, anotación humana simple
- SA-Co/Bronze y SA-Co/Bio: 9 datasets existentes adaptados para la segmentación de conceptos
- SA-Co/VEval: Benchmark de vídeo con 3 dominios (SA-V, YT-Temporal-1B, SmartGlasses)
Link to this sectionInnovaciones del motor de datos#
El motor de datos escalable de SAM 3 con humanos y modelos en el bucle logra 2× el rendimiento de anotación a través de:
- Anotadores IA: Modelos basados en Llama proponen frases nominales diversas incluyendo negativos difíciles
- Verificadores IA: LLMs multimodales ajustados verifican la calidad de la máscara y la exhaustividad a un rendimiento casi humano
- Minería activa: Enfoca el esfuerzo humano en casos de fallo desafiantes donde la IA tiene dificultades
- Basado en ontología: Aprovecha una gran ontología fundamentada en Wikidata para la cobertura de conceptos
Link to this sectionInstalación#
SAM 3 está disponible en la versión 8.3.237 de Ultralytics y posteriores. Instala o actualiza con:
pip install -U ultralyticsA diferencia de otros modelos de Ultralytics, los pesos de SAM 3 (sam3.pt) no se descargan automáticamente. Primero debes solicitar acceso para los pesos del modelo en la página del modelo SAM 3 en Hugging Face y luego, una vez aprobado, descarga sam3.pt desde esa página. Coloca el archivo sam3.pt descargado en tu directorio de trabajo o especifica la ruta completa al cargar el modelo.
Si obtienes el error anterior durante la predicción, significa que tienes instalado el paquete clip incorrecto. Instala el paquete clip correcto ejecutando lo siguiente:
pip uninstall clip -y
pip install git+https://github.com/ultralytics/CLIP.gitLink to this sectionCómo usar SAM 3: Versatilidad en la segmentación de conceptos#
SAM 3 soporta tanto tareas de Segmentación de Conceptos Promptable (PCS) como tareas de Segmentación Visual Promptable (PVS) a través de diferentes interfaces de predictor:
Link to this sectionTareas y modelos soportados#
| Tipo de tarea | Tipos de prompt | Salida |
|---|---|---|
| Segmentación de conceptos (PCS) | Texto (frases nominales), ejemplos de imagen | Todas las instancias que coincidan con el concepto |
| Segmentación visual (PVS) | Puntos, cajas, máscaras | Instancia de un solo objeto (estilo SAM 2) |
| Refinamiento interactivo | Añadir/eliminar ejemplos o clics iterativamente | Segmentación refinada con precisión mejorada |
Link to this sectionEjemplos de segmentación de conceptos#
Link to this sectionSegmenta con prompts de texto#
Encuentra y segmenta todas las instancias de un concepto usando una descripción de texto. Los prompts de texto requieren la interfaz SAM3SemanticPredictor.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor with configuration
overrides = dict(
conf=0.25,
task="segment",
mode="predict",
model="sam3.pt",
quantize=16, # Use FP16 for faster inference
save=True,
)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image once for multiple queries
predictor.set_image("path/to/image.jpg")
# Query with multiple text prompts
results = predictor(text=["person", "bus", "glasses"])
# Works with descriptive phrases
results = predictor(text=["person with red cloth", "person with blue cloth"])
# Query with a single concept
results = predictor(text=["a person"])Link to this sectionSegmentación con ejemplares de imagen#
Usa cuadros delimitadores como prompts visuales para encontrar todas las instancias similares. Esto también requiere SAM3SemanticPredictor para la coincidencia basada en conceptos.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16, save=True)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image
predictor.set_image("path/to/image.jpg")
# Provide bounding box examples to segment similar objects
results = predictor(bboxes=[[480.0, 290.0, 590.0, 650.0]])
# Multiple bounding boxes as exemplars of the same visual concept
results = predictor(bboxes=[[539, 599, 589, 639], [343, 267, 499, 662]])Link to this sectionInferencia basada en características para mayor eficiencia#
Extrae las características de la imagen una vez y reutilízalas para múltiples consultas de segmentación para mejorar la eficiencia.
import cv2
from ultralytics.models.sam import SAM3SemanticPredictor
from ultralytics.utils.plotting import Annotator, colors
# Initialize predictors
overrides = dict(conf=0.50, task="segment", mode="predict", model="sam3.pt", verbose=False)
predictor = SAM3SemanticPredictor(overrides=overrides)
predictor2 = SAM3SemanticPredictor(overrides=overrides)
# Extract features from the first predictor
source = "path/to/image.jpg"
predictor.set_image(source)
src_shape = cv2.imread(source).shape[:2]
# Setup second predictor and reuse features
predictor2.setup_model()
# Perform inference using shared features with text prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, text=["person"])
# Perform inference using shared features with bounding box prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, bboxes=[[439, 437, 524, 709]])
# Visualize results
if masks is not None:
masks, boxes = masks.cpu().numpy(), boxes.cpu().numpy()
im = cv2.imread(source)
annotator = Annotator(im, pil=False)
annotator.masks(masks, [colors(x, True) for x in range(len(masks))])
cv2.imshow("result", annotator.result())
cv2.waitKey(0)Link to this sectionSegmentación de conceptos en vídeo#
Link to this sectionRastrea conceptos en vídeo con cuadros delimitadores#
Detecta y rastrea instancias de objetos a través de fotogramas de vídeo usando prompts de cuadros delimitadores.
from ultralytics.models.sam import SAM3VideoPredictor
# Create video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16)
predictor = SAM3VideoPredictor(overrides=overrides)
# Track objects using bounding box prompts
results = predictor(source="path/to/video.mp4", bboxes=[[706.5, 442.5, 905.25, 555], [598, 635, 725, 750]], stream=True)
# Process and display results
for r in results:
r.show() # Display frame with segmentation masksLink to this sectionRastrea conceptos con prompts de texto#
Rastrea todas las instancias de conceptos especificados por texto a través de fotogramas de vídeo.
from ultralytics.models.sam import SAM3VideoSemanticPredictor
# Initialize semantic video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=640, model="sam3.pt", quantize=16, save=True)
predictor = SAM3VideoSemanticPredictor(overrides=overrides)
# Track concepts using text prompts
results = predictor(source="path/to/video.mp4", text=["person", "bicycle"], stream=True)
# Process results
for r in results:
r.show() # Display frame with tracked objects
# Alternative: Track with bounding box prompts
results = predictor(
source="path/to/video.mp4",
bboxes=[[864, 383, 975, 620], [705, 229, 782, 402]],
labels=[1, 1], # Positive labels
stream=True,
)Link to this sectionPrompts visuales (compatibilidad con SAM 2)#
SAM 3 mantiene compatibilidad total hacia atrás con los prompts visuales de SAM 2 para la segmentación de un solo objeto:
La interfaz básica SAM se comporta exactamente como SAM 2, segmentando solo el área específica indicada por prompts visuales (puntos, cuadros o máscaras).
from ultralytics import SAM
model = SAM("sam3.pt")
# Single point prompt - segments object at specific location
results = model.predict(source="path/to/image.jpg", points=[900, 370], labels=[1])
results[0].show()
# Multiple points - segments single object with multiple point hints
results = model.predict(source="path/to/image.jpg", points=[[400, 370], [900, 370]], labels=[1, 1])
# Box prompt - segments object within bounding box
results = model.predict(source="path/to/image.jpg", bboxes=[100, 150, 300, 400])
results[0].show()Usar SAM("sam3.pt") con prompts visuales (puntos/cuadros/máscaras) segmentará solo el objeto específico en esa ubicación, igual que SAM 2. Para segmentar todas las instancias de un concepto, usa SAM3SemanticPredictor con prompts de texto o ejemplares como se muestra arriba.
Link to this sectionBenchmarks de rendimiento#
Link to this sectionSegmentación de imágenes#
SAM 3 logra resultados de vanguardia en múltiples puntos de referencia, incluyendo conjuntos de datos del mundo real como LVIS y COCO para segmentación:
| Evaluación comparativa (Benchmark) | Métrica | SAM 3 | Mejor anterior | Mejora |
|---|---|---|---|---|
| LVIS (zero-shot) | Mask AP | 47.0 | 38.5 | +22.1% |
| SA-Co/Gold | CGF1 | 65.0 | 34.3 (OWLv2) | +89.5% |
| COCO (zero-shot) | Box AP | 53.5 | 52.2 (T-Rex2) | +2.5% |
| ADE-847 (segmentación semántica) | mIoU | 14.7 | 9.2 (APE-D) | +59.8% |
| PascalConcept-59 | mIoU | 59.4 | 58.5 (APE-D) | +1.5% |
| Cityscapes (segmentación semántica) | mIoU | 65.1 | 44.2 (APE-D) | +47.3% |
Explora las opciones de conjuntos de datos para una experimentación rápida en Ultralytics datasets.
Link to this sectionRendimiento de segmentación de vídeo#
SAM 3 muestra mejoras significativas sobre SAM 2 y el estado del arte anterior en puntos de referencia de vídeo como DAVIS 2017 y YouTube-VOS:
| Evaluación comparativa (Benchmark) | Métrica | SAM 3 | SAM 2.1 L | Mejora |
|---|---|---|---|---|
| MOSEv2 | J&F | 60.1 | 47.9 | +25.5% |
| DAVIS 2017 | J&F | 92.0 | 90.7 | +1.4% |
| LVOSv2 | J&F | 88.2 | 79.6 | +10.8% |
| SA-V | J&F | 84.6 | 78.4 | +7.9% |
| YTVOS19 | J&F | 89.6 | 89.3 | +0.3% |
Link to this sectionAdaptación de pocos ejemplos (few-shot)#
SAM 3 destaca en la adaptación a nuevos dominios con ejemplos mínimos, relevante para flujos de trabajo de data-centric AI:
| Evaluación comparativa (Benchmark) | 0-shot AP | 10-shot AP | Mejor anterior (10-shot) |
|---|---|---|---|
| ODinW13 | 59.9 | 71.6 | 67.9 (gDino1.5-Pro) |
| RF100-VL | 14.3 | 35.7 | 33.7 (gDino-T) |
Link to this sectionEfectividad del refinamiento interactivo#
El prompting basado en conceptos de SAM 3 con ejemplares converge mucho más rápido que el prompting visual:
| Prompts añadidos | Puntuación CGF1 | Ganancia frente a solo texto | Ganancia frente a línea base PVS |
|---|---|---|---|
| Solo texto | 46.4 | línea base | línea base |
| +1 ejemplar | 57.6 | +11.2 | +6.7 |
| +2 ejemplares | 62.2 | +15.8 | +9.7 |
| +3 ejemplares | 65.0 | +18.6 | +11.2 |
| +4 ejemplares | 65.7 | +19.3 | +11.5 (meseta) |
Link to this sectionPrecisión de conteo de objetos#
SAM 3 proporciona un conteo preciso mediante la segmentación de todas las instancias, un requisito común en el conteo de objetos:
| Evaluación comparativa (Benchmark) | Precisión | MAE | vs mejor MLLM |
|---|---|---|---|
| CountBench | 95.6% | 0.11 | 92.4% (Gemini 2.5) |
| PixMo-Count | 87.3% | 0.22 | 88.8% (Molmo-72B) |
Link to this sectionComparativa entre SAM 3, SAM 2 y YOLO#
Aquí comparamos las capacidades de SAM 3 con los modelos SAM 2 y YOLO26:
| Capacidad | SAM 3 | SAM 2 | YOLO26n-seg |
|---|---|---|---|
| Segmentación de conceptos | ✅ Todas las instancias mediante texto/ejemplares | ❌ No compatible | ❌ No compatible |
| Segmentación visual | ✅ Instancia única (compatible con SAM 2) | ✅ Instancia única | ✅ Todas las instancias |
| Capacidad Zero-shot | ✅ Vocabulario abierto | ✅ Prompts geométricos | ❌ Conjunto cerrado |
| Refinamiento interactivo | ✅ Ejemplares + clics | ✅ Solo clics | ❌ No compatible |
| Seguimiento de vídeo | ✅ Multiobjeto con identidades | ✅ Multiobjeto | ✅ Multiobjeto |
| LVIS Mask AP (zero-shot) | 47.0 | N/A | N/A |
| MOSEv2 J&F | 60.1 | 47.9 | N/A |
| Velocidad (GPU, ms/im) | 2921 | 857 | 8.4 |
| Tamaño del modelo | 3.45 GB | 162 MB (base) | 6.4 MB |
Velocidad medida en una NVIDIA RTX PRO 6000 con torch==2.9.1 y ultralytics==8.4.19.
Conclusiones clave:
- SAM 3: Lo mejor para segmentación de conceptos de vocabulario abierto, encontrando todas las instancias de un concepto con prompts de texto o ejemplares
- SAM 2: Lo mejor para segmentación interactiva de un solo objeto en imágenes y vídeos con prompts geométricos
- YOLO26: Lo mejor para segmentación de alta velocidad en tiempo real con inferencia de extremo a extremo sin NMS, exportable a muchos formatos para despliegue en GPUs, CPUs y dispositivos periféricos
Link to this sectionComparativa de SAM frente a YOLO#
Comparativa de SAM 3, SAM 2, SAM, MobileSAM y FastSAM frente a los modelos de segmentación Ultralytics YOLO (YOLOv8, YOLO11, YOLO26) en tamaño, parámetros y velocidad de inferencia en GPU:
| Modelo | Tamaño (MB) | Parámetros (M) | Velocidad (GPU) (ms/im) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 1306 |
| Meta SAM2-b | 162 | 80.8 | 857 |
| Meta SAM2-t | 78.1 | 38.9 | 668 |
| Meta SAM3 | 3450 | 473.6 | 2921 |
| MobileSAM | 40.7 | 10.1 | 605 |
| FastSAM-s con backbone de YOLOv8 | 23.7 | 11.8 | 55.9 |
| Ultralytics YOLOv8n-seg | 6.7 (515x menor) | 3.4 (139.1x menos) | 17.4 (167x más rápido) |
| Ultralytics YOLO11n-seg | 5.9 (585x menor) | 2.9 (163.1x menos) | 12.6 (231x más rápido) |
| Ultralytics YOLO26n-seg | 6.4 (539x menor) | 2.7 (175.2x menos) | 8.4 (347x más rápido) |
Esta comparativa demuestra las diferencias sustanciales en los tamaños y velocidades de los modelos entre las variantes de SAM y los modelos de segmentación YOLO. Mientras que SAM proporciona capacidades de segmentación automática únicas, los modelos YOLO, particularmente YOLOv8n-seg, YOLO11n-seg y YOLO26n-seg, son significativamente más pequeños, rápidos y computacionalmente eficientes.
Pruebas realizadas en una NVIDIA RTX PRO 6000 con 96GB de VRAM utilizando torch==2.9.1 y ultralytics==8.4.19. Para reproducir esta prueba:
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# Profile SAM3, SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt", "sam3.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# Profile FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# Profile YOLO models
for file_name in ["yolov8n-seg.pt", "yolo11n-seg.pt", "yolo26n-seg.pt"]:
model = YOLO(file_name)
model.info()
model(ASSETS)Link to this sectionMétricas de evaluación#
SAM 3 introduce nuevas métricas diseñadas para la tarea PCS, complementando medidas familiares como puntuación F1, precisión y recall.
Link to this sectionF1 clasificado por presencia (CGF1)#
La métrica principal que combina localización y clasificación:
CGF1 = 100 × pmF1 × IL_MCC
Donde:
- pmF1 (F1 macro positivo): Mide la calidad de la localización en ejemplos positivos
- IL_MCC (Coeficiente de correlación de Matthews a nivel de imagen): Mide la precisión de la clasificación binaria ("¿está presente el concepto?")
Link to this section¿Por qué estas métricas?#
Las métricas AP tradicionales no tienen en cuenta la calibración, lo que hace que los modelos sean difíciles de usar en la práctica. Al evaluar solo las predicciones por encima de una confianza de 0.5, las métricas de SAM 3 fuerzan una buena calibración y mimetizan patrones de uso del mundo real en bucles interactivos de predicción y seguimiento.
Link to this sectionAblaciones clave y perspectivas#
Link to this sectionImpacto de la cabecera de presencia#
La cabecera de presencia desacopla el reconocimiento de la localización, proporcionando mejoras significativas:
| Configuración | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Sin presencia | 57.6 | 0.77 | 74.7 |
| Con presencia | 63.3 | 0.82 | 77.1 |
La cabecera de presencia proporciona un impulso de +5.7 CGF1 (+9.9%), mejorando principalmente la capacidad de reconocimiento (IL_MCC +6.5%).
Link to this sectionEfecto de los negativos difíciles#
| Negativos difíciles/Imagen | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 0 | 31.8 | 0.44 | 70.2 |
| 5 | 44.8 | 0.62 | 71.9 |
| 30 | 49.2 | 0.68 | 72.3 |
Los negativos difíciles son fundamentales para el reconocimiento de vocabulario abierto, mejorando el IL_MCC en un 54.5% (0.44 → 0.68).
Link to this sectionEscalado de datos de entrenamiento#
| Fuentes de datos | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Solo externos | 30.9 | 0.46 | 66.3 |
| Externos + Sintéticos | 39.7 | 0.57 | 70.6 |
| Externos + HQ | 51.8 | 0.71 | 73.2 |
| Los tres | 54.3 | 0.74 | 73.5 |
Las anotaciones humanas de alta calidad proporcionan grandes ganancias frente a datos sintéticos o externos por sí solos. Para obtener información sobre las prácticas de calidad de datos, consulta recolección y anotación de datos.
Link to this sectionAplicaciones#
La capacidad de segmentación de conceptos de SAM 3 permite nuevos casos de uso:
- Moderación de contenido: Encuentra todas las instancias de tipos de contenido específicos en bibliotecas de medios
- Comercio electrónico: segmenta todos los productos de un tipo determinado en las imágenes del catálogo, lo que permite la auto-anotación
- Imágenes médicas: Identifica todas las apariciones de tipos de tejido o anomalías específicos
- Sistemas autónomos: Rastrea todas las instancias de señales de tráfico, peatones o vehículos por categoría
- Análisis de vídeo: Cuenta y rastrea a todas las personas que llevan ropa específica o realizan acciones
- Anotación de conjuntos de datos: Anota rápidamente todas las instancias de categorías de objetos poco comunes
- Investigación científica: Cuantifica y analiza todos los especímenes que coinciden con criterios específicos
Link to this sectionAgente SAM 3: Razonamiento lingüístico extendido#
SAM 3 se puede combinar con modelos de lenguaje multimodal (MLLM) para manejar consultas complejas que requieren razonamiento, similar en espíritu a los sistemas de vocabulario abierto como OWLv2 y T-Rex.
Link to this sectionRendimiento en tareas de razonamiento#
| Evaluación comparativa (Benchmark) | Métrica | Agente SAM 3 (Gemini 2.5 Pro) | Mejor anterior |
|---|---|---|---|
| ReasonSeg (validación) | gIoU | 76.0 | 65.0 (SoTA) |
| ReasonSeg (prueba) | gIoU | 73.8 | 61.3 (SoTA) |
| OmniLabel (validación) | AP | 46.7 | 36.5 (REAL) |
| RefCOCO+ | Acc | 91.2 | 89.3 (LISA) |
Link to this sectionEjemplos de consultas complejas#
El Agente SAM 3 puede manejar consultas que requieren razonamiento:
- "Personas sentadas pero que no sostienen una caja de regalo en sus manos"
- "El perro más cercano a la cámara que no lleva collar"
- "Objetos rojos más grandes que la mano de la persona"
El MLLM propone consultas simples de frases nominales a SAM 3, analiza las máscaras devueltas e itera hasta quedar satisfecho.
Link to this sectionLimitaciones#
Aunque SAM 3 representa un gran avance, tiene ciertas limitaciones:
- Complejidad de frases: Es más adecuado para frases nominales simples; las expresiones de referencia largas o el razonamiento complejo pueden requerir la integración de un MLLM
- Manejo de ambigüedad: Algunos conceptos siguen siendo intrínsecamente ambiguos (por ejemplo, "ventana pequeña", "habitación acogedora")
- Requisitos computacionales: Más grande y lento que los modelos de detección especializados como YOLO
- Alcance del vocabulario: Centrado en conceptos visuales atómicos; el razonamiento composicional es limitado sin la asistencia de un MLLM
- Conceptos raros: El rendimiento puede degradarse en conceptos extremadamente raros o granulares que no están bien representados en los datos de entrenamiento
Link to this sectionCita#
@inproceedings{sam3_2025,
title = {SAM 3: Segment Anything with Concepts},
author = {Anonymous authors},
booktitle = {Submitted to ICLR 2026},
year = {2025},
url = {https://openreview.net/forum?id=r35clVtGzw},
note = {Paper ID: 4183, under double-blind review}
}Link to this sectionFAQ#
Link to this section¿Cuándo se lanzó SAM 3?#
SAM 3 fue lanzado por Meta el 20 de noviembre de 2025 y está totalmente integrado en Ultralytics desde la versión 8.3.237 (PR #22897). Hay soporte completo disponible para el modo de predicción y el modo de seguimiento.
Link to this section¿Está SAM 3 integrado en Ultralytics?#
¡Sí! SAM 3 está totalmente integrado en el paquete Python de Ultralytics, incluyendo segmentación de conceptos, prompts visuales al estilo SAM 2 y seguimiento de vídeo de múltiples objetos. SAM 3 también impulsa la función de anotación inteligente en Ultralytics Platform, donde puedes anotar imágenes con solo unos clics.
Link to this section¿Qué es la segmentación de conceptos mediante prompts (PCS)?#
PCS es una nueva tarea introducida en SAM 3 que segmenta todas las instancias de un concepto visual en una imagen o vídeo. A diferencia de la segmentación tradicional que se dirige a una instancia de objeto específica, PCS encuentra cada aparición de una categoría. Por ejemplo:
- Prompt de texto: "autobús escolar amarillo" → segmenta todos los autobuses escolares amarillos en la escena
- Ejemplar de imagen: Cuadro alrededor de un perro → segmenta todos los perros en la imagen
- Combinado: "gato atigrado" + cuadro de ejemplar → segmenta todos los gatos atigrados que coincidan con el ejemplo
Consulta los antecedentes relacionados sobre detección de objetos y segmentación de instancias.
Link to this section¿En qué se diferencia SAM 3 de SAM 2?#
| Característica | SAM 2 | SAM 3 |
|---|---|---|
| Tarea | Un objeto único por prompt | Todas las instancias de un concepto |
| Tipos de prompts | Puntos, cajas, máscaras | + Frases de texto, ejemplares de imagen |
| Capacidad de detección | Requiere detector externo | Detector integrado de vocabulario abierto |
| Reconocimiento | Solo basado en geometría | Reconocimiento visual y de texto |
| Arquitectura | Solo rastreador | Detector + Rastreador con cabezal de presencia |
| Rendimiento Zero-Shot | N/A (requiere prompts visuales) | 47.0 AP en LVIS, 2× mejor en SA-Co |
| Refinamiento interactivo | Solo clics | Clics + generalización de ejemplares |
SAM 3 mantiene la compatibilidad con versiones anteriores con el prompting visual de SAM 2 al mismo tiempo que añade capacidades basadas en conceptos.
Link to this section¿Qué conjuntos de datos se utilizan para entrenar a SAM 3?#
SAM 3 está entrenado con el conjunto de datos Segment Anything with Concepts (SA-Co):
Datos de entrenamiento:
- 5,2 M de imágenes con 4 M de frases nominales únicas (SA-Co/HQ): anotaciones humanas de alta calidad
- 52,5 K de vídeos con 24,8 K de frases nominales únicas (SA-Co/VIDEO)
- 1,4 B de máscaras sintéticas en 38 M de frases nominales (SA-Co/SYN)
- 15 conjuntos de datos externos enriquecidos con ejemplos negativos difíciles (SA-Co/EXT)
Datos de referencia:
- 214 K de conceptos únicos en 126 K de imágenes/vídeos
- 50 veces más conceptos que los puntos de referencia existentes (p. ej., LVIS tiene ~4 K de conceptos)
- Triple anotación en SA-Co/Gold para medir los límites del rendimiento humano
Esta escala y diversidad masivas permiten la superior generalización zero-shot de SAM 3 en conceptos de vocabulario abierto.
Link to this section¿Cómo se compara SAM 3 con YOLO26 en segmentación?#
SAM 3 y YOLO26 cubren casos de uso diferentes:
Ventajas de SAM 3:
- Vocabulario abierto: segmenta cualquier concepto mediante prompts de texto sin necesidad de entrenamiento
- Zero-shot: funciona en nuevas categorías de forma inmediata
- Interactivo: el refinamiento basado en ejemplos se generaliza a objetos similares
- Basado en conceptos: encuentra automáticamente todas las instancias de una categoría
- Precisión: 47,0 AP en segmentación de instancias zero-shot de LVIS
Ventajas de YOLO26:
- Velocidad: inferencia órdenes de magnitud más rápida con un diseño end-to-end sin NMS
- Eficiencia: modelos 539 veces más pequeños (6,4 MB frente a 3,45 GB)
- Amigable con los recursos: funciona en dispositivos de borde y móviles
- Tiempo real: optimizado para despliegues en producción
Recomendación:
- Usa SAM 3 para segmentación flexible de vocabulario abierto donde necesites encontrar todas las instancias de conceptos descritos por texto o ejemplos
- Usa YOLO26 para despliegues de producción de alta velocidad donde las categorías se conocen de antemano
- Usa SAM 2 para segmentación interactiva de un solo objeto con prompts geométricos
Link to this section¿Puede SAM 3 manejar consultas lingüísticas complejas?#
SAM 3 está diseñado para frases nominales simples (p. ej., "manzana roja", "persona con sombrero"). Para consultas complejas que requieran razonamiento, combina SAM 3 con un MLLM como SAM 3 Agent:
Consultas simples (SAM 3 nativo):
- "autobús escolar amarillo"
- "gato atigrado"
- "persona con sombrero rojo"
Consultas complejas (SAM 3 Agent con MLLM):
- "Personas sentadas pero que no sostienen una caja de regalo"
- "El perro más cercano a la cámara sin collar"
- "Objetos rojos más grandes que la mano de la persona"
SAM 3 Agent alcanza 76,0 gIoU en la validación de ReasonSeg (frente a 65,0 anterior mejor, una mejora del +16,9%) al combinar la segmentación de SAM 3 con las capacidades de razonamiento de MLLM.
Link to this section¿Qué tan preciso es SAM 3 en comparación con el rendimiento humano?#
En el punto de referencia SA-Co/Gold con triple anotación humana:
- Límite inferior humano: 74,2 CGF1 (anotador más conservador)
- Rendimiento de SAM 3: 65,0 CGF1
- Logro: 88 % del límite inferior humano estimado
- Límite superior humano: 81,4 CGF1 (anotador más liberal)
SAM 3 logra un rendimiento sólido que se aproxima a la precisión de nivel humano en la segmentación de conceptos de vocabulario abierto, siendo la brecha principalmente en conceptos ambiguos o subjetivos (p. ej., "ventana pequeña", "habitación acogedora").