Link to this sectionUltralytics YOLO26#
Link to this section개요#
Ultralytics YOLO26은 Ultralytics YOLO26 논문에 기술된 실시간 비전 모델의 통합 제품군입니다. 이 모델은 네이티브 엔드투엔드 추론, 더 가벼워진 탐지 헤드, 업데이트된 학습 레시피, 그리고 탐지, 세그멘테이션, 포즈 추정, 분류 및 지향성 탐지를 위한 작업별 헤드를 도입했습니다.
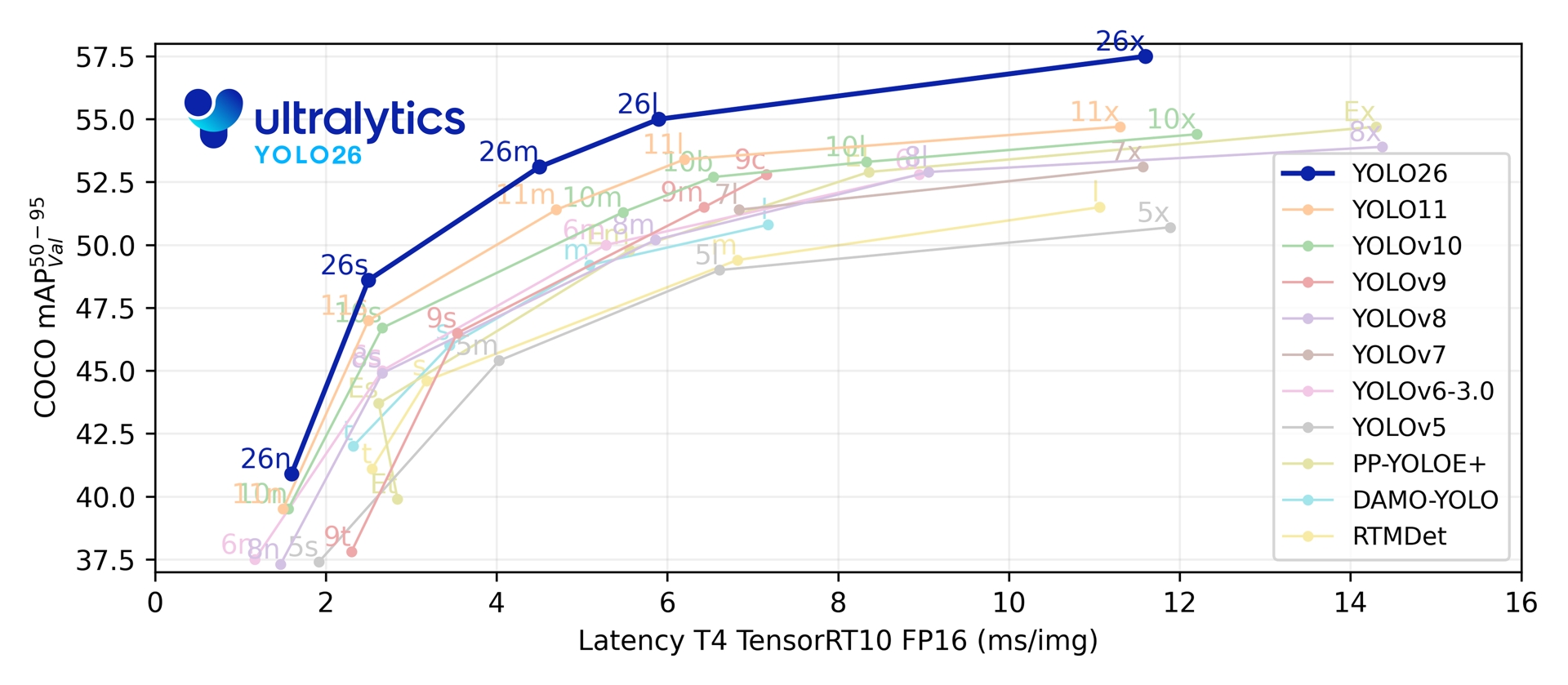
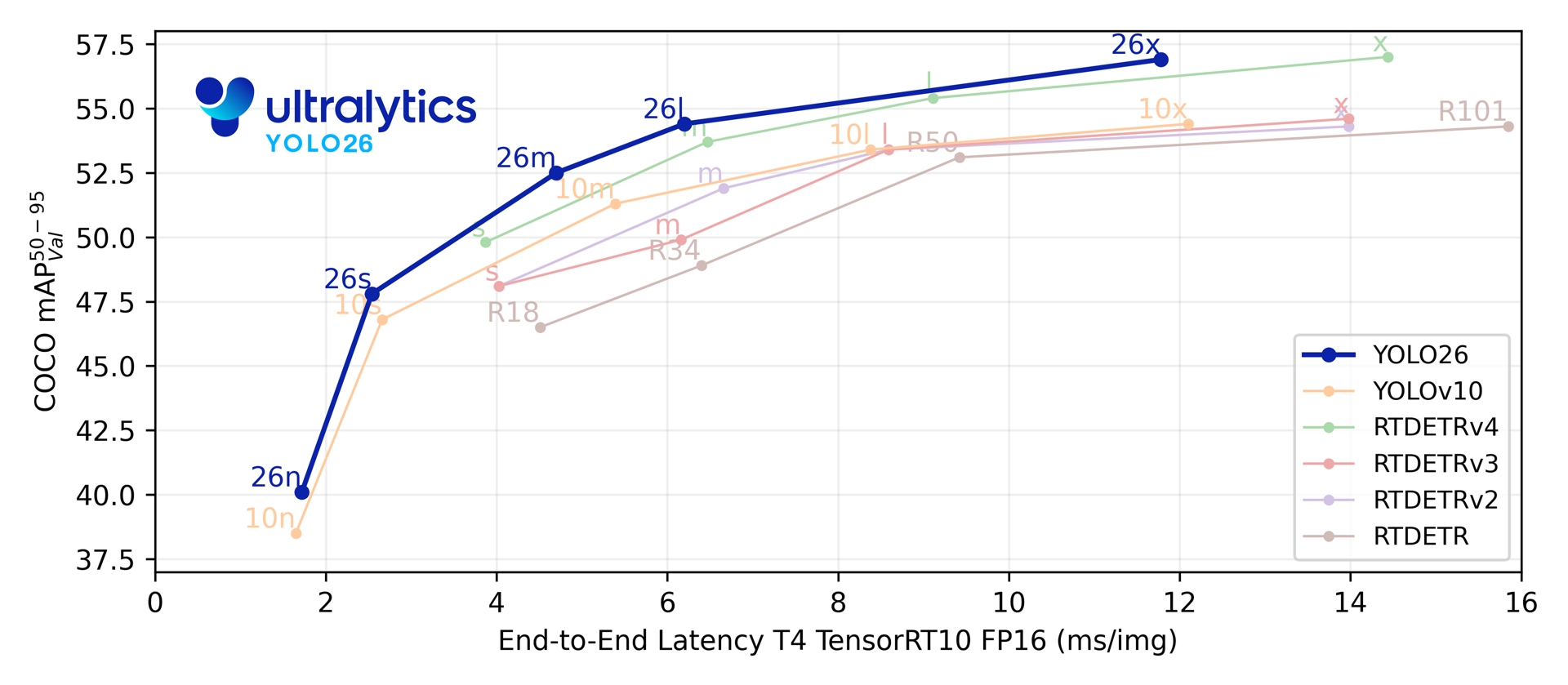
5가지 탐지 스케일에 걸쳐 YOLO26은 1.7-11.8 ms T4 TensorRT 지연 시간에서 COCO 기준 40.9-57.5 mAP를 달성합니다. 또한, 해당 논문은 Intel Xeon CPU @ 2.00 GHz 환경에서 YOLO11n 대비 YOLO26n의 CPU ONNX 추론 속도가 최대 43% 더 빠름을 보고합니다.
Ultralytics Platform에서 YOLO26 모델을 직접 탐색하고 실행해 보십시오.
YOLO26 모델 제품군은 다음 4가지 설계 영역을 중심으로 구축되었습니다:
- 네이티브 엔드투엔드 추론: 기본 일대일(one-to-one) 탐지 헤드는 NMS(비최대 억제) 없이 예측을 생성하여 배포를 간소화하고 후처리를 줄입니다.
- 더 가벼워진 박스 회귀: YOLO26은 DFL(분산 초점 손실)을 제거하여, 제약 없는 회귀 범위를 유지하면서도 탐지 헤드의 복잡성을 줄였습니다.
- 학습 레시피 업데이트: 학습 파이프라인은 MuSGD, Progressive Loss, STAL을 결합하여 최적화를 개선하고, 추론 시점의 헤드(inference-time head)로 감독을 이동시키며, 작은 객체에 대한 양수 레이블 커버리지를 유지합니다. 출시된 체크포인트의 전체 하이퍼파라미터는 YOLO26 Training Recipe 가이드에 문서화되어 있습니다.
- 작업별 헤드 및 손실 함수: YOLO26은 인스턴스 세그멘테이션, 시맨틱 세그멘테이션 변형, 포즈 추정 및 지향성 탐지를 위한 목표 설계를 추가하는 동시에, 모든 작업에서 단일 모델 파이프라인을 유지합니다.
이러한 업데이트들을 통해 모델 스케일 및 배포 대상 전반에서 정확도와 지연 시간 사이의 트레이드오프가 개선됩니다.
Link to this section주요 특징#
-
DFL-Free 회귀 YOLO26은 DFL(분산 초점 손실)을 제거하여 탐지 헤드의 복잡성을 줄이고 내보내기(export) 과정을 단순화합니다.
-
엔드투엔드 NMS-Free 추론 별도의 후처리 단계로 NMS에 의존하는 기존 탐지기와 달리, YOLO26은 기본적으로 네이티브 엔드투엔드 방식을 취합니다. 예측이 직접 생성되므로 지연 시간이 줄어들고 프로덕션 통합이 더 간편해집니다.
-
Progressive Loss + STAL Progressive Loss는 학습의 초점을 추론 시점의 헤드로 전환하며, STAL은 작은 객체에 대한 양성 라벨 커버리지를 향상시킵니다.
-
MuSGD 옵티마이저 SGD와 Muon을 결합한 하이브리드 옵티마이저로, 거대 언어 모델 학습의 최적화 개념을 컴퓨터 비전에 적용합니다.
-
효율적인 배포 간소화된 헤드와 NMS-Free 기본 경로를 통해 내보내기 대상 및 하드웨어 프로필 전반에서 추론 오버헤드가 감소합니다. 논문에서는 YOLO11n 대비 YOLO26n의 CPU ONNX 속도 향상이 보고되었습니다.
-
인스턴스 세그멘테이션 강화 모델 수렴을 개선하기 위한 시맨틱 세그멘테이션 손실과, 멀티 스케일 정보를 활용하여 마스크 품질을 높인 업그레이드된 proto 모듈을 도입했습니다. 논문에 따르면 COCO 인스턴스 세그멘테이션에서 YOLO11 대비 박스 AP 최대 +2.5, 마스크 AP 최대 +3.7 향상을 기록했습니다.
-
정밀 포즈 추정 RLE(잔차 로그 가능성 추정)를 통합하여 키포인트 위치 추정 정확도를 높이고, 추론 속도를 위해 디코딩 과정을 최적화했습니다. 논문에서는 COCO 포즈 추정에서 YOLO11 대비 AP 최대 +7.2 향상을 보고합니다.
-
개선된 OBB 디코딩 정사각형 객체에 대한 탐지 정확도를 개선하기 위해 특수 각도 손실(angle loss)을 도입하고, 경계 불연속성 문제를 해결하기 위해 OBB 디코딩을 최적화했습니다. 논문에서는 DOTA-v1.0 지향성 탐지에서 YOLO11 대비 mAP 최대 +3.4 향상을 보고합니다.
Link to this section지원되는 작업 및 모드#
YOLO26은 5가지 모델 스케일에 걸쳐 표준 Ultralytics 작업 세트를 지원합니다:
| 모델 | 파일 이름 | 작업 | 추론 | 검증 | 학습 | 내보내기(Export) |
|---|---|---|---|---|---|---|
| YOLO26 | yolo26n.pt yolo26s.pt yolo26m.pt yolo26l.pt yolo26x.pt | 탐지 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-seg | yolo26n-seg.pt yolo26s-seg.pt yolo26m-seg.pt yolo26l-seg.pt yolo26x-seg.pt | 인스턴스 세분화(Instance Segmentation) | ✅ | ✅ | ✅ | ✅ |
| YOLO26-sem | yolo26n-sem.pt yolo26s-sem.pt yolo26m-sem.pt yolo26l-sem.pt yolo26x-sem.pt | 시맨틱 세그멘테이션 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-pose | yolo26n-pose.pt yolo26s-pose.pt yolo26m-pose.pt yolo26l-pose.pt yolo26x-pose.pt | 포즈/키포인트 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-obb | yolo26n-obb.pt yolo26s-obb.pt yolo26m-obb.pt yolo26l-obb.pt yolo26x-obb.pt | 지향성 탐지 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-cls | yolo26n-cls.pt yolo26s-cls.pt yolo26m-cls.pt yolo26l-cls.pt yolo26x-cls.pt | 분류 | ✅ | ✅ | ✅ | ✅ |
이 통합 프레임워크는 학습, 검증, 추론 및 내보내기 지원과 함께 실시간 탐지, 인스턴스 세그멘테이션, 시맨틱 세그멘테이션, 분류, 포즈 추정 및 지향성 객체 탐지를 모두 다룹니다.
yolo26-p2.yaml 및 yolo26-p6.yaml은 P2(소형 객체) 또는 P6(대형 입력) 탐지 헤드를 추가하며, YAML 아키텍처로만 제공됩니다. 스케일별 yolo26*-p2.pt 또는 yolo26*-p6.pt 가중치는 릴리스되지 않습니다. YAML에서 스케일링된 설정을 인스턴스화하고(예: YOLO("yolo26n-p6.yaml")), 필요에 따라 학습 또는 파인튜닝하십시오.
Link to this section성능 지표#
See Detection Docs for usage examples with these models trained on COCO, which include 80 pretrained classes.
| 모델 | 크기 (픽셀) | mAPval 50-95 | mAPval 50-95(e2e) | 속도 CPU ONNX (ms) | 속도 T4 TensorRT10 (ms) | 파라미터 (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO26n | 640 | 40.9 | 40.1 | 38.9 ± 0.7 | 1.7 ± 0.0 | 2.4 | 5.4 |
| YOLO26s | 640 | 48.6 | 47.8 | 87.2 ± 0.9 | 2.5 ± 0.0 | 9.5 | 20.7 |
| YOLO26m | 640 | 53.1 | 52.5 | 220.0 ± 1.4 | 4.7 ± 0.1 | 20.4 | 68.2 |
| YOLO26l | 640 | 55.0 | 54.4 | 286.2 ± 2.0 | 6.2 ± 0.2 | 24.8 | 86.4 |
| YOLO26x | 640 | 57.5 | 56.9 | 525.8 ± 4.0 | 11.8 ± 0.2 | 55.7 | 193.9 |
Params 및 FLOPs 값은 model.fuse() 이후 융합된 모델 기준입니다. 이는 Conv 및 BatchNorm 레이어를 병합하고 보조 일대다(one-to-many) 탐지 헤드를 제거합니다. 사전 학습된 체크포인트는 전체 학습 아키텍처를 유지하므로 더 높은 수치를 나타낼 수 있습니다.
Link to this section사용 예제#
이 섹션에서는 간단한 YOLO26 학습 및 추론 예제를 제공합니다. 이 모드 및 기타 모드에 대한 전체 문서는 예측(Predict), 학습(Train), 검증(Val) 및 내보내기(Export) 문서 페이지를 참조하십시오.
아래 예시는 YOLO26 Detect 모델을 이용한 object detection 관련 내용입니다. 추가로 지원되는 작업은 Segment, Semantic Segmentation, Classify, OBB, Pose 문서를 참조하십시오.
PyTorch 사전 학습된 *.pt 모델과 구성 *.yaml 파일을 YOLO() 클래스에 전달하여 Python에서 모델 인스턴스를 생성할 수 있습니다:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLO26n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")YOLO26 탐지 모델은 다양한 배포 시나리오에 유연성을 제공하는 듀얼 헤드 아키텍처를 사용합니다:
- 일대일(One-to-One) 헤드 (기본값): NMS 없이 엔드 투 엔드(end-to-end) 예측을 생성하며, 이미지당 최대 300개의 탐지 결과인
(N, 300, 6)을 출력합니다. 이 헤드는 빠른 추론과 간소화된 배포에 최적화되어 있습니다. - 일대다(One-to-Many) 헤드: NMS 후처리가 필요한 전통적인 YOLO 출력을 생성하며,
(N, nc + 4, 8400)을 출력합니다 (여기서nc는 클래스 수). 이 헤드는 일반적으로 추가 처리 비용을 들여 약간 더 높은 정확도를 달성합니다.
내보내기, 예측 또는 검증 중에 헤드를 전환할 수 있습니다:
from ultralytics import YOLO
model = YOLO("yolo26n.pt")
# Use one-to-one head (default, no NMS required)
results = model.predict("image.jpg") # inference
metrics = model.val(data="coco.yaml") # validation
model.export(format="onnx") # export
# Use one-to-many head (requires NMS)
results = model.predict("image.jpg", end2end=False) # inference
metrics = model.val(data="coco.yaml", end2end=False) # validation
model.export(format="onnx", end2end=False) # export선택은 배포 요구 사항에 따라 다릅니다. 최대 속도와 단순성이 필요한 경우 일대일 헤드를 사용하고, 정확도가 최우선인 경우 일대다 헤드를 사용하십시오.
Link to this sectionYOLOE-26: 오픈 어휘 탐지 및 세그멘테이션#
YOLOE-26은 YOLOE 시리즈의 오픈 어휘 기능을 활용하여 YOLO26을 확장합니다. 이를 통해 텍스트 프롬프트, 시각적 프롬프트 또는 프롬프트 프리(prompt-free) 모드를 사용하여 오픈 세트 객체 카테고리를 실시간으로 탐지하고 세그멘테이션할 수 있습니다.
YOLO26의 NMS가 필요 없는 엔드 투 엔드 설계를 활용하여 YOLOE-26은 대상 카테고리가 시간이 지남에 따라 변할 수 있는 동적 환경에서도 오픈 어휘 추론 속도를 유지합니다. YOLOE-26x는 텍스트 프롬프팅 시 LVIS minival에서 40.6 AP, 시각적 프롬프팅 시 38.5 AP, 프롬프트 프리 Non-E2E 설정에서 31.1 AP를 달성합니다.
See YOLOE Docs for usage examples with these models trained on Objects365v1, GQA and Flickr30k datasets.
| 모델 | 크기 (픽셀) | 프롬프트 유형 | mAPminival 50-95(e2e) | mAPminival 50-95 | mAPr | mAPc | mAPf | 파라미터 (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOE-26n-seg | 640 | 텍스트/시각적 | 23.7 / 20.9 | 24.7 / 21.9 | 20.5 / 17.6 | 24.1 / 22.3 | 26.1 / 22.4 | 4.8 | 6.0 |
| YOLOE-26s-seg | 640 | 텍스트/시각적 | 29.9 / 27.1 | 30.8 / 28.6 | 23.9 / 25.1 | 29.6 / 27.8 | 33.0 / 29.9 | 13.1 | 21.7 |
| YOLOE-26m-seg | 640 | 텍스트/시각적 | 35.4 / 31.3 | 35.4 / 33.9 | 31.1 / 33.4 | 34.7 / 34.0 | 36.9 / 33.8 | 27.9 | 70.1 |
| YOLOE-26l-seg | 640 | 텍스트/시각적 | 36.8 / 33.7 | 37.8 / 36.3 | 35.1 / 37.6 | 37.6 / 36.2 | 38.5 / 36.1 | 32.3 | 88.3 |
| YOLOE-26x-seg | 640 | 텍스트/시각적 | 39.5 / 36.2 | 40.6 / 38.5 | 37.4 / 35.3 | 40.9 / 38.8 | 41.0 / 38.8 | 69.9 | 196.7 |
Link to this section사용 예시#
YOLOE-26은 텍스트 기반 및 시각적 프롬프트를 모두 지원합니다. 프롬프트 사용은 간단하며, 아래와 같이 predict 메서드를 통해 전달하기만 하면 됩니다:
텍스트 프롬프트를 사용하면 텍스트 설명을 통해 탐지하려는 클래스를 지정할 수 있습니다. 다음 코드는 YOLOE-26을 사용하여 이미지에서 사람과 버스를 탐지하는 방법을 보여줍니다:
from ultralytics import YOLO
# Initialize model
model = YOLO("yoloe-26l-seg.pt") # or select yoloe-26s/m-seg.pt for different sizes
# Set text prompt to detect person and bus. You only need to do this once after you load the model.
model.set_classes(["person", "bus"])
# Run detection on the given image
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()프롬프팅 기술 및 전체 사용 예시를 보려면 **YOLOE Documentation**을 방문하십시오.
Link to this section인용 및 감사의 글#
YOLO26 아키텍처, 학습 레시피, 태스크 헤드 및 YOLOE-26 오픈 어휘 확장에 대한 전체 기술 설명은 Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models를 읽어보십시오. 연구에 YOLO26을 사용하는 경우 다음을 인용해 주십시오:
@misc{jocher2026ultralyticsyolo26unifiedrealtime,
title = {Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models},
author = {Glenn Jocher and Jing Qiu and Mengyu Liu and Shuai Lyu and Fatih Cagatay Akyon and Muhammet Esat Kalfaoglu},
year = {2026},
eprint = {2606.03748},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
doi = {10.48550/arXiv.2606.03748},
url = {https://arxiv.org/abs/2606.03748},
}YOLO26 code, models, and documentation are available in the Ultralytics GitHub repository and Ultralytics Docs under AGPL-3.0 and Enterprise licenses.
Link to this sectionFAQ#
Link to this sectionYOLO26의 주요 개선 사항은 무엇입니까?#
- DFL-free 회귀: 탐지 헤드 및 내보내기 경로 간소화
- 엔드투엔드 NMS-free 추론: 기본 추론 경로에서 NMS 제거
- Progressive Loss + STAL: 학습 정렬 및 소형 객체 레이블 커버리지 향상
- MuSGD 옵티마이저: 안정적인 학습을 위해 SGD와 Muon 기반 최적화를 결합
- 태스크별 헤드 및 손실 함수: 세그멘테이션, 포즈 및 방향 탐지 지원 향상
Link to this sectionYOLO26은 어떤 태스크를 지원합니까?#
YOLO26은 통합 모델 제품군으로, 다중 컴퓨터 비전 태스크에 대해 엔드투엔드 지원을 제공합니다:
각 크기 변형(n, s, m, l, x)은 모든 작업을 지원하며, YOLOE-26을 통해 오픈 어휘(open-vocabulary) 버전도 제공합니다.
Link to this sectionYOLO26이 배포에 효율적인 이유는 무엇입니까?#
YOLO26은 다음과 같은 기능으로 배포 효율성을 향상시킵니다:
- 기본적으로 NMS가 필요 없는 네이티브 엔드투엔드(end-to-end) 추론
- DFL 없는 회귀(regression) 및 더 가벼워진 탐지 헤드
- 학습 전용 보조 구성 요소를 제거하는 퓨즈드 모델(fused-model) 내보내기
- Intel Xeon CPU @ 2.00 GHz 환경에서 YOLO11n 대비 YOLO26n의 CPU ONNX 추론 속도가 최대 43% 향상됨
- TensorRT, ONNX, CoreML, LiteRT 및 OpenVINO를 포함한 유연한 내보내기 형식
Link to this sectionYOLO26을 시작하려면 어떻게 해야 합니까?#
YOLO26 모델은 ultralytics 패키지를 통해 다운로드할 수 있습니다. 패키지를 설치하거나 업데이트하고 모델을 로드하십시오:
from ultralytics import YOLO
# Load a pretrained YOLO26 nano model
model = YOLO("yolo26n.pt")
# Run inference on an image
results = model("image.jpg")학습, 검증 및 내보내기 지침은 Usage Examples 섹션을 참조하십시오.