Ultralytics YOLOv5 Architectuur
YOLOv5 (v6.0/6.1) is een krachtig objectdetectiealgoritme dat is ontwikkeld door Ultralytics. Dit artikel gaat diep in op de architectuur van YOLOv5 , strategieën voor gegevensuitbreiding, trainingsmethoden en technieken voor het berekenen van verliezen. Dit uitgebreide inzicht zal helpen om je praktische toepassing van objectdetectie op verschillende gebieden te verbeteren, waaronder surveillance, autonome voertuigen en beeldherkenning.
1. Modelstructuur
YOLOv5De architectuur bestaat uit drie hoofdonderdelen:
- Ruggengraat: Dit is de hoofdstructuur van het netwerk. Voor YOLOv5 wordt de backbone ontworpen met behulp van de
New CSP-Darknet53structuur, een aanpassing van de Darknet-architectuur die in eerdere versies werd gebruikt. - Hals: Dit deel verbindt de ruggengraat en het hoofd. In YOLOv5,
SPPFenNew CSP-PANstructuren worden gebruikt. - Hoofd: Dit deel is verantwoordelijk voor het genereren van de uiteindelijke uitvoer. YOLOv5 gebruikt de
YOLOv3 Headvoor dit doel.
De structuur van het model is weergegeven in de afbeelding hieronder. De details van de modelstructuur zijn te vinden in yolov5l.yaml.
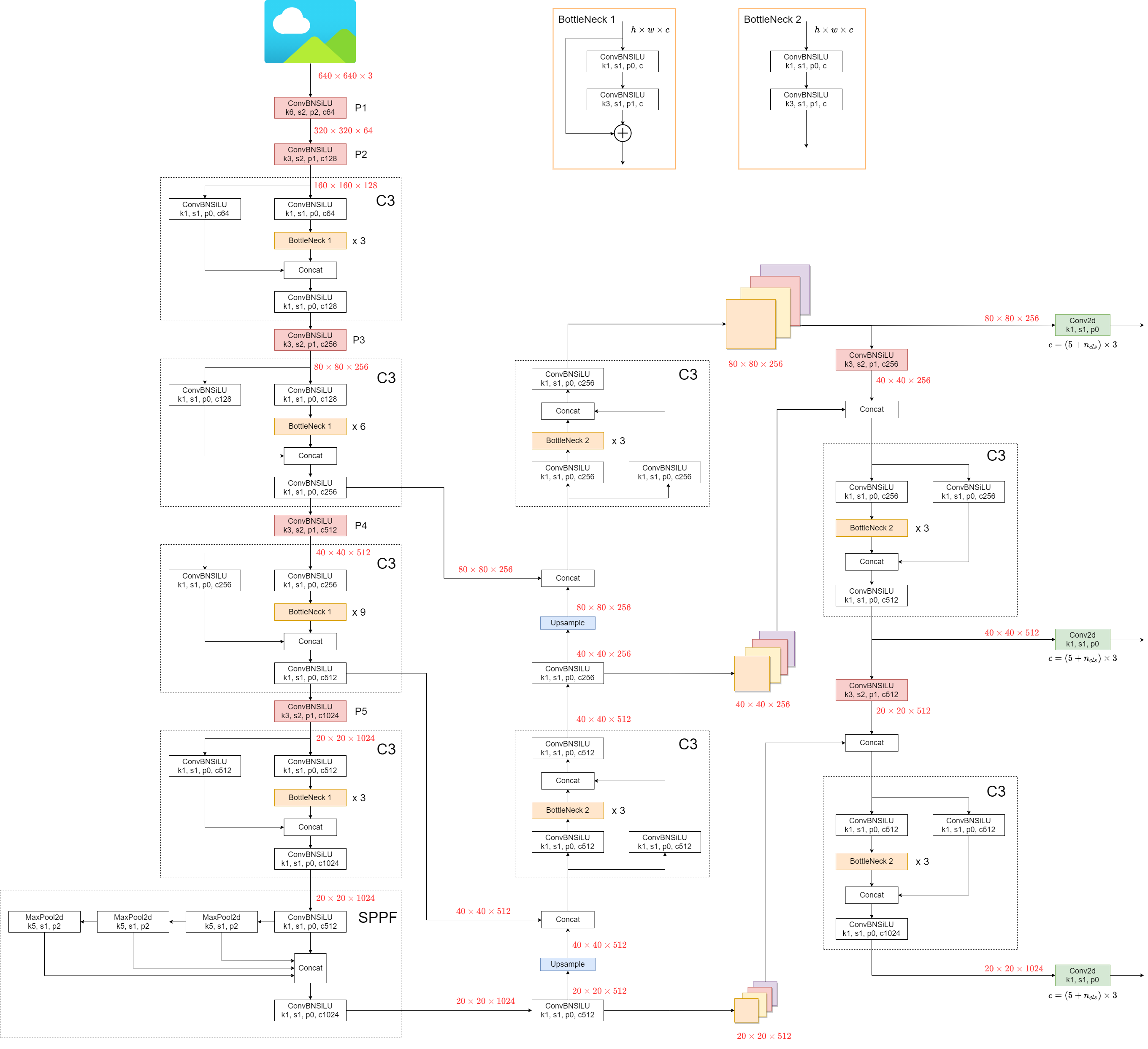
YOLOv5 introduceert enkele kleine veranderingen ten opzichte van zijn voorgangers:
- De
Focusstructuur, gevonden in eerdere versies, is vervangen door een6x6 Conv2dstructuur. Deze verandering verhoogt de efficiëntie #4825. - De
SPPstructuur wordt vervangen doorSPPF. Deze wijziging verdubbelt de verwerkingssnelheid meer dan.
Om de snelheid van SPP en SPPFkan de volgende code worden gebruikt:
Voorbeeld SPP vs SPPF snelheidsprofilering (klik om te openen)
import time
import torch
import torch.nn as nn
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3], dim=1)
class SPPF(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
def forward(self, x):
o1 = self.maxpool(x)
o2 = self.maxpool(o1)
o3 = self.maxpool(o2)
return torch.cat([x, o1, o2, o3], dim=1)
def main():
input_tensor = torch.rand(8, 32, 16, 16)
spp = SPP()
sppf = SPPF()
output1 = spp(input_tensor)
output2 = sppf(input_tensor)
print(torch.equal(output1, output2))
t_start = time.time()
for _ in range(100):
spp(input_tensor)
print(f"SPP time: {time.time() - t_start}")
t_start = time.time()
for _ in range(100):
sppf(input_tensor)
print(f"SPPF time: {time.time() - t_start}")
if __name__ == '__main__':
main()
2. Technieken voor gegevensuitbreiding
YOLOv5 maakt gebruik van verschillende gegevensuitbreidingstechnieken om het generalisatievermogen van het model te verbeteren en overpassen te verminderen. Deze technieken omvatten:
- Mozaïekvergroting: Een beeldverwerkingstechniek die vier trainingsbeelden combineert tot één beeld op een manier die objectdetectiemodellen aanmoedigt om beter om te gaan met verschillende objectschalen en vertalingen.

- Copy-Paste Augmentation: Een innovatieve gegevensuitbreidingsmethode waarbij willekeurige patches uit een afbeelding worden gekopieerd en op een andere willekeurig gekozen afbeelding worden geplakt, waardoor effectief een nieuw trainingsvoorbeeld wordt gegenereerd.

- Willekeurige Affiene Transformaties: Dit omvat willekeurige rotatie, schaling, translatie en afschuiving van de afbeeldingen.

- MixUp Augmentation: Een methode die samengestelde afbeeldingen maakt door een lineaire combinatie te nemen van twee afbeeldingen en hun bijbehorende labels.
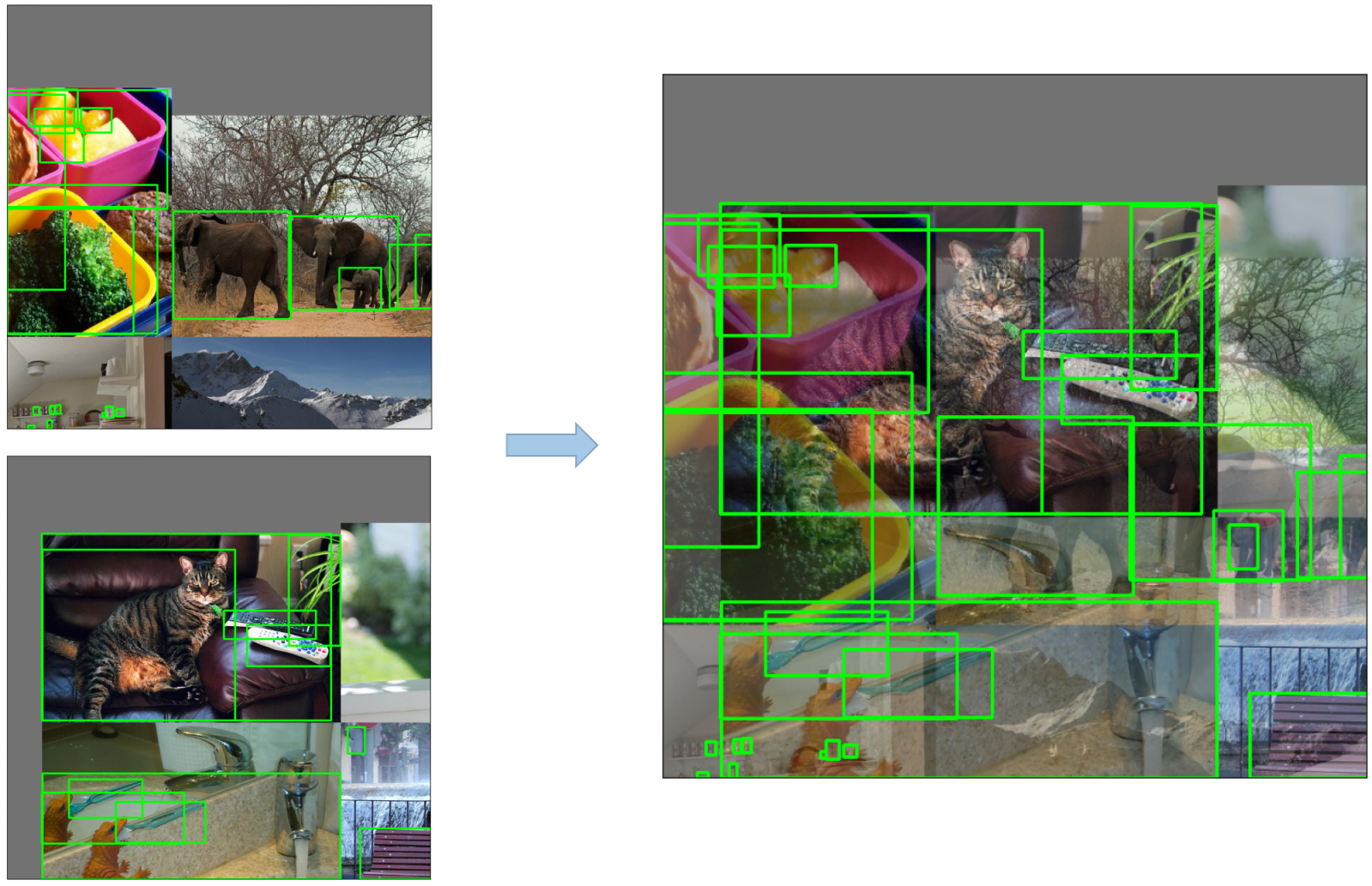
-
Albumentaties: Een krachtige bibliotheek voor het augmenteren van afbeeldingen die een grote verscheidenheid aan augmentatietechnieken ondersteunt.
-
HSV Vergroting: Willekeurige veranderingen in de Tint, Verzadiging en Waarde van de afbeeldingen.

- Willekeurige horizontale flip: Een augmentatiemethode waarbij afbeeldingen willekeurig horizontaal worden omgedraaid.
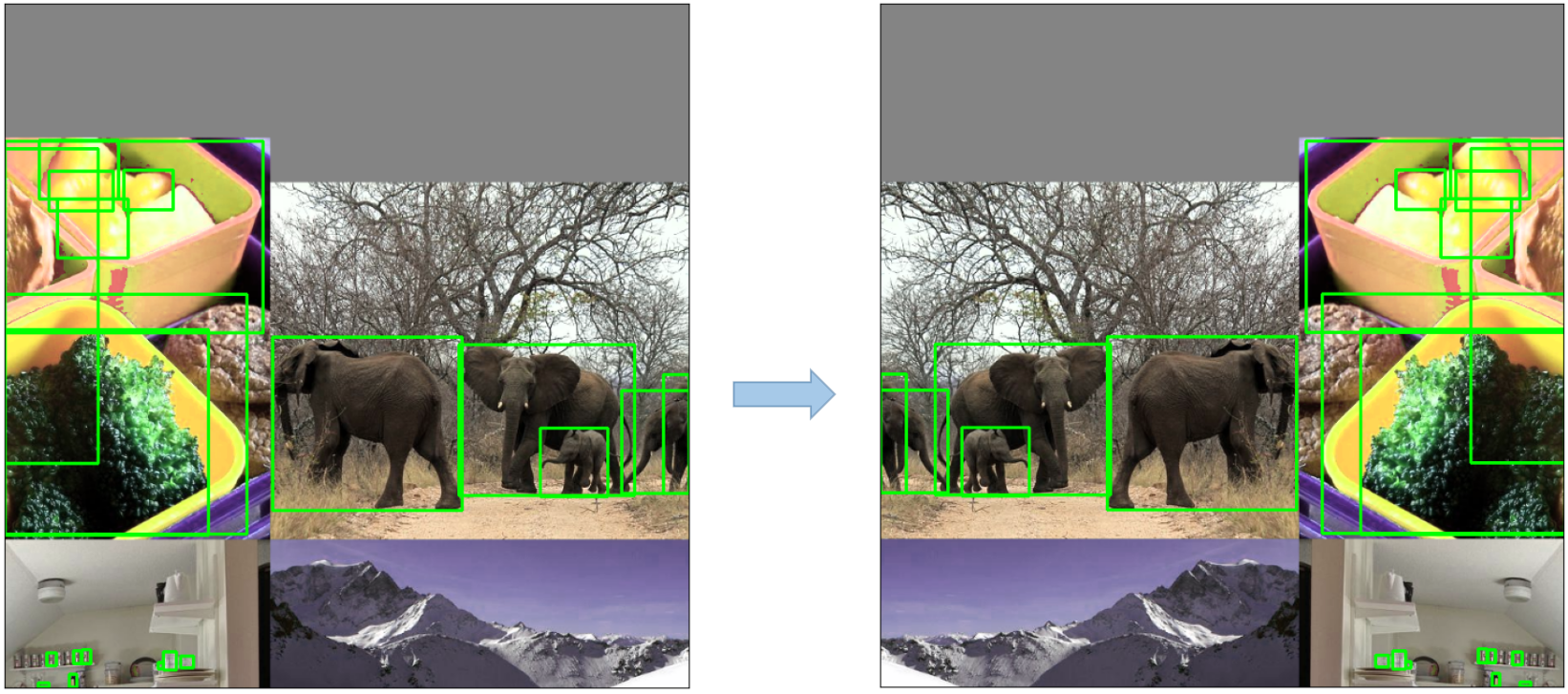
3. Trainingsstrategieën
YOLOv5 past verschillende geavanceerde trainingsstrategieën toe om de prestaties van het model te verbeteren. Deze omvatten:
- Training met meerdere schalen: De invoerafbeeldingen worden willekeurig herschaald binnen een bereik van 0,5 tot 1,5 keer hun oorspronkelijke grootte tijdens het trainingsproces.
- AutoAnchor: Deze strategie optimaliseert de voorafgaande ankervakken om overeen te komen met de statistische kenmerken van de grondwaarheidsvakken in je aangepaste gegevens.
- Opwarming en Cosine LR Scheduler: Een methode om de leersnelheid aan te passen om de prestaties van het model te verbeteren.
- Exponentieel Bewegend Gemiddelde (EMA): Een strategie die het gemiddelde van parameters over eerdere stappen gebruikt om het trainingsproces te stabiliseren en generalisatiefouten te verminderen.
- Gemengde precisie training: Een methode om bewerkingen uit te voeren in half-precisie formaat, waardoor minder geheugen wordt gebruikt en de rekensnelheid toeneemt.
- Hyperparameter evolutie: Een strategie om hyperparameters automatisch af te stemmen voor optimale prestaties.
4. Extra functies
4.1 Verliezen berekenen
Het verlies in YOLOv5 wordt berekend als een combinatie van drie afzonderlijke verliescomponenten:
- Klassen verlies (BCE verlies): Binary Cross-Entropy loss meet de fout voor de classificatietaak.
- Objectness Loss (BCE-verlies): Een ander Binary Cross-Entropy verlies berekent de fout in het detecteren of een object aanwezig is in een bepaalde rastercel of niet.
- Locatieverlies (CIoU-verlies): Volledig IoU-verlies meet de fout in het lokaliseren van het object binnen de rastercel.
De totale verliesfunctie wordt weergegeven door:
4.2 Balansverliezen
De objectiviteitsverliezen van de drie voorspellende lagen (P3, P4, P5) worden verschillend gewogen. De balansgewichten zijn [4.0, 1.0, 0.4] respectievelijk. Deze aanpak zorgt ervoor dat de voorspellingen op verschillende schalen op de juiste manier bijdragen aan het totale verlies.
4.3 Netgevoeligheid elimineren
De YOLOv5 architectuur brengt enkele belangrijke veranderingen aan in de voorspellingsstrategie van de boxen vergeleken met eerdere versies van YOLO. In YOLOv2 en YOLOv3 werden de boxcoördinaten direct voorspeld met behulp van de activering van de laatste laag.

In YOLOv5 is de formule voor het voorspellen van de dooscoördinaten echter bijgewerkt om de rastergevoeligheid te verminderen en te voorkomen dat het model onbegrensde doosafmetingen voorspelt.
De herziene formules voor het berekenen van de voorspelde bounding box zijn als volgt:
Vergelijk de verschuiving van het middelpunt voor en na het schalen. Het bereik van de middelpuntverschuiving wordt aangepast van (0, 1) tot (-0,5, 1,5). Daarom kan de offset gemakkelijk 0 of 1 worden.

Vergelijk de hoogte- en breedteschaalverhouding (ten opzichte van het anker) voor en na de aanpassing. De originele yolo/darknet box vergelijkingen hebben een ernstige fout. Breedte en hoogte zijn volledig onbegrensd omdat ze eenvoudigweg out=exp(in) zijn, wat gevaarlijk is, omdat het kan leiden tot op hol geslagen gradiënten, instabiliteiten, NaN-verliezen en uiteindelijk een volledig verlies van de training. verwijs naar dit probleem

4.4 Bouwdoelen
Het doelproces in YOLOv5 is cruciaal voor de trainingsefficiëntie en de nauwkeurigheid van het model. Het bestaat uit het toewijzen van grondwaarheidsvakken aan de juiste rastercellen in de uitvoerkaart en het matchen van deze vakken met de juiste ankervakken.
Dit proces verloopt als volgt:
- Bereken de verhouding tussen de afmetingen van de grondwaarheidsbox en de afmetingen van elke ankermal.

- Als de berekende verhouding binnen de drempelwaarde ligt, match dan het grondwaarheidsvak met het corresponderende anker.

- Wijs het gematchte anker toe aan de juiste cellen, waarbij je in gedachten moet houden dat door de herziene middelpuntverschuiving een grondwaarheidsvak aan meer dan één anker kan worden toegewezen. Omdat het bereik van de middelpuntverschuiving is aangepast van (0, 1) naar (-0,5, 1,5). GT Box kan aan meer ankers worden toegewezen.

Op deze manier zorgt het build targets proces ervoor dat elk ground truth object goed wordt toegewezen en gematcht tijdens het trainingsproces, waardoor YOLOv5 de taak van objectdetectie effectiever kan leren.
Conclusie
Concluderend kan worden gesteld dat YOLOv5 een belangrijke stap voorwaarts is in de ontwikkeling van realtime objectdetectiemodellen. Door verschillende nieuwe functies, verbeteringen en trainingsstrategieën in te bouwen, overtreft het eerdere versies van de YOLO familie in prestaties en efficiëntie.
De belangrijkste verbeteringen in YOLOv5 omvatten het gebruik van een dynamische architectuur, een uitgebreide reeks technieken voor gegevensuitbreiding, innovatieve trainingsstrategieën en belangrijke aanpassingen in de rekenverliezen en het proces om doelen te bouwen. Al deze innovaties zorgen voor een aanzienlijke verbetering van de nauwkeurigheid en efficiëntie van objectdetectie met behoud van een hoge mate van snelheid, wat het handelsmerk is van YOLO modellen.