Model Dağıtımı için En İyi Uygulamalar
Giriş
Model dağıtımı, bir modeli geliştirme aşamasından gerçek dünya uygulamasına taşıyan bilgisayar görüşü projesindeki adımdır. Çeşitli model dağıtım seçenekleri vardır: bulut dağıtımı ölçeklenebilirlik ve erişim kolaylığı sunar, uç dağıtımı modeli veri kaynağına yaklaştırarak gecikmeyi azaltır ve yerel dağıtım gizlilik ve kontrol sağlar. Doğru stratejiyi seçmek, uygulamanızın hız, güvenlik ve ölçeklenebilirlik arasında denge kurma ihtiyaçlarına bağlıdır.
İzle: AI Modellerini Optimize Etme ve Dağıtma: En İyi Uygulamalar, Sorun Giderme ve Güvenlik Hususları
Modelin dağıtımı, modelin performansının etkinliğini ve güvenilirliğini önemli ölçüde etkileyebileceğinden, bir modeli dağıtırken en iyi uygulamaları izlemek de önemlidir. Bu kılavuzda, model dağıtımınızın sorunsuz, verimli ve güvenli olduğundan nasıl emin olacağınıza odaklanacağız.
Model Dağıtım Seçenekleri
Çoğu zaman, bir model eğitildikten, değerlendirildikten ve test edildikten sonra, bulut, uç veya yerel cihazlar gibi çeşitli ortamlarda etkili bir şekilde dağıtılabilmesi için belirli biçimlere dönüştürülmesi gerekir.
YOLO26 ile, dağıtım ihtiyaçlarınıza bağlı olarak modelinizi çeşitli formatlara aktarabilirsiniz. Örneğin, YOLO26'yı ONNX'e aktarmak basittir ve modelleri çerçeveler arasında aktarmak için idealdir. Daha fazla entegrasyon seçeneğini keşfetmek ve farklı ortamlarda sorunsuz bir dağıtım sağlamak için model entegrasyon merkezimizi ziyaret edin.
Dağıtım Ortamı Seçimi
Bilgisayar görüşü modelinizi nereye dağıtacağınızı seçmek birçok faktöre bağlıdır. Farklı ortamların benzersiz faydaları ve zorlukları vardır, bu nedenle ihtiyaçlarınıza en uygun olanı seçmek önemlidir.
Bulut Ortamına Dağıtım
Bulut ortamına dağıtım, hızla ölçeklenmesi ve büyük miktarda veriyi işlemesi gereken uygulamalar için harikadır. AWS, Google Cloud ve Azure gibi platformlar, modellerinizi eğitimden dağıtıma kadar yönetmeyi kolaylaştırır. Süreç boyunca size yardımcı olmak için AWS SageMaker, Google AI Platform ve Azure Machine Learning gibi hizmetler sunarlar.
Ancak, bulutu kullanmak, özellikle yüksek veri kullanımında maliyetli olabilir ve kullanıcılarınız veri merkezlerinden uzaktaysa gecikme sorunlarıyla karşılaşabilirsiniz. Maliyetleri ve performansı yönetmek için kaynak kullanımını optimize etmek ve veri gizliliği kurallarına uyumu sağlamak önemlidir.
Uç Nokta Dağıtımı
Uç nokta dağıtımı, özellikle internet erişiminin sınırlı veya hiç olmadığı yerlerde, gerçek zamanlı yanıtlar ve düşük gecikme süresi gerektiren uygulamalar için iyi sonuç verir. Modellerin akıllı telefonlar veya IoT cihazları gibi uç nokta cihazlarına dağıtılması, hızlı işlemeyi sağlar ve verileri yerel tutarak gizliliği artırır. Uç noktada dağıtım yapmak, buluta gönderilen veri miktarını azaltarak bant genişliğinden de tasarruf sağlar.
Ancak, uç cihazlar genellikle sınırlı işlem gücüne sahiptir, bu nedenle modellerinizi optimize etmeniz gerekecektir. TensorFlow Lite ve NVIDIA Jetson gibi araçlar yardımcı olabilir. Faydalarına rağmen, birçok cihazı sürdürmek ve güncellemek zor olabilir.
Yerel Dağıtım
Veri gizliliğinin kritik olduğu veya güvenilir olmayan veya hiç internet erişiminin olmadığı durumlarda Yerel Dağıtım en iyisidir. Modelleri yerel sunucularda veya masaüstlerinde çalıştırmak size tam kontrol sağlar ve verilerinizi güvende tutar. Sunucu kullanıcıya yakınsa gecikmeyi de azaltabilir.
Ancak, yerel ölçeklendirme zor olabilir ve bakım zaman alıcı olabilir. Kapsayıcılaştırma için Docker ve yönetim için Kubernetes gibi araçları kullanmak, yerel dağıtımları daha verimli hale getirmeye yardımcı olabilir. Her şeyin sorunsuz çalışmasını sağlamak için düzenli güncellemeler ve bakım gereklidir.
Kolaylaştırılmış Dağıtım için Konteynerleştirme
Konteynerleştirme, modelinizi ve tüm bağımlılıklarını konteyner adı verilen standartlaştırılmış bir birime paketleyen güçlü bir yaklaşımdır. Bu teknik, farklı ortamlarda tutarlı performans sağlar ve dağıtım sürecini basitleştirir.
Model Dağıtımı için Docker Kullanmanın Faydaları
Docker, çeşitli nedenlerle makine öğrenimi dağıtımlarında konteynerleştirme için endüstri standardı haline gelmiştir:
- Ortam Tutarlılığı: Docker konteynerleri, modelinizi ve tüm bağımlılıklarını kapsar ve geliştirme, test ve üretim ortamlarında tutarlı davranış sağlayarak "benim makinemde çalışıyor" sorununu ortadan kaldırır.
- İzolasyon: Kapsayıcılar, uygulamaları birbirinden izole ederek farklı yazılım sürümleri veya kitaplıklar arasındaki çakışmaları önler.
- Taşınabilirlik: Docker konteynerleri, Docker'ı destekleyen herhangi bir sistemde çalışabilir, bu da modellerinizi farklı platformlarda değişiklik yapmadan dağıtmayı kolaylaştırır.
- Ölçeklenebilirlik: Kapsayıcılar talebe göre kolayca ölçeklenebilir veya azaltılabilir ve Kubernetes gibi orkestrasyon araçları bu süreci otomatikleştirebilir.
- Sürüm Kontrolü: Docker görselleri sürümlenebilir, bu da değişiklikleri izlemenize ve gerekirse önceki sürümlere geri dönmenize olanak tanır.
YOLO26 Dağıtımı için Docker Uygulaması
YOLO26 modelinizi kapsayıcılaştırmak için, gerekli tüm bağımlılıkları ve yapılandırmaları belirten bir Dockerfile oluşturabilirsiniz. İşte temel bir örnek:
FROM ultralytics/ultralytics:latest
WORKDIR /app
# Copy your model and any additional files
COPY ./models/yolo26.pt /app/models/
COPY ./scripts /app/scripts/
# Set up any environment variables
ENV MODEL_PATH=/app/models/yolo26.pt
# Command to run when the container starts
CMD ["python", "/app/scripts/predict.py"]
Bu yaklaşım, model dağıtımınızın farklı ortamlarda yeniden üretilebilir ve tutarlı olmasını sağlayarak, dağıtım süreçlerine sıklıkla musallat olan "benim makinemde çalışıyor" sorununu önemli ölçüde azaltır.
Model Optimizasyon Teknikleri
Bilgisayar görüşü modelinizi optimize etmek, özellikle uç cihazlar gibi sınırlı kaynaklara sahip ortamlarda dağıtım yaparken verimli bir şekilde çalışmasına yardımcı olur. Modelinizi optimize etmek için bazı temel teknikler şunlardır.
Model Budama
Budama, nihai çıktıya çok az katkıda bulunan ağırlıkları kaldırarak modelin boyutunu küçültür. Doğruluğu önemli ölçüde etkilemeden modeli daha küçük ve daha hızlı hale getirir. Budama, gereksiz parametreleri tanımlamayı ve ortadan kaldırmayı içerir, bu da daha az işlem gücü gerektiren daha hafif bir modelle sonuçlanır. Özellikle sınırlı kaynaklara sahip cihazlarda modelleri dağıtmak için kullanışlıdır.
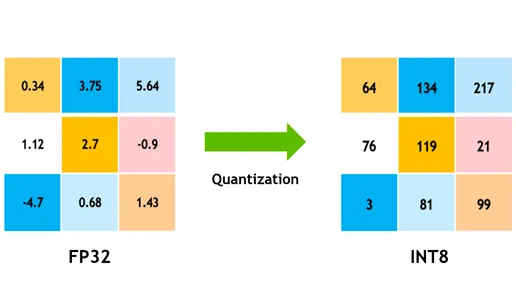
Model Kuantalama
Kuantalama, modelin ağırlıklarını ve aktivasyonlarını yüksek hassasiyetten (32-bit kayan sayılar gibi) daha düşük hassasiyete (8-bit tamsayılar gibi) dönüştürür. Model boyutunu küçülterek çıkarımı hızlandırır. Kuantalama duyarlı eğitim (QAT), modelin kuantalama göz önünde bulundurularak eğitildiği ve eğitim sonrası kuantalamadan daha iyi doğruluk sağlayan bir yöntemdir. Eğitim aşamasında kuantalamayı ele alarak, model daha düşük hassasiyete uyum sağlamayı öğrenir ve hesaplama taleplerini azaltırken performansı korur.
Bilgi Damıtımı
Bilgi damıtımı, daha büyük, daha karmaşık bir modelin (öğretmen) çıktılarını taklit etmek için daha küçük, daha basit bir modelin (öğrenci) eğitilmesini içerir. Öğrenci modeli, öğretmenin tahminlerini yaklaşık olarak öğrenir ve bu da öğretmenin doğruluğunun çoğunu koruyan kompakt bir modelle sonuçlanır. Bu teknik, kısıtlı kaynaklara sahip uç cihazlarda dağıtım için uygun verimli modeller oluşturmak için faydalıdır.
Dağıtım Sorunlarını Giderme
Bilgisayar görüşü modellerinizi dağıtırken zorluklarla karşılaşabilirsiniz, ancak yaygın sorunları ve çözümleri anlamak süreci daha sorunsuz hale getirebilir. Dağıtım sorunlarında yolunuzu bulmanıza yardımcı olacak bazı genel sorun giderme ipuçları ve en iyi uygulamalar şunlardır.
Modeliniz Dağıtımdan Sonra Daha Az Doğru
Modelinizin doğruluğunda dağıtımdan sonra bir düşüş yaşamak sinir bozucu olabilir. Bu sorun çeşitli faktörlerden kaynaklanabilir. Sorunu belirlemenize ve çözmenize yardımcı olacak bazı adımlar şunlardır:
- Veri Tutarlılığını Kontrol Edin: Modelinizin dağıtım sonrası işlediği verilerin, üzerinde eğitildiği verilerle tutarlı olup olmadığını kontrol edin. Veri dağılımı, kalitesi veya formatındaki farklılıklar performansı önemli ölçüde etkileyebilir.
- Ön İşleme Adımlarını Doğrulayın: Eğitim sırasında uygulanan tüm ön işleme adımlarının, dağıtım sırasında da tutarlı bir şekilde uygulandığını doğrulayın. Buna görüntüleri yeniden boyutlandırma, piksel değerlerini normalleştirme ve diğer veri dönüşümleri dahildir.
- Modelin Ortamını Değerlendirin: Dağıtım sırasında kullanılan donanım ve yazılım yapılandırmalarının, eğitim sırasında kullanılanlarla eşleştiğinden emin olun. Kitaplıklardaki, sürümlerdeki ve donanım özelliklerindeki farklılıklar tutarsızlıklara neden olabilir.
- Model Çıkarımını İzleme: Herhangi bir anormalliği tespit etmek için çıkarım hattının çeşitli aşamalarında girişleri ve çıktıları günlüğe kaydedin. Bu, veri bozulması veya model çıktılarının yanlış işlenmesi gibi sorunları belirlemeye yardımcı olabilir.
- Model Dışa Aktarma ve Dönüştürmeyi İnceleme: Modeli yeniden dışa aktarın ve dönüştürme işleminin model ağırlıklarının ve mimarisinin bütünlüğünü koruduğundan emin olun.
- Kontrollü Bir Veri Kümesiyle Test Edin: Modeli, kontrol ettiğiniz bir veri kümesiyle bir test ortamında dağıtın ve sonuçları eğitim aşamasıyla karşılaştırın. Sorunun dağıtım ortamından mı yoksa verilerden mi kaynaklandığını belirleyebilirsiniz.
YOLO26 dağıtılırken, model doğruluğunu etkileyebilecek çeşitli faktörler vardır. Modelleri TensorRT gibi formatlara dönüştürmek, ağırlık niceleme ve katman birleştirme gibi optimizasyonları içerir ve bu da küçük hassasiyet kayıplarına neden olabilir. FP32 (tam hassasiyet) yerine FP16 (yarım hassasiyet) kullanmak çıkarımı hızlandırabilir ancak sayısal hassasiyet hatalarına yol açabilir. Ayrıca, daha düşük CUDA çekirdek sayıları ve azaltılmış bellek bant genişliği ile Jetson Nano gibi donanım kısıtlamaları performansı etkileyebilir.
Çıkarımlar Beklediğinizden Daha Uzun Sürüyor
Makine öğrenimi modellerini dağıtırken, verimli çalışması önemlidir. Çıkarımlar beklenenden uzun sürüyorsa, kullanıcı deneyimini ve uygulamanızın etkinliğini etkileyebilir. Sorunu belirlemenize ve çözmenize yardımcı olacak bazı adımlar şunlardır:
- Isınma Çalışmaları Uygulayın: İlk çalıştırmalar genellikle kurulum ek yükünü içerir ve bu da gecikme ölçümlerini çarpıtabilir. Gecikmeyi ölçmeden önce birkaç ısınma çıkarımı gerçekleştirin. Bu ilk çalıştırmaları hariç tutmak, modelin performansının daha doğru bir ölçümünü sağlar.
- Çıkarım Motorunu Optimize Edin: Çıkarım motorunun belirli GPU mimariniz için tamamen optimize edildiğini iki kez kontrol edin. Maksimum performans ve uyumluluk sağlamak için donanımınıza göre uyarlanmış en son sürücüleri ve yazılım sürümlerini kullanın.
- Asenkron İşleme Kullanın: Asenkron işleme, iş yüklerini daha verimli yönetmeye yardımcı olabilir. Yükü dağıtmaya ve bekleme sürelerini azaltmaya yardımcı olabilecek birden çok çıkarımı eşzamanlı olarak işlemek için asenkron işleme tekniklerini kullanın.
- Çıkarım Hattını Profilleyin: Çıkarım hattındaki darboğazları belirlemek, gecikmelerin kaynağını tespit etmeye yardımcı olabilir. Çıkarım sürecinin her adımını analiz etmek, verimsiz katmanlar veya veri aktarım sorunları gibi önemli gecikmelere neden olan aşamaları belirlemek ve ele almak için profil oluşturma araçlarını kullanın.
- Uygun Hassasiyeti Kullanın: Gerekenden daha yüksek hassasiyet kullanmak, çıkarım sürelerini yavaşlatabilir. FP32 (tam hassasiyet) yerine FP16 (yarım hassasiyet) gibi daha düşük hassasiyet kullanmayı deneyin. FP16 çıkarım süresini azaltabilirken, model doğruluğunu etkileyebileceğini de unutmayın.
YOLO26 dağıtırken bu sorunla karşılaşıyorsanız, YOLO26'nın, daha düşük bellek kapasitesine sahip cihazlar için YOLO26n (nano) ve daha güçlü GPU'lar için YOLO26x (ekstra büyük) gibi çeşitli model boyutları sunduğunu göz önünde bulundurun. Donanımınız için doğru model varyantını seçmek, bellek kullanımını ve işlem süresini dengelemeye yardımcı olabilir.
Ayrıca, girdi görüntülerinin boyutunun bellek kullanımı ve işleme süresini doğrudan etkilediğini unutmayın. Daha düşük çözünürlükler bellek kullanımını azaltır ve çıkarımı hızlandırırken, daha yüksek çözünürlükler doğruluğu artırır ancak daha fazla bellek ve işlem gücü gerektirir.
Model Dağıtımında Güvenlik Hususları
Dağıtımın bir diğer önemli yönü de güvenliktir. Hassas verileri ve fikri mülkiyeti korumak için dağıtılan modellerinizin güvenliği kritik öneme sahiptir. Güvenli model dağıtımıyla ilgili olarak izleyebileceğiniz bazı en iyi uygulamalar şunlardır.
Güvenli Veri İletimi
İstemciler ve sunucular arasında gönderilen verilerin güvenliğini sağlamak, yetkisiz taraflarca ele geçirilmesini veya erişilmesini önlemek için çok önemlidir. Verileri aktarılırken şifrelemek için TLS (Transport Layer Security) gibi şifreleme protokolleri kullanabilirsiniz. Birisi verileri ele geçirse bile okuyamaz. Ayrıca, verileri kaynaktan hedefe kadar koruyan uçtan uca şifreleme de kullanabilirsiniz, böylece arada kimse erişemez.
Erişim Kontrolleri
Modelinize ve verilerine kimlerin erişebileceğini kontrol etmek, yetkisiz kullanımı önlemek için çok önemlidir. Modele erişmeye çalışan kullanıcıların veya sistemlerin kimliğini doğrulamak için güçlü kimlik doğrulama yöntemleri kullanın ve çok faktörlü kimlik doğrulama (MFA) ile ek güvenlik eklemeyi düşünün. Kullanıcı rollerine göre izinler atamak için rol tabanlı erişim kontrolü (RBAC) ayarlayın, böylece kişiler yalnızca ihtiyaç duyduklarına erişebilir. Modeldeki ve verilerindeki tüm erişimi ve değişiklikleri izlemek için ayrıntılı denetim günlükleri tutun ve herhangi bir şüpheli etkinliği tespit etmek için bu günlükleri düzenli olarak inceleyin.
Model Karartma
Modelinizi tersine mühendislikten veya kötüye kullanımdan korumak, model karartma yoluyla yapılabilir. Bu, yetkisiz kişilerin modeli anlamasını veya değiştirmesini zorlaştırmak için sinir ağlarındaki ağırlıklar ve sapmalar gibi model parametrelerini şifrelemeyi içerir. Katmanları ve parametreleri yeniden adlandırarak veya kukla katmanlar ekleyerek modelin mimarisini de karartabilir, böylece saldırganların tersine mühendislik yapması zorlaşır. Modeli güvenli bir ortamda, örneğin güvenli bir bölgede veya güvenilir bir yürütme ortamı (TEE) kullanarak sunmak, çıkarım sırasında ekstra bir koruma katmanı sağlayabilir.
Akranlarınızla Fikir Alışverişinde Bulunun
Bilgisayar görüşü meraklılarından oluşan bir topluluğun parçası olmak, sorunları çözmenize ve daha hızlı öğrenmenize yardımcı olabilir. İşte bağlantı kurmanın, yardım almanın ve fikir paylaşmanın bazı yolları.
Topluluk Kaynakları
- GitHub Sorunları: YOLO26 GitHub deposunu keşfedin ve Sorunlar sekmesini kullanarak sorular sorun, hataları bildirin ve yeni özellikler önerin. Topluluk ve sürdürücüler çok aktif ve yardıma hazır.
- Ultralytics Discord Sunucusu: Diğer kullanıcılar ve geliştiricilerle sohbet etmek, destek almak ve deneyimlerinizi paylaşmak için Ultralytics Discord sunucusuna katılın.
Resmi Belgelendirme
- Ultralytics YOLO26 Dokümantasyonu: Çeşitli bilgisayar görüşü projeleri hakkında ayrıntılı kılavuzlar ve faydalı ipuçları için resmi YOLO26 dokümantasyonunu ziyaret edin.
Bu kaynakları kullanmak, zorlukları çözmenize ve bilgisayar görüşü topluluğundaki en son trendler ve uygulamalarla güncel kalmanıza yardımcı olacaktır.
Sonuç ve Sonraki Adımlar
Bilgisayarla görü modellerini dağıtırken izlenecek bazı en iyi uygulamaları gözden geçirdik. Verileri güvenli hale getirerek, erişimi kontrol ederek ve model ayrıntılarını gizleyerek, modellerinizi sorunsuz bir şekilde çalışır durumda tutarken hassas bilgileri koruyabilirsiniz. Ayrıca, ısınma çalıştırmaları, motorları optimize etme, eşzamansız işleme, profil oluşturma işlem hatları ve doğru hassasiyeti seçme gibi stratejiler kullanarak doğruluğun azalması ve yavaş çıkarımlar gibi yaygın sorunların nasıl ele alınacağını da tartıştık.
Modelinizi dağıttıktan sonraki adım, uygulamanızı izlemek, bakımını yapmak ve belgelemektir. Düzenli izleme, sorunları hızlı bir şekilde yakalayıp düzeltmeye yardımcı olur, bakım modellerinizi güncel ve işlevsel tutar ve iyi bir dokümantasyon tüm değişiklikleri ve güncellemeleri izler. Bu adımlar, bilgisayar görüşü projenizin hedeflerine ulaşmanıza yardımcı olacaktır.
SSS
Ultralytics YOLO26 kullanarak bir makine öğrenimi modelini dağıtmak için en iyi uygulamalar nelerdir?
Bir makine öğrenimi modelini, özellikle Ultralytics YOLO26 ile dağıtmak, verimlilik ve güvenilirliği sağlamak için çeşitli en iyi uygulamaları içerir. İlk olarak, ihtiyaçlarınıza uygun dağıtım ortamını seçin — bulut, kenar veya yerel. Kaynak kısıtlı ortamlarda verimli dağıtım için modelinizi budama, niceleme ve bilgi damıtma gibi tekniklerle optimize edin. Farklı ortamlar arasında tutarlılık sağlamak için Docker ile kapsayıcılaştırmayı kullanmayı düşünün. Son olarak, performansı sürdürmek için veri tutarlılığını ve ön işleme adımlarının eğitim aşamasıyla uyumlu olduğundan emin olun. Daha ayrıntılı yönergeler için model dağıtım seçeneklerine de başvurabilirsiniz.
Ultralytics YOLO26 modelleriyle ilgili yaygın dağıtım sorunlarını nasıl giderebilirim?
Dağıtım sorunlarını giderme, birkaç temel adıma ayrılabilir. Modelinizin doğruluğu dağıtımdan sonra düşerse, veri tutarlılığını kontrol edin, ön işleme adımlarını doğrulayın ve donanım/yazılım ortamının eğitim sırasında kullandığınızla eşleştiğinden emin olun. Yavaş çıkarım süreleri için, ısınma çalıştırmaları yapın, çıkarım motorunuzu optimize edin, asenkron işlemeyi kullanın ve çıkarım hattınızın profilini çıkarın. Bu en iyi uygulamalar hakkında ayrıntılı bir kılavuz için dağıtım sorunlarını giderme bölümüne bakın.
Ultralytics YOLO26 optimizasyonu, uç cihazlarda model performansını nasıl artırır?
Ultralytics YOLO26 modellerini kenar cihazlar için optimize etmek, model boyutunu küçültmek için budama, ağırlıkları daha düşük hassasiyete dönüştürmek için niceleme ve daha büyük modelleri taklit eden daha küçük modelleri eğitmek için bilgi damıtma gibi teknikleri kullanmayı içerir. Bu teknikler, modelin sınırlı hesaplama gücüne sahip cihazlarda verimli bir şekilde çalışmasını sağlar. TensorFlow Lite ve NVIDIA Jetson gibi araçlar bu optimizasyonlar için özellikle faydalıdır. Bu teknikler hakkında daha fazla bilgiyi model optimizasyonu bölümümüzde bulabilirsiniz.
Ultralytics YOLO26 ile makine öğrenimi modellerini dağıtırken güvenlik hususları nelerdir?
Makine öğrenimi modellerini dağıtırken güvenlik büyük önem taşır. TLS gibi şifreleme protokollerini kullanarak güvenli veri iletimi sağlayın. Güçlü kimlik doğrulama ve rol tabanlı erişim kontrolü (RBAC) dahil olmak üzere sağlam erişim kontrolleri uygulayın. Model parametrelerini şifreleme ve modelleri güvenilir bir yürütme ortamı (TEE) gibi güvenli bir ortamda sunma gibi model karartma teknikleri ek koruma sağlar. Ayrıntılı uygulamalar için güvenlik hususlarına bakın.
Ultralytics YOLO26 modelim için doğru dağıtım ortamını nasıl seçerim?
Ultralytics YOLO26 modeliniz için en uygun dağıtım ortamını seçmek, uygulamanızın özel ihtiyaçlarına bağlıdır. Bulut dağıtımı, ölçeklenebilirlik ve erişim kolaylığı sunarak yüksek veri hacmine sahip uygulamalar için idealdir. Kenar dağıtımı, TensorFlow Lite gibi araçları kullanarak gerçek zamanlı yanıtlar gerektiren düşük gecikmeli uygulamalar için en iyisidir. Yerel dağıtım, sıkı veri gizliliği ve kontrol gerektiren senaryolara uygundur. Her bir ortama kapsamlı bir genel bakış için, dağıtım ortamı seçimi bölümümüze göz atın.




