Ultralytics YOLO11
概要
YOLO11は2024年9月10日にUltralyticsによってリリースされ、優れた精度、速度、効率を提供します。以前のYOLOバージョンの目覚ましい進歩を基盤として、YOLO11はアーキテクチャとトレーニング方法に大幅な改善を導入し、幅広いコンピュータービジョンタスクに対応する多用途な選択肢となっています。エンドツーエンドのNMSフリー推論と最適化されたエッジデプロイメントを備えた最新のUltralyticsモデルについては、YOLO26をご覧ください。
Ultralytics YOLO11 🚀 NotebookLMによって生成されたポッドキャスト
見る: Ultralytics YOLO11を物体検出とトラッキングに使用する方法 | ベンチマーク方法 | YOLO11リリース🚀
Ultralytics をお試しください
Ultralytics Platform上でYOLO11 直接探索・実行できます。
主な特徴
- 強化された特徴抽出: YOLO11は、改善されたバックボーンとネックアーキテクチャを採用しており、より正確な物体検出と複雑なタスクパフォーマンスのための特徴抽出機能を強化します。
- 効率と速度の最適化: YOLO11 は、洗練されたアーキテクチャ設計と最適化されたトレーニングパイプラインを導入し、より高速な処理速度を実現し、精度とパフォーマンスの最適なバランスを維持します。
- 少ないパラメータで高い精度: モデル設計の進歩により、YOLO11mはYOLOv8mと比較して22%少ないパラメータを使用しながら、COCOデータセットでより高いmean Average Precision (mAP) を達成し、精度を損なうことなく計算効率を高めています。
- 環境全体での適応性: YOLO11は、エッジデバイス、クラウドプラットフォーム、NVIDIA GPUをサポートするシステムなど、さまざまな環境にシームレスにデプロイでき、最大限の柔軟性を保証します。
- 広範なサポート対象タスク: オブジェクト検出、インスタンスセグメンテーション、画像分類、ポーズ推定、または指向性オブジェクト検出(OBB)であれ、YOLO11は、多様なコンピュータビジョン課題に対応するように設計されています。
サポートされているタスクとモード
YOLO11は、以前のUltralytics YOLOリリースによって確立された汎用性の高いモデル群を基盤として構築されており、さまざまなコンピュータービジョンタスクで強化されたサポートを提供します。
| モデル | ファイル名 | タスク | 推論 | 検証 | 学習 | エクスポート |
|---|---|---|---|---|---|---|
| YOLO11 | yolo11n.pt yolo11s.pt yolo11m.pt yolo11l.pt yolo11x.pt | 検出 | ✅ | ✅ | ✅ | ✅ |
| YOLO11-seg | yolo11n-seg.pt yolo11s-seg.pt yolo11m-seg.pt yolo11l-seg.pt yolo11x-seg.pt | インスタンスセグメンテーション | ✅ | ✅ | ✅ | ✅ |
| YOLO11-pose | yolo11n-pose.pt yolo11s-pose.pt yolo11m-pose.pt yolo11l-pose.pt yolo11x-pose.pt | ポーズ/キーポイント | ✅ | ✅ | ✅ | ✅ |
| YOLO11-obb | yolo11n-obb.pt yolo11s-obb.pt yolo11m-obb.pt yolo11l-obb.pt yolo11x-obb.pt | 傾斜検出 | ✅ | ✅ | ✅ | ✅ |
| YOLO11-cls | yolo11n-cls.pt yolo11s-cls.pt yolo11m-cls.pt yolo11l-cls.pt yolo11x-cls.pt | 分類 | ✅ | ✅ | ✅ | ✅ |
この表は、YOLO11モデルのバリアントの概要を示し、特定のタスクへの適用性と、推論、検証、トレーニング、エクスポートなどの動作モードとの互換性を示しています。この柔軟性により、YOLO11は、リアルタイム検出から複雑なセグメンテーションタスクまで、コンピュータビジョンの幅広いアプリケーションに適しています。
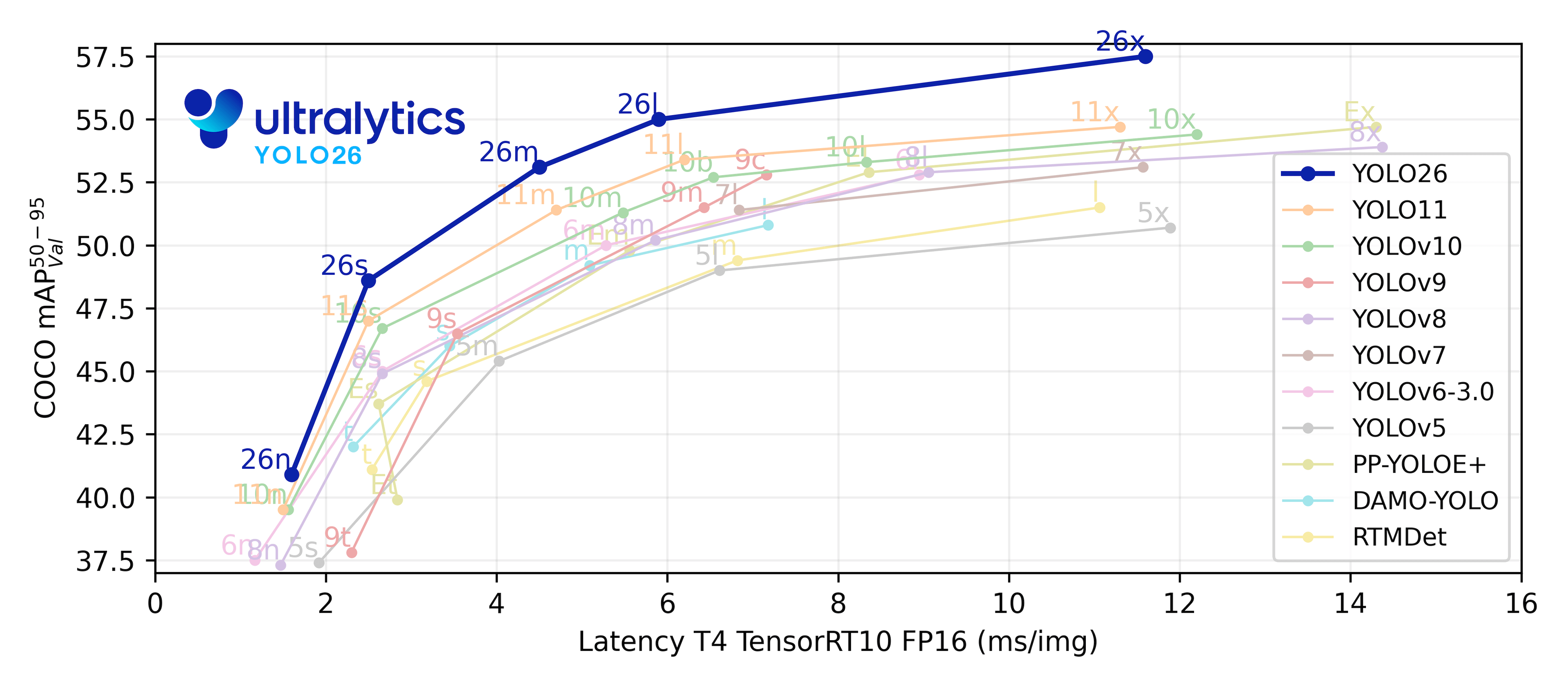
パフォーマンス指標
パフォーマンス
検出ドキュメントで、80の事前学習済みクラスを含むCOCOでトレーニングされたこれらのモデルの使用例をご覧ください。
| モデル | サイズ (ピクセル) | mAPval 50-95 | 速度 CPU ONNX (ms) | 速度 T4 TensorRT10 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLO11n | 640 | 39.5 | 56.1 ± 0.8 | 1.5 ± 0.0 | 2.6 | 6.5 |
| YOLO11s | 640 | 47.0 | 90.0 ± 1.2 | 2.5 ± 0.0 | 9.4 | 21.5 |
| YOLO11m | 640 | 51.5 | 183.2 ± 2.0 | 4.7 ± 0.1 | 20.1 | 68.0 |
| YOLO11l | 640 | 53.4 | 238.6 ± 1.4 | 6.2 ± 0.1 | 25.3 | 86.9 |
| YOLO11x | 640 | 54.7 | 462.8 ± 6.7 | 11.3 ± 0.2 | 56.9 | 194.9 |
セグメンテーションドキュメントで、80の事前学習済みクラスを含むCOCOでトレーニングされたこれらのモデルの使用例をご覧ください。
| モデル | サイズ (ピクセル) | mAPbox 50-95 | mAPmask 50-95 | 速度 CPU ONNX (ms) | 速度 T4 TensorRT10 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO11n-seg | 640 | 38.9 | 32.0 | 65.9 ± 1.1 | 1.8 ± 0.0 | 2.9 | 9.7 |
| YOLO11s-seg | 640 | 46.6 | 37.8 | 117.6 ± 4.9 | 2.9 ± 0.0 | 10.1 | 33.0 |
| YOLO11m-seg | 640 | 51.5 | 41.5 | 281.6 ± 1.2 | 6.3 ± 0.1 | 22.4 | 113.2 |
| YOLO11l-seg | 640 | 53.4 | 42.9 | 344.2 ± 3.2 | 7.8 ± 0.2 | 27.6 | 132.2 |
| YOLO11x-seg | 640 | 54.7 | 43.8 | 664.5 ± 3.2 | 15.8 ± 0.7 | 62.1 | 296.4 |
分類ドキュメントで、1000の事前学習済みクラスを含むImageNetでトレーニングされたこれらのモデルの使用例をご覧ください。
| モデル | サイズ (ピクセル) | acc top1 | acc top5 | 速度 CPU ONNX (ms) | 速度 T4 TensorRT10 (ms) | params (M) | FLOPs (B) at 224 |
|---|---|---|---|---|---|---|---|
| YOLO11n-cls | 224 | 70.0 | 89.4 | 5.0 ± 0.3 | 1.1 ± 0.0 | 2.8 | 0.5 |
| YOLO11s-cls | 224 | 75.4 | 92.7 | 7.9 ± 0.2 | 1.3 ± 0.0 | 6.7 | 1.6 |
| YOLO11m-cls | 224 | 77.3 | 93.9 | 17.2 ± 0.4 | 2.0 ± 0.0 | 11.6 | 4.9 |
| YOLO11l-cls | 224 | 78.3 | 94.3 | 23.2 ± 0.3 | 2.8 ± 0.0 | 14.1 | 6.2 |
| YOLO11x-cls | 224 | 79.5 | 94.9 | 41.4 ± 0.9 | 3.8 ± 0.0 | 29.6 | 13.6 |
COCOでトレーニングされ、1つの事前学習済みクラス「person」を含むこれらのモデルの使用例については、ポーズ推定ドキュメントを参照してください。
| モデル | サイズ (ピクセル) | mAPpose 50-95 | mAPpose 50 | 速度 CPU ONNX (ms) | 速度 T4 TensorRT10 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO11n-pose | 640 | 50.0 | 81.0 | 52.4 ± 0.5 | 1.7 ± 0.0 | 2.9 | 7.4 |
| YOLO11s-pose | 640 | 58.9 | 86.3 | 90.5 ± 0.6 | 2.6 ± 0.0 | 9.9 | 23.1 |
| YOLO11m-pose | 640 | 64.9 | 89.4 | 187.3 ± 0.8 | 4.9 ± 0.1 | 20.9 | 71.4 |
| YOLO11l-pose | 640 | 66.1 | 89.9 | 247.7 ± 1.1 | 6.4 ± 0.1 | 26.1 | 90.3 |
| YOLO11x-pose | 640 | 69.5 | 91.1 | 488.0 ± 13.9 | 12.1 ± 0.2 | 58.8 | 202.8 |
指向性検出ドキュメントで、15の事前学習済みクラスを含むDOTAv1でトレーニングされたこれらのモデルの使用例をご覧ください。
| モデル | サイズ (ピクセル) | mAPtest 50 | 速度 CPU ONNX (ms) | 速度 T4 TensorRT10 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLO11n-obb | 1024 | 78.4 | 117.6 ± 0.8 | 4.4 ± 0.0 | 2.7 | 16.8 |
| YOLO11s-obb | 1024 | 79.5 | 219.4 ± 4.0 | 5.1 ± 0.0 | 9.7 | 57.1 |
| YOLO11m-obb | 1024 | 80.9 | 562.8 ± 2.9 | 10.1 ± 0.4 | 20.9 | 182.8 |
| YOLO11l-obb | 1024 | 81.0 | 712.5 ± 5.0 | 13.5 ± 0.6 | 26.1 | 231.2 |
| YOLO11x-obb | 1024 | 81.3 | 1408.6 ± 7.7 | 28.6 ± 1.0 | 58.8 | 519.1 |
使用例
このセクションでは、簡単なYOLO11のトレーニングと推論の例を紹介します。これらおよびその他のモードに関する完全なドキュメントについては、Predict、Train、Val、およびExportのドキュメントページを参照してください。
以下の例は、物体検出用のYOLO11 Detectモデルに関するものであることに注意してください。その他のサポートされているタスクについては、Segment、Classify、OBB、およびPoseのドキュメントを参照してください。
例
PyTorch 学習済み *.pt モデルおよび構成 *.yaml filesを以下に渡すことができます。 YOLO() pythonでモデルインスタンスを作成するためのclass:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLO11n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")
CLIコマンドは、モデルを直接実行するために利用できます。
# Load a COCO-pretrained YOLO11n model and train it on the COCO8 example dataset for 100 epochs
yolo train model=yolo11n.pt data=coco8.yaml epochs=100 imgsz=640
# Load a COCO-pretrained YOLO11n model and run inference on the 'bus.jpg' image
yolo predict model=yolo11n.pt source=path/to/bus.jpg
引用と謝辞
Ultralytics YOLO11 の出版物
Ultralyticsは、モデルの急速な進化のため、YOLO11の正式な研究論文を発表していません。静的なドキュメントを作成するのではなく、テクノロジーを進歩させ、使いやすくすることに重点を置いています。YOLOアーキテクチャ、機能、および使用法に関する最新情報については、GitHubリポジトリおよびドキュメントを参照してください。
YOLO11 またはこのリポジトリのその他のソフトウェアを研究で使用する場合は、次の形式で引用してください。
@software{yolo11_ultralytics,
author = {Glenn Jocher and Jing Qiu},
title = {Ultralytics YOLO11},
version = {11.0.0},
year = {2024},
url = {https://github.com/ultralytics/ultralytics},
orcid = {0000-0001-5950-6979, 0000-0003-3783-7069},
license = {AGPL-3.0}
}
DOIは申請中であり、利用可能になり次第、引用に追加されます。YOLO11モデルは、AGPL-3.0およびEnterpriseライセンスの下で提供されます。
よくある質問
Ultralytics YOLO11におけるYOLOv8と比較した主な改善点は何ですか?
Ultralytics YOLO11は、YOLOv8と比較していくつかの重要な進歩を導入しています。主な改善点は以下の通りです。
- 強化された特徴抽出: YOLO11は、改善されたバックボーンとネックのアーキテクチャを採用し、より正確な物体検出のために特徴抽出機能を強化します。
- 効率と速度の最適化: 洗練されたアーキテクチャ設計と最適化されたトレーニングパイプラインにより、より高速な処理速度を実現し、精度とパフォーマンスのバランスを維持します。
- 少ないパラメータで高い精度: YOLO11mは、YOLOv8mと比較して22%少ないパラメータでCOCOデータセットにおいてより高いmean Average Precision (mAP) を達成し、精度を損なうことなく計算効率を高めています。
- 環境全体での適応性: YOLO11は、エッジデバイス、クラウドプラットフォーム、NVIDIA GPUをサポートするシステムなど、さまざまな環境にデプロイできます。
- 広範なサポート対象タスク: YOLO11は、オブジェクト検出、インスタンスセグメンテーション、画像分類、ポーズ推定、指向性オブジェクト検出(OBB)など、多様なコンピュータビジョンタスクをサポートしています。
物体検出のために YOLO11 モデルをトレーニングするにはどうすればよいですか?
オブジェクト検出用のYOLO11モデルの学習は、PythonまたはCLIコマンドを使用して実行できます。以下は、両方のメソッドの例です。
例
from ultralytics import YOLO
# Load a COCO-pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Load a COCO-pretrained YOLO11n model and train it on the COCO8 example dataset for 100 epochs
yolo train model=yolo11n.pt data=coco8.yaml epochs=100 imgsz=640
詳細な手順については、Trainのドキュメントを参照してください。
YOLO11モデルはどのようなタスクを実行できますか?
YOLO11モデルは汎用性が高く、以下を含む幅広いコンピュータビジョンタスクをサポートしています。
- 物体検出: 画像内の物体を識別して位置を特定します。
- インスタンスセグメンテーション: オブジェクトを検出し、その境界を明確にします。
- Image Classification(画像分類):画像を定義済みのクラスに分類します。
- 姿勢推定: 人体上のキーポイントを検出および追跡します。
- 傾斜物体検出 (OBB): 回転を伴う物体を検出し、精度を高めます。
各タスクの詳細については、Detection、Instance Segmentation、Classification、Pose Estimation、およびOriented Detectionのドキュメントをご覧ください。
YOLO11は、より少ないパラメータで、どのようにしてより高い精度を達成していますか?
YOLO11は、モデル設計と最適化技術の進歩により、より少ないパラメータで高い精度を実現します。改善されたアーキテクチャは、効率的な特徴抽出と処理を可能にし、YOLOv8mと比較して22%少ないパラメータを使用しながら、COCOのようなデータセットでより高いmean Average Precision (mAP) を達成します。これにより、YOLO11は精度を損なうことなく計算効率が高く、リソースが限られたデバイスへの展開に適しています。
YOLO11をエッジデバイスにデプロイできますか?
はい、YOLO11は、エッジデバイスを含むさまざまな環境での適応性を考慮して設計されています。最適化されたアーキテクチャと効率的な処理能力により、エッジデバイス、クラウドプラットフォーム、およびNVIDIA GPUをサポートするシステムへのデプロイに適しています。この柔軟性により、YOLO11は、モバイルデバイスでのリアルタイム検出からクラウド環境での複雑なセグメンテーションタスクまで、多様なアプリケーションで使用できます。デプロイオプションの詳細については、エクスポートのドキュメントを参照してください。





