De belangrijkste stappen in een computervisieproject begrijpen
Inleiding
Computer vision is een deelgebied van kunstmatige intelligentie (AI) dat computers helpt om de wereld te zien en te begrijpen zoals mensen dat doen. Het verwerkt en analyseert afbeeldingen of video's om informatie te extraheren, patronen te herkennen en beslissingen te nemen op basis van die gegevens.
Computer vision-technieken zoals objectdetectie, beeldclassificatie en segmentatie kunnen worden toegepast in verschillende sectoren, van autonoom rijden tot medische beeldvorming, om waardevolle inzichten te verkrijgen.

Working on your own computer vision projects is a great way to understand and learn more about computer vision. However, a computer vision project can consist of many steps, and it might seem confusing at first. By the end of this guide, you'll be familiar with the steps involved in a computer vision project. We'll walk through everything from the beginning to the end of a project, explaining why each part is important. Let's get started and make your computer vision project a success!
Een overzicht van een computervisieproject
Before discussing the details of each step involved in a computer vision project, let's look at the overall process. If you started a computer vision project today, you'd take the following steps:
- Your first priority would be to understand your project's requirements.
- Then, you'd collect and accurately label the images that will help train your model.
- Next, you'd clean your data and apply augmentation techniques to prepare it for model training.
- After model training, you'd thoroughly test and evaluate your model to make sure it performs consistently under different conditions.
- Finally, you'd deploy your model into the real world and update it based on new insights and feedback.
.jpeg)
Nu we weten wat we kunnen verwachten, duiken we meteen in de stappen om je project vooruit te helpen.
Step 1: Defining Your Project's Goals
The first step in any computer vision project is clearly defining the problem you're trying to solve. Knowing the end goal helps you start to build a solution. This is especially true when it comes to computer vision because your project's objective will directly affect which computer vision task you need to focus on.
Hier volgen enkele voorbeelden van projectdoelen en de computervisietaken die gebruikt kunnen worden om deze doelen te bereiken:
-
Doelstelling: Het ontwikkelen van een systeem dat de stroom van verschillende voertuigtypes op snelwegen kan bewaken en beheren, waardoor het verkeersbeheer en de veiligheid verbeteren.
- Computer Vision-taak: Objectdetectie is ideaal voor verkeersmonitoring omdat het efficiënt meerdere voertuigen lokaliseert en identificeert. Het is rekenkundig minder veeleisend dan beeldsegmentatie, dat onnodige details oplevert voor deze taak, waardoor een snellere real-time analyse mogelijk is.
-
Doelstelling: Het ontwikkelen van een hulpmiddel dat radiologen helpt door nauwkeurige contouren op pixelniveau te geven van tumoren in medische beeldvormingsscans.
- Computer Vision Taak: Beeldsegmentatie is geschikt voor medische beeldvorming omdat het nauwkeurige en gedetailleerde grenzen van tumoren oplevert die cruciaal zijn voor het beoordelen van de grootte, vorm en behandelplanning.
-
Doel: Een digitaal systeem maken dat verschillende documenten categoriseert (bijv. facturen, ontvangstbewijzen, juridisch papierwerk) om de efficiëntie van de organisatie en het terugvinden van documenten te verbeteren.
- Computer Vision taak: Beeldclassificatie is hier ideaal omdat het één document per keer behandelt, zonder rekening te hoeven houden met de positie van het document in het beeld. Deze benadering vereenvoudigt en versnelt het sorteerproces.
Stap 1.5: Het juiste model en de juiste trainingsmethode kiezen
Na het begrijpen van het projectdoel en de geschikte computer vision taken, is een essentieel onderdeel van het definiëren van het projectdoel het selecteren van het juiste model en de juiste trainingsaanpak.
Afhankelijk van de doelstelling kun je ervoor kiezen om eerst het model te kiezen of pas nadat je hebt gezien welke gegevens je in stap 2 kunt verzamelen. Stel bijvoorbeeld dat je project sterk afhankelijk is van de beschikbaarheid van specifieke soorten gegevens. In dat geval kan het praktischer zijn om eerst de gegevens te verzamelen en te analyseren voordat je een model kiest. Aan de andere kant, als je een duidelijk beeld hebt van de vereisten voor het model, kun je eerst het model kiezen en dan gegevens verzamelen die aan die specificaties voldoen.
Choosing between training from scratch or using transfer learning affects how you prepare your data. Training from scratch requires a diverse dataset to build the model's understanding from the ground up. Transfer learning, on the other hand, allows you to use a pre-trained model and adapt it with a smaller, more specific dataset. Also, choosing a specific model to train will determine how you need to prepare your data, such as resizing images or adding annotations, according to the model's specific requirements.
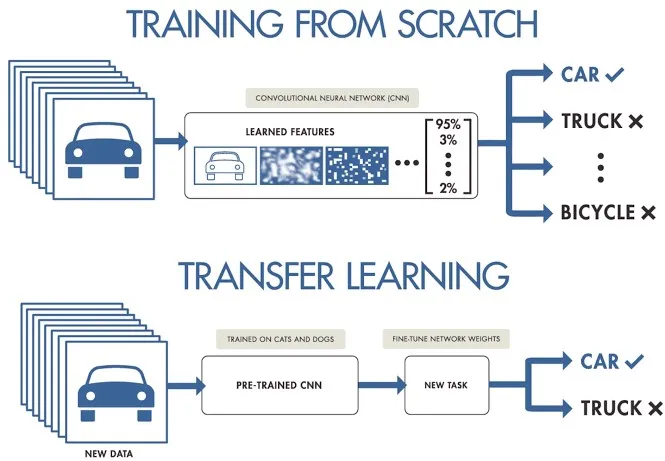
Note: When choosing a model, consider its deployment to ensure compatibility and performance. For example, lightweight models are ideal for edge computing due to their efficiency on resource-constrained devices. To learn more about the key points related to defining your project, read our guide on defining your project's goals and selecting the right model.
Voordat je begint met het praktische werk van een computervisieproject, is het belangrijk om deze details goed te begrijpen. Dubbelcheck of je het volgende hebt overwogen voordat je verder gaat met Stap 2:
- Clearly define the problem you're trying to solve.
- Bepaal het einddoel van je project.
- Identificeer de specifieke computervisietaak die nodig is (bijv. objectdetectie, beeldclassificatie, beeldsegmentatie).
- Beslis of je een model vanaf nul wilt trainen of transfer learning wilt gebruiken.
- Kies het juiste model voor je taak en inzetbehoeften.
Stap 2: Gegevensverzameling en gegevensannotatie
De kwaliteit van je computervisiemodellen hangt af van de kwaliteit van je dataset. Je kunt afbeeldingen van internet verzamelen, je eigen foto's maken of al bestaande datasets gebruiken. Hier zijn een aantal goede bronnen om datasets van hoge kwaliteit te downloaden: Google Dataset Search Engine, UC Irvine Machine Learning Repository en Kaggle Datasets.
Sommige bibliotheken, zoals Ultralytics, bieden ingebouwde ondersteuning voor verschillende datasets, waardoor het gemakkelijker wordt om aan de slag te gaan met gegevens van hoge kwaliteit. Deze bibliotheken bevatten vaak hulpprogramma's om populaire datasets naadloos te gebruiken, wat je veel tijd en moeite kan besparen in de beginfase van je project.
However, if you choose to collect images or take your own pictures, you'll need to annotate your data. Data annotation is the process of labeling your data to impart knowledge to your model. The type of data annotation you'll work with depends on your specific computer vision technique. Here are some examples:
- Image Classification: You'll label the entire image as a single class.
- Object Detection: You'll draw bounding boxes around each object in the image and label each box.
- Image Segmentation: You'll label each pixel in the image according to the object it belongs to, creating detailed object boundaries.
Data collection and annotation can be a time-consuming manual effort. Annotation tools can help make this process easier. Here are some useful open annotation tools: LabeI Studio, CVAT, and Labelme.
Stap 3: Gegevensuitbreiding en het opsplitsen van je dataset
Nadat je je afbeeldingsgegevens hebt verzameld en geannoteerd, is het belangrijk om je dataset eerst op te splitsen in een trainings-, validatie- en testset voordat je de gegevens gaat vergroten. Het splitsen van je dataset voordat je de gegevens uitbreidt is cruciaal om je model te testen en te valideren op originele, ongewijzigde gegevens. Het helpt om nauwkeurig te beoordelen hoe goed het model generaliseert naar nieuwe, ongeziene gegevens.
Hier lees je hoe je je gegevens kunt opsplitsen:
- Trainingsset: Dit is het grootste deel van je gegevens, meestal 70-80% van het totaal, dat wordt gebruikt om je model te trainen.
- Validatieset: Meestal ongeveer 10-15% van je gegevens; deze set wordt gebruikt om hyperparameters af te stemmen en het model te valideren tijdens de training, om overfitting te voorkomen.
- Testset: De resterende 10-15% van je gegevens wordt apart gezet als testset. Deze wordt gebruikt om de prestaties van het model op ongeziene gegevens te evalueren nadat de training is voltooid.
Na het splitsen van je gegevens kun je gegevensuitbreiding uitvoeren door transformaties toe te passen zoals het roteren, schalen en omdraaien van afbeeldingen om je dataset kunstmatig te vergroten. Gegevensuitbreiding maakt je model robuuster voor variaties en verbetert de prestaties op ongeziene afbeeldingen.
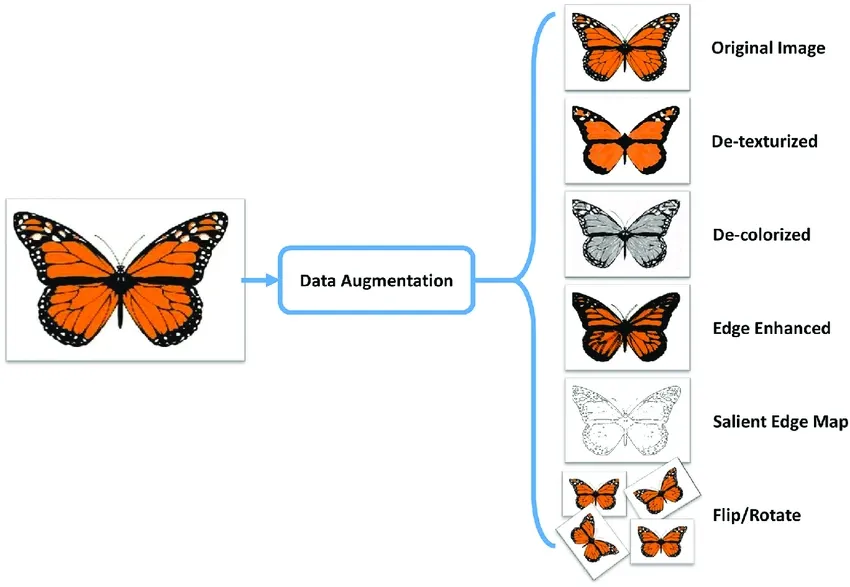
Bibliotheken zoals OpenCV, Albumentations en TensorFlow bieden flexibele augmentatiefuncties die je kunt gebruiken. Daarnaast hebben sommige bibliotheken, zoals Ultralytics, ingebouwde augmentatie-instellingen direct in de modeltrainingsfunctie, wat het proces vereenvoudigt.
Om je gegevens beter te begrijpen, kun je tools als Matplotlib of Seaborn gebruiken om de beelden te visualiseren en hun verdeling en kenmerken te analyseren. Het visualiseren van je gegevens helpt bij het identificeren van patronen, afwijkingen en de effectiviteit van je augmentatietechnieken. Je kunt ook Ultralytics Explorer gebruiken, een hulpmiddel voor het verkennen van computer vision datasets met semantisch zoeken, SQL queries en vector similarity search.
By properly understanding, splitting, and augmenting your data, you can develop a well-trained, validated, and tested model that performs well in real-world applications.
Stap 4: Modeltraining
Zodra je dataset klaar is voor training, kun je je richten op het opzetten van de benodigde omgeving, het beheren van je datasets en het trainen van je model.
First, you'll need to make sure your environment is configured correctly. Typically, this includes the following:
- Het installeren van essentiële bibliotheken en frameworks zoals TensorFlow, PyTorch, of Ultralytics.
- Als je een GPU gebruikt, helpt het installeren van bibliotheken zoals CUDA en cuDNN om GPU-versnelling mogelijk te maken en het trainingsproces te versnellen.
Vervolgens kun je je trainings- en validatiedatasets in je omgeving laden. Normaliseer en bewerk de gegevens door ze te verkleinen, formaten te converteren of uit te breiden. Als je het model hebt geselecteerd, configureer je de lagen en geef je hyperparameters op. Stel het model samen door de verliesfunctie, optimizer en prestatiekenmerken in te stellen.
Bibliotheken zoals Ultralytics vereenvoudigen het trainingsproces. Je kunt beginnen met trainen door gegevens in het model te stoppen met minimale code. Deze bibliotheken zorgen automatisch voor gewichtsaanpassingen, backpropagatie en validatie. Ze bieden ook hulpmiddelen om de voortgang te controleren en hyperparameters eenvoudig aan te passen. Na de training kun je het model en de gewichten opslaan met een paar commando's.
Het is belangrijk om in gedachten te houden dat goed beheer van datasets van vitaal belang is voor efficiënte training. Gebruik versiebeheer voor datasets om wijzigingen bij te houden en reproduceerbaarheid te garanderen. Tools zoals DVC (Data Version Control) kunnen helpen bij het beheren van grote datasets.
Stap 5: Modelevaluatie en -verfijning
It's important to assess your model's performance using various metrics and refine it to improve accuracy. Evaluating helps identify areas where the model excels and where it may need improvement. Fine-tuning ensures the model is optimized for the best possible performance.
- Performance Metrics: Use metrics like accuracy, precision, recall, and F1-score to evaluate your model's performance. These metrics provide insights into how well your model is making predictions.
-
Hyperparameter afstellen: Hyperparameters aanpassen om de prestaties van het model te optimaliseren. Technieken als grid search of random search kunnen helpen bij het vinden van de beste hyperparameterwaarden.
-
Fijnafstemming: Maak kleine aanpassingen aan de modelarchitectuur of het trainingsproces om de prestaties te verbeteren. Dit kan het aanpassen van leersnelheden, batchgroottes of andere modelparameters inhouden.
Stap 6: Model testen
In deze stap kun je er zeker van zijn dat je model goed presteert op volledig ongeziene gegevens, waarmee je bevestigt dat het klaar is om ingezet te worden. Het verschil tussen het testen van modellen en het evalueren van modellen is dat het zich richt op het verifiëren van de prestaties van het uiteindelijke model in plaats van het iteratief te verbeteren.
Het is belangrijk om veelvoorkomende problemen grondig te testen en op te lossen. Test je model op een aparte testdataset die niet is gebruikt tijdens de training of validatie. Deze dataset moet realistische scenario's weergeven om er zeker van te zijn dat de prestaties van het model consistent en betrouwbaar zijn.
Pak ook veelvoorkomende problemen aan zoals overfitting, underfitting en datalekken. Gebruik technieken als kruisvalidatie en anomaliedetectie om deze problemen te identificeren en op te lossen.
Stap 7: Modelimplementatie
Als je model grondig getest is, is het tijd om het te implementeren. Deployment houdt in dat je model beschikbaar wordt gemaakt voor gebruik in een productieomgeving. Hier zijn de stappen om een computervisiemodel te implementeren:
-
De omgeving instellen: Configureer de benodigde infrastructuur voor de door jou gekozen inzetoptie, of deze nu cloud-gebaseerd is (AWS, Google Cloud, Azure) of edge-gebaseerd (lokale apparaten, IoT).
-
Het model exporteren: Exporteer je model naar de juiste indeling (bijv. ONNX, TensorRT, CoreML voor YOLOv8) om compatibiliteit met je implementatieplatform te garanderen.
- Het model implementeren: Implementeer het model door API's of endpoints in te stellen en het te integreren met je applicatie.
- Schaalbaarheid garanderen: Implementeer load balancers, auto-scaling groepen en monitoring tools om bronnen te beheren en toenemende gegevens- en gebruikersverzoeken af te handelen.
Stap 8: Bewaking, onderhoud en documentatie
Once your model is deployed, it's important to continuously monitor its performance, maintain it to handle any issues, and document the entire process for future reference and improvements.
Met monitoring tools kun je de belangrijkste prestatie-indicatoren (KPI's) bijhouden en afwijkingen of dalingen in nauwkeurigheid detecteren. Door het model te monitoren kun je je bewust worden van modeldrift, waarbij de prestaties van het model na verloop van tijd afnemen door veranderingen in de invoergegevens. Train het model regelmatig opnieuw met bijgewerkte gegevens om de nauwkeurigheid en relevantie te behouden.
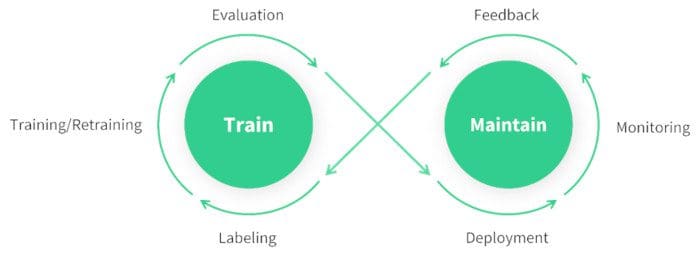
Naast controle en onderhoud is documentatie ook belangrijk. Documenteer het hele proces grondig, inclusief de modelarchitectuur, trainingsprocedures, hyperparameters, stappen voor de voorbewerking van gegevens en alle wijzigingen die tijdens de implementatie en het onderhoud worden aangebracht. Goede documentatie zorgt voor reproduceerbaarheid en maakt toekomstige updates of probleemoplossing eenvoudiger. Door je model effectief te controleren, te onderhouden en te documenteren, kun je ervoor zorgen dat het nauwkeurig en betrouwbaar blijft en gemakkelijk te beheren gedurende de levenscyclus.
FAQs
Hier zijn enkele veelvoorkomende vragen die kunnen opkomen tijdens een computervisieproject:
-
V1: Hoe veranderen de stappen als ik al een dataset of gegevens heb bij het starten van een computervisieproject?
- A1: Starting with a pre-existing dataset or data affects the initial steps of your project. In Step 1, along with deciding the computer vision task and model, you'll also need to explore your dataset thoroughly. Understanding its quality, variety, and limitations will guide your choice of model and training approach. Your approach should align closely with the data's characteristics for more effective outcomes. Depending on your data or dataset, you may be able to skip Step 2 as well.
-
Q2: I'm not sure what computer vision project to start my AI learning journey with.
- A2: Check out our guides on Real-World Projects for inspiration and guidance.
-
Q3: I don't want to train a model. I just want to try running a model on an image. How can I do that?
- A3: Je kunt een voorgetraind model gebruiken om voorspellingen te doen op een afbeelding zonder een nieuw model te trainen. Kijk op de YOLOv8 predict docs pagina voor instructies over hoe je een voorgetraind YOLOv8 model kunt gebruiken om voorspellingen te doen op je afbeeldingen.
-
V4: Waar kan ik meer gedetailleerde artikelen en updates vinden over computervisietoepassingen en YOLOv8?
- A4: Ga voor meer gedetailleerde artikelen, updates en inzichten over computervisietoepassingen en YOLOv8 naar de blogpaginaUltralytics . De blog behandelt een breed scala aan onderwerpen en biedt waardevolle informatie om je te helpen op de hoogte te blijven en je projecten te verbeteren.
Samenwerken met de gemeenschap
Contact maken met een gemeenschap van computer vision enthousiastelingen kan je helpen om problemen die je tegenkomt tijdens het werken aan je computer vision project met vertrouwen aan te pakken. Hier zijn enkele manieren om effectief te leren, problemen op te lossen en te netwerken.
Hulpbronnen van de Gemeenschap
- GitHub problemen: Bekijk de YOLOv8 GitHub repository en gebruik de Issues tab om vragen te stellen, bugs te melden en nieuwe functies voor te stellen. De actieve gemeenschap en beheerders zijn er om te helpen met specifieke problemen.
- Ultralytics Discord-server: Word lid van de Ultralytics Discord server om te communiceren met andere gebruikers en ontwikkelaars, ondersteuning te krijgen en inzichten te delen.
Officiële documentatie
- Ultralytics YOLOv8 Documentatie: Verken de officiële YOLOv8 documentatie voor gedetailleerde gidsen met handige tips voor verschillende computer vision taken en projecten.
Het gebruik van deze bronnen zal je helpen om uitdagingen te overwinnen en op de hoogte te blijven van de laatste trends en best practices in de computer vision gemeenschap.
Kickstart je computer vision project vandaag nog!
Een computervisieproject opzetten kan spannend en lonend zijn. Door de stappen in deze gids te volgen, kun je een solide basis voor succes leggen. Elke stap is cruciaal voor het ontwikkelen van een oplossing die voldoet aan je doelstellingen en goed werkt in real-world scenario's. Naarmate je meer ervaring opdoet, ontdek je geavanceerde technieken en hulpmiddelen om je projecten te verbeteren. Blijf nieuwsgierig, blijf leren en verken nieuwe methoden en innovaties!