Link to this sectionSAM 3: Segment Anything with Concepts#
O SAM 3 está totalmente integrado ao pacote Ultralytics a partir da versão 8.3.237 (PR #22897). Instala ou atualiza com pip install -U ultralytics para acederes a todas as funcionalidades do SAM 3, incluindo segmentação de conceitos baseada em texto, exemplos de imagem e seguimento de vídeo.
SAM 3 (Segment Anything Model 3) é o modelo base lançado pela Meta para Promptable Concept Segmentation (PCS). Construído sobre o SAM 2, o SAM 3 introduz uma capacidade fundamentalmente nova: detetar, segmentar e seguir todas as instâncias de um conceito visual especificado por prompts de texto, exemplos de imagem ou ambos. Ao contrário das versões anteriores do SAM que segmentam objetos únicos por prompt, o SAM 3 consegue encontrar e segmentar todas as ocorrências de um conceito que apareçam em imagens ou vídeos, alinhando-se com os objetivos de vocabulário aberto na segmentação de instâncias moderna.
Watch: How to Use Meta Segment Anything 3 with Ultralytics | Text-Prompt Segmentation on Images & Videos
O SAM 3 está agora totalmente integrado no pacote ultralytics, fornecendo suporte nativo para segmentação de conceitos com prompts de texto, prompts de exemplos de imagem e capacidades de seguimento de vídeo.
Link to this sectionVisão geral#
O SAM 3 alcança um ganho de desempenho de 2× em relação aos sistemas existentes em Promptable Concept Segmentation, mantendo e melhorando as capacidades do SAM 2 para segmentação visual interativa. O modelo destaca-se na segmentação de vocabulário aberto, permitindo aos utilizadores especificar conceitos usando frases nominais simples (por exemplo, "autocarro escolar amarelo", "gato tigrado") ou fornecendo exemplos de imagens do objeto alvo. Estas capacidades complementam pipelines prontos para produção que dependem de fluxos de trabalho simplificados de predict e track.
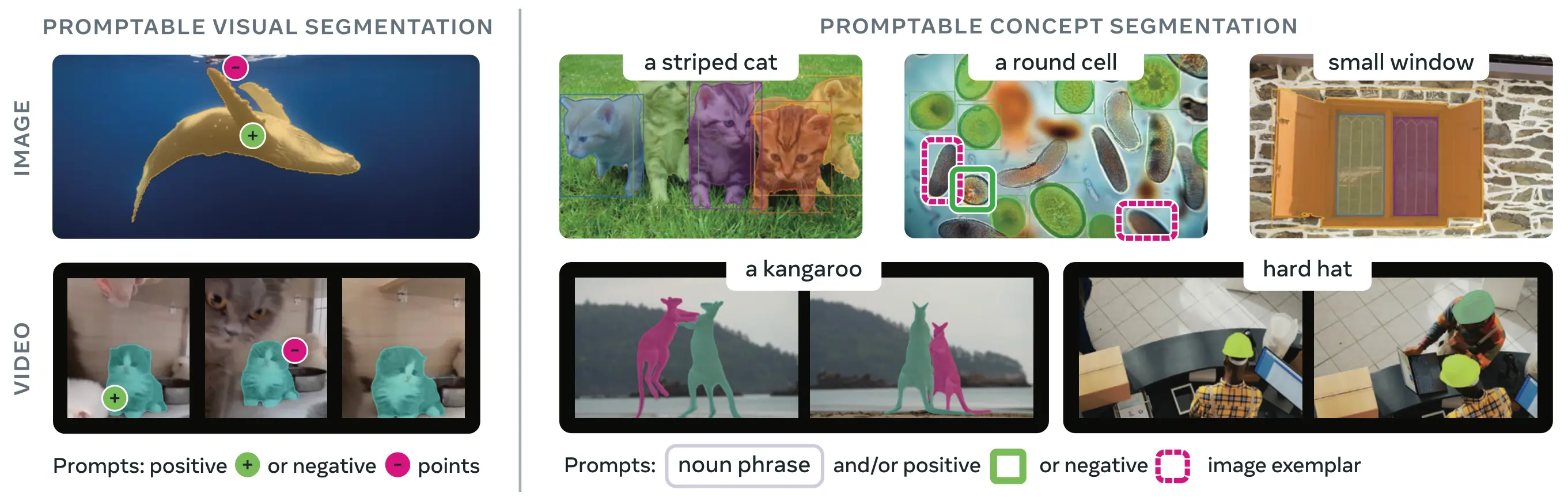
Link to this sectionO que é Promptable Concept Segmentation (PCS)?#
A tarefa PCS recebe um prompt de conceito como entrada e devolve máscaras de segmentação com identidades únicas para todas as instâncias de objetos correspondentes. Os prompts de conceito podem ser:
- Texto: Frases nominais simples como "maçã vermelha" ou "pessoa a usar um chapéu", semelhante à zero-shot learning
- Exemplos de imagem: Caixas delimitadoras em torno de objetos exemplo (positivos ou negativos) para uma generalização rápida
- Combinado: Ambos, texto e exemplos de imagem, para um controlo preciso
Isto difere dos prompts visuais tradicionais (pontos, caixas, máscaras) que segmentam apenas uma instância de objeto específica, como popularizado pela família SAM original.
Link to this sectionPrincipais Métricas de Desempenho#
| Métrica | Conquista do SAM 3 |
|---|---|
| LVIS Zero-Shot Mask AP | 47.0 (vs o melhor anterior 38.5, +22% de melhoria) |
| Benchmark SA-Co | 2× melhor que os sistemas existentes |
| Velocidade de Inferência (GPU H200) | 30 ms por imagem com mais de 100 objetos detetados |
| Desempenho em Vídeo | Próximo do tempo real para ~5 objetos simultâneos |
| Benchmark MOSEv2 VOS | 60.1 J&F (+25.5% sobre o SAM 2.1, +17% sobre o SOTA anterior) |
| Refinamento Interativo | Melhoria de +18.6 CGF1 após 3 prompts de exemplo |
| Lacuna de Desempenho Humano | Alcança 88% do limite inferior estimado no SA-Co/Gold |
Para contexto sobre métricas de modelo e compromissos em produção, consulta model evaluation insights e YOLO performance metrics.
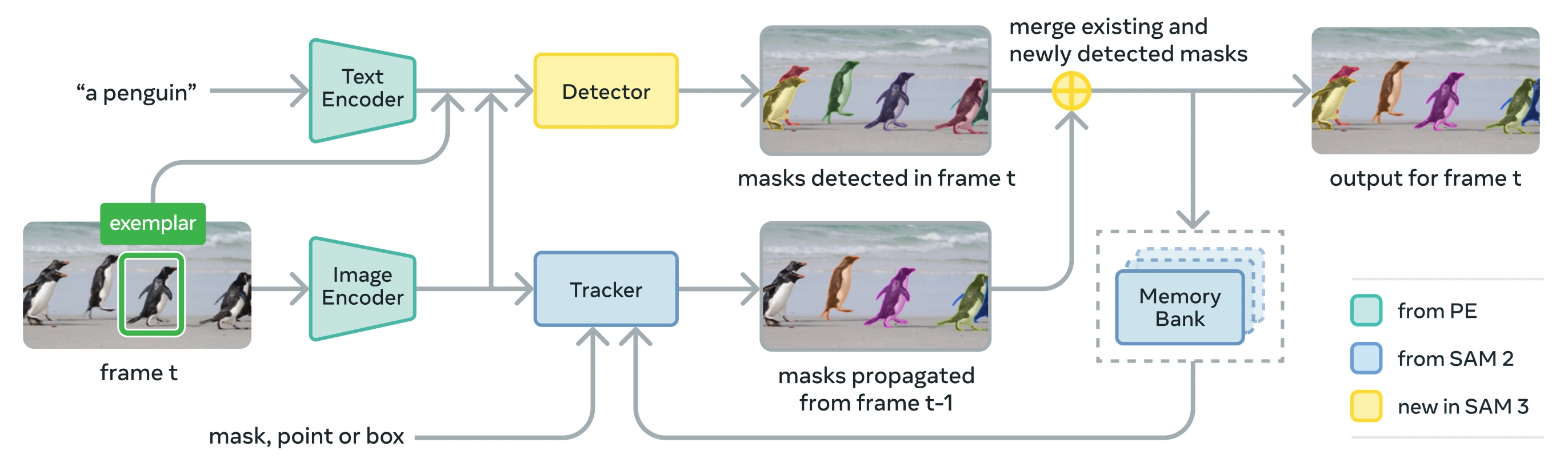
Link to this sectionArquitetura#
O SAM 3 consiste num detetor e seguidor que partilham uma backbone de visão Perception Encoder (PE). Este design desacoplado evita conflitos de tarefas ao mesmo tempo que permite a deteção ao nível da imagem e o seguimento ao nível do vídeo, com uma interface compatível com o uso em Python e o uso em CLI do Ultralytics.
Link to this sectionComponentes Principais#
-
Detetor: Arquitetura baseada em DETR para deteção de conceitos ao nível da imagem
- Codificador de texto para prompts de frases nominais
- Codificador de exemplos para prompts baseados em imagem
- Codificador de fusão para condicionar características da imagem aos prompts
- Nova cabeça de presença (presence head) que desacopla o reconhecimento ("o quê") da localização ("onde")
- Cabeça de máscara para gerar máscaras de segmentação de instâncias
-
Seguidor: Segmentação de vídeo baseada em memória herdada do SAM 2
- Codificador de prompt, descodificador de máscara, codificador de memória
- Banco de memória para armazenar a aparência do objeto ao longo dos fotogramas
- Desambiguação temporal auxiliada por técnicas como um filtro de Kalman em cenários com múltiplos objetos
-
Token de Presença: Um token global aprendido que prevê se o conceito alvo está presente na imagem/fotograma, melhorando a deteção ao separar o reconhecimento da localização.
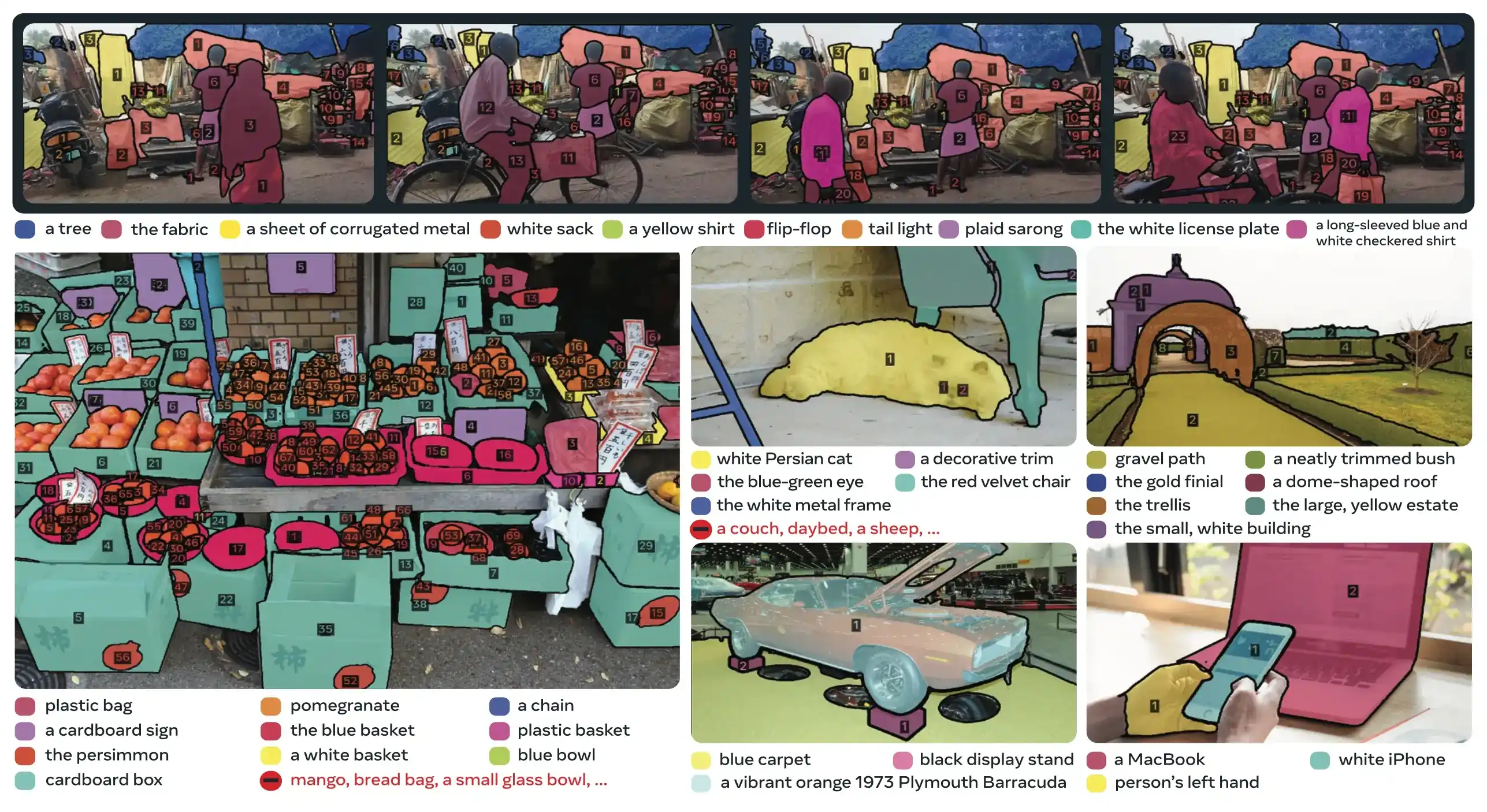
Link to this sectionPrincipais Inovações#
- Reconhecimento e Localização Desacoplados: A cabeça de presença prevê a presença do conceito globalmente, enquanto as consultas de proposta focam-se apenas na localização, evitando objetivos conflitantes.
- Prompts Visuais e de Conceito Unificados: Suporta tanto PCS (prompts de conceito) como PVS (prompts visuais como os cliques/caixas do SAM 2) num único modelo.
- Refinamento Interativo de Exemplos: Os utilizadores podem adicionar exemplos de imagem positivos ou negativos para refinar os resultados iterativamente, com o modelo a generalizar para objetos semelhantes em vez de apenas corrigir instâncias individuais.
- Desambiguação Temporal: Usa pontuações de deteção de masklet e re-prompting periódico para lidar com oclusões, cenas lotadas e falhas de seguimento em vídeo, alinhando-se com as melhores práticas de segmentação e seguimento de instâncias.
Link to this sectionDataset SA-Co#
O SAM 3 é treinado no Segment Anything with Concepts (SA-Co), o dataset de segmentação mais vasto e diversificado da Meta até à data, expandindo-se para além dos benchmarks comuns como COCO e LVIS.
Link to this sectionDados de Treino#
| Componente do Dataset | Descrição | Escala |
|---|---|---|
| SA-Co/HQ | Dados de imagem de alta qualidade anotados por humanos a partir de um motor de dados de 4 fases | 5.2M de imagens, 4M de frases nominais únicas |
| SA-Co/SYN | Dataset sintético rotulado por IA sem envolvimento humano | 38M de frases nominais, 1.4B de máscaras |
| SA-Co/EXT | 15 datasets externos enriquecidos com exemplos negativos difíceis | Varia conforme a fonte |
| SA-Co/VIDEO | Anotações de vídeo com seguimento temporal | 52.5K de vídeos, 24.8K de frases nominais únicas |
Link to this sectionDados de Benchmark#
O benchmark de avaliação SA-Co contém 214K frases únicas em 126K imagens e vídeos, fornecendo mais de 50× mais conceitos do que os benchmarks existentes. Inclui:
- SA-Co/Gold: 7 domínios, com anotação tripla para medir limites de desempenho humano
- SA-Co/Silver: 10 domínios, anotação humana única
- SA-Co/Bronze e SA-Co/Bio: 9 datasets existentes adaptados para segmentação de conceitos
- SA-Co/VEval: Benchmark de vídeo com 3 domínios (SA-V, YT-Temporal-1B, SmartGlasses)
Link to this sectionInovações no Motor de Dados#
O motor de dados escalável humano-e-modelo-no-circuito do SAM 3 alcança 2× de rendimento de anotação através de:
- Anotadores de IA: Modelos baseados em Llama propõem diversas frases nominais, incluindo negativos difíceis
- Verificadores de IA: LLMs multimodais ajustados verificam a qualidade e exaustividade da máscara com um desempenho próximo do humano
- Mineração Ativa: Foca o esforço humano em casos de falha desafiantes onde a IA tem dificuldades
- Orientado por Ontologia: Aproveita uma grande ontologia baseada no Wikidata para cobertura de conceitos
Link to this sectionInstalação#
O SAM 3 está disponível na versão 8.3.237 do Ultralytics e posteriores. Instala ou atualiza com:
pip install -U ultralyticsAo contrário de outros modelos Ultralytics, os pesos do SAM 3 (sam3.pt) não são descarregados automaticamente. Tens de solicitar primeiro acesso aos pesos do modelo na página do modelo SAM 3 no Hugging Face e, depois de aprovado, descarregar o sam3.pt dessa página. Coloca o ficheiro sam3.pt descarregado no teu diretório de trabalho ou especifica o caminho completo ao carregar o modelo.
Se obtiveres o erro acima durante a predição, significa que tens o pacote clip incorreto instalado. Instala o pacote clip correto executando o seguinte:
pip uninstall clip -y
pip install git+https://github.com/ultralytics/CLIP.gitLink to this sectionComo usar o SAM 3: Versatilidade na Segmentação de Conceitos#
O SAM 3 suporta tarefas de Promptable Concept Segmentation (PCS) e Promptable Visual Segmentation (PVS) através de diferentes interfaces de preditor:
Link to this sectionTarefas e Modelos Suportados#
| Tipo de Tarefa | Tipos de Prompt | Saída |
|---|---|---|
| Segmentação de Conceitos (PCS) | Texto (frases nominais), exemplos de imagem | Todas as instâncias que correspondem ao conceito |
| Segmentação Visual (PVS) | Pontos, caixas, máscaras | Instância de objeto único (estilo SAM 2) |
| Refinamento Interativo | Adicionar/remover exemplos ou cliques iterativamente | Segmentação refinada com precisão melhorada |
Link to this sectionExemplos de Segmentação de Conceitos#
Link to this sectionSegmentar com Prompts de Texto#
Encontre e segmente todas as instâncias de um conceito usando uma descrição de texto. Prompts de texto exigem a interface SAM3SemanticPredictor.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor with configuration
overrides = dict(
conf=0.25,
task="segment",
mode="predict",
model="sam3.pt",
quantize=16, # Use FP16 for faster inference
save=True,
)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image once for multiple queries
predictor.set_image("path/to/image.jpg")
# Query with multiple text prompts
results = predictor(text=["person", "bus", "glasses"])
# Works with descriptive phrases
results = predictor(text=["person with red cloth", "person with blue cloth"])
# Query with a single concept
results = predictor(text=["a person"])Link to this sectionSegmentação com Exemplos de Imagem#
Use bounding boxes como prompts visuais para encontrar todas as instâncias similares. Isso também requer o SAM3SemanticPredictor para correspondência baseada em conceito.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16, save=True)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image
predictor.set_image("path/to/image.jpg")
# Provide bounding box examples to segment similar objects
results = predictor(bboxes=[[480.0, 290.0, 590.0, 650.0]])
# Multiple bounding boxes as exemplars of the same visual concept
results = predictor(bboxes=[[539, 599, 589, 639], [343, 267, 499, 662]])Link to this sectionInferência baseada em características para Eficiência#
Extraia características de imagem uma vez e reutilize-as para múltiplas consultas de segmentação para melhorar a eficiência.
import cv2
from ultralytics.models.sam import SAM3SemanticPredictor
from ultralytics.utils.plotting import Annotator, colors
# Initialize predictors
overrides = dict(conf=0.50, task="segment", mode="predict", model="sam3.pt", verbose=False)
predictor = SAM3SemanticPredictor(overrides=overrides)
predictor2 = SAM3SemanticPredictor(overrides=overrides)
# Extract features from the first predictor
source = "path/to/image.jpg"
predictor.set_image(source)
src_shape = cv2.imread(source).shape[:2]
# Setup second predictor and reuse features
predictor2.setup_model()
# Perform inference using shared features with text prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, text=["person"])
# Perform inference using shared features with bounding box prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, bboxes=[[439, 437, 524, 709]])
# Visualize results
if masks is not None:
masks, boxes = masks.cpu().numpy(), boxes.cpu().numpy()
im = cv2.imread(source)
annotator = Annotator(im, pil=False)
annotator.masks(masks, [colors(x, True) for x in range(len(masks))])
cv2.imshow("result", annotator.result())
cv2.waitKey(0)Link to this sectionSegmentação de Conceito em Vídeo#
Link to this sectionRastreie Conceitos em Vídeo com Bounding Boxes#
Detecte e rastreie instâncias de objetos em quadros de vídeo usando prompts de bounding box.
from ultralytics.models.sam import SAM3VideoPredictor
# Create video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16)
predictor = SAM3VideoPredictor(overrides=overrides)
# Track objects using bounding box prompts
results = predictor(source="path/to/video.mp4", bboxes=[[706.5, 442.5, 905.25, 555], [598, 635, 725, 750]], stream=True)
# Process and display results
for r in results:
r.show() # Display frame with segmentation masksLink to this sectionRastreie Conceitos com Prompts de Texto#
Rastreie todas as instâncias de conceitos especificados por texto em quadros de vídeo.
from ultralytics.models.sam import SAM3VideoSemanticPredictor
# Initialize semantic video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=640, model="sam3.pt", quantize=16, save=True)
predictor = SAM3VideoSemanticPredictor(overrides=overrides)
# Track concepts using text prompts
results = predictor(source="path/to/video.mp4", text=["person", "bicycle"], stream=True)
# Process results
for r in results:
r.show() # Display frame with tracked objects
# Alternative: Track with bounding box prompts
results = predictor(
source="path/to/video.mp4",
bboxes=[[864, 383, 975, 620], [705, 229, 782, 402]],
labels=[1, 1], # Positive labels
stream=True,
)Link to this sectionPrompts Visuais (Compatibilidade com SAM 2)#
O SAM 3 mantém total compatibilidade retroativa com o prompt visual do SAM 2 para segmentação de objeto único:
A interface básica SAM comporta-se exatamente como o SAM 2, segmentando apenas a área específica indicada por prompts visuais (pontos, caixas ou máscaras).
from ultralytics import SAM
model = SAM("sam3.pt")
# Single point prompt - segments object at specific location
results = model.predict(source="path/to/image.jpg", points=[900, 370], labels=[1])
results[0].show()
# Multiple points - segments single object with multiple point hints
results = model.predict(source="path/to/image.jpg", points=[[400, 370], [900, 370]], labels=[1, 1])
# Box prompt - segments object within bounding box
results = model.predict(source="path/to/image.jpg", bboxes=[100, 150, 300, 400])
results[0].show()Usar SAM("sam3.pt") com prompts visuais (pontos/caixas/máscaras) segmentará apenas o objeto específico naquele local, assim como o SAM 2. Para segmentar todas as instâncias de um conceito, use SAM3SemanticPredictor com prompts de texto ou exemplares como mostrado acima.
Link to this sectionBenchmarks de Desempenho#
Link to this sectionSegmentação de Imagem#
O SAM 3 alcança resultados de ponta em vários benchmarks, incluindo conjuntos de dados do mundo real como LVIS e COCO for segmentation:
| Benchmark | Métrica | SAM 3 | Melhor Anterior | Melhoria |
|---|---|---|---|---|
| LVIS (zero-shot) | Mask AP | 47.0 | 38.5 | +22.1% |
| SA-Co/Gold | CGF1 | 65.0 | 34.3 (OWLv2) | +89.5% |
| COCO (zero-shot) | Box AP | 53.5 | 52.2 (T-Rex2) | +2.5% |
| ADE-847 (seg semântica) | mIoU | 14.7 | 9.2 (APE-D) | +59.8% |
| PascalConcept-59 | mIoU | 59.4 | 58.5 (APE-D) | +1.5% |
| Cityscapes (seg semântica) | mIoU | 65.1 | 44.2 (APE-D) | +47.3% |
Explore opções de conjuntos de dados para experimentação rápida em Ultralytics datasets.
Link to this sectionDesempenho de Segmentação de Vídeo#
O SAM 3 mostra melhorias significativas em relação ao SAM 2 e ao estado da arte anterior em benchmarks de vídeo, como DAVIS 2017 e YouTube-VOS:
| Benchmark | Métrica | SAM 3 | SAM 2.1 L | Melhoria |
|---|---|---|---|---|
| MOSEv2 | J&F | 60.1 | 47.9 | +25.5% |
| DAVIS 2017 | J&F | 92.0 | 90.7 | +1.4% |
| LVOSv2 | J&F | 88.2 | 79.6 | +10.8% |
| SA-V | J&F | 84.6 | 78.4 | +7.9% |
| YTVOS19 | J&F | 89.6 | 89.3 | +0.3% |
Link to this sectionAdaptação Few-Shot#
O SAM 3 destaca-se na adaptação a novos domínios com exemplos mínimos, relevante para fluxos de trabalho de data-centric AI:
| Benchmark | 0-shot AP | 10-shot AP | Melhor Anterior (10-shot) |
|---|---|---|---|
| ODinW13 | 59.9 | 71.6 | 67.9 (gDino1.5-Pro) |
| RF100-VL | 14.3 | 35.7 | 33.7 (gDino-T) |
Link to this sectionEficácia do Refinamento Interativo#
O prompt baseado em conceito do SAM 3 com exemplares converge muito mais rápido do que o prompt visual:
| Prompts Adicionados | Pontuação CGF1 | Ganho vs Apenas Texto | Ganho vs Baseline PVS |
|---|---|---|---|
| Apenas texto | 46.4 | baseline | baseline |
| +1 exemplar | 57.6 | +11.2 | +6.7 |
| +2 exemplares | 62.2 | +15.8 | +9.7 |
| +3 exemplares | 65.0 | +18.6 | +11.2 |
| +4 exemplares | 65.7 | +19.3 | +11.5 (platô) |
Link to this sectionPrecisão de Contagem de Objetos#
O SAM 3 oferece uma contagem precisa ao segmentar todas as instâncias, um requisito comum na contagem de objetos:
| Benchmark | Precisão | MAE | vs Melhor MLLM |
|---|---|---|---|
| CountBench | 95.6% | 0.11 | 92.4% (Gemini 2.5) |
| PixMo-Count | 87.3% | 0.22 | 88.8% (Molmo-72B) |
Link to this sectionComparação SAM 3 vs SAM 2 vs YOLO#
Aqui comparamos as capacidades do SAM 3 com os modelos SAM 2 e YOLO26:
| Capacidade | SAM 3 | SAM 2 | YOLO26n-seg |
|---|---|---|---|
| Segmentação de Conceitos | ✅ Todas as instâncias via texto/exemplares | ❌ Não suportado | ❌ Não suportado |
| Segmentação Visual | ✅ Instância única (compatível com SAM 2) | ✅ Instância única | ✅ Todas as instâncias |
| Capacidade Zero-shot | ✅ Vocabulário aberto | ✅ Prompts geométricos | ❌ Conjunto fechado |
| Refinamento Interativo | ✅ Exemplares + cliques | ✅ Apenas cliques | ❌ Não suportado |
| Rastreamento de Vídeo | ✅ Multiobjetos com identidades | ✅ Multiobjetos | ✅ Multiobjetos |
| LVIS Mask AP (zero-shot) | 47.0 | N/A | N/A |
| MOSEv2 J&F | 60.1 | 47.9 | N/A |
| Velocidade (GPU, ms/im) | 2921 | 857 | 8.4 |
| Tamanho do Modelo | 3.45 GB | 162 MB (base) | 6.4 MB |
Velocidade medida em uma NVIDIA RTX PRO 6000 com torch==2.9.1 e ultralytics==8.4.19.
Principais Conclusões:
- SAM 3: Ideal para segmentação de conceitos de vocabulário aberto, encontrando todas as instâncias de um conceito com prompts de texto ou exemplares
- SAM 2: Ideal para segmentação interativa de objetos únicos em imagens e vídeos com prompts geométricos
- YOLO26: Ideal para segmentação de alta velocidade em tempo real com inferência fim a fim sem NMS, exportável para vários formatos para implantação em GPUs, CPUs e dispositivos de borda
Link to this sectionComparação SAM vs YOLO#
Comparando SAM 3, SAM 2, SAM, MobileSAM e FastSAM com os modelos de segmentação Ultralytics YOLO (YOLOv8, YOLO11, YOLO26) em tamanho, parâmetros e velocidade de inferência em GPU:
| Modelo | Tamanho (MB) | Parâmetros (M) | Velocidade (GPU) (ms/im) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 1306 |
| Meta SAM2-b | 162 | 80.8 | 857 |
| Meta SAM2-t | 78.1 | 38.9 | 668 |
| Meta SAM3 | 3450 | 473.6 | 2921 |
| MobileSAM | 40.7 | 10.1 | 605 |
| FastSAM-s com backbone YOLOv8 | 23.7 | 11.8 | 55.9 |
| YOLOv8n-seg da Ultralytics | 6.7 (515x menor) | 3.4 (139.1x menos) | 17.4 (167x mais rápido) |
| YOLO11n-seg da Ultralytics | 5.9 (585x menor) | 2.9 (163.1x menos) | 12.6 (231x mais rápido) |
| YOLO26n-seg da Ultralytics | 6.4 (539x menor) | 2.7 (175.2x menos) | 8.4 (347x mais rápido) |
Esta comparação demonstra as diferenças substanciais nos tamanhos e velocidades dos modelos entre as variantes do SAM e os modelos de segmentação YOLO. Enquanto o SAM fornece capacidades de segmentação automática únicas, os modelos YOLO, particularmente YOLOv8n-seg, YOLO11n-seg e YOLO26n-seg, são significativamente menores, mais rápidos e computacionalmente mais eficientes.
Testes executados em uma NVIDIA RTX PRO 6000 com 96GB de VRAM usando torch==2.9.1 e ultralytics==8.4.19. Para reproduzir este teste:
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# Profile SAM3, SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt", "sam3.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# Profile FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# Profile YOLO models
for file_name in ["yolov8n-seg.pt", "yolo11n-seg.pt", "yolo26n-seg.pt"]:
model = YOLO(file_name)
model.info()
model(ASSETS)Link to this sectionMétricas de Avaliação#
O SAM 3 introduz novas métricas projetadas para a tarefa PCS, complementando medidas familiares como pontuação F1, precisão e recall.
Link to this sectionF1 de Classificação Controlada (CGF1)#
A métrica principal que combina localização e classificação:
CGF1 = 100 × pmF1 × IL_MCC
Onde:
- pmF1 (F1 Macro Positivo): Mede a qualidade da localização em exemplos positivos
- IL_MCC (Coeficiente de Correlação de Matthews ao nível da imagem): Mede a precisão da classificação binária ("o conceito está presente?")
Link to this sectionPor que estas métricas?#
As métricas AP tradicionais não levam em conta a calibração, tornando os modelos difíceis de usar na prática. Ao avaliar apenas previsões acima de 0.5 de confiança, as métricas do SAM 3 reforçam uma boa calibração e imitam padrões de uso do mundo real em loops interativos de previsão e rastreamento.
Link to this sectionPrincipais Ablações e Insights#
Link to this sectionImpacto da Cabeça de Presença#
A cabeça de presença desacopla o reconhecimento da localização, proporcionando melhorias significativas:
| Configuração | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Sem presença | 57.6 | 0.77 | 74.7 |
| Com presença | 63.3 | 0.82 | 77.1 |
A cabeça de presença oferece um aumento de +5.7 CGF1 (+9.9%), melhorando principalmente a capacidade de reconhecimento (IL_MCC +6.5%).
Link to this sectionEfeito de Negativos Difíceis#
| Negativos Difíceis/Imagem | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 0 | 31.8 | 0.44 | 70.2 |
| 5 | 44.8 | 0,62 | 71.9 |
| 30 | 49.2 | 0.68 | 72.3 |
Hard negatives são cruciais para reconhecimento de vocabulário aberto, melhorando o IL_MCC em 54.5% (0.44 → 0.68).
Link to this sectionEscalonamento de dados de treinamento#
| Fontes de dados | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Apenas externo | 30.9 | 0.46 | 66.3 |
| Externo + Sintético | 39.7 | 0.57 | 70.6 |
| Externo + HQ | 51.8 | 0.71 | 73.2 |
| Todos os três | 54.3 | 0.74 | 73.5 |
Anotações humanas de alta qualidade proporcionam ganhos significativos em relação a dados sintéticos ou externos isoladamente. Para saber mais sobre práticas de qualidade de dados, consulte coleta e anotação de dados.
Link to this sectionAplicações#
A capacidade de segmentação de conceitos do SAM 3 possibilita novos casos de uso:
- Moderação de conteúdo: Encontre todas as instâncias de tipos de conteúdo específicos em bibliotecas de mídia
- E-commerce: Segmenta todos os produtos de um determinado tipo em imagens de catálogo, oferecendo suporte para auto-annotation
- Imagens médicas: Identifique todas as ocorrências de tipos específicos de tecido ou anomalias
- Sistemas autônomos: Rastreie todas as instâncias de sinais de trânsito, pedestres ou veículos por categoria
- Análise de vídeo: Conte e rastreie todas as pessoas vestindo roupas específicas ou realizando ações
- Anotação de conjunto de dados: Anote rapidamente todas as instâncias de categorias de objetos raras
- Pesquisa científica: Quantifique e analise todos os espécimes que correspondam a critérios específicos
Link to this sectionAgente SAM 3: Raciocínio de linguagem estendido#
O SAM 3 pode ser combinado com Multimodal Large Language Models (MLLMs) para lidar com consultas complexas que exigem raciocínio, de forma semelhante a sistemas de vocabulário aberto como OWLv2 e T-Rex.
Link to this sectionDesempenho em tarefas de raciocínio#
| Benchmark | Métrica | Agente SAM 3 (Gemini 2.5 Pro) | Melhor Anterior |
|---|---|---|---|
| ReasonSeg (validação) | gIoU | 76.0 | 65.0 (SoTA) |
| ReasonSeg (teste) | gIoU | 73.8 | 61.3 (SoTA) |
| OmniLabel (validação) | AP | 46.7 | 36.5 (REAL) |
| RefCOCO+ | Acc | 91.2 | 89.3 (LISA) |
Link to this sectionExemplos de consultas complexas#
O Agente SAM 3 consegue lidar com consultas que exigem raciocínio:
- "Pessoas sentadas, mas que não estão segurando uma caixa de presente nas mãos"
- "O cachorro mais próximo da câmera que não está usando coleira"
- "Objetos vermelhos maiores que a mão da pessoa"
O MLLM propõe consultas de frase nominal simples para o SAM 3, analisa as máscaras retornadas e itera até obter um resultado satisfatório.
Link to this sectionLimitações#
Embora o SAM 3 represente um grande avanço, ele possui certas limitações:
- Complexidade de frases: Melhor adaptado para frases nominais simples; expressões de referência longas ou raciocínios complexos podem exigir integração com MLLM
- Tratamento de ambiguidade: Alguns conceitos permanecem inerentemente ambíguos (por exemplo, "janela pequena", "quarto aconchegante")
- Requisitos computacionais: Maior e mais lento que modelos de detecção especializados como o YOLO
- Escopo de vocabulário: Focado em conceitos visuais atômicos; o raciocínio composicional é limitado sem a assistência de um MLLM
- Conceitos raros: O desempenho pode diminuir em conceitos extremamente raros ou muito específicos que não estejam bem representados nos dados de treinamento
Link to this sectionCitação#
@inproceedings{sam3_2025,
title = {SAM 3: Segment Anything with Concepts},
author = {Anonymous authors},
booktitle = {Submitted to ICLR 2026},
year = {2025},
url = {https://openreview.net/forum?id=r35clVtGzw},
note = {Paper ID: 4183, under double-blind review}
}Link to this sectionFAQ#
Link to this sectionQuando o SAM 3 foi lançado?#
O SAM 3 foi lançado pela Meta em 20 de novembro de 2025 e está totalmente integrado ao Ultralytics a partir da versão 8.3.237 (PR #22897). Suporte completo está disponível para modo de predição e modo de rastreamento.
Link to this sectionO SAM 3 está integrado ao Ultralytics?#
Sim! O SAM 3 está totalmente integrado ao pacote Python do Ultralytics, incluindo segmentação de conceitos, prompts visuais no estilo do SAM 2 e rastreamento de vídeo de múltiplos objetos. O SAM 3 também impulsiona o recurso de anotação inteligente na Plataforma Ultralytics, onde você pode anotar imagens com apenas alguns cliques.
Link to this sectionO que é Segmentação de Conceitos Prompteável (PCS)?#
PCS é uma nova tarefa introduzida no SAM 3 que segmenta todas as instâncias de um conceito visual em uma imagem ou vídeo. Diferente da segmentação tradicional que foca em uma instância de objeto específica, a PCS encontra todas as ocorrências de uma categoria. Por exemplo:
- Prompt de texto: "ônibus escolar amarelo" → segmenta todos os ônibus escolares amarelos na cena
- Exemplar de imagem: Caixa ao redor de um cachorro → segmenta todos os cachorros na imagem
- Combinado: "gato listrado" + caixa exemplar → segmenta todos os gatos listrados que correspondem ao exemplo
Veja informações relacionadas sobre detecção de objetos e segmentação de instâncias.
Link to this sectionComo o SAM 3 difere do SAM 2?#
| Funcionalidade | SAM 2 | SAM 3 |
|---|---|---|
| Tarefa | Objeto único por prompt | Todas as instâncias de um conceito |
| Tipos de prompt | Pontos, caixas, máscaras | + Frases de texto, exemplares de imagem |
| Capacidade de detecção | Requer detector externo | Detector de vocabulário aberto integrado |
| Reconhecimento | Apenas baseado em geometria | Reconhecimento visual e de texto |
| Arquitetura | Apenas rastreador | Detector + Rastreador com head de presença |
| Desempenho Zero-Shot | N/A (requer prompts visuais) | 47.0 AP no LVIS, 2× melhor no SA-Co |
| Refinamento Interativo | Apenas cliques | Cliques + generalização de exemplares |
O SAM 3 mantém a retrocompatibilidade com o prompt visual do SAM 2 enquanto adiciona recursos baseados em conceitos.
Link to this sectionQuais conjuntos de dados são usados para treinar o SAM 3?#
O SAM 3 é treinado no conjunto de dados Segment Anything with Concepts (SA-Co):
Dados de treinamento:
- 5,2 M de imagens com 4 M de frases nominais únicas (SA-Co/HQ) - anotações humanas de alta qualidade
- 52,5 K de vídeos com 24,8 K de frases nominais únicas (SA-Co/VIDEO)
- 1,4 B de máscaras sintéticas em 38 M de frases nominais (SA-Co/SYN)
- 15 conjuntos de dados externos enriquecidos com exemplos negativos difíceis (SA-Co/EXT)
Dados de Benchmark:
- 214 K de conceitos únicos em 126 K de imagens/vídeos
- 50× mais conceitos do que benchmarks existentes (por exemplo, o LVIS tem ~4 K conceitos)
- Tripla anotação no SA-Co/Gold para medir os limites de desempenho humano
Essa escala e diversidade massivas permitem a generalização zero-shot superior do SAM 3 em conceitos de vocabulário aberto.
Link to this sectionComo o SAM 3 se compara ao YOLO26 para segmentação?#
O SAM 3 e o YOLO26 atendem a casos de uso diferentes:
Vantagens do SAM 3:
- Vocabulário aberto: Segmenta qualquer conceito via prompts de texto sem treinamento
- Zero-shot: Funciona em novas categorias imediatamente
- Interativo: O refinamento baseado em exemplares generaliza para objetos semelhantes
- Baseado em conceitos: Encontra automaticamente todas as instâncias de uma categoria
- Precisão: 47,0 AP em segmentação de instância zero-shot no LVIS
Vantagens do YOLO26:
- Velocidade: Inferência ordens de grandeza mais rápida com design end-to-end sem NMS
- Eficiência: Modelos 539× menores (6,4 MB vs 3,45 GB)
- Amigável a recursos: Executa em dispositivos de borda e dispositivos móveis
- Tempo real: Otimizado para implementações em produção
Recomendação:
- Use o SAM 3 para segmentação flexível de vocabulário aberto onde você precisa encontrar todas as instâncias de conceitos descritos por texto ou exemplos
- Use o YOLO26 para implementações de alta velocidade em produção onde as categorias são conhecidas antecipadamente
- Use o SAM 2 para segmentação interativa de objeto único com prompts geométricos
Link to this sectionO SAM 3 consegue lidar com consultas de linguagem complexas?#
O SAM 3 foi projetado para frases nominais simples (por exemplo, "maçã vermelha", "pessoa usando chapéu"). Para consultas complexas que exigem raciocínio, combine o SAM 3 com um MLLM como SAM 3 Agent:
Consultas simples (SAM 3 nativo):
- "ônibus escolar amarelo"
- "gato listrado"
- "pessoa usando chapéu vermelho"
Consultas complexas (SAM 3 Agent com MLLM):
- "Pessoas sentadas, mas não segurando uma caixa de presente"
- "O cachorro mais próximo da câmera sem coleira"
- "Objetos vermelhos maiores que a mão da pessoa"
O SAM 3 Agent alcança 76,0 gIoU na validação ReasonSeg (vs 65,0 anterior, +16,9% de melhoria) combinando a segmentação do SAM 3 com capacidades de raciocínio de MLLM.
Link to this sectionQual é a precisão do SAM 3 em comparação com o desempenho humano?#
No benchmark SA-Co/Gold com tripla anotação humana:
- Limite inferior humano: 74,2 CGF1 (anotador mais conservador)
- Desempenho do SAM 3: 65,0 CGF1
- Conquista: 88% do limite inferior humano estimado
- Limite superior humano: 81,4 CGF1 (anotador mais liberal)
O SAM 3 alcança um forte desempenho aproximando-se da precisão de nível humano na segmentação de conceitos de vocabulário aberto, com a lacuna principalmente em conceitos ambíguos ou subjetivos (por exemplo, "janela pequena", "quarto aconchegante").