Best Practices für Model Deployment
Einführung
Die Modellbereitstellung ist der Schritt in einem Computer-Vision-Projekt, der ein Modell aus der Entwicklungsphase in eine reale Anwendung überführt. Es gibt verschiedene Optionen für die Modellbereitstellung: Die Cloud-Bereitstellung bietet Skalierbarkeit und einfachen Zugriff, die Edge-Bereitstellung reduziert die Latenz, indem sie das Modell näher an die Datenquelle bringt, und die lokale Bereitstellung gewährleistet Datenschutz und Kontrolle. Die Wahl der richtigen Strategie hängt von den Anforderungen Ihrer Anwendung ab und berücksichtigt Geschwindigkeit, Sicherheit und Skalierbarkeit.
Ansehen: So optimieren und implementieren Sie KI-Modelle: Best Practices, Fehlerbehebung und Sicherheitsüberlegungen
Es ist auch wichtig, Best Practices bei der Bereitstellung eines Modells zu befolgen, da die Bereitstellung die Effektivität und Zuverlässigkeit der Leistung des Modells erheblich beeinflussen kann. In diesem Leitfaden konzentrieren wir uns darauf, wie Sie sicherstellen können, dass Ihre Modellbereitstellung reibungslos, effizient und sicher ist.
Optionen zur Modellbereitstellung
Oftmals muss ein Modell, sobald es trainiert, evaluiert und getestet wurde, in spezifische Formate konvertiert werden, um es effektiv in verschiedenen Umgebungen wie Cloud, Edge oder lokalen Geräten bereitzustellen.
Mit YOLO26 können Sie Ihr Modell in verschiedene Formate exportieren, je nach Ihren Bereitstellungsanforderungen. Zum Beispiel ist der Export von YOLO26 nach ONNX unkompliziert und ideal für die Übertragung von Modellen zwischen Frameworks. Um weitere Integrationsoptionen zu erkunden und eine reibungslose Bereitstellung in verschiedenen Umgebungen zu gewährleisten, besuchen Sie unser Integrations-Hub für Modelle.
Auswahl einer Deployment-Umgebung
Die Wahl des Bereitstellungsortes für Ihr Computer-Vision-Modell hängt von mehreren Faktoren ab. Verschiedene Umgebungen haben einzigartige Vorteile und Herausforderungen, daher ist es wichtig, diejenige auszuwählen, die Ihren Bedürfnissen am besten entspricht.
Cloud-Bereitstellung
Die Cloud-Bereitstellung eignet sich hervorragend für Anwendungen, die schnell skaliert werden müssen und große Datenmengen verarbeiten müssen. Plattformen wie AWS, Google Cloud und Azure erleichtern die Verwaltung Ihrer Modelle von der Schulung bis zur Bereitstellung. Sie bieten Dienste wie AWS SageMaker, Google AI Platform und Azure Machine Learning, um Sie während des gesamten Prozesses zu unterstützen.
Die Nutzung der Cloud kann jedoch teuer sein, insbesondere bei hoher Datennutzung, und es können Latenzprobleme auftreten, wenn sich Ihre Benutzer weit entfernt von den Rechenzentren befinden. Um Kosten und Leistung zu verwalten, ist es wichtig, die Ressourcennutzung zu optimieren und die Einhaltung der Datenschutzbestimmungen sicherzustellen.
Edge-Bereitstellung
Die Edge-Bereitstellung eignet sich gut für Anwendungen, die Echtzeitreaktionen und geringe Latenzzeiten erfordern, insbesondere an Orten mit eingeschränktem oder keinem Internetzugang. Die Bereitstellung von Modellen auf Edge-Geräten wie Smartphones oder IoT-Geräten gewährleistet eine schnelle Verarbeitung und hält Daten lokal, was den Datenschutz verbessert. Die Bereitstellung am Edge spart auch Bandbreite, da weniger Daten in die Cloud gesendet werden.
Edge-Geräte haben jedoch oft eine begrenzte Rechenleistung, daher müssen Sie Ihre Modelle optimieren. Tools wie TensorFlow Lite und NVIDIA Jetson können dabei helfen. Trotz der Vorteile kann die Wartung und Aktualisierung vieler Geräte eine Herausforderung darstellen.
Lokale Bereitstellung
Die lokale Bereitstellung ist am besten geeignet, wenn die Datenvertraulichkeit von entscheidender Bedeutung ist oder wenn kein oder kein unzuverlässiger Internetzugang besteht. Das Ausführen von Modellen auf lokalen Servern oder Desktops gibt Ihnen die volle Kontrolle und schützt Ihre Daten. Es kann auch die Latenz verringern, wenn sich der Server in der Nähe des Benutzers befindet.
Die lokale Skalierung kann jedoch schwierig sein, und die Wartung kann zeitaufwändig sein. Die Verwendung von Tools wie Docker für die Containerisierung und Kubernetes für die Verwaltung kann dazu beitragen, lokale Bereitstellungen effizienter zu gestalten. Regelmäßige Aktualisierungen und Wartung sind notwendig, um einen reibungslosen Betrieb zu gewährleisten.
Containerisierung für eine optimierte Bereitstellung
Containerisierung ist ein leistungsstarker Ansatz, der Ihr Modell und alle seine Abhängigkeiten in einer standardisierten Einheit, einem sogenannten Container, verpackt. Diese Technik gewährleistet eine konsistente Leistung in verschiedenen Umgebungen und vereinfacht den Bereitstellungsprozess.
Vorteile der Verwendung von Docker für die Modellbereitstellung
Docker hat sich aus verschiedenen Gründen zum Industriestandard für die Containerisierung in Machine-Learning-Bereitstellungen entwickelt:
- Umgebungskonsistenz: Docker-Container kapseln Ihr Modell und alle seine Abhängigkeiten und beseitigen das Problem "es funktioniert auf meinem Rechner", indem sie ein konsistentes Verhalten über Entwicklungs-, Test- und Produktionsumgebungen hinweg gewährleisten.
- Isolation: Container isolieren Anwendungen voneinander und verhindern so Konflikte zwischen verschiedenen Softwareversionen oder Bibliotheken.
- Portabilität: Docker-Container können auf jedem System ausgeführt werden, das Docker unterstützt, wodurch es einfach ist, Ihre Modelle ohne Änderungen auf verschiedenen Plattformen bereitzustellen.
- Skalierbarkeit: Container können je nach Bedarf einfach hoch- oder herunterskaliert werden, und Orchestrierungs-Tools wie Kubernetes können diesen Prozess automatisieren.
- Versionskontrolle: Docker-Images können versioniert werden, was es ermöglicht, Änderungen zu verfolgen und bei Bedarf auf frühere Versionen zurückzugreifen.
Implementierung von Docker für die YOLO26-Bereitstellung
Um Ihr YOLO26-Modell zu containerisieren, können Sie ein Dockerfile erstellen, das alle notwendigen Abhängigkeiten und Konfigurationen festlegt. Hier ist ein grundlegendes Beispiel:
FROM ultralytics/ultralytics:latest
WORKDIR /app
# Copy your model and any additional files
COPY ./models/yolo26.pt /app/models/
COPY ./scripts /app/scripts/
# Set up any environment variables
ENV MODEL_PATH=/app/models/yolo26.pt
# Command to run when the container starts
CMD ["python", "/app/scripts/predict.py"]
Dieser Ansatz stellt sicher, dass Ihr Modelldepot reproduzierbar und konsistent in verschiedenen Umgebungen ist, wodurch das Problem "funktioniert auf meinem Rechner", das oft Bereitstellungsprozesse plagt, erheblich reduziert wird.
Techniken zur Modelloptimierung
Die Optimierung Ihres Computer Vision Modells trägt dazu bei, dass es effizient läuft, insbesondere bei der Bereitstellung in Umgebungen mit begrenzten Ressourcen wie Edge-Geräten. Hier sind einige Schlüsseltechniken zur Optimierung Ihres Modells.
Modellbeschneidung
Pruning reduziert die Größe des Modells, indem Gewichte entfernt werden, die wenig zum Endergebnis beitragen. Es macht das Modell kleiner und schneller, ohne die Genauigkeit wesentlich zu beeinträchtigen. Pruning beinhaltet das Identifizieren und Eliminieren unnötiger Parameter, was zu einem schlankeren Modell führt, das weniger Rechenleistung benötigt. Es ist besonders nützlich für den Einsatz von Modellen auf Geräten mit begrenzten Ressourcen.
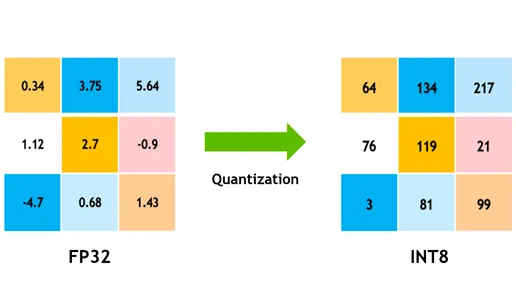
Modellquantisierung
Die Quantisierung wandelt die Gewichte und Aktivierungen des Modells von hoher Präzision (wie 32-Bit-Floats) in niedrigere Präzision (wie 8-Bit-Integer) um. Durch die Reduzierung der Modellgröße wird die Inferenz beschleunigt. Quantisierungsbewusstes Training (QAT) ist eine Methode, bei der das Modell unter Berücksichtigung der Quantisierung trainiert wird, wodurch die Genauigkeit besser erhalten bleibt als bei der Post-Training-Quantisierung. Durch die Handhabung der Quantisierung während der Trainingsphase lernt das Modell, sich an eine niedrigere Präzision anzupassen, wodurch die Leistung erhalten bleibt und gleichzeitig der Rechenaufwand reduziert wird.
Knowledge Distillation
Knowledge Distillation beinhaltet das Trainieren eines kleineren, einfacheren Modells (des Studenten), um die Ausgaben eines größeren, komplexeren Modells (des Lehrers) nachzubilden. Das Studentenmodell lernt, die Vorhersagen des Lehrers zu approximieren, was zu einem kompakten Modell führt, das einen Großteil der Genauigkeit des Lehrers beibehält. Diese Technik ist vorteilhaft für die Erstellung effizienter Modelle, die für den Einsatz auf Edge-Geräten mit begrenzten Ressourcen geeignet sind.
Fehlerbehebung bei Bereitstellungsproblemen
Bei der Bereitstellung Ihrer Computer-Vision-Modelle können Herausforderungen auftreten. Das Verständnis gängiger Probleme und Lösungen kann den Prozess jedoch reibungsloser gestalten. Hier sind einige allgemeine Tipps zur Fehlerbehebung und Best Practices, die Ihnen bei der Bewältigung von Bereitstellungsproblemen helfen.
Ihr Modell ist nach der Bereitstellung weniger genau
Ein Rückgang der Genauigkeit Ihres Modells nach der Bereitstellung kann frustrierend sein. Dieses Problem kann verschiedene Ursachen haben. Hier sind einige Schritte, die Ihnen helfen, das Problem zu identifizieren und zu beheben:
- Datenkonsistenz prüfen: Stellen Sie sicher, dass die Daten, die Ihr Modell nach der Bereitstellung verarbeitet, mit den Daten übereinstimmen, mit denen es trainiert wurde. Unterschiede in der Datenverteilung, -qualität oder -formatierung können die Leistung erheblich beeinträchtigen.
- Validierung der Vorverarbeitungsschritte: Stellen Sie sicher, dass alle während des Trainings angewendeten Vorverarbeitungsschritte auch während der Bereitstellung konsistent angewendet werden. Dazu gehören das Anpassen der Bildgröße, das Normalisieren von Pixelwerten und andere Datentransformationen.
- Bewerten Sie die Umgebung des Modells: Stellen Sie sicher, dass die während der Bereitstellung verwendeten Hardware- und Softwarekonfigurationen mit denen übereinstimmen, die während des Trainings verwendet wurden. Unterschiede in Bibliotheken, Versionen und Hardwarefunktionen können zu Abweichungen führen.
- Modellinferenz überwachen: Protokollieren Sie Eingaben und Ausgaben in verschiedenen Phasen der Inferenz-Pipeline, um Anomalien zu erkennen. Dies kann helfen, Probleme wie Datenkorruption oder unsachgemäße Handhabung von Modellausgaben zu identifizieren.
- Überprüfung des Modellexports und der Konvertierung: Exportieren Sie das Modell erneut und stellen Sie sicher, dass der Konvertierungsprozess die Integrität der Modellgewichte und der Architektur beibehält.
- Testen mit einem kontrollierten Datensatz: Stellen Sie das Modell in einer Testumgebung mit einem von Ihnen kontrollierten Datensatz bereit und vergleichen Sie die Ergebnisse mit der Trainingsphase. Sie können feststellen, ob das Problem bei der Bereitstellungsumgebung oder den Daten liegt.
Bei der Bereitstellung von YOLO26 können mehrere Faktoren die Modellgenauigkeit beeinflussen. Die Konvertierung von Modellen in Formate wie TensorRT beinhaltet Optimierungen wie Gewichtsquantisierung und Layer-Fusion, was zu geringfügigen Präzisionsverlusten führen kann. Die Verwendung von FP16 (Halbpräzision) anstelle von FP32 (Vollpräzision) kann die Inferenz beschleunigen, aber numerische Präzisionsfehler einführen. Auch Hardwarebeschränkungen, wie die des Jetson Nano, mit geringeren CUDA-Kernzahlen und reduzierter Speicherbandbreite, können die Leistung beeinträchtigen.
Inferenz dauert länger als erwartet
Bei der Bereitstellung von Machine-Learning-Modellen ist es wichtig, dass diese effizient laufen. Wenn Inferenzierungen länger als erwartet dauern, kann dies die Benutzererfahrung und die Effektivität Ihrer Anwendung beeinträchtigen. Hier sind einige Schritte, die Ihnen helfen, das Problem zu identifizieren und zu beheben:
- Implementieren Sie Warm-Up-Durchläufe: Anfängliche Durchläufe beinhalten oft Setup-Overhead, der die Latenzmessungen verfälschen kann. Führen Sie einige Warm-Up-Inferences durch, bevor Sie die Latenz messen. Das Ausschließen dieser anfänglichen Durchläufe liefert eine genauere Messung der Leistung des Modells.
- Inference Engine optimieren: Überprüfen Sie, ob die Inference Engine vollständig für Ihre spezifische GPU-Architektur optimiert ist. Verwenden Sie die neuesten Treiber und Softwareversionen, die auf Ihre Hardware zugeschnitten sind, um maximale Leistung und Kompatibilität zu gewährleisten.
- Asynchrone Verarbeitung verwenden: Asynchrone Verarbeitung kann helfen, Workloads effizienter zu verwalten. Verwenden Sie asynchrone Verarbeitungstechniken, um mehrere Inferenzvorgänge gleichzeitig zu bearbeiten, was helfen kann, die Last zu verteilen und Wartezeiten zu reduzieren.
- Profilerstellung der Inferenzpipeline: Das Erkennen von Engpässen in der Inferenzpipeline kann helfen, die Ursache von Verzögerungen zu ermitteln. Verwenden Sie Profilerstellungstools, um jeden Schritt des Inferenzprozesses zu analysieren und alle Phasen zu identifizieren und zu beheben, die erhebliche Verzögerungen verursachen, wie z. B. ineffiziente Schichten oder Datenübertragungsprobleme.
- Angemessene Präzision verwenden: Die Verwendung einer höheren Präzision als nötig kann die Inferenzzeiten verlangsamen. Experimentieren Sie mit der Verwendung einer geringeren Präzision, z. B. FP16 (halbe Präzision), anstelle von FP32 (volle Präzision). Während FP16 die Inferenzzeit verkürzen kann, ist zu beachten, dass dies auch die Modellgenauigkeit beeinträchtigen kann.
Wenn Sie bei der Bereitstellung von YOLO26 auf dieses Problem stoßen, bedenken Sie, dass YOLO26 verschiedene Modellgrößen anbietet, wie YOLO26n (nano) für Geräte mit geringerer Speicherkapazität und YOLO26x (extra-large) für leistungsstärkere GPUs. Die Wahl der richtigen Modellvariante für Ihre Hardware kann dazu beitragen, Speichernutzung und Verarbeitungszeit auszugleichen.
Beachten Sie auch, dass die Größe der Eingangsbilder direkten Einfluss auf die Speichernutzung und die Verarbeitungszeit hat. Niedrigere Auflösungen reduzieren die Speichernutzung und beschleunigen die Inferenz, während höhere Auflösungen die Genauigkeit verbessern, aber mehr Speicher und Rechenleistung erfordern.
Sicherheitsüberlegungen bei der Modellbereitstellung
Ein weiterer wichtiger Aspekt beim Deployment ist die Sicherheit. Die Sicherheit Ihrer bereitgestellten Modelle ist entscheidend, um sensible Daten und geistiges Eigentum zu schützen. Hier sind einige Best Practices, die Sie im Zusammenhang mit einem sicheren Model Deployment befolgen können.
Sichere Datenübertragung
Sicherzustellen, dass Daten, die zwischen Clients und Servern gesendet werden, sicher sind, ist sehr wichtig, um zu verhindern, dass sie von unbefugten Dritten abgefangen oder abgerufen werden. Sie können Verschlüsselungsprotokolle wie TLS (Transport Layer Security) verwenden, um Daten während der Übertragung zu verschlüsseln. Selbst wenn jemand die Daten abfängt, kann er sie nicht lesen. Sie können auch eine End-to-End-Verschlüsselung verwenden, die die Daten vom Ursprung bis zum Ziel schützt, sodass niemand dazwischen darauf zugreifen kann.
Zugriffskontrollen
Es ist unerlässlich zu kontrollieren, wer auf Ihr Modell und dessen Daten zugreifen kann, um unbefugte Nutzung zu verhindern. Verwenden Sie starke Authentifizierungsmethoden, um die Identität von Benutzern oder Systemen zu überprüfen, die versuchen, auf das Modell zuzugreifen, und erwägen Sie, zusätzliche Sicherheit durch Multi-Faktor-Authentifizierung (MFA) hinzuzufügen. Richten Sie eine rollenbasierte Zugriffskontrolle (RBAC) ein, um Berechtigungen basierend auf Benutzerrollen zuzuweisen, sodass Personen nur Zugriff auf das erhalten, was sie benötigen. Führen Sie detaillierte Audit-Logs, um alle Zugriffe und Änderungen am Modell und seinen Daten zu verfolgen, und überprüfen Sie diese Logs regelmäßig, um verdächtige Aktivitäten zu erkennen.
Modellverschleierung
Der Schutz Ihres Modells vor Reverse Engineering oder Missbrauch kann durch Modellverschleierung erfolgen. Dies beinhaltet die Verschlüsselung von Modellparametern, wie z. B. Gewichten und Bias in neuronalen Netzen, um es Unbefugten zu erschweren, das Modell zu verstehen oder zu verändern. Sie können auch die Architektur des Modells verschleiern, indem Sie Schichten und Parameter umbenennen oder Dummy-Schichten hinzufügen, wodurch es für Angreifer schwieriger wird, es per Reverse Engineering zu rekonstruieren. Sie können das Modell auch in einer sicheren Umgebung bereitstellen, z. B. in einer sicheren Enklave oder mithilfe einer Trusted Execution Environment (TEE), um eine zusätzliche Schutzschicht während der Inferenz zu bieten.
Tauschen Sie sich mit Ihren Kollegen aus
Teil einer Community von Computer-Vision-Enthusiasten zu sein, kann Ihnen helfen, Probleme zu lösen und schneller zu lernen. Hier sind einige Möglichkeiten, sich zu vernetzen, Hilfe zu erhalten und Ideen auszutauschen.
Community-Ressourcen
- GitHub Issues: Erkunden Sie das YOLO26 GitHub-Repository und nutzen Sie den Tab „Issues“, um Fragen zu stellen, Fehler zu melden und neue Funktionen vorzuschlagen. Die Community und die Betreuer sind sehr aktiv und hilfsbereit.
- Ultralytics Discord Server: Treten Sie dem Ultralytics Discord Server bei, um sich mit anderen Benutzern und Entwicklern auszutauschen, Unterstützung zu erhalten und Ihre Erfahrungen zu teilen.
Offizielle Dokumentation
- Ultralytics YOLO26 Dokumentation: Besuchen Sie die offizielle YOLO26 Dokumentation für detaillierte Anleitungen und hilfreiche Tipps zu verschiedenen Computer-Vision-Projekten.
Die Nutzung dieser Ressourcen wird Ihnen helfen, Herausforderungen zu meistern und mit den neuesten Trends und Praktiken in der Computer-Vision-Community auf dem Laufenden zu bleiben.
Fazit und nächste Schritte
Wir haben einige Best Practices für die Bereitstellung von Computer-Vision-Modellen durchgesprochen. Durch die Sicherung von Daten, die Kontrolle des Zugriffs und die Verschleierung von Modelldetails können Sie sensible Informationen schützen und gleichzeitig sicherstellen, dass Ihre Modelle reibungslos laufen. Wir haben auch besprochen, wie Sie häufige Probleme wie reduzierte Genauigkeit und langsame Inferenz mithilfe von Strategien wie Warm-up-Läufen, Optimierung von Engines, asynchroner Verarbeitung, Profiling-Pipelines und der Wahl der richtigen Präzision beheben können.
Nach der Bereitstellung Ihres Modells wären die nächsten Schritte die Überwachung, Wartung und Dokumentation Ihrer Anwendung. Regelmäßige Überwachung hilft, Probleme schnell zu erkennen und zu beheben, die Wartung hält Ihre Modelle auf dem neuesten Stand und funktionsfähig, und eine gute Dokumentation verfolgt alle Änderungen und Aktualisierungen. Diese Schritte helfen Ihnen, die Ziele Ihres Computer-Vision-Projekts zu erreichen.
FAQ
Was sind die Best Practices für die Bereitstellung eines Machine-Learning-Modells mit Ultralytics YOLO26?
Die Bereitstellung eines Machine-Learning-Modells, insbesondere mit Ultralytics YOLO26, umfasst mehrere Best Practices, um Effizienz und Zuverlässigkeit zu gewährleisten. Wählen Sie zunächst die Bereitstellungsumgebung, die Ihren Anforderungen entspricht – Cloud, Edge oder lokal. Optimieren Sie Ihr Modell durch Techniken wie Pruning, Quantisierung und Knowledge Distillation für eine effiziente Bereitstellung in ressourcenbeschränkten Umgebungen. Erwägen Sie die Verwendung von Containerisierung mit Docker, um Konsistenz in verschiedenen Umgebungen zu gewährleisten. Stellen Sie schließlich sicher, dass die Datenkonsistenz und die Vorverarbeitungsschritte mit der Trainingsphase übereinstimmen, um die Leistung aufrechtzuerhalten. Weitere detaillierte Richtlinien finden Sie auch unter Modellbereitstellungsoptionen.
Wie kann ich häufige Bereitstellungsprobleme mit Ultralytics YOLO26-Modellen beheben?
Die Fehlerbehebung bei Bereitstellungsproblemen lässt sich in einige wichtige Schritte unterteilen. Wenn die Genauigkeit Ihres Modells nach der Bereitstellung sinkt, überprüfen Sie die Datenkonsistenz, validieren Sie die Vorverarbeitungsschritte und stellen Sie sicher, dass die Hardware- / Softwareumgebung mit der während des Trainings verwendeten übereinstimmt. Für langsame Inferenzzeiten führen Sie Warm-up-Läufe durch, optimieren Sie Ihre Inferenz-Engine, verwenden Sie asynchrone Verarbeitung und erstellen Sie ein Profil Ihrer Inferenz-Pipeline. Eine detaillierte Anleitung zu diesen Best Practices finden Sie unter Fehlerbehebung bei Bereitstellungsproblemen.
Wie verbessert die Ultralytics YOLO26-Optimierung die Modellleistung auf Edge-Geräten?
Die Optimierung von Ultralytics YOLO26-Modellen für Edge-Geräte umfasst Techniken wie Pruning zur Reduzierung der Modellgröße, Quantisierung zur Umwandlung von Gewichten in geringere Präzision und Knowledge Distillation zum Training kleinerer Modelle, die größere imitieren. Diese Techniken stellen sicher, dass das Modell effizient auf Geräten mit begrenzter Rechenleistung läuft. Tools wie TensorFlow Lite und NVIDIA Jetson sind für diese Optimierungen besonders nützlich. Erfahren Sie mehr über diese Techniken in unserem Abschnitt zur Modelloptimierung.
Welche Sicherheitsaspekte sind bei der Bereitstellung von Machine-Learning-Modellen mit Ultralytics YOLO26 zu beachten?
Sicherheit ist von größter Bedeutung bei der Bereitstellung von Machine-Learning-Modellen. Stellen Sie eine sichere Datenübertragung mithilfe von Verschlüsselungsprotokollen wie TLS sicher. Implementieren Sie robuste Zugriffskontrollen, einschließlich starker Authentifizierung und rollenbasierter Zugriffskontrolle (RBAC). Modellverschleierungstechniken, wie z. B. die Verschlüsselung von Modellparametern und das Bereitstellen von Modellen in einer sicheren Umgebung wie einer Trusted Execution Environment (TEE), bieten zusätzlichen Schutz. Detaillierte Verfahren finden Sie unter Sicherheitsüberlegungen.
Wie wähle ich die richtige Bereitstellungsumgebung für mein Ultralytics YOLO26-Modell?
Die Auswahl der optimalen Bereitstellungsumgebung für Ihr Ultralytics YOLO26-Modell hängt von den spezifischen Anforderungen Ihrer Anwendung ab. Cloud-Bereitstellung bietet Skalierbarkeit und einfachen Zugriff, was sie ideal für Anwendungen mit hohen Datenmengen macht. Edge-Bereitstellung eignet sich am besten für Anwendungen mit geringer Latenz, die Echtzeitantworten erfordern, unter Verwendung von Tools wie TensorFlow Lite. Lokale Bereitstellung eignet sich für Szenarien, die strenge Datenschutz- und Kontrollanforderungen haben. Für einen umfassenden Überblick über jede Umgebung besuchen Sie unseren Abschnitt zur Auswahl einer Bereitstellungsumgebung.




