Link to this sectionSAM 3 : Segmentation de tout à partir de concepts#
SAM 3 est entièrement intégré au package Ultralytics depuis la version 8.3.237 (PR #22897). Installe ou mets à niveau avec pip install -U ultralytics pour accéder à toutes les fonctionnalités de SAM 3, y compris la segmentation de concepts basée sur le texte, les exemples d'images et le suivi vidéo.
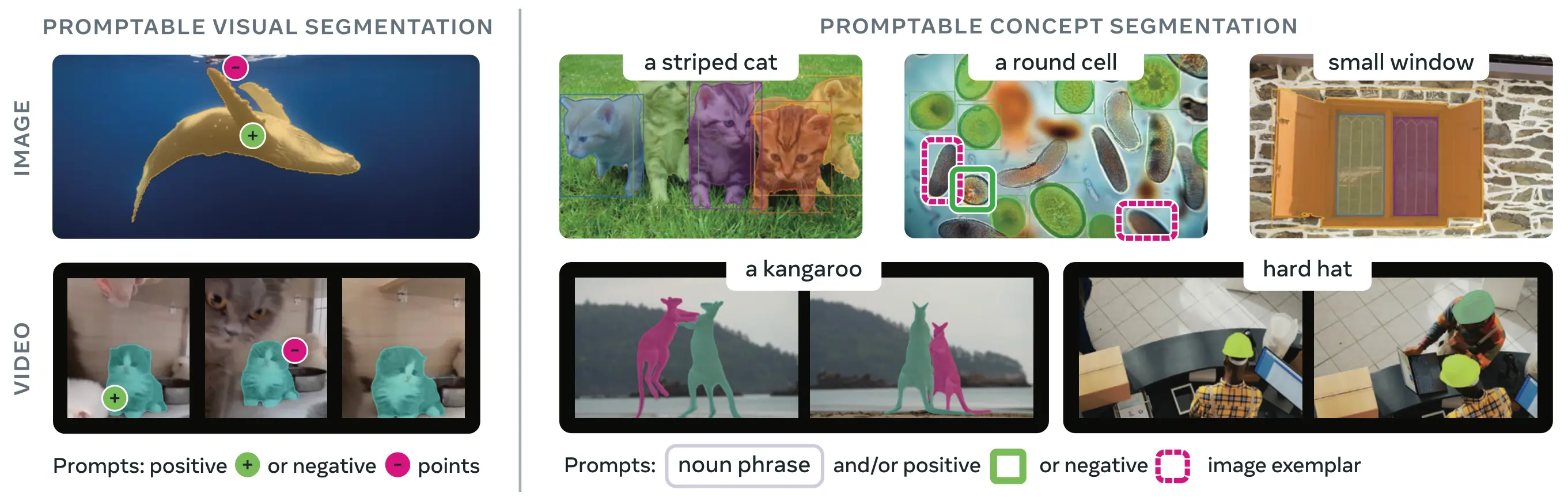
SAM 3 (Segment Anything Model 3) est le modèle de base publié par Meta pour la Promptable Concept Segmentation (PCS). En s'appuyant sur SAM 2, SAM 3 introduit une capacité fondamentalement nouvelle : détecter, segmenter et suivre toutes les instances d'un concept visuel spécifié par des prompts textuels, des exemples d'images, ou les deux. Contrairement aux versions précédentes de SAM qui segmentent des objets individuels par prompt, SAM 3 peut trouver et segmenter chaque occurrence d'un concept apparaissant n'importe où dans des images ou des vidéos, s'alignant sur les objectifs de vocabulaire ouvert dans l'instance segmentation moderne.
Watch: How to Use Meta Segment Anything 3 with Ultralytics | Text-Prompt Segmentation on Images & Videos
SAM 3 est maintenant entièrement intégré dans le package ultralytics, offrant un support natif pour la segmentation de concepts avec des prompts textuels, des prompts d'exemples d'images et des capacités de suivi vidéo.
Link to this sectionPrésentation#
SAM 3 réalise un gain de performance de 2× par rapport aux systèmes existants en Promptable Concept Segmentation tout en maintenant et en améliorant les capacités de SAM 2 pour la visual segmentation interactive. Le modèle excelle dans la segmentation à vocabulaire ouvert, permettant aux utilisateurs de spécifier des concepts à l'aide de simples groupes nominaux (par ex., "bus scolaire jaune", "chat rayé") ou en fournissant des exemples d'images de l'objet cible. Ces capacités complètent les pipelines prêts pour la production qui s'appuient sur des flux de travail predict et track rationalisés.
Link to this sectionQu'est-ce que la Promptable Concept Segmentation (PCS) ?#
La tâche PCS prend un concept prompt en entrée et renvoie des masques de segmentation avec des identités uniques pour toutes les instances d'objets correspondantes. Les concept prompts peuvent être :
- Texte : Simples groupes nominaux comme "pomme rouge" ou "personne portant un chapeau", similaire au zero-shot learning
- Exemples d'images : Boîtes englobantes autour d'objets exemples (positifs ou négatifs) pour une généralisation rapide
- Combiné : À la fois du texte et des exemples d'images pour un contrôle précis
Cela diffère des prompts visuels traditionnels (points, boîtes, masques) qui segmentent uniquement une instance d'objet spécifique, tels que popularisés par la SAM family originale.
Link to this sectionPrincipales métriques de performance#
| Métrique | Réalisation SAM 3 |
|---|---|
| LVIS Zero-Shot Mask AP | 47,0 (contre 38,5 précédemment, +22 % d'amélioration) |
| Benchmark SA-Co | 2× meilleur que les systèmes existants |
| Vitesse d'inférence (GPU H200) | 30 ms par image avec plus de 100 objets détectés |
| Performance vidéo | Quasi temps réel pour environ 5 objets simultanés |
| Benchmark MOSEv2 VOS | 60,1 J&F (+25,5 % par rapport à SAM 2.1, +17 % par rapport au SOTA précédent) |
| Raffinement interactif | Amélioration de +18,6 CGF1 après 3 exemples de prompts |
| Écart de performance humaine | Atteint 88 % de la borne inférieure estimée sur SA-Co/Gold |
Pour le contexte sur les métriques du modèle et les compromis en production, vois model evaluation insights et YOLO performance metrics.
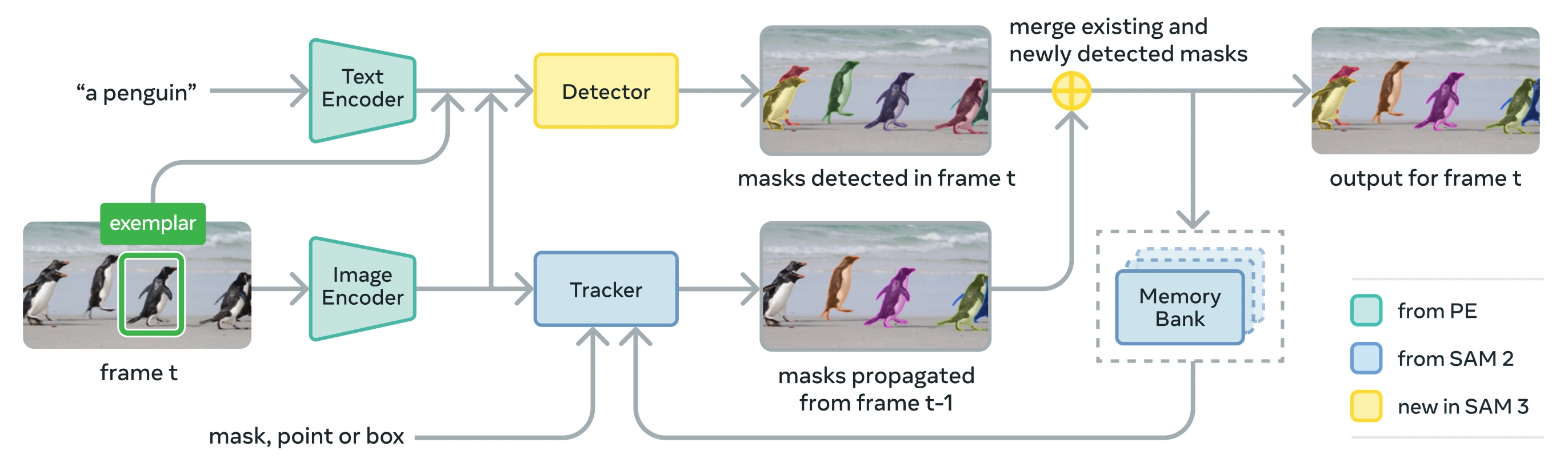
Link to this sectionArchitecture#
SAM 3 se compose d'un détecteur et d'un tracker qui partagent une dorsale de vision Perception Encoder (PE). Cette conception découplée évite les conflits de tâches tout en permettant à la fois la détection au niveau de l'image et le suivi au niveau de la vidéo, avec une interface compatible avec l'utilisation Python et CLI d'Ultralytics.
Link to this sectionComposants principaux#
-
Détecteur : Architecture basée sur DETR pour la détection de concept au niveau de l'image
- Encodeur de texte pour les prompts de groupes nominaux
- Encodeur d'exemples pour les prompts basés sur des images
- Encodeur de fusion pour conditionner les caractéristiques de l'image sur les prompts
- Nouvelle tête de présence qui découple la reconnaissance ("quoi") de la localisation ("où")
- Tête de masque pour générer des masques de segmentation d'instance
-
Tracker : Segmentation vidéo basée sur la mémoire héritée de SAM 2
- Encodeur de prompt, décodeur de masque, encodeur de mémoire
- Banque de mémoire pour stocker l'apparence de l'objet à travers les cadres
- Désambiguïsation temporelle aidée par des techniques comme un Kalman filter dans les configurations multi-objets
-
Jeton de présence : Un jeton global appris qui prédit si le concept cible est présent dans l'image/cadre, améliorant la détection en séparant la reconnaissance de la localisation.
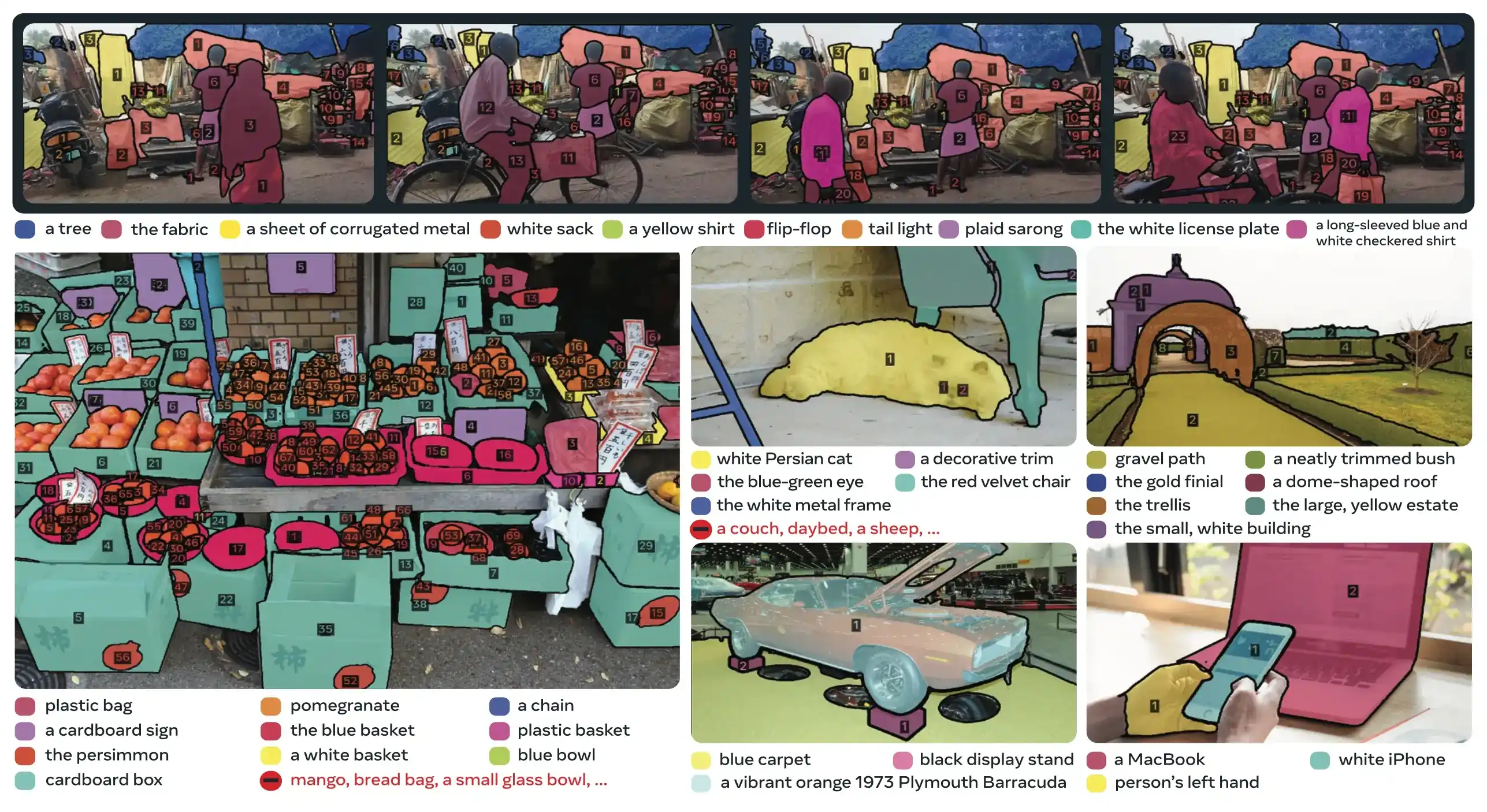
Link to this sectionInnovations clés#
- Reconnaissance et localisation découplées : La tête de présence prédit globalement la présence du concept, tandis que les requêtes de proposition se concentrent uniquement sur la localisation, évitant les objectifs contradictoires.
- Prompts conceptuels et visuels unifiés : Prend en charge à la fois PCS (prompts de concept) et PVS (prompts visuels comme les clics/boîtes de SAM 2) dans un seul modèle.
- Raffinement interactif par exemples : Les utilisateurs peuvent ajouter des exemples d'images positifs ou négatifs pour affiner les résultats de manière itérative, le modèle se généralisant à des objets similaires plutôt que de simplement corriger des instances individuelles.
- Désambiguïsation temporelle : Utilise des scores de détection de masques et des re-prompts périodiques pour gérer les occlusions, les scènes encombrées et les échecs de suivi en vidéo, en s'alignant avec les meilleures pratiques d'instance segmentation and tracking.
Link to this sectionJeu de données SA-Co#
SAM 3 est entraîné sur Segment Anything with Concepts (SA-Co), le plus grand et le plus diversifié des jeux de données de segmentation de Meta à ce jour, allant au-delà des benchmarks courants comme COCO et LVIS.
Link to this sectionDonnées d'entraînement#
| Composant du jeu de données | Description | Échelle |
|---|---|---|
| SA-Co/HQ | Données d'image de haute qualité annotées par des humains à partir d'un moteur de données en 4 phases | 5,2 M d'images, 4 M de groupes nominaux uniques |
| SA-Co/SYN | Jeu de données synthétique étiqueté par l'IA sans intervention humaine | 38 M de groupes nominaux, 1,4 Md de masques |
| SA-Co/EXT | 15 jeux de données externes enrichis avec des négatifs difficiles | Varie selon la source |
| SA-Co/VIDEO | Annotations vidéo avec suivi temporel | 52,5 K vidéos, 24,8 K groupes nominaux uniques |
Link to this sectionDonnées de benchmark#
Le benchmark d'évaluation SA-Co contient 214 K phrases uniques sur 126 K images et vidéos, fournissant plus de 50× plus de concepts que les benchmarks existants. Il comprend :
- SA-Co/Gold : 7 domaines, triple annotation pour mesurer les limites de performance humaine
- SA-Co/Silver : 10 domaines, annotation humaine unique
- SA-Co/Bronze et SA-Co/Bio : 9 jeux de données existants adaptés pour la segmentation de concepts
- SA-Co/VEval : Benchmark vidéo avec 3 domaines (SA-V, YT-Temporal-1B, SmartGlasses)
Link to this sectionInnovations du moteur de données#
Le moteur de données scalable avec humain et modèle dans la boucle de SAM 3 atteint un débit d'annotation 2× grâce à :
- Annotateurs IA : Des modèles basés sur Llama proposent des groupes nominaux diversifiés, y compris des négatifs difficiles
- Vérificateurs IA : Des multimodal LLMs affinés vérifient la qualité et l'exhaustivité des masques avec une performance quasi humaine
- Exploitation active : Concentre l'effort humain sur les cas d'échec difficiles où l'IA peine
- Axé sur l'ontologie : Tire parti d'une grande ontologie fondée sur Wikidata pour la couverture des concepts
Link to this sectionInstallation#
SAM 3 est disponible dans Ultralytics version 8.3.237 et ultérieure. Installe ou mets à niveau avec :
pip install -U ultralyticsContrairement aux autres modèles Ultralytics, les poids de SAM 3 (sam3.pt) ne sont pas téléchargés automatiquement. Tu dois d'abord demander l'accès aux poids du modèle sur la page du modèle SAM 3 sur Hugging Face puis, une fois approuvé, télécharger sam3.pt depuis cette page. Place le fichier sam3.pt téléchargé dans ton répertoire de travail ou spécifie le chemin complet lors du chargement du modèle.
Si tu obtiens l'erreur ci-dessus lors de la prédiction, cela signifie que tu as installé le mauvais package clip. Installe le bon package clip en exécutant ce qui suit :
pip uninstall clip -y
pip install git+https://github.com/ultralytics/CLIP.gitLink to this sectionComment utiliser SAM 3 : Polyvalence dans la segmentation de concepts#
SAM 3 prend en charge les tâches de Promptable Concept Segmentation (PCS) et de Promptable Visual Segmentation (PVS) via différentes interfaces de prédicteur :
Link to this sectionTâches et modèles pris en charge#
| Type de tâche | Types de prompts | Sortie |
|---|---|---|
| Concept Segmentation (PCS) | Texte (groupes nominaux), exemples d'images | Toutes les instances correspondant au concept |
| Visual Segmentation (PVS) | Points, boîtes, masques | Instance d'objet unique (style SAM 2) |
| Raffinement interactif | Ajouter/supprimer des exemples ou des clics de manière itérative | Segmentation raffinée avec une précision améliorée |
Link to this sectionExemples de segmentation de concepts#
Link to this sectionSegmenter avec des prompts textuels#
Trouve et segmente toutes les instances d'un concept à l'aide d'une description textuelle. Les invites textuelles nécessitent l'interface SAM3SemanticPredictor.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor with configuration
overrides = dict(
conf=0.25,
task="segment",
mode="predict",
model="sam3.pt",
quantize=16, # Use FP16 for faster inference
save=True,
)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image once for multiple queries
predictor.set_image("path/to/image.jpg")
# Query with multiple text prompts
results = predictor(text=["person", "bus", "glasses"])
# Works with descriptive phrases
results = predictor(text=["person with red cloth", "person with blue cloth"])
# Query with a single concept
results = predictor(text=["a person"])Link to this sectionSegmentation avec des exemples d'images#
Utilise des boîtes englobantes comme invites visuelles pour trouver toutes les instances similaires. Cela nécessite également SAM3SemanticPredictor pour une correspondance basée sur les concepts.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16, save=True)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image
predictor.set_image("path/to/image.jpg")
# Provide bounding box examples to segment similar objects
results = predictor(bboxes=[[480.0, 290.0, 590.0, 650.0]])
# Multiple bounding boxes as exemplars of the same visual concept
results = predictor(bboxes=[[539, 599, 589, 639], [343, 267, 499, 662]])Link to this sectionInférence basée sur les caractéristiques pour plus d'efficacité#
Extrais les caractéristiques de l'image une fois et réutilise-les pour plusieurs requêtes de segmentation afin d'améliorer l'efficacité.
import cv2
from ultralytics.models.sam import SAM3SemanticPredictor
from ultralytics.utils.plotting import Annotator, colors
# Initialize predictors
overrides = dict(conf=0.50, task="segment", mode="predict", model="sam3.pt", verbose=False)
predictor = SAM3SemanticPredictor(overrides=overrides)
predictor2 = SAM3SemanticPredictor(overrides=overrides)
# Extract features from the first predictor
source = "path/to/image.jpg"
predictor.set_image(source)
src_shape = cv2.imread(source).shape[:2]
# Setup second predictor and reuse features
predictor2.setup_model()
# Perform inference using shared features with text prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, text=["person"])
# Perform inference using shared features with bounding box prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, bboxes=[[439, 437, 524, 709]])
# Visualize results
if masks is not None:
masks, boxes = masks.cpu().numpy(), boxes.cpu().numpy()
im = cv2.imread(source)
annotator = Annotator(im, pil=False)
annotator.masks(masks, [colors(x, True) for x in range(len(masks))])
cv2.imshow("result", annotator.result())
cv2.waitKey(0)Link to this sectionSegmentation de concepts vidéo#
Link to this sectionSuivi de concepts dans la vidéo avec des boîtes englobantes#
Détecte et suis les instances d'objets dans les trames vidéo en utilisant des invites de boîtes englobantes.
from ultralytics.models.sam import SAM3VideoPredictor
# Create video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16)
predictor = SAM3VideoPredictor(overrides=overrides)
# Track objects using bounding box prompts
results = predictor(source="path/to/video.mp4", bboxes=[[706.5, 442.5, 905.25, 555], [598, 635, 725, 750]], stream=True)
# Process and display results
for r in results:
r.show() # Display frame with segmentation masksLink to this sectionSuivi de concepts avec des invites textuelles#
Suis toutes les instances de concepts spécifiés par du texte à travers les trames vidéo.
from ultralytics.models.sam import SAM3VideoSemanticPredictor
# Initialize semantic video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=640, model="sam3.pt", quantize=16, save=True)
predictor = SAM3VideoSemanticPredictor(overrides=overrides)
# Track concepts using text prompts
results = predictor(source="path/to/video.mp4", text=["person", "bicycle"], stream=True)
# Process results
for r in results:
r.show() # Display frame with tracked objects
# Alternative: Track with bounding box prompts
results = predictor(
source="path/to/video.mp4",
bboxes=[[864, 383, 975, 620], [705, 229, 782, 402]],
labels=[1, 1], # Positive labels
stream=True,
)Link to this sectionInvites visuelles (Compatibilité SAM 2)#
SAM 3 maintient une rétrocompatibilité totale avec les invites visuelles de SAM 2 pour la segmentation d'objet unique :
L'interface SAM de base se comporte exactement comme SAM 2, ne segmentant que la zone spécifique indiquée par les invites visuelles (points, boîtes ou masques).
from ultralytics import SAM
model = SAM("sam3.pt")
# Single point prompt - segments object at specific location
results = model.predict(source="path/to/image.jpg", points=[900, 370], labels=[1])
results[0].show()
# Multiple points - segments single object with multiple point hints
results = model.predict(source="path/to/image.jpg", points=[[400, 370], [900, 370]], labels=[1, 1])
# Box prompt - segments object within bounding box
results = model.predict(source="path/to/image.jpg", bboxes=[100, 150, 300, 400])
results[0].show()Utiliser SAM("sam3.pt") avec des invites visuelles (points/boîtes/masques) segmentera uniquement l'objet spécifique à cet emplacement, tout comme SAM 2. Pour segmenter toutes les instances d'un concept, utilise SAM3SemanticPredictor avec des invites textuelles ou des exemples comme indiqué ci-dessus.
Link to this sectionBenchmarks de performance#
Link to this sectionSegmentation d'image#
SAM 3 obtient des résultats de pointe sur plusieurs benchmarks, y compris des jeux de données réels comme LVIS et COCO pour la segmentation :
| Benchmark | Métrique | SAM 3 | Meilleur précédent | Amélioration |
|---|---|---|---|---|
| LVIS (zero-shot) | Mask AP | 47.0 | 38.5 | +22,1 % |
| SA-Co/Gold | CGF1 | 65,0 | 34,3 (OWLv2) | +89,5 % |
| COCO (zero-shot) | Box AP | 53,5 | 52,2 (T-Rex2) | +2,5 % |
| ADE-847 (seg sémantique) | mIoU | 14,7 | 9,2 (APE-D) | +59,8 % |
| PascalConcept-59 | mIoU | 59,4 | 58,5 (APE-D) | +1,5 % |
| Cityscapes (seg sémantique) | mIoU | 65,1 | 44,2 (APE-D) | +47,3 % |
Explore les options de jeux de données pour une expérimentation rapide dans Ultralytics datasets.
Link to this sectionPerformance de segmentation vidéo#
SAM 3 montre des améliorations significatives par rapport à SAM 2 et aux précédents résultats de pointe sur des benchmarks vidéo tels que DAVIS 2017 et YouTube-VOS :
| Benchmark | Métrique | SAM 3 | SAM 2.1 L | Amélioration |
|---|---|---|---|---|
| MOSEv2 | J&F | 60,1 | 47,9 | +25,5 % |
| DAVIS 2017 | J&F | 92,0 | 90,7 | +1,4 % |
| LVOSv2 | J&F | 88,2 | 79,6 | +10,8 % |
| SA-V | J&F | 84,6 | 78,4 | +7,9 % |
| YTVOS19 | J&F | 89,6 | 89,3 | +0,3 % |
Link to this sectionAdaptation Few-Shot#
SAM 3 excelle dans l'adaptation à de nouveaux domaines avec un minimum d'exemples, ce qui est pertinent pour les workflows d'IA centrée sur les données :
| Benchmark | 0-shot AP | 10-shot AP | Meilleur précédent (10-shot) |
|---|---|---|---|
| ODinW13 | 59,9 | 71,6 | 67,9 (gDino1.5-Pro) |
| RF100-VL | 14.3 | 35,7 | 33,7 (gDino-T) |
Link to this sectionEfficacité du raffinement interactif#
L'incitation basée sur les concepts de SAM 3 avec des exemples converge beaucoup plus rapidement que l'incitation visuelle :
| Invites ajoutées | Score CGF1 | Gain vs texte seul | Gain vs base de référence PVS |
|---|---|---|---|
| Texte seul | 46,4 | base de référence | base de référence |
| +1 exemple | 57.6 | +11,2 | +6,7 |
| +2 exemples | 62.2 | +15.8 | +9.7 |
| +3 exemplaires | 65,0 | +18.6 | +11.2 |
| +4 exemplaires | 65.7 | +19.3 | +11.5 (plateau) |
Link to this sectionPrécision du comptage d'objets#
SAM 3 fournit un comptage précis en segmentant toutes les instances, une exigence courante dans le comptage d'objets :
| Benchmark | Précision | MAE | vs meilleur MLLM |
|---|---|---|---|
| CountBench | 95.6% | 0.11 | 92.4% (Gemini 2.5) |
| PixMo-Count | 87.3% | 0.22 | 88.8% (Molmo-72B) |
Link to this sectionComparaison SAM 3 vs SAM 2 vs YOLO#
Nous comparons ici les capacités de SAM 3 avec les modèles SAM 2 et YOLO26 :
| Capacité | SAM 3 | SAM 2 | YOLO26n-seg |
|---|---|---|---|
| Segmentation de concept | ✅ Toutes les instances à partir de texte/exemplaires | ❌ Non supporté | ❌ Non supporté |
| Segmentation visuelle | ✅ Instance unique (compatible SAM 2) | ✅ Instance unique | ✅ Toutes les instances |
| Capacité zero-shot | ✅ Vocabulaire ouvert | ✅ Prompts géométriques | ❌ Ensemble fermé |
| Raffinement interactif | ✅ Exemplaires + clics | ✅ Clics uniquement | ❌ Non supporté |
| Suivi vidéo | ✅ Multi-objet avec identités | ✅ Multi-objet | ✅ Multi-objet |
| LVIS Mask AP (zero-shot) | 47.0 | N/A | N/A |
| MOSEv2 J&F | 60,1 | 47,9 | N/A |
| Vitesse (GPU, ms/im) | 2921 | 857 | 8.4 |
| Taille du modèle | 3.45 GB | 162 Mo (base) | 6.4 Mo |
Vitesse évaluée sur NVIDIA RTX PRO 6000 avec torch==2.9.1 et ultralytics==8.4.19.
Points clés :
- SAM 3 : Le meilleur pour la segmentation de concept à vocabulaire ouvert, trouvant toutes les instances d'un concept avec des prompts textuels ou par exemplaires
- SAM 2 : Le meilleur pour la segmentation interactive d'un objet unique dans des images et vidéos avec des prompts géométriques
- YOLO26 : Le meilleur pour une segmentation en temps réel à haute vitesse avec une inférence de bout en bout sans NMS, exportable vers de nombreux formats pour un déploiement sur GPU, CPU et appareils en périphérie
Link to this sectionComparaison de SAM vs YOLO#
Comparaison de SAM 3, SAM 2, SAM, MobileSAM et FastSAM avec les modèles de segmentation Ultralytics YOLO (YOLOv8, YOLO11, YOLO26) en termes de taille, paramètres et vitesse d'inférence GPU :
| Modèle | Taille (Mo) | Paramètres (M) | Vitesse (GPU) (ms/im) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 1306 |
| Meta SAM2-b | 162 | 80.8 | 857 |
| Meta SAM2-t | 78.1 | 38.9 | 668 |
| Meta SAM3 | 3450 | 473.6 | 2921 |
| MobileSAM | 40.7 | 10.1 | 605 |
| FastSAM-s avec backbone YOLOv8 | 23.7 | 11.8 | 55.9 |
| Ultralytics YOLOv8n-seg | 6.7 (515x plus petit) | 3.4 (139.1x de moins) | 17.4 (167x plus rapide) |
| Ultralytics YOLO11n-seg | 5.9 (585x plus petit) | 2.9 (163.1x de moins) | 12.6 (231x plus rapide) |
| Ultralytics YOLO26n-seg | 6.4 (539x plus petit) | 2.7 (175.2x de moins) | 8.4 (347x plus rapide) |
Cette comparaison démontre les différences substantielles de tailles et de vitesses de modèle entre les variantes de SAM et les modèles de segmentation YOLO. Bien que SAM offre des capacités de segmentation automatique uniques, les modèles YOLO, en particulier YOLOv8n-seg, YOLO11n-seg et YOLO26n-seg, sont nettement plus petits, plus rapides et plus efficaces sur le plan informatique.
Tests effectués sur une NVIDIA RTX PRO 6000 avec 96 Go de VRAM en utilisant torch==2.9.1 et ultralytics==8.4.19. Pour reproduire ce test :
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# Profile SAM3, SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt", "sam3.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# Profile FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# Profile YOLO models
for file_name in ["yolov8n-seg.pt", "yolo11n-seg.pt", "yolo26n-seg.pt"]:
model = YOLO(file_name)
model.info()
model(ASSETS)Link to this sectionMétriques d'évaluation#
SAM 3 introduit de nouvelles métriques conçues pour la tâche PCS, complétant les mesures familières comme le score F1, la précision et le rappel.
Link to this sectionClassification-Gated F1 (CGF1)#
La métrique principale combinant localisation et classification :
CGF1 = 100 × pmF1 × IL_MCC
Où :
- pmF1 (Positive Macro F1) : Mesure la qualité de localisation sur les exemples positifs
- IL_MCC (Image-Level Matthews Correlation Coefficient) : Mesure la précision de la classification binaire ("le concept est-il présent ?")
Link to this sectionPourquoi ces métriques ?#
Les métriques AP traditionnelles ne tiennent pas compte du calibrage, rendant les modèles difficiles à utiliser en pratique. En évaluant uniquement les prédictions au-dessus de 0,5 de confiance, les métriques de SAM 3 imposent un bon calibrage et imitent les modèles d'utilisation réels dans les boucles interactives de predict et track.
Link to this sectionAblations clés et enseignements#
Link to this sectionImpact de la tête de présence#
La tête de présence dissocie la reconnaissance de la localisation, offrant des améliorations significatives :
| Configuration | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Sans présence | 57.6 | 0.77 | 74.7 |
| Avec présence | 63.3 | 0.82 | 77.1 |
La tête de présence fournit un gain de +5.7 CGF1 (+9.9%), améliorant principalement la capacité de reconnaissance (IL_MCC +6.5%).
Link to this sectionEffet des exemples négatifs difficiles#
| Exemples négatifs difficiles/Image | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 0 | 31.8 | 0.44 | 70.2 |
| 5 | 44.8 | 0.62 | 71.9 |
| 30 | 49.2 | 0.68 | 72.3 |
Les exemples négatifs difficiles sont cruciaux pour la reconnaissance à vocabulaire ouvert, améliorant le IL_MCC de 54.5% (0.44 → 0.68).
Link to this sectionMise à l'échelle des données d'entraînement#
| Sources de données | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Externe seulement | 30.9 | 0.46 | 66.3 |
| Externe + Synthétique | 39.7 | 0.57 | 70.6 |
| Externe + HQ | 51.8 | 0.71 | 73.2 |
| Tous les trois | 54.3 | 0.74 | 73.5 |
Les annotations humaines de haute qualité offrent des gains importants par rapport aux seules données synthétiques ou externes. Pour en savoir plus sur les pratiques de qualité des données, consulte la collecte et l'annotation de données.
Link to this sectionApplications#
La capacité de segmentation de concepts de SAM 3 permet de nouveaux cas d'usage :
- Modération de contenu : Trouve toutes les occurrences de types de contenu spécifiques dans les bibliothèques multimédias
- E-commerce : segmente tous les produits d'un certain type dans les images de catalogue, en prenant en charge l'auto-annotation
- Imagerie médicale : Identifie toutes les occurrences de types de tissus ou d'anomalies spécifiques
- Systèmes autonomes : Suis toutes les instances de panneaux de signalisation, piétons ou véhicules par catégorie
- Analyse vidéo : Compte et suis toutes les personnes portant des vêtements spécifiques ou effectuant des actions
- Annotation de jeu de données : Annote rapidement toutes les instances de catégories d'objets rares
- Recherche scientifique : Quantifie et analyse tous les spécimens correspondant à des critères spécifiques
Link to this sectionAgent SAM 3 : Raisonnement linguistique étendu#
SAM 3 peut être combiné avec des modèles de langage multimodaux (MLLM) pour traiter des requêtes complexes nécessitant un raisonnement, dans le même esprit que les systèmes à vocabulaire ouvert comme OWLv2 et T-Rex.
Link to this sectionPerformance sur les tâches de raisonnement#
| Benchmark | Métrique | Agent SAM 3 (Gemini 2.5 Pro) | Meilleur précédent |
|---|---|---|---|
| ReasonSeg (validation) | gIoU | 76.0 | 65.0 (SoTA) |
| ReasonSeg (test) | gIoU | 73.8 | 61.3 (SoTA) |
| OmniLabel (validation) | AP | 46.7 | 36.5 (REAL) |
| RefCOCO+ | Acc | 91.2 | 89.3 (LISA) |
Link to this sectionExemples de requêtes complexes#
L'agent SAM 3 peut gérer des requêtes nécessitant un raisonnement :
- "Des personnes assises mais ne tenant pas de boîte cadeau dans leurs mains"
- "Le chien le plus proche de la caméra qui ne porte pas de collier"
- "Objets rouges plus grands que la main de la personne"
Le MLLM propose des requêtes sous forme de syntagmes nominaux simples à SAM 3, analyse les masques renvoyés et itère jusqu'à satisfaction.
Link to this sectionLimites#
Bien que SAM 3 représente une avancée majeure, il présente certaines limitations :
- Complexité des expressions : Mieux adapté aux syntagmes nominaux simples ; les expressions référentielles longues ou le raisonnement complexe peuvent nécessiter une intégration MLLM
- Gestion de l'ambiguïté : Certains concepts restent intrinsèquement ambigus (ex. : "petite fenêtre", "pièce confortable")
- Exigences computationnelles : Plus grand et plus lent que les modèles de détection spécialisés comme YOLO
- Portée du vocabulaire : Focalisé sur des concepts visuels atomiques ; le raisonnement compositionnel est limité sans assistance MLLM
- Concepts rares : Les performances peuvent se dégrader sur des concepts extrêmement rares ou très spécifiques peu représentés dans les données d'entraînement
Link to this sectionCitation#
@inproceedings{sam3_2025,
title = {SAM 3: Segment Anything with Concepts},
author = {Anonymous authors},
booktitle = {Submitted to ICLR 2026},
year = {2025},
url = {https://openreview.net/forum?id=r35clVtGzw},
note = {Paper ID: 4183, under double-blind review}
}Link to this sectionFAQ#
Link to this sectionQuand SAM 3 est-il sorti ?#
SAM 3 a été publié par Meta le 20 novembre 2025 et est entièrement intégré dans Ultralytics depuis la version 8.3.237 (PR #22897). Un support complet est disponible pour le mode de prédiction et le mode de suivi.
Link to this sectionSAM 3 est-il intégré dans Ultralytics ?#
Oui ! SAM 3 est entièrement intégré dans le package Python Ultralytics, incluant la segmentation de concepts, les invites visuelles de style SAM 2 et le suivi vidéo multi-objets. SAM 3 alimente également la fonctionnalité d'annotation intelligente sur la plateforme Ultralytics, où tu peux annoter des images en quelques clics.
Link to this sectionQu'est-ce que la segmentation de concepts sollicitable (PCS) ?#
PCS est une nouvelle tâche introduite dans SAM 3 qui segmente toutes les instances d'un concept visuel dans une image ou une vidéo. Contrairement à la segmentation traditionnelle qui cible une instance d'objet spécifique, PCS trouve chaque occurrence d'une catégorie. Par exemple :
- Invite textuelle : "bus scolaire jaune" → segmente tous les bus scolaires jaunes de la scène
- Exemplaire d'image : Encadrement d'un chien → segmente tous les chiens dans l'image
- Combiné : "chat tigré" + boîte exemplaire → segmente tous les chats tigrés correspondant à l'exemple
Voir le contexte associé sur la détection d'objets et la segmentation d'instances.
Link to this sectionEn quoi SAM 3 diffère-t-il de SAM 2 ?#
| Fonctionnalité | SAM 2 | SAM 3 |
|---|---|---|
| Tâche | Objet unique par invite | Toutes les instances d'un concept |
| Types d'invites | Points, boîtes, masques | + Expressions textuelles, exemplaires d'images |
| Capacité de détection | Nécessite un détecteur externe | Détecteur à vocabulaire ouvert intégré |
| Reconnaissance | Basée sur la géométrie uniquement | Reconnaissance textuelle et visuelle |
| Architecture | Suiveur uniquement | Détecteur + Suiveur avec tête de présence |
| Performance Zero-Shot | N/A (nécessite des invites visuelles) | 47.0 AP sur LVIS, 2× mieux sur SA-Co |
| Raffinement interactif | Clics uniquement | Clics + généralisation par exemplaire |
SAM 3 maintient la rétrocompatibilité avec les invites visuelles SAM 2 tout en ajoutant des capacités basées sur les concepts.
Link to this sectionQuels jeux de données sont utilisés pour entraîner SAM 3 ?#
SAM 3 est entraîné sur le jeu de données Segment Anything with Concepts (SA-Co) :
Données d'entraînement :
- 5,2 M d'images avec 4 M de phrases nominales uniques (SA-Co/HQ) - annotations humaines de haute qualité
- 52,5 K vidéos avec 24,8 K phrases nominales uniques (SA-Co/VIDEO)
- 1,4 Md de masques synthétiques sur 38 M de phrases nominales (SA-Co/SYN)
- 15 jeux de données externes enrichis avec des exemples négatifs difficiles (SA-Co/EXT)
Données de référence :
- 214 K concepts uniques sur 126 K images/vidéos
- 50× plus de concepts que les benchmarks existants (par exemple, LVIS possède ~4 K concepts)
- Triple annotation sur SA-Co/Gold pour mesurer les limites de performance humaine
Cette échelle et cette diversité massives permettent la généralisation zero-shot supérieure de SAM 3 sur des concepts à vocabulaire ouvert.
Link to this sectionComment SAM 3 se compare-t-il à YOLO26 pour la segmentation ?#
SAM 3 et YOLO26 répondent à des cas d'utilisation différents :
Avantages de SAM 3 :
- Vocabulaire ouvert : Segmente tout concept via des invites textuelles sans entraînement
- Zero-shot : Fonctionne immédiatement sur de nouvelles catégories
- Interactif : Le raffinement basé sur des exemples se généralise à des objets similaires
- Basé sur des concepts : Trouve automatiquement toutes les instances d'une catégorie
- Précision : 47,0 AP sur la segmentation d'instances LVIS zero-shot
Avantages de YOLO26 :
- Vitesse : Inférence des ordres de grandeur plus rapide avec une conception de bout en bout sans NMS
- Efficacité : Modèles 539× plus petits (6,4 Mo contre 3,45 Go)
- Adapté aux ressources : Fonctionne sur les appareils edge et mobiles
- Temps réel : Optimisé pour les déploiements en production
Recommandation :
- Utilise SAM 3 pour une segmentation flexible à vocabulaire ouvert lorsque tu dois trouver toutes les instances de concepts décrits par du texte ou des exemples
- Utilise YOLO26 pour des déploiements en production haute vitesse où les catégories sont connues à l'avance
- Utilise SAM 2 pour une segmentation interactive d'objet unique avec des invites géométriques
Link to this sectionEst-ce que SAM 3 peut gérer des requêtes linguistiques complexes ?#
SAM 3 est conçu pour des phrases nominales simples (par exemple, "pomme rouge", "personne portant un chapeau"). Pour des requêtes complexes nécessitant du raisonnement, combine SAM 3 avec un MLLM en tant que SAM 3 Agent :
Requêtes simples (SAM 3 natif) :
- "bus scolaire jaune"
- "chat rayé"
- "personne portant un chapeau rouge"
Requêtes complexes (SAM 3 Agent avec MLLM) :
- "Personnes assises mais ne tenant pas de boîte cadeau"
- "Le chien le plus proche de la caméra sans collier"
- "Objets rouges plus grands que la main de la personne"
SAM 3 Agent atteint 76,0 gIoU sur la validation ReasonSeg (contre 65,0 pour le précédent record, soit une amélioration de +16,9 %) en combinant la segmentation de SAM 3 avec les capacités de raisonnement des MLLM.
Link to this sectionQuelle est la précision de SAM 3 par rapport à la performance humaine ?#
Sur le benchmark SA-Co/Gold avec triple annotation humaine :
- Limite inférieure humaine : 74,2 CGF1 (annotateur le plus conservateur)
- Performance de SAM 3 : 65,0 CGF1
- Réalisation : 88 % de la limite inférieure humaine estimée
- Limite supérieure humaine : 81,4 CGF1 (annotateur le plus libéral)
SAM 3 obtient de solides performances approchant la précision humaine sur la segmentation de concepts à vocabulaire ouvert, l'écart se situant principalement sur des concepts ambigus ou subjectifs (par exemple, "petite fenêtre", "pièce confortable").