Transfer leren met bevroren lagen
📚 Deze handleiding legt uit hoe je YOLOv5 🚀 lagen bevriest bij transfer learning. Transfer learning is een handige manier om een model snel opnieuw te trainen op nieuwe gegevens zonder het hele netwerk opnieuw te hoeven trainen. In plaats daarvan wordt een deel van de initiële gewichten bevroren en de rest van de gewichten wordt gebruikt om verlies te berekenen en wordt bijgewerkt door de optimizer. Dit vereist minder middelen dan normale training en maakt snellere training mogelijk, hoewel het ook kan leiden tot een lagere uiteindelijke getrainde nauwkeurigheid.
Voordat je begint
Kloon repo en installeer requirements.txt in een Python>=3.8.0 omgeving, inclusief PyTorch>=1.8. Modellen en datasets worden automatisch gedownload van de nieuwste YOLOv5 release.
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
Bevries ruggengraat
Alle lagen die overeenkomen met de train.py freeze lijst in train.py worden bevroren door hun gradiënten op nul te zetten voordat de training begint.
# Freeze
freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
print(f'freezing {k}')
v.requires_grad = False
Om een lijst met modulenamen te zien:
for k, v in model.named_parameters():
print(k)
"""Output:
model.0.conv.conv.weight
model.0.conv.bn.weight
model.0.conv.bn.bias
model.1.conv.weight
model.1.bn.weight
model.1.bn.bias
model.2.cv1.conv.weight
model.2.cv1.bn.weight
...
model.23.m.0.cv2.bn.weight
model.23.m.0.cv2.bn.bias
model.24.m.0.weight
model.24.m.0.bias
model.24.m.1.weight
model.24.m.1.bias
model.24.m.2.weight
model.24.m.2.bias
"""
Als we naar de modelarchitectuur kijken, zien we dat de ruggengraat van het model uit lagen 0-9 bestaat:
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
- [-1, 1, Conv, [64, 6, 2, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C3, [128]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C3, [256]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 9, C3, [512]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C3, [1024]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv5 v6.0 head
head:
- [-1, 1, Conv, [512, 1, 1]]
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C3, [512, False]] # 13
- [-1, 1, Conv, [256, 1, 1]]
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C3, [256, False]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 3, C3, [512, False]] # 20 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C3, [1024, False]] # 23 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
zodat we de freeze-lijst zo kunnen definiëren dat deze alle modules met 'model.0.' - model.9.' in hun naam hebben:
Alle lagen bevriezen
Om het volledige model te bevriezen, behalve de laatste convolutielagen in Detect(), stellen we freeze list in op alle modules met 'model.0.' - model.23.' in hun naam:
Resultaten
We trainen YOLOv5m op VOC op beide bovenstaande scenario's, samen met een standaardmodel (geen bevriezing), uitgaande van het officiële COCO voorgetrainde --weights yolov5m.pt:
train.py --batch 48 --weights yolov5m.pt --data voc.yaml --epochs 50 --cache --img 512 --hyp hyp.finetune.yaml
Nauwkeurigheidsvergelijking
De resultaten laten zien dat bevriezen de training versnelt, maar de uiteindelijke nauwkeurigheid iets verlaagt.
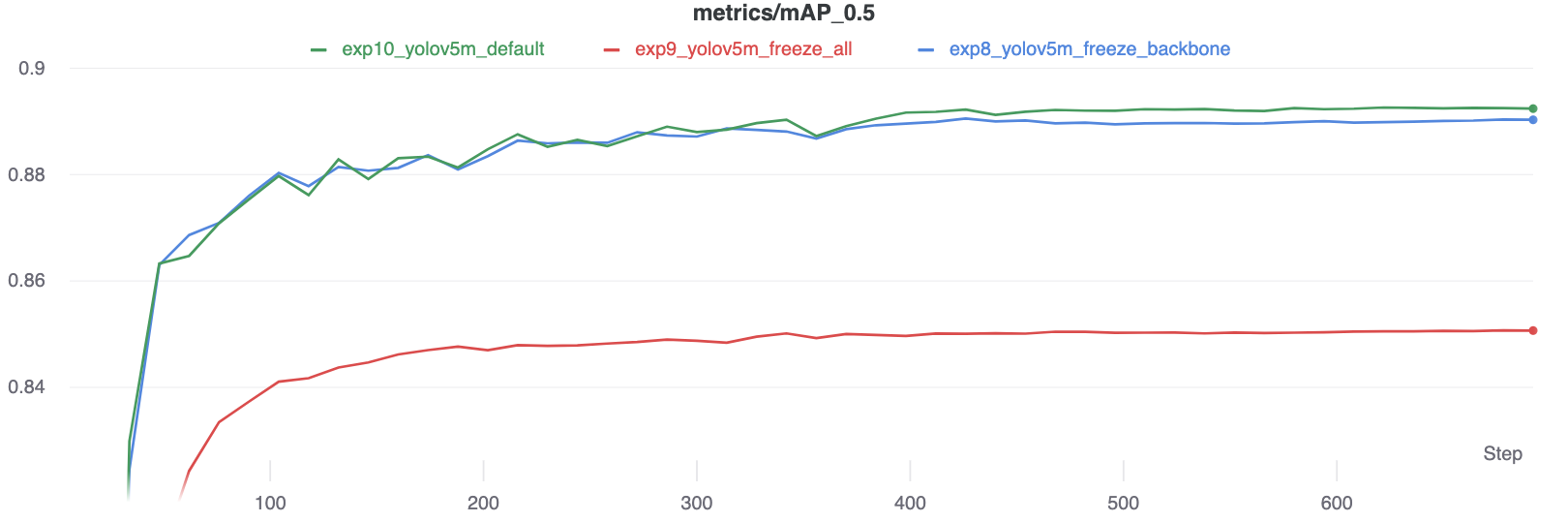
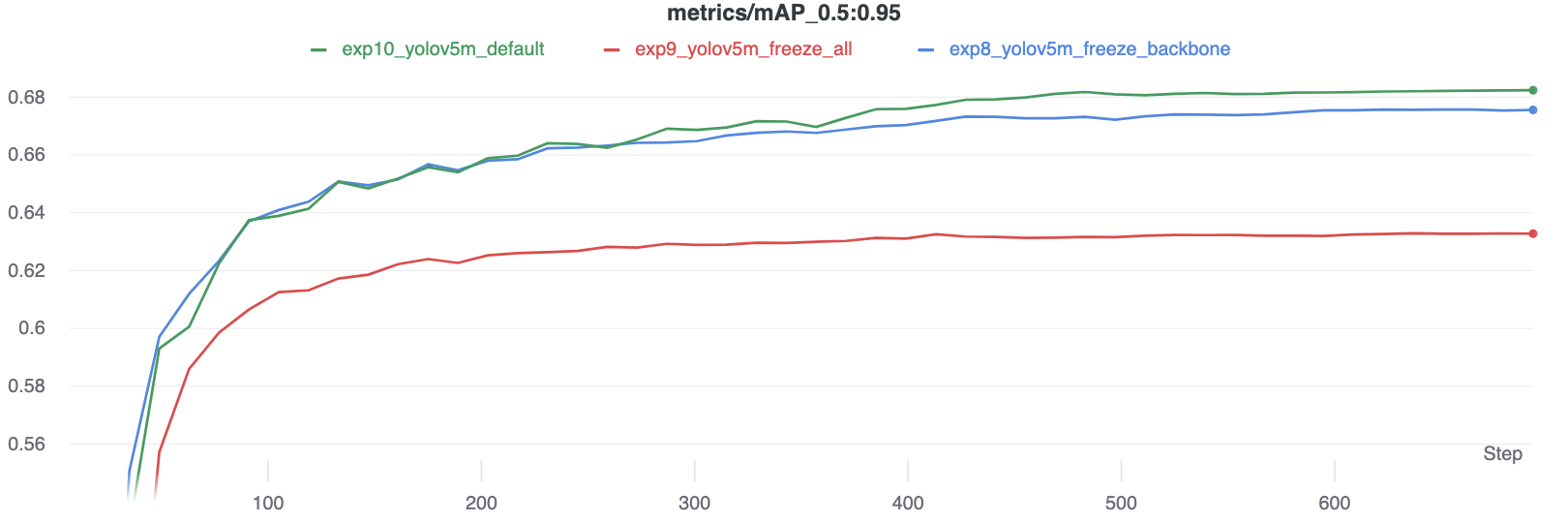
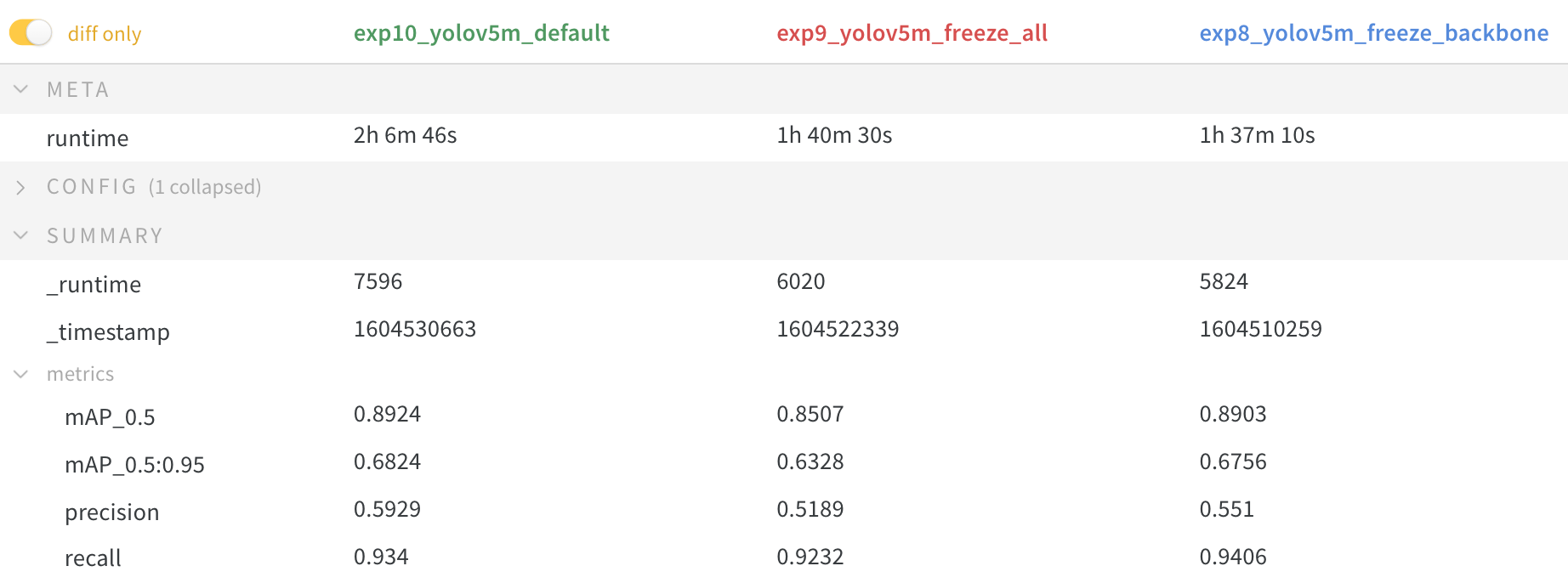
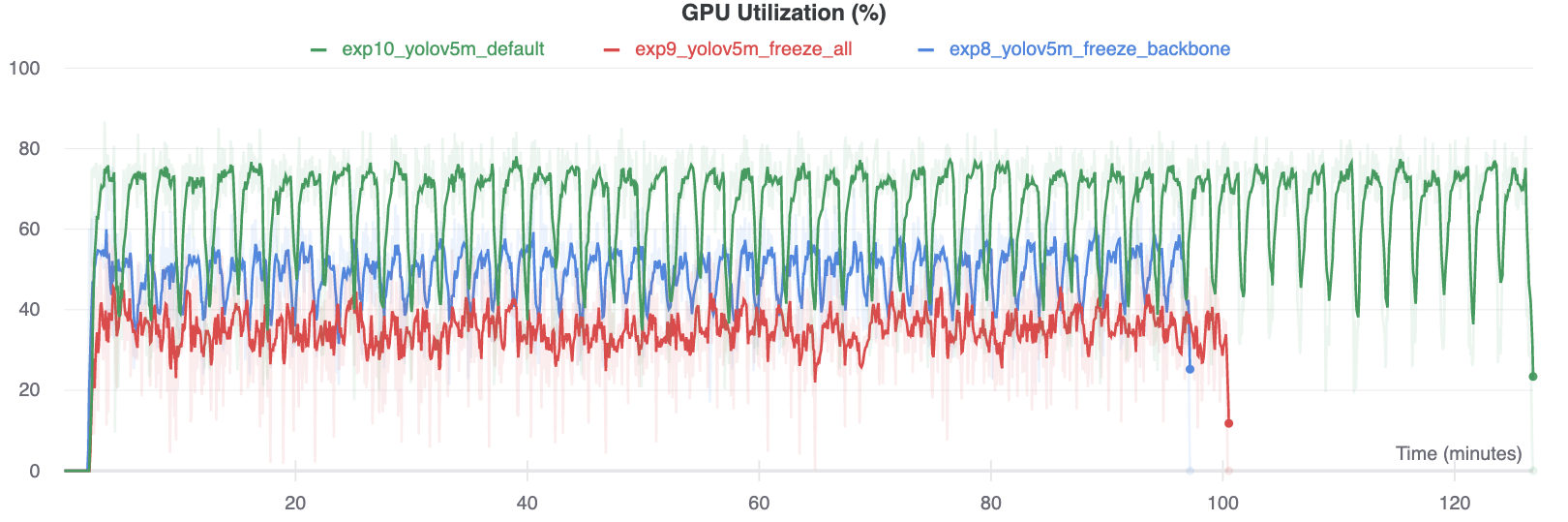
Vergelijking GPU-gebruik
Interessant is dat hoe meer modules worden bevroren, hoe minder GPU-geheugen nodig is om te trainen en hoe lager het GPU-gebruik. Dit geeft aan dat grotere modellen, of modellen die getraind zijn op een grotere beeldgrootte, baat kunnen hebben bij bevriezen om sneller te kunnen trainen.
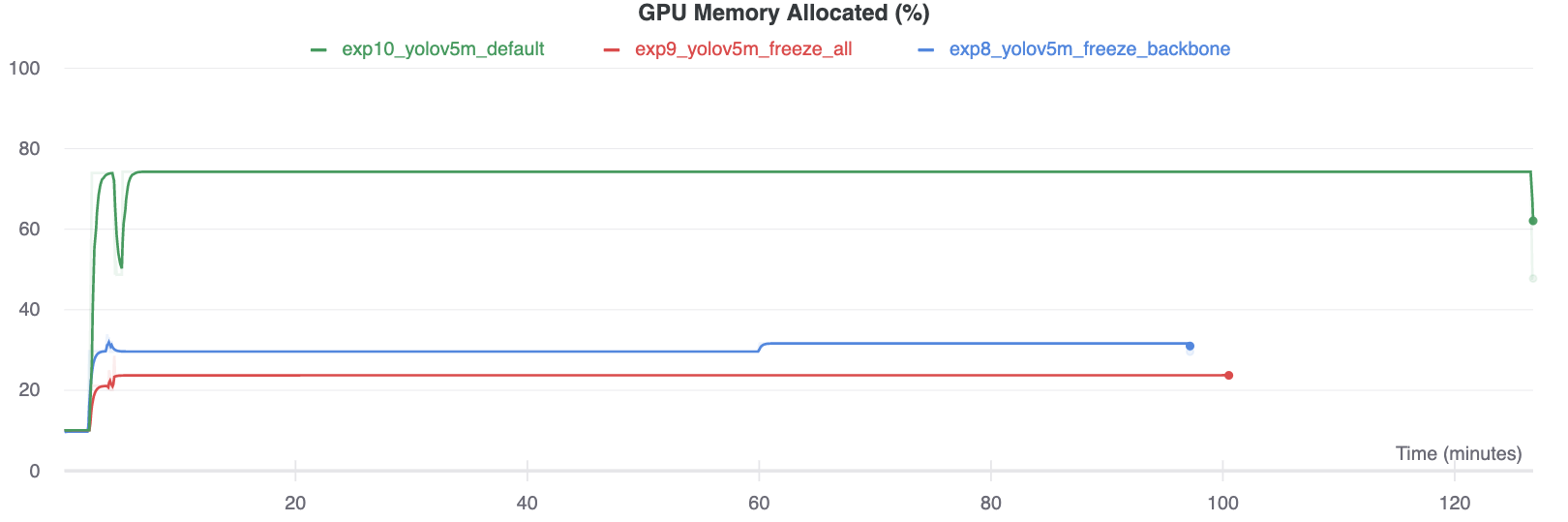
Ondersteunde omgevingen
Ultralytics biedt een reeks kant-en-klare omgevingen, elk vooraf geïnstalleerd met essentiële afhankelijkheden zoals CUDA, CUDNN, Python, en PyTorchom je projecten een kickstart te geven.
- Gratis GPU notitieboeken:



- Google Cloud: GCP snelstartgids
- Amazon: AWS Snelstartgids
- Azure: AzureML snelstartgids
- Docker: Docker snelstartgids

Projectstatus
![]()
Deze badge geeft aan dat alle YOLOv5 GitHub Actions Continuous Integration (CI) tests met succes zijn doorstaan. Deze CI-tests controleren rigoureus de functionaliteit en prestaties van YOLOv5 op verschillende belangrijke aspecten: training, validatie, inferentie, export en benchmarks. Ze zorgen voor een consistente en betrouwbare werking op macOS, Windows en Ubuntu, met tests die elke 24 uur en bij elke nieuwe commit worden uitgevoerd.