أفضل الممارسات لنشر النماذج
مقدمة
يعد نشر النموذج هو الخطوة في مشروع رؤية الكمبيوتر التي تنقل النموذج من مرحلة التطوير إلى تطبيق في العالم الحقيقي. هناك العديد من خيارات نشر النموذج: يوفر النشر السحابي قابلية التوسع وسهولة الوصول، ويقلل النشر على الحافة من زمن الوصول عن طريق تقريب النموذج من مصدر البيانات، ويضمن النشر المحلي الخصوصية والتحكم. يعتمد اختيار الإستراتيجية الصحيحة على احتياجات تطبيقك، مع الموازنة بين السرعة والأمان وقابلية التوسع.
شاهد: كيفية تحسين ونشر نماذج الذكاء الاصطناعي: أفضل الممارسات واستكشاف الأخطاء وإصلاحها واعتبارات الأمان
من المهم أيضًا اتباع أفضل الممارسات عند نشر نموذج ما لأن النشر يمكن أن يؤثر بشكل كبير على فعالية وموثوقية أداء النموذج. في هذا الدليل، سنركز على كيفية التأكد من أن نشر النموذج الخاص بك سلس وفعال وآمن.
خيارات نشر النموذج
في كثير من الأحيان، بمجرد تدريب النموذج و تقييمه و اختباره، يجب تحويله إلى تنسيقات معينة ليتم نشره بفعالية في بيئات مختلفة، مثل السحابة أو الحافة أو الأجهزة المحلية.
باستخدام YOLO26، يمكنك تصدير نموذجك إلى تنسيقات مختلفة اعتمادًا على احتياجات النشر الخاصة بك. على سبيل المثال، يعد تصدير YOLO26 إلى ONNX أمرًا مباشرًا ومثاليًا لنقل النماذج بين الأطر. لاستكشاف المزيد من خيارات التكامل وضمان نشر سلس عبر بيئات مختلفة، قم بزيارة مركز تكامل النماذج الخاص بنا.
اختيار بيئة النشر
يعتمد اختيار مكان نشر نموذج الرؤية الحاسوبية الخاص بك على عوامل متعددة. تتمتع البيئات المختلفة بمزايا وتحديات فريدة، لذلك من الضروري اختيار البيئة التي تناسب احتياجاتك على أفضل وجه.
النشر السحابي
يعد النشر السحابي رائعًا للتطبيقات التي تحتاج إلى التوسع بسرعة والتعامل مع كميات كبيرة من البيانات. تسهل الأنظمة الأساسية مثل AWS و Google Cloud و Azure إدارة نماذجك من التدريب إلى النشر. إنها توفر خدمات مثل AWS SageMaker ومنصة Google AI و Azure Machine Learning لمساعدتك طوال العملية.
ومع ذلك، يمكن أن يكون استخدام السحابة مكلفًا، خاصة مع الاستخدام العالي للبيانات، وقد تواجه مشكلات في زمن الوصول إذا كان المستخدمون بعيدين عن مراكز البيانات. لإدارة التكاليف والأداء، من المهم تحسين استخدام الموارد وضمان الامتثال لقواعد خصوصية البيانات.
النشر على الحافة
يعمل النشر على الحافة بشكل جيد للتطبيقات التي تحتاج إلى استجابات في الوقت الفعلي وزمن انتقال منخفض، خاصة في الأماكن ذات الوصول المحدود أو المعدوم إلى الإنترنت. يضمن نشر النماذج على الأجهزة الطرفية مثل الهواتف الذكية أو أدوات إنترنت الأشياء معالجة سريعة ويحافظ على البيانات محلية، مما يعزز الخصوصية. يوفر النشر على الحافة أيضًا عرض النطاق الترددي نظرًا لتقليل البيانات المرسلة إلى السحابة.
ومع ذلك، غالبًا ما تكون أجهزة الحافة محدودة في قوة المعالجة، لذا ستحتاج إلى تحسين النماذج الخاصة بك. يمكن أن تساعد أدوات مثل TensorFlow Lite و NVIDIA Jetson. على الرغم من الفوائد، يمكن أن يكون الحفاظ على العديد من الأجهزة وتحديثها أمرًا صعبًا.
النشر المحلي
يكون النشر المحلي هو الأفضل عندما تكون خصوصية البيانات بالغة الأهمية أو عندما يكون الوصول إلى الإنترنت غير موثوق به أو معدومًا. يمنحك تشغيل النماذج على الخوادم المحلية أو أجهزة سطح المكتب تحكمًا كاملاً ويحافظ على أمان بياناتك. يمكن أن يقلل أيضًا من زمن الوصول إذا كان الخادم قريبًا من المستخدم.
ومع ذلك، يمكن أن يكون التوسع محليًا صعبًا، وقد يستغرق الصيانة وقتًا طويلاً. يمكن أن يساعد استخدام أدوات مثل Docker للحاويات و Kubernetes للإدارة في جعل عمليات النشر المحلية أكثر كفاءة. التحديثات والصيانة المنتظمة ضرورية للحفاظ على سير كل شيء بسلاسة.
حاويات لتسهيل عملية النشر
الحاويات هي طريقة قوية لحزم النموذج الخاص بك وجميع تبعياته في وحدة موحدة تسمى حاوية. تضمن هذه التقنية أداءً ثابتًا عبر بيئات مختلفة وتبسط عملية النشر.
فوائد استخدام Docker لنشر النموذج
أصبح Docker هو المعيار الصناعي للحاويات في عمليات نشر تعلم الآلة لعدة أسباب:
- اتساق البيئة: تغلف حاويات Docker النموذج الخاص بك وجميع تبعياته، مما يزيل مشكلة "إنه يعمل على جهازي" من خلال ضمان سلوك متسق عبر بيئات التطوير والاختبار والإنتاج.
- العزل: تعزل الحاويات التطبيقات عن بعضها البعض، مما يمنع التعارضات بين إصدارات البرامج أو المكتبات المختلفة.
- إمكانية النقل: يمكن لحاويات Docker العمل على أي نظام يدعم Docker، مما يسهل نشر النماذج الخاصة بك عبر منصات مختلفة دون تعديل.
- قابلية التوسع: يمكن بسهولة زيادة أو تقليل حجم الحاويات بناءً على الطلب، ويمكن لأدوات التنسيق مثل Kubernetes أتمتة هذه العملية.
- التحكم في الإصدار: يمكن ترقيم إصدارات صور Docker، مما يسمح لك بتتبع التغييرات والرجوع إلى الإصدارات السابقة إذا لزم الأمر.
تطبيق Docker لنشر YOLO26
لتحويل نموذج YOLO26 الخاص بك إلى حاوية، يمكنك إنشاء Dockerfile يحدد جميع التبعيات والتكوينات الضرورية. إليك مثال أساسي:
FROM ultralytics/ultralytics:latest
WORKDIR /app
# Copy your model and any additional files
COPY ./models/yolo26.pt /app/models/
COPY ./scripts /app/scripts/
# Set up any environment variables
ENV MODEL_PATH=/app/models/yolo26.pt
# Command to run when the container starts
CMD ["python", "/app/scripts/predict.py"]
تضمن هذه الطريقة أن يكون نشر النموذج الخاص بك قابلاً للتكرار ومتسقًا عبر البيئات المختلفة، مما يقلل بشكل كبير من مشكلة "يعمل على جهازي" التي غالبًا ما تبتلي عمليات النشر.
تقنيات تحسين النموذج
يساعد تحسين نموذج رؤية الكمبيوتر الخاص بك على تشغيله بكفاءة، خاصة عند النشر في بيئات ذات موارد محدودة مثل الأجهزة الطرفية. فيما يلي بعض التقنيات الأساسية لتحسين النموذج الخاص بك.
تقليم النموذج
يقلل التقليم من حجم النموذج عن طريق إزالة الأوزان التي تساهم بشكل ضئيل في الناتج النهائي. فهو يجعل النموذج أصغر وأسرع دون التأثير بشكل كبير على الدقة. يتضمن التقليم تحديد المعلمات غير الضرورية وإزالتها، مما يؤدي إلى نموذج أخف يتطلب طاقة حسابية أقل. وهو مفيد بشكل خاص لنشر النماذج على الأجهزة ذات الموارد المحدودة.
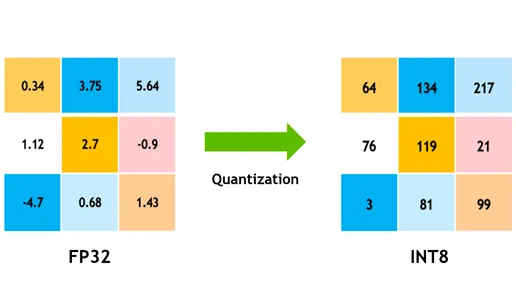
تكميم النموذج
يحول التكميم أوزان النموذج وتنشيطاته من دقة عالية (مثل الأعداد العشرية 32 بت) إلى دقة أقل (مثل الأعداد الصحيحة 8 بت). من خلال تقليل حجم النموذج، فإنه يسرع الاستدلال. التدريب المدرك للتكميم (QAT) هو طريقة يتم فيها تدريب النموذج مع وضع التكميم في الاعتبار، مما يحافظ على الدقة بشكل أفضل من التكميم بعد التدريب. من خلال التعامل مع التكميم خلال مرحلة التدريب، يتعلم النموذج التكيف مع الدقة الأقل، والحفاظ على الأداء مع تقليل المتطلبات الحسابية.
تقطير المعرفة
يتضمن تقطير المعرفة تدريب نموذج أصغر وأبسط (الطالب) لتقليد مخرجات نموذج أكبر وأكثر تعقيدًا (المعلم). يتعلم نموذج الطالب تقريب تنبؤات المعلم، مما يؤدي إلى نموذج مضغوط يحتفظ بالكثير من دقة المعلم. هذه التقنية مفيدة لإنشاء نماذج فعالة مناسبة للنشر على الأجهزة الطرفية ذات الموارد المحدودة.
استكشاف أخطاء النشر وإصلاحها
قد تواجه تحديات أثناء نشر نماذج رؤية الكمبيوتر الخاصة بك، ولكن فهم المشكلات والحلول الشائعة يمكن أن يجعل العملية أكثر سلاسة. فيما يلي بعض النصائح العامة لاستكشاف الأخطاء وإصلاحها وأفضل الممارسات لمساعدتك في التغلب على مشكلات النشر.
النموذج الخاص بك أقل دقة بعد النشر
قد يكون انخفاض دقة النموذج الخاص بك بعد النشر أمرًا محبطًا. يمكن أن تنبع هذه المشكلة من عوامل مختلفة. فيما يلي بعض الخطوات لمساعدتك في تحديد المشكلة وحلها:
- التحقق من اتساق البيانات: تحقق من أن البيانات التي يعالجها النموذج الخاص بك بعد النشر متوافقة مع البيانات التي تم تدريبه عليها. يمكن أن تؤثر الاختلافات في توزيع البيانات أو جودتها أو تنسيقها بشكل كبير على الأداء.
- التحقق من خطوات المعالجة المسبقة: تحقق من أن جميع خطوات المعالجة المسبقة التي يتم تطبيقها أثناء التدريب يتم تطبيقها أيضًا باستمرار أثناء النشر. وهذا يشمل تغيير حجم الصور، وتطبيع قيم البكسل، وتحويلات البيانات الأخرى.
- تقييم بيئة النموذج: تأكد من أن تكوينات الأجهزة والبرامج المستخدمة أثناء النشر تتطابق مع تلك المستخدمة أثناء التدريب. يمكن أن تؤدي الاختلافات في المكتبات والإصدارات وقدرات الأجهزة إلى اختلافات.
- مراقبة استدلال النموذج: سجل المدخلات والمخرجات في مراحل مختلفة من مسار الاستدلال detect أي حالات شاذة. يمكن أن يساعد في تحديد مشكلات مثل تلف البيانات أو المعالجة غير السليمة لمخرجات النموذج.
- مراجعة تصدير النموذج وتحويله: أعد تصدير النموذج وتأكد من أن عملية التحويل تحافظ على سلامة أوزان النموذج وهيكله.
- الاختبار باستخدام مجموعة بيانات مُدارة: انشر النموذج في بيئة اختبار مع مجموعة بيانات تتحكم فيها وقارن النتائج بمرحلة التدريب. يمكنك تحديد ما إذا كانت المشكلة في بيئة النشر أو البيانات.
عند نشر YOLO26، يمكن أن تؤثر عدة عوامل على دقة النموذج. يتضمن تحويل النماذج إلى تنسيقات مثل TensorRT تحسينات مثل تكميم الأوزان ودمج الطبقات، مما قد يسبب خسائر طفيفة في الدقة. يمكن أن يؤدي استخدام FP16 (نصف الدقة) بدلاً من FP32 (الدقة الكاملة) إلى تسريع الاستدلال ولكنه قد يؤدي إلى أخطاء في الدقة العددية. بالإضافة إلى ذلك، يمكن أن تؤثر قيود الأجهزة، مثل تلك الموجودة على Jetson Nano، ذات عدد أقل من أنوية CUDA وعرض نطاق ترددي منخفض للذاكرة، على الأداء.
عمليات الاستدلال تستغرق وقتًا أطول من المتوقع
عند نشر نماذج التعلم الآلي، من المهم أن تعمل بكفاءة. إذا استغرقت الاستدلالات وقتًا أطول من المتوقع، فقد يؤثر ذلك على تجربة المستخدم وفعالية تطبيقك. فيما يلي بعض الخطوات لمساعدتك في تحديد المشكلة وحلها:
- تنفيذ عمليات الإحماء: غالبًا ما تتضمن التشغيلات الأولية حملًا زائدًا للإعداد، مما قد يؤدي إلى انحراف قياسات زمن الوصول. قم بإجراء عدد قليل من الاستدلالات التجريبية قبل قياس زمن الوصول. يوفر استبعاد هذه التشغيلات الأولية قياسًا أكثر دقة لأداء النموذج.
- تحسين محرك الاستدلال: تأكد جيدًا من أن محرك الاستدلال مُحسَّن بالكامل لبنية وحدة معالجة الرسوميات (GPU) الخاصة بك. استخدم أحدث برامج التشغيل وإصدارات البرامج المصممة خصيصًا لأجهزتك لضمان أقصى قدر من الأداء والتوافق.
- استخدام المعالجة غير المتزامنة: يمكن أن تساعد المعالجة غير المتزامنة في إدارة أعباء العمل بكفاءة أكبر. استخدم تقنيات المعالجة غير المتزامنة للتعامل مع استدلالات متعددة في وقت واحد، مما يساعد على توزيع الحمل وتقليل أوقات الانتظار.
- تحليل أداء خط أنابيب الاستدلال: يمكن أن يساعد تحديد الاختناقات في خط أنابيب الاستدلال في تحديد مصدر التأخير. استخدم أدوات التحليل لتحليل كل خطوة من خطوات عملية الاستدلال، وتحديد ومعالجة أي مراحل تسبب تأخيرات كبيرة، مثل الطبقات غير الفعالة أو مشكلات نقل البيانات.
- استخدام الدقة المناسبة: يمكن أن يؤدي استخدام دقة أعلى من اللازم إلى إبطاء أوقات الاستدلال. جرب استخدام دقة أقل، مثل FP16 (نصف الدقة)، بدلاً من FP32 (الدقة الكاملة). في حين أن FP16 يمكن أن تقلل من وقت الاستدلال، ضع في اعتبارك أيضًا أنها يمكن أن تؤثر على دقة النموذج.
إذا كنت تواجه هذه المشكلة أثناء نشر YOLO26، فضع في اعتبارك أن YOLO26 يقدم أحجام نماذج متنوعة، مثل YOLO26n (نانو) للأجهزة ذات سعة الذاكرة المنخفضة و YOLO26x (كبير جدًا) لوحدات GPU الأكثر قوة. يمكن أن يساعد اختيار متغير النموذج المناسب لجهازك في تحقيق التوازن بين استخدام الذاكرة ووقت المعالجة.
ضع في اعتبارك أيضًا أن حجم الصور المدخلة يؤثر بشكل مباشر على استخدام الذاكرة ووقت المعالجة. تقلل الدقة المنخفضة من استخدام الذاكرة وتسرع الاستدلال، بينما تحسن الدقة العالية الدقة ولكنها تتطلب المزيد من الذاكرة وقوة المعالجة.
اعتبارات الأمان في نشر النماذج
جانب آخر مهم من جوانب النشر هو الأمن. يعد أمان النماذج المنشورة أمرًا بالغ الأهمية لحماية البيانات الحساسة والملكية الفكرية. فيما يلي بعض أفضل الممارسات التي يمكنك اتباعها فيما يتعلق بنشر النماذج الآمنة.
نقل البيانات بشكل آمن
يعد التأكد من أن البيانات المرسلة بين العملاء والخوادم آمنة أمرًا مهمًا للغاية لمنع اعتراضها أو الوصول إليها من قبل أطراف غير مصرح لها. يمكنك استخدام بروتوكولات التشفير مثل TLS (Transport Layer Security) لتشفير البيانات أثناء إرسالها. حتى إذا اعترض شخص ما البيانات، فلن يتمكن من قراءتها. يمكنك أيضًا استخدام التشفير الشامل الذي يحمي البيانات على طول الطريق من المصدر إلى الوجهة، بحيث لا يمكن لأي شخص في الوسط الوصول إليها.
ضوابط الوصول
من الضروري التحكم فيمن يمكنه الوصول إلى النموذج الخاص بك وبياناته لمنع الاستخدام غير المصرح به. استخدم طرق مصادقة قوية للتحقق من هوية المستخدمين أو الأنظمة التي تحاول الوصول إلى النموذج، وفكر في إضافة المزيد من الأمان باستخدام المصادقة متعددة العوامل (MFA). قم بإعداد التحكم في الوصول المستند إلى الأدوار (RBAC) لتعيين الأذونات بناءً على أدوار المستخدم حتى يتمكن الأشخاص من الوصول فقط إلى ما يحتاجون إليه. احتفظ بسجلات تدقيق مفصلة لـ track جميع عمليات الوصول والتغييرات التي تطرأ على النموذج وبياناته، وراجع هذه السجلات بانتظام لاكتشاف أي نشاط مشبوه.
إخفاء النموذج
يمكن حماية النموذج الخاص بك من التعرض للهندسة العكسية أو سوء الاستخدام من خلال إخفاء النموذج. وهو ينطوي على تشفير معلمات النموذج، مثل الأوزان والانحيازات في الشبكات العصبية، لجعل من الصعب على الأفراد غير المصرح لهم فهم النموذج أو تغييره. يمكنك أيضًا إخفاء بنية النموذج عن طريق إعادة تسمية الطبقات والمعلمات أو إضافة طبقات وهمية، مما يجعل من الصعب على المهاجمين إجراء هندسة عكسية له. يمكنك أيضًا تقديم النموذج في بيئة آمنة، مثل منطقة آمنة أو استخدام بيئة تنفيذ موثوقة (TEE)، مما يوفر طبقة إضافية من الحماية أثناء الاستدلال.
شارك الأفكار مع زملائك
يمكن أن تساعدك المشاركة في مجتمع من المتحمسين لرؤية الكمبيوتر في حل المشكلات والتعلم بشكل أسرع. فيما يلي بعض الطرق للتواصل والحصول على المساعدة وتبادل الأفكار.
مصادر المجتمع
- مشاكل GitHub: استكشف مستودع YOLO26 على GitHub واستخدم علامة تبويب المشاكل لطرح الأسئلة، والإبلاغ عن الأخطاء، واقتراح ميزات جديدة. المجتمع والقائمون على الصيانة نشطون للغاية ومستعدون للمساعدة.
- خادم Ultralytics Discord: انضم إلى خادم Ultralytics Discord للدردشة مع المستخدمين والمطورين الآخرين، والحصول على الدعم، ومشاركة خبراتك.
الوثائق الرسمية
- وثائق Ultralytics YOLO26: قم بزيارة وثائق YOLO26 الرسمية للحصول على أدلة مفصلة ونصائح مفيدة حول مشاريع رؤية الكمبيوتر المختلفة.
سيساعدك استخدام هذه الموارد على حل التحديات والبقاء على اطلاع دائم بأحدث الاتجاهات والممارسات في مجتمع رؤية الحاسوب.
الخلاصة والخطوات التالية
لقد استعرضنا بعض أفضل الممارسات التي يجب اتباعها عند نشر نماذج رؤية الكمبيوتر. من خلال تأمين البيانات والتحكم في الوصول وإخفاء تفاصيل النموذج، يمكنك حماية المعلومات الحساسة مع الحفاظ على تشغيل النماذج بسلاسة. ناقشنا أيضًا كيفية معالجة المشكلات الشائعة مثل انخفاض الدقة والاستدلالات البطيئة باستخدام استراتيجيات مثل عمليات الإحماء، وتحسين المحركات، والمعالجة غير المتزامنة، وخطوط الأنابيب التعريفية، واختيار الدقة الصحيحة.
بعد نشر النموذج الخاص بك، فإن الخطوة التالية هي مراقبة تطبيقك وصيانته وتوثيقه. تساعد المراقبة المنتظمة في اكتشاف المشكلات وإصلاحها بسرعة، وتحافظ الصيانة على تحديث النماذج الخاصة بك وعملها، وتتبع الوثائق الجيدة جميع التغييرات والتحديثات. ستساعدك هذه الخطوات على تحقيق أهداف مشروع رؤية الكمبيوتر الخاص بك.
الأسئلة الشائعة
ما هي أفضل الممارسات لنشر نموذج تعلم آلي باستخدام Ultralytics YOLO26؟
يتضمن نشر نموذج تعلم آلة، وخاصةً باستخدام Ultralytics YOLO26، العديد من أفضل الممارسات لضمان الكفاءة والموثوقية. أولاً، اختر بيئة النشر التي تناسب احتياجاتك—سحابية، أو طرفية، أو محلية. قم بتحسين نموذجك من خلال تقنيات مثل التقليم، والتكميم، وتقطير المعرفة للنشر الفعال في البيئات محدودة الموارد. فكر في استخدام الحاويات مع Docker لضمان الاتساق عبر البيئات المختلفة. أخيرًا، تأكد من توافق اتساق البيانات وخطوات المعالجة المسبقة مع مرحلة التدريب للحفاظ على الأداء. يمكنك أيضًا الرجوع إلى خيارات نشر النموذج للحصول على إرشادات أكثر تفصيلاً.
كيف يمكنني استكشاف مشكلات النشر الشائعة وإصلاحها مع نماذج Ultralytics YOLO26؟
يمكن تقسيم استكشاف أخطاء النشر وإصلاحها إلى بعض الخطوات الرئيسية. إذا انخفضت دقة النموذج الخاص بك بعد النشر، فتحقق من تناسق البيانات، وتحقق من صحة خطوات المعالجة المسبقة، وتأكد من أن بيئة الأجهزة / البرامج تطابق ما استخدمته أثناء التدريب. للحصول على أوقات استنتاج بطيئة، قم بإجراء عمليات إحماء، وحسّن محرك الاستنتاج الخاص بك، واستخدم المعالجة غير المتزامنة، وقم بملف تعريف خط أنابيب الاستنتاج الخاص بك. ارجع إلى استكشاف أخطاء النشر وإصلاحها للحصول على دليل مفصل حول أفضل الممارسات هذه.
كيف يعزز تحسين Ultralytics YOLO26 أداء النموذج على الأجهزة الطرفية؟
يتضمن تحسين نماذج Ultralytics YOLO26 للأجهزة الطرفية استخدام تقنيات مثل التقليم لتقليل حجم النموذج، والتكميم لتحويل الأوزان إلى دقة أقل، وتقطير المعرفة لتدريب نماذج أصغر تحاكي النماذج الأكبر. تضمن هذه التقنيات تشغيل النموذج بكفاءة على الأجهزة ذات القدرة الحاسوبية المحدودة. تعد أدوات مثل TensorFlow Lite و NVIDIA Jetson مفيدة بشكل خاص لهذه التحسينات. تعرف على المزيد حول هذه التقنيات في قسمنا حول تحسين النموذج.
ما هي الاعتبارات الأمنية لنشر نماذج التعلم الآلي باستخدام Ultralytics YOLO26؟
الأمان له أهمية قصوى عند نشر نماذج تعلم الآلة. تأكد من نقل البيانات بشكل آمن باستخدام بروتوكولات التشفير مثل TLS. قم بتطبيق عناصر تحكم وصول قوية، بما في ذلك المصادقة القوية والتحكم في الوصول المستند إلى الأدوار (RBAC). توفر تقنيات إخفاء النموذج، مثل تشفير معلمات النموذج وتقديم النماذج في بيئة آمنة مثل بيئة التنفيذ الموثوقة (TEE)، حماية إضافية. للحصول على ممارسات مفصلة، راجع اعتبارات الأمان.
كيف أختار بيئة النشر المناسبة لنموذج Ultralytics YOLO26 الخاص بي؟
يعتمد اختيار بيئة النشر المثلى لنموذج Ultralytics YOLO26 الخاص بك على الاحتياجات المحددة لتطبيقك. يوفر النشر السحابي قابلية التوسع وسهولة الوصول، مما يجعله مثاليًا للتطبيقات ذات أحجام البيانات الكبيرة. يعد النشر الطرفي هو الأفضل للتطبيقات ذات زمن الاستجابة المنخفض التي تتطلب استجابات في الوقت الفعلي، باستخدام أدوات مثل TensorFlow Lite. يناسب النشر المحلي السيناريوهات التي تحتاج إلى خصوصية وتحكم صارمين في البيانات. للحصول على نظرة عامة شاملة لكل بيئة، تحقق من قسمنا حول اختيار بيئة النشر.




