Link to this sectionUltralytics YOLO26#
Link to this sectionDescripción general#
Ultralytics YOLO26 es una familia unificada de modelos de visión en tiempo real descrita en el artículo de Ultralytics YOLO26. Introduce una inferencia nativa de extremo a extremo, una cabecera de detección más ligera, una receta de entrenamiento actualizada y cabeceras específicas para tareas de detección, segmentación, estimación de poses, clasificación y detección orientada.
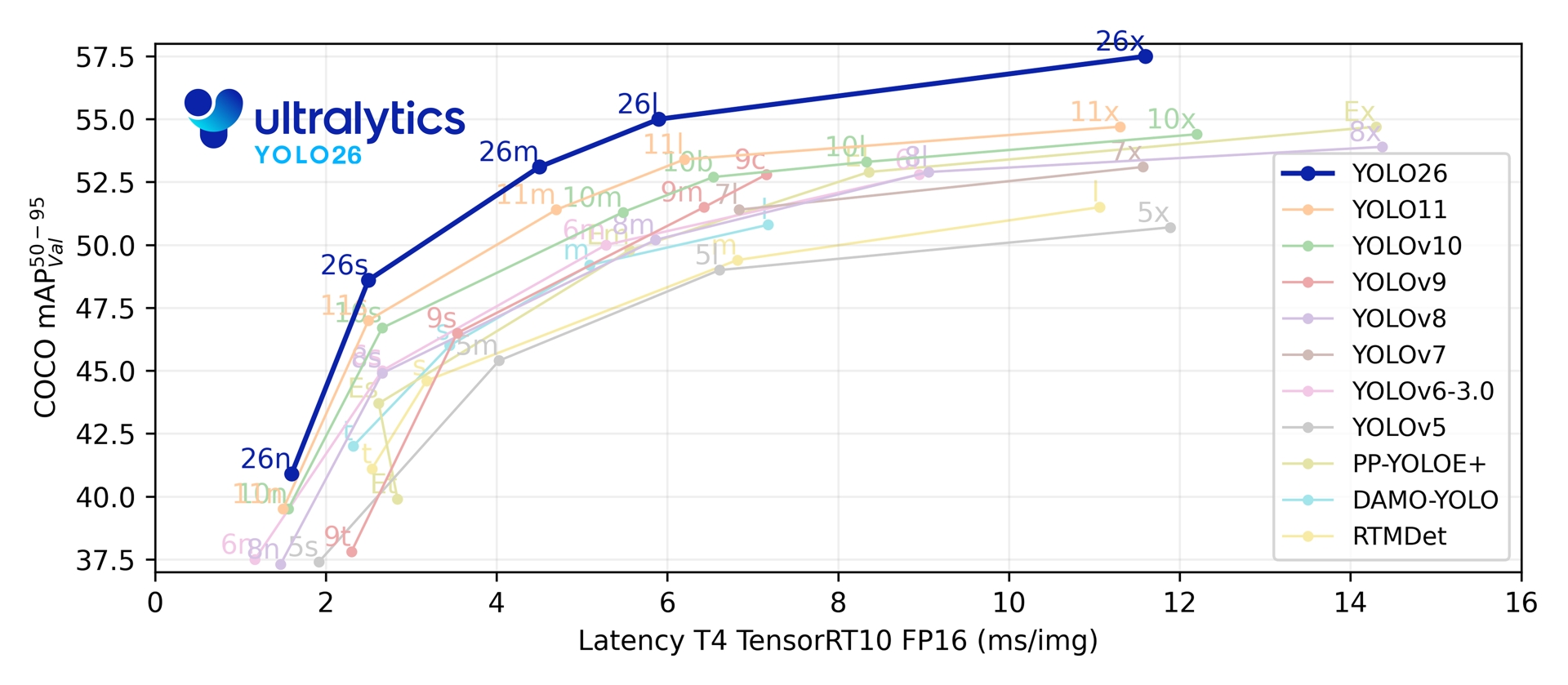
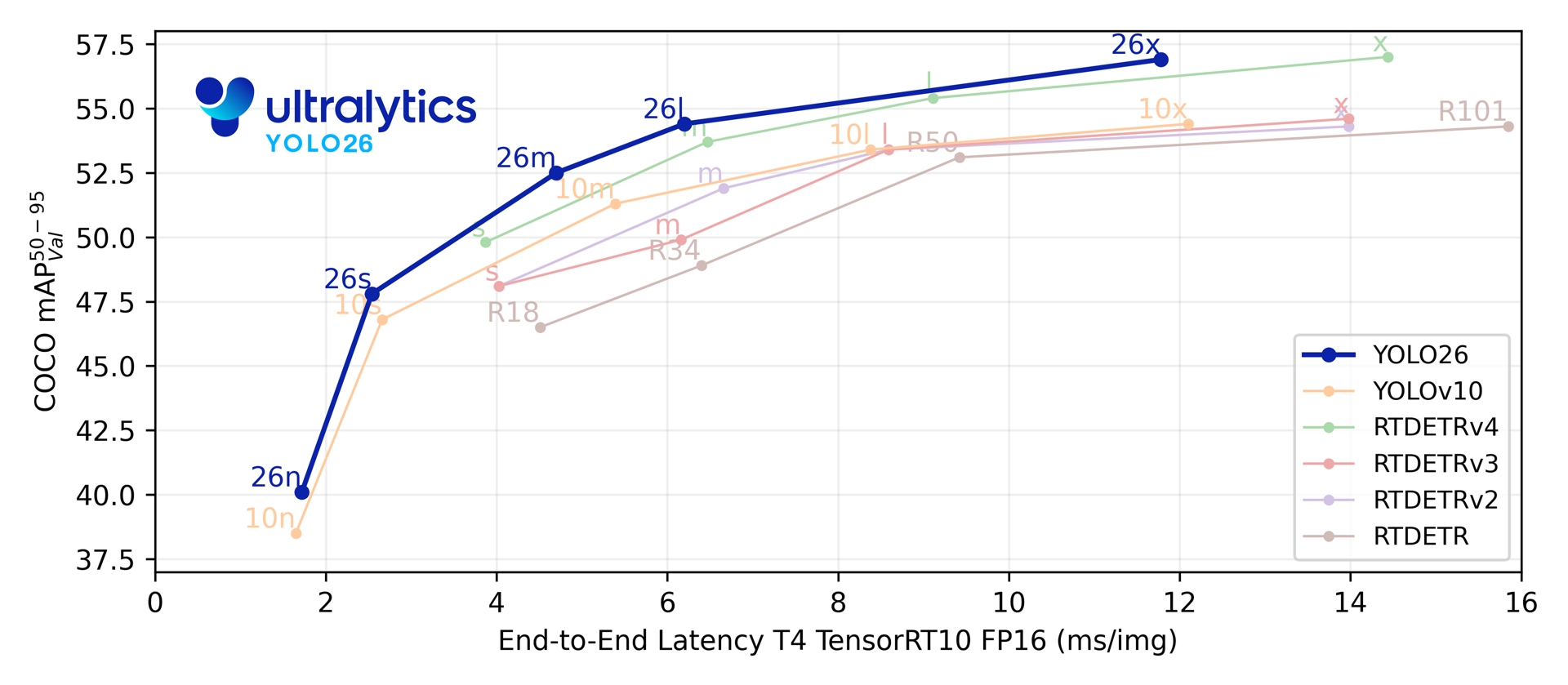
A través de sus cinco escalas de detección, YOLO26 alcanza 40.9-57.5 mAP en COCO con una latencia de 1.7-11.8 ms en TensorRT sobre T4. El artículo también reporta una inferencia en CPU ONNX hasta un 43% más rápida para YOLO26n en comparación con YOLO11n en una CPU Intel Xeon a 2.00 GHz.
from ultralytics import YOLO
model = YOLO("yolo26n.pt") # load a pretrained YOLO26n model
results = model("path/to/bus.jpg") # run inferenceExplora y ejecuta modelos YOLO26 directamente en la Plataforma Ultralytics.
La familia de modelos YOLO26 está construida en torno a cuatro áreas de diseño:
- Inferencia nativa de extremo a extremo: La cabecera de detección predeterminada de uno a uno produce predicciones sin supresión de no máximos (NMS), lo que simplifica el despliegue y reduce el post-procesamiento.
- Regresión de cajas más ligera: YOLO26 elimina la Distribution Focal Loss (DFL), reduciendo la complejidad de la cabecera de detección mientras preserva un rango de regresión sin restricciones.
- Actualizaciones en la receta de entrenamiento: La tubería de entrenamiento combina MuSGD (un optimizador híbrido de Muon + SGD), Progressive Loss y STAL (Small-Target-Aware Label Assignment) para mejorar la optimización, desplazar la supervisión hacia la cabeza de inferencia y mantener una cobertura de etiquetas positiva para objetos pequeños. Los hiperparámetros completos detrás de los checkpoints publicados están documentados en la guía de la receta de entrenamiento de YOLO26.
- Cabeceras y pérdidas específicas para tareas: YOLO26 añade diseños específicos para segmentación de instancias, variantes de segmentación semántica, estimación de poses y detección orientada, manteniendo una única tubería de modelo para todas las tareas.
En conjunto, estas actualizaciones mejoran el equilibrio entre precisión y latencia a través de diversas escalas de modelos y objetivos de despliegue.
Link to this sectionCaracterísticas clave#
-
Regresión sin DFL YOLO26 elimina la Distribution Focal Loss (DFL), reduciendo la complejidad de la cabecera de detección y simplificando la exportación.
-
Inferencia de extremo a extremo sin NMS A diferencia de los detectores tradicionales que dependen de la NMS como un paso de post-procesamiento separado, YOLO26 es nativamente de extremo a extremo de forma predeterminada. Las predicciones se generan directamente, lo que reduce la latencia y facilita la integración en producción.
-
Progressive Loss + STAL Progressive Loss desplaza el énfasis del entrenamiento hacia la cabecera de tiempo de inferencia, mientras que STAL mejora la cobertura de etiquetas positivas para objetos pequeños.
-
Optimizador MuSGD Un optimizador híbrido que combina SGD con Muon, adaptando ideas de optimización del entrenamiento de modelos de lenguaje grandes a la visión artificial.
-
Despliegue eficiente La cabecera simplificada y la ruta predeterminada sin NMS reducen la sobrecarga de inferencia en todos los objetivos de exportación y perfiles de hardware, incluyendo la aceleración en CPU ONNX reportada en el artículo para YOLO26n frente a YOLO11n.
-
Mejoras en segmentación de instancias Introduce la pérdida de segmentación semántica para mejorar la convergencia del modelo y un módulo proto actualizado que aprovecha la información multiescala para una calidad de máscara superior. El artículo reporta ganancias sobre YOLO11 de hasta +2.5 AP en cajas y +3.7 AP en máscaras en COCO para segmentación de instancias.
-
Estimación de poses de precisión Integra Residual Log-Likelihood Estimation (RLE) para una localización de puntos clave más precisa y optimiza el proceso de decodificación para aumentar la velocidad de inferencia. El artículo reporta hasta +7.2 AP sobre YOLO11 en la estimación de poses en COCO.
-
Decodificación OBB refinada Introduce una pérdida angular especializada para mejorar la precisión de detección de objetos cuadrados y optimiza la decodificación OBB para resolver problemas de discontinuidad en los bordes. El artículo reporta hasta +3.4 mAP sobre YOLO11 en la detección orientada DOTA-v1.0.
Link to this sectionTareas y modos soportados#
YOLO26 soporta el conjunto estándar de tareas de Ultralytics a través de cinco escalas de modelo:
| Modelo | Nombres de archivo | Tarea | Inferencia | Validación | Entrenamiento | Exportar |
|---|---|---|---|---|---|---|
| YOLO26 | yolo26n.pt yolo26s.pt yolo26m.pt yolo26l.pt yolo26x.pt | Detección | ✅ | ✅ | ✅ | ✅ |
| YOLO26-seg | yolo26n-seg.pt yolo26s-seg.pt yolo26m-seg.pt yolo26l-seg.pt yolo26x-seg.pt | Segmentación de instancias | ✅ | ✅ | ✅ | ✅ |
| YOLO26-sem | yolo26n-sem.pt yolo26s-sem.pt yolo26m-sem.pt yolo26l-sem.pt yolo26x-sem.pt | Segmentación semántica | ✅ | ✅ | ✅ | ✅ |
| YOLO26-depth | yolo26n-depth.pt yolo26s-depth.pt yolo26m-depth.pt yolo26l-depth.pt yolo26x-depth.pt | Estimación de profundidad | ✅ | ✅ | ✅ | ✅ |
| YOLO26-pose | yolo26n-pose.pt yolo26s-pose.pt yolo26m-pose.pt yolo26l-pose.pt yolo26x-pose.pt | Pose/Puntos clave | ✅ | ✅ | ✅ | ✅ |
| YOLO26-obb | yolo26n-obb.pt yolo26s-obb.pt yolo26m-obb.pt yolo26l-obb.pt yolo26x-obb.pt | Detección orientada | ✅ | ✅ | ✅ | ✅ |
| YOLO26-cls | yolo26n-cls.pt yolo26s-cls.pt yolo26m-cls.pt yolo26l-cls.pt yolo26x-cls.pt | Clasificación | ✅ | ✅ | ✅ | ✅ |
Este marco unificado cubre detección en tiempo real, segmentación de instancias, segmentación semántica, estimación de profundidad monocular, clasificación, estimación de poses y detección de objetos orientados con soporte para entrenamiento, validación, inferencia y exportación.
yolo26-p2.yaml y yolo26-p6.yaml añaden una cabecera de detección P2 (para objetos pequeños) o P6 (para entradas grandes) y se suministran únicamente como arquitecturas YAML. No se han lanzado pesos específicos de escala yolo26*-p2.pt o yolo26*-p6.pt. Instancia una configuración escalada desde YAML (por ejemplo, YOLO("yolo26n-p6.yaml")) y entrénala o ajústala según sea necesario.
Link to this sectionMétricas de rendimiento#
Consulta la Documentación de detección para ver ejemplos de uso con estos modelos entrenados en COCO, que incluyen 80 clases preentrenadas.
| Modelo | tamaño (píxeles) | mAPval 50-95 | mAPval 50-95(e2e) | Velocidad CPU ONNX (ms) | Velocidad T4 TensorRT10 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO26n | 640 | 40.9 | 40.1 | 38.9 ± 0.7 | 1.7 ± 0.0 | 2.4 | 5.4 |
| YOLO26s | 640 | 48.6 | 47.8 | 87.2 ± 0.9 | 2.5 ± 0.0 | 9.5 | 20.7 |
| YOLO26m | 640 | 53.1 | 52.5 | 220.0 ± 1.4 | 4.7 ± 0.1 | 20.4 | 68.2 |
| YOLO26l | 640 | 55.0 | 54.4 | 286.2 ± 2.0 | 6.2 ± 0.2 | 24.8 | 86.4 |
| YOLO26x | 640 | 57.5 | 56.9 | 525.8 ± 4.0 | 11.8 ± 0.2 | 55.7 | 193.9 |
Los valores de parámetros y FLOPs corresponden al modelo fusionado tras usar model.fuse(), que combina las capas Conv y BatchNorm y elimina la cabecera auxiliar de detección uno-a-muchos. Los puntos de control preentrenados conservan la arquitectura de entrenamiento completa y pueden mostrar recuentos más elevados.
Link to this sectionEjemplos de uso#
Esta sección proporciona ejemplos sencillos de entrenamiento e inferencia con YOLO26. Para obtener la documentación completa sobre estos y otros modos, consulta las páginas de documentación de Predict, Train, Val y Export.
Ten en cuenta que el ejemplo siguiente es para modelos de Detección de YOLO26 para detección de objetos. Para tareas adicionales compatibles, consulta la documentación sobre Segmentación, Segmentación semántica, Profundidad, Clasificación, OBB y Pose.
Se pueden pasar modelos PyTorch preentrenados *.pt, así como archivos de configuración *.yaml, a la clase YOLO() para crear una instancia del modelo en Python:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Run inference with the YOLO26n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)Los modelos de detección YOLO26 utilizan una arquitectura de doble cabecera que ofrece flexibilidad para diferentes escenarios de despliegue:
- Cabecera uno-a-uno (predeterminada): Produce predicciones de extremo a extremo sin NMS, generando
(N, 300, 6)con un máximo de 300 detecciones por imagen. Esta cabecera está optimizada para una inferencia rápida y un despliegue simplificado. - Cabecera uno-a-muchos: Genera salidas YOLO tradicionales que requieren post-procesamiento con NMS, generando
(N, nc + 4, 8400)dondences el número de clases. Esta cabecera suele lograr una precisión ligeramente superior a costa de un procesamiento adicional.
Puedes cambiar entre cabeceras durante la exportación, la predicción o la validación:
from ultralytics import YOLO
model = YOLO("yolo26n.pt")
# Use one-to-one head (default, no NMS required)
results = model.predict("image.jpg") # inference
metrics = model.val(data="coco.yaml") # validation
model.export(format="onnx") # export
# Use one-to-many head (requires NMS)
results = model.predict("image.jpg", end2end=False) # inference
metrics = model.val(data="coco.yaml", end2end=False) # validation
model.export(format="onnx", end2end=False) # exportLa elección depende de tus requisitos de despliegue: utiliza la cabecera uno-a-uno para obtener la máxima velocidad y simplicidad, o la cabecera uno-a-muchos cuando la precisión sea la máxima prioridad.
Link to this sectionYOLOE-26: Detección y segmentación de vocabulario abierto#
YOLO26 también impulsa YOLOE-26, una variante de vocabulario abierto que detecta y segmenta categorías de objetos a partir de indicaciones de texto, indicaciones visuales o un modo sin indicaciones en lugar de una lista de clases fija aprendida durante el entrenamiento. YOLOE-26 mantiene el diseño sin NMS y de extremo a extremo (e2e) de YOLO26, por lo que la inferencia de vocabulario abierto sigue siendo lo suficientemente rápida para entornos dinámicos donde las categorías objetivo cambian con el tiempo. YOLOE-26x alcanza 40.6 AP en LVIS minival bajo indicaciones de texto, 38.5 AP bajo indicaciones visuales y 31.1 AP en la configuración sin indicaciones Non-E2E.
Consulta la documentación de YOLOE para ver tablas de rendimiento por escala, variantes sin indicaciones y ejemplos de uso completos.
Link to this sectionCitas y agradecimientos#
Para una descripción técnica completa de la arquitectura de YOLO26, la receta de entrenamiento, las cabezas de tarea y la extensión de vocabulario abierto de YOLOE-26, lee Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models. Si usas YOLO26 en tu investigación, por favor cita:
@misc{jocher2026ultralyticsyolo26unifiedrealtime,
title = {Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models},
author = {Glenn Jocher and Jing Qiu and Mengyu Liu and Shuai Lyu and Fatih Cagatay Akyon and Muhammet Esat Kalfaoglu},
year = {2026},
eprint = {2606.03748},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
doi = {10.48550/arXiv.2606.03748},
url = {https://arxiv.org/abs/2606.03748},
}El código, los modelos y la documentación de YOLO26 están disponibles en el repositorio de GitHub de Ultralytics y en Ultralytics Docs bajo licencias AGPL-3.0 y Enterprise.
Link to this sectionFAQ#
Link to this section¿Cuáles son las mejoras clave en YOLO26?#
- Regresión sin DFL: Simplifica la cabeza de detección y la ruta de exportación
- Inferencia de extremo a extremo sin NMS: Elimina el NMS de la ruta de inferencia predeterminada
- Progressive Loss + STAL: Mejora la alineación del entrenamiento y la cobertura de etiquetas para objetos pequeños
- Optimizador MuSGD: Combina SGD con una optimización inspirada en Muon para un entrenamiento estable
- Cabezas y funciones de pérdida específicas para cada tarea: Mejora el soporte para segmentación, pose y detección orientada
Link to this section¿Qué tareas admite YOLO26?#
YOLO26 es una familia de modelos unificada, que proporciona soporte integral para múltiples tareas de visión artificial:
- Detección de objetos
- Segmentación de instancias
- Segmentación semántica
- Estimación de profundidad monocular
- Clasificación de imágenes
- Estimación de pose
- Detección de objetos orientados (OBB)
Cada variante de tamaño (n, s, m, l, x) admite todas las tareas, además de versiones de vocabulario abierto a través de YOLOE-26.
Link to this section¿Por qué es YOLO26 eficiente para el despliegue?#
YOLO26 mejora la eficiencia del despliegue con:
- Inferencia nativa de extremo a extremo sin NMS por defecto
- Regresión sin DFL y una cabecera de detección más ligera
- Exportación de modelos fusionados que elimina componentes auxiliares exclusivos del entrenamiento
- Hasta un 43% más de rapidez en la inferencia ONNX en CPU para YOLO26n frente a YOLO11n en una CPU Intel Xeon @ 2.00 GHz
- Formatos de exportación flexibles, incluyendo TensorRT, ONNX, CoreML, LiteRT y OpenVINO
Link to this section¿Cómo empiezo con YOLO26?#
Los modelos YOLO26 están disponibles para su descarga a través del paquete ultralytics. Instala o actualiza el paquete y carga un modelo:
from ultralytics import YOLO
# Load a pretrained YOLO26 nano model
model = YOLO("yolo26n.pt")
# Run inference on an image
results = model("image.jpg")Consulta la sección Ejemplos de uso para obtener instrucciones sobre entrenamiento, validación y exportación.