Link to this sectionSAM 3: Kavramlarla Her Şeyi Segmentleme#
SAM 3, 8.3.237 sürümü (PR #22897) itibarıyla Ultralytics paketine tamamen entegre edilmiştir. Metin tabanlı kavram segmentasyonu, görsel örnek istemleri ve video takibi dahil tüm SAM 3 özelliklerine erişmek için pip install -U ultralytics komutuyla yükleyin veya yükseltin.
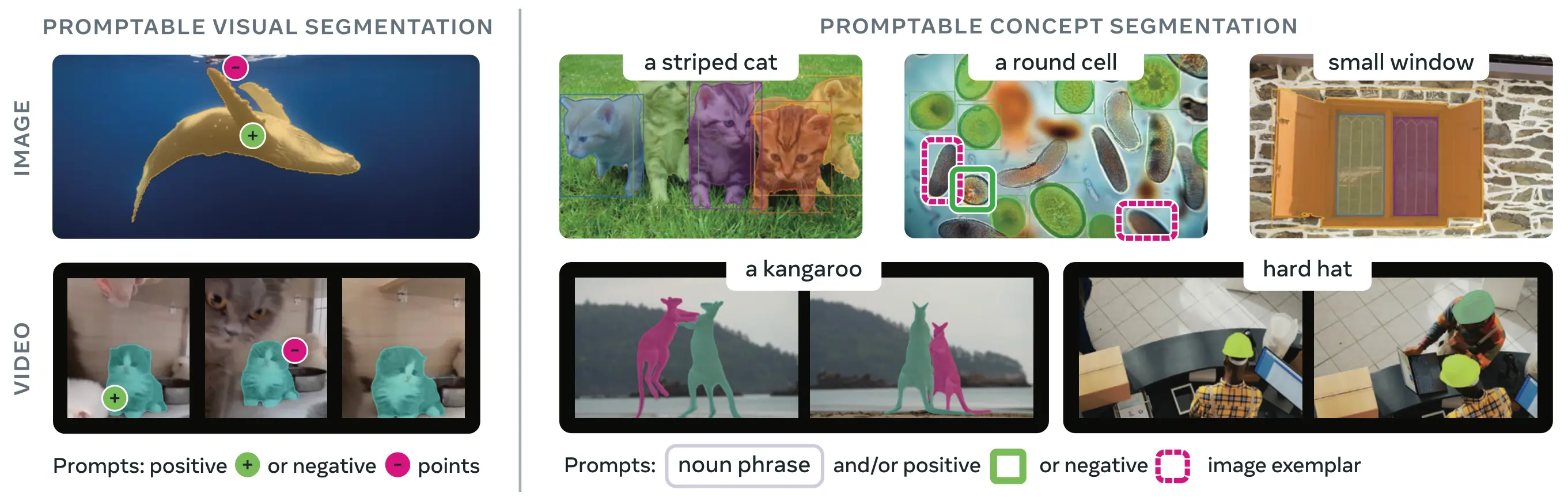
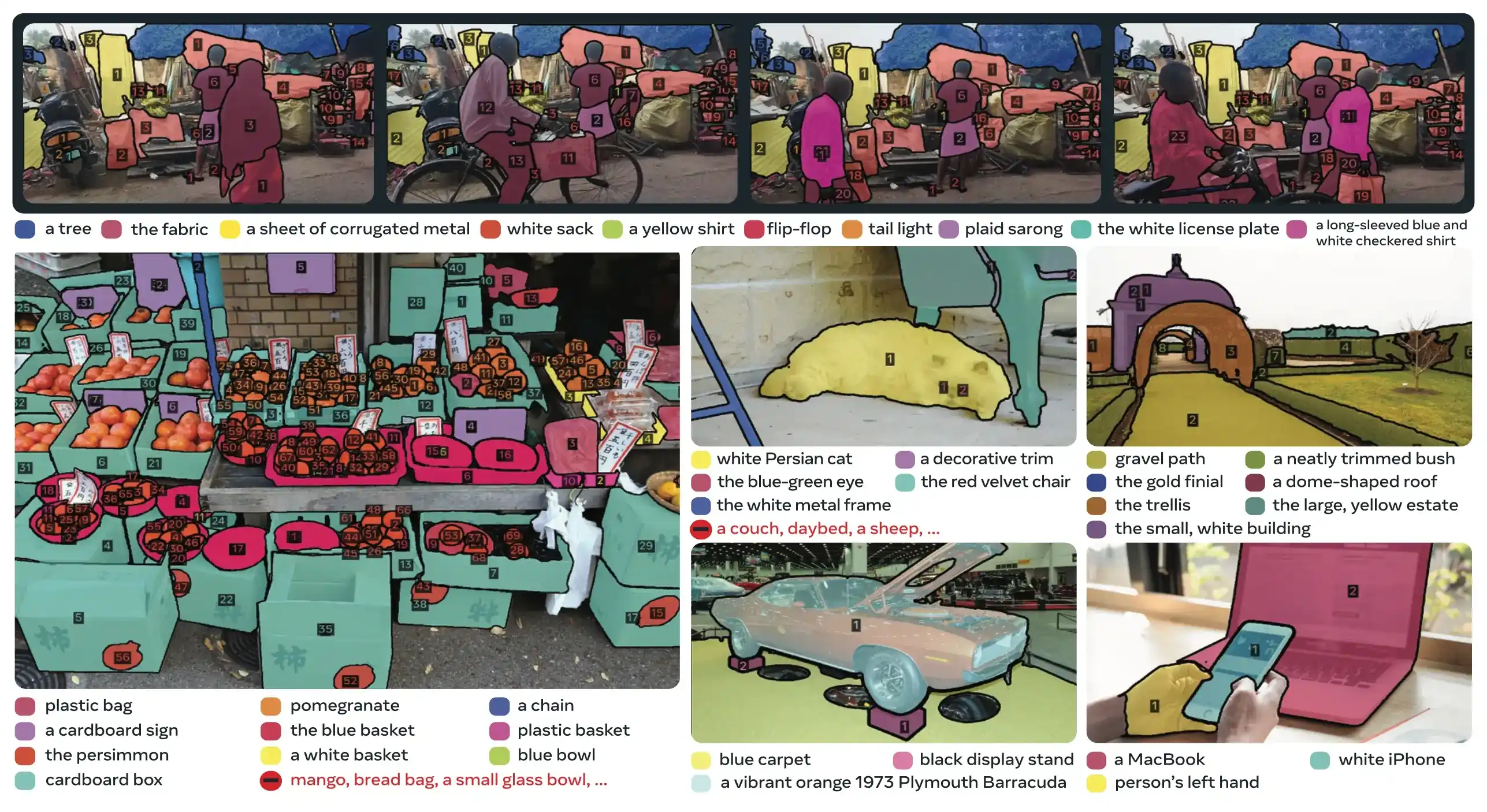
SAM 3 (Segment Anything Model 3), Meta'nın İstemle Kavram Segmentasyonu (PCS) için yayınladığı temel modeldir. SAM 2 üzerine inşa edilen SAM 3, temel olarak yeni bir yetenek sunar: metin istemleri, görsel örnekleri veya her ikisi tarafından belirtilen bir görsel kavramın tüm örneklerini tespit etme, segmentleme ve takip etme. Her istem için tek bir nesneyi segmentleyen önceki SAM sürümlerinin aksine SAM 3, modern instance segmentation kapsamındaki açık sözcüklü (open-vocabulary) hedeflerle uyumlu olarak, görüntülerde veya videolarda görünen bir kavramın her oluşumunu bulabilir ve segmentleyebilir.
Watch: How to Use Meta Segment Anything 3 with Ultralytics | Text-Prompt Segmentation on Images & Videos
SAM 3 artık ultralytics paketine tamamen entegre edilmiştir ve metin istemleri, görsel örnek istemleri ve video takip yetenekleriyle kavram segmentasyonu için yerel destek sağlar.
Link to this sectionGenel Bakış#
SAM 3, etkileşimli visual segmentation için SAM 2'nin yeteneklerini koruyup geliştirirken, İstemle Kavram Segmentasyonunda mevcut sistemlere göre 2 kat performans artışı sağlar. Model, kullanıcıların kavramları basit ad tamlamalarıyla (örneğin "sarı okul otobüsü", "çizgili kedi") veya hedef nesnenin örnek görsellerini sağlayarak belirlemesine olanak tanıyan açık sözcüklü segmentasyon konusunda mükemmeldir. Bu yetenekler, kolaylaştırılmış predict ve track iş akışlarına dayanan üretime hazır süreçleri tamamlar.
Link to this sectionİstemle Kavram Segmentasyonu (PCS) nedir?#
PCS görevi, girdi olarak bir kavram istemi alır ve tüm eşleşen nesne örnekleri için benzersiz kimliklere sahip segmentasyon maskeleri döndürür. Kavram istemleri şunlar olabilir:
- Metin: zero-shot learning benzeri "kırmızı elma" veya "şapka takan kişi" gibi basit ad tamlamaları
- Görsel örnekleri: Hızlı genelleme için örnek nesnelerin etrafındaki sınırlayıcı kutular (pozitif veya negatif)
- Birleşik: Hassas kontrol için hem metin hem de görsel örnekleri birlikte
Bu, orijinal SAM family tarafından popüler hale getirilen ve yalnızca tek bir özel nesne örneğini segmentleyen geleneksel görsel istemlerden (noktalar, kutular, maskeler) farklıdır.
Link to this sectionTemel Performans Metrikleri#
| Metrik | SAM 3 Başarısı |
|---|---|
| LVIS Zero-Shot Mask AP | 47.0 (önceki en iyi 38.5'e karşı, +%22 iyileşme) |
| SA-Co Karşılaştırması | Mevcut sistemlerden 2 kat daha iyi |
| Çıkarım Hızı (H200 GPU) | 100'den fazla tespit edilen nesne ile görüntü başına 30 ms |
| Video Performansı | ~5 eşzamanlı nesne için neredeyse gerçek zamanlı |
| MOSEv2 VOS Karşılaştırması | 60.1 J&F (SAM 2.1'e göre +%25.5, önceki SOTA'ya göre +%17) |
| Etkileşimli İyileştirme | 3 örnek istemden sonra +18.6 CGF1 iyileşme |
| İnsan Performansı Farkı | SA-Co/Gold üzerinde tahmini alt sınırın %88'ine ulaşır |
Model metrikleri ve üretimdeki ödünleşimler hakkında bağlam için model evaluation insights ve YOLO performance metrics sayfalarına bakın.
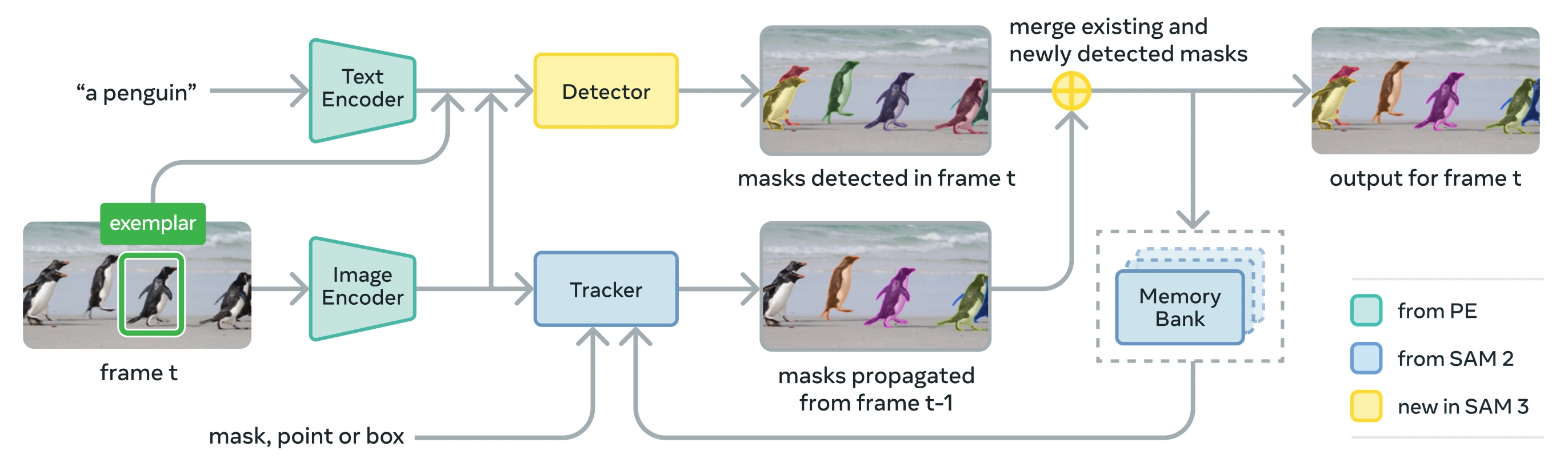
Link to this sectionMimari#
SAM 3, bir Perception Encoder (PE) vizyon omurgasını paylaşan bir detektör ve izleyiciden oluşur. Bu ayrık tasarım, görev çatışmalarını önlerken hem görüntü düzeyinde tespit hem de video düzeyinde takibe olanak tanır ve Ultralytics Python usage ve CLI usage ile uyumlu bir arayüze sahiptir.
Link to this sectionTemel Bileşenler#
-
Detektör: Görüntü düzeyinde kavram tespiti için DETR-based architecture
- Ad tamlaması istemleri için metin kodlayıcı
- Görsel tabanlı istemler için örnek kodlayıcı
- Görsel özelliklerini istemlere göre koşullandırmak için füzyon kodlayıcı
- Tanımayı ("ne") yerelleştirmeden ("nerede") ayıran yeni mevcudiyet başlığı (presence head)
- Örnek segmentasyon maskeleri oluşturmak için maske başlığı
-
İzleyici: SAM 2ten devralınan bellek tabanlı video segmentasyonu
- İstem kodlayıcı, maske kod çözücü, bellek kodlayıcı
- Nesne görünümünü kareler arasında depolamak için bellek bankası
- Çoklu nesne ortamlarında Kalman filter gibi tekniklerle desteklenen zamansal netleştirme
-
Mevcudiyet Simgesi: Hedef kavramın görüntüde/karede bulunup bulunmadığını tahmin eden, tanımayı yerelleştirmeden ayırarak tespiti iyileştiren öğrenilmiş bir küresel simge.
Link to this sectionTemel Yenilikler#
- Ayrıştırılmış Tanıma ve Yerelleştirme: Mevcudiyet başlığı kavram mevcudiyetini küresel olarak tahmin ederken, öneri sorguları yalnızca yerelleştirmeye odaklanarak çelişkili hedefleri önler.
- Birleşik Kavram ve Görsel İstemler: Tek bir modelde hem PCS'yi (kavram istemleri) hem de PVS'yi (SAM 2'nin tıklamaları/kutuları gibi görsel istemler) destekler.
- Etkileşimli Örnek İyileştirme: Kullanıcılar sonuçları yinelemeli olarak iyileştirmek için pozitif veya negatif görsel örnekleri ekleyebilir; model sadece tekil örnekleri düzeltmek yerine benzer nesnelere genelleme yapar.
- Zamansal Netleştirme: Tıkanmaları, kalabalık sahneleri ve izleme hatalarını yönetmek için masklet tespit puanlarını ve periyodik yeniden istem oluşturmayı kullanır; bu, instance segmentation and tracking en iyi uygulamalarıyla uyumludur.
Link to this sectionSA-Co Veri Kümesi#
SAM 3, Meta'nın bugüne kadarki en büyük ve en çeşitli segmentasyon veri kümesi olan ve COCO ve LVIS gibi yaygın karşılaştırmaların ötesine geçen Segment Anything with Concepts (SA-Co) üzerinde eğitilmiştir.
Link to this sectionEğitim Verisi#
| Veri Kümesi Bileşeni | Açıklama | Ölçek |
|---|---|---|
| SA-Co/HQ | 4 aşamalı veri motorundan gelen yüksek kaliteli insan açıklamalı görüntü verisi | 5.2M görüntü, 4M benzersiz ad tamlaması |
| SA-Co/SYN | İnsan müdahalesi olmadan yapay zeka tarafından etiketlenen sentetik veri kümesi | 38M ad tamlaması, 1.4B maske |
| SA-Co/EXT | Zor negatiflerle zenginleştirilmiş 15 harici veri kümesi | Kaynağa göre değişir |
| SA-Co/VIDEO | Zamansal takipli video açıklamaları | 52.5K video, 24.8K benzersiz ad tamlaması |
Link to this sectionKarşılaştırma Verisi#
SA-Co değerlendirme karşılaştırması, mevcut karşılaştırmalardan 50 kat daha fazla kavram sunan 126K görüntü ve video üzerinde 214K benzersiz ifade içerir. Şunları kapsar:
- SA-Co/Gold: İnsan performansı sınırlarını ölçmek için üçlü açıklamalı 7 alan
- SA-Co/Silver: 10 alan, tek insan açıklaması
- SA-Co/Bronze ve SA-Co/Bio: Kavram segmentasyonu için uyarlanmış 9 mevcut veri kümesi
- SA-Co/VEval: 3 alanlı (SA-V, YT-Temporal-1B, SmartGlasses) video karşılaştırması
Link to this sectionVeri Motoru Yenilikleri#
SAM 3'ün ölçeklenebilir insan ve model döngülü veri motoru, şunlar aracılığıyla 2 kat açıklama iş hacmi sağlar:
- AI Açıklayıcılar: Llama tabanlı modeller, zor negatifler dahil çeşitli ad tamlamaları önerir
- AI Doğrulayıcılar: İnce ayarlı multimodal LLMs, maske kalitesini ve kapsayıcılığını insan performansına yakın bir şekilde doğrular
- Aktif Madencilik: İnsan çabasını yapay zekanın zorlandığı başarısızlık durumlarına odaklar
- Ontoloji Odaklı: Kavram kapsamı için Wikidata tabanlı büyük bir ontolojiden yararlanır
Link to this sectionKurulum#
SAM 3, Ultralytics 8.3.237 ve sonraki sürümlerinde mevcuttur. Şununla yükleyin veya yükseltin:
pip install -U ultralyticsDiğer Ultralytics modellerinin aksine, SAM 3 ağırlıkları (sam3.pt) otomatik olarak indirilmez. Önce Hugging Face üzerindeki SAM 3 model sayfasında model ağırlıkları için erişim talebinde bulunmalı ve onaylandıktan sonra sam3.pt dosyasını bu sayfadan indirmelisiniz. İndirilen sam3.pt dosyasını çalışma dizininize yerleştirin veya modeli yüklerken tam yolu belirtin.
Tahmin sırasında yukarıdaki hatayı alırsanız, yanlış clip paketinin yüklü olduğu anlamına gelir. Aşağıdakini çalıştırarak doğru clip paketini yükleyin:
pip uninstall clip -y
pip install git+https://github.com/ultralytics/CLIP.gitLink to this sectionSAM 3 Nasıl Kullanılır: Kavram Segmentasyonunda Çok Yönlülük#
SAM 3, farklı tahmin arayüzleri aracılığıyla hem İstemle Kavram Segmentasyonu (PCS) hem de İstemle Görsel Segmentasyon (PVS) görevlerini destekler:
Link to this sectionDesteklenen Görevler ve Modeller#
| Görev Türü | İstem Türleri | Çıktı |
|---|---|---|
| Kavram Segmentasyonu (PCS) | Metin (ad tamlamaları), görsel örnekleri | Kavramla eşleşen tüm örnekler |
| Görsel Segmentasyon (PVS) | Noktalar, kutular, maskeler | Tek nesne örneği (SAM 2 stili) |
| Etkileşimli İyileştirme | Yinelemeli olarak örnek veya tıklama ekle/kaldır | Geliştirilmiş doğrulukla iyileştirilmiş segmentasyon |
Link to this sectionKavram Segmentasyonu Örnekleri#
Link to this sectionMetin İstemleriyle Segmentle#
Bir metin açıklaması kullanarak bir kavramın tüm örneklerini bul ve bölütle. Metin istemleri SAM3SemanticPredictor arayüzünü gerektirir.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor with configuration
overrides = dict(
conf=0.25,
task="segment",
mode="predict",
model="sam3.pt",
quantize=16, # Use FP16 for faster inference
save=True,
)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image once for multiple queries
predictor.set_image("path/to/image.jpg")
# Query with multiple text prompts
results = predictor(text=["person", "bus", "glasses"])
# Works with descriptive phrases
results = predictor(text=["person with red cloth", "person with blue cloth"])
# Query with a single concept
results = predictor(text=["a person"])Link to this sectionGörüntü Örnekleri ile Bölütleme#
Tüm benzer örnekleri bulmak için sınırlayıcı kutuları (bounding boxes) görsel istem olarak kullan. Bu aynı zamanda kavram tabanlı eşleştirme için SAM3SemanticPredictor gerektirir.
from ultralytics.models.sam import SAM3SemanticPredictor
# Initialize predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16, save=True)
predictor = SAM3SemanticPredictor(overrides=overrides)
# Set image
predictor.set_image("path/to/image.jpg")
# Provide bounding box examples to segment similar objects
results = predictor(bboxes=[[480.0, 290.0, 590.0, 650.0]])
# Multiple bounding boxes as exemplars of the same visual concept
results = predictor(bboxes=[[539, 599, 589, 639], [343, 267, 499, 662]])Link to this sectionVerimlilik için Öznitelik Tabanlı Çıkarım#
Verimliliği artırmak için görüntü özniteliklerini bir kez çıkar ve bunları birden fazla bölütleme sorgusu için yeniden kullan.
import cv2
from ultralytics.models.sam import SAM3SemanticPredictor
from ultralytics.utils.plotting import Annotator, colors
# Initialize predictors
overrides = dict(conf=0.50, task="segment", mode="predict", model="sam3.pt", verbose=False)
predictor = SAM3SemanticPredictor(overrides=overrides)
predictor2 = SAM3SemanticPredictor(overrides=overrides)
# Extract features from the first predictor
source = "path/to/image.jpg"
predictor.set_image(source)
src_shape = cv2.imread(source).shape[:2]
# Setup second predictor and reuse features
predictor2.setup_model()
# Perform inference using shared features with text prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, text=["person"])
# Perform inference using shared features with bounding box prompt
masks, boxes = predictor2.inference_features(predictor.features, src_shape=src_shape, bboxes=[[439, 437, 524, 709]])
# Visualize results
if masks is not None:
masks, boxes = masks.cpu().numpy(), boxes.cpu().numpy()
im = cv2.imread(source)
annotator = Annotator(im, pil=False)
annotator.masks(masks, [colors(x, True) for x in range(len(masks))])
cv2.imshow("result", annotator.result())
cv2.waitKey(0)Link to this sectionVideo Kavram Bölütleme#
Link to this sectionSınırlayıcı Kutular ile Video Boyunca Kavramları Takip Et#
Sınırlayıcı kutu istemlerini kullanarak video kareleri boyunca nesne örneklerini tespit et ve takip et.
from ultralytics.models.sam import SAM3VideoPredictor
# Create video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="sam3.pt", quantize=16)
predictor = SAM3VideoPredictor(overrides=overrides)
# Track objects using bounding box prompts
results = predictor(source="path/to/video.mp4", bboxes=[[706.5, 442.5, 905.25, 555], [598, 635, 725, 750]], stream=True)
# Process and display results
for r in results:
r.show() # Display frame with segmentation masksLink to this sectionMetin İstemleri ile Kavramları Takip Et#
Video kareleri boyunca metinle belirtilen kavramların tüm örneklerini takip et.
from ultralytics.models.sam import SAM3VideoSemanticPredictor
# Initialize semantic video predictor
overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=640, model="sam3.pt", quantize=16, save=True)
predictor = SAM3VideoSemanticPredictor(overrides=overrides)
# Track concepts using text prompts
results = predictor(source="path/to/video.mp4", text=["person", "bicycle"], stream=True)
# Process results
for r in results:
r.show() # Display frame with tracked objects
# Alternative: Track with bounding box prompts
results = predictor(
source="path/to/video.mp4",
bboxes=[[864, 383, 975, 620], [705, 229, 782, 402]],
labels=[1, 1], # Positive labels
stream=True,
)Link to this sectionGörsel İstemler (SAM 2 Uyumluluğu)#
SAM 3, tek nesne bölütlemesi için SAM 2'nin görsel istemleriyle tam geriye dönük uyumluluğu korur:
Temel SAM arayüzü tıpkı SAM 2 gibi davranır ve yalnızca görsel istemlerle (noktalar, kutular veya maskeler) belirtilen belirli alanı bölütler.
from ultralytics import SAM
model = SAM("sam3.pt")
# Single point prompt - segments object at specific location
results = model.predict(source="path/to/image.jpg", points=[900, 370], labels=[1])
results[0].show()
# Multiple points - segments single object with multiple point hints
results = model.predict(source="path/to/image.jpg", points=[[400, 370], [900, 370]], labels=[1, 1])
# Box prompt - segments object within bounding box
results = model.predict(source="path/to/image.jpg", bboxes=[100, 150, 300, 400])
results[0].show()Görsel istemlerle (noktalar/kutular/maskeler) SAM("sam3.pt") kullanmak, tıpkı SAM 2'de olduğu gibi o konumdaki yalnızca belirli nesneyi bölütleyecektir. Bir kavramın tüm örneklerini bölütlemek için yukarıda gösterildiği gibi metin veya örnek istemleri ile SAM3SemanticPredictor kullan.
Link to this sectionPerformans Karşılaştırmaları#
Link to this sectionGörüntü Bölütleme#
SAM 3, LVIS ve COCO for segmentation gibi gerçek dünya veri kümeleri dahil olmak üzere birden fazla kıyaslamada en son teknoloji sonuçlarına ulaşır:
| Kıyaslama | Metrik | SAM 3 | Önceki En İyi | Geliştirme |
|---|---|---|---|---|
| LVIS (zero-shot) | Mask AP | 47.0 | 38.5 | +22.1% |
| SA-Co/Gold | CGF1 | 65.0 | 34.3 (OWLv2) | +89.5% |
| COCO (zero-shot) | Box AP | 53.5 | 52.2 (T-Rex2) | +2.5% |
| ADE-847 (semantic seg) | mIoU | 14.7 | 9.2 (APE-D) | +59.8% |
| PascalConcept-59 | mIoU | 59.4 | 58.5 (APE-D) | +1.5% |
| Cityscapes (semantic seg) | mIoU | 65.1 | 44.2 (APE-D) | +47.3% |
Ultralytics datasets içindeki hızlı denemeler için veri kümesi seçeneklerini keşfet.
Link to this sectionVideo Bölütleme Performansı#
SAM 3, DAVIS 2017 ve YouTube-VOS gibi video kıyaslamalarında SAM 2'ye ve önceki en iyi sonuçlara göre önemli iyileştirmeler gösterir:
| Kıyaslama | Metrik | SAM 3 | SAM 2.1 L | Geliştirme |
|---|---|---|---|---|
| MOSEv2 | J&F | 60.1 | 47.9 | +25.5% |
| DAVIS 2017 | J&F | 92.0 | 90.7 | +1.4% |
| LVOSv2 | J&F | 88.2 | 79.6 | +10.8% |
| SA-V | J&F | 84.6 | 78.4 | +7.9% |
| YTVOS19 | J&F | 89.6 | 89.3 | +0.3% |
Link to this sectionAz Verili (Few-Shot) Uyarlama#
SAM 3, data-centric AI iş akışlarıyla ilgili olarak minimum örnekle yeni alanlara uyum sağlamada mükemmeldir:
| Kıyaslama | 0-shot AP | 10-shot AP | Önceki En İyi (10-shot) |
|---|---|---|---|
| ODinW13 | 59.9 | 71.6 | 67.9 (gDino1.5-Pro) |
| RF100-VL | 14.3 | 35.7 | 33.7 (gDino-T) |
Link to this sectionEtkileşimli İyileştirme Etkinliği#
SAM 3'ün örneklerle kavram tabanlı istemi, görsel isteme göre çok daha hızlı yakınsar:
| Eklenen İstemler | CGF1 Skoru | Yalnızca Metne Göre Kazanç | PVS Temel Hattına Göre Kazanç |
|---|---|---|---|
| Yalnızca metin | 46.4 | temel hat | temel hat |
| +1 örnek | 57.6 | +11.2 | +6.7 |
| +2 örnek | 62.2 | +15.8 | +9.7 |
| +3 örnek | 65.0 | +18.6 | +11.2 |
| +4 örnek | 65.7 | +19.3 | +11.5 (platolar) |
Link to this sectionNesne Sayma Doğruluğu#
SAM 3, nesne sayma işlemlerinde sıkça ihtiyaç duyulan tüm örnekleri segmentlere ayırarak doğru sayım sağlar:
| Kıyaslama | Doğruluk | MAE | En İyi MLLM'e Karşı |
|---|---|---|---|
| CountBench | %95.6 | 0.11 | %92.4 (Gemini 2.5) |
| PixMo-Count | %87.3 | 0.22 | %88.8 (Molmo-72B) |
Link to this sectionSAM 3, SAM 2 ve YOLO Karşılaştırması#
Burada SAM 3'ün yeteneklerini SAM 2 ve YOLO26 modelleriyle karşılaştırıyoruz:
| Yetenek | SAM 3 | SAM 2 | YOLO26n-seg |
|---|---|---|---|
| Kavram Segmentasyonu | ✅ Metin/örneklerden gelen tüm örnekler | ❌ Desteklenmiyor | ❌ Desteklenmiyor |
| Görsel Segmentasyon | ✅ Tek örnek (SAM 2 uyumlu) | ✅ Tek örnek | ✅ Tüm örnekler |
| Sıfır-atış (Zero-shot) Yeteneği | ✅ Açık kelime dağarcığı | ✅ Geometrik istemler | ❌ Kapalı küme |
| Etkileşimli İyileştirme | ✅ Örnekler + tıklamalar | ✅ Sadece tıklamalar | ❌ Desteklenmiyor |
| Video İzleme | ✅ Kimliklerle çoklu nesne | ✅ Çoklu nesne | ✅ Çoklu nesne |
| LVIS Mask AP (sıfır-atış) | 47.0 | N/A | N/A |
| MOSEv2 J&F | 60.1 | 47.9 | N/A |
| Hız (GPU, ms/im) | 2921 | 857 | 8.4 |
| Model Boyutu | 3.45 GB | 162 MB (temel) | 6.4 MB |
Hız testi torch==2.9.1 ve ultralytics==8.4.19 ile NVIDIA RTX PRO 6000 üzerinde gerçekleştirilmiştir.
Önemli Çıkarımlar:
- SAM 3: Metin veya örnek istemleriyle bir kavramın tüm örneklerini bulmak için açık kelime dağarcıklı kavram segmentasyonunda en iyisidir
- SAM 2: Geometrik istemlerle görüntülerde ve videolarda etkileşimli tek nesne segmentasyonu için en iyisidir
- YOLO26: NMS'siz uçtan uca çıkarım ile gerçek zamanlı, yüksek hızlı segmentasyon için en iyisidir, GPU'lar, CPU'lar ve uç cihazlarda dağıtım için birçok formata aktarılabilir
Link to this sectionSAM ve YOLO Karşılaştırması#
SAM 3, SAM 2, SAM, MobileSAM ve FastSAM modellerini, Ultralytics YOLO segmentasyon modelleriyle (YOLOv8, YOLO11, YOLO26) boyut, parametreler ve GPU çıkarım hızı açısından karşılaştırıyoruz:
| Model | Boyut (MB) | Parametreler (M) | Hız (GPU) (ms/im) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 1306 |
| Meta SAM2-b | 162 | 80.8 | 857 |
| Meta SAM2-t | 78.1 | 38.9 | 668 |
| Meta SAM3 | 3450 | 473.6 | 2921 |
| MobileSAM | 40.7 | 10.1 | 605 |
| FastSAM-s YOLOv8 backbone ile | 23.7 | 11.8 | 55.9 |
| Ultralytics YOLOv8n-seg | 6.7 (515 kat daha küçük) | 3.4 (139.1 kat daha az) | 17.4 (167 kat daha hızlı) |
| Ultralytics YOLO11n-seg | 5.9 (585 kat daha küçük) | 2.9 (163.1 kat daha az) | 12.6 (231 kat daha hızlı) |
| Ultralytics YOLO26n-seg | 6.4 (539 kat daha küçük) | 2.7 (175.2 kat daha az) | 8.4 (347 kat daha hızlı) |
Bu karşılaştırma, SAM varyantları ile YOLO segmentasyon modelleri arasındaki model boyutları ve hızlarındaki önemli farkları göstermektedir. SAM benzersiz otomatik segmentasyon yetenekleri sunarken, YOLO modelleri, özellikle YOLOv8n-seg, YOLO11n-seg ve YOLO26n-seg, önemli ölçüde daha küçük, daha hızlı ve hesaplama açısından daha verimlidir.
Testler, torch==2.9.1 ve ultralytics==8.4.19 kullanılarak 96GB VRAM'li bir NVIDIA RTX PRO 6000 üzerinde çalıştırılmıştır. Bu testi yeniden oluşturmak için:
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# Profile SAM3, SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt", "sam3.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# Profile FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# Profile YOLO models
for file_name in ["yolov8n-seg.pt", "yolo11n-seg.pt", "yolo26n-seg.pt"]:
model = YOLO(file_name)
model.info()
model(ASSETS)Link to this sectionDeğerlendirme Metrikleri#
SAM 3, F1 skoru, hassasiyet ve anımsama gibi bilinen ölçümleri tamamlayan, PCS görevi için tasarlanmış yeni metrikler sunar.
Link to this sectionSınıflandırma Korumalı F1 (CGF1)#
Yerelleştirme ve sınıflandırmayı birleştiren temel metrik:
CGF1 = 100 × pmF1 × IL_MCC
Burada:
- pmF1 (Pozitif Makro F1): Pozitif örnekler üzerindeki yerelleştirme kalitesini ölçer
- IL_MCC (Görüntü Düzeyinde Matthews Korelasyon Katsayısı): İkili sınıflandırma doğruluğunu ölçer ("kavram mevcut mu?")
Link to this sectionNeden Bu Metrikler?#
Geleneksel AP metrikleri kalibrasyonu hesaba katmaz, bu da modellerin pratikte kullanılmasını zorlaştırır. SAM 3'ün metrikleri, yalnızca 0.5 güven eşiğinin üzerindeki tahminleri değerlendirerek iyi bir kalibrasyon sağlar ve etkileşimli predict ve track döngülerindeki gerçek dünya kullanım modellerini taklit eder.
Link to this sectionÖnemli Ablasyonlar ve İçgörüler#
Link to this sectionVarlık Başlığının (Presence Head) Etkisi#
Varlık başlığı, tanımayı yerelleştirmeden ayırarak önemli iyileştirmeler sağlar:
| Yapılandırma | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Varlık başlığı olmadan | 57.6 | 0.77 | 74.7 |
| Varlık başlığı ile | 63.3 | 0.82 | 77.1 |
Varlık başlığı, özellikle tanıma yeteneğini (IL_MCC +%6.5) geliştirerek +5.7 CGF1 artışı (+%9.9) sağlar.
Link to this sectionZor Negatiflerin Etkisi#
| Görüntü Başına Zor Negatifler | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| 0 | 31.8 | 0.44 | 70.2 |
| 5 | 44.8 | 0.62 | 71.9 |
| 30 | 49.2 | 0.68 | 72.3 |
Zor negatif örnekler, açık uçlu kelime dağarcığı tanıma için kritik öneme sahiptir ve IL_MCC değerini %54,5 (0,44 → 0,68) oranında iyileştirir.
Link to this sectionEğitim Verisi Ölçeklendirme#
| Veri Kaynakları | CGF1 | IL_MCC | pmF1 |
|---|---|---|---|
| Sadece harici | 30.9 | 0.46 | 66.3 |
| Harici + Sentetik | 39.7 | 0.57 | 70.6 |
| Harici + HQ | 51.8 | 0.71 | 73.2 |
| Üçü birden | 54.3 | 0.74 | 73.5 |
Yüksek kaliteli insan etiketleri, yalnızca sentetik veya harici verilere kıyasla büyük kazanımlar sağlar. Veri kalitesi uygulamaları hakkında bilgi almak için veri toplama ve etiketleme bölümüne bak.
Link to this sectionUygulamalar#
SAM 3'ün kavram bölümleme yeteneği yeni kullanım durumlarını mümkün kılar:
- İçerik Denetimi: Medya kütüphanelerindeki belirli içerik türlerinin tüm örneklerini bul
- E-ticaret: Katalog görsellerindeki belirli bir türdeki tüm ürünleri segmentlere ayırarak otomatik etiketlemeyi destekle.
- Tıbbi Görüntüleme: Belirli doku türlerinin veya anormalliklerin tüm oluşumlarını tanımla
- Otonom Sistemler: Trafik işaretleri, yayalar veya araçların tüm örneklerini kategoriye göre takip et
- Video Analitiği: Belirli kıyafetleri giyen veya belirli eylemleri gerçekleştiren tüm insanları say ve takip et
- Veri Kümesi Etiketleme: Nadir nesne kategorilerinin tüm örneklerini hızla etiketle
- Bilimsel Araştırma: Belirli kriterlere uyan tüm numuneleri ölç ve analiz et
Link to this sectionSAM 3 Agent: Gelişmiş Dil Muhakemesi#
SAM 3, OWLv2 ve T-Rex gibi açık uçlu kelime dağarcığına sahip sistemlerin ruhuna benzer şekilde, muhakeme gerektiren karmaşık sorguları işlemek için Çok Modlu Büyük Dil Modelleri (MLLM) ile birleştirilebilir.
Link to this sectionMuhakeme Görevlerinde Performans#
| Kıyaslama | Metrik | SAM 3 Agent (Gemini 2.5 Pro) | Önceki En İyi |
|---|---|---|---|
| ReasonSeg (doğrulama) | gIoU | 76.0 | 65.0 (SoTA) |
| ReasonSeg (test) | gIoU | 73.8 | 61.3 (SoTA) |
| OmniLabel (doğrulama) | AP | 46.7 | 36.5 (REAL) |
| RefCOCO+ | Acc | 91.2 | 89.3 (LISA) |
Link to this sectionKarmaşık Sorgu Örnekleri#
SAM 3 Agent, muhakeme gerektiren sorguları şu şekilde işleyebilir:
- "Oturan ancak ellerinde hediye kutusu tutmayan insanlar"
- "Kameraya en yakın olan ve tasma takmayan köpek"
- "Kişinin elinden daha büyük kırmızı nesneler"
MLLM, SAM 3'e basit isim tamlaması sorguları önerir, döndürülen maskeleri analiz eder ve tatmin olana kadar tekrarlar.
Link to this sectionSınırlamalar#
SAM 3 büyük bir ilerlemeyi temsil etse de, bazı sınırlamalara sahiptir:
- İfade Karmaşıklığı: En iyi basit isim tamlamaları için uygundur; uzun atıfta bulunan ifadeler veya karmaşık muhakeme MLLM entegrasyonu gerektirebilir
- Belirsizlik Yönetimi: Bazı kavramlar özünde belirsiz kalır (ör. "küçük pencere", "rahat oda")
- Hesaplama Gereksinimleri: YOLO gibi özelleşmiş tespit modellerinden daha büyük ve daha yavaştır
- Kelime Dağarcığı Kapsamı: Atomik görsel kavramlara odaklanır; MLLM desteği olmadan bileşimsel muhakeme sınırlıdır
- Nadir Kavramlar: Eğitim verilerinde iyi temsil edilmeyen son derece nadir veya ince detaylı kavramlarda performans düşebilir
Link to this sectionAtıf#
@inproceedings{sam3_2025,
title = {SAM 3: Segment Anything with Concepts},
author = {Anonymous authors},
booktitle = {Submitted to ICLR 2026},
year = {2025},
url = {https://openreview.net/forum?id=r35clVtGzw},
note = {Paper ID: 4183, under double-blind review}
}Link to this sectionSSS#
Link to this sectionSAM 3 Ne Zaman Yayınlandı?#
SAM 3, Meta tarafından 20 Kasım 2025 tarihinde yayınlandı ve 8.3.237 (PR #22897) sürümü itibarıyla Ultralytics'e tamamen entegre edildi. predict modu ve track modu için tam destek mevcuttur.
Link to this sectionSAM 3 Ultralytics İçine Entegre Edildi mi?#
Yes! SAM 3 is fully integrated into the Ultralytics Python package, including concept segmentation, SAM 2–style visual prompts, and multi-object video tracking. SAM 3 also powers the smart annotation feature on Ultralytics Platform, where you can annotate images with just a few clicks.
Link to this sectionYönlendirilebilir Kavram Bölümleme (PCS) Nedir?#
PCS, SAM 3 ile tanıtılan ve bir görsel veya videodaki görsel bir kavramın tüm örneklerini bölütleyen yeni bir görevdir. Belirli bir nesne örneğini hedefleyen geleneksel bölümlemenin aksine, PCS bir kategorinin her oluşumunu bulur. Örneğin:
- Metin yönlendirmesi: "sarı okul otobüsü" → sahnedeki tüm sarı okul otobüslerini bölütler
- Görsel örneği: Bir köpeğin etrafındaki kutu → görseldeki tüm köpekleri bölütler
- Birleştirilmiş: "çizgili kedi" + örnek kutusu → örnekle eşleşen tüm çizgili kedileri bölütler
Nesne tespiti ve örnek bölümleme hakkındaki ilgili arka plana bak.
Link to this sectionSAM 3, SAM 2'den Nasıl Farklıdır?#
| Özellik | SAM 2 | SAM 3 |
|---|---|---|
| Görev | İstem başına tek nesne | Bir kavramın tüm örnekleri |
| İstem Türleri | Noktalar, kutular, maskeler | + Metin ifadeleri, görsel örnekleri |
| Tespit Yeteneği | Harici tespit cihazı gerektirir | Dahili açık uçlu kelime dağarcığı tespit cihazı |
| Tanıma | Sadece geometri tabanlı | Metin ve görsel tanıma |
| Mimari | Sadece takip edici | Varlık başlığına sahip tespit cihazı + Takip edici |
| Sıfır Çekim Performansı | N/A (görsel yönlendirmeler gerektirir) | LVIS üzerinde 47.0 AP, SA-Co üzerinde 2 kat daha iyi |
| Etkileşimli İyileştirme | Sadece tıklamalar | Tıklamalar + örnek genellemesi |
SAM 3, SAM 2 görsel yönlendirme ile geriye dönük uyumluluğu korurken kavram tabanlı yetenekler ekler.
Link to this sectionSAM 3'ü eğitmek için hangi veri kümeleri kullanılır?#
SAM 3, Segment Anything with Concepts (SA-Co) veri kümesi üzerinde eğitilir:
Eğitim Verisi:
- 5.2M görsel ve 4M benzersiz isim tamlaması (SA-Co/HQ) - yüksek kaliteli insan etiketlemeleri
- 52.5K video ve 24.8K benzersiz isim tamlaması (SA-Co/VIDEO)
- 38M isim tamlaması genelinde 1.4B sentetik maske (SA-Co/SYN)
- Zor negatif örneklerle zenginleştirilmiş 15 harici veri kümesi (SA-Co/EXT)
Kıyaslama Verileri:
- 126K görsel/video genelinde 214K benzersiz kavram
- Mevcut kıyaslamalara göre 50× daha fazla kavram (örneğin, LVIS ~4K kavrama sahiptir)
- İnsan performans sınırlarını ölçmek için SA-Co/Gold üzerinde üçlü etiketleme
Bu devasa ölçek ve çeşitlilik, SAM 3'ün açık uçlu kavramlar genelinde üstün sıfır-atımlı (zero-shot) genelleme yapmasını sağlar.
Link to this sectionSAM 3, segmentasyon konusunda YOLO26 ile nasıl karşılaştırılır?#
SAM 3 ve YOLO26 farklı kullanım durumlarına hizmet eder:
SAM 3 Avantajları:
- Açık uçlu (Open-vocabulary): Eğitim gerektirmeden metin istemleri aracılığıyla herhangi bir kavramı segmentlere ayırır
- Sıfır-atımlı (Zero-shot): Yeni kategoriler üzerinde anında çalışır
- Etkileşimli: Örnek tabanlı iyileştirme benzer nesnelere genellenir
- Kavram tabanlı: Bir kategorideki tüm örnekleri otomatik olarak bulur
- Doğruluk: LVIS sıfır-atımlı örnek segmentasyonunda 47.0 AP
YOLO26 Avantajları:
- Hız: NMS gerektirmeyen uçtan uca tasarım ile kat kat daha hızlı çıkarım
- Verimlilik: 539× daha küçük modeller (3.45GB yerine 6.4MB)
- Kaynak dostu: Uç cihazlarda ve mobilde çalışır
- Gerçek zamanlı: Üretim dağıtımları için optimize edilmiştir
Öneri:
- Metin veya örneklerle açıklanan kavramların tüm örneklerini bulman gereken esnek, açık uçlu segmentasyon için SAM 3 kullan
- Kategorilerin önceden bilindiği yüksek hızlı üretim dağıtımları için YOLO26 kullan
- Geometrik istemlerle etkileşimli tek nesne segmentasyonu için SAM 2 kullan
Link to this sectionSAM 3 karmaşık dil sorgularını işleyebilir mi?#
SAM 3, basit isim tamlamaları (örneğin, "kırmızı elma", "şapka takan kişi") için tasarlanmıştır. Akıl yürütme gerektiren karmaşık sorgular için, SAM 3'ü bir MLLM ile SAM 3 Agent olarak birleştir:
Basit sorgular (yerel SAM 3):
- "sarı okul otobüsü"
- "çizgili kedi"
- "kırmızı şapka takan kişi"
Karmaşık sorgular (MLLM ile SAM 3 Agent):
- "Oturan ancak hediye kutusu tutmayan insanlar"
- "Kameraya en yakın tasmasız köpek"
- "Kişinin elinden daha büyük kırmızı nesneler"
SAM 3 Agent, SAM 3'ün segmentasyonunu MLLM akıl yürütme yetenekleriyle birleştirerek ReasonSeg doğrulamasında 76.0 gIoU elde eder (önceki en iyi değer 65.0, +%16.9 iyileşme).
Link to this sectionSAM 3'ün doğruluğu insan performansına kıyasla ne düzeydedir?#
Üçlü insan etiketlemesi içeren SA-Co/Gold kıyaslamasında:
- İnsan alt sınırı: 74.2 CGF1 (en tutucu etiketleyici)
- SAM 3 performansı: 65.0 CGF1
- Başarı: Tahmini insan alt sınırının %88'i
- İnsan üst sınırı: 81.4 CGF1 (en esnek etiketleyici)
SAM 3, açık uçlu kavram segmentasyonunda insan seviyesine yaklaşan güçlü bir performans sergiler; boşluk temel olarak belirsiz veya öznel kavramlarda (örneğin, "küçük pencere", "rahat oda") ortaya çıkar.