Link to this sectionSAM 3: تجزئة أي شيء باستخدام المفاهيم#
تم دمج SAM 3 بالكامل في حزمة Ultralytics بدءاً من الإصدار 8.3.237 (PR #22897). قم بالتثبيت أو الترقية باستخدام pip install -U ultralytics للوصول إلى جميع ميزات SAM 3 بما في ذلك تجزئة المفاهيم المستندة إلى النص، ومطالبات أمثلة الصور، وتتبع الفيديو.
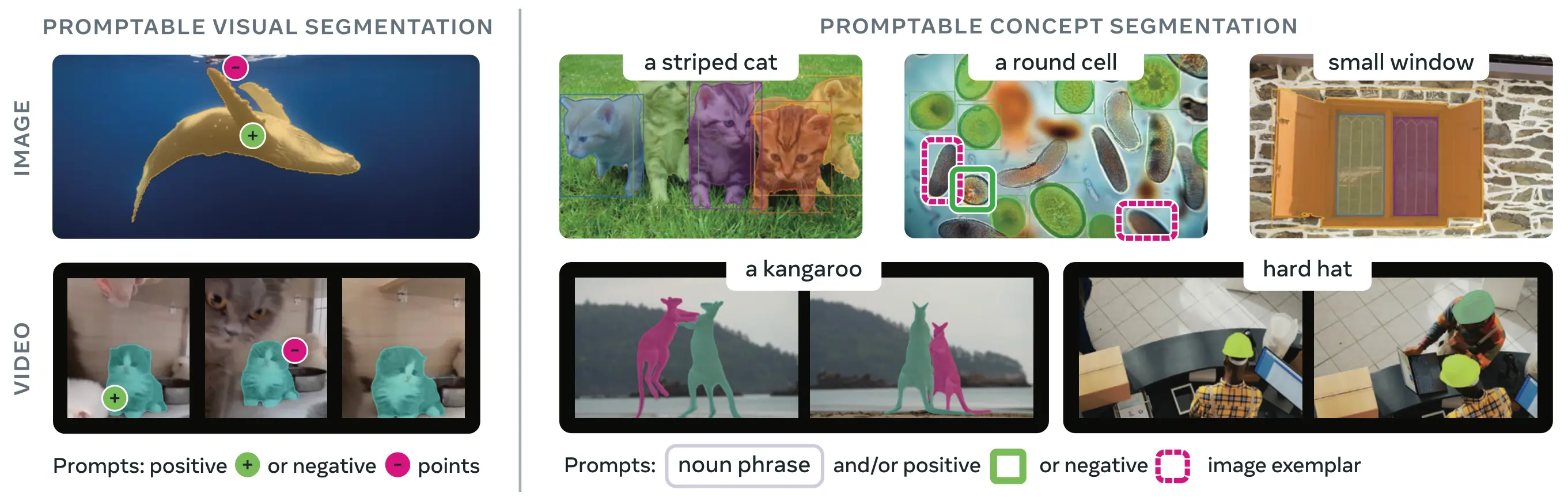
SAM 3 (نموذج تجزئة أي شيء 3) هو نموذج أساسي أصدرته Meta لـ تجزئة المفاهيم القابلة للمطالبة (PCS). بناءً على SAM 2، يقدم SAM 3 قدرة جديدة جوهرياً: اكتشاف وتجزئة وتتبع جميع حالات مفهوم بصري محدد بواسطة مطالبات نصية أو أمثلة صور أو كليهما. على عكس إصدارات SAM السابقة التي تجزئ كائنات مفردة لكل مطالبة، يمكن لـ SAM 3 العثور على وتجزئة كل ظهور لمفهوم يظهر في أي مكان في الصور أو مقاطع الفيديو، مما يتماشى مع أهداف المفردات المفتوحة في تجزئة المثيلات الحديثة.
Watch: How to Use Meta Segment Anything 3 with Ultralytics | Text-Prompt Segmentation on Images & Videos
تم دمج SAM 3 الآن بالكامل في حزمة ultralytics، مما يوفر دعماً أصلياً لتجزئة المفاهيم باستخدام مطالبات النص، ومطالبات أمثلة الصور، وقدرات تتبع الفيديو.
Link to this sectionنظرة عامة#
يحقق SAM 3 مكاسب في الأداء بمقدار ضعفين (2×) مقارنة بالأنظمة الحالية في تجزئة المفاهيم القابلة للمطالبة مع الحفاظ على قدرات SAM 2 وتحسينها لـ التجزئة البصرية التفاعلية. يتفوق النموذج في التجزئة ذات المفردات المفتوحة، مما يسمح للمستخدمين بتحديد المفاهيم باستخدام عبارات اسمية بسيطة (على سبيل المثال: "حافلة مدرسية صفراء"، "قطة مخططة") أو من خلال تقديم صور توضيحية للكائن المستهدف. تكمل هذه القدرات خطوط أنابيب جاهزة للإنتاج تعتمد على سير عمل توقع و تتبع مبسط.
Link to this sectionما هي تجزئة المفاهيم القابلة للمطالبة (PCS)؟#
تأخذ مهمة PCS مطالبة بالمفهوم كمدخل وتعيد أقنعة تجزئة بهويات فريدة لـ جميع مثيلات الكائنات المطابقة. يمكن أن تكون مطالبات المفهوم:
- نص: عبارات اسمية بسيطة مثل "تفاحة حمراء" أو "شخص يرتدي قبعة"، تشبه التعلم بدون أمثلة
- أمثلة الصور: مربعات إحاطة حول كائنات أمثلة (إيجابية أو سلبية) لتعميم سريع
- مدمجة: كل من النص وأمثلة الصور معاً للتحكم الدقيق
يختلف هذا عن المطالبات البصرية التقليدية (نقاط، مربعات، أقنعة) التي تجزئ فقط مثيل كائن واحد محدد، كما تم تعميمه بواسطة عائلة SAM الأصلية.
Link to this sectionمقاييس الأداء الرئيسية#
| المقياس | إنجاز SAM 3 |
|---|---|
| LVIS Zero-Shot Mask AP | 47.0 (مقابل أفضل سابق 38.5، تحسن بنسبة 22%+) |
| مقياس SA-Co | أفضل بمقدار ضعفين (2×) من الأنظمة الحالية |
| سرعة الاستدلال (H200 GPU) | 30 مللي ثانية لكل صورة مع 100+ كائن مكتشف |
| أداء الفيديو | شبه الوقت الفعلي لحوالي 5 كائنات متزامنة |
| مقياس MOSEv2 VOS | 60.1 J&F (زيادة 25.5%+ عن SAM 2.1، زيادة 17%+ عن الحالة السابقة للفن SOTA) |
| تحسين تفاعلي | تحسن +18.6 CGF1 بعد 3 مطالبات أمثلة |
| فجوة الأداء البشري | يحقق 88% من الحد الأدنى المقدر على SA-Co/Gold |
للحصول على سياق حول مقاييس النموذج والمقايضات في الإنتاج، راجع رؤى تقييم النموذج و مقاييس أداء YOLO.
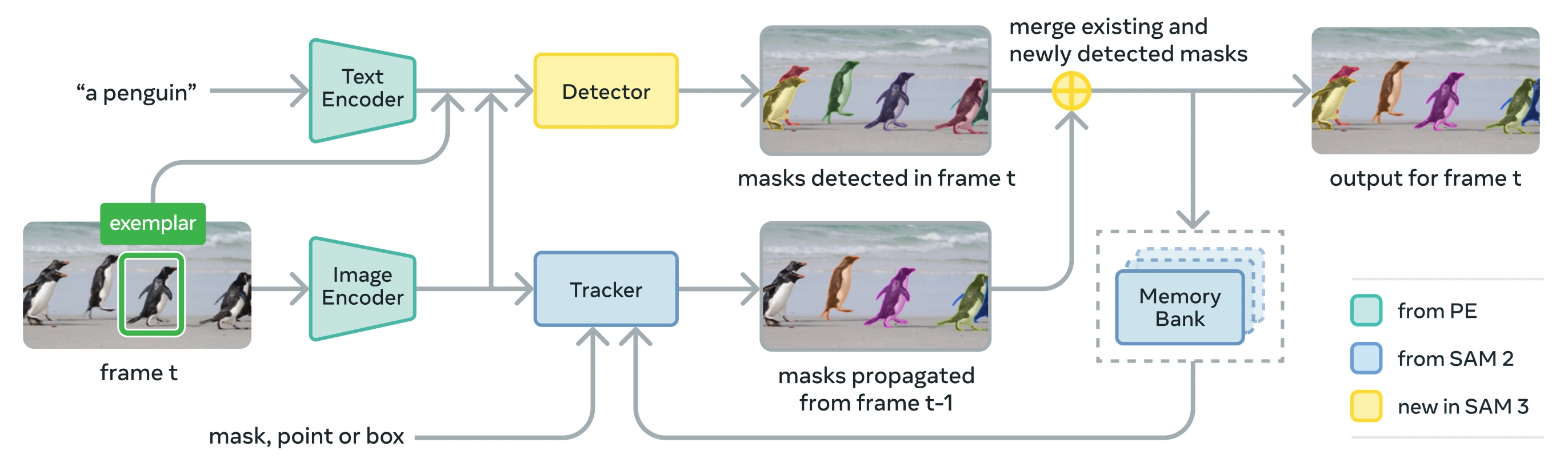
Link to this sectionالبنية الهندسية#
يتكون SAM 3 من مكتشف و متتبع يتشاركان في هيكل رؤية Perception Encoder (PE). يتجنب هذا التصميم المفكك تعارضات المهام مع تمكين كل من الاكتشاف على مستوى الصورة والتتبع على مستوى الفيديو، مع واجهة متوافقة مع استخدام Python و استخدام CLI في Ultralytics.
Link to this sectionالمكونات الأساسية#
-
مكتشف: هيكل يعتمد على DETR لاكتشاف المفهوم على مستوى الصورة
- مشفر نص للمطالبات بالعبارات الاسمية
- مشفر أمثلة للمطالبات القائمة على الصور
- مشفر دمج لتكييف ميزات الصورة مع المطالبات
- رأس وجود مبتكر يفصل التعرف ("ماذا") عن التوطين ("أين")
- رأس قناع لتوليد أقنعة تجزئة المثيلات
-
متتبع: تجزئة فيديو قائمة على الذاكرة موروثة من SAM 2
- مشفر المطالبة، فك تشفير القناع، مشفر الذاكرة
- بنك ذاكرة لتخزين مظهر الكائن عبر الإطارات
- تفكيك الغموض الزمني بمساعدة تقنيات مثل مرشح كالمان في إعدادات الكائنات المتعددة
-
رمز الوجود: رمز عالمي متعلم يتنبأ بما إذا كان المفهوم المستهدف موجوداً في الصورة/الإطار، مما يحسن الاكتشاف عن طريق فصل التعرف عن التوطين.
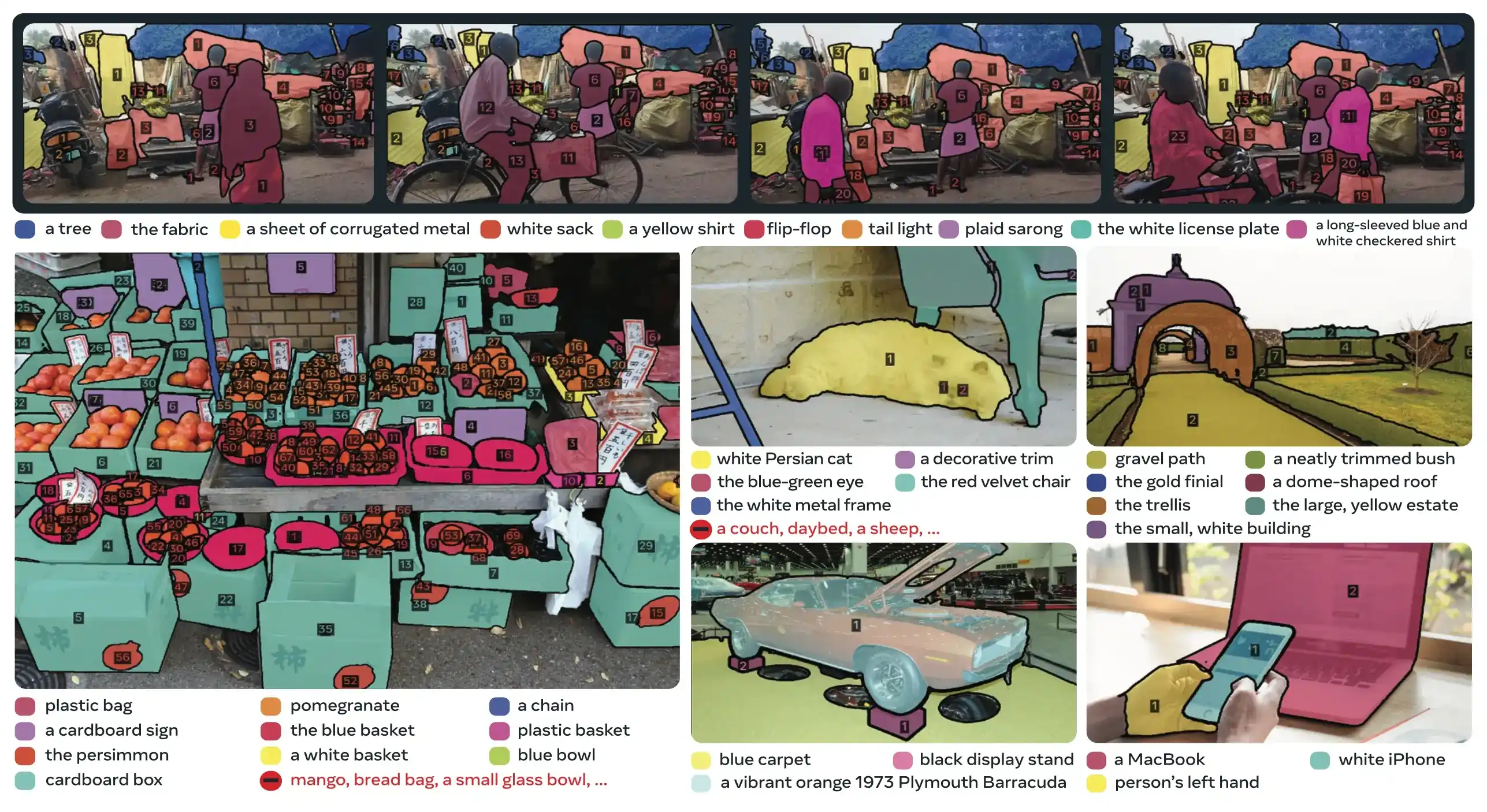
Link to this sectionالابتكارات الرئيسية#
- التعرف والتوطين المفككان: يتنبأ رأس الوجود بوجود المفهوم عالمياً، بينما تركز استعلامات الاقتراح فقط على التوطين، مما يتجنب الأهداف المتضاربة.
- مطالبات المفاهيم والمطالبات البصرية الموحدة: يدعم كلاً من PCS (مطالبات المفاهيم) و PVS (المطالبات البصرية مثل نقرات/مربعات SAM 2) في نموذج واحد.
- تحسين الأمثلة التفاعلي: يمكن للمستخدمين إضافة أمثلة صور إيجابية أو سلبية لتحسين النتائج بشكل تكراري، حيث يعمم النموذج على كائنات مشابهة بدلاً من مجرد تصحيح مثيلات فردية.
- تفكيك الغموض الزمني: يستخدم درجات اكتشاف masklet وإعادة المطالبة الدورية للتعامل مع الانسدادات، والمشاهد المزدحمة، وإخفاقات التتبع في الفيديو، بما يتماشى مع أفضل ممارسات تجزئة وتتبع المثيلات.
Link to this sectionمجموعة بيانات SA-Co#
تم تدريب SAM 3 على تجزئة أي شيء باستخدام المفاهيم (SA-Co)، وهي أكبر وأكثر مجموعات بيانات التجزئة تنوعاً لدى Meta حتى الآن، والتي تتوسع إلى ما هو أبعد من المقاييس الشائعة مثل COCO و LVIS.
Link to this sectionبيانات التدريب#
| مكون مجموعة البيانات | الوصف | النطاق |
|---|---|---|
| SA-Co/HQ | بيانات صور عالية الجودة مشروحة بشرياً من محرك بيانات ذو 4 مراحل | 5.2 مليون صورة، 4 مليون عبارة اسمية فريدة |
| SA-Co/SYN | مجموعة بيانات اصطناعية مصنفة بواسطة AI دون تدخل بشري | 38 مليون عبارة اسمية، 1.4 مليار قناع |
| SA-Co/EXT | 15 مجموعة بيانات خارجية معززة بسلبيات صعبة | يختلف حسب المصدر |
| SA-Co/VIDEO | تعليقات توضيحية للفيديو مع تتبع زمني | 52.5 ألف فيديو، 24.8 ألف عبارة اسمية فريدة |
Link to this sectionبيانات القياس#
يحتوي مقياس تقييم SA-Co على 214 ألف عبارة فريدة عبر 126 ألف صورة وفيديو، مما يوفر أكثر من 50 ضعفاً من المفاهيم مقارنة بالمقاييس الحالية. ويشمل:
- SA-Co/Gold: 7 مجالات، مشروحة ثلاثياً لقياس حدود الأداء البشري
- SA-Co/Silver: 10 مجالات، تعليق بشري مفرد
- SA-Co/Bronze و SA-Co/Bio: 9 مجموعات بيانات موجودة تم تكييفها لتجزئة المفاهيم
- SA-Co/VEval: مقياس فيديو بـ 3 مجالات (SA-V, YT-Temporal-1B, SmartGlasses)
Link to this sectionابتكارات محرك البيانات#
يحقق محرك بيانات SAM 3 القابل للتطوير (بشري + نموذج في الحلقة) ضعف إنتاجية التعليق (2×) من خلال:
- معلقو AI: نماذج تعتمد على Llama تقترح عبارات اسمية متنوعة بما في ذلك السلبيات الصعبة
- متحققو AI: نماذج LLMs متعددة الوسائط مضبوطة دقيقاً تتحقق من جودة القناع وشموليته بأداء يقارب الأداء البشري
- التنقيب النشط: يركز الجهد البشري على حالات الفشل الصعبة التي تكافح فيها AI
- مدفوع بالأنطولوجيا: يستفيد من أنطولوجيا كبيرة قائمة على Wikidata لتغطية المفاهيم
Link to this sectionالتثبيت#
SAM 3 متاح في Ultralytics الإصدار 8.3.237 وما بعده. قم بالتثبيت أو الترقية باستخدام:
pip install -U ultralyticsعلى عكس نماذج Ultralytics الأخرى، لا يتم تنزيل أوزان SAM 3 (sam3.pt) تلقائياً. يجب عليك أولاً طلب الوصول إلى أوزان النموذج على صفحة نموذج SAM 3 على Hugging Face ثم، بمجرد الموافقة، قم بتنزيل sam3.pt من تلك الصفحة. ضع ملف sam3.pt الذي تم تنزيله في دليل العمل الخاص بك أو حدد المسار الكامل عند تحميل النموذج.
إذا تلقيت الخطأ أعلاه أثناء التنبؤ، فهذا يعني أن لديك حزمة clip غير صحيحة مثبتة. قم بتثبيت حزمة clip الصحيحة عن طريق تشغيل ما يلي:
pip uninstall clip -y
pip install git+https://github.com/ultralytics/CLIP.gitLink to this sectionكيفية استخدام SAM 3: التنوع في تجزئة المفاهيم#
يدعم SAM 3 كلاً من مهام تجزئة المفاهيم القابلة للمطالبة (PCS) والتجزئة البصرية القابلة للمطالبة (PVS) من خلال واجهات متنبئ مختلفة:
Link to this sectionالمهام والنماذج المدعومة#
| نوع المهمة | أنواع المطالبات | المخرجات |
|---|---|---|
| تجزئة المفاهيم (PCS) | نص (عبارات اسمية)، أمثلة صور | جميع المثيلات التي تطابق المفهوم |
| التجزئة البصرية (PVS) | نقاط، مربعات، أقنعة | مثيل كائن واحد (نمط SAM 2) |
| تحسين تفاعلي | إضافة/إزالة أمثلة أو نقرات بشكل تكراري | تجزئة محسنة بدقة أفضل |
Link to this sectionأمثلة على تجزئة المفاهيم#
Link to this sectionالتجزئة باستخدام مطالبات النص#
يمكنك العثور على جميع حالات المفهوم وتقسيمها باستخدام وصف نصي. تتطلب التلميحات النصية واجهة SAM3SemanticPredictor.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor with configuration
overrides = dict(
conf=0.25,
task="segment",
mode="predict",
model="sam3.pt",
quantize=16, # Use FP16 for faster inference
save=True,
)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image once for multiple queries
predictor.set_image("path/to/image.jpg")
# Query with multiple text prompts
results = predictor(text=["person", "bus", "glasses"])
# Works with descriptive phrases
results = predictor(text=["person with red cloth", "person with blue cloth"])
# Query with a single concept
results = predictor(text=["a person"])Link to this sectionالتقسيم باستخدام أمثلة الصور#
استخدم صناديق الإحاطة كتلميحات مرئية للعثور على جميع الحالات المتشابهة. يتطلب هذا أيضاً SAM3SemanticPredictor للمطابقة القائمة على المفهوم.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16, save=True)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image
predictor.set_image("path/to/image.jpg")
# Provide bounding box examples to segment similar objects
results = predictor(bboxes=[[480.0, 290.0, 590.0, 650.0]])
# Multiple bounding boxes as exemplars of the same visual concept
results = predictor(bboxes=[[539, 599, 589, 639], [343, 267, 499, 662]])Link to this sectionالاستدلال القائم على الميزات من أجل الكفاءة#
قم باستخراج ميزات الصورة مرة واحدة وأعد استخدامها في استعلامات تقسيم متعددة لتحسين الكفاءة.
import cv2
from ultralytics.models.sam import SAM3SemanticPredictor
from ultralytics.utils.plotting import Annotator, colors
# Initialize predictors
overrides = dict(conf=0.50, task="segment", mode="predict", model="sam3.pt", verbose=False)
predictor = SAM3SemanticPredictor(overrides=overrides)
predictor2 = SAM3SemanticPredictor(overrides=overrides)
# Extract features from the first predictor
source = "path/to/image.jpg"
predictor.set_image(source)
src_shape = cv2.imread(source).shape[:2]
# Setup second predictor and reuse features
predictor2.setup_model()
# Perform inference using shared features with text prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, text=["person"])
# Perform inference using shared features with bounding box prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, bboxes=[[439, 437, 524, 709]])
# Visualize results
if masks is not None:
masks, boxes = masks.cpu().numpy(), boxes.cpu().numpy()
im = cv2.imread(source)
annotator = Annotator(im, pil=False)
annotator.masks(masks, [colors(x, True) for x in range(len(masks))])
cv2.imshow("result", annotator.result())
cv2.waitKey(0)Link to this sectionتقسيم مفاهيم الفيديو#
Link to this sectionتتبع المفاهيم عبر الفيديو باستخدام صناديق الإحاطة#
اكتشف وتتبع حالات الكائنات عبر إطارات الفيديو باستخدام تلميحات صناديق الإحاطة.
from ultralytics.models.sam import SAM3VideoPredictor
# Create video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16)
predictor = SAM3VideoPredictor(overrides=overrides)
# Track objects using bounding box prompts
results = predictor(source="path/to/video.mp4", bboxes=[[706.5, 442.5, 905.25, 555], [598, 635, 725, 750]], stream=True)
# Process and display results
for r in results:
r.show() # Display frame with segmentation masksLink to this sectionتتبع المفاهيم باستخدام التلميحات النصية#
تتبع جميع حالات المفاهيم المحددة نصياً عبر إطارات الفيديو.
from ultralytics.models.sam import SAM3VideoSemanticPredictor
# Initialize semantic video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=640, model="sam3.pt", quantize=16, save=True)
predictor = SAM3VideoSemanticPredictor(overrides=overrides)
# Track concepts using text prompts
results = predictor(source="path/to/video.mp4", text=["person", "bicycle"], stream=True)
# Process results
for r in results:
r.show() # Display frame with tracked objects
# Alternative: Track with bounding box prompts
results = predictor(
source="path/to/video.mp4",
bboxes=[[864, 383, 975, 620], [705, 229, 782, 402]],
labels=[1, 1], # Positive labels
stream=True,
)Link to this sectionالتلميحات المرئية (التوافق مع SAM 2)#
يحافظ SAM 3 على التوافق الكامل مع التلميحات المرئية في SAM 2 لتقسيم كائن واحد:
تعمل واجهة SAM الأساسية تماماً مثل SAM 2، حيث تقسم فقط المنطقة المحددة بواسطة التلميحات المرئية (نقاط، صناديق، أو أقنعة).
from ultralytics import SAM
model = SAM("sam3.pt")
# Single point prompt - segments object at specific location
results = model.predict(source="path/to/image.jpg", points=[900, 370], labels=[1])
results[0].show()
# Multiple points - segments single object with multiple point hints
results = model.predict(source="path/to/image.jpg", points=[[400, 370], [900, 370]], labels=[1, 1])
# Box prompt - segments object within bounding box
results = model.predict(source="path/to/image.jpg", bboxes=[100, 150, 300, 400])
results[0].show()سيقوم استخدام SAM("sam3.pt") مع التلميحات المرئية (نقاط/صناديق/أقنعة) بتقسيم الكائن المحدد فقط في ذلك الموقع، تماماً مثل SAM 2. لتقسيم جميع حالات المفهوم، استخدم SAM3SemanticPredictor مع تلميحات نصية أو أمثلة كما هو موضح أعلاه.
Link to this sectionمقاييس الأداء#
Link to this sectionتقسيم الصور#
يحقق SAM 3 نتائج متطورة عبر معايير قياسية متعددة، بما في ذلك مجموعات بيانات العالم الحقيقي مثل LVIS و COCO for segmentation:
| قياس الأداء (Benchmark) | المقياس | SAM 3 | أفضل نتيجة سابقة | التحسن |
|---|---|---|---|---|
| LVIS (zero-shot) | Mask AP | 47.0 | 38.5 | +22.1% |
| SA-Co/Gold | CGF1 | 65.0 | 34.3 (OWLv2) | +89.5% |
| COCO (zero-shot) | Box AP | 53.5 | 52.2 (T-Rex2) | +2.5% |
| ADE-847 (semantic seg) | mIoU | 14.7 | 9.2 (APE-D) | +59.8% |
| PascalConcept-59 | mIoU | 59.4 | 58.5 (APE-D) | +1.5% |
| Cityscapes (semantic seg) | mIoU | 65.1 | 44.2 (APE-D) | +47.3% |
استكشف خيارات مجموعات البيانات لإجراء تجارب سريعة في Ultralytics datasets.
Link to this sectionأداء تقسيم الفيديو#
يظهر SAM 3 تحسينات كبيرة مقارنة بـ SAM 2 وأفضل التقنيات السابقة عبر معايير الفيديو مثل DAVIS 2017 و YouTube-VOS:
| قياس الأداء (Benchmark) | المقياس | SAM 3 | SAM 2.1 L | التحسن |
|---|---|---|---|---|
| MOSEv2 | J&F | 60.1 | 47.9 | +25.5% |
| DAVIS 2017 | J&F | 92.0 | 90.7 | +1.4% |
| LVOSv2 | J&F | 88.2 | 79.6 | +10.8% |
| SA-V | J&F | 84.6 | 78.4 | +7.9% |
| YTVOS19 | J&F | 89.6 | 89.3 | +0.3% |
Link to this sectionالتكيف مع الأمثلة القليلة#
يتفوق SAM 3 في التكيف مع مجالات جديدة بأمثلة قليلة، وهو أمر مهم لسير عمل data-centric AI:
| قياس الأداء (Benchmark) | 0-shot AP | 10-shot AP | أفضل نتيجة سابقة (10-shot) |
|---|---|---|---|
| ODinW13 | 59.9 | 71.6 | 67.9 (gDino1.5-Pro) |
| RF100-VL | 14.3 | 35.7 | 33.7 (gDino-T) |
Link to this sectionفعالية التحسين التفاعلي#
يتقارب توجيه SAM 3 القائم على المفاهيم مع الأمثلة بسرعة أكبر بكثير من التوجيه المرئي:
| التلميحات المضافة | درجة CGF1 | المكسب مقابل النص فقط | المكسب مقابل خط أساس PVS |
|---|---|---|---|
| نص فقط | 46.4 | خط الأساس | خط الأساس |
| +1 مثال | 57.6 | +11.2 | +6.7 |
| +2 مثال | 62.2 | +15.8 | +9.7 |
| +3 أمثلة توضيحية | 65.0 | +18.6 | +11.2 |
| +4 أمثلة توضيحية | 65.7 | +19.3 | +11.5 (استقرار) |
Link to this sectionدقة عد الكائنات#
يوفر SAM 3 عدًا دقيقًا من خلال تقسيم جميع النماذج، وهو مطلب شائع في عد الكائنات:
| قياس الأداء (Benchmark) | الدقة | MAE | مقابل أفضل MLLM |
|---|---|---|---|
| CountBench | 95.6% | 0.11 | 92.4% (Gemini 2.5) |
| PixMo-Count | 87.3% | 0.22 | 88.8% (Molmo-72B) |
Link to this sectionمقارنة بين SAM 3 و SAM 2 و YOLO#
هنا نقارن قدرات SAM 3 مع نماذج SAM 2 و YOLO26:
| القدرة | SAM 3 | SAM 2 | YOLO26n-seg |
|---|---|---|---|
| تقسيم المفاهيم | ✅ جميع النماذج من النص/الأمثلة التوضيحية | ❌ غير مدعوم | ❌ غير مدعوم |
| التقسيم المرئي | ✅ نموذج فردي (متوافق مع SAM 2) | ✅ نموذج فردي | ✅ جميع النماذج |
| قدرة Zero-shot | ✅ مفردات مفتوحة | ✅ مطالبات هندسية | ❌ مجموعة مغلقة |
| تحسين تفاعلي | ✅ أمثلة توضيحية + نقرات | ✅ نقرات فقط | ❌ غير مدعوم |
| تتبع الفيديو | ✅ كائنات متعددة مع هويات | ✅ كائنات متعددة | ✅ كائنات متعددة |
| LVIS Mask AP (zero-shot) | 47.0 | غير متاح | غير متاح |
| MOSEv2 J&F | 60.1 | 47.9 | غير متاح |
| السرعة (GPU، مللي ثانية/صورة) | 2921 | 857 | 8.4 |
| حجم النموذج | 3.45 جيجابايت | 162 ميجابايت (أساسي) | 6.4 ميجابايت |
تم قياس السرعة على NVIDIA RTX PRO 6000 باستخدام torch==2.9.1 و ultralytics==8.4.19.
الاستنتاجات الرئيسية:
- SAM 3: الأفضل لتقسيم المفاهيم ذات المفردات المفتوحة، والعثور على جميع حالات المفهوم باستخدام مطالبات نصية أو أمثلة توضيحية
- SAM 2: الأفضل للتقسيم التفاعلي لكائن واحد في الصور والفيديوهات باستخدام مطالبات هندسية
- YOLO26: الأفضل للتقسيم فائق السرعة في الوقت الفعلي مع استنتاج شامل بدون NMS، قابل للتصدير إلى العديد من التنسيقات للنشر على وحدات معالجة الرسومات (GPUs)، ووحدات المعالجة المركزية (CPUs)، والأجهزة الطرفية
Link to this sectionمقارنة SAM مقابل YOLO#
مقارنة SAM 3 و SAM 2 و SAM و MobileSAM و FastSAM مع نماذج تقسيم Ultralytics YOLO (YOLOv8 و YOLO11 و YOLO26) من حيث الحجم والمعلمات وسرعة استنتاج GPU:
| النموذج | الحجم (ميغابايت) | المعلمات (مليون) | السرعة (GPU) (مللي ثانية/صورة) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 1306 |
| Meta SAM2-b | 162 | 80.8 | 857 |
| Meta SAM2-t | 78.1 | 38.9 | 668 |
| Meta SAM3 | 3450 | 473.6 | 2921 |
| MobileSAM | 40.7 | 10.1 | 605 |
| FastSAM-s مع YOLOv8 backbone | 23.7 | 11.8 | 55.9 |
| Ultralytics YOLOv8n-seg | 6.7 (أصغر بـ 515 مرة) | 3.4 (أقل بـ 139.1 مرة) | 17.4 (أسرع بـ 167 مرة) |
| Ultralytics YOLO11n-seg | 5.9 (أصغر بـ 585 مرة) | 2.9 (أقل بـ 163.1 مرة) | 12.6 (أسرع بـ 231 مرة) |
| Ultralytics YOLO26n-seg | 6.4 (أصغر بـ 539 مرة) | 2.7 (أقل بـ 175.2 مرة) | 8.4 (أسرع بـ 347 مرة) |
توضح هذه المقارنة الاختلافات الجوهرية في أحجام النماذج وسرعاتها بين متغيرات SAM ونماذج تقسيم YOLO. في حين يوفر SAM قدرات تقسيم تلقائية فريدة، فإن نماذج YOLO، وخاصة YOLOv8n-seg وYOLO11n-seg وYOLO26n-seg، أصغر حجماً وأسرع بكثير وأكثر كفاءة من الناحية الحسابية.
تم إجراء الاختبارات على NVIDIA RTX PRO 6000 مع 96 جيجابايت من VRAM باستخدام torch==2.9.1 و ultralytics==8.4.19. لإعادة إنتاج هذا الاختبار:
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# Profile SAM3, SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt", "sam3.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# Profile FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# Profile YOLO models
for file_name in ["yolov8n-seg.pt", "yolo11n-seg.pt", "yolo26n-seg.pt"]:
model = YOLO(file_name)
model.info()
model(ASSETS)Link to this sectionمقاييس التقييم#
يقدم SAM 3 مقاييس جديدة مصممة لمهمة PCS، مكملة للمقاييس المألوفة مثل درجة F1، والدقة، والاستدعاء.
Link to this sectionF1 المعتمد على التصنيف (CGF1)#
المقياس الأساسي الذي يجمع بين التوطين والتصنيف:
CGF1 = 100 × pmF1 × IL_MCC
حيث:
- pmF1 (Macro F1 الإيجابي): يقيس جودة التوطين في الأمثلة الإيجابية
- IL_MCC (معامل ارتباط ماثيوز على مستوى الصورة): يقيس دقة التصنيف الثنائي ("هل المفهوم موجود؟")
Link to this sectionلماذا هذه المقاييس؟#
لا تأخذ مقاييس AP التقليدية في الاعتبار المعايرة، مما يجعل النماذج صعبة الاستخدام في الواقع. من خلال تقييم التوقعات التي تزيد ثقتها عن 0.5 فقط، تفرض مقاييس SAM 3 معايرة جيدة وتحاكي أنماط الاستخدام الواقعية في دورات التنبؤ والتتبع التفاعلية.
Link to this sectionأهم الاستنتاجات والرؤى#
Link to this sectionتأثير رأس الوجود#
يعمل رأس الوجود على فصل التعرف عن التوطين، مما يوفر تحسينات كبيرة:
| الإعدادات | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| بدون وجود | 57.6 | 0.77 | 74.7 |
| مع وجود | 63.3 | 0.82 | 77.1 |
يوفر رأس الوجود تعزيزًا بنسبة +5.7 CGF1 (+9.9%)، مما يحسن بشكل أساسي قدرة التعرف (IL_MCC +6.5%).
Link to this sectionتأثير الأمثلة السلبية الصعبة#
| أمثلة سلبية صعبة/صورة | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 0 | 31.8 | 0.44 | 70.2 |
| 5 | 44.8 | 0.62 | 71.9 |
| 30 | 49.2 | 0.68 | 72.3 |
تعد الأمثلة السلبية الصعبة حاسمة للتعرف باستخدام مفردات مفتوحة، مما يحسن IL_MCC بنسبة 54.5% (0.44 ← 0.68).
Link to this sectionتوسيع نطاق بيانات التدريب#
| مصادر البيانات | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| خارجية فقط | 30.9 | 0.46 | 66.3 |
| خارجية + اصطناعية | 39.7 | 0.57 | 70.6 |
| خارجية + HQ | 51.8 | 0.71 | 73.2 |
| الثلاثة جميعاً | 54.3 | 0.74 | 73.5 |
توفر التعليقات البشرية عالية الجودة مكاسب كبيرة مقارنة بالبيانات الاصطناعية أو الخارجية وحدها. للحصول على خلفية حول ممارسات جودة البيانات، راجع جمع البيانات والتعليق عليها.
Link to this sectionالتطبيقات#
تتيح قدرة تجزئة المفاهيم في SAM 3 حالات استخدام جديدة:
- اعتدال المحتوى: العثور على جميع حالات أنواع محتوى محددة عبر مكتبات الوسائط
- التجارة الإلكترونية: تقسيم جميع المنتجات من نوع معين في صور الكتالوج، مع دعم التعليق التوضيحي التلقائي
- التصوير الطبي: تحديد جميع حالات أنواع معينة من الأنسجة أو التشوهات
- الأنظمة المستقلة: تتبع جميع حالات إشارات المرور، أو المشاة، أو المركبات حسب الفئة
- تحليلات الفيديو: حساب وتتبع جميع الأشخاص الذين يرتدون ملابس معينة أو يقومون بإجراءات محددة
- تعليق مجموعة البيانات: التعليق بسرعة على جميع حالات فئات الكائنات النادرة
- البحث العلمي: قياس وتحليل جميع العينات التي تطابق معايير محددة
Link to this sectionوكيل SAM 3: الاستدلال اللغوي الموسع#
يمكن دمج SAM 3 مع نماذج اللغة الكبيرة متعددة الوسائط (MLLMs) للتعامل مع الاستعلامات المعقدة التي تتطلب استدلالاً، بشكل مشابه لأنظمة المفردات المفتوحة مثل OWLv2 و T-Rex.
Link to this sectionالأداء في مهام الاستدلال#
| قياس الأداء (Benchmark) | المقياس | وكيل SAM 3 (Gemini 2.5 Pro) | أفضل نتيجة سابقة |
|---|---|---|---|
| ReasonSeg (التحقق) | gIoU | 76.0 | 65.0 (SoTA) |
| ReasonSeg (الاختبار) | gIoU | 73.8 | 61.3 (SoTA) |
| OmniLabel (التحقق) | آسيا والمحيط الهادئ (AP) | 46.7 | 36.5 (REAL) |
| RefCOCO+ | Acc | 91.2 | 89.3 (LISA) |
Link to this sectionأمثلة على الاستعلامات المعقدة#
يمكن لوكيل SAM 3 التعامل مع الاستعلامات التي تتطلب استدلالاً:
- "أشخاص يجلسون ولكن لا يحملون صندوق هدايا في أيديهم"
- "الكلب الأقرب إلى الكاميرا الذي لا يرتدي طوقاً"
- "أشياء حمراء أكبر من يد الشخص"
يقترح MLLM استعلامات عبارات اسمية بسيطة إلى SAM 3، ويحلل الأقنعة التي تم إرجاعها، ويكرر العملية حتى الوصول إلى الرضا.
Link to this sectionالقيود#
على الرغم من أن SAM 3 يمثل تقدماً كبيراً، إلا أن له قيوداً معينة:
- تعقيد العبارة: الأنسب للعبارات الاسمية البسيطة؛ قد تتطلب تعبيرات الإشارة الطويلة أو الاستدلال المعقد تكامل MLLM
- التعامل مع الغموض: تظل بعض المفاهيم غامضة بطبيعتها (على سبيل المثال، "نافذة صغيرة"، "غرفة مريحة")
- المتطلبات الحسابية: أكبر وأبطأ من نماذج الكشف المتخصصة مثل YOLO
- نطاق المفردات: يركز على المفاهيم البصرية الذرية؛ الاستدلال التركيبي محدود بدون مساعدة MLLM
- المفاهيم النادرة: قد يتدهور الأداء مع المفاهيم النادرة جداً أو الدقيقة التي لا يتم تمثيلها بشكل جيد في بيانات التدريب
Link to this sectionالاقتباس#
@inproceedings{sam3_2025,
title = {SAM 3: Segment Anything with Concepts},
author = {Anonymous authors},
booktitle = {Submitted to ICLR 2026},
year = {2025},
url = {https://openreview.net/forum?id=r35clVtGzw},
note = {Paper ID: 4183, under double-blind review}
}Link to this sectionالأسئلة الشائعة#
Link to this sectionمتى تم إصدار SAM 3؟#
تم إصدار SAM 3 بواسطة Meta في 20 نوفمبر 2025 وهو مدمج بالكامل في Ultralytics بدءاً من الإصدار 8.3.237 (PR #22897). يتوفر الدعم الكامل لـ وضع التنبؤ و وضع التتبع.
Link to this sectionهل SAM 3 مدمج في Ultralytics؟#
نعم! SAM 3 مدمج بالكامل في حزمة Python الخاصة بـ Ultralytics، بما في ذلك تجزئة المفاهيم، والمطالبات البصرية بنمط SAM 2، وتتبع الفيديو متعدد الكائنات. يعمل SAM 3 أيضاً على تشغيل ميزة التعليق الذكي على منصة Ultralytics، حيث يمكنك التعليق على الصور ببضع نقرات فقط.
Link to this sectionما هي تجزئة المفاهيم القابلة للمطالبة (PCS)؟#
PCS هي مهمة جديدة تم تقديمها في SAM 3 تقوم بتجزئة جميع حالات مفهوم بصري في صورة أو فيديو. على عكس التجزئة التقليدية التي تستهدف حالة كائن محددة، تجد PCS كل ظهور لفئة ما. على سبيل المثال:
- موجه نصي: "حافلة مدرسية صفراء" ← تجزئة جميع الحافلات المدرسية الصفراء في المشهد
- مثال صورة: مربع حول كلب واحد ← تجزئة جميع الكلاب في الصورة
- مدمج: "قطة مخططة" + مربع مثال ← تجزئة جميع القطط المخططة التي تطابق المثال
راجع الخلفية ذات الصلة حول اكتشاف الكائنات و تجزئة المثيل.
Link to this sectionكيف يختلف SAM 3 عن SAM 2؟#
| الميزة | SAM 2 | SAM 3 |
|---|---|---|
| المهمة | كائن واحد لكل مطالبة | جميع حالات المفهوم |
| أنواع المطالبات | نقاط، مربعات، أقنعة | + عبارات نصية، أمثلة صور |
| قدرة الكشف | تتطلب كاشف خارجي | كاشف مفردات مفتوحة مدمج |
| التعرف | يعتمد على الهندسة فقط | التعرف النصي والبصري |
| البنية | متتبع فقط | كاشف + متتبع مع رأس وجود |
| أداء الصفر (Zero-Shot) | غير متاح (يتطلب مطالبات بصرية) | 47.0 AP على LVIS، أفضل بمرتين على SA-Co |
| تحسين تفاعلي | نقرات فقط | نقرات + تعميم المثال |
يحافظ SAM 3 على التوافق مع الإصدارات السابقة مع المطالبة البصرية SAM 2 مع إضافة قدرات قائمة على المفاهيم.
Link to this sectionما هي مجموعات البيانات المستخدمة لتدريب SAM 3؟#
تم تدريب SAM 3 على مجموعة بيانات Segment Anything with Concepts (SA-Co):
بيانات التدريب:
- 5.2 مليون صورة مع 4 مليون عبارة اسمية فريدة (SA-Co/HQ) - تعليقات توضيحية بشرية عالية الجودة
- 52.5 ألف مقطع فيديو مع 24.8 ألف عبارة اسمية فريدة (SA-Co/VIDEO)
- 1.4 مليار قناع اصطناعي عبر 38 مليون عبارة اسمية (SA-Co/SYN)
- 15 مجموعة بيانات خارجية مُثراة بسلبيات صعبة (SA-Co/EXT)
بيانات القياس المعياري:
- 214 ألف مفهوم فريد عبر 126 ألف صورة/فيديو
- 50 ضعف من المفاهيم مقارنة بالمعايير الحالية (على سبيل المثال، LVIS تحتوي على حوالي 4 آلاف مفهوم)
- تعليق توضيحي ثلاثي على SA-Co/Gold لقياس حدود الأداء البشري
هذا النطاق الهائل والتنوع يُمكّن SAM 3 من تحقيق تعميم فائق بنظام Zero-shot عبر مفاهيم مفتوحة المفردات.
Link to this sectionكيف يقارن SAM 3 بنموذج YOLO26 من حيث التقسيم؟#
يخدم كل من SAM 3 و YOLO26 حالات استخدام مختلفة:
مزايا SAM 3:
- مفتوح المفردات: يقوم بتقسيم أي مفهوم عبر مطالبات نصية بدون تدريب
- Zero-shot: يعمل على فئات جديدة فوراً
- تفاعلي: التحسين القائم على الأمثلة يعمم على كائنات مشابهة
- قائم على المفاهيم: يعثر تلقائياً على جميع حالات فئة معينة
- الدقة: 47.0 AP في تقسيم حالات LVIS بنظام Zero-shot
مزايا YOLO26:
- السرعة: استنتاج أسرع بأوامر من حيث الحجم مع تصميم شامل من البداية إلى النهاية بدون NMS
- الكفاءة: نماذج أصغر بـ 539 ضعف (6.4 ميجابايت مقابل 3.45 جيجابايت)
- صديق للموارد: يعمل على أجهزة الحافة والأجهزة المحمولة
- الوقت الفعلي: مُحسّن لنشر الإنتاج
توصية:
- استخدم SAM 3 للتقسيم المرن مفتوح المفردات حيث تحتاج إلى العثور على جميع حالات المفاهيم الموصوفة بنصوص أو أمثلة
- استخدم YOLO26 لعمليات النشر الإنتاجية عالية السرعة حيث تكون الفئات معروفة مسبقاً
- استخدم SAM 2 للتقسيم التفاعلي لكائن واحد باستخدام مطالبات هندسية
Link to this sectionهل يستطيع SAM 3 التعامل مع استعلامات لغوية معقدة؟#
تم تصميم SAM 3 للعبارات الاسمية البسيطة (مثل "تفاحة حمراء"، "شخص يرتدي قبعة"). بالنسبة للاستعلامات المعقدة التي تتطلب استدلالاً، ادمج SAM 3 مع نموذج MLLM كـ SAM 3 Agent:
استعلامات بسيطة (SAM 3 الأصلي):
- "حافلة مدرسة صفراء"
- "قطة مخططة"
- "شخص يرتدي قبعة حمراء"
استعلامات معقدة (SAM 3 Agent مع MLLM):
- "أشخاص جالون ولكن لا يحملون صندوق هدايا"
- "الكلب الأقرب للكاميرا بدون طوق"
- "أشياء حمراء أكبر من يد الشخص"
يحقق SAM 3 Agent نسبة 76.0 gIoU في التحقق من صحة ReasonSeg (مقابل 65.0 كأفضل نتيجة سابقة، تحسن بنسبة 16.9%+) من خلال الجمع بين تقسيم SAM 3 وقدرات الاستدلال لدى MLLM.
Link to this sectionما مدى دقة SAM 3 مقارنة بالأداء البشري؟#
في معيار SA-Co/Gold مع تعليق توضيحي بشري ثلاثي:
- الحد الأدنى البشري: 74.2 CGF1 (المُعلق الأكثر تحفظاً)
- أداء SAM 3: 65.0 CGF1
- الإنجاز: 88% من الحد الأدنى البشري المقدر
- الحد الأعلى البشري: 81.4 CGF1 (المُعلق الأكثر تحرراً)
يحقق SAM 3 أداءً قوياً يقترب من دقة المستوى البشري في تقسيم المفاهيم مفتوحة المفردات، مع وجود الفجوة بشكل أساسي في المفاهيم الغامضة أو الذاتية (مثل "نافذة صغيرة"، "غرفة مريحة").