Link to this sectionUltralytics YOLO26#
Link to this section概述#
Ultralytics YOLO26 是一个统一的实时视觉模型系列,详见 Ultralytics YOLO26 论文。它引入了原生端到端推理、更轻量的检测头、更新的训练方案,以及针对检测、分割、姿态估计、分类和定向检测的特定任务头。
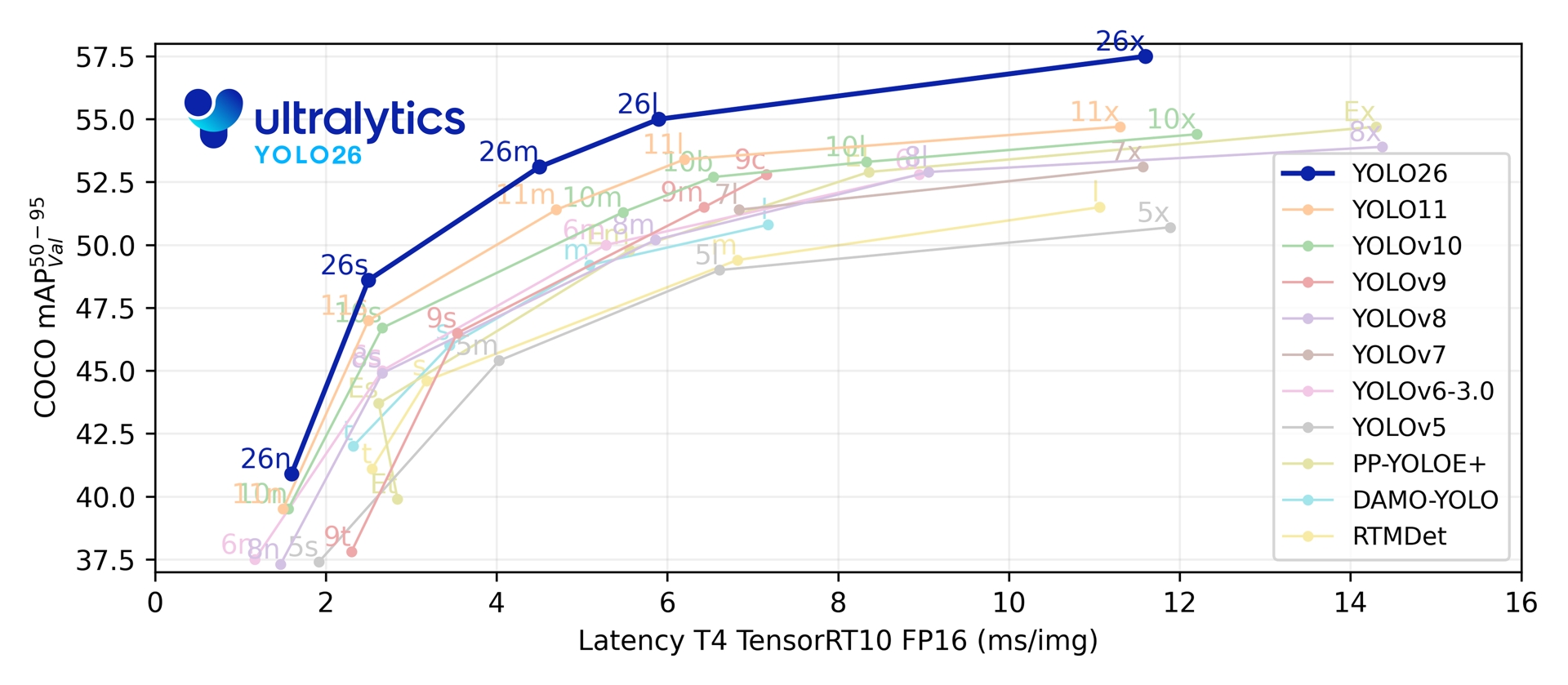
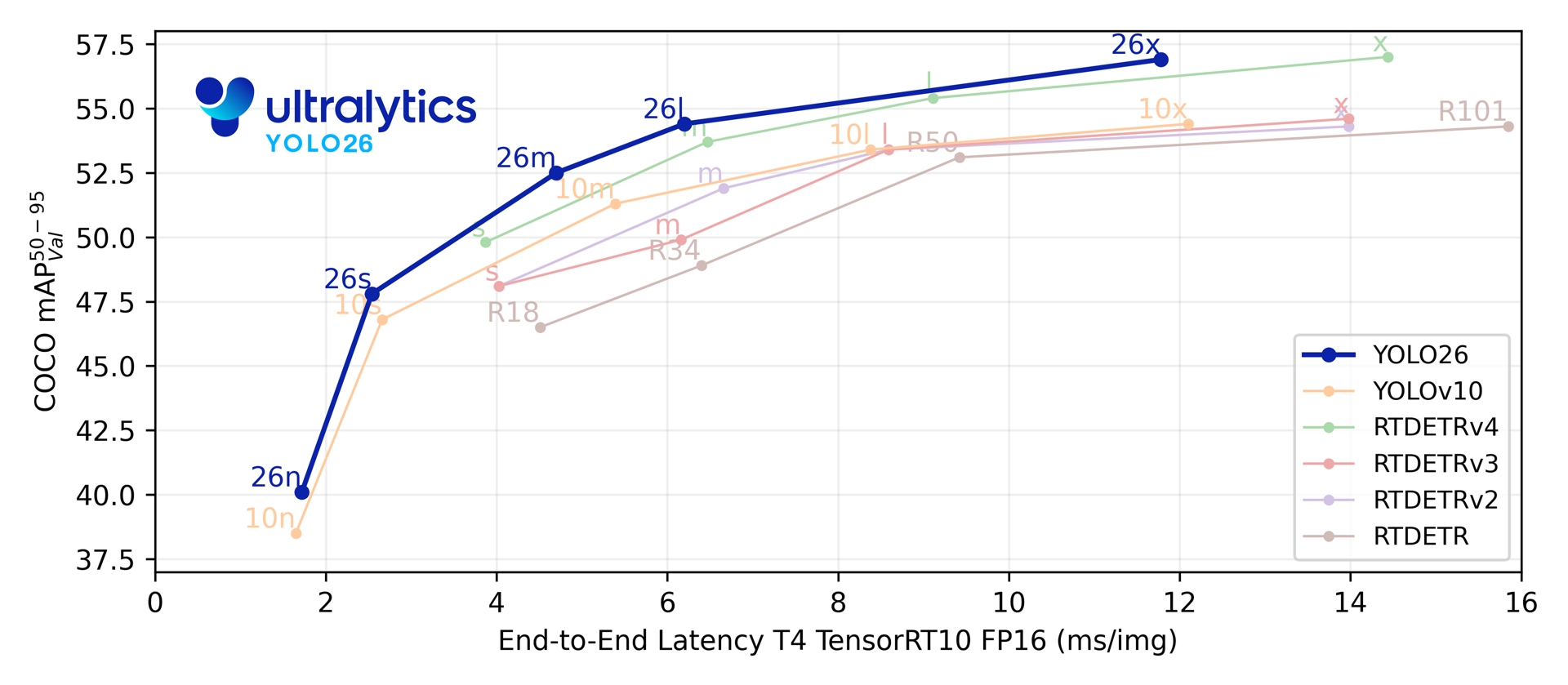
在五个检测尺度上,YOLO26 在 COCO 上达到了 40.9-57.5 mAP,且 T4 TensorRT 延迟仅为 1.7-11.8 毫秒。该论文还报告称,与 YOLO11n 相比,YOLO26n 在 Intel Xeon CPU @ 2.00 GHz 上的 CPU ONNX 推理速度提升了高达 43%。
from ultralytics import YOLO
model = YOLO("yolo26n.pt") # load a pretrained YOLO26n model
results = model("path/to/bus.jpg") # run inference在 Ultralytics Platform 上直接探索并运行 YOLO26 模型。
YOLO26 模型系列围绕四个设计领域构建:
- 原生端到端推理: 默认的一对一检测头无需非极大值抑制(NMS)即可生成预测,简化了部署并减少了后处理工作。
- 更轻量的框回归: YOLO26 移除了分布焦点损失(DFL),在保持无约束回归范围的同时降低了检测头的复杂度。
- 训练方案更新: 训练流水线结合了 MuSGD(一种 Muon + SGD 的混合优化器)、Progressive Loss 和 STAL(小目标感知标签分配),旨在提升优化效果,将监督信号转向推理阶段的检测头,并确保小目标拥有足够的正样本标签覆盖。已发布检查点背后的完整超参数记录在 YOLO26 训练方案指南中。
- 特定任务的头部和损失函数: YOLO26 增加了针对实例分割、语义分割变体、姿态估计和定向检测的专项设计,同时在不同任务间保持统一的模型流水线。
总而言之,这些更新优化了各模型尺度和部署目标在准确率与延迟之间的权衡。
Link to this section主要特性#
-
无 DFL 回归 YOLO26 移除了分布焦点损失(DFL),降低了检测头的复杂度并简化了模型导出。
-
端到端无需 NMS 推理 与传统检测器依赖 NMS 作为独立的后处理步骤不同,YOLO26 默认是原生端到端的。预测结果直接生成,从而降低了延迟并简化了生产环境集成。
-
Progressive Loss + STAL Progressive Loss 将训练重点转向推理阶段的头部,而 STAL 则改善了针对小目标的正标签覆盖率。
-
MuSGD 优化器 这是一个混合优化器,结合了 SGD 和 Muon,将大型语言模型训练中的优化思想应用于计算机视觉领域。
-
高效部署 简化的头部和无需 NMS 的默认路径减少了跨导出目标和硬件配置文件的推理开销,包括论文中报道的 YOLO26n 对比 YOLO11n 的 CPU ONNX 速度提升。
-
实例分割增强 引入了语义分割损失以提高模型收敛速度,并升级了原型模块(proto module),利用多尺度信息实现卓越的掩码质量。论文报告称,在 COCO 实例分割任务上,相较于 YOLO11,其框 AP 提升高达 +2.5,掩码 AP 提升高达 +3.7。
-
精准姿态估计 集成了 Residual Log-Likelihood Estimation (RLE) 以实现更精确的关键点定位,并优化了解码过程以提高推理速度。论文报告称,在 COCO 姿态估计任务上,其 AP 较 YOLO11 提升高达 +7.2。
-
改进的 OBB 解码 引入了专门的角度损失以提高方形物体的检测准确率,并优化了 OBB 解码以解决边界不连续问题。论文报告称,在 DOTA-v1.0 定向检测任务上,其 mAP 较 YOLO11 提升高达 +3.4。
Link to this section支持的任务和模式#
YOLO26 在五个模型尺度上支持标准的 Ultralytics 任务集:
| 模型 | 文件名 | 任务 | 推理 | 验证 | 训练 | 导出 |
|---|---|---|---|---|---|---|
| YOLO26 | yolo26n.pt yolo26s.pt yolo26m.pt yolo26l.pt yolo26x.pt | 检测 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-seg | yolo26n-seg.pt yolo26s-seg.pt yolo26m-seg.pt yolo26l-seg.pt yolo26x-seg.pt | 实例分割 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-sem | yolo26n-sem.pt yolo26s-sem.pt yolo26m-sem.pt yolo26l-sem.pt yolo26x-sem.pt | 语义分割 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-depth | yolo26n-depth.pt yolo26s-depth.pt yolo26m-depth.pt yolo26l-depth.pt yolo26x-depth.pt | 深度估计 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-pose | yolo26n-pose.pt yolo26s-pose.pt yolo26m-pose.pt yolo26l-pose.pt yolo26x-pose.pt | 姿态/关键点 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-obb | yolo26n-obb.pt yolo26s-obb.pt yolo26m-obb.pt yolo26l-obb.pt yolo26x-obb.pt | 定向检测 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-cls | yolo26n-cls.pt yolo26s-cls.pt yolo26m-cls.pt yolo26l-cls.pt yolo26x-cls.pt | 分类 | ✅ | ✅ | ✅ | ✅ |
此统一框架涵盖了实时检测、实例分割、语义分割、单目深度估计、分类、姿态估计和定向目标检测,并支持训练、验证、推理和导出。
yolo26-p2.yaml 和 yolo26-p6.yaml 增加了 P2(小目标)或 P6(大输入)检测头,仅作为 YAML 架构发布。没有针对特定尺度的 yolo26*-p2.pt 或 yolo26*-p6.pt 权重。你可以从 YAML 实例化缩放配置(例如 YOLO("yolo26n-p6.yaml")),并根据需要进行训练或微调。
Link to this section性能指标#
参阅 检测文档 获取在 COCO 上训练的这些模型的使用示例,这些模型包含 80 个预训练类别。
| 模型 | 尺寸 (像素) | mAPval 50-95 | mAPval 50-95(e2e) | 速度 CPU ONNX (ms) | 速度 T4 TensorRT10 (ms) | 参数量 (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO26n | 640 | 40.9 | 40.1 | 38.9 ± 0.7 | 1.7 ± 0.0 | 2.4 | 5.4 |
| YOLO26s | 640 | 48.6 | 47.8 | 87.2 ± 0.9 | 2.5 ± 0.0 | 9.5 | 20.7 |
| YOLO26m | 640 | 53.1 | 52.5 | 220.0 ± 1.4 | 4.7 ± 0.1 | 20.4 | 68.2 |
| YOLO26l | 640 | 55.0 | 54.4 | 286.2 ± 2.0 | 6.2 ± 0.2 | 24.8 | 86.4 |
| YOLO26x | 640 | 57.5 | 56.9 | 525.8 ± 4.0 | 11.8 ± 0.2 | 55.7 | 193.9 |
参数和 FLOPs 数值基于 model.fuse() 后的融合模型,该操作会合并 Conv 和 BatchNorm 层并移除辅助的一对多检测头。预训练检查点保留完整的训练架构,可能会显示更高的统计数值。
Link to this section使用示例#
本节提供简单的 YOLO26 训练和推理示例。有关这些模式及其他 模式 的完整文档,请参阅 预测 (Predict)、训练 (Train)、验证 (Val) 和 导出 (Export) 文档页面。
请注意,以下示例是针对YOLO26检测模型用于目标检测的。有关其他支持的任务,请参阅分割、语义分割、深度、分类、OBB和姿态文档。
PyTorch 预训练的 *.pt 模型以及配置文件 *.yaml 均可传递给 YOLO() 类,从而在 Python 中创建模型实例:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Run inference with the YOLO26n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)YOLO26 检测模型采用 双头架构,为不同的部署场景提供了灵活性:
- 一对一检测头(默认):无需 NMS 即可产生端到端预测,输出
(N, 300, 6),每张图片最多 300 个检测结果。此检测头针对快速推理和简化部署进行了优化。 - 一对多检测头:生成需要 NMS 后处理的传统 YOLO 输出,输出
(N, nc + 4, 8400),其中nc为类别数量。此检测头通常以额外的处理成本为代价,实现略高的精度。
你可以在导出、预测或验证过程中切换检测头:
from ultralytics import YOLO
model = YOLO("yolo26n.pt")
# Use one-to-one head (default, no NMS required)
results = model.predict("image.jpg") # inference
metrics = model.val(data="coco.yaml") # validation
model.export(format="onnx") # export
# Use one-to-many head (requires NMS)
results = model.predict("image.jpg", end2end=False) # inference
metrics = model.val(data="coco.yaml", end2end=False) # validation
model.export(format="onnx", end2end=False) # export选择取决于你的部署需求:使用一对一检测头以获得最大的速度和简便性,或者在精度为首要任务时使用一对多检测头。
Link to this sectionYOLOE-26:开放词汇检测与分割#
YOLO26 同时为 YOLOE-26 提供支持,这是一个开放词汇变体,它可以通过 文本提示 (text prompts)、视觉提示 (visual prompts) 或 无提示模式 (prompt-free mode) 来检测和分割对象类别,而无需在训练时学习固定的类别列表。YOLOE-26 保留了 YOLO26 的 NMS-free、端到端 (e2e) 设计,因此其开放词汇推理速度足够快,适用于目标类别随时间变化的动态环境。YOLOE-26x 在 LVIS minival 数据集上,文本提示下的 AP 为 40.6,视觉提示下为 38.5 AP,在无提示的 Non-E2E 设置下为 31.1 AP。
请参阅 YOLOE 文档 以查看各尺度的性能表格、无提示变体及完整使用示例。
Link to this section引用与致谢#
有关 YOLO26 架构、训练配方、任务头和 YOLOE-26 开放词汇扩展的完整技术描述,请阅读 Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models。如果你在研究中使用 YOLO26,请引用:
@misc{jocher2026ultralyticsyolo26unifiedrealtime,
title = {Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models},
author = {Glenn Jocher and Jing Qiu and Mengyu Liu and Shuai Lyu and Fatih Cagatay Akyon and Muhammet Esat Kalfaoglu},
year = {2026},
eprint = {2606.03748},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
doi = {10.48550/arXiv.2606.03748},
url = {https://arxiv.org/abs/2606.03748},
}YOLO26 的代码、模型和文档可在 Ultralytics GitHub 仓库 和 Ultralytics Docs 中获取,并遵循 AGPL-3.0 和 Enterprise 许可协议。
Link to this section常见问题解答#
Link to this sectionYOLO26 的主要改进是什么?#
- 无 DFL 回归:简化了检测头和导出路径
- 端到端无 NMS 推理:从默认推理路径中移除了 NMS
- 渐进式损失 + STAL:改进了训练对齐和小目标标签覆盖
- MuSGD 优化器:结合了 SGD 和受 Muon 启发的优化,以实现稳定的训练
- 任务特定的头和损失:改进了对分割、姿态和旋转检测的支持
Link to this sectionYOLO26 支持哪些任务?#
YOLO26 是一个统一的模型系列,为多个计算机视觉任务提供端到端支持:
每种尺寸变体 (n, s, m, l, x) 均支持所有任务,并通过 YOLOE-26 提供开放词汇版本。
Link to this section为什么 YOLO26 在部署方面如此高效?#
YOLO26 通过以下特性提升了部署效率:
- 默认支持无需 NMS 的原生端到端推理
- 无 DFL 回归及更轻量化的检测头
- 融合模型导出,移除仅用于训练的辅助组件
- 在 Intel Xeon CPU @ 2.00 GHz 上,YOLO26n 的 CPU ONNX 推理速度比 YOLO11n 快达 43%
- 灵活的导出格式,包括 TensorRT、ONNX、CoreML、LiteRT 和 OpenVINO
Link to this section如何开始使用 YOLO26?#
你可以通过 ultralytics 软件包下载 YOLO26 模型。安装或更新该软件包并加载模型:
from ultralytics import YOLO
# Load a pretrained YOLO26 nano model
model = YOLO("yolo26n.pt")
# Run inference on an image
results = model("image.jpg")请参阅 使用示例 部分以获取训练、验证和导出说明。