Melhores Práticas para Implantação de Modelo
Introdução
A implantação de modelo é a etapa em um projeto de visão computacional que leva um modelo da fase de desenvolvimento para uma aplicação no mundo real. Existem várias opções de implantação de modelo: a implantação na nuvem oferece escalabilidade e facilidade de acesso, a implantação na borda reduz a latência ao aproximar o modelo da fonte de dados e a implantação local garante privacidade e controle. A escolha da estratégia certa depende das necessidades da sua aplicação, equilibrando velocidade, segurança e escalabilidade.
Assista: Como Otimizar e Implantar Modelos de IA: Melhores Práticas, Solução de Problemas e Considerações de Segurança
Também é importante seguir as melhores práticas ao implementar um modelo, pois a implementação pode impactar significativamente a eficácia e a confiabilidade do desempenho do modelo. Neste guia, vamos nos concentrar em como garantir que a implementação do seu modelo seja tranquila, eficiente e segura.
Opções de Implantação de Modelo
Muitas vezes, depois de um modelo ser treinado, avaliado e testado, ele precisa de ser convertido em formatos específicos para ser implementado eficazmente em vários ambientes, como cloud, edge ou dispositivos locais.
Com o YOLO26, você pode exportar seu modelo para vários formatos dependendo das suas necessidades de implantação. Por exemplo, exportar YOLO26 para ONNX é simples e ideal para transferir modelos entre frameworks. Para explorar mais opções de integração e garantir uma implantação tranquila em diferentes ambientes, visite nosso hub de integração de modelos.
Escolhendo um Ambiente de Implantação
Escolher onde implantar seu modelo de visão computacional depende de vários fatores. Diferentes ambientes têm benefícios e desafios únicos, por isso é essencial escolher aquele que melhor se adapta às suas necessidades.
Implantação na Nuvem
A implantação na nuvem é excelente para aplicações que precisam ser escaladas rapidamente e lidar com grandes quantidades de dados. Plataformas como AWS, Google Cloud e Azure facilitam o gerenciamento de seus modelos desde o treinamento até a implantação. Eles oferecem serviços como AWS SageMaker, Google AI Platform e Azure Machine Learning para ajudá-lo durante todo o processo.
No entanto, usar a nuvem pode ser caro, especialmente com alto uso de dados, e você pode enfrentar problemas de latência se seus usuários estiverem longe dos data centers. Para gerenciar custos e desempenho, é importante otimizar o uso de recursos e garantir a conformidade com as regras de privacidade de dados.
Implantação Edge
A implementação edge funciona bem para aplicações que necessitam de respostas em tempo real e baixa latência, particularmente em locais com acesso limitado ou inexistente à internet. Implementar modelos em dispositivos edge, como smartphones ou gadgets IoT, garante um processamento rápido e mantém os dados locais, o que aumenta a privacidade. A implementação em edge também economiza largura de banda devido à redução de dados enviados para a nuvem.
No entanto, os dispositivos edge geralmente têm poder de processamento limitado, então você precisará otimizar seus modelos. Ferramentas como TensorFlow Lite e NVIDIA Jetson podem ajudar. Apesar dos benefícios, manter e atualizar muitos dispositivos pode ser desafiador.
Implantação Local
A Implantação Local é melhor quando a privacidade dos dados é crítica ou quando há acesso à internet não confiável ou inexistente. Executar modelos em servidores locais ou desktops oferece controle total e mantém seus dados seguros. Também pode reduzir a latência se o servidor estiver perto do usuário.
No entanto, escalar localmente pode ser difícil e a manutenção pode ser demorada. O uso de ferramentas como Docker para conteinerização e Kubernetes para gerenciamento pode ajudar a tornar as implementações locais mais eficientes. Atualizações e manutenção regulares são necessárias para manter tudo funcionando sem problemas.
Containerização para Implantação Simplificada
A containerização é uma abordagem poderosa que empacota seu modelo e todas as suas dependências em uma unidade padronizada chamada container. Essa técnica garante um desempenho consistente em diferentes ambientes e simplifica o processo de implantação.
Benefícios de Usar o Docker para o Deploy de Modelos
O Docker se tornou o padrão da indústria para conteinerização em implementações de aprendizado de máquina por vários motivos:
- Consistência do Ambiente: Os contêineres Docker encapsulam seu modelo e todas as suas dependências, eliminando o problema de "funciona na minha máquina", garantindo um comportamento consistente entre os ambientes de desenvolvimento, teste e produção.
- Isolamento: Os contentores isolam as aplicações umas das outras, evitando conflitos entre diferentes versões de software ou bibliotecas.
- Portabilidade: Os contêineres Docker podem ser executados em qualquer sistema que suporte Docker, facilitando a implantação de seus modelos em diferentes plataformas sem modificação.
- Escalabilidade: Os contêineres podem ser facilmente escalados verticalmente ou horizontalmente com base na demanda, e ferramentas de orquestração como o Kubernetes podem automatizar esse processo.
- Controle de Versão: As imagens Docker podem ser versionadas, permitindo que você rastreie as alterações e reverta para versões anteriores, se necessário.
Implementando Docker para Implantação de YOLO26
Para conteinerizar seu modelo YOLO26, você pode criar um Dockerfile que especifica todas as dependências e configurações necessárias. Aqui está um exemplo básico:
FROM ultralytics/ultralytics:latest
WORKDIR /app
# Copy your model and any additional files
COPY ./models/yolo26.pt /app/models/
COPY ./scripts /app/scripts/
# Set up any environment variables
ENV MODEL_PATH=/app/models/yolo26.pt
# Command to run when the container starts
CMD ["python", "/app/scripts/predict.py"]
Esta abordagem garante que a implantação do seu modelo seja reproduzível e consistente em diferentes ambientes, reduzindo significativamente o problema de "funciona na minha máquina" que frequentemente afeta os processos de implantação.
Técnicas de Otimização de Modelo
Otimizar seu modelo de visão computacional ajuda a executá-lo de forma eficiente, especialmente ao implementar em ambientes com recursos limitados, como dispositivos de borda. Aqui estão algumas técnicas importantes para otimizar seu modelo.
Poda de Modelo
A poda reduz o tamanho do modelo, removendo pesos que contribuem pouco para a saída final. Isso torna o modelo menor e mais rápido, sem afetar significativamente a precisão. A poda envolve a identificação e eliminação de parâmetros desnecessários, resultando em um modelo mais leve que requer menos poder computacional. É particularmente útil para implantar modelos em dispositivos com recursos limitados.
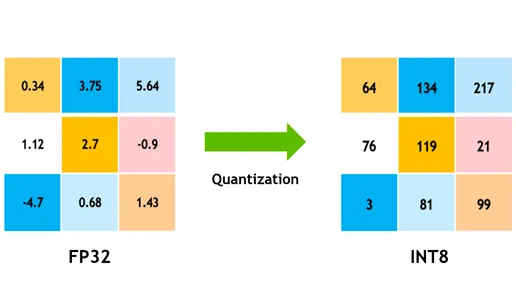
Quantização de Modelo
A quantização converte os pesos e ativações do modelo de alta precisão (como floats de 32 bits) para precisão mais baixa (como inteiros de 8 bits). Ao reduzir o tamanho do modelo, acelera a inferência. O treinamento com reconhecimento de quantização (QAT) é um método onde o modelo é treinado tendo em mente a quantização, preservando a precisão melhor do que a quantização pós-treinamento. Ao lidar com a quantização durante a fase de treinamento, o modelo aprende a se ajustar à precisão mais baixa, mantendo o desempenho e reduzindo as demandas computacionais.
Destilação de Conhecimento
A destilação de conhecimento envolve treinar um modelo menor e mais simples (o aluno) para imitar as saídas de um modelo maior e mais complexo (o professor). O modelo aluno aprende a aproximar as previsões do professor, resultando num modelo compacto que retém grande parte da precisão do professor. Esta técnica é benéfica para criar modelos eficientes adequados para implementação em dispositivos edge com recursos limitados.
Solução de Problemas de Implantação
Você pode enfrentar desafios ao implementar seus modelos de visão computacional, mas entender os problemas e soluções comuns pode tornar o processo mais tranquilo. Aqui estão algumas dicas gerais de solução de problemas e práticas recomendadas para ajudá-lo a lidar com problemas de implementação.
Seu modelo está menos preciso após a implementação
Experimentar uma queda na precisão do seu modelo após a implementação pode ser frustrante. Este problema pode resultar de vários fatores. Aqui estão alguns passos para ajudá-lo a identificar e resolver o problema:
- Verifique a Consistência dos Dados: Verifique se os dados que seu modelo está processando após a implantação são consistentes com os dados com os quais foi treinado. Diferenças na distribuição, qualidade ou formato dos dados podem impactar significativamente o desempenho.
- Valide as Etapas de Pré-processamento: Verifique se todas as etapas de pré-processamento aplicadas durante o treinamento também são aplicadas consistentemente durante a implantação. Isso inclui redimensionar imagens, normalizar valores de pixel e outras transformações de dados.
- Avalie o Ambiente do Modelo: Garanta que as configurações de hardware e software usadas durante a implantação correspondam às usadas durante o treinamento. Diferenças em bibliotecas, versões e capacidades de hardware podem introduzir discrepâncias.
- Monitorar a Inferência do Modelo: Registre as entradas e saídas em vários estágios do pipeline de inferência para detectar quaisquer anomalias. Isso pode ajudar a identificar problemas como corrupção de dados ou manuseio inadequado das saídas do modelo.
- Revisar a Exportação e Conversão do Modelo: Reexporte o modelo e certifique-se de que o processo de conversão mantém a integridade dos pesos e da arquitetura do modelo.
- Teste com um Conjunto de Dados Controlado: Implante o modelo em um ambiente de teste com um conjunto de dados que você controla e compare os resultados com a fase de treinamento. Você pode identificar se o problema está no ambiente de implantação ou nos dados.
Ao implantar o YOLO26, vários fatores podem afetar a precisão do modelo. A conversão de modelos para formatos como TensorRT envolve otimizações como quantização de pesos e fusão de camadas, o que pode causar pequenas perdas de precisão. Usar FP16 (meia precisão) em vez de FP32 (precisão total) pode acelerar a inferência, mas pode introduzir erros de precisão numérica. Além disso, restrições de hardware, como as do Jetson Nano, com menor número de núcleos CUDA e largura de banda de memória reduzida, podem impactar o desempenho.
As Inferências Estão Demorando Mais do Que o Esperado
Ao implementar modelos de machine learning, é importante que eles sejam executados de forma eficiente. Se as inferências demorarem mais do que o esperado, isso pode afetar a experiência do usuário e a eficácia de sua aplicação. Aqui estão alguns passos para ajudá-lo a identificar e resolver o problema:
- Implemente Execuções de Aquecimento: As execuções iniciais frequentemente incluem sobrecarga de configuração, o que pode distorcer as medições de latência. Realize algumas inferências de aquecimento antes de medir a latência. Excluir essas execuções iniciais fornece uma medição mais precisa do desempenho do modelo.
- Otimize o Mecanismo de Inferência: Verifique se o mecanismo de inferência está totalmente otimizado para sua arquitetura de GPU específica. Use os drivers e as versões de software mais recentes, adaptados ao seu hardware, para garantir o máximo desempenho e compatibilidade.
- Use Processamento Assíncrono: O processamento assíncrono pode ajudar a gerenciar as cargas de trabalho de forma mais eficiente. Use técnicas de processamento assíncrono para lidar com várias inferências simultaneamente, o que pode ajudar a distribuir a carga e reduzir os tempos de espera.
- Perfilar o Pipeline de Inferência: Identificar gargalos no pipeline de inferência pode ajudar a identificar a origem dos atrasos. Use ferramentas de criação de perfil para analisar cada etapa do processo de inferência, identificando e abordando quaisquer estágios que causem atrasos significativos, como camadas ineficientes ou problemas de transferência de dados.
- Use a Precisão Adequada: Usar uma precisão maior do que o necessário pode diminuir os tempos de inferência. Experimente usar uma precisão mais baixa, como FP16 (meia precisão), em vez de FP32 (precisão total). Embora o FP16 possa reduzir o tempo de inferência, tenha em mente que ele também pode afetar a precisão do modelo.
Se você estiver enfrentando este problema ao implantar o YOLO26, considere que o YOLO26 oferece vários tamanhos de modelo, como YOLO26n (nano) para dispositivos com menor capacidade de memória e YOLO26x (extra-grande) para GPUs mais potentes. Escolher a variante de modelo correta para o seu hardware pode ajudar a equilibrar o uso da memória e o tempo de processamento.
Além disso, tenha em mente que o tamanho das imagens de entrada impacta diretamente o uso de memória e o tempo de processamento. Resoluções mais baixas reduzem o uso de memória e aceleram a inferência, enquanto resoluções mais altas melhoram a precisão, mas exigem mais memória e poder de processamento.
Considerações de Segurança na Implantação de Modelos
Outro aspeto importante da implementação é a segurança. A segurança dos seus modelos implementados é fundamental para proteger dados confidenciais e propriedade intelectual. Aqui estão algumas práticas recomendadas que você pode seguir relacionadas à implementação segura de modelos.
Transmissão Segura de Dados
Garantir que os dados enviados entre clientes e servidores estejam seguros é muito importante para evitar que sejam interceptados ou acedidos por partes não autorizadas. Pode usar protocolos de encriptação como o TLS (Transport Layer Security) para encriptar os dados enquanto estão a ser transmitidos. Mesmo que alguém intercete os dados, não conseguirá lê-los. Também pode usar a encriptação ponto a ponto que protege os dados desde a origem até ao destino, para que ninguém no meio consiga aceder a eles.
Controles de Acesso
É essencial controlar quem pode acessar seu modelo e seus dados para evitar o uso não autorizado. Use métodos de autenticação fortes para verificar a identidade de usuários ou sistemas que tentam acessar o modelo e considere adicionar segurança extra com a autenticação multifator (MFA). Configure o controle de acesso baseado em função (RBAC) para atribuir permissões com base nas funções do usuário, para que as pessoas só tenham acesso ao que precisam. Mantenha logs de auditoria detalhados para rastrear todo o acesso e alterações no modelo e seus dados e revise regularmente esses logs para identificar qualquer atividade suspeita.
Ofuscação de Modelo
A proteção do seu modelo contra engenharia reversa ou uso indevido pode ser feita através da ofuscação do modelo. Isso envolve a criptografia dos parâmetros do modelo, como pesos e biases em redes neurais, para dificultar que indivíduos não autorizados compreendam ou alterem o modelo. Você também pode ofuscar a arquitetura do modelo, renomeando camadas e parâmetros ou adicionando camadas fictícias, tornando mais difícil para os invasores fazerem engenharia reversa. Você também pode servir o modelo em um ambiente seguro, como um enclave seguro ou usando um ambiente de execução confiável (TEE), pode fornecer uma camada extra de proteção durante a inferência.
Compartilhe Ideias com Seus Colegas
Fazer parte de uma comunidade de entusiastas de visão computacional pode ajudá-lo a resolver problemas e aprender mais rápido. Aqui estão algumas maneiras de se conectar, obter ajuda e compartilhar ideias.
Recursos da Comunidade
- Problemas no GitHub: Explore o repositório YOLO26 no GitHub e use a aba Issues para fazer perguntas, relatar bugs e sugerir novos recursos. A comunidade e os mantenedores são muito ativos e estão prontos para ajudar.
- Servidor Ultralytics Discord: Junte-se ao servidor Ultralytics Discord para conversar com outros usuários e desenvolvedores, obter suporte e compartilhar suas experiências.
Documentação Oficial
- Documentação Ultralytics YOLO26: Visite a documentação oficial do YOLO26 para guias detalhados e dicas úteis sobre vários projetos de visão computacional.
Usar esses recursos ajudará você a resolver desafios e a se manter atualizado com as últimas tendências e práticas na comunidade de visão computacional.
Conclusão e Próximos Passos
Analisamos algumas das melhores práticas a serem seguidas ao implementar modelos de visão computacional. Ao proteger os dados, controlar o acesso e obscurecer os detalhes do modelo, você pode proteger informações confidenciais, mantendo seus modelos funcionando sem problemas. Também discutimos como resolver problemas comuns, como precisão reduzida e inferências lentas, usando estratégias como execuções de aquecimento, otimização de engines, processamento assíncrono, pipelines de criação de perfil e escolha da precisão certa.
Após implantar seu modelo, o próximo passo seria monitorar, manter e documentar sua aplicação. O monitoramento regular ajuda a detectar e corrigir problemas rapidamente, a manutenção mantém seus modelos atualizados e funcionais, e uma boa documentação rastreia todas as mudanças e atualizações. Esses passos ajudarão você a alcançar os objetivos do seu projeto de visão computacional.
FAQ
Quais são as melhores práticas para implantar um modelo de machine learning usando Ultralytics YOLO26?
A implantação de um modelo de machine learning, particularmente com Ultralytics YOLO26, envolve várias boas práticas para garantir eficiência e confiabilidade. Primeiro, escolha o ambiente de implantação que melhor se adapta às suas necessidades — nuvem, edge ou local. Otimize seu modelo através de técnicas como poda (pruning), quantização e destilação de conhecimento para uma implantação eficiente em ambientes com recursos limitados. Considere usar a conteinerização com Docker para garantir a consistência em diferentes ambientes. Por fim, garanta que a consistência dos dados e as etapas de pré-processamento estejam alinhadas com a fase de treinamento para manter o desempenho. Você também pode consultar as opções de implantação de modelos para diretrizes mais detalhadas.
Como posso resolver problemas comuns de implantação com modelos Ultralytics YOLO26?
A solução de problemas de implantação pode ser dividida em algumas etapas principais. Se a precisão do seu modelo diminuir após a implantação, verifique a consistência dos dados, valide as etapas de pré-processamento e certifique-se de que o ambiente de hardware/software corresponda ao que você usou durante o treinamento. Para tempos de inferência lentos, execute execuções de aquecimento, otimize seu mecanismo de inferência, use processamento assíncrono e crie um perfil de seu pipeline de inferência. Consulte solução de problemas de implantação para obter um guia detalhado sobre essas práticas recomendadas.
Como a otimização do Ultralytics YOLO26 melhora o desempenho do modelo em dispositivos edge?
A otimização de modelos Ultralytics YOLO26 para dispositivos edge envolve o uso de técnicas como poda (pruning) para reduzir o tamanho do modelo, quantização para converter pesos para menor precisão e destilação de conhecimento para treinar modelos menores que mimetizam os maiores. Essas técnicas garantem que o modelo seja executado eficientemente em dispositivos com poder computacional limitado. Ferramentas como TensorFlow Lite e NVIDIA Jetson são particularmente úteis para essas otimizações. Saiba mais sobre essas técnicas em nossa seção sobre otimização de modelos.
Quais são as considerações de segurança para implantar modelos de machine learning com Ultralytics YOLO26?
A segurança é fundamental ao implantar modelos de machine learning. Garanta a transmissão segura de dados usando protocolos de criptografia como TLS. Implemente controles de acesso robustos, incluindo autenticação forte e controle de acesso baseado em função (RBAC). Técnicas de ofuscação de modelo, como criptografar parâmetros do modelo e servir modelos em um ambiente seguro como um ambiente de execução confiável (TEE), oferecem proteção adicional. Para práticas detalhadas, consulte as considerações de segurança.
Como escolho o ambiente de implantação certo para o meu modelo Ultralytics YOLO26?
A seleção do ambiente de implantação ideal para o seu modelo Ultralytics YOLO26 depende das necessidades específicas da sua aplicação. A implantação em nuvem oferece escalabilidade e facilidade de acesso, tornando-a ideal para aplicações com grandes volumes de dados. A implantação em edge é melhor para aplicações de baixa latência que exigem respostas em tempo real, utilizando ferramentas como TensorFlow Lite. A implantação local é adequada para cenários que exigem rigorosa privacidade e controle de dados. Para uma visão geral abrangente de cada ambiente, consulte nossa seção sobre como escolher um ambiente de implantação.




