SAM 3:基于概念的任何事物分割 (Segment Anything with Concepts)#
自 8.3.237 版本 (PR #22897) 起,SAM 3 已完全集成到 Ultralytics 包中。请安装或更新至最新版本 pip install -U ultralytics,即可使用所有 SAM 3 功能,包括基于文本的概念分割、图像范例提示和视频追踪。
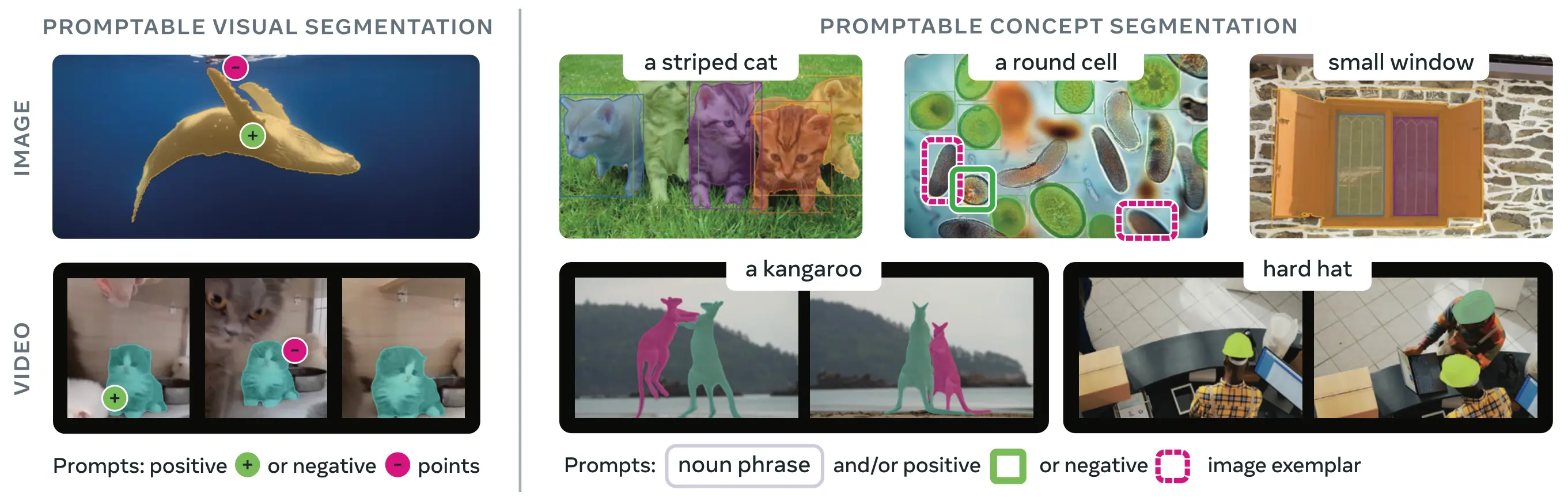
SAM 3 (Segment Anything Model 3) 是 Meta 发布的首个用于 可提示概念分割 (PCS) 的基础模型。在 SAM 2 的基础上,SAM 3 引入了一项全新的基础能力:检测、分割并追踪由文本提示、图像范例或两者结合所指定的视觉概念的所有实例。与以往每个提示仅分割单个对象的 SAM 版本不同,SAM 3 可以查找并分割图像或视频中出现的任何概念的所有实例,这与现代 实例分割 中的开放词汇目标保持一致。
Watch: How to Use Meta Segment Anything 3 with Ultralytics | Text-Prompt Segmentation on Images & Videos
SAM 3 现已完全集成到 ultralytics 包中,为使用文本提示、图像范例提示和视频追踪功能进行概念分割提供了原生支持。
概述#
SAM 3 在可提示概念分割任务上的性能比现有系统提升了 2 倍,同时保持并优化了 SAM 2 在交互式 视觉分割 方面的能力。该模型在开放词汇分割方面表现出色,允许你通过简单的名词短语(例如“黄色校车”、“条纹猫”)或提供目标对象的示例图像来指定概念。这些能力与依赖精简的 预测 和 追踪 工作流的生产级流水线形成了良好的互补。
什么是可提示概念分割 (PCS)?#
PCS 任务以 概念提示 作为输入,并返回具有唯一标识的分割掩码,涵盖所有匹配的对象实例。概念提示可以是:
- 文本:简单的名词短语,如“红苹果”或“戴帽子的那个人”,类似于 零样本学习
- 图像范例:围绕示例对象(正面或负面)的边界框,用于快速泛化
- 组合:同时结合文本和图像范例,以实现精确控制
这与传统的视觉提示(点、框、掩码)不同,传统的视觉提示仅分割单个特定对象实例,正如最初的 SAM 系列 所普及的那样。
关键性能指标#
| 指标 | SAM 3 成就 |
|---|---|
| LVIS Zero-Shot Mask AP | 47.0 (对比之前最高 38.5,提升 22%) |
| SA-Co 基准测试 | 比现有系统强 2 倍 |
| 推理速度 (H200 GPU) | 每张图片 30 ms,可检测 100+ 个对象 |
| 视频性能 | 接近实时,支持约 5 个并发对象 |
| MOSEv2 VOS 基准测试 | 60.1 J&F (较 SAM 2.1 提升 25.5%,较之前 SOTA 提升 17%) |
| 交互式修正 | 在 3 次范例提示后提升 +18.6 CGF1 |
| 人类性能差距 | 在 SA-Co/Gold 上达到估计下界的 88% |
有关生产环境中的模型指标和权衡的背景信息,请查看 模型评估见解 和 YOLO 性能指标。
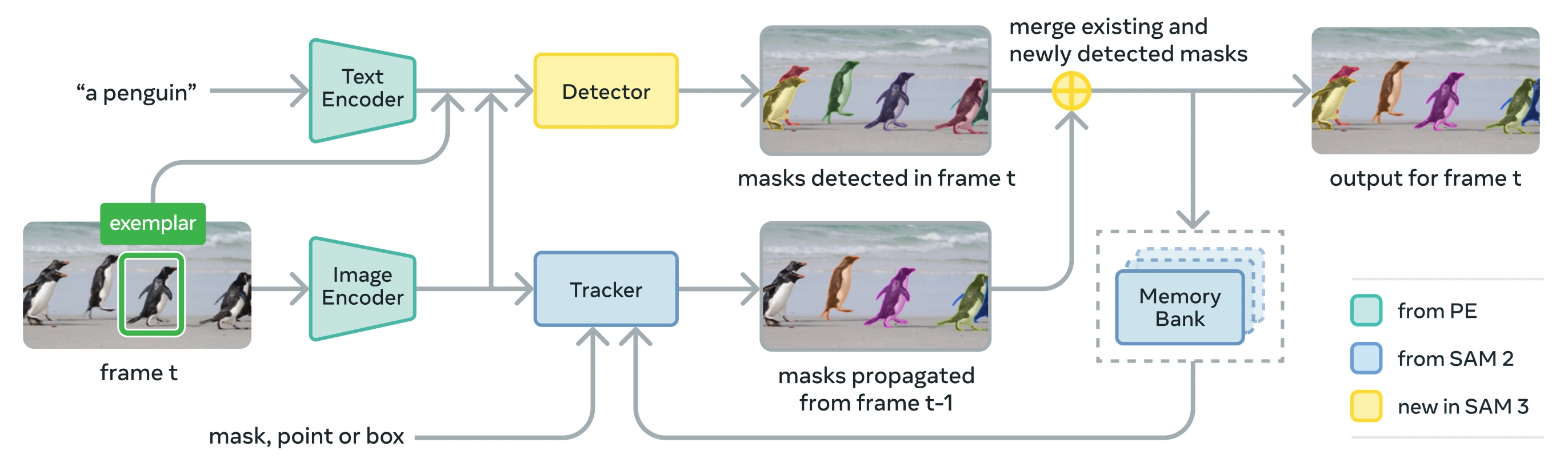
架构#
SAM 3 由一个 检测器 和一个 追踪器 组成,它们共享一个感知编码器 (PE) 视觉骨干网络。这种解耦设计避免了任务冲突,同时实现了图像级检测和视频级追踪,并且其接口兼容 Ultralytics 的 Python 使用方式 和 CLI 使用方式。
核心组件#
-
检测器:用于图像级概念检测的 基于 DETR 的架构
- 用于名词短语提示的文本编码器
- 用于基于图像的提示的范例编码器
- 用于将图像特征与提示条件相结合的融合编码器
- 新型 存在头 (presence head),将识别(“是什么”)与定位(“在哪里”)解耦
- 用于生成实例分割掩码的掩码头
-
追踪器:继承自 SAM 2 的基于内存的视频分割
- 提示编码器、掩码解码器、内存编码器
- 用于在不同帧间存储对象外观的内存库
- 在多对象设置中,通过 卡尔曼滤波 (Kalman filter) 等技术辅助进行时间消歧
-
存在标记 (Presence Token):一种学习到的全局标记,用于预测目标概念是否存在于图像/帧中,通过将识别与定位分离来改善检测效果。
关键创新#
- 解耦识别与定位:存在头在全局预测概念是否存在,而提议查询仅专注于定位,避免了冲突的目标。
- 统一概念与视觉提示:在单一模型中同时支持 PCS(概念提示)和 PVS(类似 SAM 2 的点击/框等视觉提示)。
- 交互式范例修正:用户可以添加正面或负面图像范例来迭代修正结果,模型将泛化到相似对象,而不仅仅是修正单个实例。
- 时间消歧:使用掩码检测分数和定期重新提示来处理视频中的遮挡、拥挤场景和追踪失败,符合 实例分割和追踪 的最佳实践。
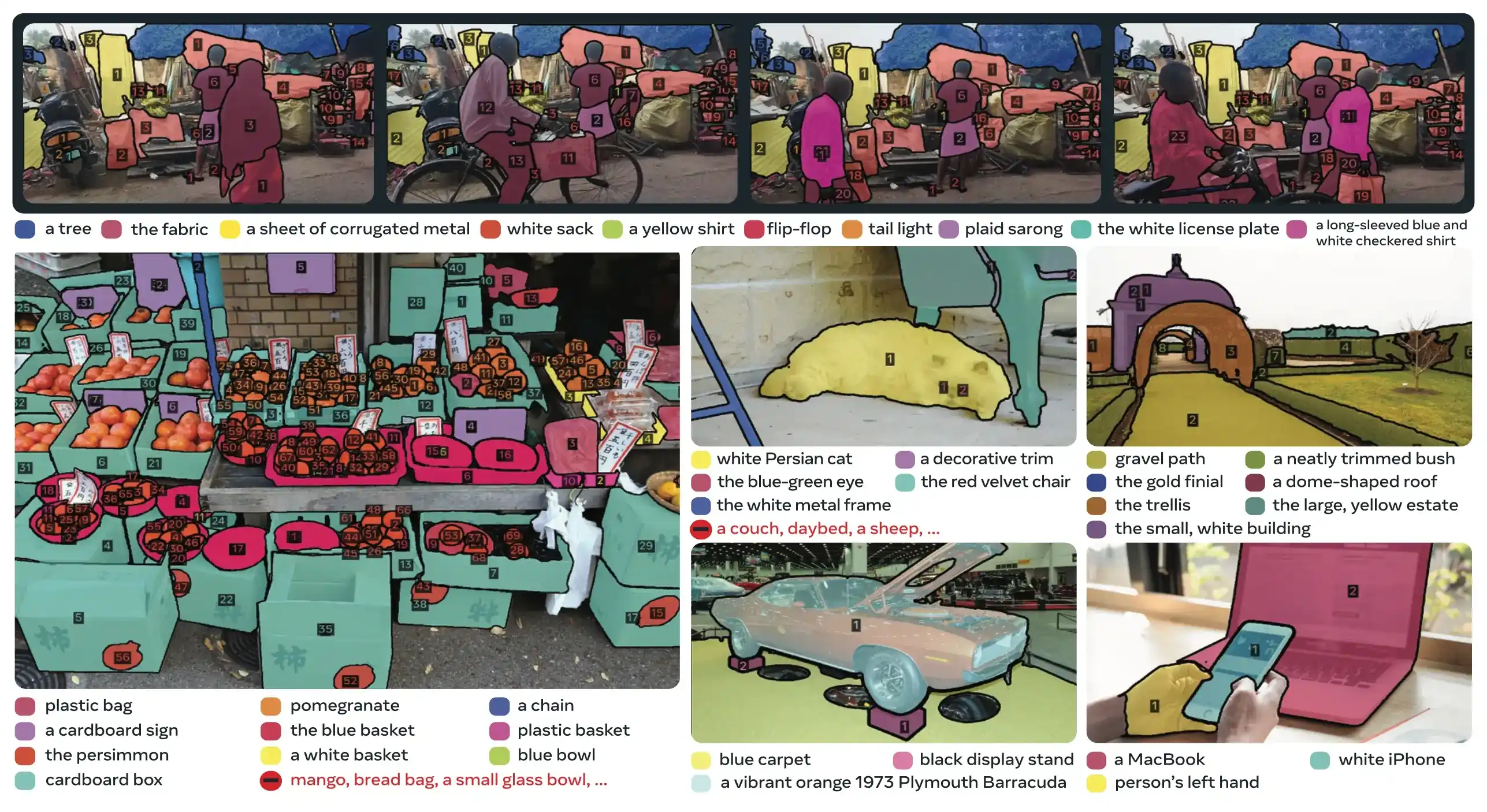
SA-Co 数据集#
SAM 3 在 Segment Anything with Concepts (SA-Co) 上进行训练,这是 Meta 迄今为止最大且最多样化的分割数据集,超越了常见的基准测试,如 COCO 和 LVIS。
训练数据#
| 数据集组件 | 描述 | 规模 |
|---|---|---|
| SA-Co/HQ | 来自 4 阶段数据引擎的高质量人工标注图像数据 | 520 万张图片,400 万个唯一名词短语 |
| SA-Co/SYN | 由 AI 在无需人工参与下标注的合成数据集 | 3800 万个名词短语,14 亿个掩码 |
| SA-Co/EXT | 15 个包含难例样本的外部增强数据集 | 随来源而异 |
| SA-Co/VIDEO | 带有时间追踪的视频标注 | 5.25 万个视频,2.48 万个唯一名词短语 |
基准数据#
SA-Co 评估基准测试 包含横跨 12.6 万张图像和视频 的 21.4 万个唯一短语,提供的 概念数量是现有基准的 50 倍以上。它包括:
- SA-Co/Gold:7 个领域,三重标注以衡量人类性能界限
- SA-Co/Silver:10 个领域,单次人工标注
- SA-Co/Bronze 和 SA-Co/Bio:9 个已适配用于概念分割的现有数据集
- SA-Co/VEval:包含 3 个领域的视频基准测试 (SA-V, YT-Temporal-1B, SmartGlasses)
数据引擎创新#
SAM 3 可扩展的“人在回路”和“模型在回路”数据引擎通过以下方式实现了 2 倍的标注吞吐量:
- AI 标注员:基于 Llama 的模型提出多样化的名词短语,包括难例样本
- AI 验证员:经过微调的 多模态大模型 以接近人类的性能验证掩码质量和穷尽性
- 主动挖掘:将人力集中在 AI 处理困难的失败案例上
- 本体驱动:利用基于 Wikidata 的大型本体进行概念覆盖
安装#
SAM 3 可用于 Ultralytics 8.3.237 及更高版本。请使用以下命令安装或升级:
pip install -U ultralytics与其他 Ultralytics 模型不同,SAM 3 的权重 (sam3.pt) 不会自动下载。你必须首先在 Hugging Face 上的 SAM 3 模型页面 上申请访问模型权重,批准后从该页面下载 sam3.pt。将下载的 sam3.pt 文件放入你的工作目录,或者在加载模型时指定完整路径。
如果在预测期间收到上述错误,意味着你安装了错误的 clip 包。请通过运行以下命令安装正确的 clip 包:
pip uninstall clip -y
pip install git+https://github.com/ultralytics/CLIP.git如何使用 SAM 3:概念分割的多功能性#
SAM 3 通过不同的预测器接口支持可提示概念分割 (PCS) 和可提示视觉分割 (PVS) 任务:
支持的任务和模型#
| 任务类型 | 提示类型 | 输出 |
|---|---|---|
| 概念分割 (PCS) | 文本(名词短语)、图像范例 | 匹配该概念的所有实例 |
| 视觉分割 (PVS) | 点、框、掩码 | 单个对象实例(SAM 2 风格) |
| 交互式修正 | 迭代式添加/移除范例或点击 | 具有更高准确性的精细化分割 |
概念分割示例#
使用文本提示进行分割#
使用文本描述查找并分割概念的所有实例。文本提示需要 SAM3SemanticPredictor 接口。
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor with configuration
overrides = {
"conf": 0.25,
"task": "segment",
"mode": "predict",
"model": "sam3.pt",
"quantize": 16, # Use FP16 for faster inference
"save": True,
}
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image once for multiple queries
predictor.set_image("path/to/image.jpg")
# Query with multiple text prompts
results = predictor(text=["person", "bus", "glasses"])
# Works with descriptive phrases
results = predictor(text=["person with red cloth", "person with blue cloth"])
# Query with a single concept
results = predictor(text=["a person"])使用图像示例进行分割#
使用边界框作为视觉提示来查找所有相似实例。这也需要 SAM3SemanticPredictor 来进行基于概念的匹配。
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor
overrides = {"conf": 0.25, "task": "segment", "mode": "predict", "model": "sam3.pt", "quantize": 16, "save": True}
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image
predictor.set_image("path/to/image.jpg")
# Provide bounding box examples to segment similar objects
results = predictor(bboxes=[[480.0, 290.0, 590.0, 650.0]])
# Multiple bounding boxes as exemplars of the same visual concept
results = predictor(bboxes=[[539, 599, 589, 639], [343, 267, 499, 662]])提高效率的基于特征的推理#
提取一次图像特征并将其用于多个分割查询,以提高效率。
import cv2
from ultralytics.models.sam import SAM3SemanticPredictor
from ultralytics.utils.plotting import Annotator, colors
# Initialize predictors
overrides = {"conf": 0.50, "task": "segment", "mode": "predict", "model": "sam3.pt", "verbose": False}
predictor = SAM3SemanticPredictor(overrides=overrides)
predictor2 = SAM3SemanticPredictor(overrides=overrides)
# Extract features from the first predictor
source = "path/to/image.jpg"
predictor.set_image(source)
src_shape = cv2.imread(source).shape[:2]
# Setup second predictor and reuse features
predictor2.setup_model()
# Perform inference using shared features with text prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, text=["person"])
# Perform inference using shared features with bounding box prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, bboxes=[[439, 437, 524, 709]])
# Visualize results
if masks is not None:
masks, boxes = masks.cpu().numpy(), boxes.cpu().numpy()
im = cv2.imread(source)
annotator = Annotator(im, pil=False)
annotator.masks(masks, [colors(x, True) for x in range(len(masks))])
cv2.imshow("result", annotator.result())
cv2.waitKey(0)视频概念分割#
利用边界框在视频中跟踪概念#
使用边界框提示检测并跟踪跨视频帧的对象实例。
from ultralytics.models.sam import SAM3VideoPredictor
# Create video predictor
overrides = {"conf": 0.25, "task": "segment", "mode": "predict", "model": "sam3.pt", "quantize": 16}
predictor = SAM3VideoPredictor(overrides=overrides)
# Track objects using bounding box prompts
results = predictor(source="path/to/video.mp4", bboxes=[[706.5, 442.5, 905.25, 555], [598, 635, 725, 750]], stream=True)
# Process and display results
for r in results:
r.show() # Display frame with segmentation masks使用文本提示跟踪概念#
在视频帧中跟踪文本所指定的概念的所有实例。
from ultralytics.models.sam import SAM3VideoSemanticPredictor
# Initialize semantic video predictor
overrides = {
"conf": 0.25,
"task": "segment",
"mode": "predict",
"imgsz": 640,
"model": "sam3.pt",
"quantize": 16,
"save": True,
}
predictor = SAM3VideoSemanticPredictor(overrides=overrides)
# Track concepts using text prompts
results = predictor(source="path/to/video.mp4", text=["person", "bicycle"], stream=True)
# Process results
for r in results:
r.show() # Display frame with tracked objects
# Alternative: Track with bounding box prompts
results = predictor(
source="path/to/video.mp4",
bboxes=[[864, 383, 975, 620], [705, 229, 782, 402]],
labels=[1, 1], # Positive labels
stream=True,
)视觉提示(SAM 2 兼容性)#
SAM 3 完全保持与 SAM 2 用于单对象分割的视觉提示的向后兼容性:
基本的 SAM 接口行为与 SAM 2 完全一致,仅分割由视觉提示(点、框或掩码)指示的特定区域。
from ultralytics import SAM
model = SAM("sam3.pt")
# Single point prompt - segments object at specific location
results = model.predict(source="path/to/image.jpg", points=[900, 370], labels=[1])
results[0].show()
# Multiple points - segments single object with multiple point hints
results = model.predict(source="path/to/image.jpg", points=[[400, 370], [900, 370]], labels=[1, 1])
# Box prompt - segments object within bounding box
results = model.predict(source="path/to/image.jpg", bboxes=[100, 150, 300, 400])
results[0].show()将 SAM("sam3.pt") 与视觉提示(点/框/掩码)结合使用时,就像 SAM 2 一样,只会分割该位置的特定对象。若要分割一个概念的所有实例,请按上述方法使用带有文本或示例提示的 SAM3SemanticPredictor。
性能基准#
图像分割#
SAM 3 在多个基准测试中取得了领先的结果,包括像 LVIS 和 COCO for segmentation 这样的真实世界数据集:
| 基准测试 | 指标 | SAM 3 | 之前最佳 | 提升幅度 |
|---|---|---|---|---|
| LVIS (zero-shot) | Mask AP | 47.0 | 38.5 | +22.1% |
| SA-Co/Gold | CGF1 | 65.0 | 34.3 (OWLv2) | +89.5% |
| COCO (zero-shot) | Box AP | 53.5 | 52.2 (T-Rex2) | +2.5% |
| ADE-847 (semantic seg) | mIoU | 14.7 | 9.2 (APE-D) | +59.8% |
| PascalConcept-59 | mIoU | 59.4 | 58.5 (APE-D) | +1.5% |
| Cityscapes (semantic seg) | mIoU | 65.1 | 44.2 (APE-D) | +47.3% |
探索 Ultralytics datasets 中的数据集选项以进行快速实验。
视频分割性能#
SAM 3 在视频基准测试(如 DAVIS 2017 和 YouTube-VOS)中表现出比 SAM 2 和之前最先进技术显著的改进:
| 基准测试 | 指标 | SAM 3 | SAM 2.1 L | 提升幅度 |
|---|---|---|---|---|
| MOSEv2 | J&F | 60.1 | 47.9 | +25.5% |
| DAVIS 2017 | J&F | 92.0 | 90.7 | +1.4% |
| LVOSv2 | J&F | 88.2 | 79.6 | +10.8% |
| SA-V | J&F | 84.6 | 78.4 | +7.9% |
| YTVOS19 | J&F | 89.6 | 89.3 | +0.3% |
少样本适应#
SAM 3 擅长通过极少的样本适应新领域,这与 data-centric AI 工作流程相关:
| 基准测试 | 0-shot AP | 10-shot AP | 之前最佳 (10-shot) |
|---|---|---|---|
| ODinW13 | 59.9 | 71.6 | 67.9 (gDino1.5-Pro) |
| RF100-VL | 14.3 | 35.7 | 33.7 (gDino-T) |
交互式精炼的有效性#
SAM 3 基于概念的示例提示比视觉提示收敛得快得多:
| 已添加提示 | CGF1 得分 | 相比仅文本的增益 | 相比 PVS 基准的增益 |
|---|---|---|---|
| 仅文本 | 46.4 | 基准 | 基准 |
| +1 示例 | 57.6 | +11.2 | +6.7 |
| +2 示例 | 62.2 | +15.8 | +9.7 |
| +3 个示例 | 65.0 | +18.6 | +11.2 |
| +4 个示例 | 65.7 | +19.3 | +11.5 (平台期) |
物体计数准确率#
SAM 3 通过分割所有实例提供精确的计数,这是 物体计数 中的常见需求:
| 基准测试 | 准确率 | MAE | 与最佳 MLLM 相比 |
|---|---|---|---|
| CountBench | 95.6% | 0.11 | 92.4% (Gemini 2.5) |
| PixMo-Count | 87.3% | 0.22 | 88.8% (Molmo-72B) |
SAM 3、SAM 2 与 YOLO 对比#
在此我们将 SAM 3 的功能与 SAM 2 和 YOLO26 模型进行比较:
| 功能 | SAM 3 | SAM 2 | YOLO26n-seg |
|---|---|---|---|
| 概念分割 | ✅ 来自文本/示例的所有实例 | ❌ 不支持 | ❌ 不支持 |
| 视觉分割 | ✅ 单个实例 (兼容 SAM 2) | ✅ 单个实例 | ✅ 所有实例 |
| 零样本能力 | ✅ 开放词汇 | ✅ 几何提示 | ❌ 闭合集 |
| 交互式修正 | ✅ 示例 + 点击 | ✅ 仅点击 | ❌ 不支持 |
| 视频追踪 | ✅ 带有身份的多目标 | ✅ 多目标 | ✅ 多目标 |
| LVIS Mask AP (零样本) | 47.0 | 不适用 | 不适用 |
| MOSEv2 J&F | 60.1 | 47.9 | 不适用 |
| 速度 (GPU, ms/im) | 2921 | 857 | 8.4 |
| 模型大小 | 3.45 GB | 162 MB (基础版) | 6.4 MB |
速度基于 NVIDIA RTX PRO 6000,使用 torch==2.9.1 和 ultralytics==8.4.19 进行基准测试。
关键要点:
- SAM 3:最适合开放词汇概念分割,通过文本或示例提示查找概念的所有实例
- SAM 2:最适合使用几何提示进行图像和视频中的交互式单目标分割
- YOLO26:最适合实时、高速分割,采用无 NMS 的端到端推理,可导出为多种格式,用于在 GPU、CPU 和边缘设备上部署
SAM 与 YOLO 的对比#
在大小、参数和 GPU 推理速度方面,对比 SAM 3、SAM 2、SAM、MobileSAM、FastSAM 与 Ultralytics YOLO 分割模型 (YOLOv8, YOLO11, YOLO26):
| 模型 | 大小 (MB) | 参数量 (M) | 速度 (GPU) (ms/im) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 1306 |
| Meta SAM2-b | 162 | 80.8 | 857 |
| Meta SAM2-t | 78.1 | 38.9 | 668 |
| Meta SAM3 | 3450 | 473.6 | 2921 |
| MobileSAM | MobileSAM | 10.1 | 605 |
| FastSAM-s 使用 YOLOv8 骨干网络 | 23.7 | 11.8 | 55.9 |
| Ultralytics YOLOv8n-seg | 6.7 (小 515 倍) | 3.4 (少 139.1 倍) | 17.4 (快 167 倍) |
| Ultralytics YOLO11n-seg | 5.9 (小 585 倍) | 2.9 (少 163.1 倍) | 12.6 (快 231 倍) |
| Ultralytics YOLO26n-seg | 6.4 (小 539 倍) | 2.7 (少 175.2 倍) | 8.4 (快 347 倍) |
此对比展示了 SAM 变体与 YOLO 分割模型在模型大小和速度上的显著差异。虽然 SAM 提供了独特的自动分割能力,但 YOLO 模型(特别是 YOLOv8n-seg、YOLO11n-seg 和 YOLO26n-seg)在尺寸更小、速度更快且计算效率更高。
测试在 NVIDIA RTX PRO 6000(96GB VRAM)上运行,使用 torch==2.9.1 和 ultralytics==8.4.19。要复现此测试:
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# Profile SAM3, SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt", "sam3.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# Profile FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# Profile YOLO models
for file_name in ["yolov8n-seg.pt", "yolo11n-seg.pt", "yolo26n-seg.pt"]:
model = YOLO(file_name)
model.info()
model(ASSETS)评估指标#
SAM 3 引入了专为 PCS 任务设计的新指标,以补充熟悉的衡量标准,如 F1 score、precision 和 recall。
分类门控 F1 (CGF1)#
结合定位和分类的主要指标:
CGF1 = 100 × pmF1 × IL_MCC
其中:
- pmF1 (正向宏 F1):衡量正样本上的定位质量
- IL_MCC (图像级马修相关系数):衡量二分类准确率(“该概念是否存在?”)
为什么选择这些指标?#
传统的 AP 指标不考虑校准,导致模型在实际应用中难以使用。通过仅评估置信度高于 0.5 的预测,SAM 3 的指标强制要求良好的校准,并模拟在交互式 predict 和 track 循环中的实际使用模式。
关键消融研究与见解#
存在头(Presence Head)的影响#
存在头将识别与定位解耦,提供了显著的改进:
| 配置 | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 无存在头 | 57.6 | 0.77 | 74.7 |
| 有存在头 | 63.3 | 0.82 | 77.1 |
存在头提供了 +5.7 CGF1 的提升 (+9.9%),主要改善了识别能力 (IL_MCC +6.5%)。
困难负样本的影响#
| 困难负样本/图像 | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 0 | 31.8 | 0.44 | 70.2 |
| 5 | 44.8 | 0.62 | 71.9 |
| 30 | 49.2 | 0.68 | 72.3 |
难负样本对于开放词汇识别至关重要,能将 IL_MCC 提升 54.5% (0.44 → 0.68)。
训练数据缩放#
| 数据源 | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 仅外部数据 | 30.9 | 0.46 | 66.3 |
| 外部数据 + 合成数据 | 39.7 | 0.57 | 70.6 |
| 外部数据 + 高质量数据 | 51.8 | 0.71 | 73.2 |
| 三者皆有 | 54.3 | 0.74 | 73.5 |
高质量的人工标注相比仅使用合成或外部数据能带来显著提升。关于数据质量实践的背景信息,请参阅 数据收集与标注。
应用#
SAM 3 的概念分割能力开启了新的应用场景:
- 内容审核:在媒体库中查找特定内容类型的所有实例
- 电子商务:在商品目录图片中分割特定类型的所有产品,支持自动标注
- 医学影像:识别特定组织类型或异常的所有出现位置
- 自动驾驶系统:按类别追踪所有交通标志、行人或车辆的实例
- 视频分析:计数并追踪所有穿着特定服装或执行特定动作的人员
- 数据集标注:快速标注罕见对象类别的所有实例
- 科学研究:量化并分析所有符合特定标准的样本
SAM 3 Agent:扩展语言推理#
SAM 3 可以与多模态大语言模型 (MLLM) 相结合,以处理需要推理的复杂查询,这在理念上类似于 OWLv2 和 T-Rex 等开放词汇系统。
推理任务表现#
| 基准测试 | 指标 | SAM 3 Agent (Gemini 2.5 Pro) | 之前最佳 |
|---|---|---|---|
| ReasonSeg (验证集) | gIoU | 76.0 | 65.0 (SoTA) |
| ReasonSeg (测试集) | gIoU | 73.8 | 61.3 (SoTA) |
| OmniLabel (验证集) | 亚太 (AP) | 46.7 | 36.5 (REAL) |
| RefCOCO+ | Acc | 91.2 | 89.3 (LISA) |
复杂查询示例#
SAM 3 Agent 可以处理需要推理的查询:
- “坐着但手中没有拿着礼品盒的人”
- “离摄像头最近且没戴项圈的狗”
- “比人手大的红色物体”
MLLM 向 SAM 3 提出简单的名词短语查询,分析返回的掩码,并进行迭代直到结果满足要求。
局限性#
虽然 SAM 3 代表了重大进步,但它仍存在一些局限性:
- 短语复杂性:最适合简单的名词短语;长指代表达式或复杂推理可能需要结合 MLLM
- 歧义处理:某些概念本质上仍然模棱两可(例如,“小窗户”,“舒适的房间”)
- 计算需求:比 YOLO 等专业检测模型更大、更慢
- 词汇范围:专注于原子级视觉概念;没有 MLLM 辅助时组合推理能力有限
- 罕见概念:在训练数据中未充分表示的极其罕见或细粒度概念上,性能可能会下降
引用#
@inproceedings{sam3_2025,
title = {SAM 3: Segment Anything with Concepts},
author = {Anonymous authors},
booktitle = {Submitted to ICLR 2026},
year = {2025},
url = {https://openreview.net/forum?id=r35clVtGzw},
note = {Paper ID: 4183, under double-blind review}
}常见问题解答#
SAM 3 是何时发布的?#
SAM 3 由 Meta 于 2025年11月20日 发布,并已在 8.3.237 版本 (PR #22897) 中完全集成到 Ultralytics 中。 预测模式 和 追踪模式 可使用完整功能支持。
SAM 3 是否已集成到 Ultralytics 中?#
Yes! SAM 3 is fully integrated into the Ultralytics Python package, including concept segmentation, SAM 2–style visual prompts, and multi-object video tracking. SAM 3 also powers the smart annotation feature on Ultralytics Platform, where you can annotate images with just a few clicks.
什么是可提示概念分割 (PCS)?#
PCS 是 SAM 3 中引入的一项新任务,用于分割图像或视频中视觉概念的所有实例。与针对特定对象实例的传统分割不同,PCS 会查找类别的所有出现位置。例如:
- 文本提示:“黄色校车” → 分割场景中所有黄色校车
- 图像示例:狗周围的框 → 分割图像中所有的狗
- 组合提示:“条纹猫” + 示例框 → 分割所有与示例相符的条纹猫
SAM 3 与 SAM 2 有何不同?#
| 功能 | SAM 2 | SAM 3 |
|---|---|---|
| 任务 | 每个提示对应单个对象 | 概念的所有实例 |
| 提示类型 | 点、框、掩码 | + 文本短语、图像示例 |
| 检测能力 | 需要外部检测器 | 内置开放词汇检测器 |
| 识别 | 仅基于几何形状 | 文本和视觉识别 |
| 架构 | 仅追踪器 | 带存在头 (presence head) 的检测器 + 追踪器 |
| 零样本性能 | 不适用(需要视觉提示) | LVIS 上 47.0 AP,在 SA-Co 上性能提升 2 倍 |
| 交互式修正 | 仅点击 | 点击 + 示例泛化 |
SAM 3 在保留 SAM 2 视觉提示向后兼容性的同时,增加了基于概念的功能。
SAM 3 使用哪些数据集进行训练?#
SAM 3 是在 Segment Anything with Concepts (SA-Co) 数据集上训练的:
训练数据:
- 520万张图像,包含 400万个唯一名词短语 (SA-Co/HQ) - 高质量人工标注
- 5.25万个视频,包含 2.48万个唯一名词短语 (SA-Co/VIDEO)
- 14亿个合成掩膜,涵盖 3800万个名词短语 (SA-Co/SYN)
- 15个外部数据集,并添加了难负样本 (SA-Co/EXT)
基准测试数据:
- 21.4万个唯一概念,涵盖 12.6万张图像/视频
- 概念数量比现有基准多 50 倍 (例如,LVIS 仅有约 4000 个概念)
- 对 SA-Co/Gold 进行三重标注,以衡量人类性能的界限
这种大规模和多样性使得 SAM 3 在开放词汇概念上具备卓越的零样本泛化能力。
SAM 3 与 YOLO26 在分割任务上有何区别?#
SAM 3 和 YOLO26 适用于不同的使用场景:
SAM 3 的优势:
- 开放词汇:通过文本提示即可分割任何概念,无需训练
- 零样本:可立即处理新类别
- 交互式:基于样本的细化可泛化到相似对象
- 基于概念:自动查找类别的所有实例
- 准确性:在 LVIS 零样本实例分割中达到 47.0 AP
YOLO26 的优势:
- 速度:凭借无需 NMS 的端到端设计,推理速度快几个数量级
- 效率:模型小 539 倍 (6.4MB vs 3.45GB)
- 资源友好:可在边缘设备和移动设备上运行
- 实时性:针对生产部署进行优化
建议:
- 如果需要灵活的开放词汇分割,且要查找由文本或示例描述的所有概念实例,请使用 SAM 3
- 如果类别已知,需要进行高速度的生产部署,请使用 YOLO26
- 如果需要通过几何提示进行交互式单对象分割,请使用 SAM 2
SAM 3 能处理复杂的语言查询吗?#
SAM 3 专为简单名词短语(例如“红苹果”、“戴帽子的男人”)设计。对于需要推理的复杂查询,请将 SAM 3 与多模态大语言模型(MLLM)组合为 SAM 3 Agent:
简单查询(原生 SAM 3):
- “黄色校车”
- “条纹猫”
- “戴红帽子的男人”
复杂查询(结合 MLLM 的 SAM 3 Agent):
- “坐着但没拿着礼品盒的人”
- “离镜头最近且没有项圈的狗”
- “比人手大的红色物体”
SAM 3 Agent 通过将 SAM 3 的分割能力与 MLLM 推理能力相结合,在 ReasonSeg 验证集上达到了 76.0 gIoU(相比之前的最佳水平 65.0,提升了 16.9%)。
SAM 3 的准确度与人类表现相比如何?#
在具有三重人工标注的 SA-Co/Gold 基准测试中:
- 人类下限:74.2 CGF1 (最保守标注者)
- SAM 3 性能:65.0 CGF1
- 成就:达到预估人类下限的 88%
- 人类上限:81.4 CGF1 (最宽松标注者)
SAM 3 在开放词汇概念分割上表现出色,接近人类水平的准确度。差距主要存在于模糊或主观的概念上(例如“小窗户”、“温馨的房间”)。