Ultralytics YOLO11
Aperçu
YOLO11 a été publié par Ultralytics le 10 septembre 2024, offrant une excellente précision, rapidité et efficacité. S'appuyant sur les avancées impressionnantes des versions précédentes de YOLO, YOLO11 introduit des améliorations significatives dans l'architecture et les méthodes d'entraînement, ce qui en fait un choix polyvalent pour un large éventail de tâches de vision par ordinateur. Pour le dernier modèle Ultralytics avec inférence de bout en bout sans NMS et déploiement optimisé en périphérie, voir YOLO26.
Ultralytics YOLO11 🚀 Podcast généré par NotebookLM
Regarder : Comment utiliser Ultralytics YOLO11 pour la détection et le suivi d'objets | Comment effectuer un benchmark | YOLO11 LANCÉ🚀
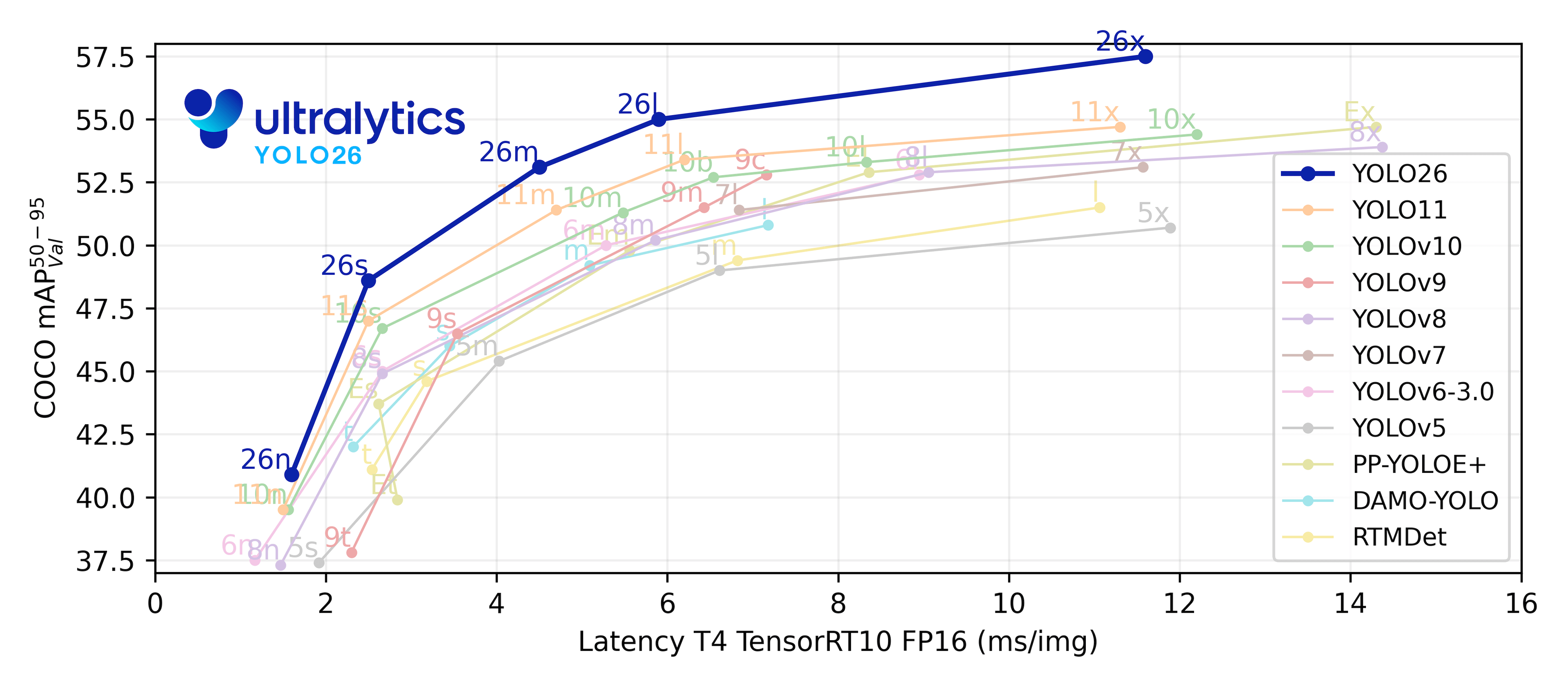
Essayer Ultralytics
Explorez et exécutez YOLO11 directement sur Ultralytics .
Principales caractéristiques
- Extraction de caractéristiques améliorée : YOLO11 utilise une backbone et une architecture de neck améliorées, ce qui améliore les capacités d'extraction de caractéristiques pour une détection d'objets plus précise et une performance de tâches complexes.
- Optimisé pour l'efficacité et la vitesse : YOLO11 introduit des conceptions architecturales raffinées et des pipelines d'entraînement optimisés, offrant des vitesses de traitement plus rapides et maintenant un équilibre optimal entre la précision et les performances.
- Plus grande précision avec moins de paramètres : Grâce aux progrès de la conception des modèles, YOLO11m atteint une précision moyenne moyenne (mAP) plus élevée sur l'ensemble de données COCO tout en utilisant 22 % moins de paramètres que YOLOv8m, ce qui le rend efficace sur le plan computationnel sans compromettre la précision.
- Adaptabilité à tous les environnements : YOLO11 peut être déployé de manière transparente dans divers environnements, y compris les appareils périphériques, les plateformes cloud et les systèmes prenant en charge les GPU NVIDIA, garantissant une flexibilité maximale.
- Large éventail de tâches prises en charge : Qu'il s'agisse de la détection d'objets, de la segmentation d'instances, de la classification d'images, de l'estimation de pose ou de la détection d'objets orientés (OBB), YOLO11 est conçu pour répondre à un ensemble diversifié de défis en matière de vision par ordinateur.
Tâches et modes pris en charge
YOLO11 s'appuie sur la gamme de modèles polyvalents établie par les versions antérieures d'Ultralytics YOLO, offrant une prise en charge améliorée pour diverses tâches de vision par ordinateur :
| Modèle | Noms de fichiers | Tâche | Inférence | Validation | Entraînement | Exporter |
|---|---|---|---|---|---|---|
| YOLO11 | yolo11n.pt yolo11s.pt yolo11m.pt yolo11l.pt yolo11x.pt | Détection | ✅ | ✅ | ✅ | ✅ |
| YOLO11-seg | yolo11n-seg.pt yolo11s-seg.pt yolo11m-seg.pt yolo11l-seg.pt yolo11x-seg.pt | Segmentation d'instance | ✅ | ✅ | ✅ | ✅ |
| YOLO11-pose | yolo11n-pose.pt yolo11s-pose.pt yolo11m-pose.pt yolo11l-pose.pt yolo11x-pose.pt | Pose/Points clés | ✅ | ✅ | ✅ | ✅ |
| YOLO11-obb | yolo11n-obb.pt yolo11s-obb.pt yolo11m-obb.pt yolo11l-obb.pt yolo11x-obb.pt | Détection orientée | ✅ | ✅ | ✅ | ✅ |
| YOLO11-cls | yolo11n-cls.pt yolo11s-cls.pt yolo11m-cls.pt yolo11l-cls.pt yolo11x-cls.pt | Classification | ✅ | ✅ | ✅ | ✅ |
Ce tableau donne un aperçu des variantes du modèle YOLO11, présentant leur applicabilité dans des tâches spécifiques et leur compatibilité avec les modes de fonctionnement tels que l'inférence, la validation, l'entraînement et l'exportation. Cette flexibilité rend YOLO11 adapté à un large éventail d'applications dans le domaine de la vision par ordinateur, de la détection en temps réel aux tâches de segmentation complexes.
Mesures de performance
Performance
Consultez les Docs de détection pour des exemples d'utilisation avec ces modèles entraînés sur COCO, qui incluent 80 classes pré-entraînées.
| Modèle | Taille (pixels) | mAPval 50-95 | Vitesse CPU ONNX (ms) | Vitesse T4 TensorRT10 (ms) | paramètres (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLO11n | 640 | 39.5 | 56.1 ± 0.8 | 1.5 ± 0.0 | 2.6 | 6.5 |
| YOLO11s | 640 | 47.0 | 90.0 ± 1.2 | 2.5 ± 0.0 | 9.4 | 21.5 |
| YOLO11m | 640 | 51.5 | 183.2 ± 2.0 | 4.7 ± 0.1 | 20.1 | 68.0 |
| YOLO11l | 640 | 53.4 | 238.6 ± 1.4 | 6.2 ± 0.1 | 25.3 | 86.9 |
| YOLO11x | 640 | 54.7 | 462.8 ± 6.7 | 11.3 ± 0.2 | 56.9 | 194.9 |
Consultez les Docs de segmentation pour des exemples d'utilisation avec ces modèles entraînés sur COCO, qui incluent 80 classes pré-entraînées.
| Modèle | Taille (pixels) | mAPbox 50-95 | mAPmask 50-95 | Vitesse CPU ONNX (ms) | Vitesse T4 TensorRT10 (ms) | paramètres (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO11n-seg | 640 | 38.9 | 32.0 | 65.9 ± 1.1 | 1.8 ± 0.0 | 2.9 | 9.7 |
| YOLO11s-seg | 640 | 46.6 | 37.8 | 117.6 ± 4.9 | 2.9 ± 0.0 | 10.1 | 33.0 |
| YOLO11m-seg | 640 | 51.5 | 41.5 | 281.6 ± 1.2 | 6.3 ± 0.1 | 22.4 | 113.2 |
| YOLO11l-seg | 640 | 53.4 | 42.9 | 344.2 ± 3.2 | 7.8 ± 0.2 | 27.6 | 132.2 |
| YOLO11x-seg | 640 | 54.7 | 43.8 | 664.5 ± 3.2 | 15.8 ± 0.7 | 62.1 | 296.4 |
Consultez les Docs de classification pour des exemples d'utilisation avec ces modèles entraînés sur ImageNet, qui incluent 1000 classes pré-entraînées.
| Modèle | Taille (pixels) | acc top1 | acc top5 | Vitesse CPU ONNX (ms) | Vitesse T4 TensorRT10 (ms) | paramètres (M) | FLOPs (B) à 224 |
|---|---|---|---|---|---|---|---|
| YOLO11n-cls | 224 | 70.0 | 89.4 | 5.0 ± 0.3 | 1.1 ± 0.0 | 2.8 | 0.5 |
| YOLO11s-cls | 224 | 75.4 | 92.7 | 7.9 ± 0.2 | 1.3 ± 0.0 | 6.7 | 1.6 |
| YOLO11m-cls | 224 | 77.3 | 93.9 | 17.2 ± 0.4 | 2.0 ± 0.0 | 11.6 | 4.9 |
| YOLO11l-cls | 224 | 78.3 | 94.3 | 23.2 ± 0.3 | 2.8 ± 0.0 | 14.1 | 6.2 |
| YOLO11x-cls | 224 | 79.5 | 94.9 | 41.4 ± 0.9 | 3.8 ± 0.0 | 29.6 | 13.6 |
Consultez les Docs d'estimation de pose pour des exemples d'utilisation avec ces modèles entraînés sur COCO, qui incluent 1 classe pré-entraînée, 'personne'.
| Modèle | Taille (pixels) | mAPpose 50-95 | mAPpose 50 | Vitesse CPU ONNX (ms) | Vitesse T4 TensorRT10 (ms) | paramètres (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO11n-pose | 640 | 50.0 | 81.0 | 52.4 ± 0.5 | 1.7 ± 0.0 | 2.9 | 7.4 |
| YOLO11s-pose | 640 | 58.9 | 86.3 | 90.5 ± 0.6 | 2.6 ± 0.0 | 9.9 | 23.1 |
| YOLO11m-pose | 640 | 64.9 | 89.4 | 187.3 ± 0.8 | 4.9 ± 0.1 | 20.9 | 71.4 |
| YOLO11l-pose | 640 | 66.1 | 89.9 | 247.7 ± 1.1 | 6.4 ± 0.1 | 26.1 | 90.3 |
| YOLO11x-pose | 640 | 69.5 | 91.1 | 488.0 ± 13.9 | 12.1 ± 0.2 | 58.8 | 202.8 |
Consultez les Docs de détection orientée pour des exemples d'utilisation avec ces modèles entraînés sur DOTAv1, qui incluent 15 classes pré-entraînées.
| Modèle | Taille (pixels) | mAPtest 50 | Vitesse CPU ONNX (ms) | Vitesse T4 TensorRT10 (ms) | paramètres (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLO11n-obb | 1024 | 78.4 | 117.6 ± 0.8 | 4.4 ± 0.0 | 2.7 | 16.8 |
| YOLO11s-obb | 1024 | 79.5 | 219.4 ± 4.0 | 5.1 ± 0.0 | 9.7 | 57.1 |
| YOLO11m-obb | 1024 | 80.9 | 562.8 ± 2.9 | 10.1 ± 0.4 | 20.9 | 182.8 |
| YOLO11l-obb | 1024 | 81.0 | 712.5 ± 5.0 | 13.5 ± 0.6 | 26.1 | 231.2 |
| YOLO11x-obb | 1024 | 81.3 | 1408.6 ± 7.7 | 28.6 ± 1.0 | 58.8 | 519.1 |
Exemples d'utilisation
Cette section fournit des exemples simples d'entraînement et d'inférence YOLO11. Pour une documentation complète sur ces modes et d'autres, consultez les pages de documentation Prédire, Entraîner, Valider et Exporter.
Veuillez noter que l'exemple ci-dessous concerne les modèles Detect YOLO11 pour la détection d'objets. Pour les tâches supplémentaires prises en charge, consultez les documents Segment, Classify, OBB et Pose.
Exemple
PyTorch pré-entraînés *.pt ainsi que la configuration des modèles *.yaml fichiers peuvent être passés aux YOLO() class pour créer une instance de modèle en python :
from ultralytics import YOLO
# Load a COCO-pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLO11n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")
Des commandes CLI sont disponibles pour exécuter directement les modèles :
# Load a COCO-pretrained YOLO11n model and train it on the COCO8 example dataset for 100 epochs
yolo train model=yolo11n.pt data=coco8.yaml epochs=100 imgsz=640
# Load a COCO-pretrained YOLO11n model and run inference on the 'bus.jpg' image
yolo predict model=yolo11n.pt source=path/to/bus.jpg
Citations et remerciements
Publication Ultralytics YOLO11
Ultralytics n'a pas publié d'article de recherche formel pour YOLO11 en raison de la nature évolutive rapide des modèles. Nous nous concentrons sur l'avancement de la technologie et la simplification de son utilisation, plutôt que sur la production d'une documentation statique. Pour obtenir les informations les plus récentes sur l'architecture, les fonctionnalités et l'utilisation de YOLO, veuillez consulter notre dépôt GitHub et notre documentation.
Si vous utilisez YOLO11 ou tout autre logiciel de ce dépôt dans votre travail, veuillez le citer en utilisant le format suivant :
@software{yolo11_ultralytics,
author = {Glenn Jocher and Jing Qiu},
title = {Ultralytics YOLO11},
version = {11.0.0},
year = {2024},
url = {https://github.com/ultralytics/ultralytics},
orcid = {0000-0001-5950-6979, 0000-0003-3783-7069},
license = {AGPL-3.0}
}
Veuillez noter que le DOI est en attente et sera ajouté à la citation dès qu'il sera disponible. Les modèles YOLO11 sont fournis sous licences AGPL-3.0 et Enterprise.
FAQ
Quelles sont les améliorations clés d'Ultralytics YOLO11 par rapport à YOLOv8 ?
Ultralytics YOLO11 introduit plusieurs avancées significatives par rapport à YOLOv8. Les améliorations clés incluent :
- Extraction de caractéristiques améliorée : YOLO11 utilise une architecture dorsale et de cou améliorée, ce qui renforce les capacités d'extraction de caractéristiques pour une détection d'objets plus précise.
- Efficacité et vitesse optimisées : Des conceptions architecturales raffinées et des pipelines d'entraînement optimisés offrent des vitesses de traitement plus rapides tout en maintenant un équilibre entre la précision et les performances.
- Plus grande précision avec moins de paramètres : YOLO11m atteint une précision moyenne (mAP) plus élevée sur l'ensemble de données COCO avec 22 % moins de paramètres que YOLOv8m, ce qui le rend efficace sur le plan computationnel sans compromettre la précision.
- Adaptabilité à différents environnements : YOLO11 peut être déployé dans divers environnements, y compris les appareils périphériques, les plateformes cloud et les systèmes prenant en charge les GPU NVIDIA.
- Large éventail de tâches prises en charge : YOLO11 prend en charge diverses tâches de vision par ordinateur telles que la détection d'objets, la segmentation d'instances, la classification d'images, l'estimation de pose et la détection d'objets orientés (OBB).
Comment puis-je entraîner un modèle YOLO11 pour la détection d'objets ?
L'entraînement d'un modèle YOLO11 pour la détection d'objets peut être effectué à l'aide de commandes python ou CLI. Vous trouverez ci-dessous des exemples pour les deux méthodes :
Exemple
from ultralytics import YOLO
# Load a COCO-pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Load a COCO-pretrained YOLO11n model and train it on the COCO8 example dataset for 100 epochs
yolo train model=yolo11n.pt data=coco8.yaml epochs=100 imgsz=640
Pour des instructions plus détaillées, consultez la documentation Train.
Quelles tâches les modèles YOLO11 peuvent-ils effectuer ?
Les modèles YOLO11 sont polyvalents et prennent en charge un large éventail de tâches de vision par ordinateur, notamment :
- Détection d'objets : Identification et localisation d'objets dans une image.
- Segmentation d'instance : Détection d'objets et délimitation de leurs frontières.
- Classification d'images : Classement des images dans des classes prédéfinies.
- Estimation de la pose : Détection et suivi des points clés sur le corps humain.
- Détection d'objets orientés (OBB) : Détection d'objets avec rotation pour une plus grande précision.
Pour plus d'informations sur chaque tâche, consultez la documentation Détection, Segmentation d'instance, Classification, Estimation de la pose et Détection orientée.
Comment YOLO11 atteint-il une plus grande précision avec moins de paramètres ?
YOLO11 atteint une plus grande précision avec moins de paramètres grâce aux avancées dans la conception du modèle et les techniques d'optimisation. L'architecture améliorée permet une extraction et un traitement efficaces des caractéristiques, ce qui se traduit par une moyenne de précision moyenne (mAP) plus élevée sur des ensembles de données comme COCO tout en utilisant 22 % de paramètres en moins que YOLOv8m. Cela rend YOLO11 efficace sur le plan du calcul sans compromettre la précision, ce qui le rend adapté au déploiement sur des appareils aux ressources limitées.
YOLO11 peut-il être déployé sur des appareils périphériques ?
Oui, YOLO11 est conçu pour s'adapter à divers environnements, y compris les appareils périphériques. Son architecture optimisée et ses capacités de traitement efficaces le rendent approprié pour un déploiement sur des appareils périphériques, des plateformes cloud et des systèmes prenant en charge les GPU NVIDIA. Cette flexibilité garantit que YOLO11 peut être utilisé dans diverses applications, de la détection en temps réel sur les appareils mobiles aux tâches de segmentation complexes dans les environnements cloud. Pour plus de détails sur les options de déploiement, consultez la documentation Export.





