Link to this sectionUltralytics YOLO26#
Link to this sectionTổng quan#
Ultralytics YOLO26 là một họ mô hình thị giác thời gian thực thống nhất được mô tả trong bài báo nghiên cứu về Ultralytics YOLO26. Nó giới thiệu khả năng suy luận end-to-end tự nhiên, đầu phát hiện (detection head) nhẹ hơn, công thức huấn luyện cập nhật và các đầu ra chuyên biệt cho các tác vụ phát hiện, phân đoạn, ước tính tư thế, phân loại và phát hiện theo hướng (oriented detection).
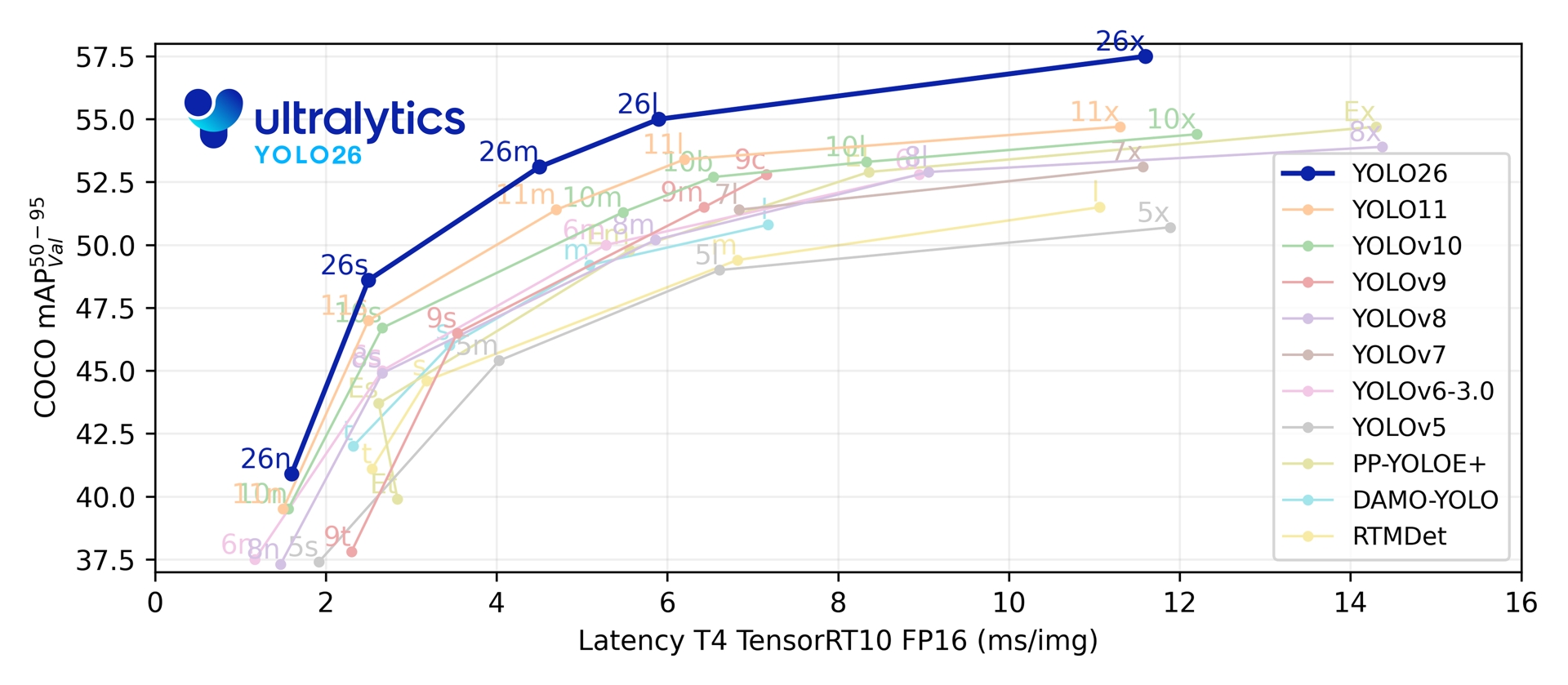
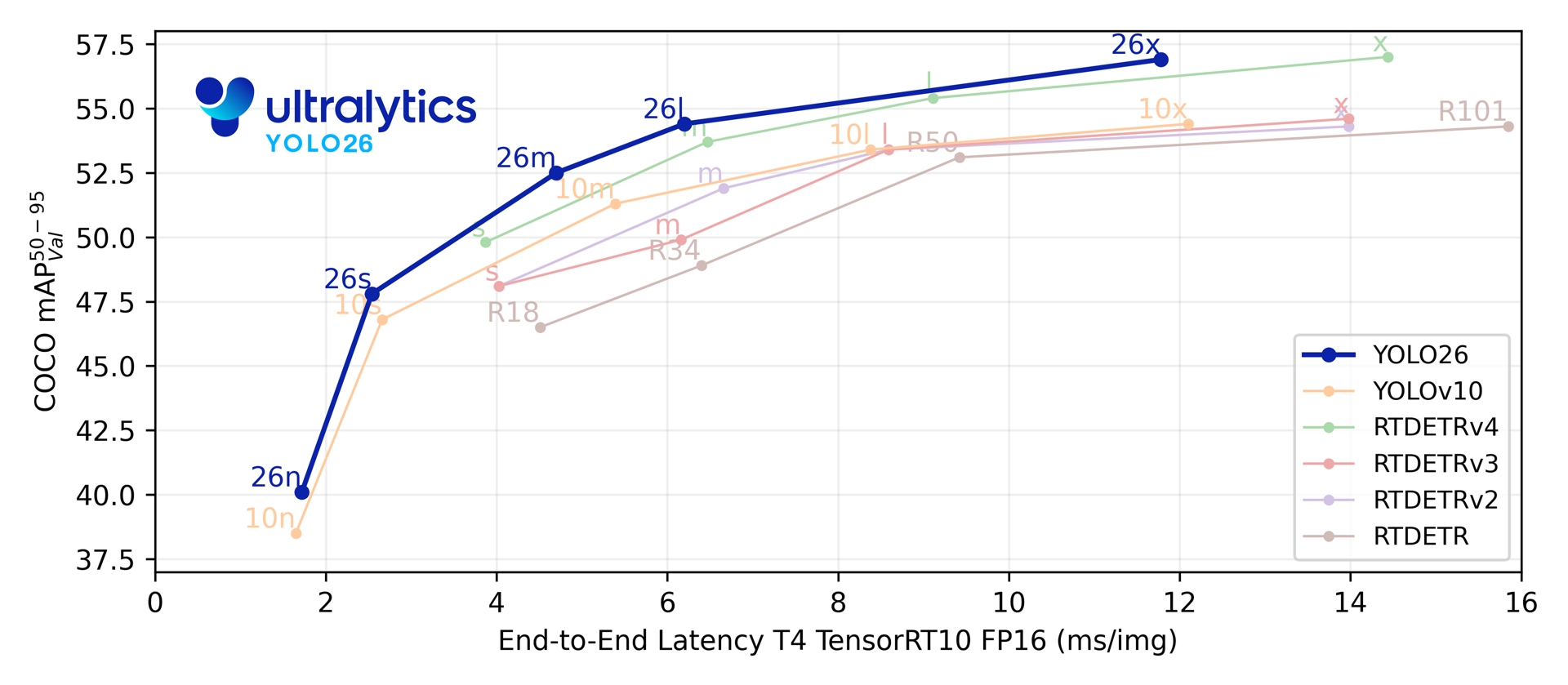
Trên năm thang đo phát hiện, YOLO26 đạt 40.9-57.5 mAP trên COCO với độ trễ 1.7-11.8 ms trên T4 TensorRT. Bài báo cũng báo cáo tốc độ suy luận CPU ONNX nhanh hơn tới 43% đối với YOLO26n so với YOLO11n trên CPU Intel Xeon @ 2.00 GHz.
Khám phá và chạy các mô hình YOLO26 trực tiếp trên Ultralytics Platform.
Họ mô hình YOLO26 được xây dựng dựa trên bốn lĩnh vực thiết kế:
- Suy luận end-to-end tự nhiên: Đầu phát hiện one-to-one mặc định tạo ra các dự đoán mà không cần NMS, giúp đơn giản hóa việc triển khai và giảm bớt các bước hậu xử lý.
- Hồi quy hộp (box regression) nhẹ hơn: YOLO26 loại bỏ Distribution Focal Loss (DFL), làm giảm độ phức tạp của đầu phát hiện trong khi vẫn duy trì phạm vi hồi quy không giới hạn.
- Cập nhật quy trình đào tạo: Pipeline đào tạo kết hợp MuSGD, Progressive Loss và STAL để cải thiện quá trình tối ưu hóa, chuyển dịch giám sát về phía head tại thời điểm inference và duy trì độ bao phủ nhãn dương tính cho các đối tượng nhỏ. Các siêu tham số đầy đủ đằng sau các checkpoint đã phát hành được ghi lại trong hướng dẫn về Quy trình Đào tạo YOLO26.
- Các đầu ra và hàm mất mát chuyên biệt: YOLO26 bổ sung các thiết kế nhắm mục tiêu cho phân đoạn instance, các biến thể phân đoạn ngữ nghĩa, ước tính tư thế và phát hiện theo hướng trong khi vẫn duy trì một pipeline mô hình duy nhất cho tất cả các tác vụ.
Tổng hợp lại, những cập nhật này cải thiện sự cân bằng giữa độ chính xác và độ trễ trên các thang đo mô hình và mục tiêu triển khai khác nhau.
Link to this sectionTính năng chính#
-
Hồi quy không dùng DFL YOLO26 loại bỏ Distribution Focal Loss (DFL), giúp giảm độ phức tạp của đầu phát hiện và đơn giản hóa quy trình xuất mô hình.
-
Suy luận end-to-end không cần NMS Không giống như các bộ phát hiện truyền thống dựa vào NMS như một bước hậu xử lý riêng biệt, YOLO26 mặc định có khả năng end-to-end tự nhiên. Các dự đoán được tạo ra trực tiếp, giúp giảm độ trễ và làm cho việc tích hợp vào môi trường sản xuất trở nên đơn giản hơn.
-
Progressive Loss + STAL Progressive Loss chuyển trọng tâm huấn luyện về phía đầu ra tại thời điểm suy luận, trong khi STAL cải thiện độ bao phủ nhãn dương tính cho các đối tượng nhỏ.
-
Trình tối ưu hóa MuSGD Một trình tối ưu hóa lai kết hợp SGD với Muon, áp dụng các ý tưởng tối ưu hóa từ huấn luyện mô hình ngôn ngữ lớn vào thị giác máy tính.
-
Triển khai hiệu quả Đầu ra đơn giản hóa và đường dẫn mặc định không cần NMS giúp giảm chi phí suy luận trên các mục tiêu xuất và cấu hình phần cứng khác nhau, bao gồm cả tốc độ tăng cường CPU ONNX đối với YOLO26n so với YOLO11n đã được báo cáo trong bài báo.
-
Cải tiến phân đoạn Instance Giới thiệu hàm mất mát phân đoạn ngữ nghĩa để cải thiện khả năng hội tụ của mô hình và mô-đun proto được nâng cấp tận dụng thông tin đa quy mô để đạt chất lượng mặt nạ (mask) vượt trội. Bài báo báo cáo mức tăng so với YOLO11 lên tới +2.5 box AP và +3.7 mask AP trên phân đoạn instance của COCO.
-
Ước tính tư thế chính xác Tích hợp Residual Log-Likelihood Estimation (RLE) để định vị điểm khóa chính xác hơn và tối ưu hóa quy trình giải mã để tăng tốc độ suy luận. Bài báo báo cáo mức tăng tới +7.2 AP so với YOLO11 trên tác vụ ước tính tư thế của COCO.
-
Giải mã OBB tinh chỉnh Giới thiệu hàm mất mát góc chuyên biệt để cải thiện độ chính xác phát hiện cho các đối tượng hình vuông và tối ưu hóa giải mã OBB để giải quyết các vấn đề gián đoạn biên. Bài báo báo cáo mức tăng tới +3.4 mAP so với YOLO11 trên tác vụ phát hiện theo hướng của DOTA-v1.0.
Link to this sectionCác tác vụ và chế độ được hỗ trợ#
YOLO26 hỗ trợ bộ tác vụ chuẩn của Ultralytics trên năm thang đo mô hình:
| Mô hình | Tên tệp | Tác vụ | Suy luận | Validation | Huấn luyện | Xuất (Export) |
|---|---|---|---|---|---|---|
| YOLO26 | yolo26n.pt yolo26s.pt yolo26m.pt yolo26l.pt yolo26x.pt | Phát hiện | ✅ | ✅ | ✅ | ✅ |
| YOLO26-seg | yolo26n-seg.pt yolo26s-seg.pt yolo26m-seg.pt yolo26l-seg.pt yolo26x-seg.pt | Phân đoạn Instance | ✅ | ✅ | ✅ | ✅ |
| YOLO26-sem | yolo26n-sem.pt yolo26s-sem.pt yolo26m-sem.pt yolo26l-sem.pt yolo26x-sem.pt | Phân đoạn ngữ nghĩa | ✅ | ✅ | ✅ | ✅ |
| YOLO26-pose | yolo26n-pose.pt yolo26s-pose.pt yolo26m-pose.pt yolo26l-pose.pt yolo26x-pose.pt | Tư thế/Điểm khóa | ✅ | ✅ | ✅ | ✅ |
| YOLO26-obb | yolo26n-obb.pt yolo26s-obb.pt yolo26m-obb.pt yolo26l-obb.pt yolo26x-obb.pt | Phát hiện theo hướng | ✅ | ✅ | ✅ | ✅ |
| YOLO26-cls | yolo26n-cls.pt yolo26s-cls.pt yolo26m-cls.pt yolo26l-cls.pt yolo26x-cls.pt | Phân loại | ✅ | ✅ | ✅ | ✅ |
Framework thống nhất này bao gồm phát hiện thời gian thực, phân đoạn instance, phân đoạn ngữ nghĩa, phân loại, ước tính tư thế và phát hiện đối tượng theo hướng với hỗ trợ cho huấn luyện, validation, suy luận và xuất mô hình.
yolo26-p2.yaml và yolo26-p6.yaml bổ sung một đầu phát hiện P2 (đối tượng nhỏ) hoặc P6 (đầu vào lớn) và chỉ được cung cấp dưới dạng kiến trúc YAML. Không có trọng số yolo26*-p2.pt hoặc yolo26*-p6.pt theo thang đo cụ thể nào được phát hành. Hãy khởi tạo một cấu hình từ YAML (ví dụ: YOLO("yolo26n-p6.yaml")) và huấn luyện hoặc tinh chỉnh (fine-tune) khi cần.
Link to this sectionChỉ số hiệu suất#
Xem Tài liệu Phát hiện để biết các ví dụ sử dụng với các mô hình này đã được huấn luyện trên COCO, bao gồm 80 lớp đã được huấn luyện trước.
| Mô hình | kích thước (pixel) | mAPval 50-95 | mAPval 50-95(e2e) | Tốc độ CPU ONNX (ms) | Tốc độ T4 TensorRT10 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO26n | 640 | 40.9 | 40.1 | 38.9 ± 0.7 | 1.7 ± 0.0 | 2.4 | 5.4 |
| YOLO26s | 640 | 48.6 | 47.8 | 87.2 ± 0.9 | 2.5 ± 0.0 | 9.5 | 20.7 |
| YOLO26m | 640 | 53.1 | 52.5 | 220.0 ± 1.4 | 4.7 ± 0.1 | 20.4 | 68.2 |
| YOLO26l | 640 | 55.0 | 54.4 | 286.2 ± 2.0 | 6.2 ± 0.2 | 24.8 | 86.4 |
| YOLO26x | 640 | 57.5 | 56.9 | 525.8 ± 4.0 | 11.8 ± 0.2 | 55.7 | 193.9 |
Các giá trị Params và FLOPs dành cho model đã được hợp nhất sau model.fuse(), giúp gộp các lớp Conv và BatchNorm cũng như loại bỏ head phát hiện one-to-many phụ trợ. Các checkpoint được huấn luyện trước giữ nguyên kiến trúc huấn luyện đầy đủ và có thể hiển thị số lượng cao hơn.
Link to this sectionVí dụ Sử dụng#
Phần này cung cấp các ví dụ đơn giản về huấn luyện và suy luận với YOLO26. Để xem tài liệu đầy đủ về các chế độ này và những chế độ khác, hãy xem các trang tài liệu Dự đoán (Predict), Huấn luyện (Train), Val và Xuất (Export).
Lưu ý rằng ví dụ dưới đây dành cho các model YOLO26 Detect cho phát hiện đối tượng. Đối với các tác vụ được hỗ trợ bổ sung, hãy xem tài liệu về Segment, Phân đoạn Ngữ nghĩa (Semantic Segmentation), Phân loại (Classify), OBB và Pose.
Các mô hình PyTorch đã được huấn luyện trước với định dạng *.pt cũng như các tệp cấu hình *.yaml có thể được truyền vào lớp YOLO() để tạo một thực thể mô hình trong Python:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLO26n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")Các model phát hiện YOLO26 sử dụng kiến trúc dual-head giúp mang lại sự linh hoạt cho các tình huống triển khai khác nhau:
- One-to-One Head (Mặc định): Tạo ra các dự đoán end-to-end mà không cần NMS, xuất ra
(N, 300, 6)với tối đa 300 phát hiện trên mỗi hình ảnh. Head này được tối ưu hóa cho suy luận nhanh và triển khai đơn giản hóa. - One-to-Many Head: Tạo ra các đầu ra YOLO truyền thống yêu cầu hậu xử lý NMS, xuất ra
(N, nc + 4, 8400)trong đónclà số lượng lớp. Head này thường đạt độ chính xác cao hơn một chút với cái giá phải trả là xử lý bổ sung.
Bạn có thể chuyển đổi giữa các head trong quá trình xuất, dự đoán hoặc xác thực:
from ultralytics import YOLO
model = YOLO("yolo26n.pt")
# Use one-to-one head (default, no NMS required)
results = model.predict("image.jpg") # inference
metrics = model.val(data="coco.yaml") # validation
model.export(format="onnx") # export
# Use one-to-many head (requires NMS)
results = model.predict("image.jpg", end2end=False) # inference
metrics = model.val(data="coco.yaml", end2end=False) # validation
model.export(format="onnx", end2end=False) # exportSự lựa chọn phụ thuộc vào các yêu cầu triển khai của bạn: hãy sử dụng one-to-one head để đạt tốc độ và sự đơn giản tối đa, hoặc sử dụng one-to-many head khi độ chính xác là ưu tiên hàng đầu.
Link to this sectionYOLOE-26: Phát hiện và Phân đoạn Từ vựng Mở (Open-Vocabulary)#
YOLOE-26 mở rộng YOLO26 với các khả năng từ vựng mở của dòng YOLOE. Nó cho phép phát hiện và phân đoạn thời gian thực các danh mục đối tượng tập hợp mở bằng cách sử dụng text prompts, visual prompts hoặc chế độ không prompt.
Bằng cách tận dụng thiết kế end-to-end, không NMS của YOLO26, YOLOE-26 giữ cho suy luận từ vựng mở đủ nhanh cho các môi trường động nơi danh mục mục tiêu có thể thay đổi theo thời gian. YOLOE-26x đạt 40.6 AP trên LVIS minival khi sử dụng text prompting, 38.5 AP với visual prompting và 31.1 AP trong thiết lập Non-E2E không cần prompt.
Xem Tài liệu YOLOE để biết các ví dụ sử dụng với các model này đã được huấn luyện trên các tập dữ liệu Objects365v1, GQA và Flickr30k.
| Mô hình | kích thước (pixel) | Loại Prompt | mAPminival 50-95(e2e) | mAPminival 50-95 | mAPr | mAPc | mAPf | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOE-26n-seg | 640 | Văn bản/Hình ảnh | 23.7 / 20.9 | 24.7 / 21.9 | 20.5 / 17.6 | 24.1 / 22.3 | 26.1 / 22.4 | 4.8 | 6.0 |
| YOLOE-26s-seg | 640 | Văn bản/Hình ảnh | 29.9 / 27.1 | 30.8 / 28.6 | 23.9 / 25.1 | 29.6 / 27.8 | 33.0 / 29.9 | 13.1 | 21.7 |
| YOLOE-26m-seg | 640 | Văn bản/Hình ảnh | 35.4 / 31.3 | 35.4 / 33.9 | 31.1 / 33.4 | 34.7 / 34.0 | 36.9 / 33.8 | 27.9 | 70.1 |
| YOLOE-26l-seg | 640 | Văn bản/Hình ảnh | 36.8 / 33.7 | 37.8 / 36.3 | 35.1 / 37.6 | 37.6 / 36.2 | 38.5 / 36.1 | 32.3 | 88.3 |
| YOLOE-26x-seg | 640 | Văn bản/Hình ảnh | 39.5 / 36.2 | 40.6 / 38.5 | 37.4 / 35.3 | 40.9 / 38.8 | 41.0 / 38.8 | 69.9 | 196.7 |
Link to this sectionVí dụ sử dụng#
YOLOE-26 hỗ trợ cả prompt văn bản và hình ảnh. Việc sử dụng prompt rất đơn giản—chỉ cần truyền chúng qua phương thức predict như hình dưới đây:
Prompt văn bản cho phép bạn chỉ định các lớp (classes) mà bạn muốn phát hiện thông qua mô tả văn bản. Mã code sau đây cho thấy cách bạn có thể sử dụng YOLOE-26 để phát hiện người và xe buýt trong một hình ảnh:
from ultralytics import YOLO
# Initialize model
model = YOLO("yoloe-26l-seg.pt") # or select yoloe-26s/m-seg.pt for different sizes
# Set text prompt to detect person and bus. You only need to do this once after you load the model.
model.set_classes(["person", "bus"])
# Run detection on the given image
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()Để biết các kỹ thuật prompting và ví dụ sử dụng đầy đủ, hãy truy cập Tài liệu YOLOE.
Link to this sectionTrích dẫn và Ghi nhận#
Để có mô tả kỹ thuật đầy đủ về kiến trúc YOLO26, công thức huấn luyện, các đầu ra nhiệm vụ (task heads) và phần mở rộng từ vựng mở YOLOE-26, hãy đọc Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models. Nếu bạn sử dụng YOLO26 trong nghiên cứu của mình, vui lòng trích dẫn:
@misc{jocher2026ultralyticsyolo26unifiedrealtime,
title = {Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models},
author = {Glenn Jocher and Jing Qiu and Mengyu Liu and Shuai Lyu and Fatih Cagatay Akyon and Muhammet Esat Kalfaoglu},
year = {2026},
eprint = {2606.03748},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
doi = {10.48550/arXiv.2606.03748},
url = {https://arxiv.org/abs/2606.03748},
}Mã nguồn, mô hình và tài liệu của YOLO26 có sẵn tại kho lưu trữ GitHub của Ultralytics và Tài liệu Ultralytics theo giấy phép AGPL-3.0 và Enterprise.
Link to this sectionCâu hỏi thường gặp#
Link to this sectionNhững cải tiến chính trong YOLO26 là gì?#
- Hồi quy không cần DFL (DFL-free regression): Đơn giản hóa phần đầu phát hiện (detection head) và đường dẫn xuất (export path)
- Suy luận end-to-end không cần NMS: Loại bỏ NMS khỏi đường dẫn suy luận mặc định
- Progressive Loss + STAL: Cải thiện sự căn chỉnh huấn luyện và độ bao phủ nhãn đối tượng nhỏ
- Trình tối ưu hóa MuSGD: Kết hợp SGD với tối ưu hóa lấy cảm hứng từ Muon để huấn luyện ổn định
- Các đầu ra và hàm mất mát chuyên biệt cho từng tác vụ: Cải thiện hỗ trợ cho phân đoạn (segmentation), tư thế (pose) và phát hiện theo hướng (oriented detection)
Link to this sectionYOLO26 hỗ trợ các tác vụ nào?#
YOLO26 là một họ model thống nhất, cung cấp hỗ trợ end-to-end cho nhiều tác vụ thị giác máy tính:
- Phát hiện đối tượng
- Phân đoạn Instance
- Phân đoạn ngữ nghĩa
- Phân loại hình ảnh
- Ước tính tư thế
- Phát hiện đối tượng theo hướng (OBB)
Mỗi biến thể kích thước (n, s, m, l, x) đều hỗ trợ tất cả các tác vụ, cùng với các phiên bản open-vocabulary thông qua YOLOE-26.
Link to this sectionTại sao YOLO26 lại hiệu quả cho việc triển khai?#
YOLO26 cải thiện hiệu suất triển khai nhờ:
- Inference end-to-end tự nhiên không cần NMS theo mặc định
- Hồi quy không cần DFL và detection head gọn nhẹ hơn
- Xuất mô hình đã hợp nhất giúp loại bỏ các thành phần phụ trợ chỉ dùng cho huấn luyện
- Inference ONNX trên CPU nhanh hơn tới 43% cho YOLO26n so với YOLO11n trên Intel Xeon CPU @ 2.00 GHz
- Các định dạng xuất linh hoạt bao gồm TensorRT, ONNX, CoreML, LiteRT, và OpenVINO
Link to this sectionLàm thế nào để bắt đầu với YOLO26?#
Các mô hình YOLO26 có sẵn để tải xuống thông qua gói ultralytics. Hãy cài đặt hoặc cập nhật gói và tải mô hình:
from ultralytics import YOLO
# Load a pretrained YOLO26 nano model
model = YOLO("yolo26n.pt")
# Run inference on an image
results = model("image.jpg")Xem phần Usage Examples để biết hướng dẫn về huấn luyện, xác thực và xuất mô hình.