Hyperparameter evolutie
📚 Deze handleiding geeft uitleg over hyperparameter evolutie voor YOLOv5 🚀. Hyperparameter evolutie is een methode voor hyperparameter optimalisatie met behulp van een genetisch algoritme (GA) voor optimalisatie.
Hyperparameters in ML bepalen verschillende aspecten van de training en het vinden van optimale waarden hiervoor kan een uitdaging zijn. Traditionele methoden zoals rasteronderzoeken kunnen snel onuitvoerbaar worden door 1) de hoge dimensionale zoekruimte 2) onbekende correlaties tussen de dimensies, en 3) de dure aard van het evalueren van de fitness op elk punt, waardoor GA een geschikte kandidaat is voor hyperparameteronderzoeken.
Voordat je begint
Kloon repo en installeer requirements.txt in een Python>=3.8.0 omgeving, inclusief PyTorch>=1.8. Modellen en datasets worden automatisch gedownload van de nieuwste YOLOv5 release.
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
1. Hyperparameters initialiseren
YOLOv5 heeft ongeveer 30 hyperparameters die worden gebruikt voor verschillende trainingsinstellingen. Deze zijn gedefinieerd in *.yaml bestanden in de /data/hyps map. Betere initiële gissingen zullen betere eindresultaten opleveren, dus het is belangrijk om deze waarden goed te initialiseren voordat je gaat evolueren. Als je twijfelt, gebruik dan gewoon de standaardwaarden, die geoptimaliseerd zijn voor YOLOv5 COCO training vanaf nul.
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Hyperparameters for low-augmentation COCO training from scratch
# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear
# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)
2. Fitness definiëren
Fitness is de waarde die we proberen te maximaliseren. In YOLOv5 definiëren we een standaard fitnessfunctie als een gewogen combinatie van metrieken: mAP@0.5 draagt 10% bij aan het gewicht en mAP@0.5:0.95 draagt bij aan de overige 90%, met Precisie P en Terugroepen R afwezig. Je kunt deze naar eigen inzicht aanpassen of de standaard fitnessdefinitie in utils/metrics.py gebruiken (aanbevolen).
def fitness(x):
# Model fitness as a weighted combination of metrics
w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
return (x[:, :4] * w).sum(1)
3. Evolueer
Evolutie wordt uitgevoerd over een basisscenario dat we proberen te verbeteren. Het basisscenario in dit voorbeeld is het finetunen van COCO128 gedurende 10 epochs met behulp van voorgetrainde YOLOv5s. De trainingsopdracht van het basisscenario is:
Hyperparameters ontwikkelen specifiek voor dit scenario, uitgaande van onze beginwaarden gedefinieerd in Sectie 1.en het maximaliseren van de fitness gedefinieerd in Sectie 2.toevoegen --evolve:
# Single-GPU
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve
# Multi-GPU
for i in 0 1 2 3 4 5 6 7; do
sleep $(expr 30 \* $i) && # 30-second delay (optional)
echo 'Starting GPU '$i'...' &&
nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --device $i --evolve > evolve_gpu_$i.log &
done
# Multi-GPU bash-while (not recommended)
for i in 0 1 2 3 4 5 6 7; do
sleep $(expr 30 \* $i) && # 30-second delay (optional)
echo 'Starting GPU '$i'...' &&
"$(while true; do nohup python train.py... --device $i --evolve 1 > evolve_gpu_$i.log; done)" &
done
Met de standaard evolutie-instellingen wordt het basisscenario 300 keer uitgevoerd, d.w.z. gedurende 300 generaties. Je kunt generaties aanpassen via de --evolve argument, d.w.z. python train.py --evolve 1000.
De belangrijkste genetische operatoren zijn crossover en mutatie. In dit werk wordt mutatie gebruikt met een waarschijnlijkheid van 80% en een variantie van 0,04 om nieuwe nakomelingen te creëren op basis van een combinatie van de beste ouders uit alle voorgaande generaties. De resultaten worden gelogd naar runs/evolve/exp/evolve.csven de nakomelingen met de hoogste fitness worden elke generatie opgeslagen als runs/evolve/hyp_evolved.yaml:
# YOLOv5 Hyperparameter Evolution Results
# Best generation: 287
# Last generation: 300
# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss
# 0.54634, 0.55625, 0.58201, 0.33665, 0.056451, 0.042892, 0.013441
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)
We raden een minimum van 300 generaties evolutie aan voor de beste resultaten. Merk op dat evolutie over het algemeen duur en tijdrovend is, omdat het basisscenario honderden keren wordt getraind, waarvoor mogelijk honderden of duizenden GPU-uren nodig zijn.
4. Visualiseer
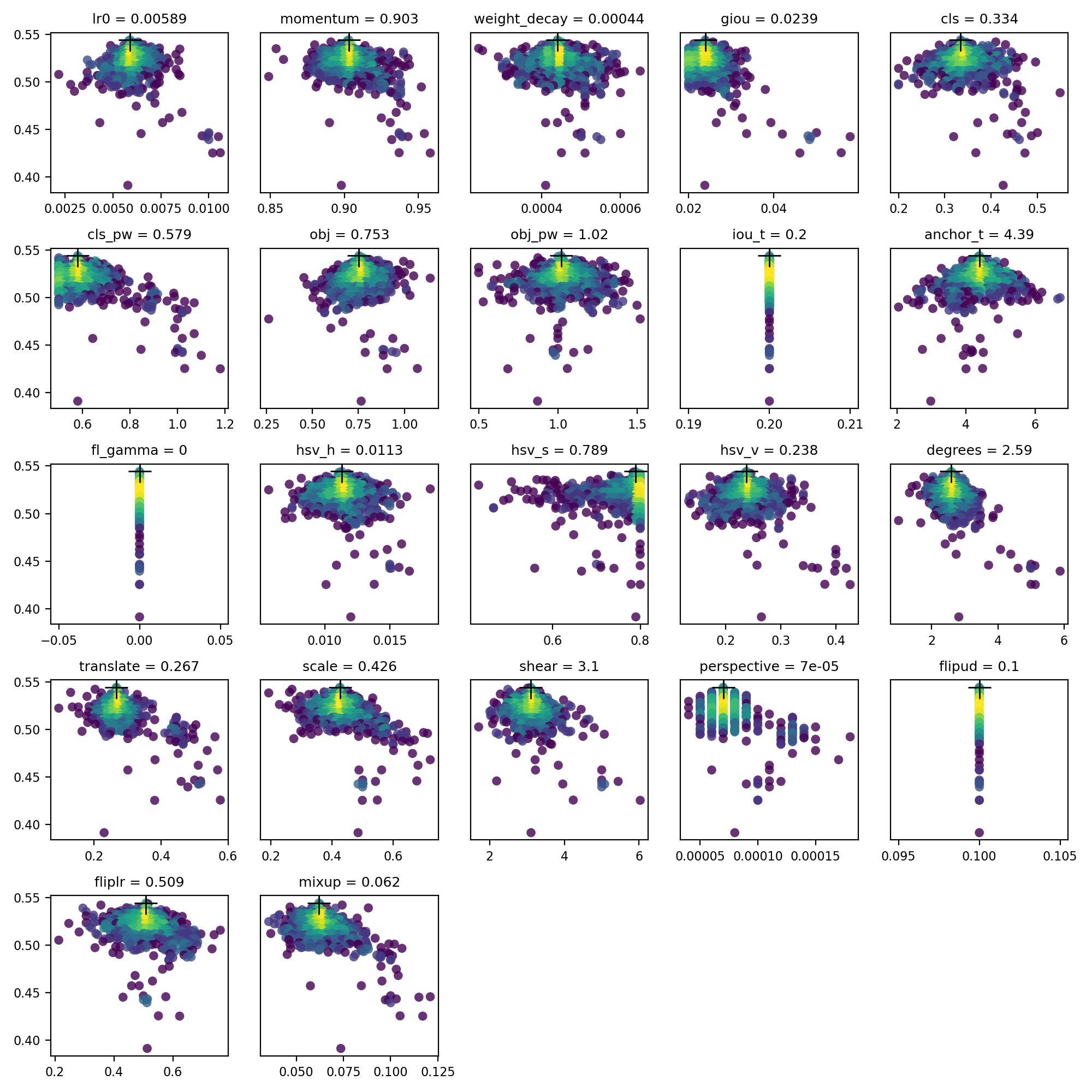
evolve.csv wordt uitgezet als evolve.png door utils.plots.plot_evolve() na beëindiging van de evolutie met een subplot per hyperparameter die fitness (y-as) versus hyperparameterwaarden (x-as) laat zien. Geel geeft hogere concentraties aan. Verticale verdelingen geven aan dat een parameter is uitgeschakeld en niet muteert. Dit is door de gebruiker te selecteren in de meta woordenboek in train.py, en is handig om parameters vast te leggen en te voorkomen dat ze evolueren.
Ondersteunde omgevingen
Ultralytics biedt een reeks kant-en-klare omgevingen, elk vooraf geïnstalleerd met essentiële afhankelijkheden zoals CUDA, CUDNN, Python, en PyTorchom je projecten een kickstart te geven.
- Gratis GPU notitieboeken:



- Google Cloud: GCP snelstartgids
- Amazon: AWS Snelstartgids
- Azure: AzureML snelstartgids
- Docker: Docker snelstartgids

Projectstatus
![]()
Deze badge geeft aan dat alle YOLOv5 GitHub Actions Continuous Integration (CI) tests met succes zijn doorstaan. Deze CI-tests controleren rigoureus de functionaliteit en prestaties van YOLOv5 op verschillende belangrijke aspecten: training, validatie, inferentie, export en benchmarks. Ze zorgen voor een consistente en betrouwbare werking op macOS, Windows en Ubuntu, met tests die elke 24 uur en bij elke nieuwe commit worden uitgevoerd.