Aangepaste gegevens trainen
📚 Deze handleiding legt uit hoe je je eigen aangepaste dataset kunt trainen met YOLOv5 🚀.
Voordat je begint
Kloon repo en installeer requirements.txt in een Python>=3.8.0 omgeving, inclusief PyTorch>=1.8. Modellen en datasets worden automatisch gedownload van de nieuwste YOLOv5 release.
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
Trainen op aangepaste gegevens

Het maken van een aangepast model om je objecten te detecteren is een iteratief proces van het verzamelen en organiseren van afbeeldingen, het labelen van je interessante objecten, het trainen van een model, het inzetten in het wild om voorspellingen te doen en vervolgens het inzetten van dat model gebruiken om voorbeelden van randgevallen te verzamelen om te herhalen en te verbeteren.
Licentie
Ultralytics biedt twee licentie-opties:
- De AGPL-3.0 Licentie, een door OSI goedgekeurde open-source licentie die ideaal is voor studenten en enthousiastelingen.
- De Enterprise License voor bedrijven die onze AI-modellen in hun producten en diensten willen opnemen.
Zie Ultralytics Licenties voor meer informatie.
YOLOv5 Modellen moeten worden getraind op gelabelde gegevens om klassen van objecten in die gegevens te leren. Er zijn twee opties om je dataset te maken voordat je begint met trainen:
Optie 1: Een Roboflow Dataset
1.1 Afbeeldingen verzamelen
Je model leert door het goede voorbeeld te geven. Trainen op beelden die lijken op de beelden die het in het wild zal zien is van het grootste belang. In het ideale geval verzamel je een grote verscheidenheid aan afbeeldingen met dezelfde configuratie (camera, hoek, belichting, enz.) als je uiteindelijk je project zult inzetten.
Als dit niet mogelijk is, kun je uitgaan van een openbare dataset om je initiële model te trainen en vervolgens tijdens de inferentie afbeeldingen uit het wild nemen om je dataset en model iteratief te verbeteren.
1.2 Labels maken
Als je eenmaal afbeeldingen hebt verzameld, moet je de objecten van belang annoteren om een grondwaarheid te creëren waarvan je model kan leren.
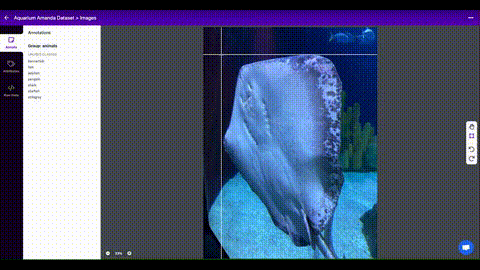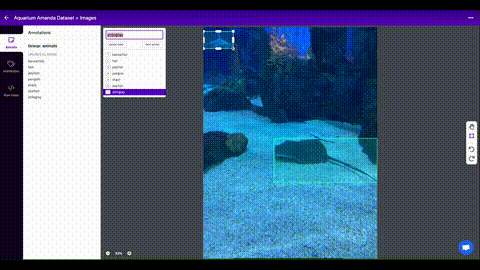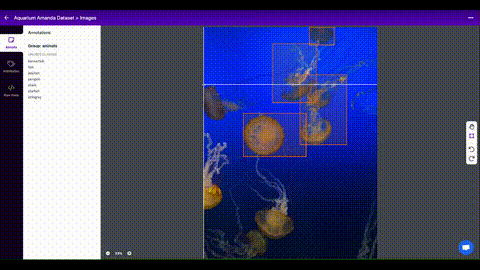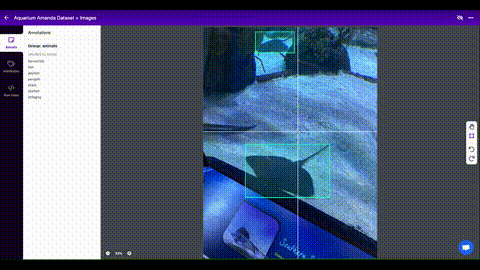
Roboflow Annotate is een eenvoudige webtool voor het beheren en labelen van je afbeeldingen met je team en om ze te exporteren in YOLOv5's annotatieformaat.
1.3 Dataset voorbereiden voor YOLOv5
Of je je afbeeldingen nu labelt met Roboflow of niet, je kunt het gebruiken om je dataset te converteren naar YOLO formaat, een YOLOv5 YAML configuratiebestand te maken en het te hosten om te importeren in je trainingsscript.
Maak een gratis Roboflow account aan en upload je dataset naar een Public werkruimte, label alle niet-geannoteerde afbeeldingen en genereer en exporteer vervolgens een versie van je dataset in YOLOv5 Pytorch formaat.
Opmerking: YOLOv5 doet online augmentatie tijdens de training, dus we raden niet aan om augmentatiestappen toe te passen in Roboflow voor training met YOLOv5. Maar we raden aan de volgende voorbewerkingsstappen toe te passen:
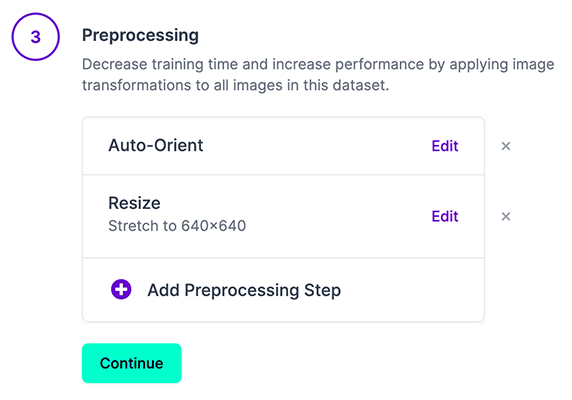
- Auto-Orient - om EXIF-oriëntatie van je afbeeldingen te verwijderen.
- Resize (Uitrekken) - naar de vierkante invoergrootte van je model (640x640 is de YOLOv5 standaard).
Het genereren van een versie geeft je een momentopname van je dataset, zodat je altijd terug kunt gaan en je toekomstige model trainingsruns ermee kunt vergelijken, zelfs als je later meer afbeeldingen toevoegt of de configuratie verandert.
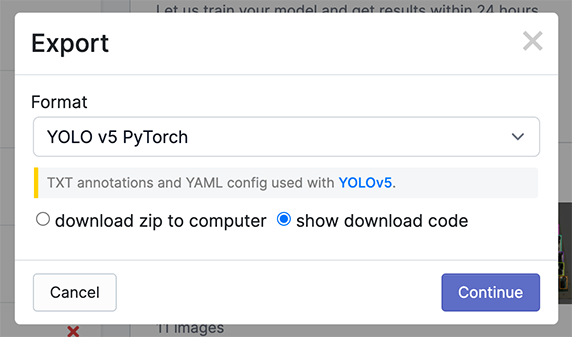
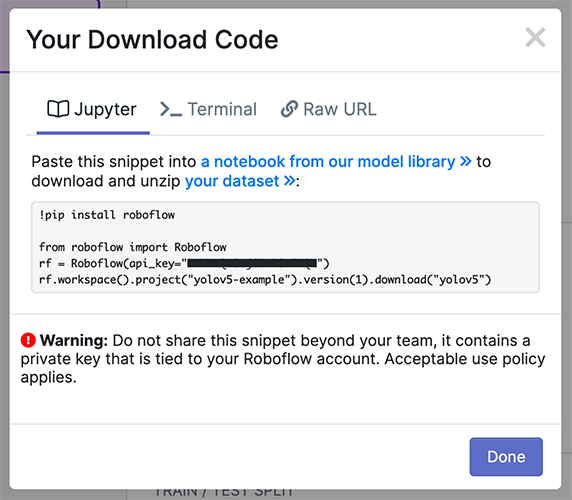
Exporteren in YOLOv5 Pytorch formaat en kopieer het knipsel naar je trainingsscript of notitieblok om je dataset te downloaden.
Optie 2: Een handmatige dataset maken
2.1 Creëer dataset.yaml
COCO128 is een voorbeeld van een kleine zelfstudiedataset die bestaat uit de eerste 128 afbeeldingen in COCO train2017. Deze zelfde 128 afbeeldingen worden gebruikt voor zowel training als validatie om te controleren of onze trainingslijn in staat is tot overfitting. gegevens/coco128.yaml, hieronder weergegeven, is het configuratiebestand van de dataset dat 1) de hoofddirectory van de dataset definieert path en relatieve paden naar train / val / test afbeeldingsmappen (of *.txt bestanden met afbeeldingspaden) en 2) een klasse names woordenboek:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes (80 COCO classes)
names:
0: person
1: bicycle
2: car
# ...
77: teddy bear
78: hair drier
79: toothbrush
2.2 Labels maken
Nadat je een annotatiegereedschap hebt gebruikt om je afbeeldingen te labelen, kun je je labels exporteren naar YOLO formaatmet één *.txt bestand per afbeelding (als er geen objecten in de afbeelding staan, geen *.txt bestand nodig is). De *.txt bestandsspecificaties zijn:
- Eén rij per object
- Elke rij is
class x_center y_center width heightformaat. - Boxcoördinaten moeten in genormaliseerde xywh formaat (van 0 tot 1). Als je vakken in pixels zijn, deel dan
x_centerenwidthper beeldbreedte eny_centerenheightdoor afbeeldingshoogte. - Klassenummers zijn nul-geïndexeerd (beginnen bij 0).

Het labelbestand dat overeenkomt met de bovenstaande afbeelding bevat 2 personen (klasse 0) en een gelijkspel (klasse 27):

2.3 Mappen organiseren
Organiseer je trein- en valafbeeldingen en labels volgens het onderstaande voorbeeld. YOLOv5 veronderstelt /coco128 binnen een /datasets map naast de /yolov5 map. YOLOv5 Lokaliseert labels automatisch voor elke afbeelding door de laatste instantie van /images/ in elk afbeeldingspad met /labels/. Bijvoorbeeld:

3. Selecteer een model
Selecteer een voorgetraind model om mee te gaan trainen. Hier selecteren we YOLOv5s, het op één na kleinste en snelste model dat beschikbaar is. Zie onze README tabel voor een volledige vergelijking van alle modellen.

4. Trein
Train een YOLOv5s-model op COCO128 door dataset, batchgrootte, afbeeldingsgrootte en ofwel voorgetrainde --weights yolov5s.pt (aanbevolen), of willekeurig geïnitialiseerd --weights '' --cfg yolov5s.yaml (niet aanbevolen). Voorgetrainde gewichten worden automatisch gedownload van de nieuwste YOLOv5 release.
Tip
Toevoegen --cache ram of --cache disk om de training te versnellen (vereist veel RAM- en schijfruimte).
Tip
💡 Train altijd vanaf een lokale dataset. Gemonteerde of netwerkschijven zoals Google Drive zullen erg traag zijn.
Alle trainingsresultaten worden opgeslagen in runs/train/ met oplopende run directories, dus runs/train/exp2, runs/train/exp3 enz. Zie voor meer informatie het gedeelte Training van ons zelfstudieschrift. ![]()

5. Visualiseer
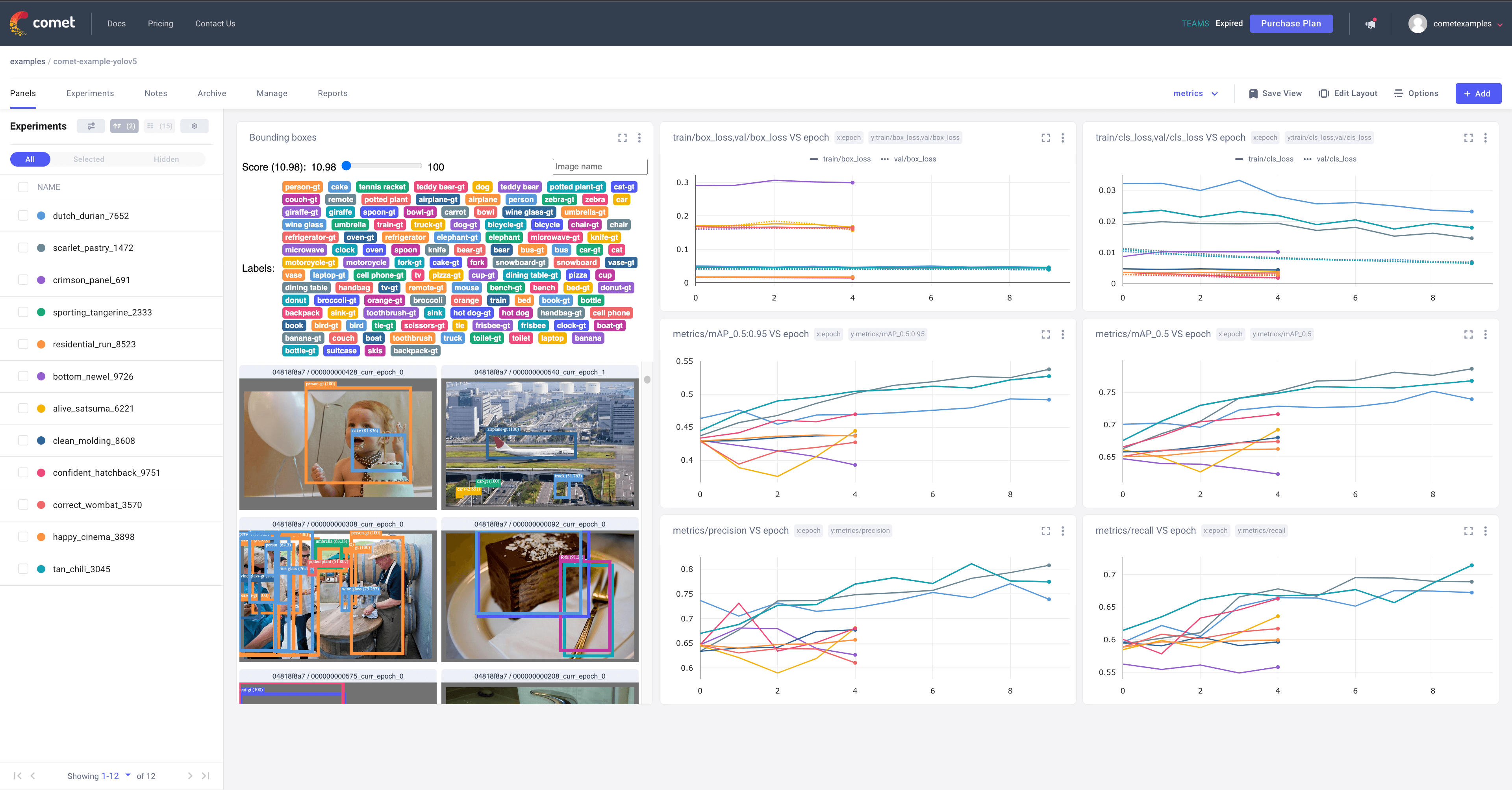
Comet Loggen en visualiseren 🌟 NIEUW
Comet is nu volledig geïntegreerd met YOLOv5. Volg en visualiseer modelmetingen in realtime, sla je hyperparameters, datasets en modelcheckpoints op en visualiseer je modelvoorspellingen met Comet Custom Panels! Comet zorgt ervoor dat je nooit het overzicht over je werk verliest en maakt het eenvoudig om resultaten te delen en samen te werken met teams van elke grootte!
Aan de slag gaan is eenvoudig:
pip install comet_ml # 1. install
export COMET_API_KEY=<Your API Key> # 2. paste API key
python train.py --img 640 --epochs 3 --data coco128.yaml --weights yolov5s.pt # 3. train
Als je meer wilt weten over alle ondersteunde Comet functies voor deze integratie, bekijk dan de Comet Les. Als je meer wilt weten over Comet, ga dan naar onze documentatie. Begin met het uitproberen van het Comet Colab Notebook: ![]()
ClearML Loggen en automatiseren 🌟 NIEUW
ClearML is volledig geïntegreerd in YOLOv5 om je experimenten bij te houden, datasetversies te beheren en zelfs op afstand trainingsruns uit te voeren. Om ClearML in te schakelen:
pip install clearml- uitvoeren
clearml-initom verbinding te maken met een ClearML server
Je krijgt alle geweldige functies die je van een experimentmanager verwacht: live updates, modelupload, experimentvergelijking etc. maar ClearML houdt bijvoorbeeld ook ongecommitteerde wijzigingen en geïnstalleerde pakketten bij. Dankzij dat zijn ClearML taken (die we experimenten noemen) ook reproduceerbaar op verschillende machines! Met slechts 1 extra regel kunnen we een YOLOv5 trainingstaak in een wachtrij plannen om te worden uitgevoerd door een willekeurig aantal ClearML Agents (werkers).
Je kunt ClearML Data gebruiken om een versie van je dataset te maken en deze vervolgens door te geven aan YOLOv5 met behulp van de unieke ID. Dit helpt je om je gegevens bij te houden zonder extra gedoe. Bekijk de ClearML Tutorial voor meer informatie!

Lokaal loggen
Trainingsresultaten worden automatisch bijgehouden met Tensorboard en CSV loggers naar runs/trainwaarbij voor elke nieuwe training een nieuwe experimenteermap wordt aangemaakt als runs/train/exp2, runs/train/exp3enz.
Deze map bevat train- en valstatistieken, mozaïeken, labels, voorspellingen en uitgebreide mozaïeken, evenals metrieken en grafieken waaronder precision-recall (PR) curven en verwarringmatrices.

Bestand met resultaten results.csv wordt na elke tijdseenheid bijgewerkt en vervolgens uitgezet als results.png (hieronder) nadat de training is voltooid. Je kunt ook alle results.csv bestand handmatig:
from utils.plots import plot_results
plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'

Volgende stappen
Als je model eenmaal getraind is, kun je je beste controlepunt gebruiken best.pt naar:
- Voer uit CLI of Python inferentie op nieuwe afbeeldingen en video's
- Valideer nauwkeurigheid op trein-, val- en testsplitsingen
- Exporteren naar TensorFlow, Keras, ONNX, TFlite, TF.js, CoreML en TensorRT formaten
- Hyperparameters evolueren om prestaties te verbeteren
- Je model verbeteren door afbeeldingen uit de echte wereld te nemen en toe te voegen aan je dataset
Ondersteunde omgevingen
Ultralytics biedt een reeks kant-en-klare omgevingen, elk vooraf geïnstalleerd met essentiële afhankelijkheden zoals CUDA, CUDNN, Python, en PyTorchom je projecten een kickstart te geven.
- Gratis GPU notitieboeken:


- Google Cloud: GCP snelstartgids
- Amazon: AWS Snelstartgids
- Azure: AzureML snelstartgids
- Docker: Docker snelstartgids

Projectstatus
![]()
Deze badge geeft aan dat alle YOLOv5 GitHub Actions Continuous Integration (CI) tests met succes zijn doorstaan. Deze CI-tests controleren rigoureus de functionaliteit en prestaties van YOLOv5 op verschillende belangrijke aspecten: training, validatie, inferentie, export en benchmarks. Ze zorgen voor een consistente en betrouwbare werking op macOS, Windows en Ubuntu, met tests die elke 24 uur en bij elke nieuwe commit worden uitgevoerd.