Link to this sectionUltralytics YOLO26#
Link to this sectionVisão geral#
O Ultralytics YOLO26 é uma família unificada de modelos de visão em tempo real descrita no artigo do Ultralytics YOLO26. Ele introduz inferência nativa de ponta a ponta, uma cabeça de detecção mais leve, uma receita de treinamento atualizada e cabeças específicas para tarefas de detecção, segmentação, estimativa de pose, classificação e detecção orientada.
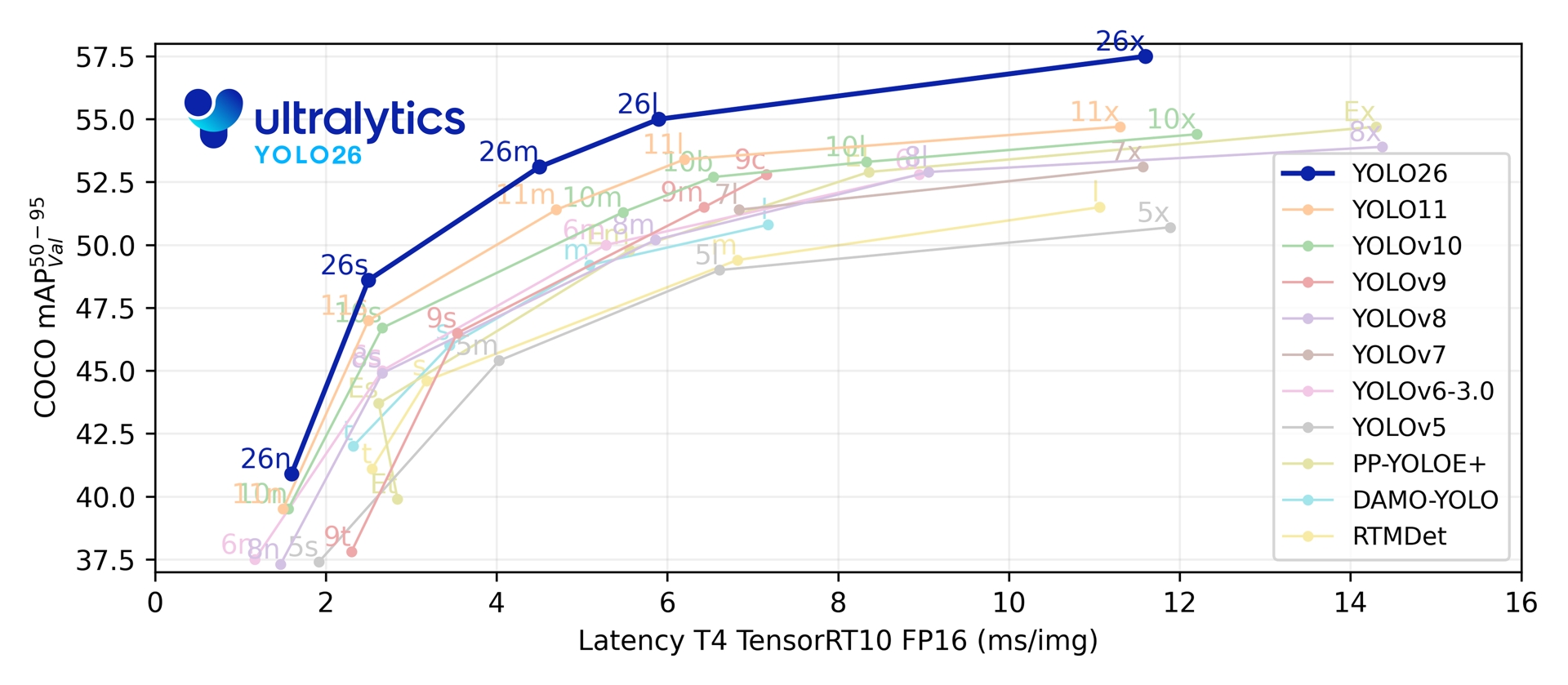
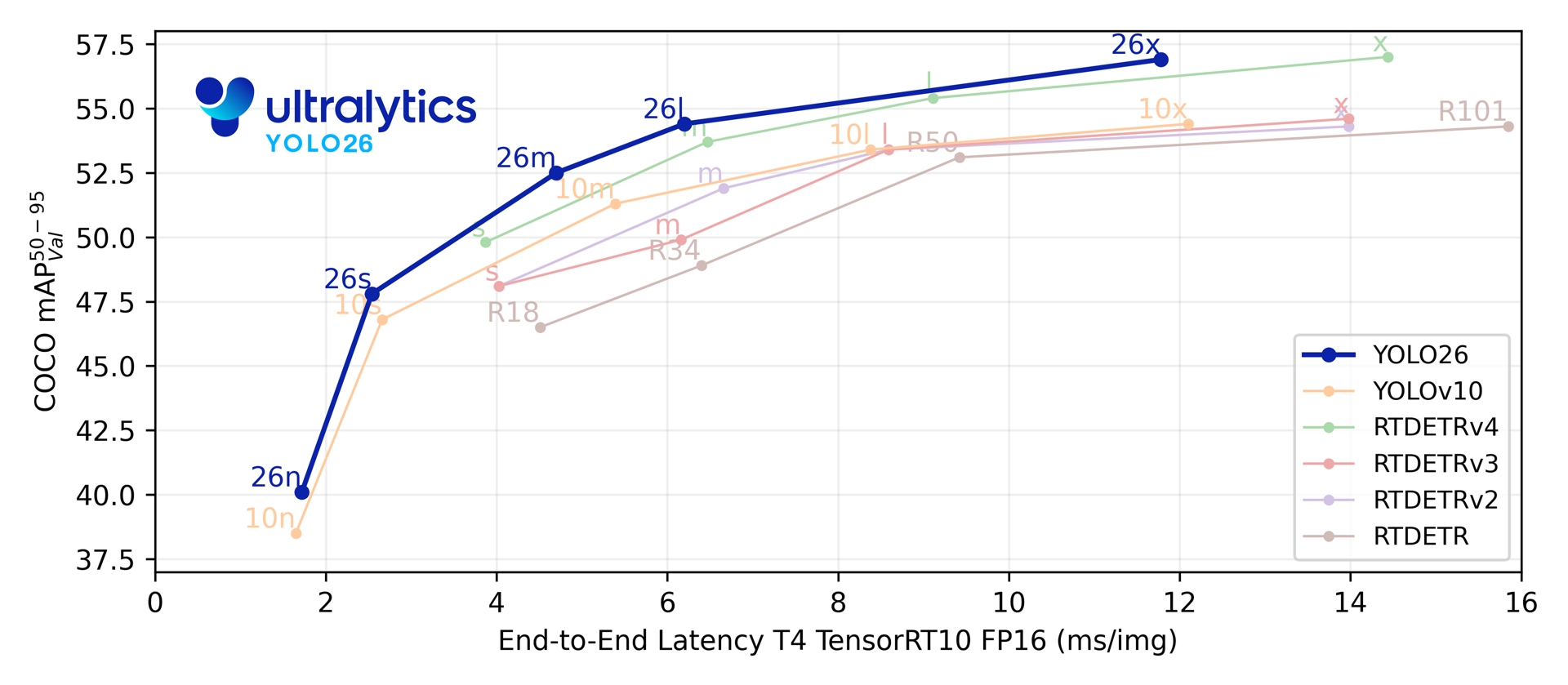
Em suas cinco escalas de detecção, o YOLO26 atinge 40,9-57,5 mAP no COCO com 1,7-11,8 ms de latência T4 TensorRT. O artigo também relata inferência CPU ONNX até 43% mais rápida para o YOLO26n em comparação com o YOLO11n em uma CPU Intel Xeon @ 2.00 GHz.
from ultralytics import YOLO
model = YOLO("yolo26n.pt") # load a pretrained YOLO26n model
results = model("path/to/bus.jpg") # run inferenceExplora e executa modelos YOLO26 diretamente na Ultralytics Platform.
A família de modelos YOLO26 é construída em torno de quatro áreas de design:
- Inferência nativa de ponta a ponta: A cabeça de detecção padrão um-para-um produz previsões sem a supressão de não-máximos (NMS), simplificando a implementação e reduzindo o pós-processamento.
- Regressão de caixa mais leve: O YOLO26 remove a Distribution Focal Loss (DFL), reduzindo a complexidade da cabeça de detecção enquanto preserva uma faixa de regressão irrestrita.
- Atualizações da receita de treinamento: O pipeline de treinamento combina MuSGD (um otimizador híbrido Muon + SGD), Progressive Loss e STAL (Small-Target-Aware Label Assignment) para melhorar a otimização, deslocar a supervisão em direção à head de tempo de inferência e manter a cobertura de rótulos positivos para objetos pequenos. Os hiperparâmetros completos por trás dos checkpoints lançados estão documentados no guia da Receita de Treinamento do YOLO26.
- Cabeças e perdas específicas para tarefas: O YOLO26 adiciona designs direcionados para segmentação de instâncias, variantes de segmentação semântica, estimativa de pose e detecção orientada, mantendo um pipeline de modelo único entre as tarefas.
Juntas, essas atualizações melhoram o equilíbrio entre precisão e latência em todas as escalas de modelo e alvos de implementação.
Link to this sectionPrincipais recursos#
-
Regressão livre de DFL O YOLO26 remove a Distribution Focal Loss (DFL), reduzindo a complexidade da cabeça de detecção e simplificando a exportação.
-
Inferência de ponta a ponta sem NMS Ao contrário dos detectores tradicionais que dependem de NMS como uma etapa separada de pós-processamento, o YOLO26 é nativamente de ponta a ponta por padrão. As previsões são geradas diretamente, reduzindo a latência e tornando a integração em produção mais simples.
-
Progressive Loss + STAL A Progressive Loss desloca a ênfase do treinamento para a cabeça de tempo de inferência, enquanto o STAL melhora a cobertura de rótulos positivos para objetos pequenos.
-
Otimizador MuSGD Um otimizador híbrido que combina SGD com Muon, adaptando ideias de otimização do treinamento de modelos de linguagem de grande escala para a visão computacional.
-
Implementação eficiente A cabeça simplificada e o caminho padrão sem NMS reduzem a sobrecarga de inferência em todos os alvos de exportação e perfis de hardware, incluindo o ganho de velocidade em CPU ONNX relatado no artigo para o YOLO26n versus o YOLO11n.
-
Melhorias na segmentação de instâncias Introduz a perda de segmentação semântica para melhorar a convergência do modelo e um módulo proto atualizado que aproveita informações multiescala para uma qualidade de máscara superior. O artigo relata ganhos em relação ao YOLO11 de até +2,5 AP de caixa e +3,7 AP de máscara na segmentação de instâncias do COCO.
-
Estimativa de pose de precisão Integra Residual Log-Likelihood Estimation (RLE) para uma localização de pontos-chave mais precisa e otimiza o processo de decodificação para aumentar a velocidade de inferência. O artigo relata até +7,2 AP em relação ao YOLO11 na estimativa de pose do COCO.
-
Decodificação de OBB refinada Introduz uma perda de ângulo especializada para melhorar a precisão da detecção para objetos em formato quadrado e otimiza a decodificação de OBB para resolver problemas de descontinuidade de limite. O artigo relata até +3,4 mAP em relação ao YOLO11 na detecção orientada DOTA-v1.0.
Link to this sectionTarefas e modos suportados#
O YOLO26 suporta o conjunto de tarefas padrão do Ultralytics em cinco escalas de modelo:
| Modelo | Nomes de arquivo | Tarefa | Inferência | Validação | Treinamento | Exportar |
|---|---|---|---|---|---|---|
| YOLO26 | yolo26n.pt yolo26s.pt yolo26m.pt yolo26l.pt yolo26x.pt | Detecção | ✅ | ✅ | ✅ | ✅ |
| YOLO26-seg | yolo26n-seg.pt yolo26s-seg.pt yolo26m-seg.pt yolo26l-seg.pt yolo26x-seg.pt | Segmentação de instâncias | ✅ | ✅ | ✅ | ✅ |
| YOLO26-sem | yolo26n-sem.pt yolo26s-sem.pt yolo26m-sem.pt yolo26l-sem.pt yolo26x-sem.pt | Segmentação semântica | ✅ | ✅ | ✅ | ✅ |
| YOLO26-pose | yolo26n-pose.pt yolo26s-pose.pt yolo26m-pose.pt yolo26l-pose.pt yolo26x-pose.pt | Pose/Pontos-chave | ✅ | ✅ | ✅ | ✅ |
| YOLO26-obb | yolo26n-obb.pt yolo26s-obb.pt yolo26m-obb.pt yolo26l-obb.pt yolo26x-obb.pt | Detecção orientada | ✅ | ✅ | ✅ | ✅ |
| YOLO26-cls | yolo26n-cls.pt yolo26s-cls.pt yolo26m-cls.pt yolo26l-cls.pt yolo26x-cls.pt | Classificação | ✅ | ✅ | ✅ | ✅ |
Esta estrutura unificada abrange detecção em tempo real, segmentação de instâncias, segmentação semântica, classificação, estimativa de pose e detecção de objetos orientados, com suporte para treinamento, validação, inferência e exportação.
yolo26-p2.yaml e yolo26-p6.yaml adicionam uma cabeça de detecção P2 (objetos pequenos) ou P6 (entrada grande) e são fornecidos apenas como arquiteturas YAML. Não há pesos específicos de escala yolo26*-p2.pt ou yolo26*-p6.pt lançados. Instancia uma configuração escalada a partir de YAML (por exemplo, YOLO("yolo26n-p6.yaml")) e treina ou ajusta conforme necessário.
Link to this sectionMétricas de desempenho#
Consulta a Documentação de detecção para ver exemplos de uso com esses modelos treinados no COCO, que incluem 80 classes pré-treinadas.
| Modelo | tamanho (pixels) | mAPval 50-95 | mAPval 50-95(e2e) | Velocidade CPU ONNX (ms) | Velocidade T4 TensorRT10 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO26n | 640 | 40,9 | 40,1 | 38,9 ± 0,7 | 1,7 ± 0,0 | 2,4 | 5,4 |
| YOLO26s | 640 | 48,6 | 47,8 | 87,2 ± 0,9 | 2,5 ± 0,0 | 9,5 | 20,7 |
| YOLO26m | 640 | 53,1 | 52,5 | 220,0 ± 1,4 | 4,7 ± 0,1 | 20,4 | 68,2 |
| YOLO26l | 640 | 55,0 | 54,4 | 286,2 ± 2,0 | 6,2 ± 0,2 | 24,8 | 86,4 |
| YOLO26x | 640 | 57,5 | 56,9 | 525,8 ± 4,0 | 11,8 ± 0,2 | 55,7 | 193,9 |
Os valores de Params e FLOPs são para o modelo fundido após model.fuse(), que combina as camadas Conv e BatchNorm e remove a cabeça de detecção auxiliar um-para-muitos. Os checkpoints pré-treinados retêm a arquitetura de treinamento completa e podem mostrar contagens mais altas.
Link to this sectionExemplos de uso#
Esta seção fornece exemplos simples de treinamento e inferência com YOLO26. Para a documentação completa sobre estes e outros modos, consulta as páginas de documentação de Predição, Treinamento, Validação e Exportação.
Observa que o exemplo abaixo é para modelos de Detecção YOLO26 para detecção de objetos. Para outras tarefas suportadas, consulta a documentação de Segmentação, Segmentação Semântica, Classificação, OBB e Pose.
Modelos pré-treinados PyTorch *.pt, bem como arquivos de configuração *.yaml, podem ser passados para a classe YOLO() para criar uma instância de modelo em Python:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Run inference with the YOLO26n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)Os modelos de detecção YOLO26 usam uma arquitetura de cabeça dupla que proporciona flexibilidade para diferentes cenários de implantação:
- Cabeça Um-para-Um (Padrão): Produz previsões de ponta a ponta (end-to-end) sem NMS, gerando
(N, 300, 6)com um máximo de 300 detecções por imagem. Esta cabeça é otimizada para inferência rápida e implantação simplificada. - Cabeça Um-para-Muitos: Gera saídas YOLO tradicionais que requerem pós-processamento NMS, gerando
(N, nc + 4, 8400)ondencé o número de classes. Esta cabeça geralmente atinge uma precisão ligeiramente maior ao custo de processamento adicional.
Podes alternar entre cabeças durante a exportação, predição ou validação:
from ultralytics import YOLO
model = YOLO("yolo26n.pt")
# Use one-to-one head (default, no NMS required)
results = model.predict("image.jpg") # inference
metrics = model.val(data="coco.yaml") # validation
model.export(format="onnx") # export
# Use one-to-many head (requires NMS)
results = model.predict("image.jpg", end2end=False) # inference
metrics = model.val(data="coco.yaml", end2end=False) # validation
model.export(format="onnx", end2end=False) # exportA escolha depende dos teus requisitos de implantação: usa a cabeça um-para-um para máxima velocidade e simplicidade, ou a cabeça um-para-muitos quando a precisão for a prioridade máxima.
Link to this sectionYOLOE-26: Detecção e Segmentação de Vocabulário Aberto#
O YOLO26 também potencializa o YOLOE-26, uma variante de vocabulário aberto que detecta e segmenta categorias de objetos a partir de prompts de texto, prompts visuais ou um modo sem prompt em vez de uma lista de classes fixa aprendida no momento do treinamento. O YOLOE-26 mantém o design NMS-free e end-to-end (e2e) do YOLO26, para que a inferência de vocabulário aberto permaneça rápida o suficiente para ambientes dinâmicos onde as categorias alvo mudam com o tempo. O YOLOE-26x alcança 40.6 AP no LVIS minival sob prompting de texto, 38.5 AP sob prompting visual e 31.1 AP na configuração Non-E2E sem prompt.
Veja a documentação do YOLOE para tabelas de desempenho por escala, variantes sem prompt e exemplos de uso completos.
Link to this sectionCitações e Agradecimentos#
Para uma descrição técnica completa da arquitetura YOLO26, receita de treinamento, cabeças de tarefa e a extensão de vocabulário aberto YOLOE-26, leia Ultralytics YOLO26: Modelos de Visão de Fim a Fim em Tempo Real Unificados. Se usares o YOLO26 em tua pesquisa, por favor, cite:
@misc{jocher2026ultralyticsyolo26unifiedrealtime,
title = {Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models},
author = {Glenn Jocher and Jing Qiu and Mengyu Liu and Shuai Lyu and Fatih Cagatay Akyon and Muhammet Esat Kalfaoglu},
year = {2026},
eprint = {2606.03748},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
doi = {10.48550/arXiv.2606.03748},
url = {https://arxiv.org/abs/2606.03748},
}O código, os modelos e a documentação do YOLO26 estão disponíveis no repositório GitHub da Ultralytics e no Ultralytics Docs sob as licenças AGPL-3.0 e Enterprise.
Link to this sectionFAQ#
Link to this sectionQuais são as principais melhorias no YOLO26?#
- Regressão sem DFL: Simplifica a cabeça de detecção e o caminho de exportação
- Inferência de fim a fim sem NMS: Remove o NMS do caminho de inferência padrão
- Progressive Loss + STAL: Melhora o alinhamento de treinamento e a cobertura de rótulos para objetos pequenos
- Otimizador MuSGD: Combina SGD com otimização inspirada em Muon para um treinamento estável
- Cabeças e perdas específicas de tarefa: Melhora o suporte para segmentação, pose e detecção orientada
Link to this sectionQuais tarefas o YOLO26 suporta?#
O YOLO26 é uma família de modelos unificada, oferecendo suporte de fim a fim para múltiplas tarefas de visão computacional:
- Detecção de Objetos
- Segmentação de instâncias
- Segmentação semântica
- Classificação de Imagem
- Estimativa de Pose
- Detecção de Objetos Orientados (OBB)
Cada variante de tamanho (n, s, m, l, x) suporta todas as tarefas, além de versões de vocabulário aberto via YOLOE-26.
Link to this sectionPor que o YOLO26 é eficiente para implantação?#
O YOLO26 melhora a eficiência da implantação com:
- Inferência ponta a ponta nativa sem NMS por padrão
- Regressão sem DFL e uma head de detecção mais leve
- Exportação de modelo fundido que remove componentes auxiliares apenas de treinamento
- Até 43% mais rápida inferência ONNX em CPU para YOLO26n em comparação ao YOLO11n em um Intel Xeon CPU @ 2.00 GHz
- Formatos de exportação flexíveis, incluindo TensorRT, ONNX, CoreML, LiteRT e OpenVINO
Link to this sectionComo posso começar a usar o YOLO26?#
Os modelos YOLO26 estão disponíveis para download através do pacote ultralytics. Instale ou atualize o pacote e carregue um modelo:
from ultralytics import YOLO
# Load a pretrained YOLO26 nano model
model = YOLO("yolo26n.pt")
# Run inference on an image
results = model("image.jpg")Veja a seção Exemplos de Uso para instruções de treinamento, validação e exportação.