Best Practices voor modelimplementatie
Inleiding
Het uitrollen van modellen is de stap in een computervisieproject waarbij een model vanuit de ontwikkelingsfase naar een echte toepassing wordt gebracht. Er zijn verschillende opties om modellen in te zetten: inzet in de cloud biedt schaalbaarheid en gemakkelijke toegang, inzet aan de rand vermindert latentie door het model dichter bij de gegevensbron te brengen en lokale inzet zorgt voor privacy en controle. Het kiezen van de juiste strategie hangt af van de behoeften van je applicatie, waarbij snelheid, beveiliging en schaalbaarheid in balans zijn.
Het is ook belangrijk om best practices te volgen bij het implementeren van een model, omdat de implementatie de effectiviteit en betrouwbaarheid van de prestaties van het model aanzienlijk kan beïnvloeden. In deze gids leggen we de nadruk op hoe je ervoor kunt zorgen dat het uitrollen van je model soepel, efficiënt en veilig verloopt.
Model Implementatie Opties
Vaak moet een model, zodra het getraind, geëvalueerd en getest is, worden omgezet in specifieke formaten om effectief te kunnen worden ingezet in verschillende omgevingen, zoals cloud, edge of lokale apparaten.
Met betrekking tot YOLOv8 kun je je model exporteren naar verschillende formaten. Als je je model bijvoorbeeld moet overzetten tussen verschillende frameworks, is ONNX een uitstekend hulpmiddel en exporteren naar YOLOv8 naar ONNX is eenvoudig. Je kunt hier meer opties bekijken over het soepel en effectief integreren van je model in verschillende omgevingen.
Een implementatieomgeving kiezen
De keuze waar je je computervisiemodel wilt inzetten hangt af van meerdere factoren. Verschillende omgevingen hebben unieke voordelen en uitdagingen, dus het is essentieel om de omgeving te kiezen die het beste past bij je behoeften.
Cloud Uitrol
Inzet in de cloud is geweldig voor toepassingen die snel moeten opschalen en grote hoeveelheden gegevens moeten verwerken. Platformen zoals AWS, Google Cloud en Azure maken het eenvoudig om je modellen te beheren, van training tot implementatie. Ze bieden diensten zoals AWS SageMaker, Google AI Platform en Azure Machine Learning om je tijdens het hele proces te helpen.
Het gebruik van de cloud kan echter duur zijn, vooral bij hoog gegevensgebruik, en je kunt te maken krijgen met latentieproblemen als je gebruikers zich ver van de datacenters bevinden. Om de kosten en prestaties te beheren, is het belangrijk om het gebruik van bronnen te optimaliseren en ervoor te zorgen dat de regels voor gegevensprivacy worden nageleefd.
Uitrol aan de rand
Edge deployment werkt goed voor toepassingen die real-time reacties en een lage latentie nodig hebben, vooral op plaatsen met beperkte of geen internettoegang. Het inzetten van modellen op randapparaten zoals smartphones of IoT gadgets zorgt voor snelle verwerking en houdt gegevens lokaal, wat de privacy ten goede komt. Inzet aan de rand bespaart ook bandbreedte doordat er minder gegevens naar de cloud worden gestuurd.
Randapparaten hebben echter vaak beperkte rekenkracht, dus je moet je modellen optimaliseren. Hulpmiddelen zoals TensorFlow Lite en NVIDIA Jetson kunnen hierbij helpen. Ondanks de voordelen kan het onderhouden en bijwerken van veel apparaten een uitdaging zijn.
Lokale implementatie
Lokale implementatie is het beste wanneer de privacy van gegevens belangrijk is of wanneer er geen of onbetrouwbare internettoegang is. Door modellen op lokale servers of desktops te draaien, heb je volledige controle en blijven je gegevens veilig. Het kan ook de latentie verminderen als de server dicht bij de gebruiker staat.
Lokaal schalen kan echter lastig zijn en onderhoud kan tijdrovend zijn. Het gebruik van tools als Docker voor containerisatie en Kubernetes voor beheer kan helpen om lokale implementaties efficiënter te maken. Regelmatige updates en onderhoud zijn nodig om alles soepel te laten draaien.
Technieken voor modeloptimalisatie
Het optimaliseren van je computervisiemodel helpt om het efficiënt uit te voeren, vooral wanneer je het gebruikt in omgevingen met beperkte bronnen zoals randapparaten. Hier zijn enkele belangrijke technieken om je model te optimaliseren.
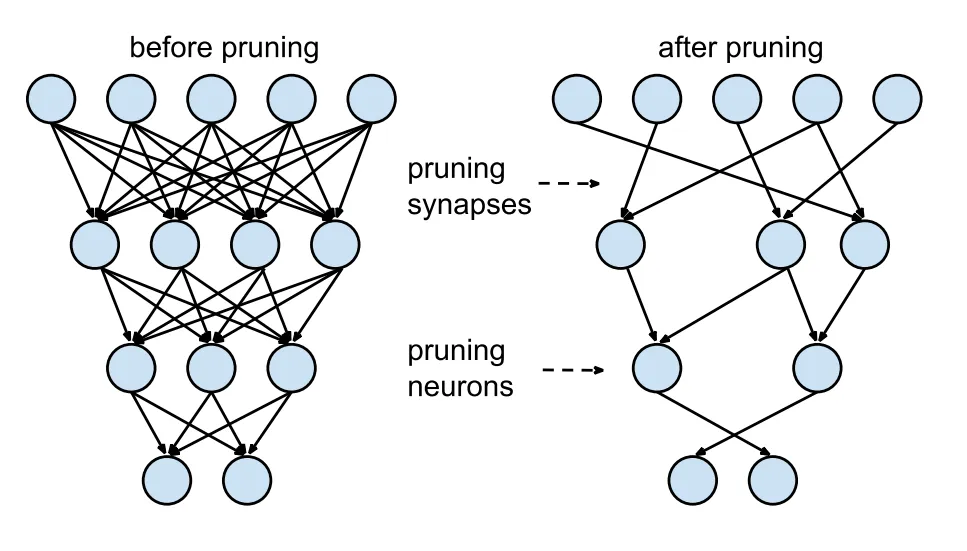
Model Snoeien
Snoeien verkleint het model door gewichten te verwijderen die weinig bijdragen aan de uiteindelijke uitvoer. Het maakt het model kleiner en sneller zonder de nauwkeurigheid significant te beïnvloeden. Pruning bestaat uit het identificeren en verwijderen van onnodige parameters, wat resulteert in een lichter model dat minder rekenkracht vereist. Het is vooral nuttig voor het inzetten van modellen op apparaten met beperkte middelen.
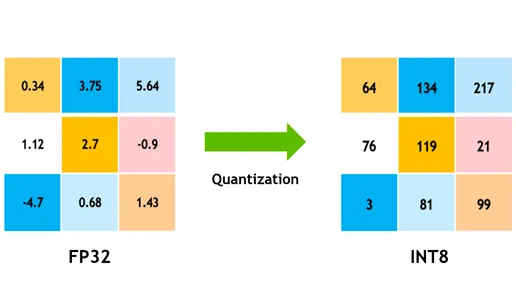
Model Kwantisering
Quantisatie zet de gewichten en activeringen van het model om van hoge precisie (zoals 32-bits floats) naar lagere precisie (zoals 8-bits gehele getallen). Door de modelgrootte te verkleinen, wordt de inferentie versneld. Quantization-aware training (QAT) is een methode waarbij het model wordt getraind met quantisatie in gedachten, waardoor de nauwkeurigheid beter behouden blijft dan bij quantisatie na de training. Door kwantisatie tijdens de trainingsfase te behandelen, leert het model zich aan te passen aan een lagere precisie, waardoor de prestaties behouden blijven en er minder rekenkracht nodig is.
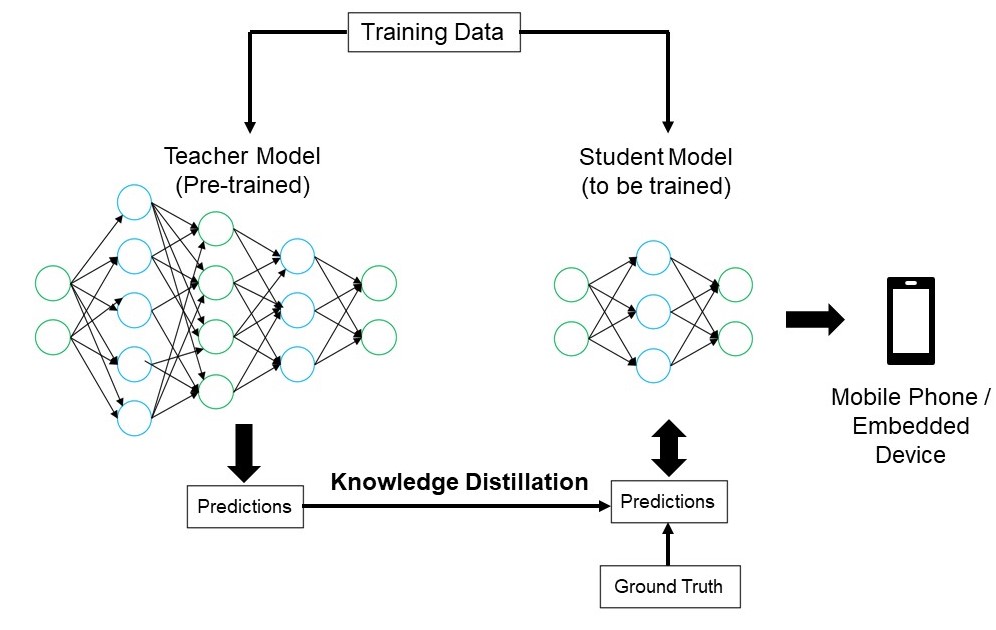
Kennisdestillatie
Bij kennisdistillatie wordt een kleiner, eenvoudiger model (de leerling) getraind om de uitvoer van een groter, complexer model (de leraar) na te bootsen. Het leerlingmodel leert om de voorspellingen van de leraar te benaderen, wat resulteert in een compact model dat veel van de nauwkeurigheid van de leraar behoudt. Deze techniek is gunstig voor het maken van efficiënte modellen die geschikt zijn voor gebruik op randapparaten met beperkte bronnen.
Problemen met implementaties oplossen
Je kunt voor uitdagingen komen te staan bij het implementeren van je computervisiemodellen, maar inzicht in veelvoorkomende problemen en oplossingen kan het proces soepeler laten verlopen. Hier zijn enkele algemene tips voor probleemoplossing en best practices om je te helpen bij problemen met de implementatie.
Je model is minder nauwkeurig na implementatie
Als de nauwkeurigheid van je model afneemt nadat het is ingezet, kan dat frustrerend zijn. Dit probleem kan verschillende oorzaken hebben. Hier volgen enkele stappen om je te helpen het probleem te identificeren en op te lossen:
- Controleer gegevensconsistentie: Controleer of de gegevens die je model verwerkt na implementatie consistent zijn met de gegevens waarop het getraind is. Verschillen in gegevensdistributie, kwaliteit of formaat kunnen de prestaties aanzienlijk beïnvloeden.
- Valideer voorbewerkingsstappen: Controleer of alle voorbewerkingsstappen die tijdens de training zijn toegepast, ook consequent worden toegepast tijdens de inzet. Dit omvat het aanpassen van de grootte van afbeeldingen, het normaliseren van pixelwaarden en andere gegevenstransformaties.
- Evalueer de omgeving van het model: Zorg ervoor dat de hardware- en softwareconfiguraties die gebruikt worden tijdens de implementatie overeenkomen met die tijdens de training. Verschillen in bibliotheken, versies en hardwaremogelijkheden kunnen discrepanties veroorzaken.
- Modelinferentie bewaken: Log invoer en uitvoer in verschillende stadia van de inferentiepijplijn om eventuele afwijkingen te detecteren. Dit kan helpen bij het identificeren van problemen zoals gegevenscorruptie of onjuiste verwerking van modeluitvoer.
- De export en conversie van het model controleren: Exporteer het model opnieuw en zorg ervoor dat het conversieproces de integriteit van de modelgewichten en architectuur behoudt.
- Test met een gecontroleerde dataset: Implementeer het model in een testomgeving met een dataset die je controleert en vergelijk de resultaten met de trainingsfase. Zo kun je vaststellen of het probleem ligt bij de inzetomgeving of bij de gegevens.
Bij het gebruik van YOLOv8 kunnen verschillende factoren de nauwkeurigheid van het model beïnvloeden. Het converteren van modellen naar formaten zoals TensorRT brengt optimalisaties met zich mee zoals gewichtskwantisering en laagfusie, die kleine precisieverliezen kunnen veroorzaken. Het gebruik van FP16 (halve precisie) in plaats van FP32 (volledige precisie) kan de inferentie versnellen, maar kan fouten in de numerieke precisie introduceren. Ook hardwarebeperkingen, zoals die op de Jetson Nano, met lagere CUDA core counts en verminderde geheugenbandbreedte, kunnen de prestaties beïnvloeden.
Inferenties duren langer dan je had verwacht
Bij het inzetten van machine learning modellen is het belangrijk dat ze efficiënt werken. Als gevolgtrekkingen langer duren dan verwacht, kan dit de gebruikerservaring en de effectiviteit van je applicatie beïnvloeden. Hier zijn enkele stappen om je te helpen het probleem te identificeren en op te lossen:
- Warm-up runs implementeren: Initiële runs bevatten vaak setup overhead, wat de latentiemetingen kan vertekenen. Voer een paar opwarm-inferenties uit voordat je de latentie meet. Het uitsluiten van deze initiële runs geeft een nauwkeurigere meting van de prestaties van het model.
- Optimaliseer de inferentie-engine: Controleer dubbel of de inferentie-engine volledig is geoptimaliseerd voor jouw specifieke GPU-architectuur. Gebruik de nieuwste stuurprogramma's en softwareversies die zijn afgestemd op je hardware om maximale prestaties en compatibiliteit te garanderen.
- Asynchrone verwerking gebruiken: Asynchrone verwerking kan helpen om werklasten efficiënter te beheren. Gebruik asynchrone verwerkingstechnieken om meerdere inferenties tegelijk te verwerken, wat kan helpen om de belasting te verdelen en wachttijden te verminderen.
- Profileer de inferentiepijplijn: Het identificeren van knelpunten in de inferentiepijplijn kan helpen bij het vinden van de bron van vertragingen. Gebruik profiling tools om elke stap van het inferentieproces te analyseren en identificeer en pak alle stappen aan die aanzienlijke vertragingen veroorzaken, zoals inefficiënte lagen of problemen met gegevensoverdracht.
- Gebruik de juiste precisie: Het gebruik van een hogere precisie dan nodig kan de inferentietijd vertragen. Experimenteer met het gebruik van lagere precisie, zoals FP16 (halve precisie), in plaats van FP32 (volledige precisie). Hoewel FP16 de inferentietijd kan verkorten, moet je er ook rekening mee houden dat het de nauwkeurigheid van het model kan beïnvloeden.
Als je tegen dit probleem aanloopt bij het inzetten van YOLOv8, bedenk dan dat YOLOv8 verschillende modelformaten biedt, zoals YOLOv8n (nano) voor apparaten met een lagere geheugencapaciteit en YOLOv8x (extra-large) voor krachtigere GPU's. Het kiezen van de juiste modelvariant voor je hardware kan helpen bij het balanceren van geheugengebruik en verwerkingstijd.
Houd er ook rekening mee dat de grootte van de invoerafbeeldingen een directe invloed heeft op het geheugengebruik en de verwerkingstijd. Lagere resoluties verminderen het geheugengebruik en versnellen de inferentie, terwijl hogere resoluties de nauwkeurigheid verbeteren maar meer geheugen en verwerkingskracht vereisen.
Beveiligingsoverwegingen bij het implementeren van modellen
Een ander belangrijk aspect van implementatie is beveiliging. De beveiliging van je geïmplementeerde modellen is cruciaal om gevoelige gegevens en intellectueel eigendom te beschermen. Hier zijn enkele best practices die je kunt volgen met betrekking tot het veilig implementeren van modellen.
Veilige gegevensoverdracht
Het is heel belangrijk om ervoor te zorgen dat gegevens die tussen clients en servers worden verzonden veilig zijn, zodat ze niet kunnen worden onderschept of ingezien door onbevoegden. Je kunt encryptieprotocollen zoals TLS (Transport Layer Security) gebruiken om gegevens te versleutelen terwijl ze worden verzonden. Zelfs als iemand de gegevens onderschept, kunnen ze deze niet lezen. Je kunt ook end-to-end versleuteling gebruiken die de gegevens helemaal van de bron naar de bestemming beschermt, zodat niemand ertussenin bij de gegevens kan.
Toegangscontrole
Het is essentieel om te controleren wie toegang heeft tot je model en de gegevens om ongeoorloofd gebruik te voorkomen. Gebruik sterke authenticatiemethoden om de identiteit te verifiëren van gebruikers of systemen die toegang proberen te krijgen tot het model, en overweeg om extra beveiliging toe te voegen met multifactor authenticatie (MFA). Stel rolgebaseerde toegangscontrole (RBAC) in om machtigingen toe te wijzen op basis van gebruikersrollen, zodat mensen alleen toegang hebben tot wat ze nodig hebben. Houd gedetailleerde auditlogs bij om alle toegang tot en wijzigingen in het model en zijn gegevens bij te houden en bekijk deze logs regelmatig om verdachte activiteiten op te sporen.
Modelverduistering
Het beschermen van je model tegen reverse-engineering of misbruik kan worden gedaan door modelobfuscatie. Dit houdt in het versleutelen van modelparameters, zoals weights and biases in neurale netwerken, om het voor onbevoegden moeilijk te maken om het model te begrijpen of te wijzigen. Je kunt ook de architectuur van het model versluieren door lagen en parameters een andere naam te geven of dummy lagen toe te voegen, waardoor het moeilijker wordt voor aanvallers om reverse-engineering toe te passen. Je kunt het model ook serveren in een beveiligde omgeving, zoals een beveiligde enclave of met behulp van een vertrouwde uitvoeringsomgeving (TEE), wat een extra beschermingslaag kan bieden tijdens de inferentie.
Deel ideeën met je collega's
Deel uitmaken van een gemeenschap van computervisie-enthousiastelingen kan u helpen problemen op te lossen en sneller te leren. Hier zijn enkele manieren om contact te maken, hulp te krijgen en ideeën uit te wisselen.
Hulpbronnen van de Gemeenschap
- GitHub problemen: Verken de YOLOv8 GitHub repository en gebruik de Issues tab om vragen te stellen, bugs te melden en nieuwe functies voor te stellen. De gemeenschap en beheerders zijn erg actief en staan klaar om te helpen.
- Ultralytics Discord-server: Word lid van de Ultralytics Discord-server om te chatten met andere gebruikers en ontwikkelaars, ondersteuning te krijgen en je ervaringen te delen.
Officiële documentatie
- Ultralytics YOLOv8 Documentatie: Ga naar de officiële YOLOv8 documentatie voor gedetailleerde handleidingen en handige tips voor verschillende computer vision projecten.
Door deze bronnen te gebruiken, kunt u uitdagingen oplossen en op de hoogte blijven van de nieuwste trends en praktijken in de computer vision-gemeenschap.
Conclusie en volgende stappen
We hebben een aantal best practices besproken die je kunt volgen bij het implementeren van computervisiemodellen. Door gegevens te beveiligen, toegang te controleren en modeldetails te versluieren, kun je gevoelige informatie beschermen terwijl je modellen soepel blijven werken. We hebben ook besproken hoe je veelvoorkomende problemen zoals verminderde nauwkeurigheid en trage conclusies kunt aanpakken met strategieën zoals opwarm runs, het optimaliseren van engines, asynchrone verwerking, het profileren van pijplijnen en het kiezen van de juiste precisie.
Na het implementeren van je model is de volgende stap het monitoren, onderhouden en documenteren van je applicatie. Regelmatige monitoring helpt om problemen snel op te sporen en te verhelpen, onderhoud houdt je modellen up-to-date en functioneel, en goede documentatie houdt alle wijzigingen en updates bij. Deze stappen zullen je helpen om de doelen van je computer vision project te bereiken.
FAQ
Wat zijn de best practices voor het implementeren van een machine learning model met Ultralytics YOLOv8 ?
Het implementeren van een machine learning model, in het bijzonder met Ultralytics YOLOv8 , vereist verschillende best practices om efficiëntie en betrouwbaarheid te garanderen. Kies eerst de inzetomgeving die past bij je behoeften: cloud, edge of lokaal. Optimaliseer je model met technieken als snoeien, kwantificeren en kennisdestillatie voor een efficiënte inzet in omgevingen met beperkte bronnen. Zorg er ten slotte voor dat de consistentie van de gegevens en de voorbewerkingsstappen zijn afgestemd op de trainingsfase om de prestaties te behouden. Je kunt ook de opties voor modelimplementatie raadplegen voor meer gedetailleerde richtlijnen.
Hoe kan ik veelvoorkomende problemen met de implementatie van Ultralytics YOLOv8 modellen oplossen?
Het oplossen van problemen bij het uitrollen kan worden onderverdeeld in een paar belangrijke stappen. Als de nauwkeurigheid van je model afneemt na het uitrollen, controleer dan of de gegevens consistent zijn, valideer de preprocessing stappen en zorg ervoor dat de hardware/software omgeving overeenkomt met wat je tijdens de training hebt gebruikt. Voor trage inferentietijden, voer opwarm runs uit, optimaliseer je inferentie engine, gebruik asynchrone verwerking en profileer je inferentiepijplijn. Raadpleeg Problemen met de implementatie oplossen voor een gedetailleerde handleiding over deze best practices.
Hoe verbetert Ultralytics YOLOv8 optimalisatie de modelprestaties op randapparaten?
Het optimaliseren van Ultralytics YOLOv8 modellen voor randapparaten omvat het gebruik van technieken zoals snoeien om het model te verkleinen, kwantisatie om gewichten om te zetten naar lagere precisie en kennisdestillatie om kleinere modellen te trainen die grotere modellen nabootsen. Deze technieken zorgen ervoor dat het model efficiënt werkt op apparaten met beperkte rekenkracht. Tools zoals TensorFlow Lite en NVIDIA Jetson zijn bijzonder handig voor deze optimalisaties. Leer meer over deze technieken in onze sectie over modeloptimalisatie.
Wat zijn de beveiligingsoverwegingen voor het implementeren van machine-learningmodellen met Ultralytics YOLOv8 ?
Beveiliging is van het grootste belang bij het inzetten van machine learning modellen. Zorg voor een veilige gegevensoverdracht met versleutelingsprotocollen zoals TLS. Implementeer robuuste toegangscontroles, waaronder sterke authenticatie en rolgebaseerde toegangscontrole (RBAC). Modelverduisteringstechnieken, zoals het versleutelen van modelparameters en het serveren van modellen in een veilige omgeving zoals een vertrouwde uitvoeringsomgeving (TEE), bieden extra bescherming. Raadpleeg Beveiligingsoverwegingen voor meer informatie.
Hoe kies ik de juiste implementatieomgeving voor mijn Ultralytics YOLOv8 model?
Het kiezen van de optimale implementatieomgeving voor je Ultralytics YOLOv8 model hangt af van de specifieke behoeften van je applicatie. Cloudimplementatie biedt schaalbaarheid en gemakkelijke toegang, waardoor het ideaal is voor toepassingen met grote datavolumes. Edge implementatie is het beste voor applicaties met een lage latentie die real-time reacties vereisen, waarbij tools zoals TensorFlow Lite worden gebruikt. Lokale implementatie is geschikt voor scenario's die een strikte dataprivacy en -controle vereisen. Bekijk voor een uitgebreid overzicht van elke omgeving onze sectie over het kiezen van een implementatieomgeving.